 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AutoOD: Automated Outlier Detection via Curiosity-guided Search and Self-imitation Learning
Jun 19, 2020
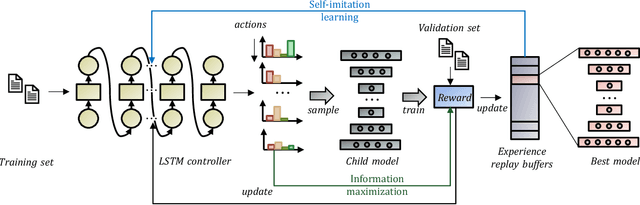
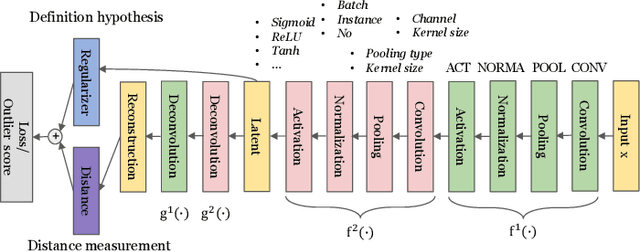
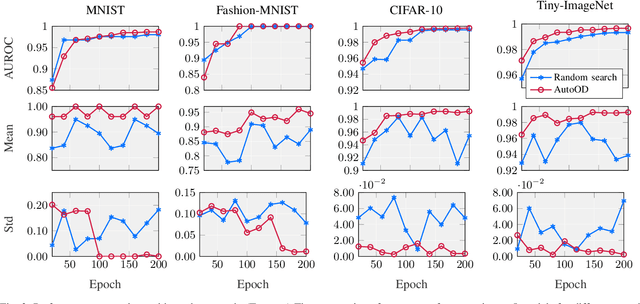
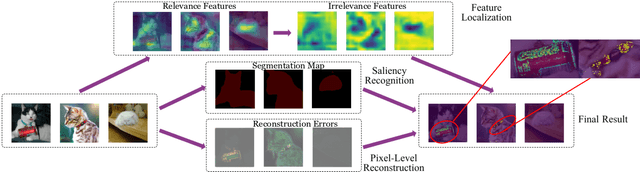
Outlier detection is an important data mining task with numerous practical applications such as intrusion detection, credit card fraud detection, and video surveillance. However, given a specific complicated task with big data, the process of building a powerful deep learning based system for outlier detection still highly relies on human expertise and laboring trials. Although Neural Architecture Search (NAS) has shown its promise in discovering effective deep architectures in various domains, such as image classification, object detection, and semantic segmentation, contemporary NAS methods are not suitable for outlier detection due to the lack of intrinsic search space, unstable search process, and low sample efficiency. To bridge the gap, in this paper, we propose AutoOD, an automated outlier detection framework, which aims to search for an optimal neural network model within a predefined search space. Specifically, we firstly design a curiosity-guided search strategy to overcome the curse of local optimality. A controller, which acts as a search agent, is encouraged to take actions to maximize the information gain about the controller's internal belief. We further introduce an experience replay mechanism based on self-imitation learning to improve the sample efficiency. Experimental results on various real-world benchmark datasets demonstrate that the deep model identified by AutoOD achieves the best performance, comparing with existing handcrafted models and traditional search methods.
Deformable Registration Using Average Geometric Transformations for Brain MR Images
Jul 23, 2019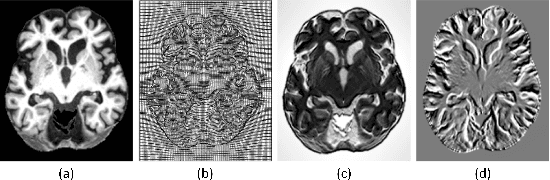

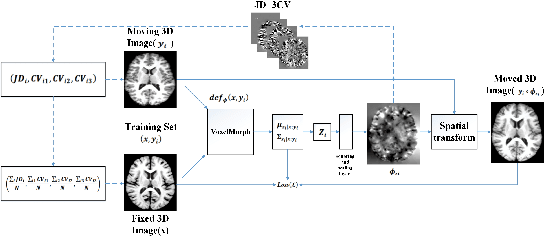
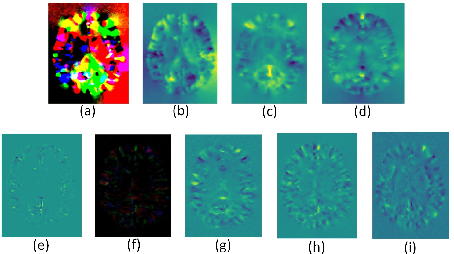
Accurate registration of medical images is vital for doctor's diagnosis and quantitative analysis. In this paper, we propose a new deformable medical image registration method based on average geometric transformations and VoxelMorph CNN architecture. We compute the differential geometric information including Jacobian determinant(JD) and the curl vector(CV) of diffeomorphic registration field and use them as multi-channel of VoxelMorph CNN for second train. In addition, we use the average transformation to construct a standard brain MRI atlas which can be used as fixed image. We verify our method on two datasets including ADNI dataset and MRBrainS18 Challenge dataset, and obtain excellent improvement on MR image registration with average Dice scores and non-negative Jacobian locations compared with MIT's original method. The experimental results show the method can achieve better performance in brain MRI diagnosis.
DeepFocus: a Few-Shot Microscope Slide Auto-Focus using a Sample Invariant CNN-based Sharpness Function
Jan 02, 2020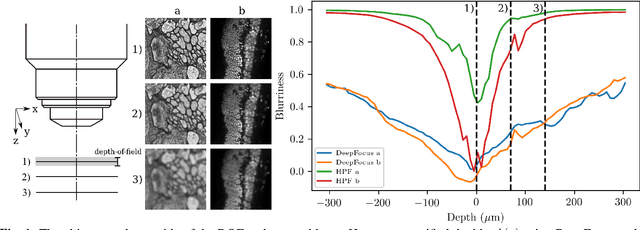
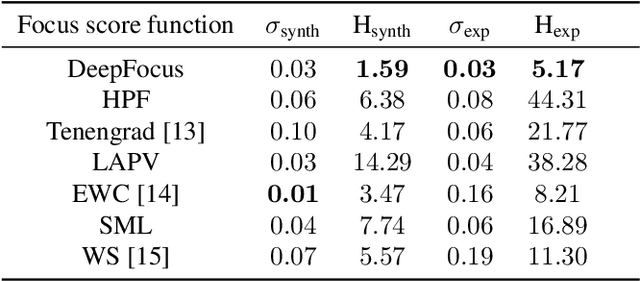
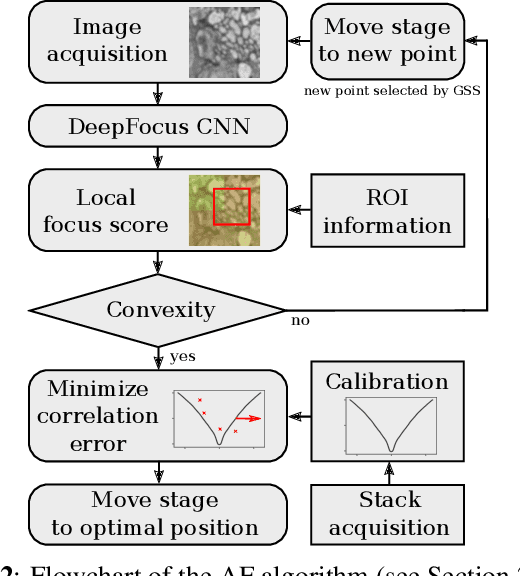
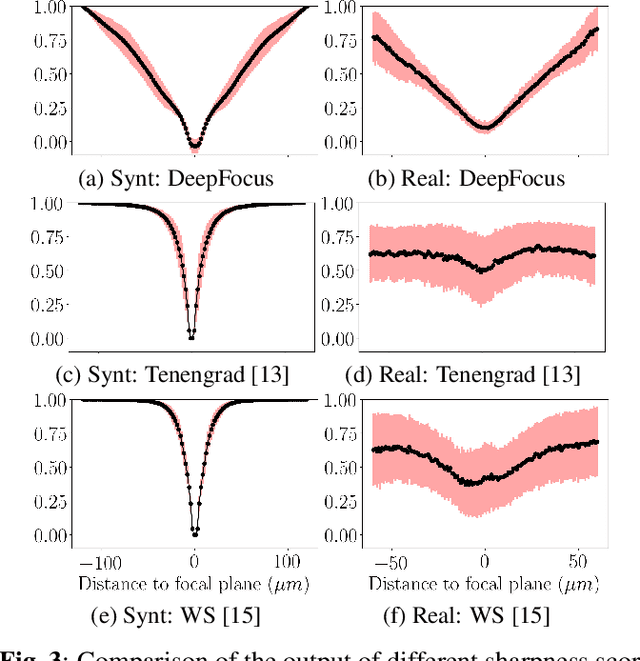
Autofocus (AF) methods are extensively used in biomicroscopy, for example to acquire timelapses, where the imaged objects tend to drift out of focus. AD algorithms determine an optimal distance by which to move the sample back into the focal plane. Current hardware-based methods require modifying the microscope and image-based algorithms either rely on many images to converge to the sharpest position or need training data and models specific to each instrument and imaging configuration. Here we propose DeepFocus, an AF method we implemented as a Micro-Manager plugin, and characterize its Convolutional neural network-based sharpness function, which we observed to be depth co-variant and sample-invariant. Sample invariance allows our AF algorithm to converge to an optimal axial position within as few as three iterations using a model trained once for use with a wide range of optical microscopes and a single instrument-dependent calibration stack acquisition of a flat (but arbitrary) textured object. From experiments carried out both on synthetic and experimental data, we observed an average precision, given 3 measured images, of 0.30 +- 0.16 micrometers with a 10x, NA 0.3 objective. We foresee that this performance and low image number will help limit photodamage during acquisitions with light-sensitive samples.
Detect and Correct Bias in Multi-Site Neuroimaging Datasets
Feb 12, 2020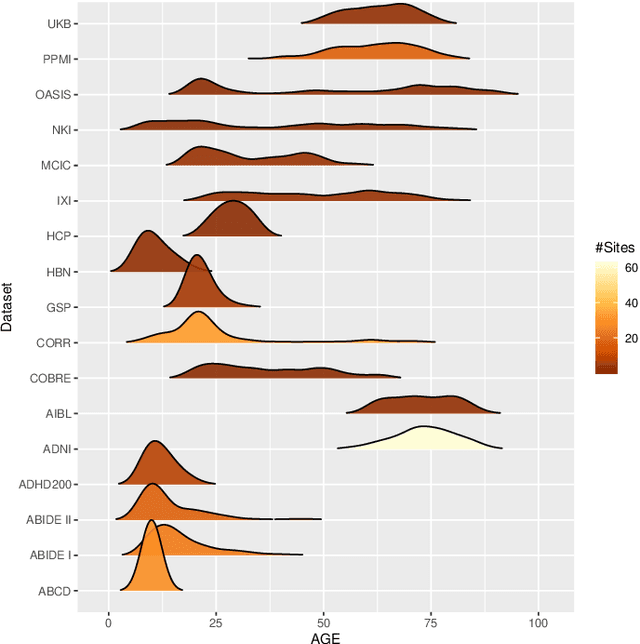
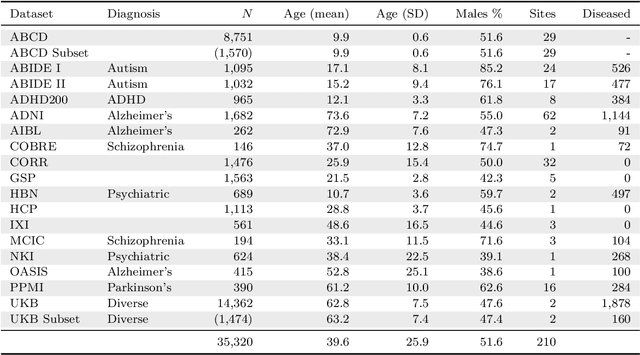
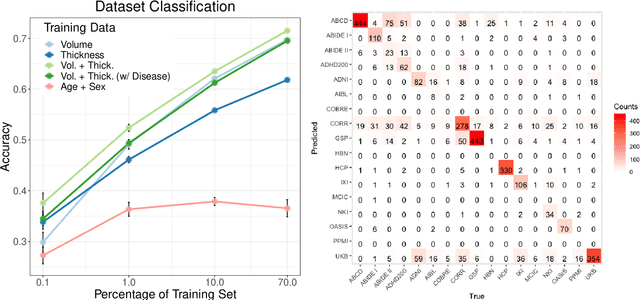
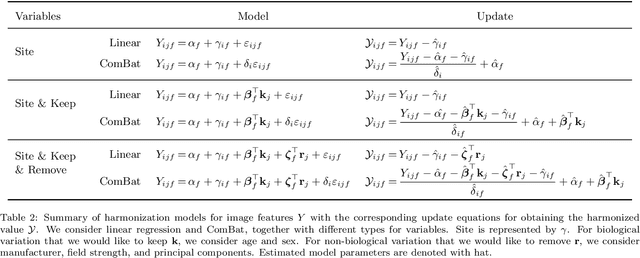
The desire to train complex machine learning algorithms and to increase the statistical power in association studies drives neuroimaging research to use ever-larger datasets. The most obvious way to increase sample size is by pooling scans from independent studies. However, simple pooling is often ill-advised as selection, measurement, and confounding biases may creep in and yield spurious correlations. In this work, we combine 35,320 magnetic resonance images of the brain from 17 studies to examine bias in neuroimaging. In the first experiment, Name That Dataset, we provide empirical evidence for the presence of bias by showing that scans can be correctly assigned to their respective dataset with 71.5% accuracy. Given such evidence, we take a closer look at confounding bias, which is often viewed as the main shortcoming in observational studies. In practice, we neither know all potential confounders nor do we have data on them. Hence, we model confounders as unknown, latent variables. Kolmogorov complexity is then used to decide whether the confounded or the causal model provides the simplest factorization of the graphical model. Finally, we present methods for dataset harmonization and study their ability to remove bias in imaging features. In particular, we propose an extension of the recently introduced ComBat algorithm to control for global variation across image features, inspired by adjusting for population stratification in genetics. Our results demonstrate that harmonization can reduce dataset-specific information in image features. Further, confounding bias can be reduced and even turned into a causal relationship. However, harmonziation also requires caution as it can easily remove relevant subject-specific information.
GIFT: Learning Transformation-Invariant Dense Visual Descriptors via Group CNNs
Nov 14, 2019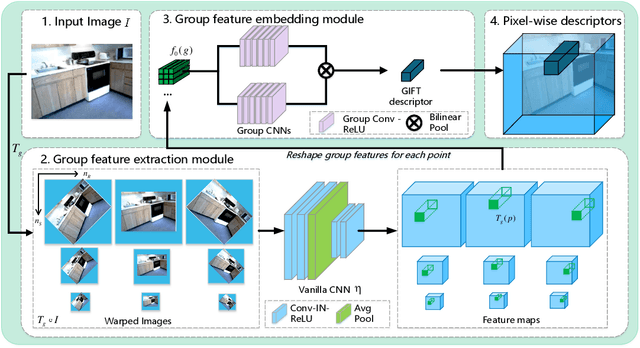
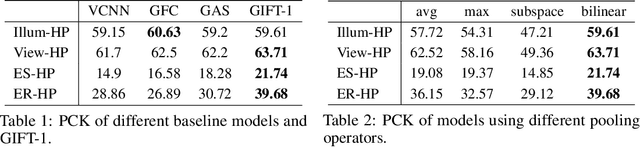
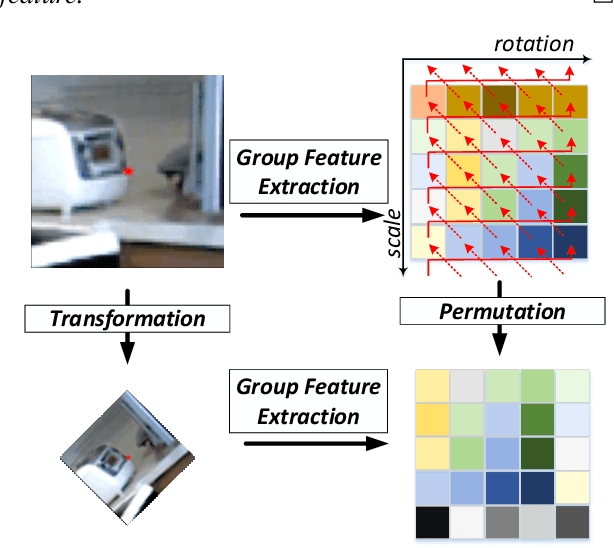

Finding local correspondences between images with different viewpoints requires local descriptors that are robust against geometric transformations. An approach for transformation invariance is to integrate out the transformations by pooling the features extracted from transformed versions of an image. However, the feature pooling may sacrifice the distinctiveness of the resulting descriptors. In this paper, we introduce a novel visual descriptor named Group Invariant Feature Transform (GIFT), which is both discriminative and robust to geometric transformations. The key idea is that the features extracted from the transformed versions of an image can be viewed as a function defined on the group of the transformations. Instead of feature pooling, we use group convolutions to exploit underlying structures of the extracted features on the group, resulting in descriptors that are both discriminative and provably invariant to the group of transformations. Extensive experiments show that GIFT outperforms state-of-the-art methods on several benchmark datasets and practically improves the performance of relative pose estimation.
Learning to Fuse 2D and 3D Image Cues for Monocular Body Pose Estimation
Apr 10, 2017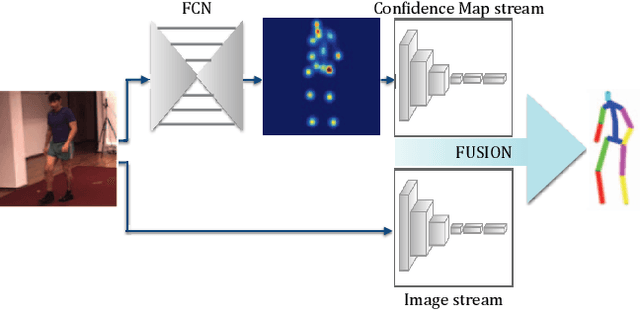
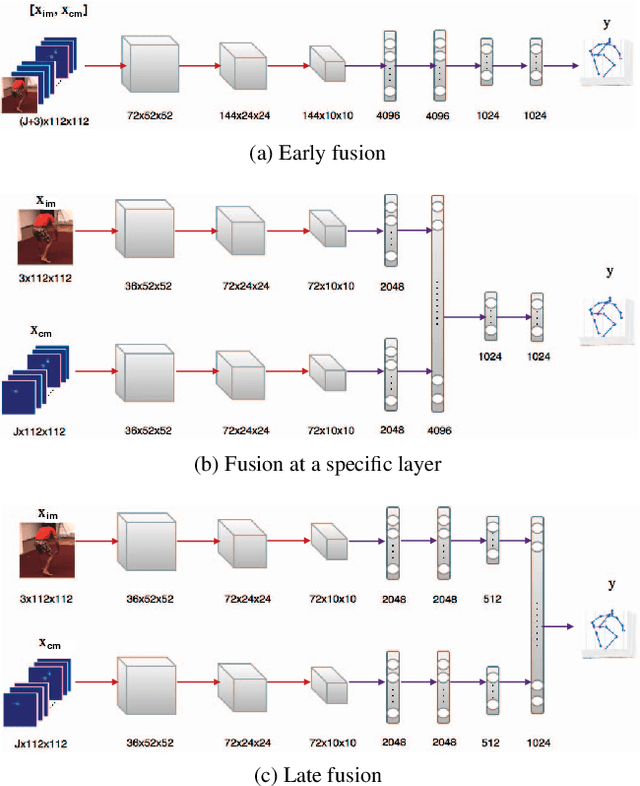

Most recent approaches to monocular 3D human pose estimation rely on Deep Learning. They typically involve regressing from an image to either 3D joint coordinates directly or 2D joint locations from which 3D coordinates are inferred. Both approaches have their strengths and weaknesses and we therefore propose a novel architecture designed to deliver the best of both worlds by performing both simultaneously and fusing the information along the way. At the heart of our framework is a trainable fusion scheme that learns how to fuse the information optimally instead of being hand-designed. This yields significant improvements upon the state-of-the-art on standard 3D human pose estimation benchmarks.
Wasserstein Generative Models for Patch-based Texture Synthesis
Jun 19, 2020
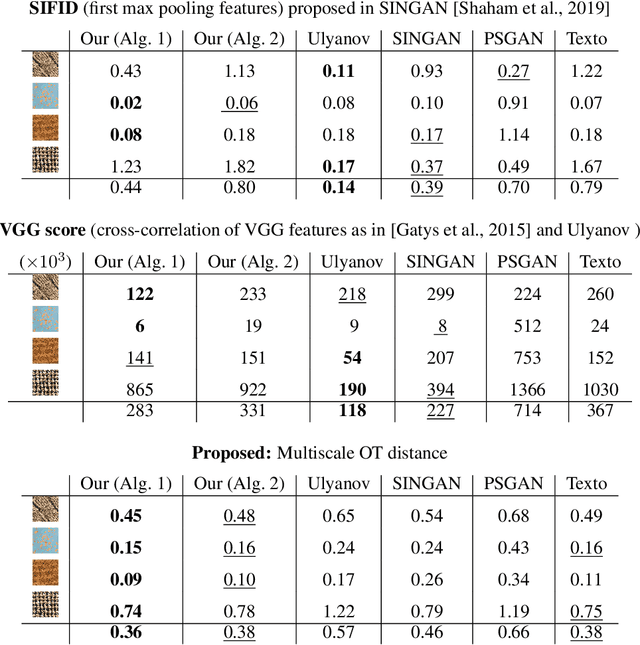

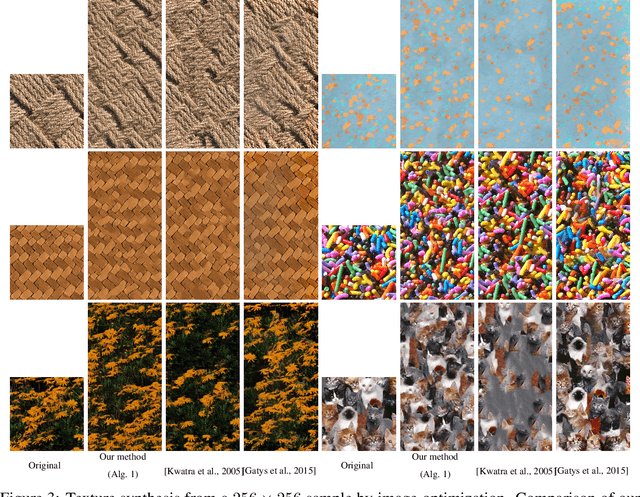
In this paper, we propose a framework to train a generative model for texture image synthesis from a single example. To do so, we exploit the local representation of images via the space of patches, that is, square sub-images of fixed size (e.g. $4\times 4$). Our main contribution is to consider optimal transport to enforce the multiscale patch distribution of generated images, which leads to two different formulations. First, a pixel-based optimization method is proposed, relying on discrete optimal transport. We show that it is related to a well-known texture optimization framework based on iterated patch nearest-neighbor projections, while avoiding some of its shortcomings. Second, in a semi-discrete setting, we exploit the differential properties of Wasserstein distances to learn a fully convolutional network for texture generation. Once estimated, this network produces realistic and arbitrarily large texture samples in real time. The two formulations result in non-convex concave problems that can be optimized efficiently with convergence properties and improved stability compared to adversarial approaches, without relying on any regularization. By directly dealing with the patch distribution of synthesized images, we also overcome limitations of state-of-the art techniques, such as patch aggregation issues that usually lead to low frequency artifacts (e.g. blurring) in traditional patch-based approaches, or statistical inconsistencies (e.g. color or patterns) in learning approaches.
A SentiWordNet Strategy for Curriculum Learning in Sentiment Analysis
May 10, 2020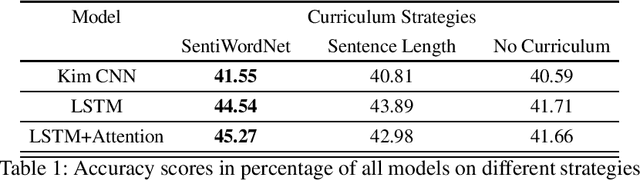
Curriculum Learning (CL) is the idea that learning on a training set sequenced or ordered in a manner where samples range from easy to difficult, results in an increment in performance over otherwise random ordering. The idea parallels cognitive science's theory of how human brains learn, and that learning a difficult task can be made easier by phrasing it as a sequence of easy to difficult tasks. This idea has gained a lot of traction in machine learning and image processing for a while and recently in Natural Language Processing (NLP). In this paper, we apply the ideas of curriculum learning, driven by SentiWordNet in a sentiment analysis setting. In this setting, given a text segment, our aim is to extract its sentiment or polarity. SentiWordNet is a lexical resource with sentiment polarity annotations. By comparing performance with other curriculum strategies and with no curriculum, the effectiveness of the proposed strategy is presented. Convolutional, Recurrence, and Attention-based architectures are employed to assess this improvement. The models are evaluated on a standard sentiment dataset, Stanford Sentiment Treebank.
Superpixel-Based Background Recovery from Multiple Images
Nov 04, 2019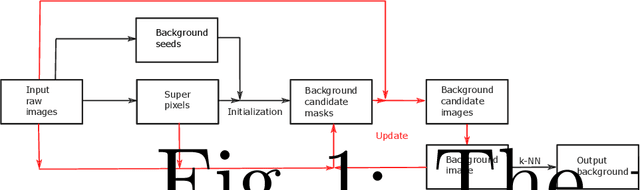


In this paper, we propose an intuitive method to recover background from multiple images. The implementation consists of three stages: model initialization, model update, and background output. We consider the pixels whose values change little in all input images as background seeds. Images are then segmented into superpixels with simple linear iterative clustering. When the number of pixels labelled as background in a superpixel is bigger than a predefined threshold, we label the superpixel as background to initialize the background candidate masks. Background candidate images are obtained from input raw images with the masks. Combining all candidate images, a background image is produced. The background candidate masks, candidate images, and the background image are then updated alternately until convergence. Finally, ghosting artifacts is removed with the k-nearest neighbour method. An experiment on an outdoor dataset demonstrates that the proposed algorithm can achieve promising results.
Accelerating cardiac cine MRI beyond compressed sensing using DL-ESPIRiT
Nov 13, 2019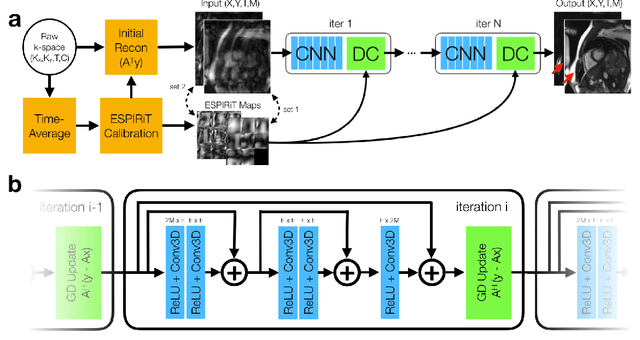
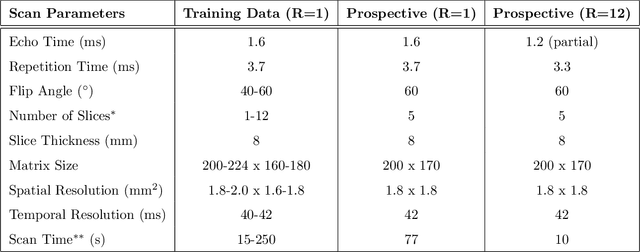
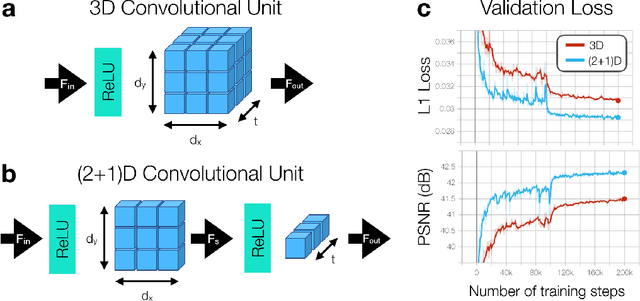
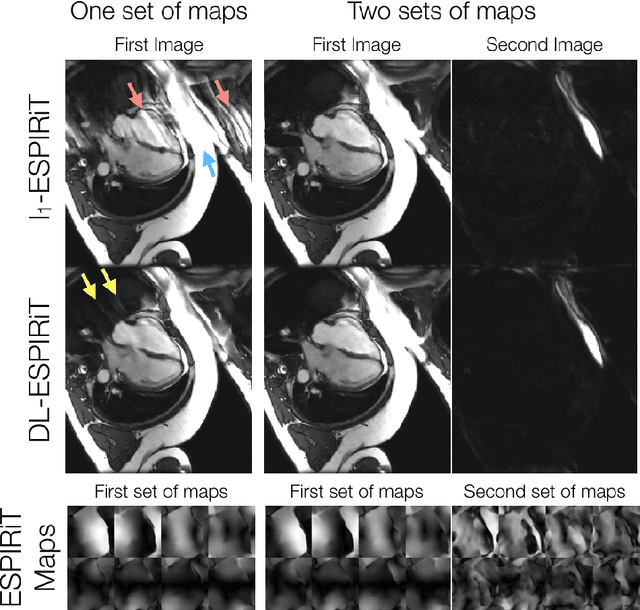
A novel neural network architecture, known as DL-ESPIRiT, is proposed to reconstruct rapidly acquired cardiac MRI data without field-of-view limitations which are present in previously proposed deep learning-based reconstruction frameworks. Additionally, a novel convolutional neural network based on separable 3D convolutions is integrated into DL-ESPIRiT to more efficiently learn spatiotemporal priors for dynamic image reconstruction. The network is trained on fully-sampled 2D cardiac cine datasets collected from eleven healthy volunteers with IRB approval. DL-ESPIRiT is compared against a state-of-the-art parallel imaging and compressed sensing method known as $l_1$-ESPIRiT. The reconstruction accuracy of both methods is evaluated on retrospectively undersampled datasets (R=12) with respect to standard image quality metrics as well as automatic deep learning-based segmentations of left ventricular volumes. Feasibility of this approach is demonstrated in reconstructions of prospectively undersampled data which were acquired in a single heartbeat per slice.