 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Automated Labelling using an Attention model for Radiology reports of MRI scans (ALARM)
Feb 16, 2020
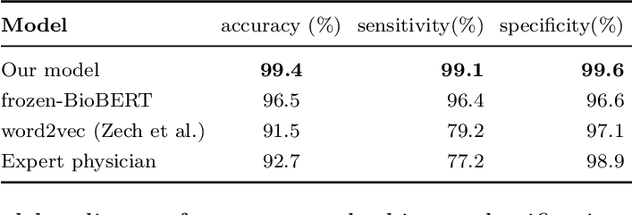


Labelling large datasets for training high-capacity neural networks is a major obstacle to the development of deep learning-based medical imaging applications. Here we present a transformer-based network for magnetic resonance imaging (MRI) radiology report classification which automates this task by assigning image labels on the basis of free-text expert radiology reports. Our model's performance is comparable to that of an expert radiologist, and better than that of an expert physician, demonstrating the feasibility of this approach. We make code available online for researchers to label their own MRI datasets for medical imaging applications.
Targeting SARS-CoV-2 with AI- and HPC-enabled Lead Generation: A First Data Release
May 28, 2020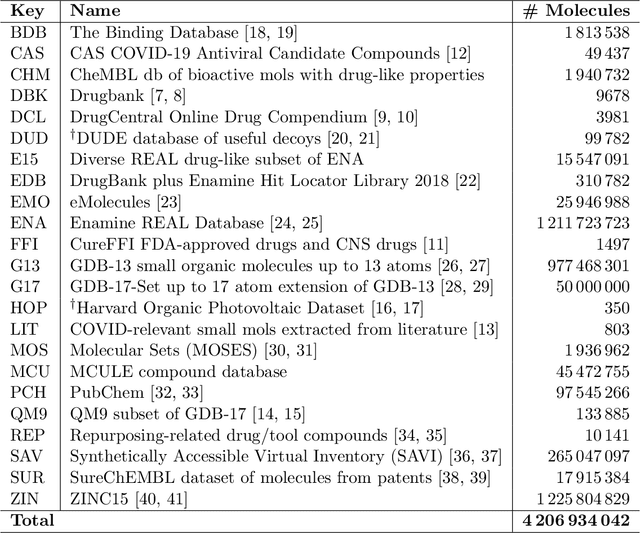
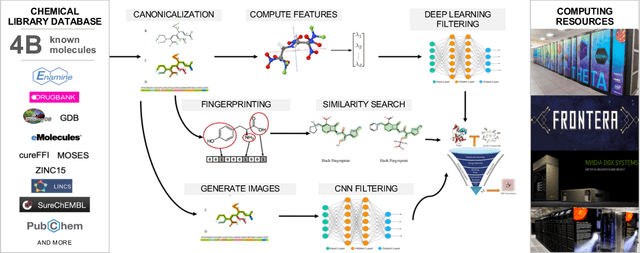

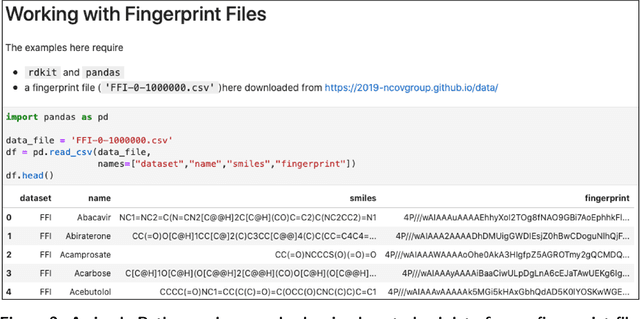
Researchers across the globe are seeking to rapidly repurpose existing drugs or discover new drugs to counter the the novel coronavirus disease (COVID-19) caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). One promising approach is to train machine learning (ML) and artificial intelligence (AI) tools to screen large numbers of small molecules. As a contribution to that effort, we are aggregating numerous small molecules from a variety of sources, using high-performance computing (HPC) to computer diverse properties of those molecules, using the computed properties to train ML/AI models, and then using the resulting models for screening. In this first data release, we make available 23 datasets collected from community sources representing over 4.2 B molecules enriched with pre-computed: 1) molecular fingerprints to aid similarity searches, 2) 2D images of molecules to enable exploration and application of image-based deep learning methods, and 3) 2D and 3D molecular descriptors to speed development of machine learning models. This data release encompasses structural information on the 4.2 B molecules and 60 TB of pre-computed data. Future releases will expand the data to include more detailed molecular simulations, computed models, and other products.
Semi-Supervised Adversarial Monocular Depth Estimation
Aug 06, 2019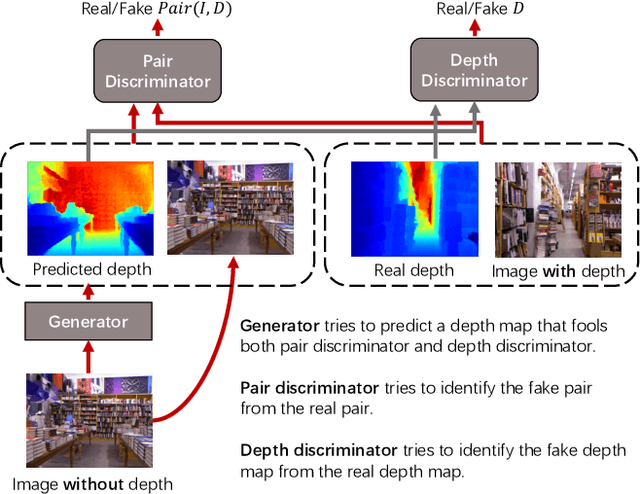
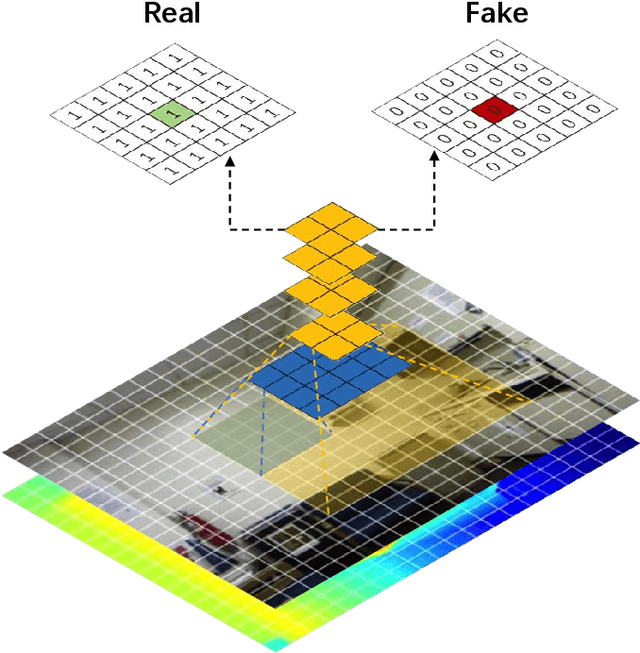
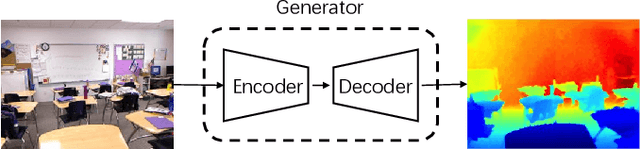
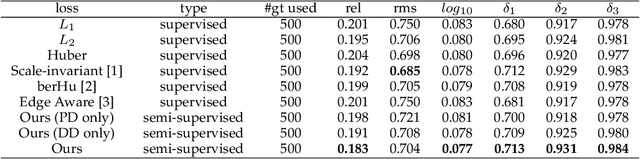
In this paper, we address the problem of monocular depth estimation when only a limited number of training image-depth pairs are available. To achieve a high regression accuracy, the state-of-the-art estimation methods rely on CNNs trained with a large number of image-depth pairs, which are prohibitively costly or even infeasible to acquire. Aiming to break the curse of such expensive data collections, we propose a semi-supervised adversarial learning framework that only utilizes a small number of image-depth pairs in conjunction with a large number of easily-available monocular images to achieve high performance. In particular, we use one generator to regress the depth and two discriminators to evaluate the predicted depth , i.e., one inspects the image-depth pair while the other inspects the depth channel alone. These two discriminators provide their feedbacks to the generator as the loss to generate more realistic and accurate depth predictions. Experiments show that the proposed approach can (1) improve most state-of-the-art models on the NYUD v2 dataset by effectively leveraging additional unlabeled data sources; (2) reach state-of-the-art accuracy when the training set is small, e.g., on the Make3D dataset; (3) adapt well to an unseen new dataset (Make3D in our case) after training on an annotated dataset (KITTI in our case).
Dynamic Sampling and Selective Masking for Communication-Efficient Federated Learning
Mar 21, 2020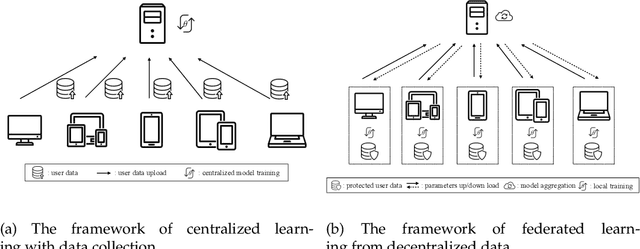

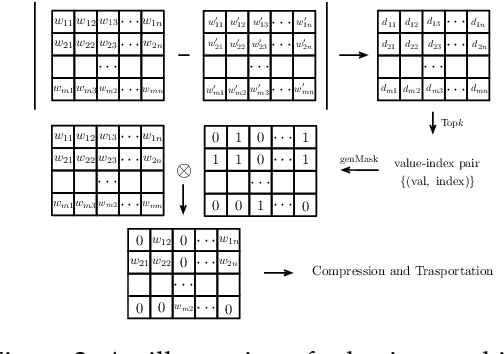
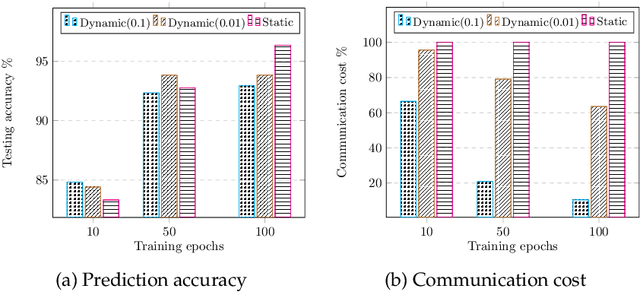
Federated learning (FL) is a novel machine learning setting which enables on-device intelligence via decentralized training and federated optimization. The rapid development of deep neural networks facilitates the learning techniques for modeling complex problems and emerges into federated deep learning under the federated setting. However, the tremendous amount of model parameters burdens the communication network with a high load of transportation. This paper introduces two approaches for improving communication efficiency by dynamic sampling and top-$k$ selective masking. The former controls the fraction of selected client models dynamically, while the latter selects parameters with top-$k$ largest values of difference for federated updating. Experiments on convolutional image classification and recurrent language modeling are conducted on three public datasets to show the effectiveness of our proposed methods.
Joint Bilateral Learning for Real-time Universal Photorealistic Style Transfer
Apr 27, 2020
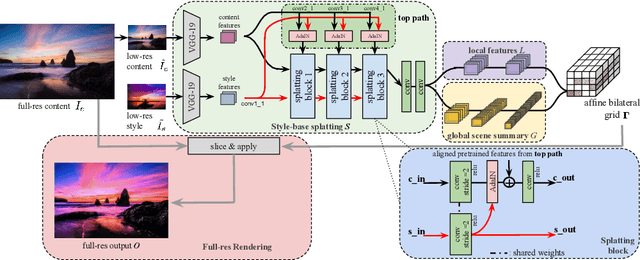


Photorealistic style transfer is the task of transferring the artistic style of an image onto a content target, producing a result that is plausibly taken with a camera. Recent approaches, based on deep neural networks, produce impressive results but are either too slow to run at practical resolutions, or still contain objectionable artifacts. We propose a new end-to-end model for photorealistic style transfer that is both fast and inherently generates photorealistic results. The core of our approach is a feed-forward neural network that learns local edge-aware affine transforms that automatically obey the photorealism constraint. When trained on a diverse set of images and a variety of styles, our model can robustly apply style transfer to an arbitrary pair of input images. Compared to the state of the art, our method produces visually superior results and is three orders of magnitude faster, enabling real-time performance at 4K on a mobile phone. We validate our method with ablation and user studies.
An Effective Image Feature Classiffication using an improved SOM
Jan 08, 2015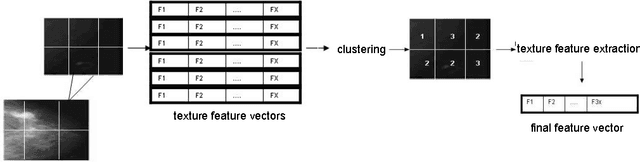
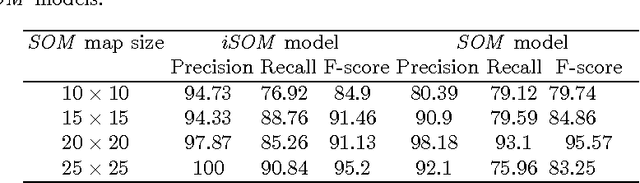
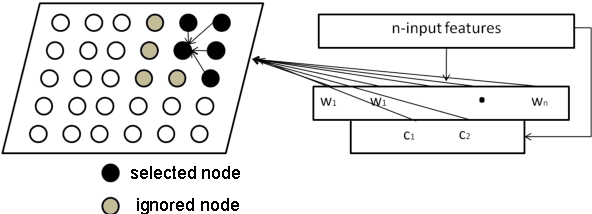
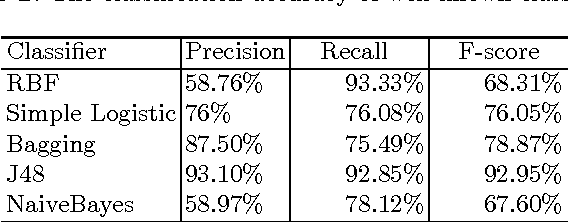
Image feature classification is a challenging problem in many computer vision applications, specifically, in the fields of remote sensing, image analysis and pattern recognition. In this paper, a novel Self Organizing Map, termed improved SOM (iSOM), is proposed with the aim of effectively classifying Mammographic images based on their texture feature representation. The main contribution of the iSOM is to introduce a new node structure for the map representation and adopting a learning technique based on Kohonen SOM accordingly. The main idea is to control, in an unsupervised fashion, the weight updating procedure depending on the class reliability of the node, during the weight update time. Experiments held on a real Mammographic images. Results showed high accuracy compared to classical SOM and other state-of-art classifiers.
Multiple resolution residual network for automatic thoracic organs-at-risk segmentation from CT
May 27, 2020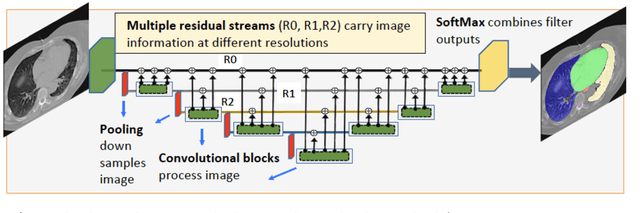
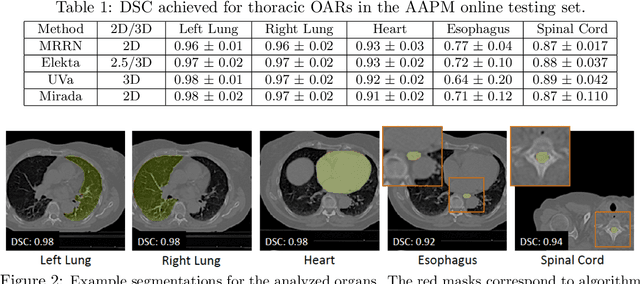
We implemented and evaluated a multiple resolution residual network (MRRN) for multiple normal organs-at-risk (OAR) segmentation from computed tomography (CT) images for thoracic radiotherapy treatment (RT) planning. Our approach simultaneously combines feature streams computed at multiple image resolutions and feature levels through residual connections. The feature streams at each level are updated as the images are passed through various feature levels. We trained our approach using 206 thoracic CT scans of lung cancer patients with 35 scans held out for validation to segment the left and right lungs, heart, esophagus, and spinal cord. This approach was tested on 60 CT scans from the open-source AAPM Thoracic Auto-Segmentation Challenge dataset. Performance was measured using the Dice Similarity Coefficient (DSC). Our approach outperformed the best-performing method in the grand challenge for hard-to-segment structures like the esophagus and achieved comparable results for all other structures. Median DSC using our method was 0.97 (interquartile range [IQR]: 0.97-0.98) for the left and right lungs, 0.93 (IQR: 0.93-0.95) for the heart, 0.78 (IQR: 0.76-0.80) for the esophagus, and 0.88 (IQR: 0.86-0.89) for the spinal cord.
Single-shot autofocusing of microscopy images using deep learning
Mar 21, 2020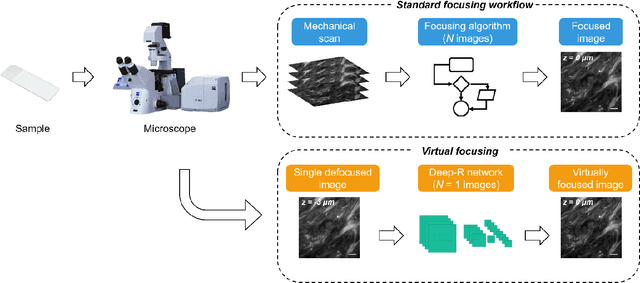
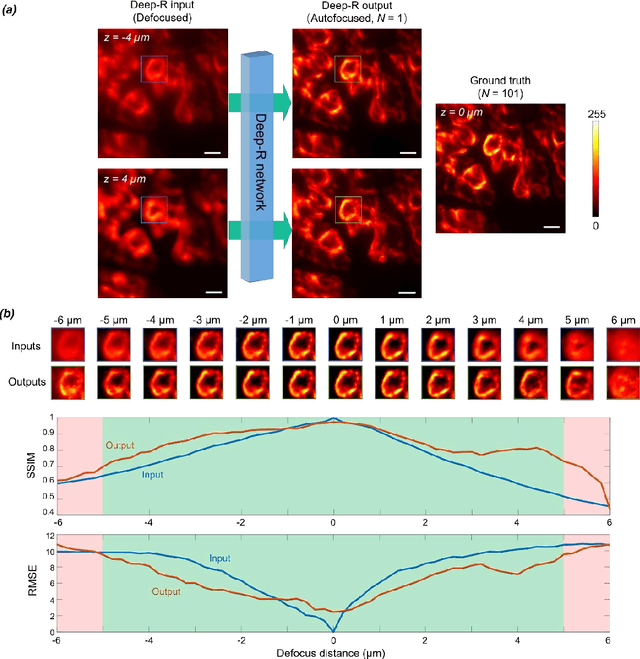
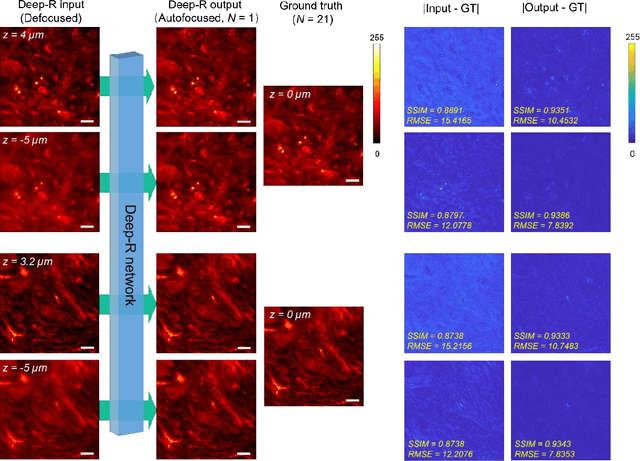
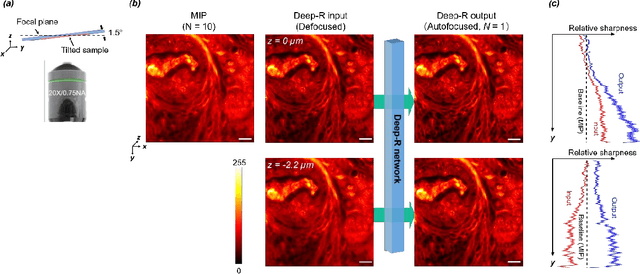
We demonstrate a deep learning-based offline autofocusing method, termed Deep-R, that is trained to rapidly and blindly autofocus a single-shot microscopy image of a specimen that is acquired at an arbitrary out-of-focus plane. We illustrate the efficacy of Deep-R using various tissue sections that were imaged using fluorescence and brightfield microscopy modalities and demonstrate snapshot autofocusing under different scenarios, such as a uniform axial defocus as well as a sample tilt within the field-of-view. Our results reveal that Deep-R is significantly faster when compared with standard online algorithmic autofocusing methods. This deep learning-based blind autofocusing framework opens up new opportunities for rapid microscopic imaging of large sample areas, also reducing the photon dose on the sample.
Self-supervised blur detection from synthetically blurred scenes
Aug 28, 2019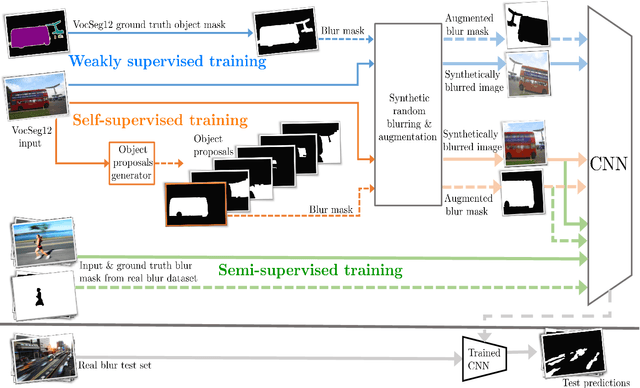
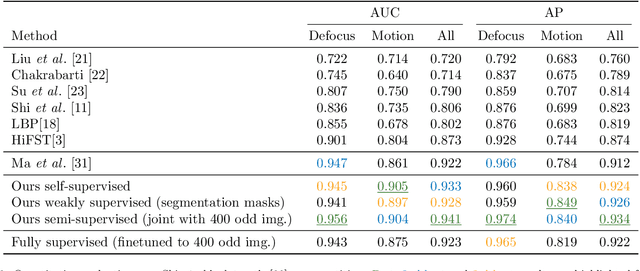
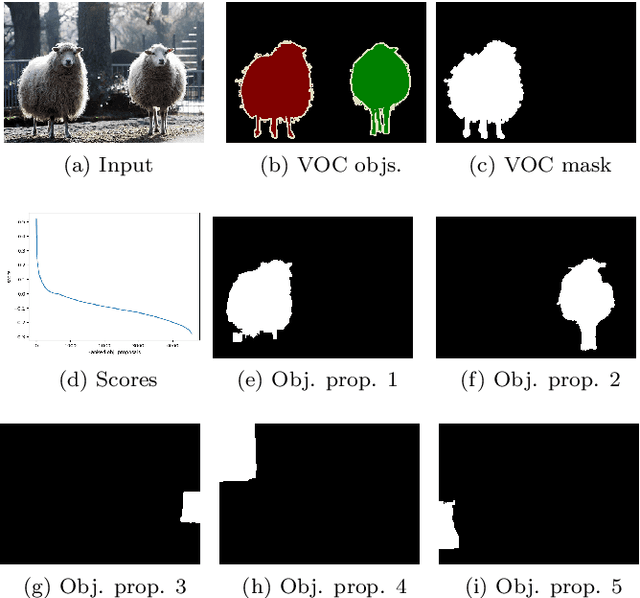
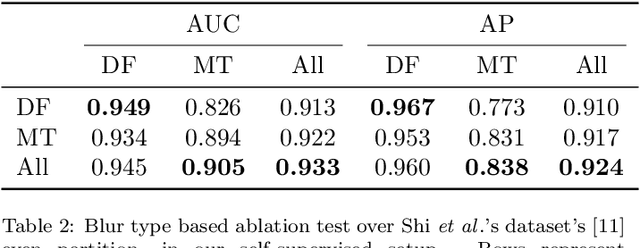
Blur detection aims at segmenting the blurred areas of a given image. Recent deep learning-based methods approach this problem by learning an end-to-end mapping between the blurred input and a binary mask representing the localization of its blurred areas. Nevertheless, the effectiveness of such deep models is limited due to the scarcity of datasets annotated in terms of blur segmentation, as blur annotation is labour intensive. In this work, we bypass the need for such annotated datasets for end-to-end learning, and instead rely on object proposals and a model for blur generation in order to produce a dataset of synthetically blurred images. This allows us to perform self-supervised learning over the generated image and ground truth blur mask pairs using CNNs, defining a framework that can be employed in purely self-supervised, weakly supervised or semi-supervised configurations. Interestingly, experimental results of such setups over the largest blur segmentation datasets available show that this approach achieves state of the art results in blur segmentation, even without ever observing any real blurred image.
In-Vehicle Object Detection in the Wild for Driverless Vehicles
Apr 27, 2020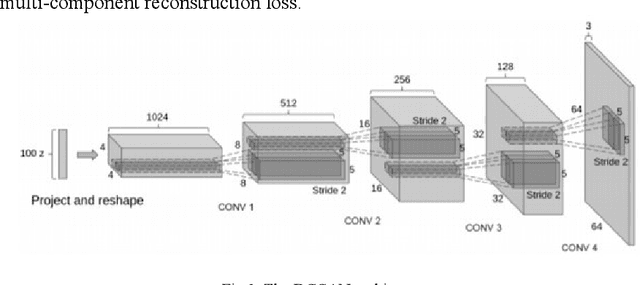
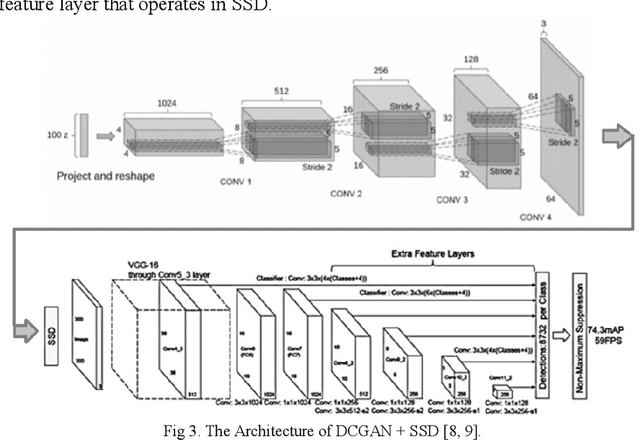
In-vehicle human object identification plays an important role in vision-based automated vehicle driving systems while objects such as pedestrians and vehicles on roads or streets are the primary targets to protect from driverless vehicles. A challenge is the difficulty to detect objects in moving under the wild conditions, while illumination and image quality could drastically vary. In this work, to address this challenge, we exploit Deep Convolutional Generative Adversarial Networks (DCGANs) with Single Shot Detector (SSD) to handle with the wild conditions. In our work, a GAN was trained with low-quality images to handle with the challenges arising from the wild conditions in smart cities, while a cascaded SSD is employed as the object detector to perform with the GAN. We used tested our approach under wild conditions using taxi driver videos on London street in both daylight and night times, and the tests from in-vehicle videos demonstrate that this strategy can drastically achieve a better detection rate under the wild conditions.
* the 14th International FLINS Conference on Robotics and Artificial Intelligence