 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
In-bed Pressure-based Pose Estimation using Image Space Representation Learning
Aug 21, 2019
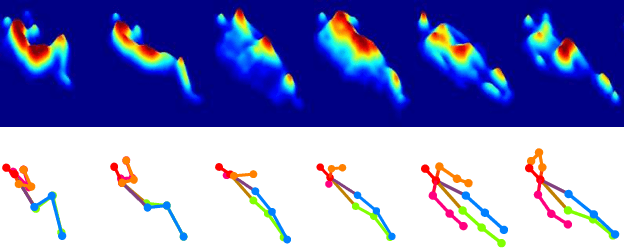

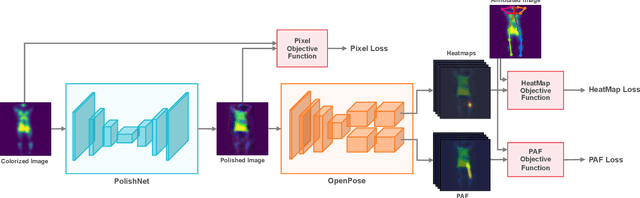

In-bed pose estimation has shown value in fields such as hospital patient monitoring, sleep studies, and smart homes. In this paper, we present a novel in-bed pressure-based pose estimation approach capable of accurately detecting body parts from highly ambiguous pressure data. We exploit the idea of using a learnable pre-processing step, which transforms the vague pressure maps to a representation close to the expected input space of common purpose pose identification modules, which fail if solely used on the pressure data. To this end, a fully convolutional network with multiple scales is used as the learnable pre-processing step to provide the pose-specific characteristics of the pressure maps to the pre-trained pose identification module. A combination of loss functions is used to model the constraints, ensuring that unclear body parts are reconstructed correctly while preventing the pre-processing block from generating arbitrary images. The evaluation results show high visual fidelity in the generated pre-processed images as well as high detection rates in pose estimation. Furthermore, we show that the trained pre-processing block can be effective for pose identification models for which it has not been trained as well.
Accurate Localization in Dense Urban Area Using Google Street View Image
Dec 29, 2014



Accurate information about the location and orientation of a camera in mobile devices is central to the utilization of location-based services (LBS). Most of such mobile devices rely on GPS data but this data is subject to inaccuracy due to imperfections in the quality of the signal provided by satellites. This shortcoming has spurred the research into improving the accuracy of localization. Since mobile devices have camera, a major thrust of this research has been seeks to acquire the local scene and apply image retrieval techniques by querying a GPS-tagged image database to find the best match for the acquired scene.. The techniques are however computationally demanding and unsuitable for real-time applications such as assistive technology for navigation by the blind and visually impaired which motivated out work. To overcome the high complexity of those techniques, we investigated the use of inertial sensors as an aid in image-retrieval-based approach. Armed with information of media other than images, such as data from the GPS module along with orientation sensors such as accelerometer and gyro, we sought to limit the size of the image set to c search for the best match. Specifically, data from the orientation sensors along with Dilution of precision (DOP) from GPS are used to find the angle of view and estimation of position. We present analysis of the reduction in the image set size for the search as well as simulations to demonstrate the effectiveness in a fast implementation with 98% Estimated Position Error.
Globally Optimal Segmentation of Mutually Interacting Surfaces using Deep Learning
Jul 15, 2020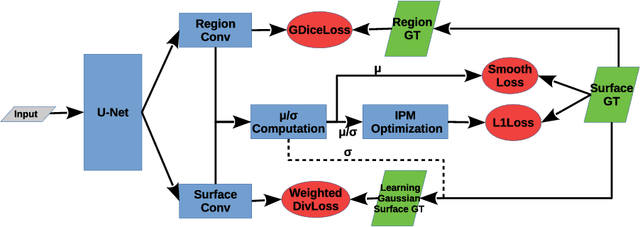
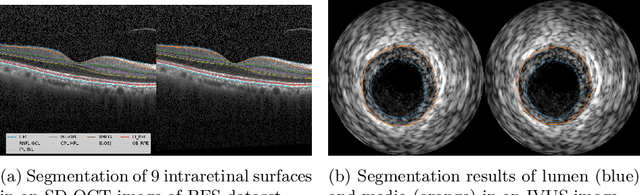

Segmentation of multiple surfaces in medical images is a challenging problem, further complicated by the frequent presence of weak boundary and mutual influence between adjacent objects. The traditional graph-based optimal surface segmentation method has proven its effectiveness with its ability of capturing various surface priors in a uniform graph model. However, its efficacy heavily relies on handcrafted features that are used to define the surface cost for the "goodness" of a surface. Recently, deep learning (DL) is emerging as powerful tools for medical image segmentation thanks to its superior feature learning capability. Unfortunately, due to the scarcity of training data in medical imaging, it is nontrivial for DL networks to implicitly learn the global structure of the target surfaces, including surface interactions. In this work, we propose to parameterize the surface cost functions in the graph model and leverage DL to learn those parameters. The multiple optimal surfaces are then simultaneously detected by minimizing the total surface cost while explicitly enforcing the mutual surface interaction constraints. The optimization problem is solved by the primal-dual Internal Point Method, which can be implemented by a layer of neural networks, enabling efficient end-to-end training of the whole network. Experiments on Spectral Domain Optical Coherence Tomography (SD-OCT) retinal layer segmentation and Intravascular Ultrasound (IVUS) vessel wall segmentation demonstrated very promising results. All source code is public to facilitate further research at this direction.
Does Multimodality Help Human and Machine for Translation and Image Captioning?
Aug 16, 2016

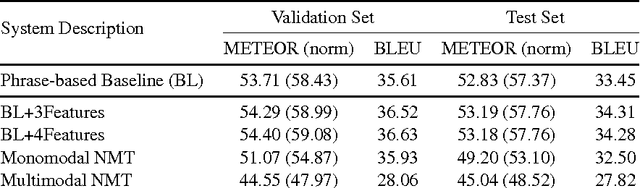
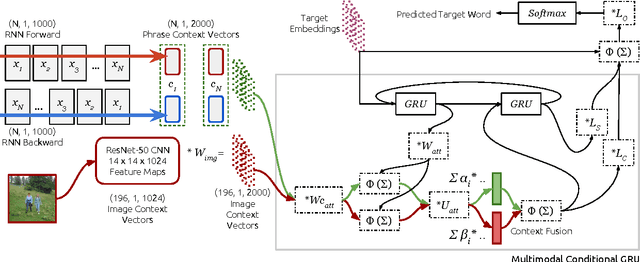
This paper presents the systems developed by LIUM and CVC for the WMT16 Multimodal Machine Translation challenge. We explored various comparative methods, namely phrase-based systems and attentional recurrent neural networks models trained using monomodal or multimodal data. We also performed a human evaluation in order to estimate the usefulness of multimodal data for human machine translation and image description generation. Our systems obtained the best results for both tasks according to the automatic evaluation metrics BLEU and METEOR.
Automated Focal Loss for Image based Object Detection
Apr 19, 2019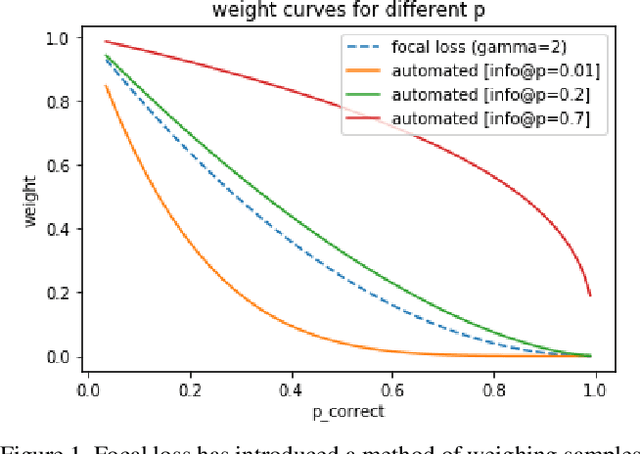
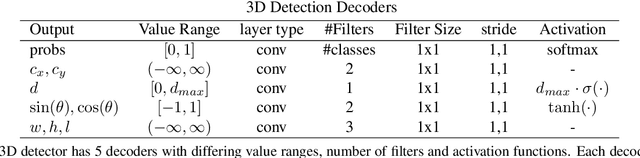
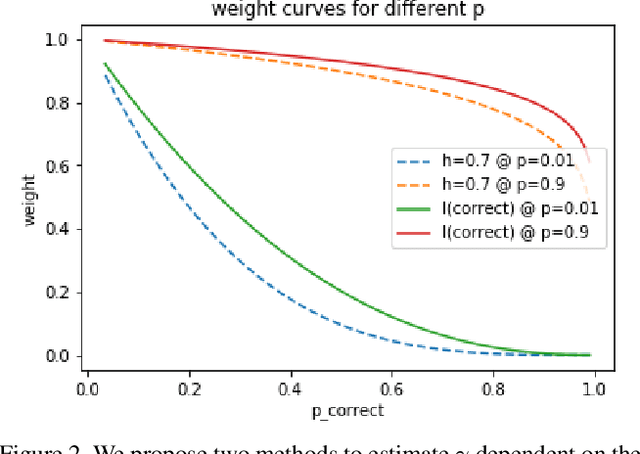
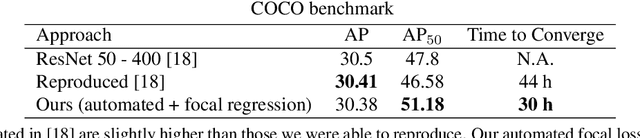
Current state-of-the-art object detection algorithms still suffer the problem of imbalanced distribution of training data over object classes and background. Recent work introduced a new loss function called focal loss to mitigate this problem, but at the cost of an additional hyperparameter. Manually tuning this hyperparameter for each training task is highly time-consuming. With automated focal loss we introduce a new loss function which substitutes this hyperparameter by a parameter that is automatically adapted during the training progress and controls the amount of focusing on hard training examples. We show on the COCO benchmark that this leads to an up to 30% faster training convergence. We further introduced a focal regression loss which on the more challenging task of 3D vehicle detection outperforms other loss functions by up to 1.8 AOS and can be used as a value range independent metric for regression.
Stereo Matching by Training a Convolutional Neural Network to Compare Image Patches
May 18, 2016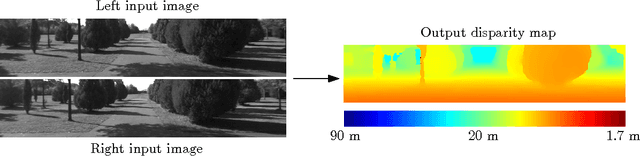
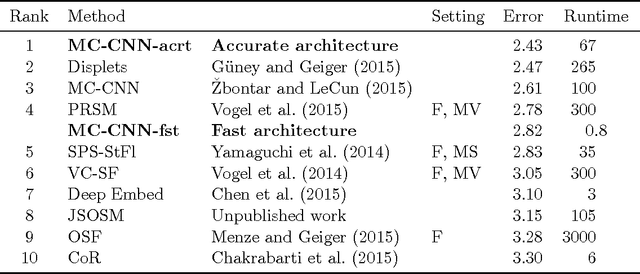
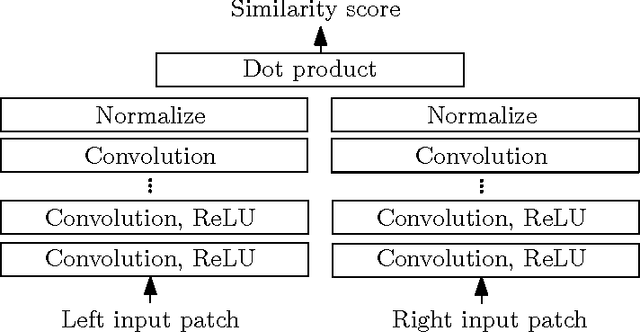
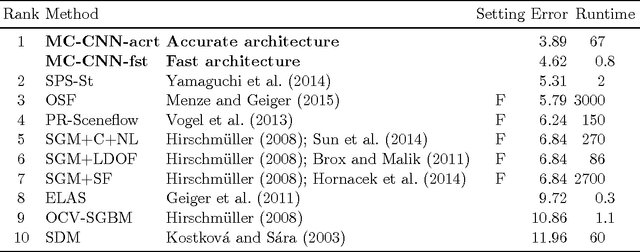
We present a method for extracting depth information from a rectified image pair. Our approach focuses on the first stage of many stereo algorithms: the matching cost computation. We approach the problem by learning a similarity measure on small image patches using a convolutional neural network. Training is carried out in a supervised manner by constructing a binary classification data set with examples of similar and dissimilar pairs of patches. We examine two network architectures for this task: one tuned for speed, the other for accuracy. The output of the convolutional neural network is used to initialize the stereo matching cost. A series of post-processing steps follow: cross-based cost aggregation, semiglobal matching, a left-right consistency check, subpixel enhancement, a median filter, and a bilateral filter. We evaluate our method on the KITTI 2012, KITTI 2015, and Middlebury stereo data sets and show that it outperforms other approaches on all three data sets.
Reducing Class Collapse in Metric Learning with Easy Positive Sampling
Jun 09, 2020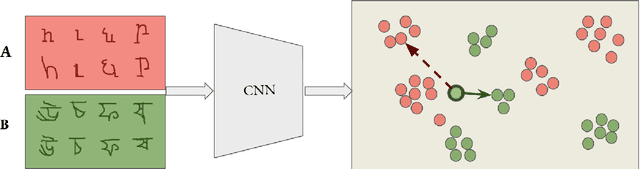

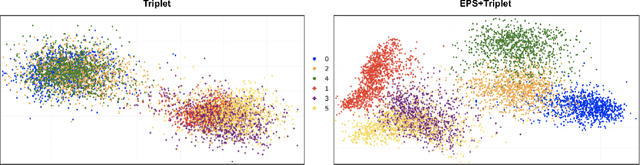
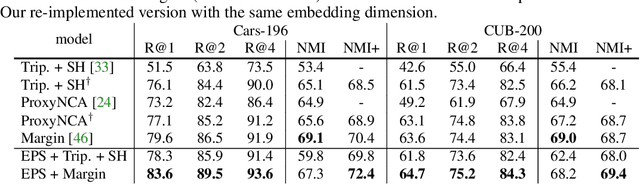
Metric learning seeks perceptual embeddings where visually similar instances are close and dissimilar instances are apart, but learn representation can be sub-optimal when the distribution of intra-class samples is diverse and distinct sub-clusters are present. We theoretically prove and empirically show that under reasonable noise assumptions, prevalent embedding losses in metric learning, e.g., triplet loss, tend to project all samples of a class with various modes onto a single point in the embedding space, resulting in class collapse that usually renders the space ill-sorted for classification or retrieval. To address this problem, we propose a simple modification to the embedding losses such that each sample selects its nearest same-class counterpart in a batch as the positive element in the tuple. This allows for the presence of multiple sub-clusters within each class. The adaptation can be integrated into a wide range of metric learning losses. Our method demonstrates clear benefits on various fine-grained image retrieval datasets over a variety of existing losses; qualitative retrieval results show that samples with similar visual patterns are indeed closer in the embedding space.
An Integrated Enhancement Solution for 24-hour Colorful Imaging
May 10, 2020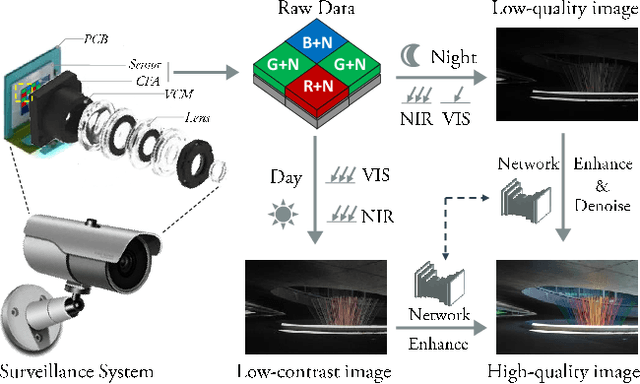
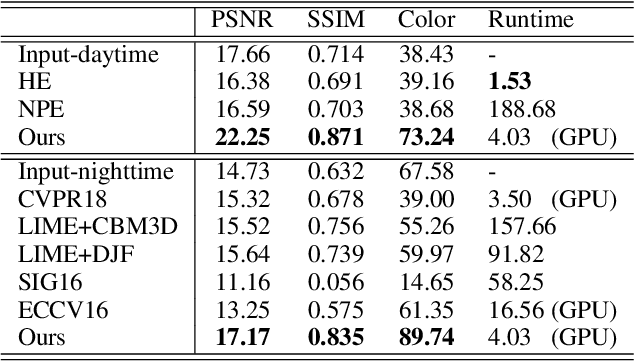
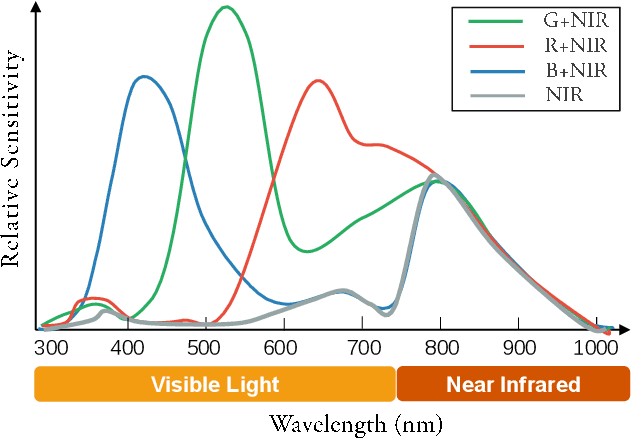
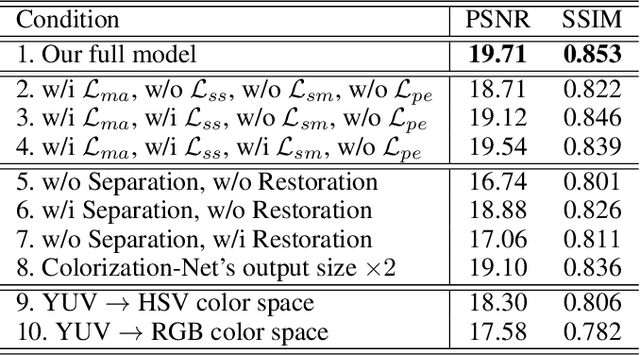
The current industry practice for 24-hour outdoor imaging is to use a silicon camera supplemented with near-infrared (NIR) illumination. This will result in color images with poor contrast at daytime and absence of chrominance at nighttime. For this dilemma, all existing solutions try to capture RGB and NIR images separately. However, they need additional hardware support and suffer from various drawbacks, including short service life, high price, specific usage scenario, etc. In this paper, we propose a novel and integrated enhancement solution that produces clear color images, whether at abundant sunlight daytime or extremely low-light nighttime. Our key idea is to separate the VIS and NIR information from mixed signals, and enhance the VIS signal adaptively with the NIR signal as assistance. To this end, we build an optical system to collect a new VIS-NIR-MIX dataset and present a physically meaningful image processing algorithm based on CNN. Extensive experiments show outstanding results, which demonstrate the effectiveness of our solution.
Red-GAN: Attacking class imbalance via conditioned generation. Yet another medical imaging perspective
Apr 22, 2020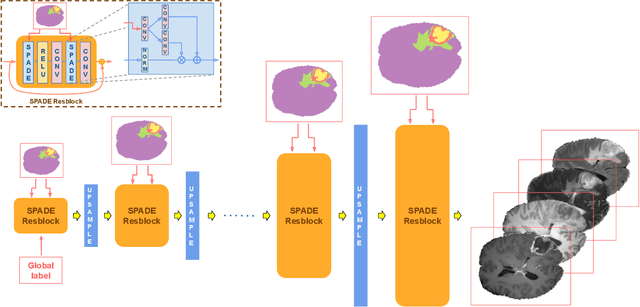

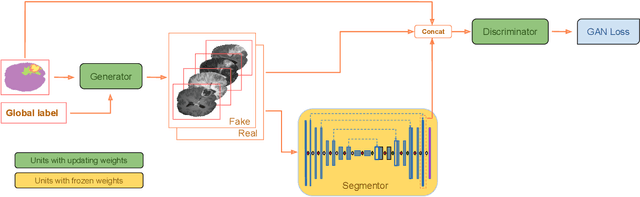
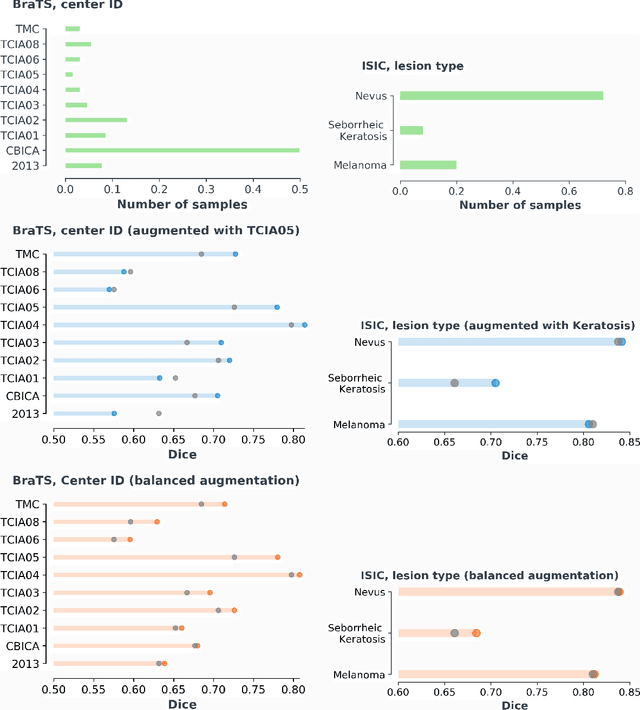
Exploiting learning algorithms under scarce data regimes is a limitation and a reality of the medical imaging field. In an attempt to mitigate the problem, we propose a data augmentation protocol based on generative adversarial networks. We condition the networks at a pixel-level (segmentation mask) and at a global-level information (acquisition environment or lesion type). Such conditioning provides immediate access to the image-label pairs while controlling global class specific appearance of the synthesized images. To stimulate synthesis of the features relevant for the segmentation task, an additional passive player in a form of segmentor is introduced into the the adversarial game. We validate the approach on two medical datasets: BraTS, ISIC. By controlling the class distribution through injection of synthetic images into the training set we achieve control over the accuracy levels of the datasets' classes.
A study on the Interpretability of Neural Retrieval Models using DeepSHAP
Jul 15, 2019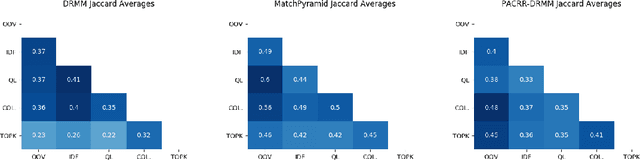
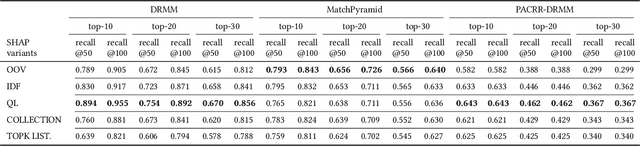
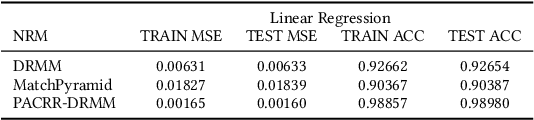
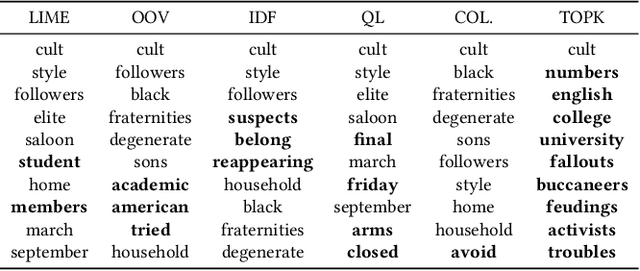
A recent trend in IR has been the usage of neural networks to learn retrieval models for text based adhoc search. While various approaches and architectures have yielded significantly better performance than traditional retrieval models such as BM25, it is still difficult to understand exactly why a document is relevant to a query. In the ML community several approaches for explaining decisions made by deep neural networks have been proposed -- including DeepSHAP which modifies the DeepLift algorithm to estimate the relative importance (shapley values) of input features for a given decision by comparing the activations in the network for a given image against the activations caused by a reference input. In image classification, the reference input tends to be a plain black image. While DeepSHAP has been well studied for image classification tasks, it remains to be seen how we can adapt it to explain the output of Neural Retrieval Models (NRMs). In particular, what is a good "black" image in the context of IR? In this paper we explored various reference input document construction techniques. Additionally, we compared the explanations generated by DeepSHAP to LIME (a model agnostic approach) and found that the explanations differ considerably. Our study raises concerns regarding the robustness and accuracy of explanations produced for NRMs. With this paper we aim to shed light on interesting problems surrounding interpretability in NRMs and highlight areas of future work.