 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DuDoNet++: Encoding mask projection to reduce CT metal artifacts
Jan 02, 2020
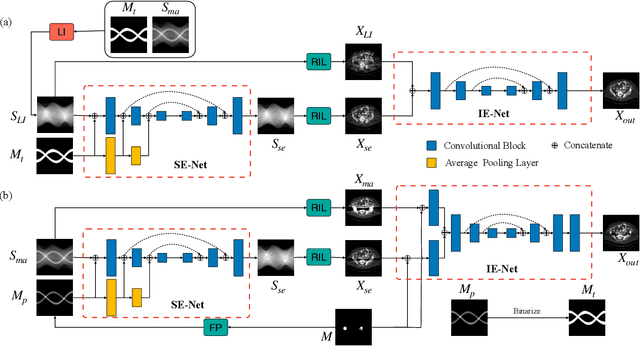

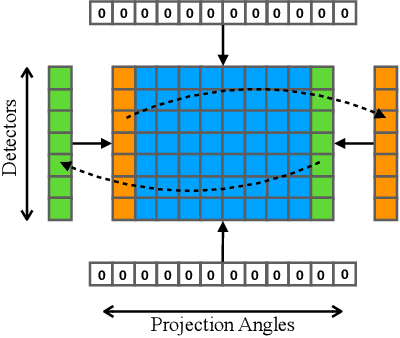

CT metal artifact reduction (MAR) is a notoriously challenging task because the artifacts are structured and non-local in the image domain. However, they are inherently local in the sinogram domain. DuDoNet is the state-of-the-art MAR algorithm which exploits the latter characteristic by learning to reduce artifacts in the sinogram and image domain jointly. By design, DuDoNet treats the metal-affected regions in sinogram as missing and replaces them with the surrogate data generated by a neural network. Since fine-grained details within the metal-affected regions are completely ignored, the artifact-reduced CT images by DuDoNet tend to be over-smoothed and distorted. In this work, we investigate the issue by theoretical derivation. We propose to address the problem by (1) retaining the metal-affected regions in sinogram and (2) replacing the binarized metal trace with the metal mask projection such that the geometry information of metal implants is encoded. Extensive experiments on simulated datasets and expert evaluations on clinical images demonstrate that our network called DuDoNet++ yields anatomically more precise artifact-reduced images than DuDoNet, especially when the metallic objects are large.
Learning Expectation of Label Distribution for Facial Age and Attractiveness Estimation
Jul 03, 2020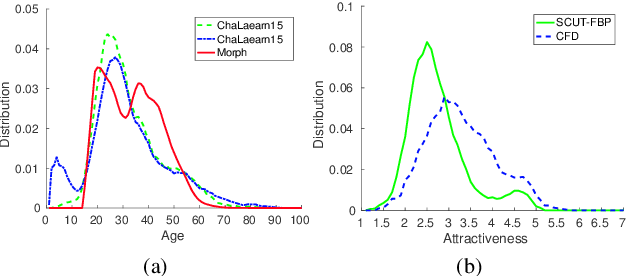
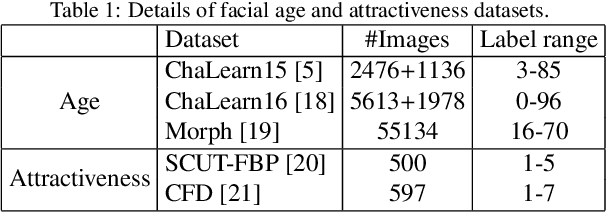
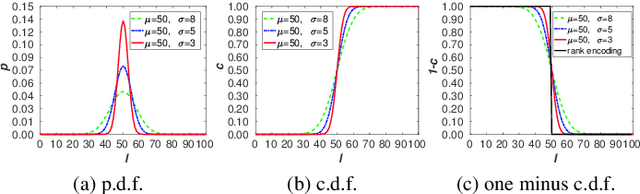
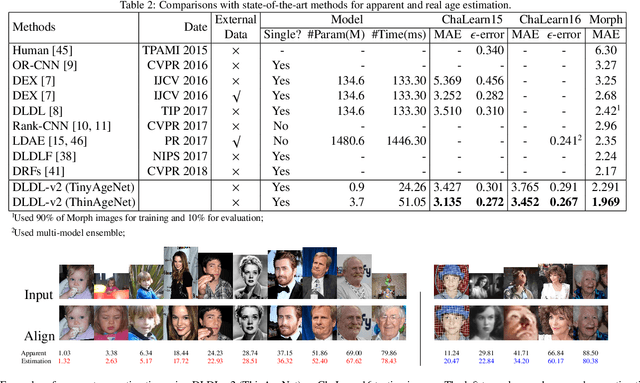
Facial attributes (e.g., age and attractiveness) estimation performance has been greatly improved by using convolutional neural networks. However, existing methods have an inconsistency between the training objectives and the evaluation metric, so they may be suboptimal. In addition, these methods always adopt image classification or face recognition models with a large amount of parameters, which carry expensive computation cost and storage overhead. In this paper, we firstly analyze the essential relationship between two state-of-the-art methods (Ranking-CNN and DLDL) and show that the Ranking method is in fact learning label distribution implicitly. This result thus firstly unifies two existing popular state-of-the-art methods into the DLDL framework. Second, in order to alleviate the inconsistency and reduce resource consumption, we design a lightweight network architecture and propose a unified framework which can jointly learn facial attribute distribution and regress attribute value. The effectiveness of our approach has been demonstrated on both facial age and attractiveness estimation tasks. Our method achieves new state-of-the-art results using the single model with 36$\times$(6$\times$) fewer parameters and 2.6$\times$(2.1$\times$) faster inference speed on facial age (attractiveness) estimation. Moreover, our method can achieve comparable results as the state-of-the-art even though the number of parameters is further reduced to 0.9M (3.8MB disk storage).
Recurrent Generative Adversarial Networks for Proximal Learning and Automated Compressive Image Recovery
Nov 27, 2017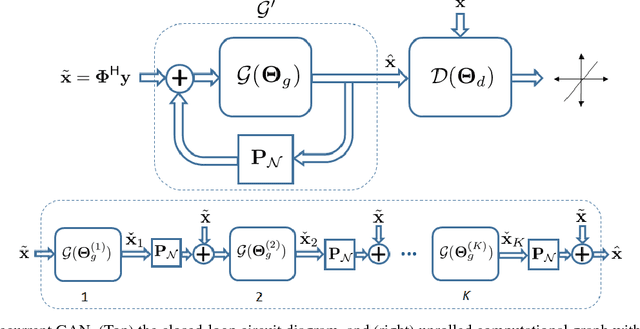

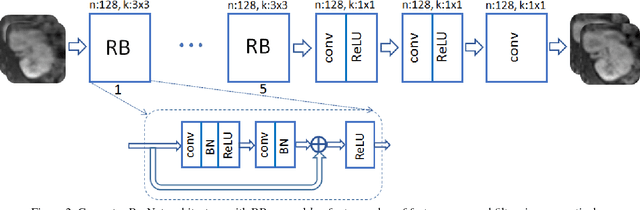
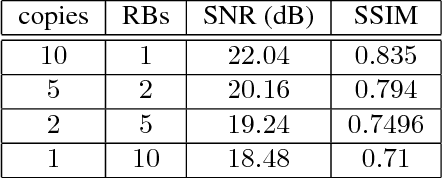
Recovering images from undersampled linear measurements typically leads to an ill-posed linear inverse problem, that asks for proper statistical priors. Building effective priors is however challenged by the low train and test overhead dictated by real-time tasks; and the need for retrieving visually "plausible" and physically "feasible" images with minimal hallucination. To cope with these challenges, we design a cascaded network architecture that unrolls the proximal gradient iterations by permeating benefits from generative residual networks (ResNet) to modeling the proximal operator. A mixture of pixel-wise and perceptual costs is then deployed to train proximals. The overall architecture resembles back-and-forth projection onto the intersection of feasible and plausible images. Extensive computational experiments are examined for a global task of reconstructing MR images of pediatric patients, and a more local task of superresolving CelebA faces, that are insightful to design efficient architectures. Our observations indicate that for MRI reconstruction, a recurrent ResNet with a single residual block effectively learns the proximal. This simple architecture appears to significantly outperform the alternative deep ResNet architecture by 2dB SNR, and the conventional compressed-sensing MRI by 4dB SNR with 100x faster inference. For image superresolution, our preliminary results indicate that modeling the denoising proximal demands deep ResNets.
Compounding the Performance Improvements of Assembled Techniques in a Convolutional Neural Network
Jan 17, 2020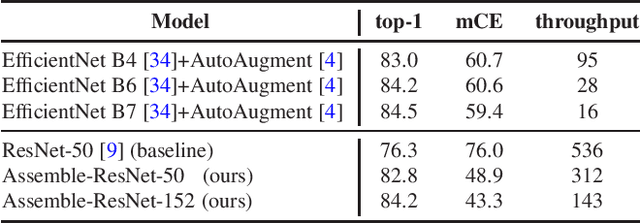
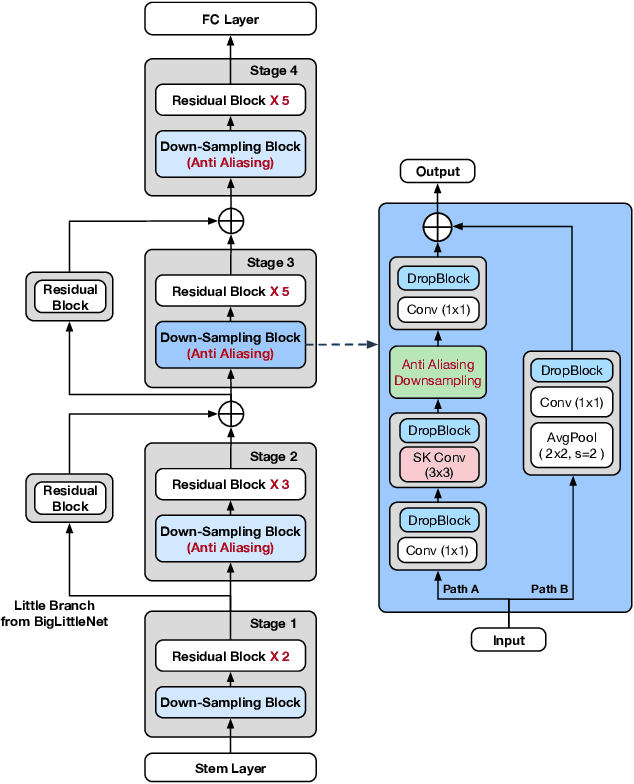
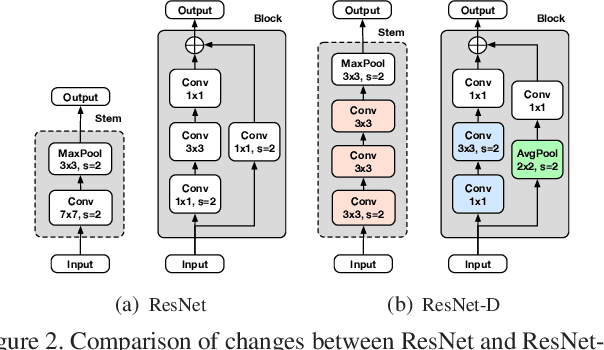
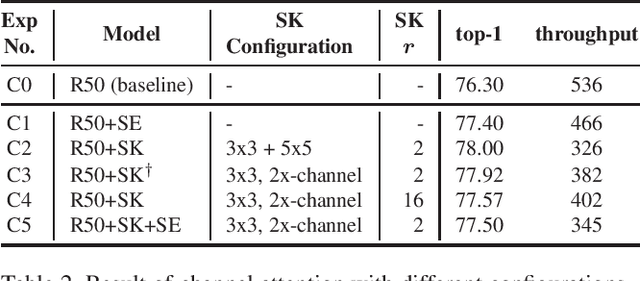
Recent studies in image classification have demonstrated a variety of techniques for improving the performance of Convolutional Neural Networks (CNNs). However, attempts to combine existing techniques to create a practical model are still uncommon. In this study, we carry out extensive experiments to validate that carefully assembling these techniques and applying them to a basic CNN model in combination can improve the accuracy and robustness of the model while minimizing the loss of throughput. For example, our proposed ResNet-50 shows an improvement in top-1 accuracy from 76.3% to 82.78%, and an mCE improvement from 76.0% to 48.9%, on the ImageNet ILSVRC2012 validation set. With these improvements, inference throughput only decreases from 536 to 312. The resulting model significantly outperforms state-of-the-art models with similar accuracy in terms of mCE and inference throughput. To verify the performance improvement in transfer learning, fine grained classification and image retrieval tasks were tested on several open datasets and showed that the improvement to backbone network performance boosted transfer learning performance significantly. Our approach achieved 1st place in the iFood Competition Fine-Grained Visual Recognition at CVPR 2019, and the source code and trained models are available at https://github.com/clovaai/assembled-cnn
Lessons Learned from the Training of GANs on Artificial Datasets
Jul 14, 2020
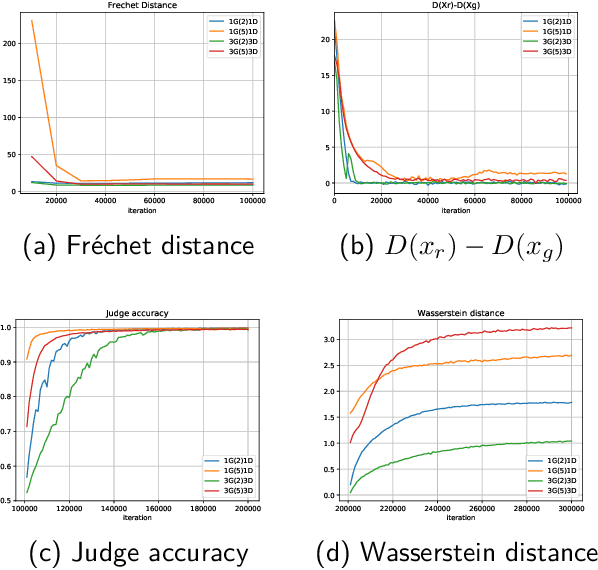
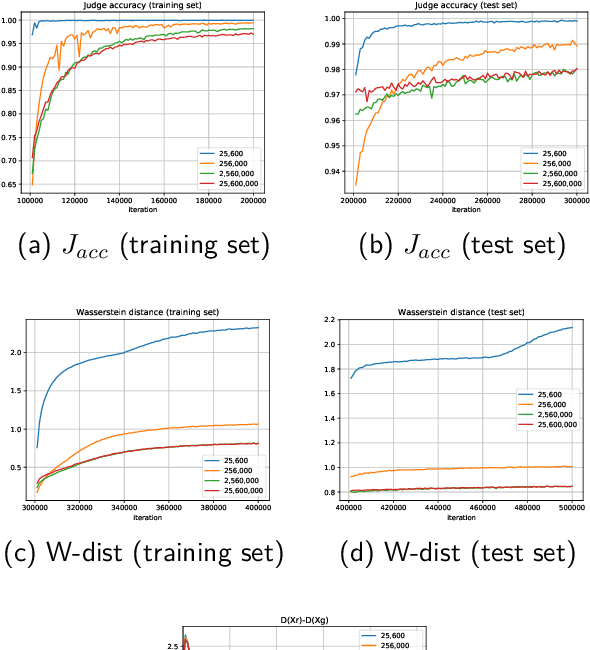
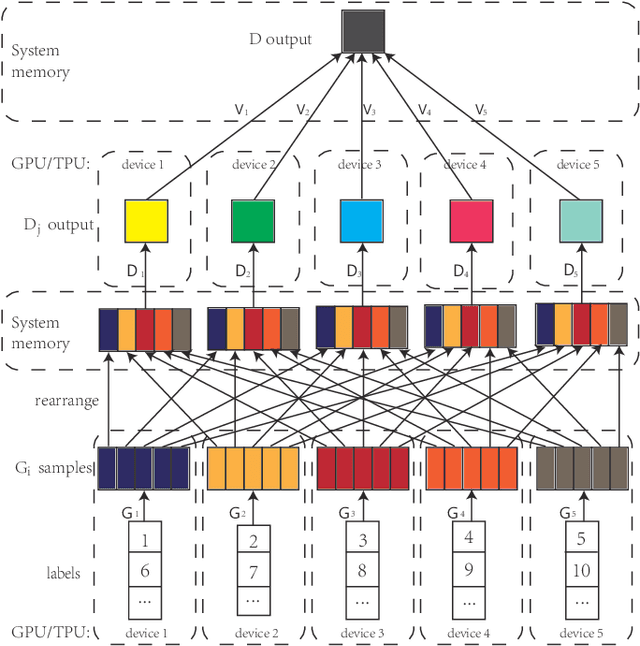
Generative Adversarial Networks (GANs) have made great progress in synthesizing realistic images in recent years. However, they are often trained on image datasets with either too few samples or too many classes belonging to different data distributions. Consequently, GANs are prone to underfitting or overfitting, making the analysis of them difficult and constrained. Therefore, in order to conduct a thorough study on GANs while obviating unnecessary interferences introduced by the datasets, we train them on artificial datasets where there are infinitely many samples and the real data distributions are simple, high-dimensional and have structured manifolds. Moreover, the generators are designed such that optimal sets of parameters exist. Empirically, we find that under various distance measures, the generator fails to learn such parameters with the GAN training procedure. We also find that training mixtures of GANs leads to more performance gain compared to increasing the network depth or width when the model complexity is high enough. Our experimental results demonstrate that a mixture of generators can discover different modes or different classes automatically in an unsupervised setting, which we attribute to the distribution of the generation and discrimination tasks across multiple generators and discriminators. As an example of the generalizability of our conclusions to realistic datasets, we train a mixture of GANs on the CIFAR-10 dataset and our method significantly outperforms the state-of-the-art in terms of popular metrics, i.e., Inception Score (IS) and Fr\'echet Inception Distance (FID).
Learning-based real-time method to looking through scattering medium oriented to practical application
Oct 20, 2019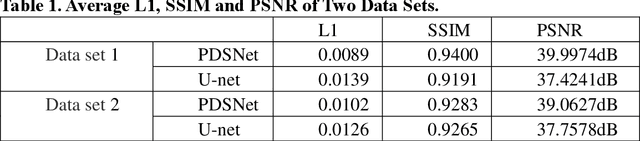


Strong scattering media brings great difficulties to optical imaging, which is also a problem that medical imaging and many other fields must face. Optical memory effect makes it possible to image through strong scattering medium. However, this method also has the limitation of limited angle field-of-view (FOV), which prevents it from being applied in practice. In this paper, a kind of practical convolutional neural network called PDSNet is proposed, which effectively breaks through the limitation of optical memory effect on image field angle. Experiments is conducted to prove that the scattered pattern can be reconstructed quickly and accurately by PDSNet, and it is widely applicable to restoring speckle pattern generated from objects of different scales and scattering medias with different statistical characteristics.
RetinaMask: A Face Mask detector
Jun 08, 2020
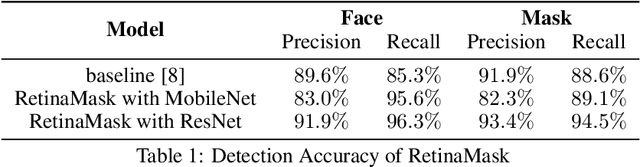
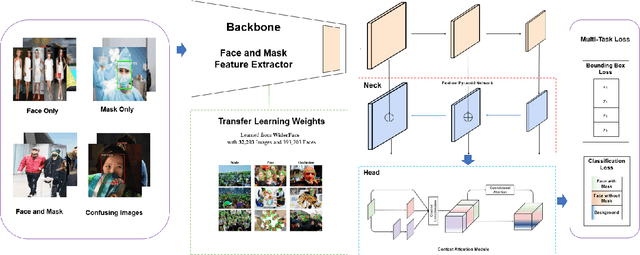
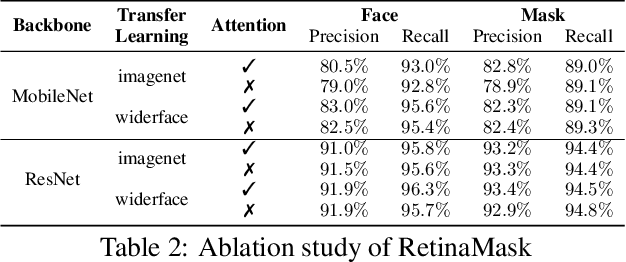
Coronavirus disease 2019 has affected the world seriously. One major protection method for people is to wear masks in public areas. Furthermore, many public service providers require customers to use the service only if they wear masks correctly. However, there are only a few research studies about face mask detection based on image analysis. In this paper, we propose RetinaFaceMask, which is a high-accuracy and efficient face mask detector. The proposed RetinaFaceMask is a one-stage detector, which consists of a feature pyramid network to fuse high-level semantic information with multiple feature maps, and a novel context attention module to focus on detecting face masks. In addition, we also propose a novel cross-class object removal algorithm to reject predictions with low confidences and the high intersection of union. Experiment results show that RetinaFaceMask achieves state-of-the-art results on a public face mask dataset with $2.3\%$ and $1.5\%$ higher than the baseline result in the face and mask detection precision, respectively, and $11.0\%$ and $5.9\%$ higher than baseline for recall. Besides, we also explore the possibility of implementing RetinaFaceMask with a light-weighted neural network MobileNet for embedded or mobile devices.
Multimodal Machine Translation through Visuals and Speech
Nov 28, 2019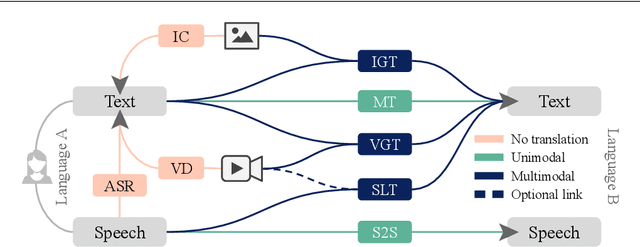
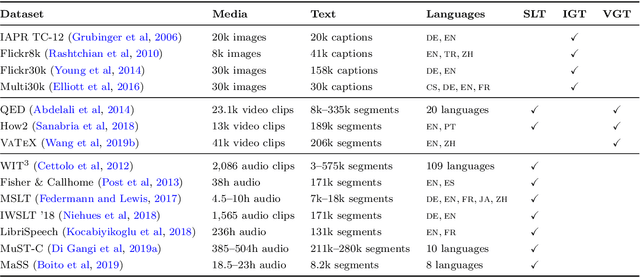

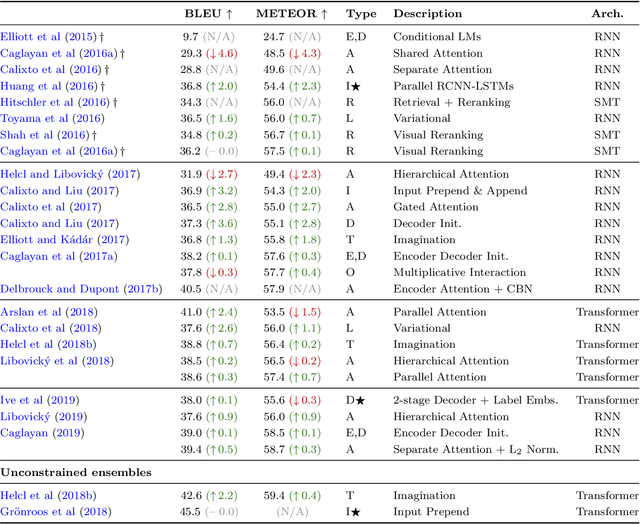
Multimodal machine translation involves drawing information from more than one modality, based on the assumption that the additional modalities will contain useful alternative views of the input data. The most prominent tasks in this area are spoken language translation, image-guided translation, and video-guided translation, which exploit audio and visual modalities, respectively. These tasks are distinguished from their monolingual counterparts of speech recognition, image captioning, and video captioning by the requirement of models to generate outputs in a different language. This survey reviews the major data resources for these tasks, the evaluation campaigns concentrated around them, the state of the art in end-to-end and pipeline approaches, and also the challenges in performance evaluation. The paper concludes with a discussion of directions for future research in these areas: the need for more expansive and challenging datasets, for targeted evaluations of model performance, and for multimodality in both the input and output space.
A Novel Pose Proposal Network and Refinement Pipeline for Better Object Pose Estimation
Apr 11, 2020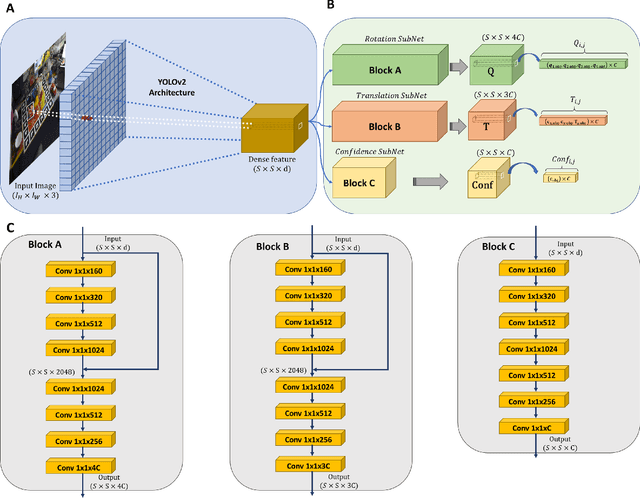

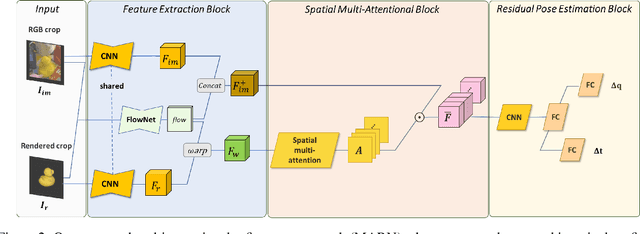
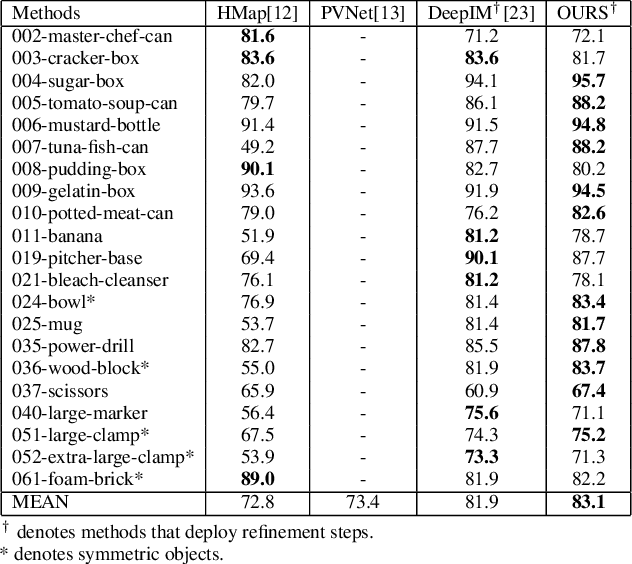
In this paper, we present a novel deep learning pipeline for 6D object pose estimation and refinement from RGB inputs. The first component of the pipeline leverages a region proposal framework to estimate multi-class single-shot 6D object poses directly from an RGB image and through a CNN-based encoder multi-decoders network. The second component, a multi-attentional pose refinement network (MARN), iteratively refines the estimated pose. MARN takes advantage of both visual and flow features to learn a relative transformation between an initially predicted pose and a target pose. MARN is further augmented by a spatial multi-attention block that emphasizes objects' discriminative feature parts. Experiments on three benchmarks for 6D pose estimation show that the proposed pipeline outperforms state-of-the-art RGB-based methods with competitive runtime performance.
Reconstructing the Forest of Lineage Trees of Diverse Bacterial Communities Using Bio-inspired Image Analysis
Jun 22, 2017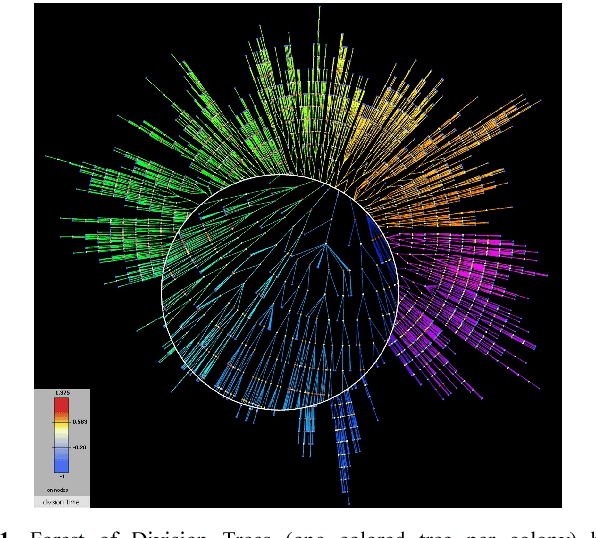
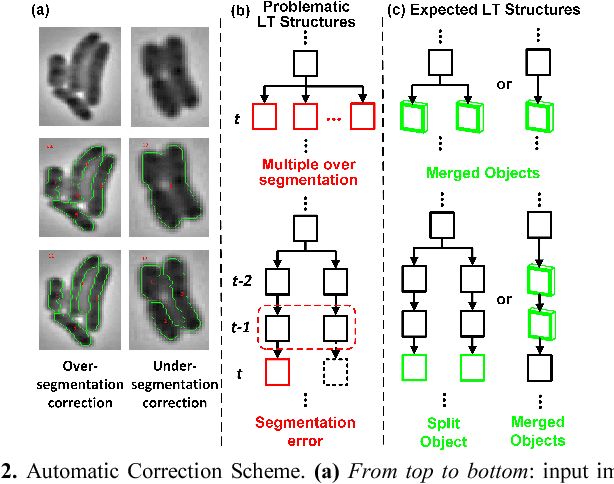
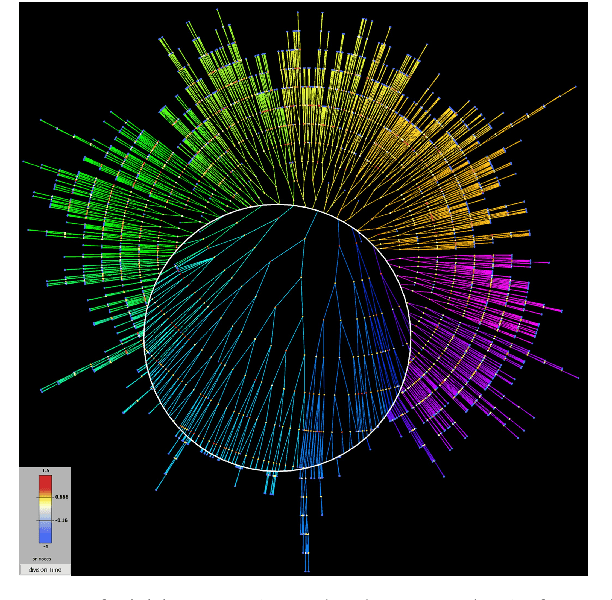
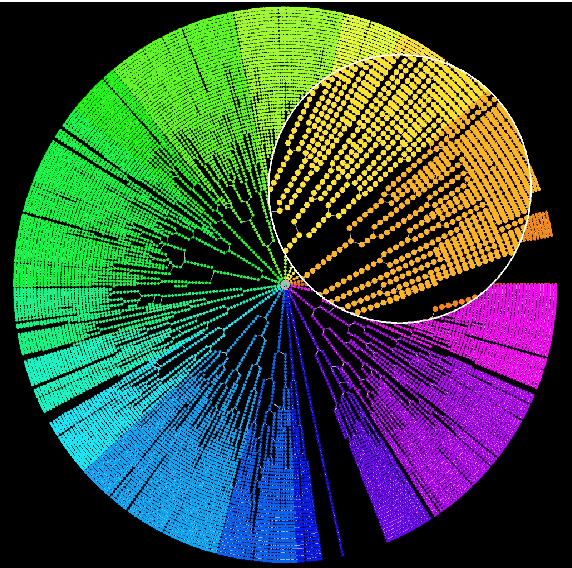
Cell segmentation and tracking allow us to extract a plethora of cell attributes from bacterial time-lapse cell movies, thus promoting computational modeling and simulation of biological processes down to the single-cell level. However, to analyze successfully complex cell movies, imaging multiple interacting bacterial clones as they grow and merge to generate overcrowded bacterial communities with thousands of cells in the field of view, segmentation results should be near perfect to warrant good tracking results. We introduce here a fully automated closed-loop bio-inspired computational strategy that exploits prior knowledge about the expected structure of a colony's lineage tree to locate and correct segmentation errors in analyzed movie frames. We show that this correction strategy is effective, resulting in improved cell tracking and consequently trustworthy deep colony lineage trees. Our image analysis approach has the unique capability to keep tracking cells even after clonal subpopulations merge in the movie. This enables the reconstruction of the complete Forest of Lineage Trees (FLT) representation of evolving multi-clonal bacterial communities. Moreover, the percentage of valid cell trajectories extracted from the image analysis almost doubles after segmentation correction. This plethora of trustworthy data extracted from a complex cell movie analysis enables single-cell analytics as a tool for addressing compelling questions for human health, such as understanding the role of single-cell stochasticity in antibiotics resistance without losing site of the inter-cellular interactions and microenvironment effects that may shape it.