 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Semantic Attribute Discovery and Control in Generative Models
Feb 25, 2020

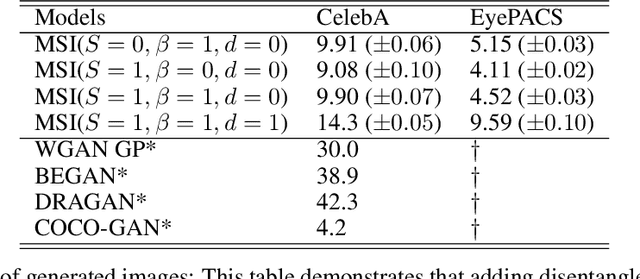
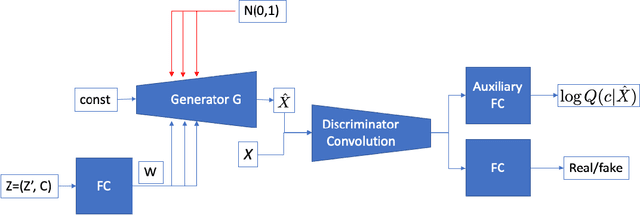

This work focuses on the ability to control via latent space factors semantic image attributes in generative models, and the faculty to discover mappings from factors to attributes in an unsupervised fashion. The discovery of controllable semantic attributes is of special importance, as it would facilitate higher level tasks such as unsupervised representation learning to improve anomaly detection, or the controlled generation of novel data for domain shift and imbalanced datasets. The ability to control semantic attributes is related to the disentanglement of latent factors, which dictates that latent factors be "uncorrelated" in their effects. Unfortunately, despite past progress, the connection between control and disentanglement remains, at best, confused and entangled, requiring clarifications we hope to provide in this work. To this end, we study the design of algorithms for image generation that allow unsupervised discovery and control of semantic attributes.We make several contributions: a) We bring order to the concepts of control and disentanglement, by providing an analytical derivation that connects mutual information maximization, which promotes attribute control, to total correlation minimization, which relates to disentanglement. b) We propose hybrid generative model architectures that use mutual information maximization with multi-scale style transfer. c) We introduce a novel metric to characterize the performance of semantic attributes control. We report experiments that appear to demonstrate, quantitatively and qualitatively, the ability of the proposed model to perform satisfactory control while still preserving competitive visual quality. We compare to other state of the art methods (e.g., Frechet inception distance (FID)= 9.90 on CelebA and 4.52 on EyePACS).
DiVA: Diverse Visual Feature Aggregation for Deep Metric Learning
Apr 29, 2020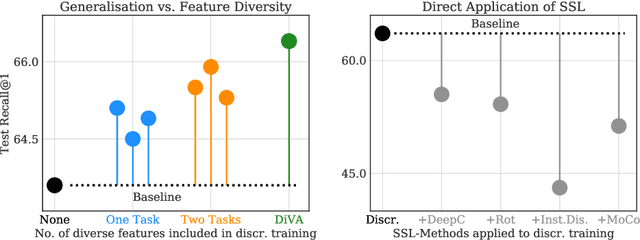
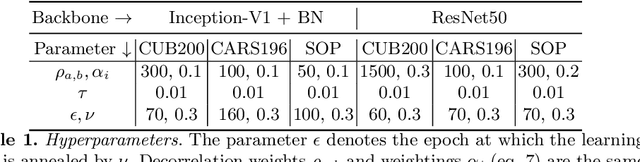
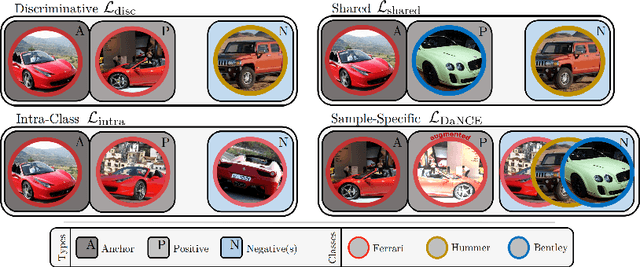
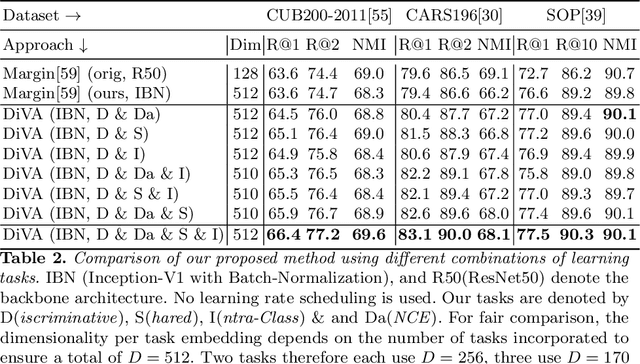
Visual Similarity plays an important role in many computer vision applications. Deep metric learning (DML) is a powerful framework for learning such similarities which not only generalize from training data to identically distributed test distributions, but in particular also translate to unknown test classes. However, its prevailing learning paradigm is class-discriminative supervised training, which typically results in representations specialized in separating training classes. For effective generalization, however, such an image representation needs to capture a diverse range of data characteristics. To this end, we propose and study multiple complementary learning tasks, targeting conceptually different data relationships by only resorting to the available training samples and labels of a standard DML setting. Through simultaneous optimization of our tasks we learn a single model to aggregate their training signals, resulting in strong generalization and state-of-the-art performance on multiple established DML benchmark datasets.
A Novel Visual Fault Detection and Classification System for Semiconductor Manufacturing Using Stacked Hybrid Convolutional Neural Networks
Dec 31, 2019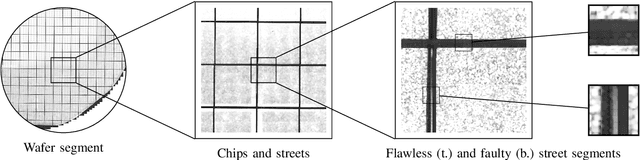
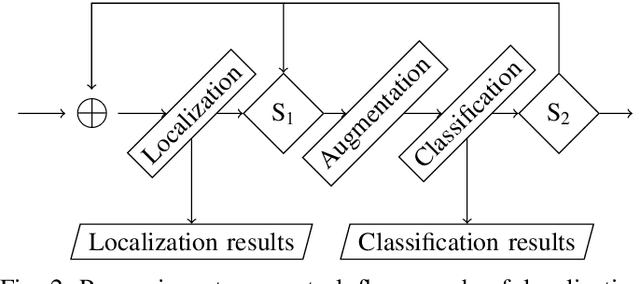
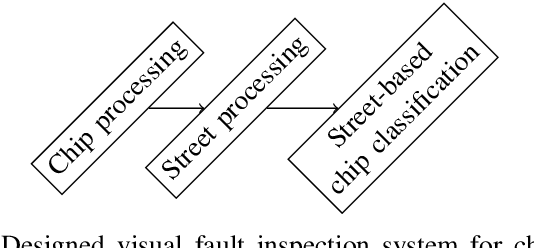
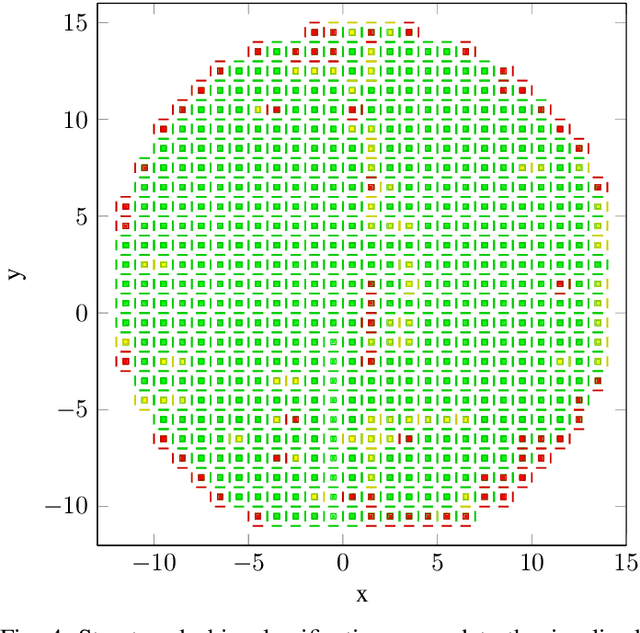
Automated visual inspection in the semiconductor industry aims to detect and classify manufacturing defects utilizing modern image processing techniques. While an earliest possible detection of defect patterns allows quality control and automation of manufacturing chains, manufacturers benefit from an increased yield and reduced manufacturing costs. Since classical image processing systems are limited in their ability to detect novel defect patterns, and machine learning approaches often involve a tremendous amount of computational effort, this contribution introduces a novel deep neural network-based hybrid approach. Unlike classical deep neural networks, a multi-stage system allows the detection and classification of the finest structures in pixel size within high-resolution imagery. Consisting of stacked hybrid convolutional neural networks (SH-CNN) and inspired by current approaches of visual attention, the realized system draws the focus over the level of detail from its structures to more task-relevant areas of interest. The results of our test environment show that the SH-CNN outperforms current approaches of learning-based automated visual inspection, whereas a distinction depending on the level of detail enables the elimination of defect patterns in earlier stages of the manufacturing process.
Deep Exposure Fusion with Deghosting via Homography Estimation and Attention Learning
Apr 20, 2020
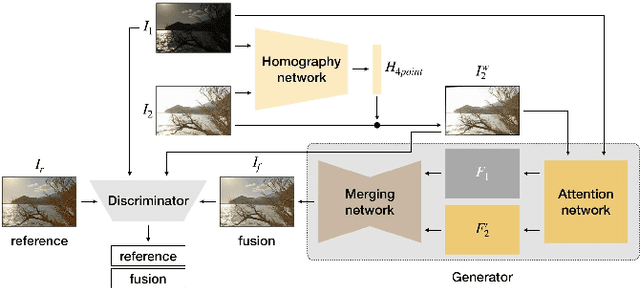
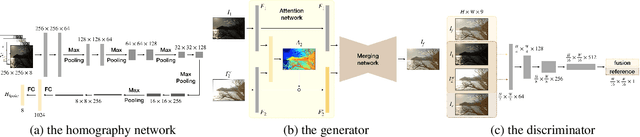

Modern cameras have limited dynamic ranges and often produce images with saturated or dark regions using a single exposure. Although the problem could be addressed by taking multiple images with different exposures, exposure fusion methods need to deal with ghosting artifacts and detail loss caused by camera motion or moving objects. This paper proposes a deep network for exposure fusion. For reducing the potential ghosting problem, our network only takes two images, an underexposed image and an overexposed one. Our network integrates together homography estimation for compensating camera motion, attention mechanism for correcting remaining misalignment and moving pixels, and adversarial learning for alleviating other remaining artifacts. Experiments on real-world photos taken using handheld mobile phones show that the proposed method can generate high-quality images with faithful detail and vivid color rendition in both dark and bright areas.
A New Distance Measure for Non-Identical Data with Application to Image Classification
Oct 31, 2016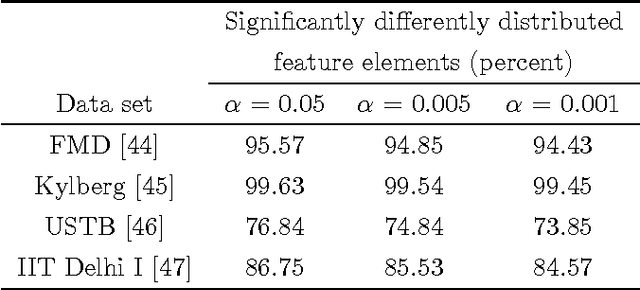
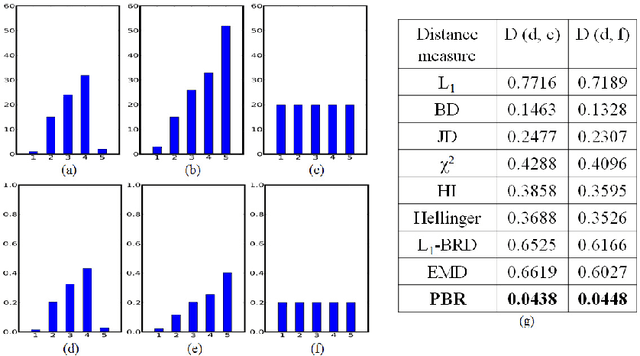
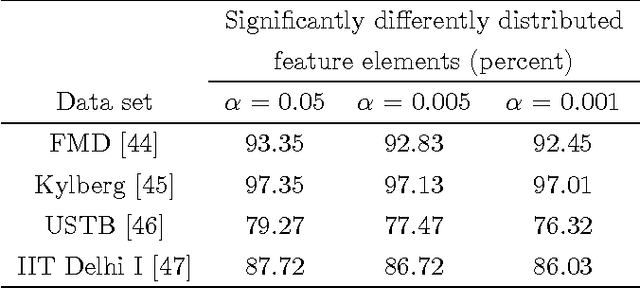
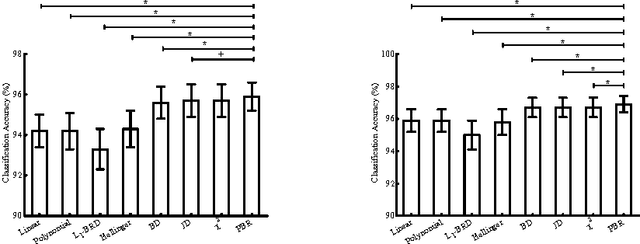
Distance measures are part and parcel of many computer vision algorithms. The underlying assumption in all existing distance measures is that feature elements are independent and identically distributed. However, in real-world settings, data generally originate from heterogeneous sources even if they do possess a common data-generating mechanism. Since these sources are not identically distributed by necessity, the assumption of identical distribution is inappropriate. Here, we use statistical analysis to show that feature elements of local image descriptors are indeed non-identically distributed. To test the effect of omitting the unified distribution assumption, we created a new distance measure called the Poisson-Binomial Radius (PBR). PBR is a bin-to-bin distance which accounts for the dispersion of bin-to-bin information. PBR's performance was evaluated on twelve benchmark data sets covering six different classification and recognition applications: texture, material, leaf, scene, ear biometrics and category-level image classification. Results from these experiments demonstrate that PBR outperforms state-of-the-art distance measures for most of the data sets and achieves comparable performance on the rest, suggesting that accounting for different distributions in distance measures can improve performance in classification and recognition tasks.
3D geometric moment invariants from the point of view of the classical invariant theory
May 23, 2020The aim of this paper is to clear up the problem of the connection between the 3D geometric moments invariants and the invariant theory, considering a problem of describing of the 3D geometric moments invariants as a problem of the classical invariant theory. Using the remarkable fact that the groups $SO(3)$ and $SL(2)$ are locally isomorphic, we reduced the problem of deriving 3D geometric moments invariants to the well-known problem of the classical invariant theory. We give a precise statement of the 3D geometric invariant moments computation, introducing the notions of the algebras of simultaneous 3D geometric moment invariants, and prove that they are isomorphic to the algebras of joint $SL(2)$-invariants of several binary forms. To simplify the calculating of the invariants we proceed from an action of Lie group $SO(3)$ to an action of its Lie algebra $\mathfrak{sl}_2$. The author hopes that the results will be useful to the researchers in the fields of image analysis and pattern recognition.
Grasping Field: Learning Implicit Representations for Human Grasps
Aug 10, 2020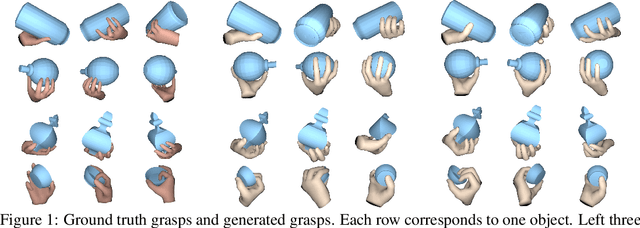
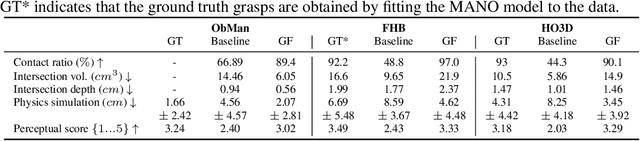
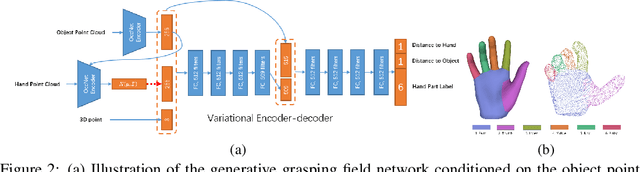
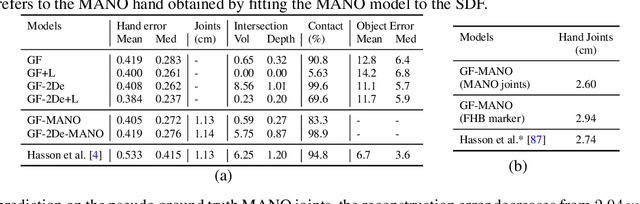
In recent years, substantial progress has been made on robotic grasping of household objects. Yet, human grasps are still difficult to synthesize realistically. There are several key reasons: (1) the human hand has many degrees of freedom (more than robotic manipulators); (2) the synthesized hand should conform naturally to the object surface; and (3) it must interact with the object in a semantically and physical plausible manner. To make progress in this direction, we draw inspiration from the recent progress on learning-based implicit representations for 3D object reconstruction. Specifically, we propose an expressive representation for human grasp modelling that is efficient and easy to integrate with deep neural networks. Our insight is that every point in a three-dimensional space can be characterized by the signed distances to the surface of the hand and the object, respectively. Consequently, the hand, the object, and the contact area can be represented by implicit surfaces in a common space, in which the proximity between the hand and the object can be modelled explicitly. We name this 3D to 2D mapping as Grasping Field, parameterize it with a deep neural network, and learn it from data. We demonstrate that the proposed grasping field is an effective and expressive representation for human grasp generation. Specifically, our generative model is able to synthesize high-quality human grasps, given only on a 3D object point cloud. The extensive experiments demonstrate that our generative model compares favorably with a strong baseline. Furthermore, based on the grasping field representation, we propose a deep network for the challenging task of 3D hand and object reconstruction from a single RGB image. Our method improves the physical plausibility of the 3D hand-object reconstruction task over baselines.
Paying more attention to snapshots of Iterative Pruning: Improving Model Compression via Ensemble Distillation
Jun 20, 2020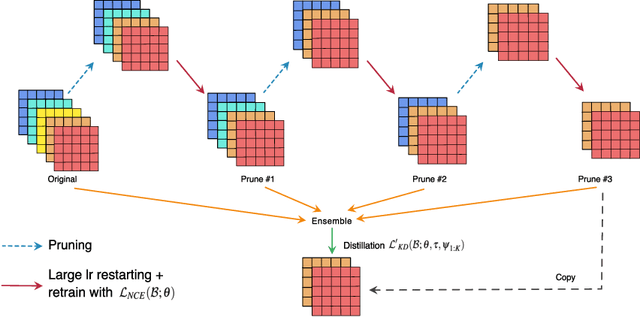
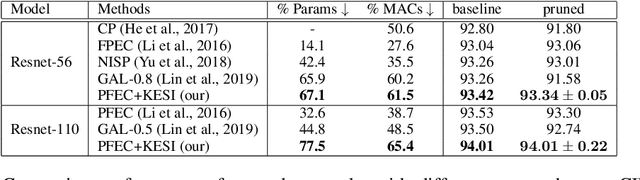
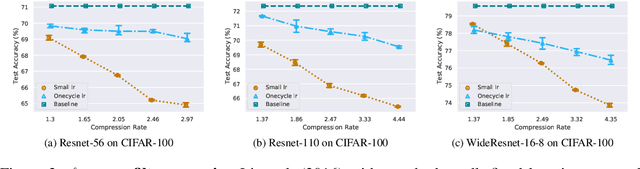
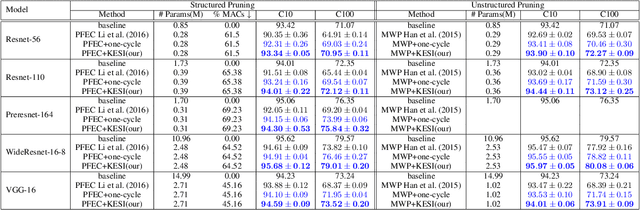
Network pruning is one of the most dominant methods for reducing the heavy inference cost of deep neural networks. Existing methods often iteratively prune networks to attain high compression ratio without incurring significant loss in performance. However, we argue that conventional methods for retraining pruned networks (i.e., using small, fixed learning rate) are inadequate as they completely ignore the benefits from snapshots of iterative pruning. In this work, we show that strong ensembles can be constructed from snapshots of iterative pruning, which achieve competitive performance and vary in network structure. Furthermore, we present simple, general and effective pipeline that generates strong ensembles of networks during pruning with large learning rate restarting, and utilizes knowledge distillation with those ensembles to improve the predictive power of compact models. In standard image classification benchmarks such as CIFAR and Tiny-Imagenet, we advance state-of-the-art pruning ratio of structured pruning by integrating simple l1-norm filters pruning into our pipeline. Specifically, we reduce 75-80% of total parameters and 65-70% MACs of numerous variants of ResNet architectures while having comparable or better performance than that of original networks. Code associate with this paper is made publicly available at https://github.com/lehduong/ginp.
Fashion Editing with Multi-scale Attention Normalization
Jun 03, 2019
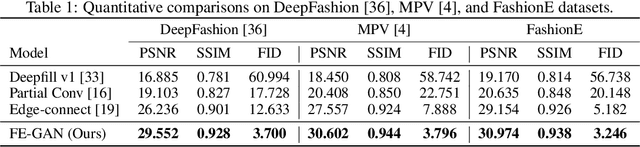
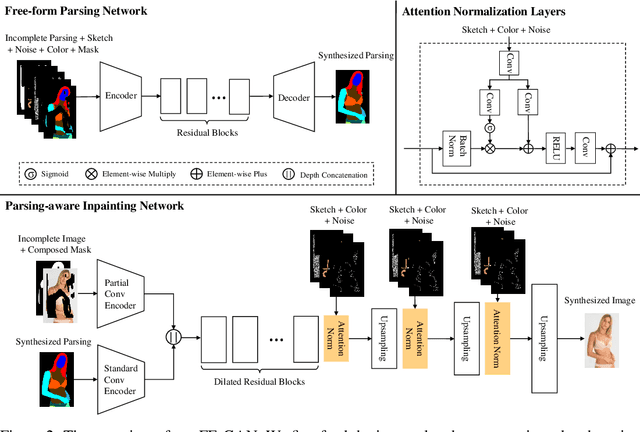

Interactive fashion image manipulation, which enables users to edit images with sketches and color strokes, is an interesting research problem with great application value. Existing works often treat it as a general inpainting task and do not fully leverage the semantic structural information in fashion images. Moreover, they directly utilize conventional convolution and normalization layers to restore the incomplete image, which tends to wash away the sketch and color information. In this paper, we propose a novel Fashion Editing Generative Adversarial Network (FE-GAN), which is capable of manipulating fashion images by free-form sketches and sparse color strokes. FE-GAN consists of two modules: 1) a free-form parsing network that learns to control the human parsing generation by manipulating sketch and color; 2) a parsing-aware inpainting network that renders detailed textures with semantic guidance from the human parsing map. A new attention normalization layer is further applied at multiple scales in the decoder of the inpainting network to enhance the quality of the synthesized image. Extensive experiments on high-resolution fashion image datasets demonstrate that the proposed method significantly outperforms the state-of-the-art methods on image manipulation.
MRI Super-Resolution with Ensemble Learning and Complementary Priors
Jul 06, 2019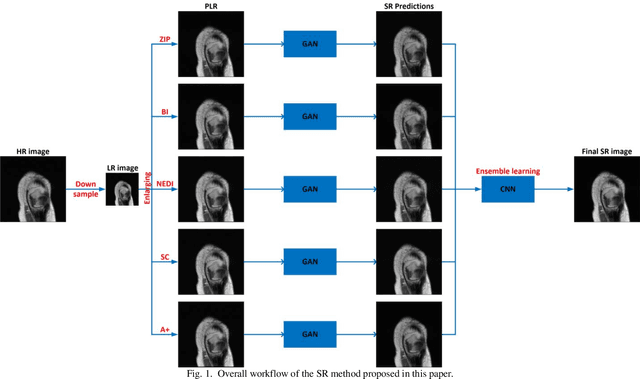
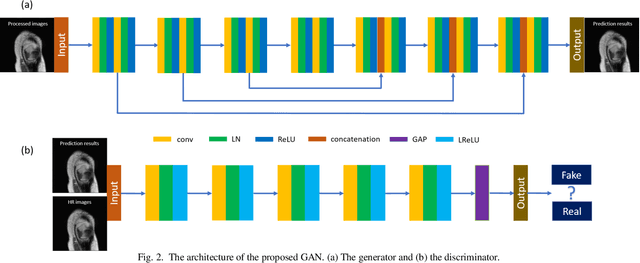
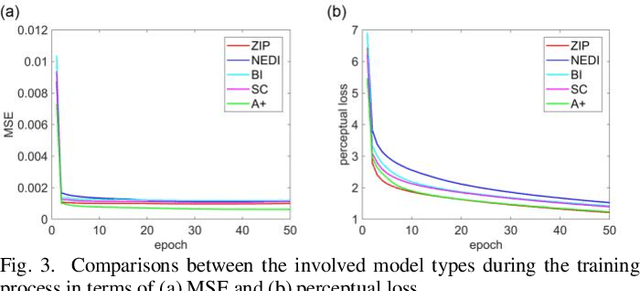

Magnetic resonance imaging (MRI) is a widely used medical imaging modality. However, due to the limitations in hardware, scan time, and throughput, it is often clinically challenging to obtain high-quality MR images. The super-resolution approach is potentially promising to improve MR image quality without any hardware upgrade. In this paper, we propose an ensemble learning and deep learning framework for MR image super-resolution. In our study, we first enlarged low resolution images using 5 commonly used super-resolution algorithms and obtained differentially enlarged image datasets with complementary priors. Then, a generative adversarial network (GAN) is trained with each dataset to generate super-resolution MR images. Finally, a convolutional neural network is used for ensemble learning that synergizes the outputs of GANs into the final MR super-resolution images. According to our results, the ensemble learning results outcome any one of GAN outputs. Compared with some state-of-the-art deep learning-based super-resolution methods, our approach is advantageous in suppressing artifacts and keeping more image details.