 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Accelerating cardiac cine MRI beyond compressed sensing using DL-ESPIRiT
Nov 13, 2019
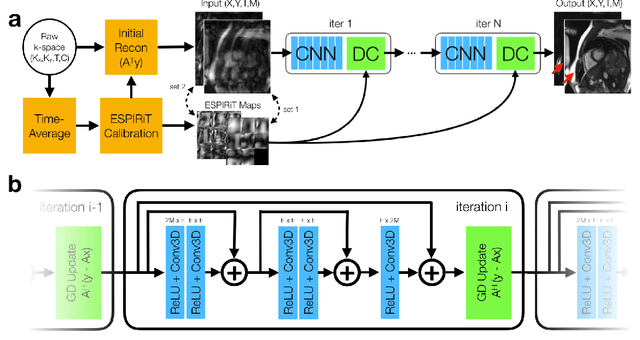
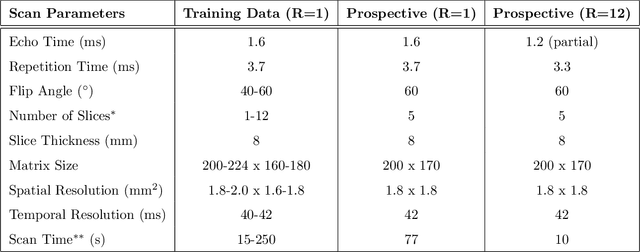
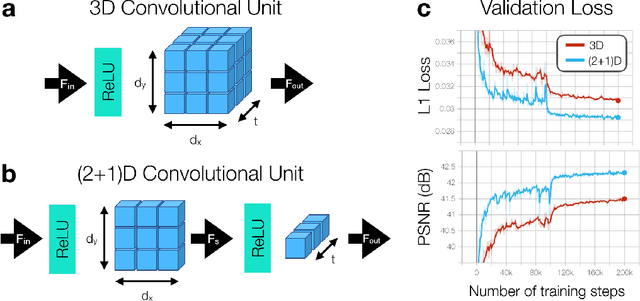
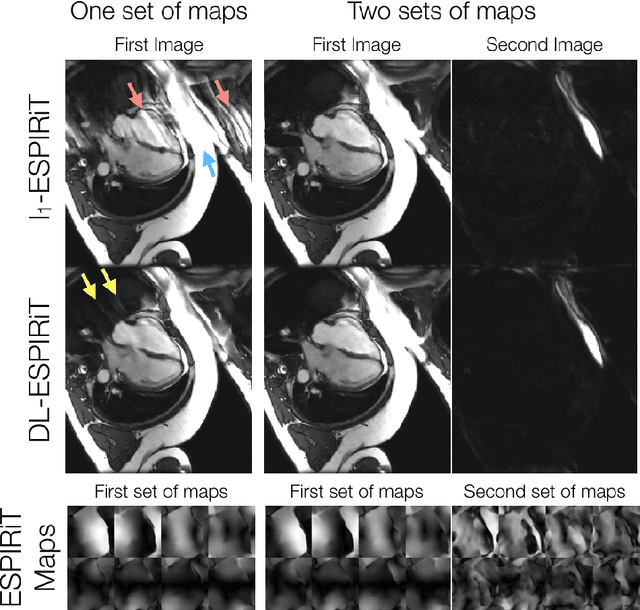
A novel neural network architecture, known as DL-ESPIRiT, is proposed to reconstruct rapidly acquired cardiac MRI data without field-of-view limitations which are present in previously proposed deep learning-based reconstruction frameworks. Additionally, a novel convolutional neural network based on separable 3D convolutions is integrated into DL-ESPIRiT to more efficiently learn spatiotemporal priors for dynamic image reconstruction. The network is trained on fully-sampled 2D cardiac cine datasets collected from eleven healthy volunteers with IRB approval. DL-ESPIRiT is compared against a state-of-the-art parallel imaging and compressed sensing method known as $l_1$-ESPIRiT. The reconstruction accuracy of both methods is evaluated on retrospectively undersampled datasets (R=12) with respect to standard image quality metrics as well as automatic deep learning-based segmentations of left ventricular volumes. Feasibility of this approach is demonstrated in reconstructions of prospectively undersampled data which were acquired in a single heartbeat per slice.
Polarized Reflection Removal with Perfect Alignment in the Wild
Mar 28, 2020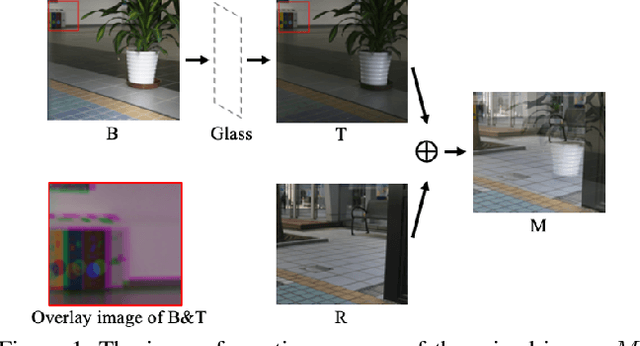

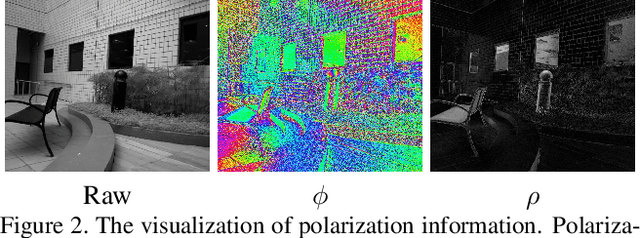
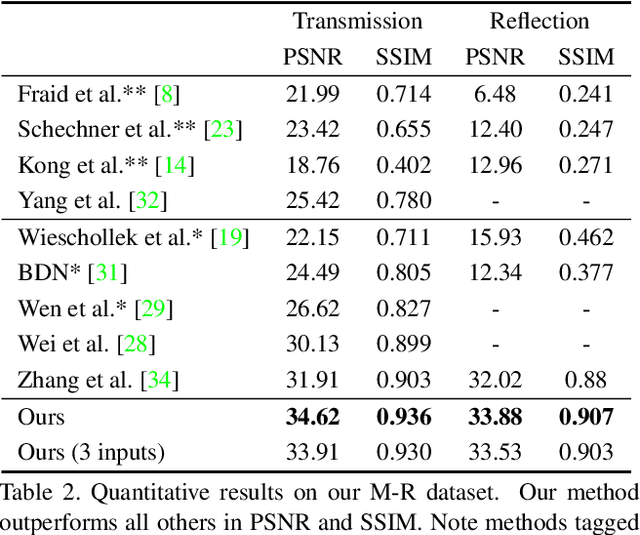
We present a novel formulation to removing reflection from polarized images in the wild. We first identify the misalignment issues of existing reflection removal datasets where the collected reflection-free images are not perfectly aligned with input mixed images due to glass refraction. Then we build a new dataset with more than 100 types of glass in which obtained transmission images are perfectly aligned with input mixed images. Second, capitalizing on the special relationship between reflection and polarized light, we propose a polarized reflection removal model with a two-stage architecture. In addition, we design a novel perceptual NCC loss that can improve the performance of reflection removal and general image decomposition tasks. We conduct extensive experiments, and results suggest that our model outperforms state-of-the-art methods on reflection removal.
Are Accelerometers for Activity Recognition a Dead-end?
Jan 30, 2020

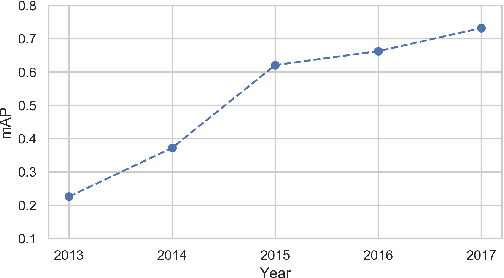
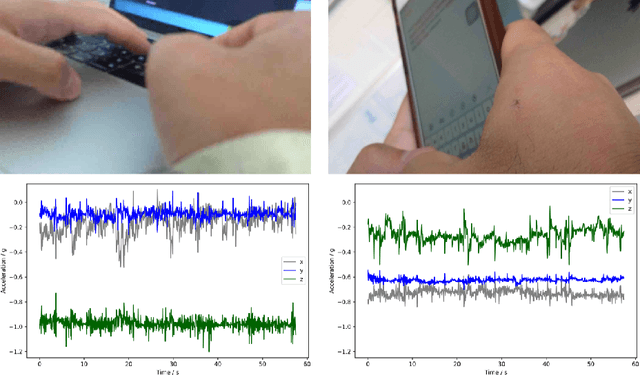
Accelerometer-based (and by extension other inertial sensors) research for Human Activity Recognition (HAR) is a dead-end. This sensor does not offer enough information for us to progress in the core domain of HAR - to recognize everyday activities from sensor data. Despite continued and prolonged efforts in improving feature engineering and machine learning models, the activities that we can recognize reliably have only expanded slightly and many of the same flaws of early models are still present today. Instead of relying on acceleration data, we should instead consider modalities with much richer information - a logical choice are images. With the rapid advance in image sensing hardware and modelling techniques, we believe that a widespread adoption of image sensors will open many opportunities for accurate and robust inference across a wide spectrum of human activities. In this paper, we make the case for imagers in place of accelerometers as the default sensor for human activity recognition. Our review of past works has led to the observation that progress in HAR had stalled, caused by our reliance on accelerometers. We further argue for the suitability of images for activity recognition by illustrating their richness of information and the marked progress in computer vision. Through a feasibility analysis, we find that deploying imagers and CNNs on device poses no substantial burden on modern mobile hardware. Overall, our work highlights the need to move away from accelerometers and calls for further exploration of using imagers for activity recognition.
Cost Volume Pyramid Based Depth Inference for Multi-View Stereo
Dec 18, 2019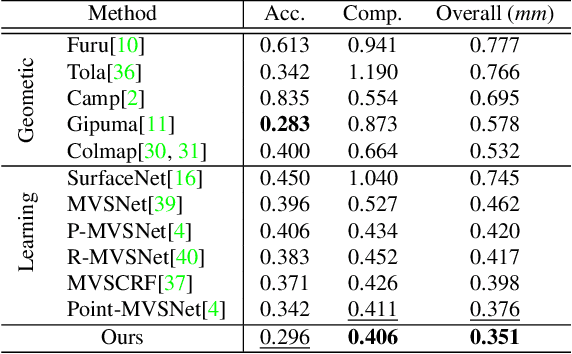
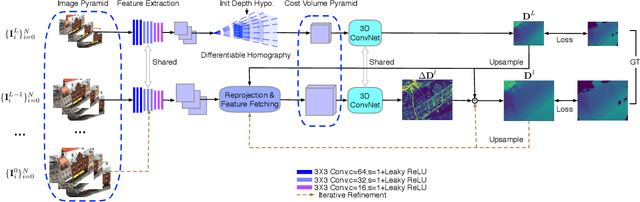
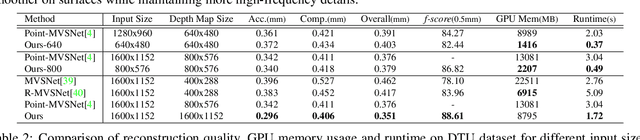
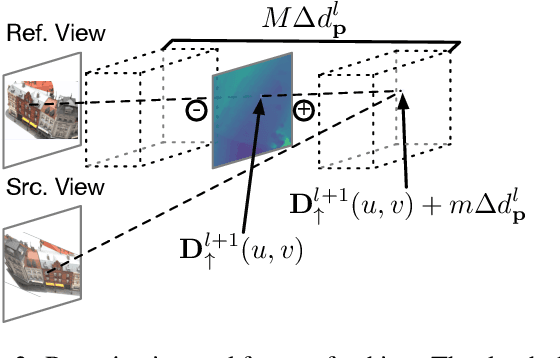
We propose a cost volume based neural network for depth inference from multi-view images. We demonstrate that building a cost volume pyramid in a coarse-to-fine manner instead of constructing a cost volume at a fixed resolution leads to a compact, lightweight network and allows us inferring high resolution depth maps to achieve better reconstruction results. To this end, a cost volume based on uniform sampling of fronto-parallel planes across entire depth range is first built at the coarsest resolution of an image. Given current depth estimate, new cost volumes are constructed iteratively on the pixelwise depth residual to perform depth map refinement. While sharing similar insight with Point-MVSNet as predicting and refining depth iteratively, we show that working on cost volume pyramid can lead to a more compact, yet efficient network structure compared with the Point-MVSNet on 3D points. We further provide detailed analyses of relation between (residual) depth sampling and image resolution, which serves as a principle for building compact cost volume pyramid. Experimental results on benchmark datasets show that our model can perform 6x faster and has similar performance as state-of-the-art methods.
Learning to Fuse 2D and 3D Image Cues for Monocular Body Pose Estimation
Apr 10, 2017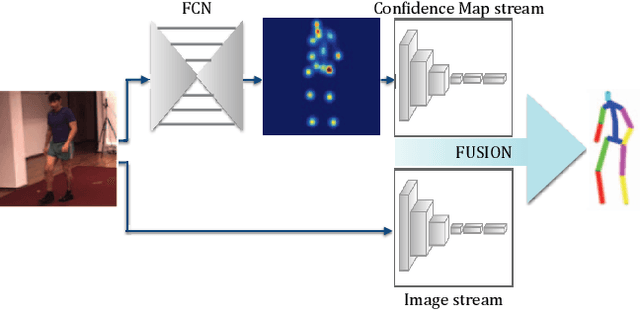
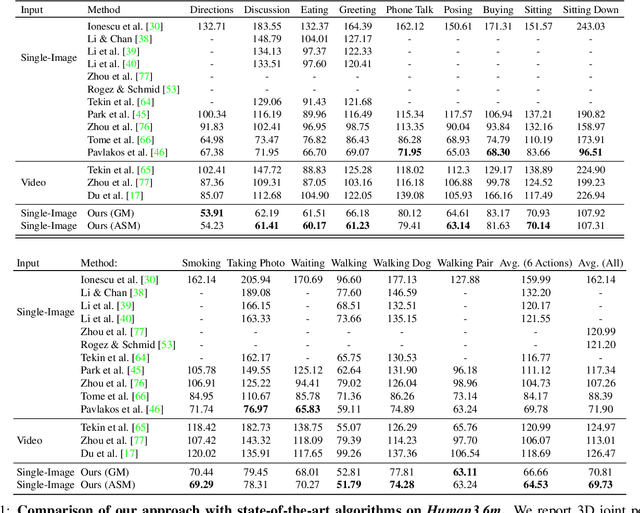
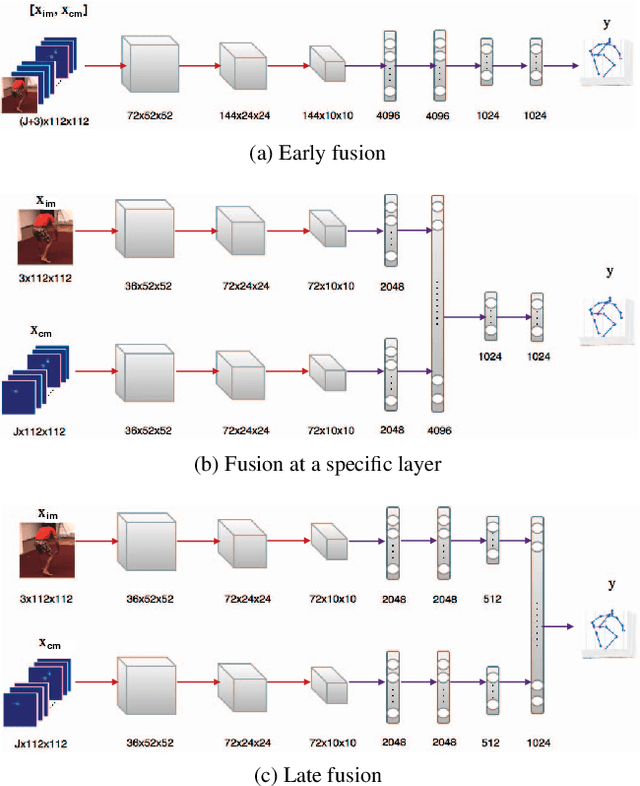

Most recent approaches to monocular 3D human pose estimation rely on Deep Learning. They typically involve regressing from an image to either 3D joint coordinates directly or 2D joint locations from which 3D coordinates are inferred. Both approaches have their strengths and weaknesses and we therefore propose a novel architecture designed to deliver the best of both worlds by performing both simultaneously and fusing the information along the way. At the heart of our framework is a trainable fusion scheme that learns how to fuse the information optimally instead of being hand-designed. This yields significant improvements upon the state-of-the-art on standard 3D human pose estimation benchmarks.
Dynamic Sampling for Deep Metric Learning
Apr 24, 2020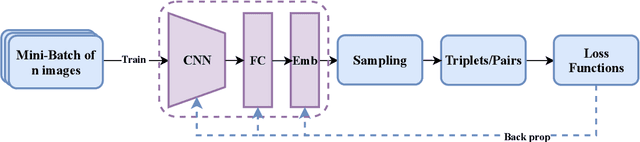
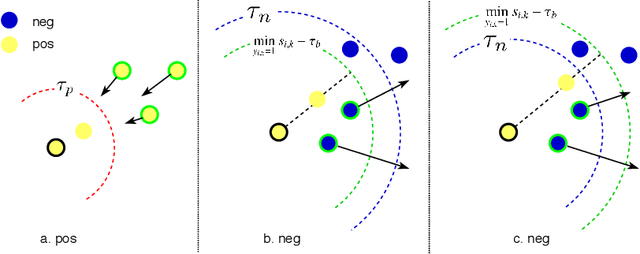
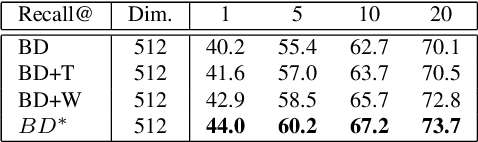
Deep metric learning maps visually similar images onto nearby locations and visually dissimilar images apart from each other in an embedding manifold. The learning process is mainly based on the supplied image negative and positive training pairs. In this paper, a dynamic sampling strategy is proposed to organize the training pairs in an easy-to-hard order to feed into the network. It allows the network to learn general boundaries between categories from the easy training pairs at its early stages and finalize the details of the model mainly relying on the hard training samples in the later. Compared to the existing training sample mining approaches, the hard samples are mined with little harm to the learned general model. This dynamic sampling strategy is formularized as two simple terms that are compatible with various loss functions. Consistent performance boost is observed when it is integrated with several popular loss functions on fashion search, fine-grained classification, and person re-identification tasks.
CorNet: Generic 3D Corners for 6D Pose Estimation of New Objects without Retraining
Aug 29, 2019
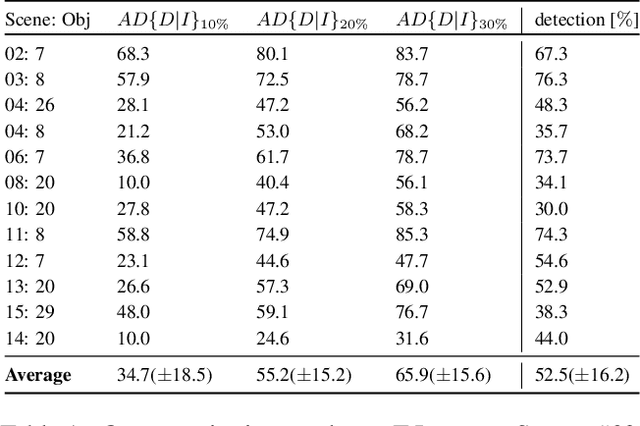
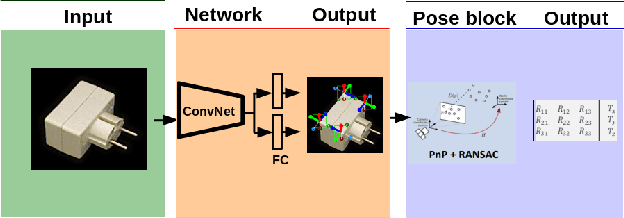
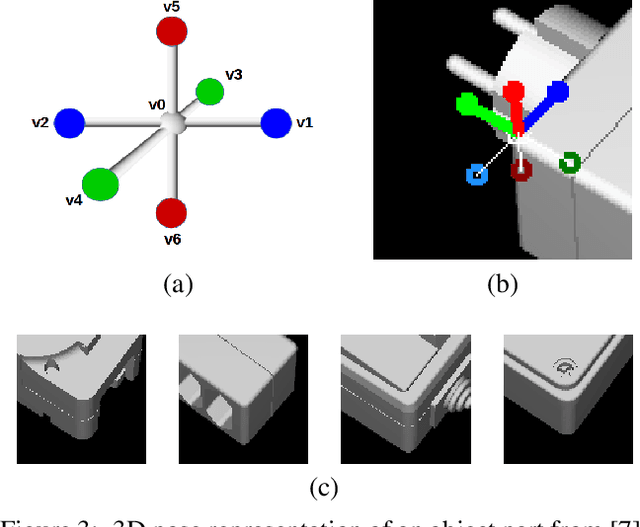
We present a novel approach to the detection and 3D pose estimation of objects in color images. Its main contribution is that it does not require any training phases nor data for new objects, while state-of-the-art methods typically require hours of training time and hundreds of training registered images. Instead, our method relies only on the objects' geometries. Our method focuses on objects with prominent corners, which covers a large number of industrial objects. We first learn to detect object corners of various shapes in images and also to predict their 3D poses, by using training images of a small set of objects. To detect a new object in a given image, we first identify its corners from its CAD model; we also detect the corners visible in the image and predict their 3D poses. We then introduce a RANSAC-like algorithm that robustly and efficiently detects and estimates the object's 3D pose by matching its corners on the CAD model with their detected counterparts in the image. Because we also estimate the 3D poses of the corners in the image, detecting only 1 or 2 corners is sufficient to estimate the pose of the object, which makes the approach robust to occlusions. We finally rely on a final check that exploits the full 3D geometry of the objects, in case multiple objects have the same corner spatial arrangement. The advantages of our approach make it particularly attractive for industrial contexts, and we demonstrate our approach on the challenging T-LESS dataset.
Expanding Sparse Guidance for Stereo Matching
Apr 24, 2020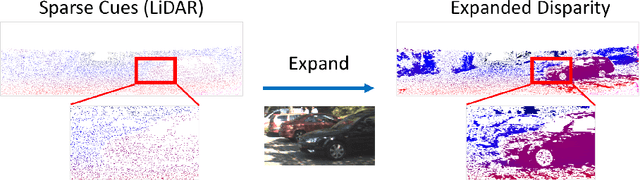
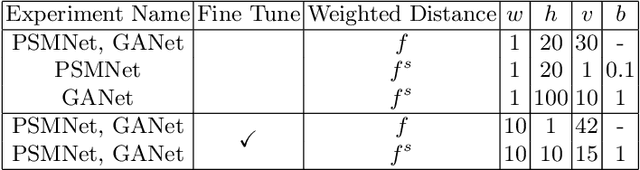
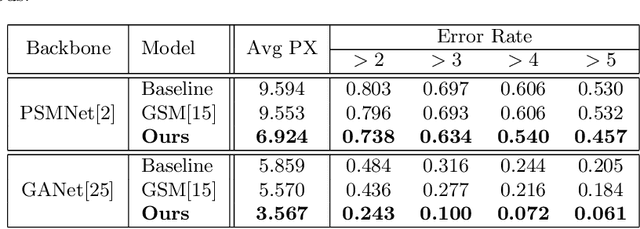

The performance of image based stereo estimation suffers from lighting variations, repetitive patterns and homogeneous appearance. Moreover, to achieve good performance, stereo supervision requires sufficient densely-labeled data, which are hard to obtain. In this work, we leverage small amount of data with very sparse but accurate disparity cues from LiDAR to bridge the gap. We propose a novel sparsity expansion technique to expand the sparse cues concerning RGB images for local feature enhancement. The feature enhancement method can be easily applied to any stereo estimation algorithms with cost volume at the test stage. Extensive experiments on stereo datasets demonstrate the effectiveness and robustness across different backbones on domain adaption and self-supervision scenario. Our sparsity expansion method outperforms previous methods in terms of disparity by more than 2 pixel error on KITTI Stereo 2012 and 3 pixel error on KITTI Stereo 2015. Our approach significantly boosts the existing state-of-the-art stereo algorithms with extremely sparse cues.
Learn to Predict Sets Using Feed-Forward Neural Networks
Jan 30, 2020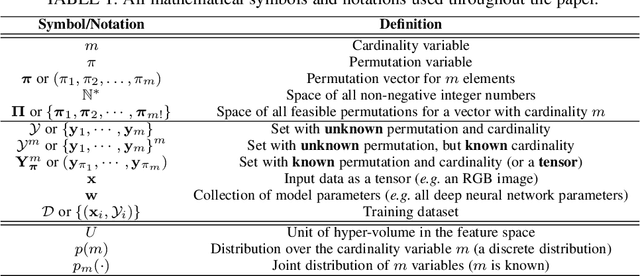
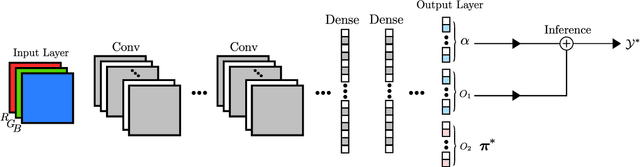
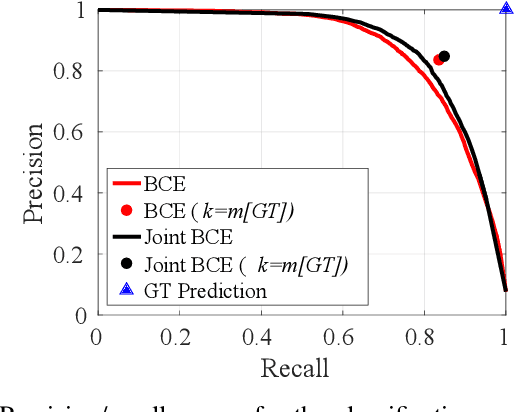

This paper addresses the task of set prediction using deep feed-forward neural networks. A set is a collection of elements which is invariant under permutation and the size of a set is not fixed in advance. Many real-world problems, such as image tagging and object detection, have outputs that are naturally expressed as sets of entities. This creates a challenge for traditional deep neural networks which naturally deal with structured outputs such as vectors, matrices or tensors. We present a novel approach for learning to predict sets with unknown permutation and cardinality using deep neural networks. In our formulation we define a likelihood for a set distribution represented by a) two discrete distributions defining the set cardinally and permutation variables, and b) a joint distribution over set elements with a fixed cardinality. Depending on the problem under consideration, we define different training models for set prediction using deep neural networks. We demonstrate the validity of our set formulations on relevant vision problems such as: 1)multi-label image classification where we achieve state-of-the-art performance on the PASCAL VOC and MS COCO datasets, 2) object detection, for which our formulation outperforms state-of-the-art detectors such as Faster R-CNN and YOLO v3, and 3) a complex CAPTCHA test, where we observe that, surprisingly, our set-based network acquired the ability of mimicking arithmetics without any rules being coded.
Virtual organelle self-coding for fluorescence imaging via adversarial learning
Sep 10, 2019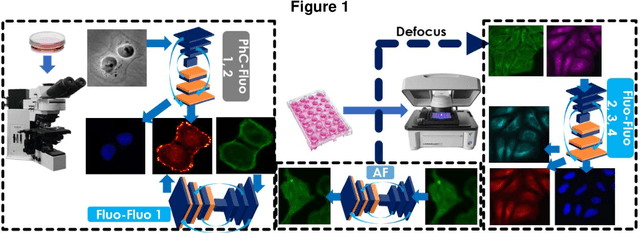
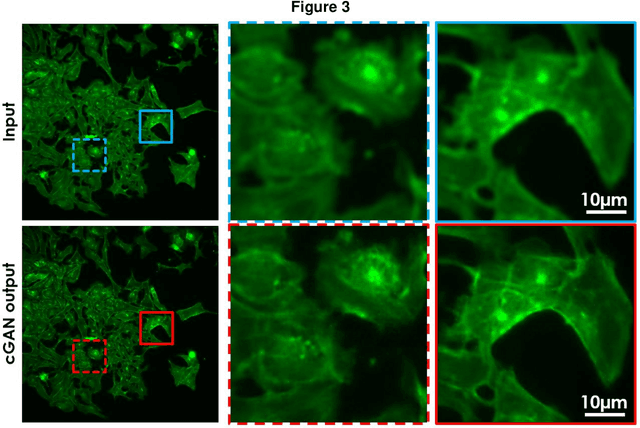
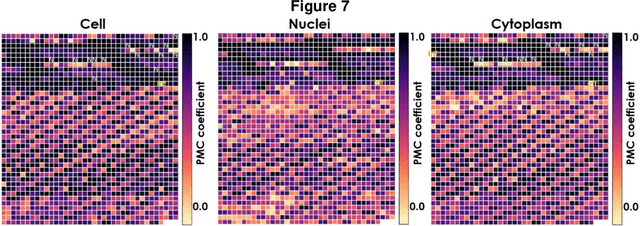
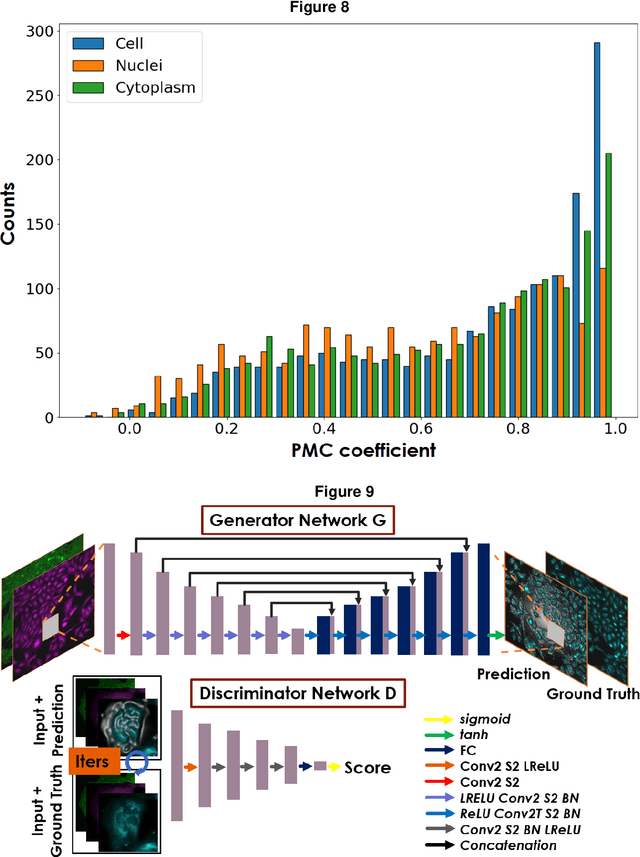
Fluorescence microscopy plays a vital role in understanding the subcellular structures of living cells. However, it requires considerable effort in sample preparation related to chemical fixation, staining, cost, and time. To reduce those factors, we present a virtual fluorescence staining method based on deep neural networks (VirFluoNet) to transform fluorescence images of molecular labels into other molecular fluorescence labels in the same field-of-view. To achieve this goal, we develop and train a conditional generative adversarial network (cGAN) to perform digital fluorescence imaging demonstrated on human osteosarcoma U2OS cell fluorescence images captured under Cell Painting staining protocol. A detailed comparative analysis is also conducted on the performance of the cGAN network between predicting fluorescence channels based on phase contrast or based on another fluorescence channel using human breast cancer MDA-MB-231 cell line as a test case. In addition, we implement a deep learning model to perform autofocusing on another human U2OS fluorescence dataset as a preprocessing step to defocus an out-focus channel in U2OS dataset. A quantitative index of image prediction error is introduced based on signal pixel-wise spatial and intensity differences with ground truth to evaluate the performance of prediction to high-complex and throughput fluorescence. This index provides a rational way to perform image segmentation on error signals and to understand the likelihood of mis-interpreting biology from the predicted image. In total, these findings contribute to the utility of deep learning image regression for fluorescence microscopy datasets of biological cells, balanced against savings of cost, time, and experimental effort. Furthermore, the approach introduced here holds promise for modeling the internal relationships between organelles and biomolecules within living cells.