 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Transfer Convolutional Neural Network and Extreme Learning Machine for Lung Nodule Diagnosis on CT images
Jan 05, 2020
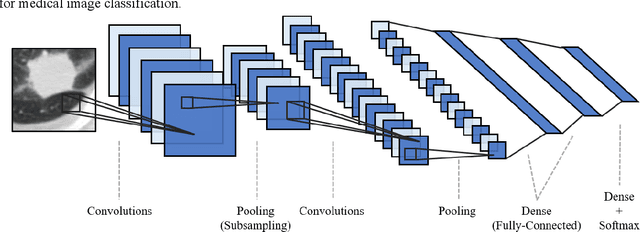
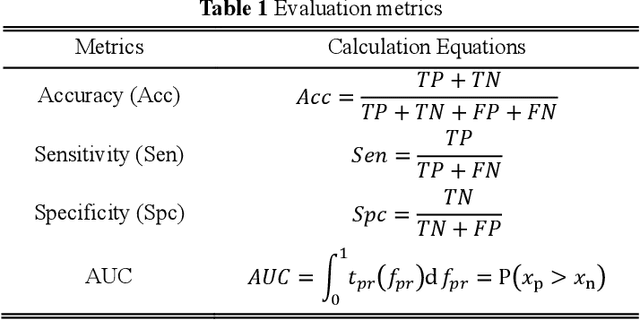
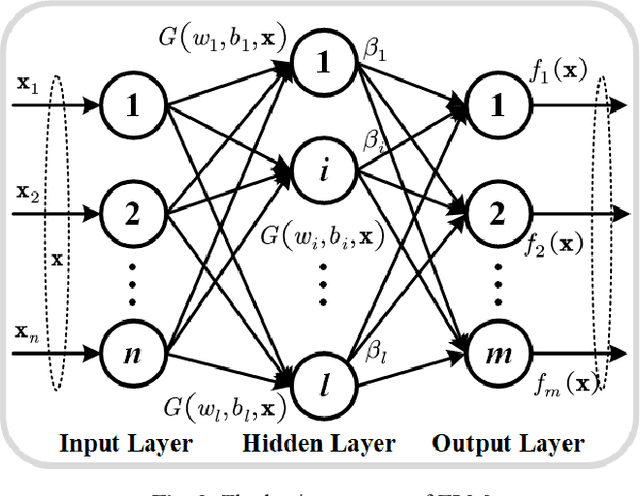
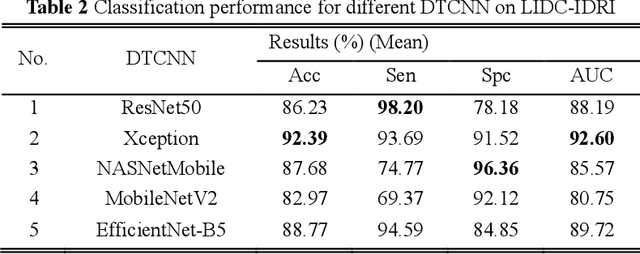
Diagnosis of benign-malignant nodules in the lung on Computed Tomography (CT) images is critical for determining tumor level and reducing patient mortality. Deep learning-based diagnosis of nodules in lung CT images, however, is time-consuming and less accurate due to redundant structure and the lack of adequate training data. In this paper, a novel diagnosis method based on Deep Transfer Convolutional Neural Network (DTCNN) and Extreme Learning Machine (ELM) is explored, which merges the synergy of two algorithms to deal with benign-malignant nodules classification. An optimal DTCNN is first adopted to extract high level features of lung nodules, which has been trained with the ImageNet dataset beforehand. After that, an ELM classifier is further developed to classify benign and malignant lung nodules. Two datasets, including the Lung Image Database Consortium and Image Database Resource Initiative (LIDC-IDRI) public dataset and a private dataset from the First Affiliated Hospital of Guangzhou Medical University in China (FAH-GMU), have been conducted to verify the efficiency and effectiveness of the proposed approach. The experimental results show that our novel DTCNN-ELM model provides the most reliable results compared with current state-of-the-art methods.
Defending against adversarial attacks on medical imaging AI system, classification or detection?
Jun 24, 2020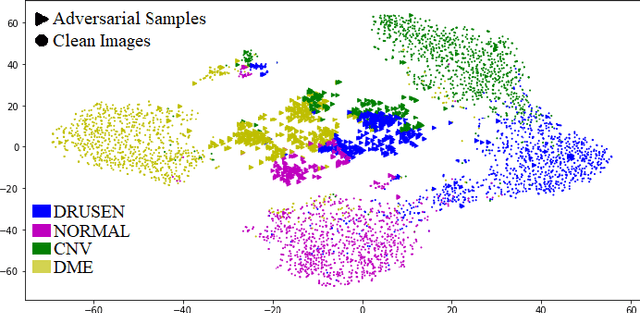
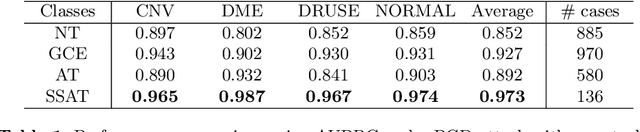
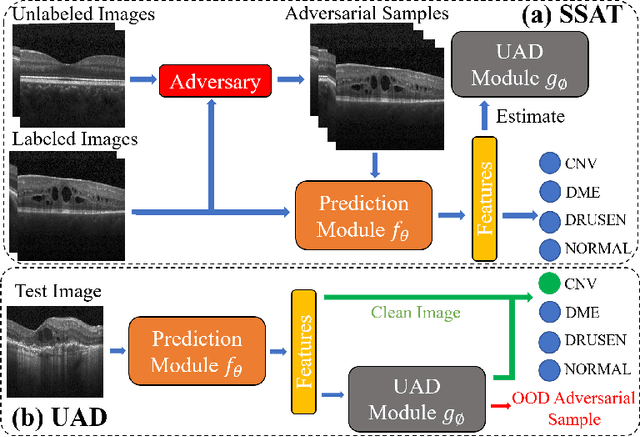

Medical imaging AI systems such as disease classification and segmentation are increasingly inspired and transformed from computer vision based AI systems. Although an array of adversarial training and/or loss function based defense techniques have been developed and proved to be effective in computer vision, defending against adversarial attacks on medical images remains largely an uncharted territory due to the following unique challenges: 1) label scarcity in medical images significantly limits adversarial generalizability of the AI system; 2) vastly similar and dominant fore- and background in medical images make it hard samples for learning the discriminating features between different disease classes; and 3) crafted adversarial noises added to the entire medical image as opposed to the focused organ target can make clean and adversarial examples more discriminate than that between different disease classes. In this paper, we propose a novel robust medical imaging AI framework based on Semi-Supervised Adversarial Training (SSAT) and Unsupervised Adversarial Detection (UAD), followed by designing a new measure for assessing systems adversarial risk. We systematically demonstrate the advantages of our robust medical imaging AI system over the existing adversarial defense techniques under diverse real-world settings of adversarial attacks using a benchmark OCT imaging data set.
Explaining Neural Networks by Decoding Layer Activations
May 27, 2020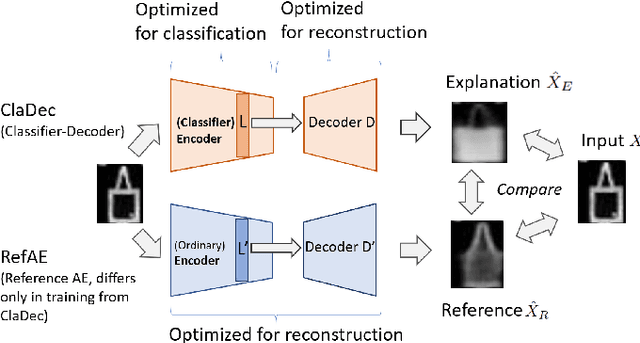
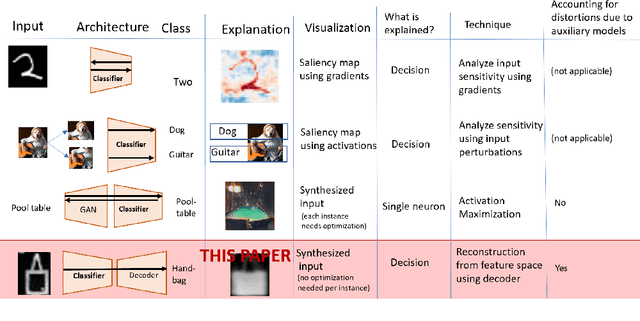
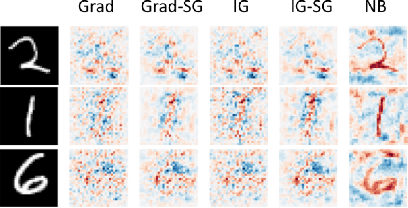
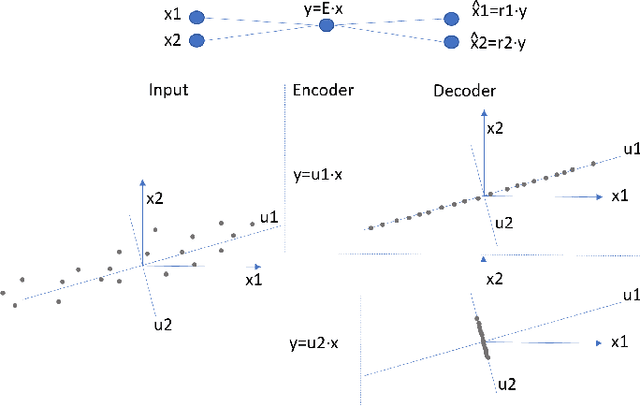
To derive explanations for deep learning models, ie. classifiers, we propose a `CLAssifier-DECoder' architecture (\emph{ClaDec}). \emph{ClaDec} allows to explain the output of an arbitrary layer. To this end, it uses a decoder that transforms the non-interpretable representation of the given layer to a representation that is more similar to training data. One can recognize what information a layer maintains by contrasting reconstructed images of \emph{ClaDec} with those of a conventional auto-encoder(AE) serving as reference. Our extended version also allows to trade human interpretability and fidelity to customize explanations to individual needs. We evaluate our approach for image classification using CNNs. In alignment with our theoretical motivation, the qualitative evaluation highlights that reconstructed images (of the network to be explained) tend to replace specific objects with more generic object templates and provide smoother reconstructions. We also show quantitatively that reconstructed visualizations using encodings from a classifier do capture more relevant information for classification than conventional AEs despite the fact that the latter contain more information on the original input.
Unblind Your Apps: Predicting Natural-Language Labels for Mobile GUI Components by Deep Learning
Mar 01, 2020

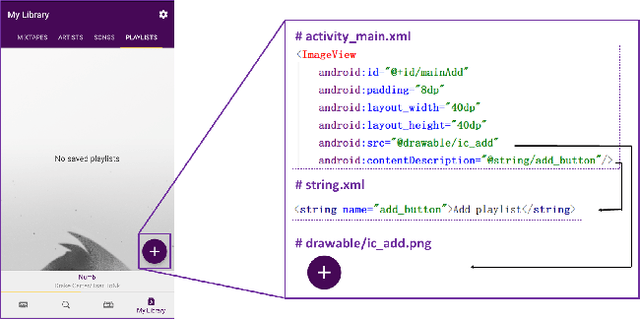
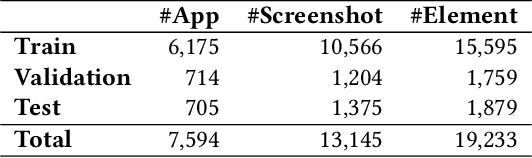
According to the World Health Organization(WHO), it is estimated that approximately 1.3 billion people live with some forms of vision impairment globally, of whom 36 million are blind. Due to their disability, engaging these minority into the society is a challenging problem. The recent rise of smart mobile phones provides a new solution by enabling blind users' convenient access to the information and service for understanding the world. Users with vision impairment can adopt the screen reader embedded in the mobile operating systems to read the content of each screen within the app, and use gestures to interact with the phone. However, the prerequisite of using screen readers is that developers have to add natural-language labels to the image-based components when they are developing the app. Unfortunately, more than 77% apps have issues of missing labels, according to our analysis of 10,408 Android apps. Most of these issues are caused by developers' lack of awareness and knowledge in considering the minority. And even if developers want to add the labels to UI components, they may not come up with concise and clear description as most of them are of no visual issues. To overcome these challenges, we develop a deep-learning based model, called LabelDroid, to automatically predict the labels of image-based buttons by learning from large-scale commercial apps in Google Play. The experimental results show that our model can make accurate predictions and the generated labels are of higher quality than that from real Android developers.
UprightNet: Geometry-Aware Camera Orientation Estimation from Single Images
Aug 19, 2019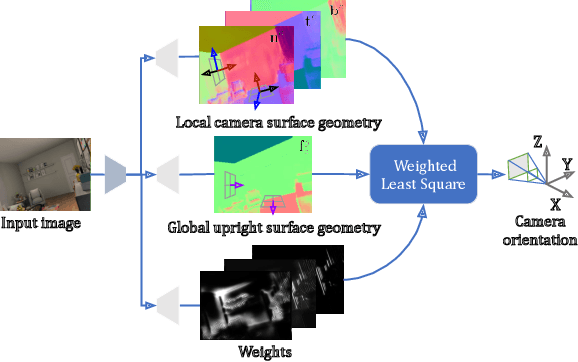
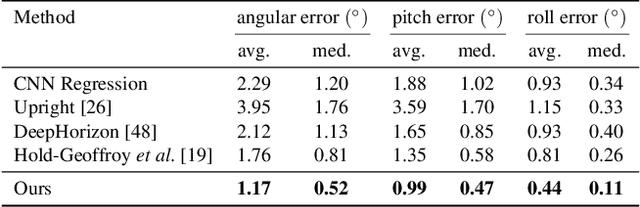
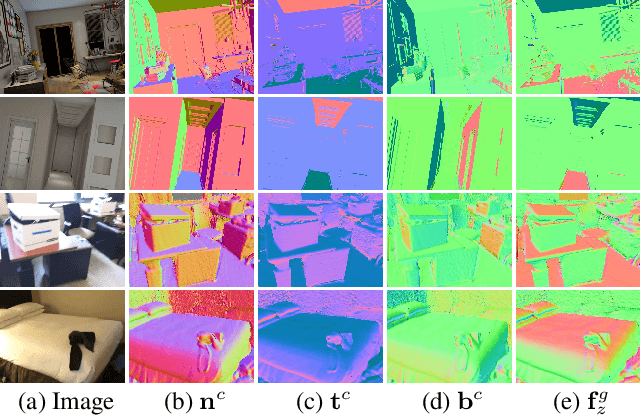
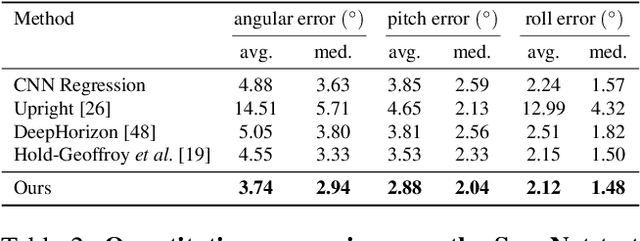
We introduce UprightNet, a learning-based approach for estimating 2DoF camera orientation from a single RGB image of an indoor scene. Unlike recent methods that leverage deep learning to perform black-box regression from image to orientation parameters, we propose an end-to-end framework that incorporates explicit geometric reasoning. In particular, we design a network that predicts two representations of scene geometry, in both the local camera and global reference coordinate systems, and solves for the camera orientation as the rotation that best aligns these two predictions via a differentiable least squares module. This network can be trained end-to-end, and can be supervised with both ground truth camera poses and intermediate representations of surface geometry. We evaluate UprightNet on the single-image camera orientation task on synthetic and real datasets, and show significant improvements over prior state-of-the-art approaches.
Sequential Latent Spaces for Modeling the Intention During Diverse Image Captioning
Aug 22, 2019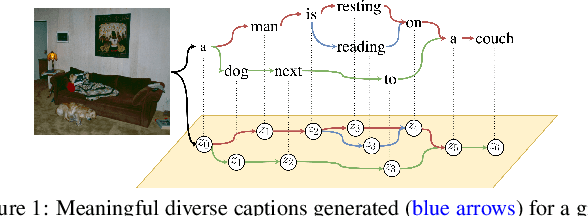
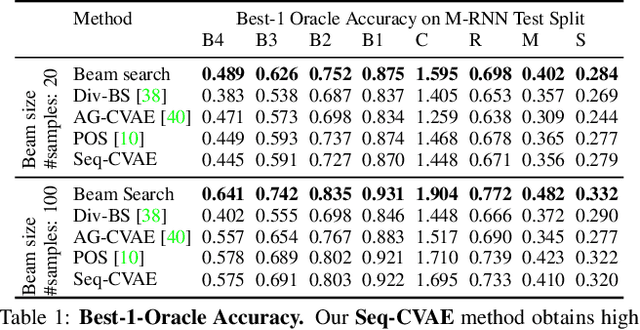
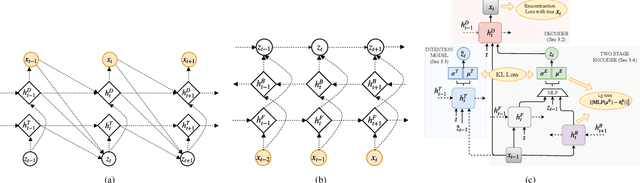
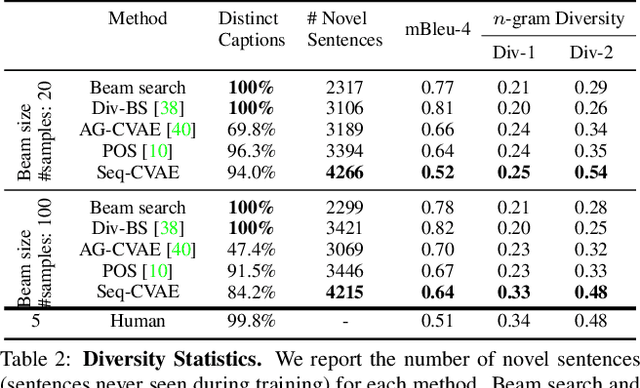
Diverse and accurate vision+language modeling is an important goal to retain creative freedom and maintain user engagement. However, adequately capturing the intricacies of diversity in language models is challenging. Recent works commonly resort to latent variable models augmented with more or less supervision from object detectors or part-of-speech tags. Common to all those methods is the fact that the latent variable either only initializes the sentence generation process or is identical across the steps of generation. Both methods offer no fine-grained control. To address this concern, we propose Seq-CVAE which learns a latent space for every word position. We encourage this temporal latent space to capture the 'intention' about how to complete the sentence by mimicking a representation which summarizes the future. We illustrate the efficacy of the proposed approach to anticipate the sentence continuation on the challenging MSCOCO dataset, significantly improving diversity metrics compared to baselines while performing on par w.r.t sentence quality.
LocoGAN -- Locally Convolutional GAN
Feb 18, 2020


In the paper we construct a fully convolutional GAN model: LocoGAN, which latent space is given by noise-like images of possibly different resolutions. The learning is local, i.e. we process not the whole noise-like image, but the sub-images of a fixed size. As a consequence LocoGAN can produce images of arbitrary dimensions e.g. LSUN bedroom data set. Another advantage of our approach comes from the fact that we use the position channels, which allows the generation of fully periodic (e.g. cylindrical panoramic images) or almost periodic ,,infinitely long" images (e.g. wall-papers).
Accelerating Neural Network Inference by Overflow Aware Quantization
May 27, 2020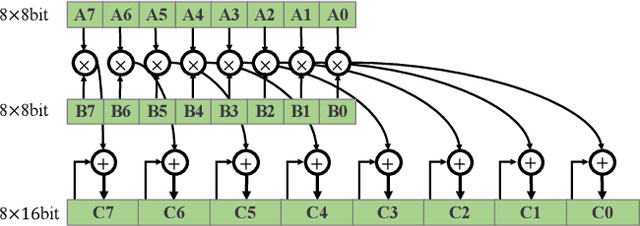
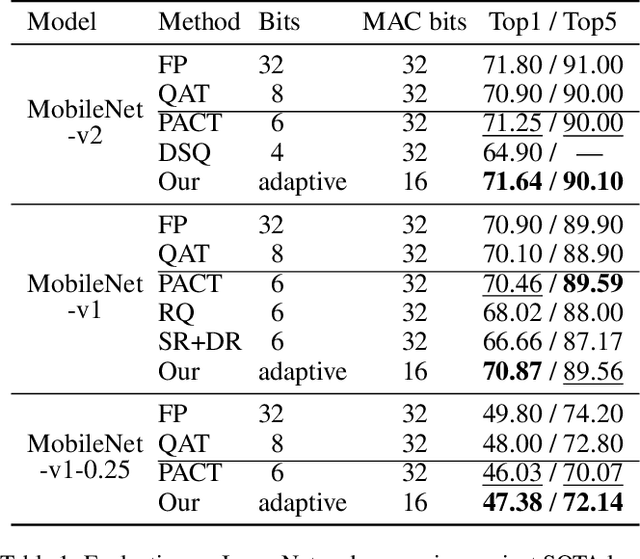
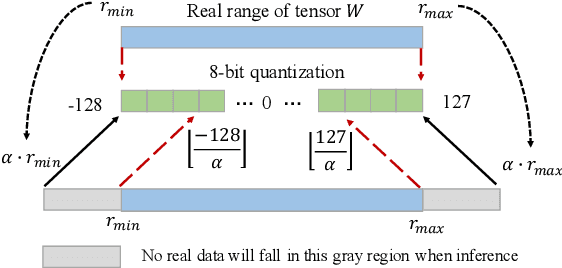
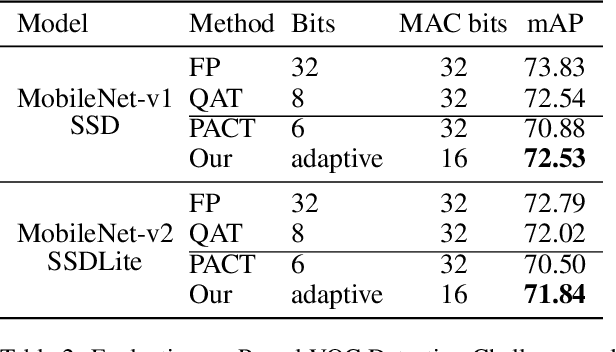
The inherent heavy computation of deep neural networks prevents their widespread applications. A widely used method for accelerating model inference is quantization, by replacing the input operands of a network using fixed-point values. Then the majority of computation costs focus on the integer matrix multiplication accumulation. In fact, high-bit accumulator leads to partially wasted computation and low-bit one typically suffers from numerical overflow. To address this problem, we propose an overflow aware quantization method by designing trainable adaptive fixed-point representation, to optimize the number of bits for each input tensor while prohibiting numeric overflow during the computation. With the proposed method, we are able to fully utilize the computing power to minimize the quantization loss and obtain optimized inference performance. To verify the effectiveness of our method, we conduct image classification, object detection, and semantic segmentation tasks on ImageNet, Pascal VOC, and COCO datasets, respectively. Experimental results demonstrate that the proposed method can achieve comparable performance with state-of-the-art quantization methods while accelerating the inference process by about 2 times.
Rapid Damage Assessment Using Social Media Images by Combining Human and Machine Intelligence
Apr 14, 2020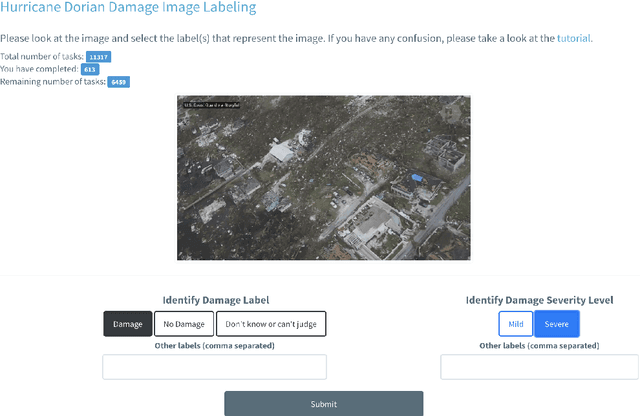


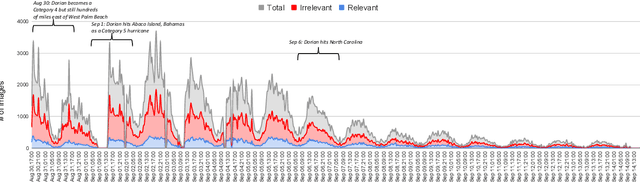
Rapid damage assessment is one of the core tasks that response organizations perform at the onset of a disaster to understand the scale of damage to infrastructures such as roads, bridges, and buildings. This work analyzes the usefulness of social media imagery content to perform rapid damage assessment during a real-world disaster. An automatic image processing system, which was activated in collaboration with a volunteer response organization, processed ~280K images to understand the extent of damage caused by the disaster. The system achieved an accuracy of 76% computed based on the feedback received from the domain experts who analyzed ~29K system-processed images during the disaster. An extensive error analysis reveals several insights and challenges faced by the system, which are vital for the research community to advance this line of research.
On the Benefit of Adversarial Training for Monocular Depth Estimation
Oct 29, 2019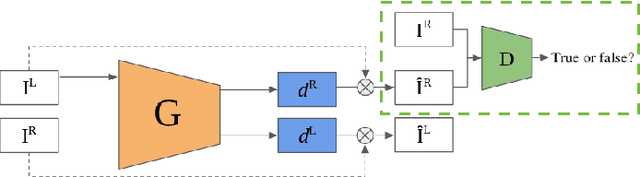
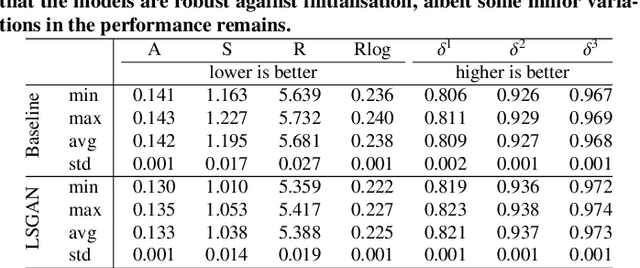
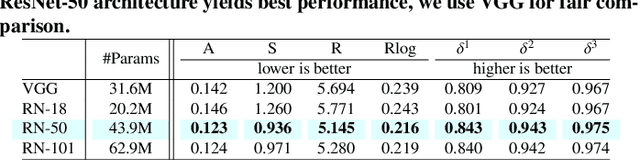
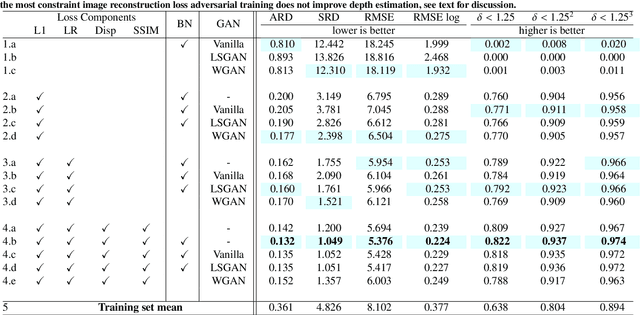
In this paper we address the benefit of adding adversarial training to the task of monocular depth estimation. A model can be trained in a self-supervised setting on stereo pairs of images, where depth (disparities) are an intermediate result in a right-to-left image reconstruction pipeline. For the quality of the image reconstruction and disparity prediction, a combination of different losses is used, including L1 image reconstruction losses and left-right disparity smoothness. These are local pixel-wise losses, while depth prediction requires global consistency. Therefore, we extend the self-supervised network to become a Generative Adversarial Network (GAN), by including a discriminator which should tell apart reconstructed (fake) images from real images. We evaluate Vanilla GANs, LSGANs and Wasserstein GANs in combination with different pixel-wise reconstruction losses. Based on extensive experimental evaluation, we conclude that adversarial training is beneficial if and only if the reconstruction loss is not too constrained. Even though adversarial training seems promising because it promotes global consistency, non-adversarial training outperforms (or is on par with) any method trained with a GAN when a constrained reconstruction loss is used in combination with batch normalisation. Based on the insights of our experimental evaluation we obtain state-of-the art monocular depth estimation results by using batch normalisation and different output scales.