 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Development and Validation of a Novel Prognostic Model for Predicting AMD Progression Using Longitudinal Fundus Images
Jul 10, 2020
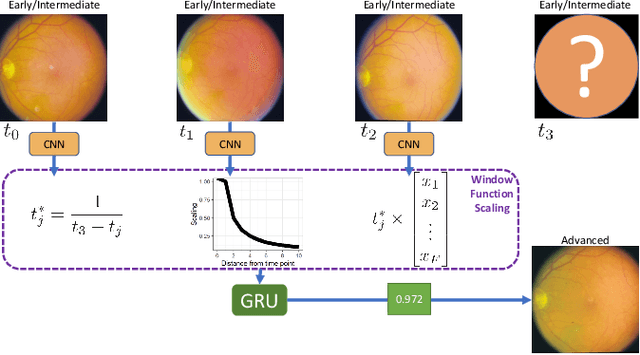
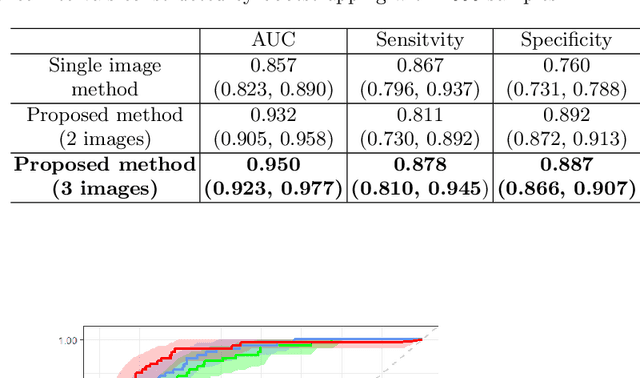
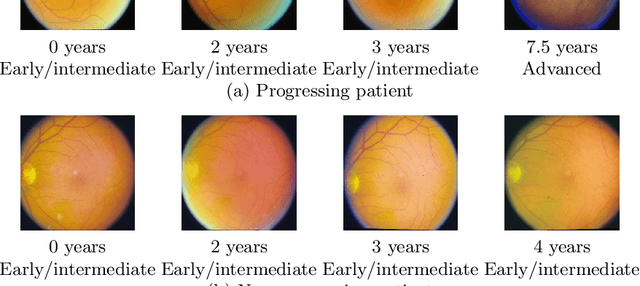
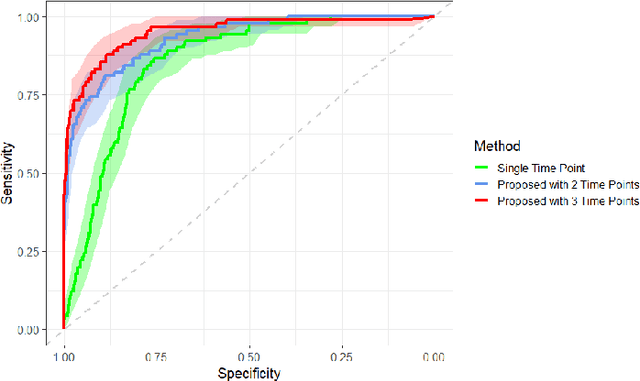
Prognostic models aim to predict the future course of a disease or condition and are a vital component of personalized medicine. Statistical models make use of longitudinal data to capture the temporal aspect of disease progression; however, these models require prior feature extraction. Deep learning avoids explicit feature extraction, meaning we can develop models for images where features are either unknown or impossible to quantify accurately. Previous prognostic models using deep learning with imaging data require annotation during training or only utilize a single time point. We propose a novel deep learning method to predict the progression of diseases using longitudinal imaging data with uneven time intervals, which requires no prior feature extraction. Given previous images from a patient, our method aims to predict whether the patient will progress onto the next stage of the disease. The proposed method uses InceptionV3 to produce feature vectors for each image. In order to account for uneven intervals, a novel interval scaling is proposed. Finally, a Recurrent Neural Network is used to prognosticate the disease. We demonstrate our method on a longitudinal dataset of color fundus images from 4903 eyes with age-related macular degeneration (AMD), taken from the Age-Related Eye Disease Study, to predict progression to late AMD. Our method attains a testing sensitivity of 0.878, a specificity of 0.887, and an area under the receiver operating characteristic of 0.950. We compare our method to previous methods, displaying superior performance in our model. Class activation maps display how the network reaches the final decision.
Overcoming Classifier Imbalance for Long-tail Object Detection with Balanced Group Softmax
Jun 18, 2020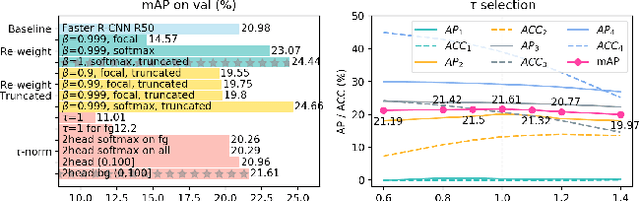
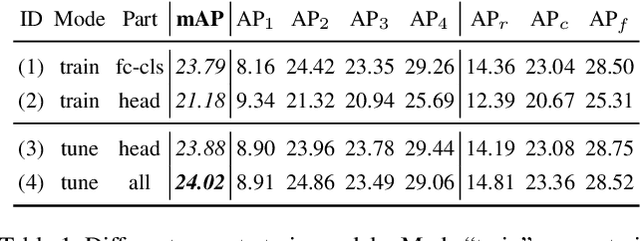
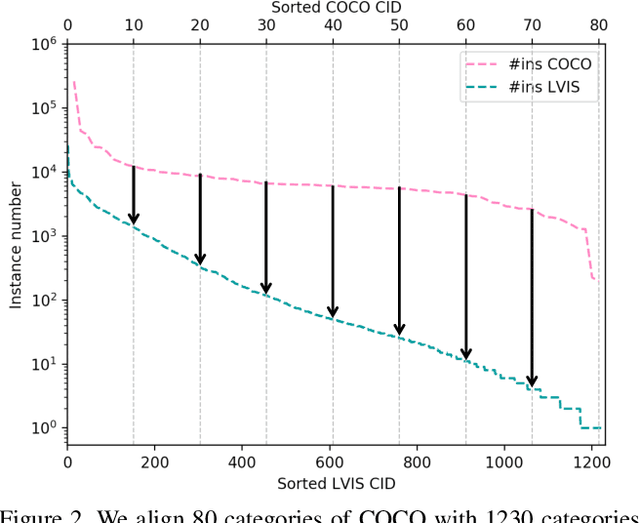
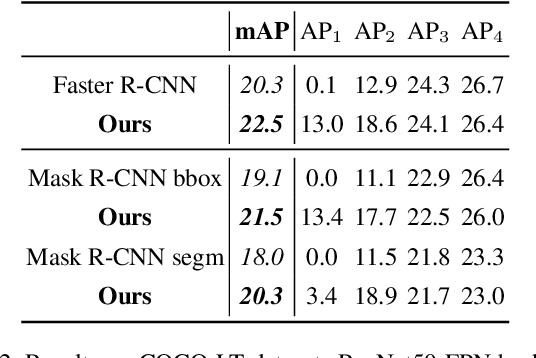
Solving long-tail large vocabulary object detection with deep learning based models is a challenging and demanding task, which is however under-explored.In this work, we provide the first systematic analysis on the underperformance of state-of-the-art models in front of long-tail distribution. We find existing detection methods are unable to model few-shot classes when the dataset is extremely skewed, which can result in classifier imbalance in terms of parameter magnitude. Directly adapting long-tail classification models to detection frameworks can not solve this problem due to the intrinsic difference between detection and classification.In this work, we propose a novel balanced group softmax (BAGS) module for balancing the classifiers within the detection frameworks through group-wise training. It implicitly modulates the training process for the head and tail classes and ensures they are both sufficiently trained, without requiring any extra sampling for the instances from the tail classes.Extensive experiments on the very recent long-tail large vocabulary object recognition benchmark LVIS show that our proposed BAGS significantly improves the performance of detectors with various backbones and frameworks on both object detection and instance segmentation. It beats all state-of-the-art methods transferred from long-tail image classification and establishes new state-of-the-art.Code is available at https://github.com/FishYuLi/BalancedGroupSoftmax.
Stochastic Conditional Generative Networks with Basis Decomposition
Sep 25, 2019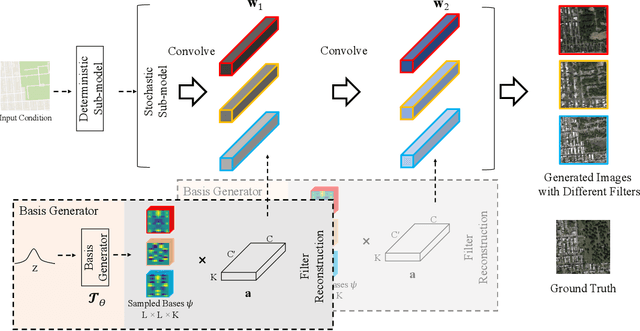
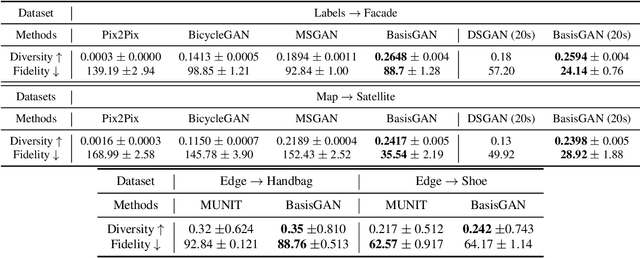


While generative adversarial networks (GANs) have revolutionized machine learning, a number of open questions remain to fully understand them and exploit their power. One of these questions is how to efficiently achieve proper diversity and sampling of the multi-mode data space. To address this, we introduce BasisGAN, a stochastic conditional multi-mode image generator. By exploiting the observation that a convolutional filter can be well approximated as a linear combination of a small set of basis elements, we learn a plug-and-played basis generator to stochastically generate basis elements, with just a few hundred of parameters, to fully embed stochasticity into convolutional filters. By sampling basis elements instead of filters, we dramatically reduce the cost of modeling the parameter space with no sacrifice on either image diversity or fidelity. To illustrate this proposed plug-and-play framework, we construct variants of BasisGAN based on state-of-the-art conditional image generation networks, and train the networks by simply plugging in a basis generator, without additional auxiliary components, hyperparameters, or training objectives. The experimental success is complemented with theoretical results indicating how the perturbations introduced by the proposed sampling of basis elements can propagate to the appearance of generated images.
MimickNet, Matching Clinical Post-Processing Under Realistic Black-Box Constraints
Aug 15, 2019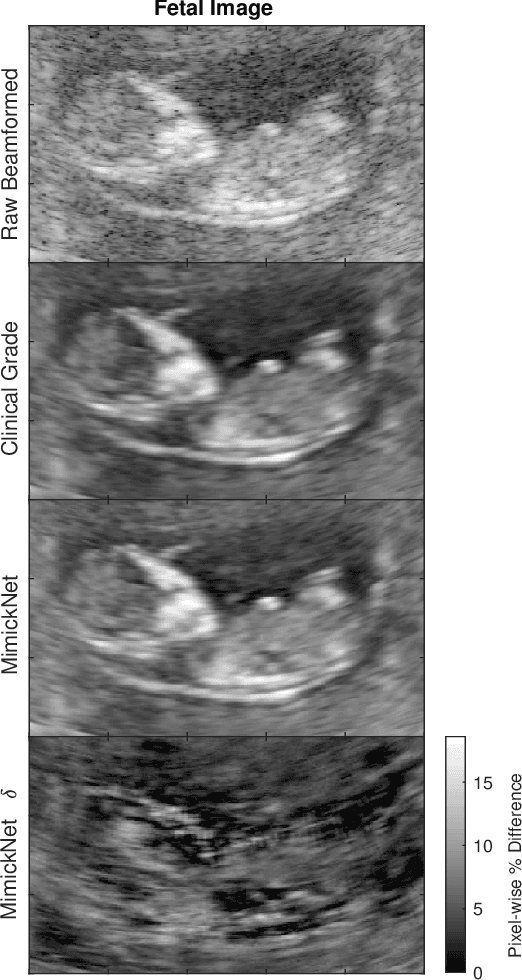
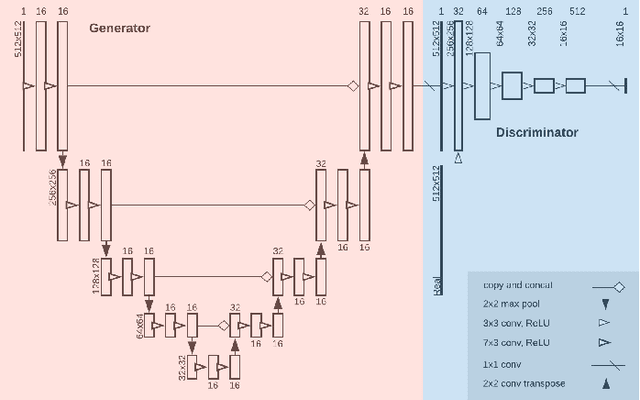
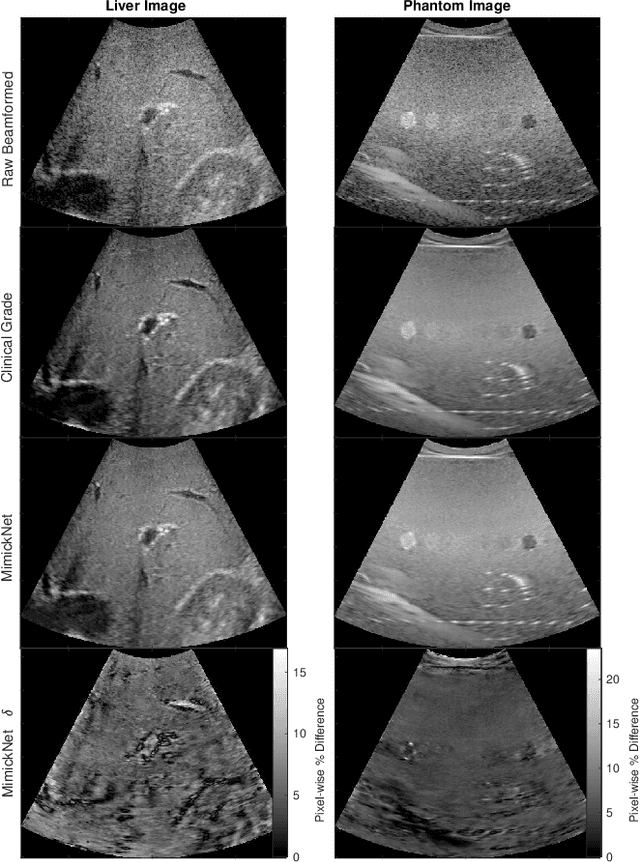
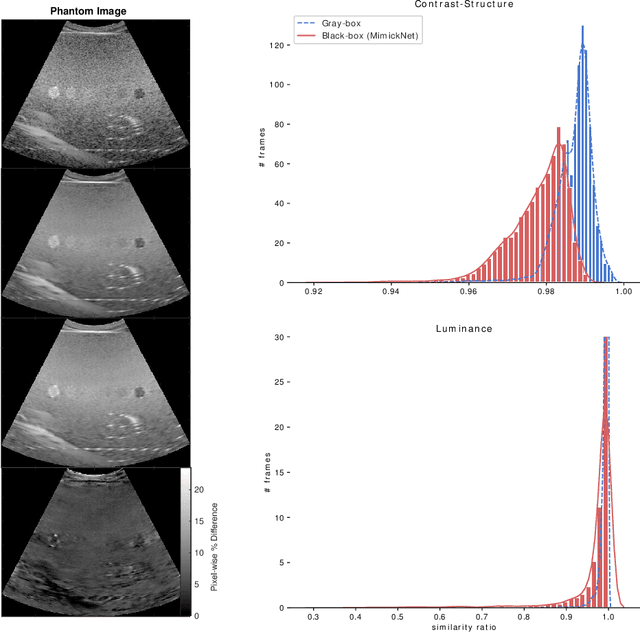
Image post-processing is used in clinical-grade ultrasound scanners to improve image quality (e.g., reduce speckle noise and enhance contrast). These post-processing techniques vary across manufacturers and are generally kept proprietary, which presents a challenge for researchers looking to match current clinical-grade workflows. We introduce a deep learning framework, MimickNet, that transforms raw conventional delay-and-summed (DAS) beams into the approximate post-processed images found on clinical-grade scanners. Training MimickNet only requires post-processed image samples from a scanner of interest without the need for explicit pairing to raw DAS data. This flexibility allows it to hypothetically approximate any manufacturer's post-processing without access to the pre-processed data. MimickNet generates images with an average similarity index measurement (SSIM) of 0.930$\pm$0.0892 on a 300 cineloop test set, and it generalizes to cardiac cineloops outside of our train-test distribution achieving an SSIM of 0.967$\pm$0.002. We also explore the theoretical SSIM achievable by evaluating MimickNet performance when trained under gray-box constraints (i.e., when both pre-processed and post-processed images are available). To our knowledge, this is the first work to establish deep learning models that closely approximate current clinical-grade ultrasound post-processing under realistic black-box constraints where before and after post-processing data is unavailable. MimickNet serves as a clinical post-processing baseline for future works in ultrasound image formation to compare against. To this end, we have made the MimickNet software open source.
Learning crystal plasticity using digital image correlation: Examples from discrete dislocation dynamics
Sep 24, 2017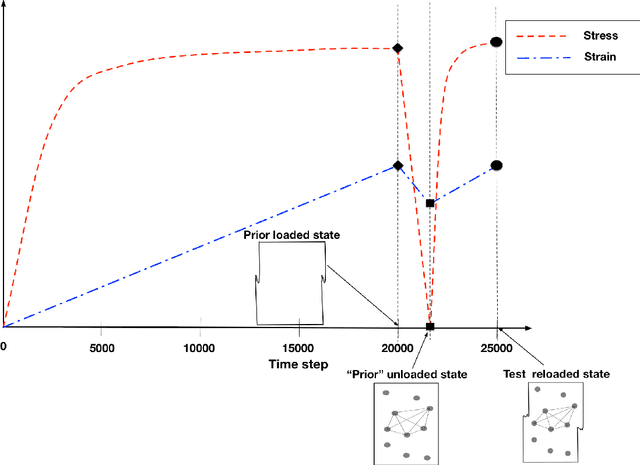
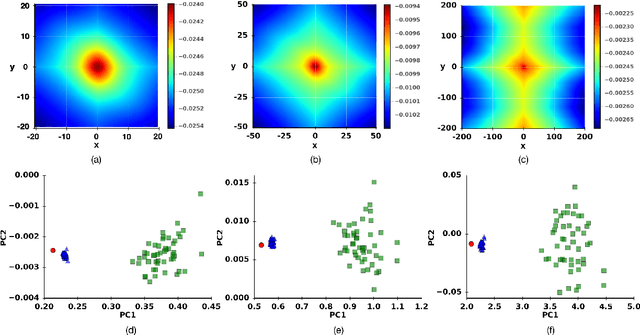
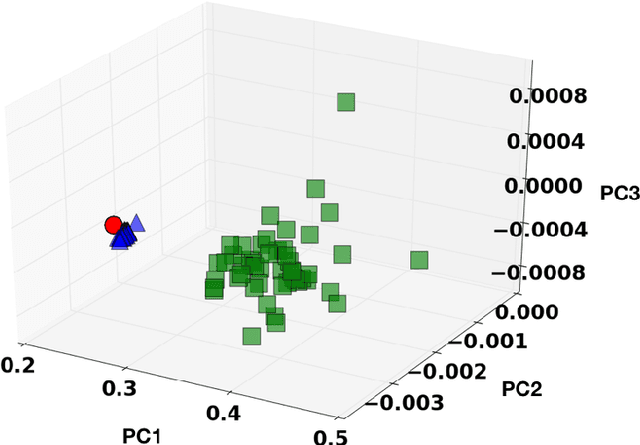
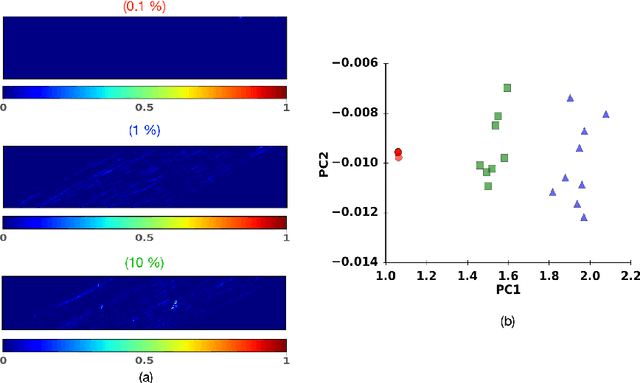
Digital image correlation (DIC) is a well-established, non-invasive technique for tracking and quantifying the deformation of mechanical samples under strain. While it provides an obvious way to observe incremental and aggregate displacement information, it seems likely that DIC data sets, which after all reflect the spatially-resolved response of a microstructure to loads, contain much richer information than has generally been extracted from them. In this paper, we demonstrate a machine-learning approach to quantifying the prior deformation history of a crystalline sample based on its response to a subsequent DIC test. This prior deformation history is encoded in the microstructure through the inhomogeneity of the dislocation microstructure, and in the spatial correlations of the dislocation patterns, which mediate the system's response to the DIC test load. Our domain consists of deformed crystalline thin films generated by a discrete dislocation plasticity simulation. We explore the range of applicability of machine learning (ML) for typical experimental protocols, and as a function of possible size effects and stochasticity. Plasticity size effects may directly influence the data, rendering unsupervised techniques unable to distinguish different plasticity regimes.
A Comprehensive Review of Image Enhancement Techniques
Mar 22, 2010

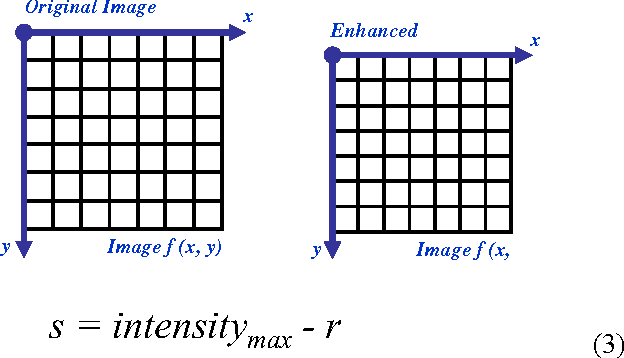
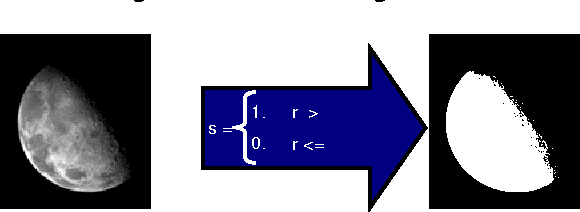
Principle objective of Image enhancement is to process an image so that result is more suitable than original image for specific application. Digital image enhancement techniques provide a multitude of choices for improving the visual quality of images. Appropriate choice of such techniques is greatly influenced by the imaging modality, task at hand and viewing conditions. This paper will provide an overview of underlying concepts, along with algorithms commonly used for image enhancement. The paper focuses on spatial domain techniques for image enhancement, with particular reference to point processing methods and histogram processing.
Accuracy comparison across face recognition algorithms: Where are we on measuring race bias?
Dec 16, 2019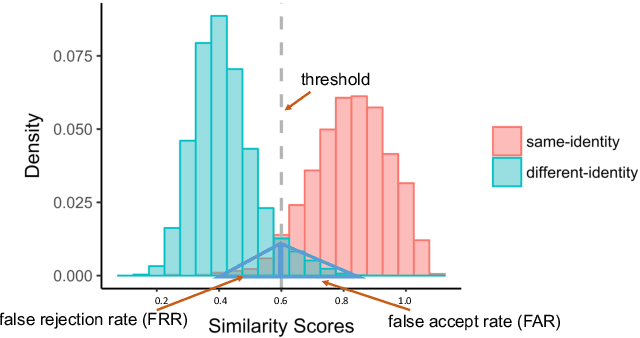
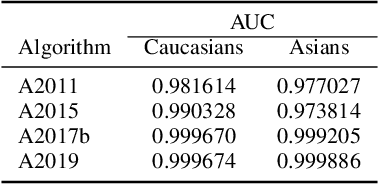

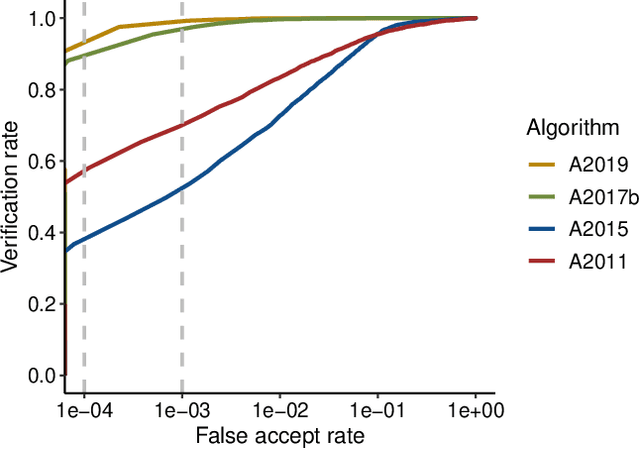
Previous generations of face recognition algorithms differ in accuracy for faces of different races (race bias). Whether deep convolutional neural networks (DCNNs) are race biased is less studied. To measure race bias in algorithms, it is important to consider the underlying factors. Here, we present the possible underlying factors and methodological considerations for assessing race bias in algorithms. We investigate data-driven and scenario modeling factors. Data-driven factors include image quality, image population statistics, and algorithm architecture. Scenario modeling considers the role of the "user" of the algorithm (e.g., threshold decisions and demographic constraints). To illustrate how these issues apply, we present data from four face recognition algorithms (one pre- DCNN, three DCNN) for Asian and Caucasian faces. First, for all four algorithms, the degree of bias varied depending on the identification decision threshold. Second, for all algorithms, to achieve equal false accept rates (FARs), Asian faces required higher identification thresholds than Caucasian faces. Third, dataset difficulty affected both overall recognition accuracy and race bias. Fourth, demographic constraints on the formulation of the distributions used in the test, impacted estimates of algorithm accuracy. We conclude with a recommended checklist for measuring race bias in face recognition algorithms.
Compositional Model based Fisher Vector Coding for Image Classification
Jan 08, 2017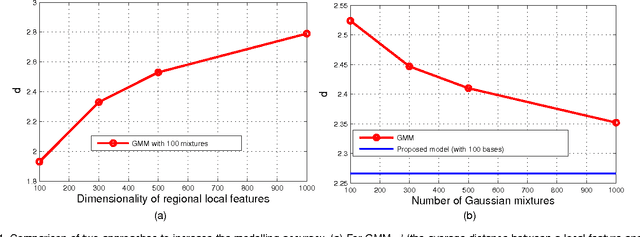
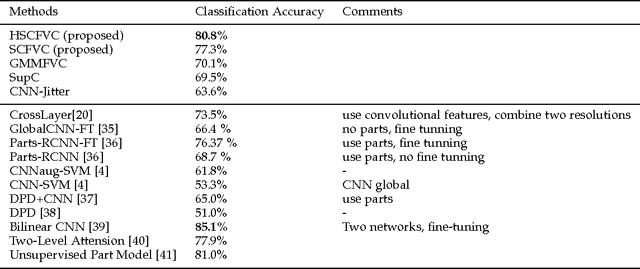
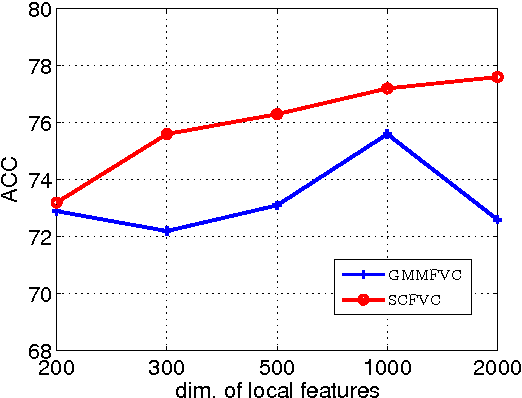

Deriving from the gradient vector of a generative model of local features, Fisher vector coding (FVC) has been identified as an effective coding method for image classification. Most, if not all, FVC implementations employ the Gaussian mixture model (GMM) to depict the generation process of local features. However, the representative power of the GMM could be limited because it essentially assumes that local features can be characterized by a fixed number of feature prototypes and the number of prototypes is usually small in FVC. To handle this limitation, in this paper we break the convention which assumes that a local feature is drawn from one of few Gaussian distributions. Instead, we adopt a compositional mechanism which assumes that a local feature is drawn from a Gaussian distribution whose mean vector is composed as the linear combination of multiple key components and the combination weight is a latent random variable. In this way, we can greatly enhance the representative power of the generative model of FVC. To implement our idea, we designed two particular generative models with such a compositional mechanism.
Geometric algorithms for predicting resilience and recovering damage in neural networks
May 23, 2020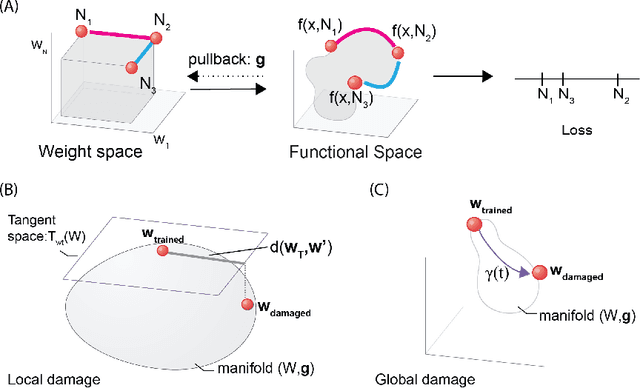
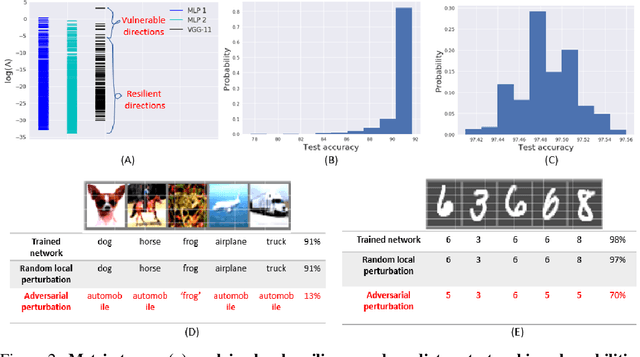
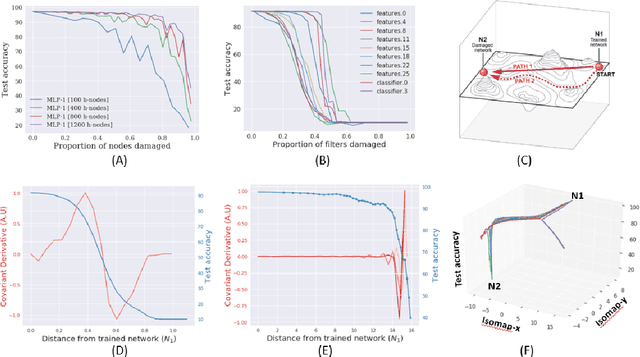
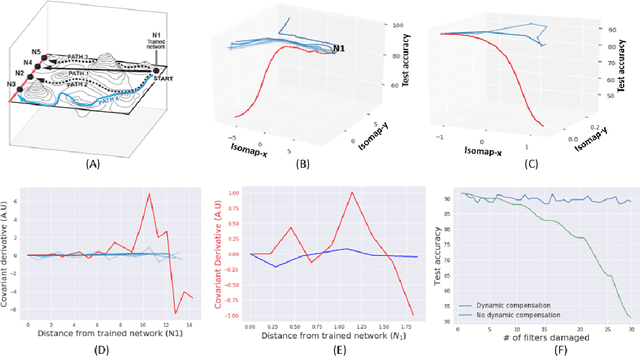
Biological neural networks have evolved to maintain performance despite significant circuit damage. To survive damage, biological network architectures have both intrinsic resilience to component loss and also activate recovery programs that adjust network weights through plasticity to stabilize performance. Despite the importance of resilience in technology applications, the resilience of artificial neural networks is poorly understood, and autonomous recovery algorithms have yet to be developed. In this paper, we establish a mathematical framework to analyze the resilience of artificial neural networks through the lens of differential geometry. Our geometric language provides natural algorithms that identify local vulnerabilities in trained networks as well as recovery algorithms that dynamically adjust networks to compensate for damage. We reveal striking vulnerabilities in commonly used image analysis networks, like MLP's and CNN's trained on MNIST and CIFAR10 respectively. We also uncover high-performance recovery paths that enable the same networks to dynamically re-adjust their parameters to compensate for damage. Broadly, our work provides procedures that endow artificial systems with resilience and rapid-recovery routines to enhance their integration with IoT devices as well as enable their deployment for critical applications.
Erase and Restore: Simple, Accurate and Resilient Detection of $L_2$ Adversarial Examples
Jan 01, 2020
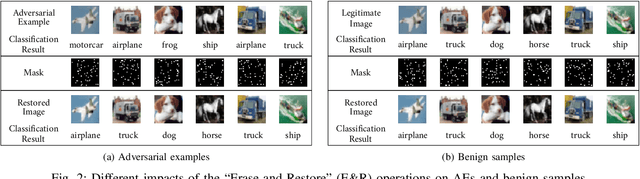
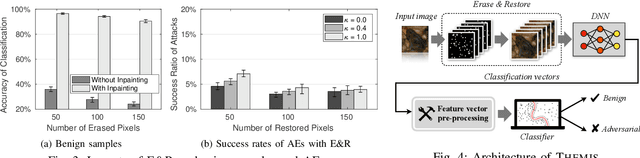
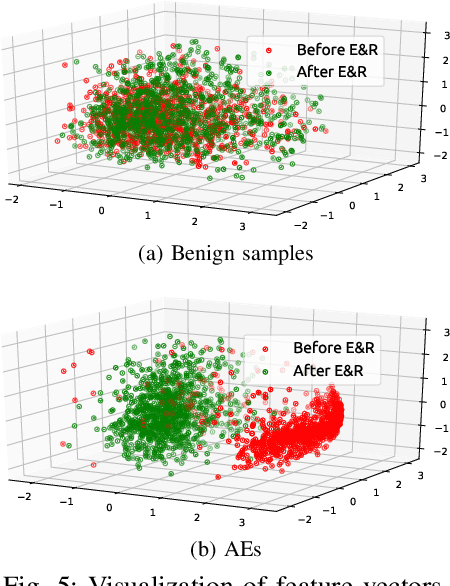
By adding carefully crafted perturbations to input images, adversarial examples (AEs) can be generated to mislead neural-network-based image classifiers. $L_2$ adversarial perturbations by Carlini and Wagner (CW) are regarded as among the most effective attacks. While many countermeasures against AEs have been proposed, detection of adaptive CW $L_2$ AEs has been very inaccurate. Our observation is that those deliberately altered pixels in an $L_2$ AE, altogether, exert their malicious influence. By randomly erasing some pixels from an $L_2$ AE and then restoring it with an inpainting technique, such an AE, before and after the steps, tends to have different classification results, while a benign sample does not show this symptom. Based on this, we propose a novel AE detection technique, Erase and Restore (E\&R), that exploits the limitation of $L_2$ attacks. On two popular image datasets, CIFAR-10 and ImageNet, our experiments show that the proposed technique is able to detect over 98% of the AEs generated by CW and other $L_2$ algorithms and has a very low false positive rate on benign images. Moreover, our approach demonstrate strong resilience to adaptive attacks. While adding noises and inpainting each have been well studied, by combining them together, we deliver a simple, accurate and resilient detection technique against adaptive $L_2$ AEs.