 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Fuse 2D and 3D Image Cues for Monocular Body Pose Estimation
Apr 10, 2017
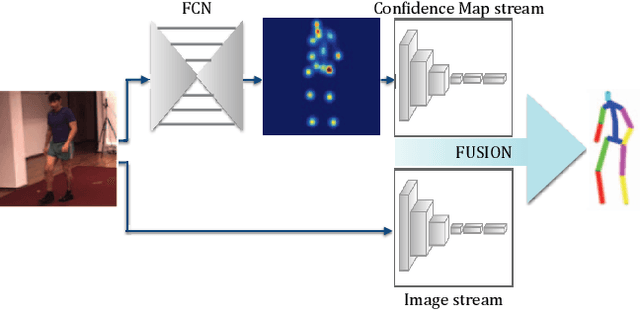
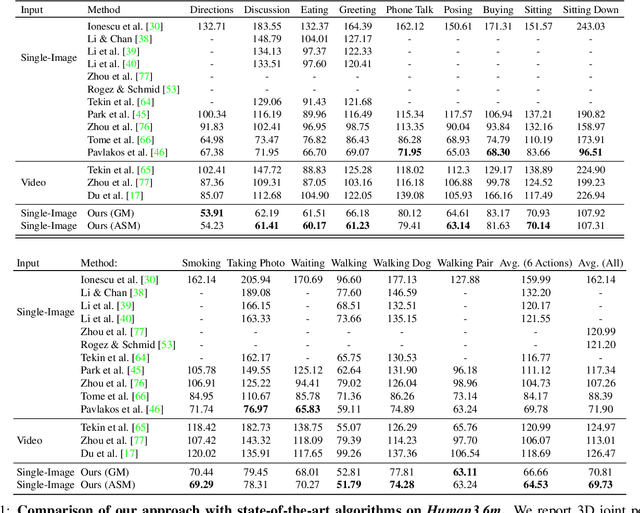
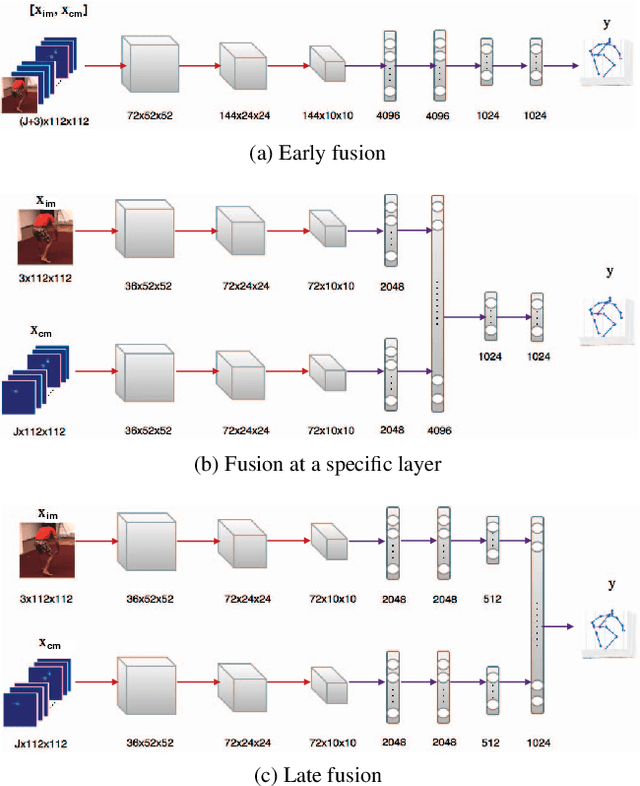

Most recent approaches to monocular 3D human pose estimation rely on Deep Learning. They typically involve regressing from an image to either 3D joint coordinates directly or 2D joint locations from which 3D coordinates are inferred. Both approaches have their strengths and weaknesses and we therefore propose a novel architecture designed to deliver the best of both worlds by performing both simultaneously and fusing the information along the way. At the heart of our framework is a trainable fusion scheme that learns how to fuse the information optimally instead of being hand-designed. This yields significant improvements upon the state-of-the-art on standard 3D human pose estimation benchmarks.
Heterogeneous Domain Adaptation via Soft Transfer Network
Aug 28, 2019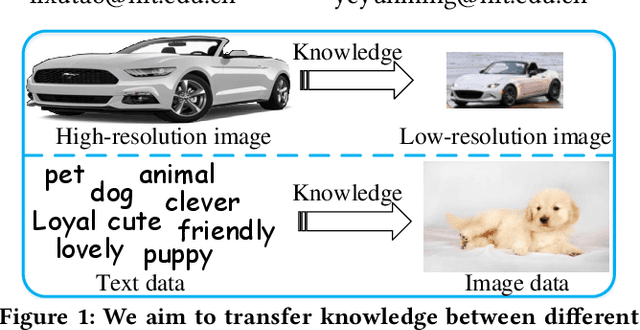
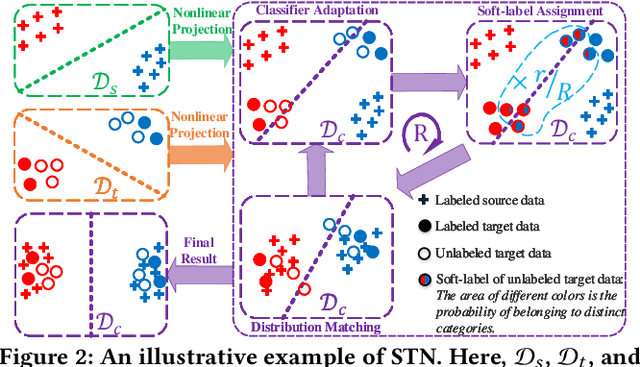
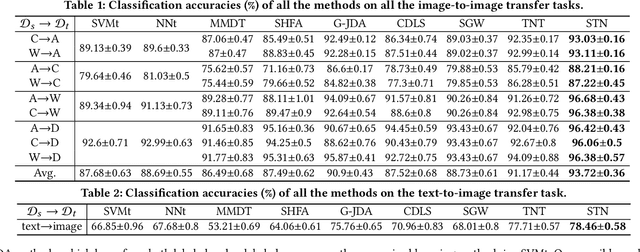
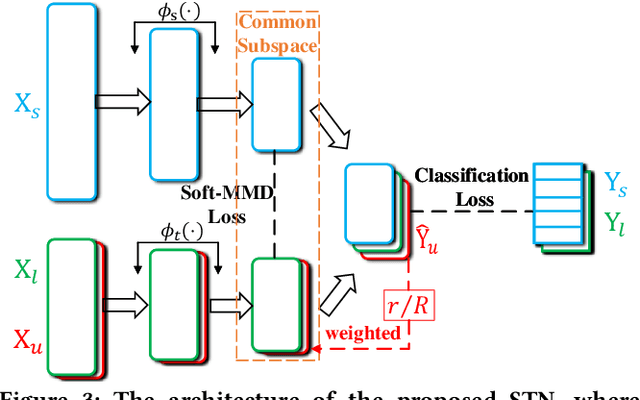
Heterogeneous domain adaptation (HDA) aims to facilitate the learning task in a target domain by borrowing knowledge from a heterogeneous source domain. In this paper, we propose a Soft Transfer Network (STN), which jointly learns a domain-shared classifier and a domain-invariant subspace in an end-to-end manner, for addressing the HDA problem. The proposed STN not only aligns the discriminative directions of domains but also matches both the marginal and conditional distributions across domains. To circumvent negative transfer, STN aligns the conditional distributions by using the soft-label strategy of unlabeled target data, which prevents the hard assignment of each unlabeled target data to only one category that may be incorrect. Further, STN introduces an adaptive coefficient to gradually increase the importance of the soft-labels since they will become more and more accurate as the number of iterations increases. We perform experiments on the transfer tasks of image-to-image, text-to-image, and text-to-text. Experimental results testify that the STN significantly outperforms several state-of-the-art approaches.
Privacy-Aware Activity Classification from First Person Office Videos
Jun 11, 2020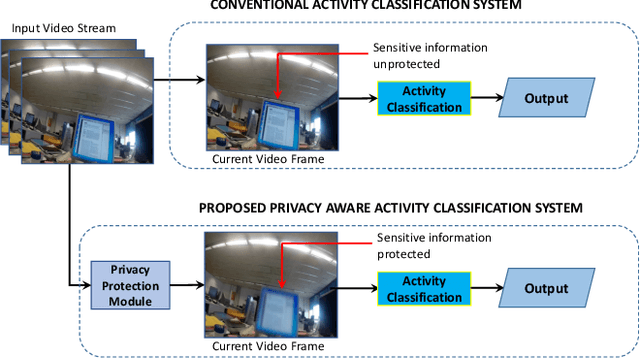

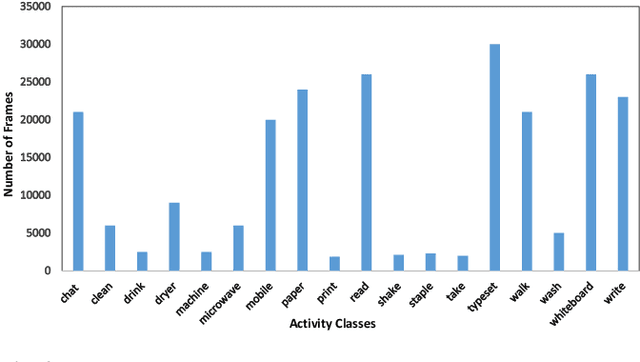

In the advent of wearable body-cameras, human activity classification from First-Person Videos (FPV) has become a topic of increasing importance for various applications, including in life-logging, law-enforcement, sports, workplace, and healthcare. One of the challenging aspects of FPV is its exposure to potentially sensitive objects within the user's field of view. In this work, we developed a privacy-aware activity classification system focusing on office videos. We utilized a Mask-RCNN with an Inception-ResNet hybrid as a feature extractor for detecting, and then blurring out sensitive objects (e.g., digital screens, human face, paper) from the videos. For activity classification, we incorporate an ensemble of Recurrent Neural Networks (RNNs) with ResNet, ResNext, and DenseNet based feature extractors. The proposed system was trained and evaluated on the FPV office video dataset that includes 18-classes made available through the IEEE Video and Image Processing (VIP) Cup 2019 competition. On the original unprotected FPVs, the proposed activity classifier ensemble reached an accuracy of 85.078% with precision, recall, and F1 scores of 0.88, 0.85 & 0.86, respectively. On privacy protected videos, the performances were slightly degraded, with accuracy, precision, recall, and F1 scores at 73.68%, 0.79, 0.75, and 0.74, respectively. The presented system won the 3rd prize in the IEEE VIP Cup 2019 competition.
Local Adaptation Improves Accuracy of Deep Learning Model for Automated X-Ray Thoracic Disease Detection : A Thai Study
Apr 28, 2020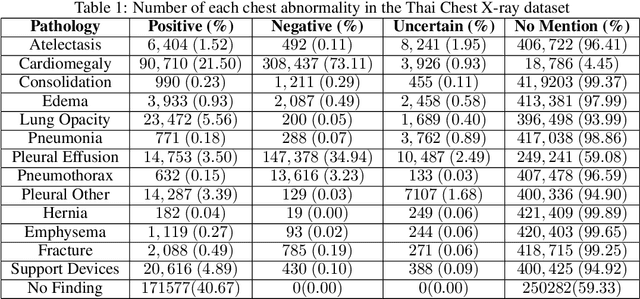
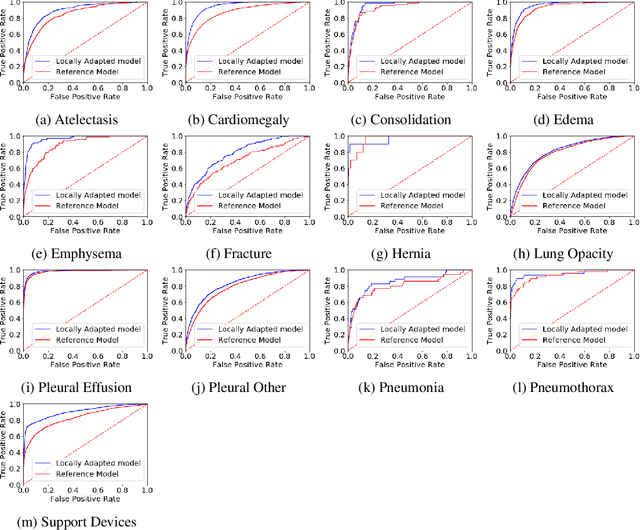
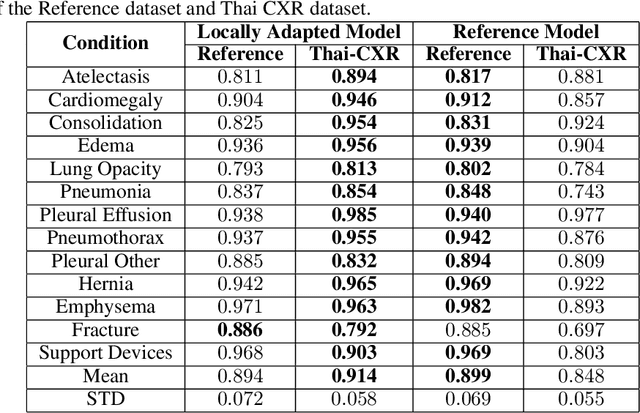
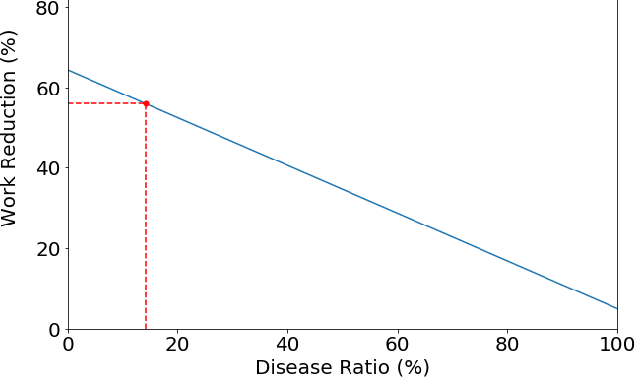
Despite much promising research in the area of artificial intelligence for medical image diagnosis, there has been no large-scale validation study done in Thailand to confirm the accuracy and utility of such algorithms when applied to local datasets. Here we present a wide-reaching development and testing of a deep learning algorithm for automated thoracic disease detection, utilizing 421,859 local chest radiographs. Our study shows that convolutional neural networks can achieve remarkable performance in detecting 13 common abnormality conditions on chest X-ray, and the incorporation of local images into the training set is key to the model's success. This paper presents a state-of-the-art model for CXR abnormality detection, reaching an average AUROC of 0.91. This model, if integrated to the workflow, can result in up to 55.6% work reduction for medical practitioners in the CXR analysis process. Our work emphasizes the importance of investing in local research of medical diagnosis algorithms to ensure safe and efficient usage within the intended region.
University-1652: A Multi-view Multi-source Benchmark for Drone-based Geo-localization
Feb 27, 2020
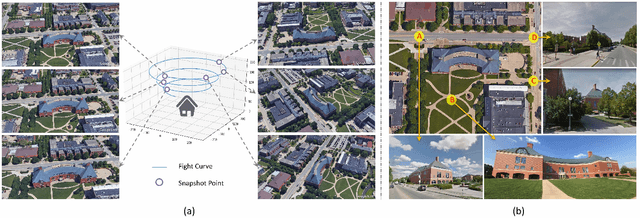
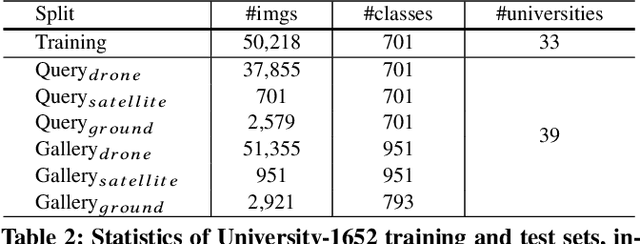
We consider the problem of cross-view geo-localization. The primary challenge of this task is to learn the robust feature against large viewpoint changes. Existing benchmarks can help, but are limited in the number of viewpoints. Image pairs, containing two viewpoints, e.g., satellite and ground, are usually provided, which may compromise the feature learning. Besides phone cameras and satellites, in this paper, we argue that drones could serve as the third platform to deal with the geo-localization problem. In contrast to the traditional ground-view images, drone-view images meet fewer obstacles, e.g., trees, and could provide a comprehensive view when flying around the target place. To verify the effectiveness of the drone platform, we introduce a new multi-view multi-source benchmark for drone-based geo-localization, named University-1652. University-1652 contains data from three platforms, i.e., synthetic drones, satellites and ground cameras of 1,652 university buildings around the world. To our knowledge, University-1652 is the first drone-based geo-localization dataset and enables two new tasks, i.e., drone-view target localization and drone navigation. As the name implies, drone-view target localization intends to predict the location of the target place via drone-view images. On the other hand, given a satellite-view query image, drone navigation is to drive the drone to the area of interest in the query. We use this dataset to analyze a variety of off-the-shelf CNN features and propose a strong CNN baseline on this challenging dataset. The experiments show that University-1652 helps the model to learn the viewpoint-invariant features and also has good generalization ability in the real-world scenario.
Multi-Scale Boosted Dehazing Network with Dense Feature Fusion
Apr 28, 2020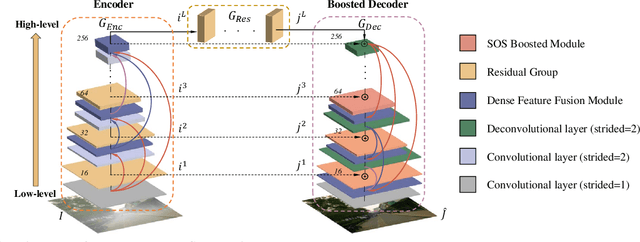

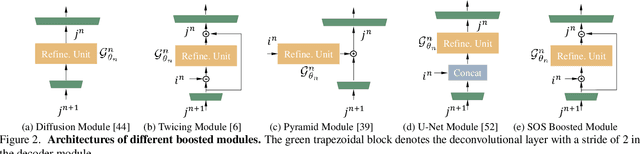
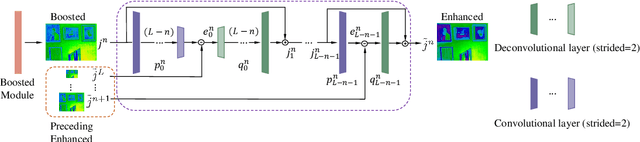
In this paper, we propose a Multi-Scale Boosted Dehazing Network with Dense Feature Fusion based on the U-Net architecture. The proposed method is designed based on two principles, boosting and error feedback, and we show that they are suitable for the dehazing problem. By incorporating the Strengthen-Operate-Subtract boosting strategy in the decoder of the proposed model, we develop a simple yet effective boosted decoder to progressively restore the haze-free image. To address the issue of preserving spatial information in the U-Net architecture, we design a dense feature fusion module using the back-projection feedback scheme. We show that the dense feature fusion module can simultaneously remedy the missing spatial information from high-resolution features and exploit the non-adjacent features. Extensive evaluations demonstrate that the proposed model performs favorably against the state-of-the-art approaches on the benchmark datasets as well as real-world hazy images.
The Edge of Depth: Explicit Constraints between Segmentation and Depth
Apr 01, 2020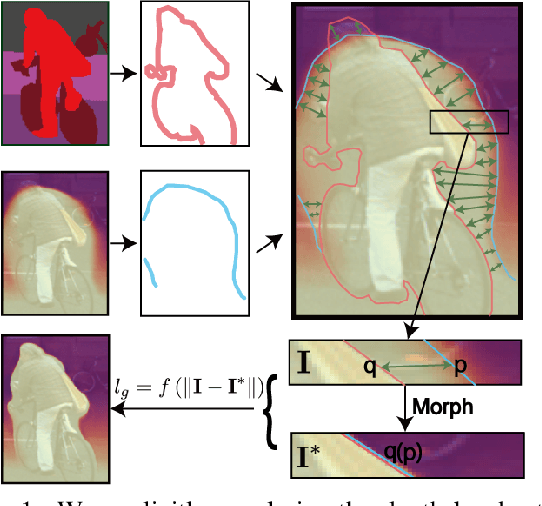
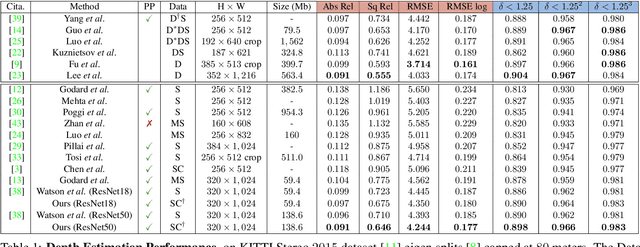
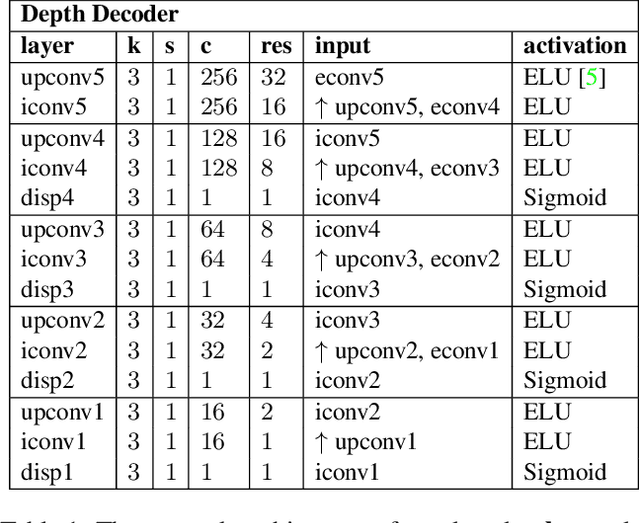
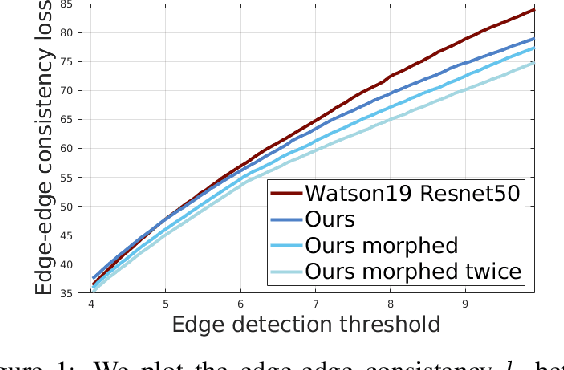
In this work we study the mutual benefits of two common computer vision tasks, self-supervised depth estimation and semantic segmentation from images. For example, to help unsupervised monocular depth estimation, constraints from semantic segmentation has been explored implicitly such as sharing and transforming features. In contrast, we propose to explicitly measure the border consistency between segmentation and depth and minimize it in a greedy manner by iteratively supervising the network towards a locally optimal solution. Partially this is motivated by our observation that semantic segmentation even trained with limited ground truth (200 images of KITTI) can offer more accurate border than that of any (monocular or stereo) image-based depth estimation. Through extensive experiments, our proposed approach advances the state of the art on unsupervised monocular depth estimation in the KITTI.
Unsupervised Microvascular Image Segmentation Using an Active Contours Mimicking Neural Network
Aug 04, 2019
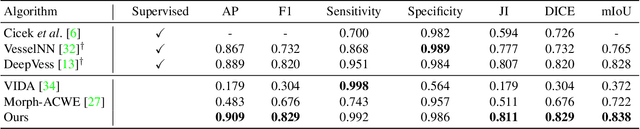

The task of blood vessel segmentation in microscopy images is crucial for many diagnostic and research applications. However, vessels can look vastly different, depending on the transient imaging conditions, and collecting data for supervised training is laborious. We present a novel deep learning method for unsupervised segmentation of blood vessels. The method is inspired by the field of active contours and we introduce a new loss term, which is based on the morphological Active Contours Without Edges (ACWE) optimization method. The role of the morphological operators is played by novel pooling layers that are incorporated to the network's architecture.We demonstrate the challenges that are faced by previous supervised learning solutions, when the imaging conditions shift. Our unsupervised method is able to outperform such previous methods in both the labeled dataset, and when applied to similar but different datasets. Our code, as well as efficient PyTorch reimplementations of the baseline methods VesselNN and DeepVess is available on GitHub - https://github.com/shirgur/UMIS.
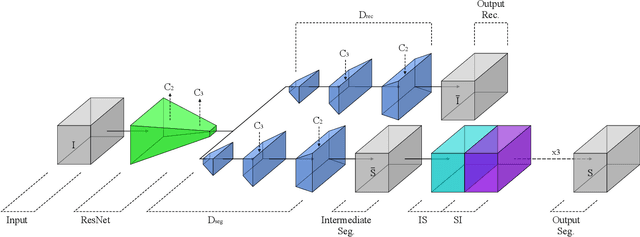
Deep Semantic Matching with Foreground Detection and Cycle-Consistency
Mar 31, 2020
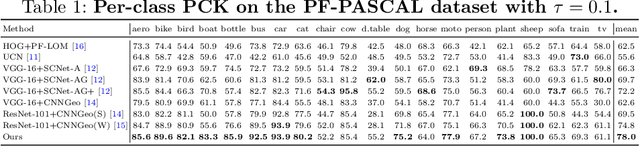
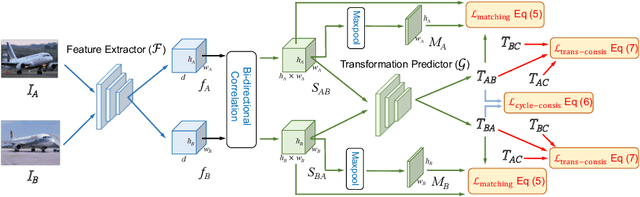
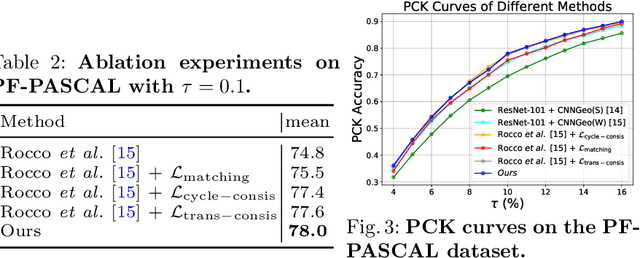
Establishing dense semantic correspondences between object instances remains a challenging problem due to background clutter, significant scale and pose differences, and large intra-class variations. In this paper, we address weakly supervised semantic matching based on a deep network where only image pairs without manual keypoint correspondence annotations are provided. To facilitate network training with this weaker form of supervision, we 1) explicitly estimate the foreground regions to suppress the effect of background clutter and 2) develop cycle-consistent losses to enforce the predicted transformations across multiple images to be geometrically plausible and consistent. We train the proposed model using the PF-PASCAL dataset and evaluate the performance on the PF-PASCAL, PF-WILLOW, and TSS datasets. Extensive experimental results show that the proposed approach performs favorably against the state-of-the-art methods.
It GAN DO Better: GAN-based Detection of Objects on Images with Varying Quality
Dec 03, 2019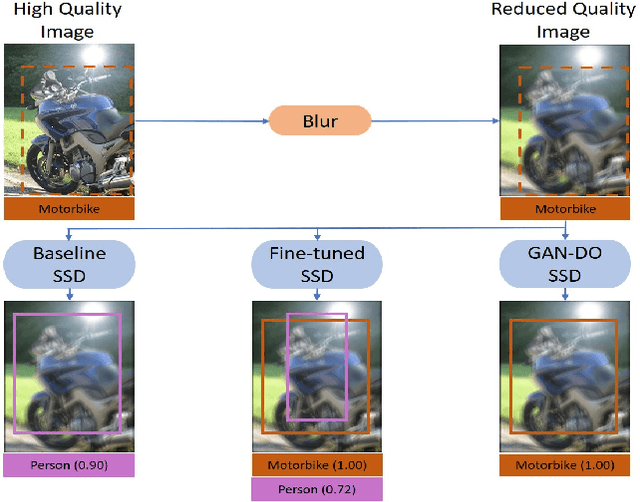
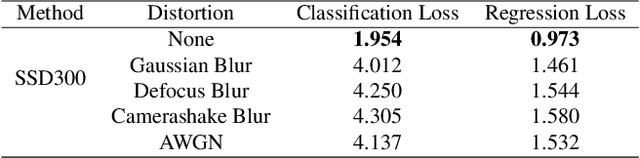
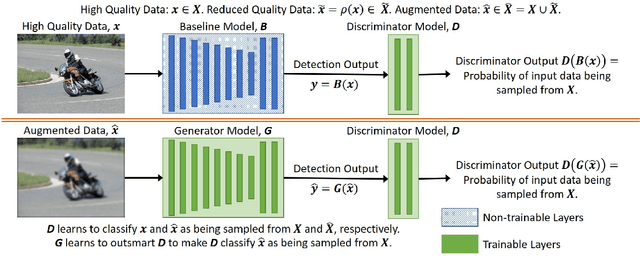
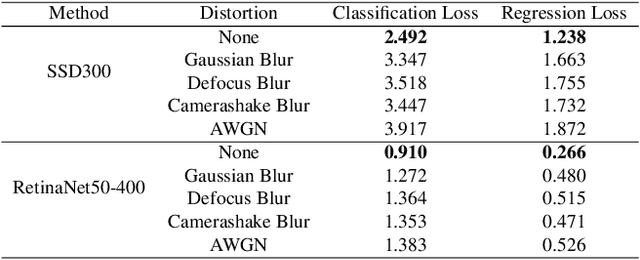
In this paper, we propose in our novel generative framework the use of Generative Adversarial Networks (GANs) to generate features that provide robustness for object detection on reduced quality images. The proposed GAN-based Detection of Objects (GAN-DO) framework is not restricted to any particular architecture and can be generalized to several deep neural network (DNN) based architectures. The resulting deep neural network maintains the exact architecture as the selected baseline model without adding to the model parameter complexity or inference speed. We first evaluate the effect of image quality not only on the object classification but also on the object bounding box regression. We then test the models resulting from our proposed GAN-DO framework, using two state-of-the-art object detection architectures as the baseline models. We also evaluate the effect of the number of re-trained parameters in the generator of GAN-DO on the accuracy of the final trained model. Performance results provided using GAN-DO on object detection datasets establish an improved robustness to varying image quality and a higher mAP compared to the existing approaches.