 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SeqDialN: Sequential Visual Dialog Networks in Joint Visual-Linguistic Representation Space
Aug 02, 2020
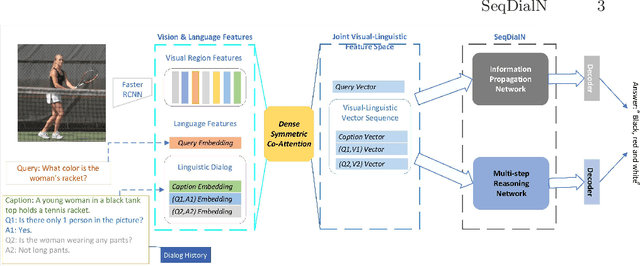

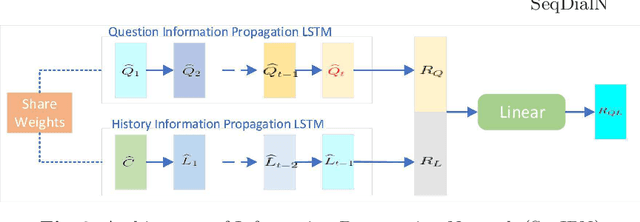
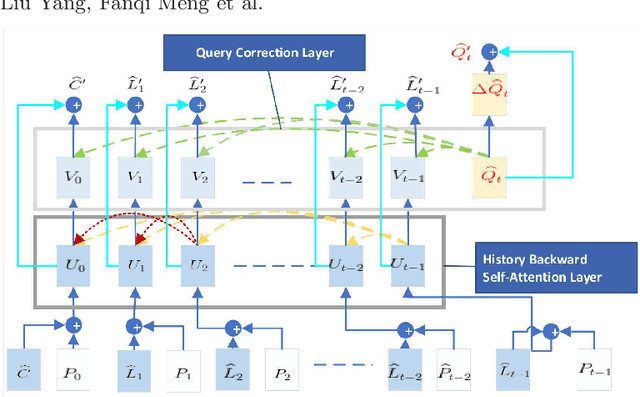
In this work, we formulate a visual dialog as an information flow in which each piece of information is encoded with the joint visual-linguistic representation of a single dialog round. Based on this formulation, we consider the visual dialog task as a sequence problem consisting of ordered visual-linguistic vectors. For featurization, we use a Dense Symmetric Co-Attention network as a lightweight vison-language joint representation generator to fuse multimodal features (i.e., image and text), yielding better computation and data efficiencies. For inference, we propose two Sequential Dialog Networks (SeqDialN): the first uses LSTM for information propagation (IP) and the second uses a modified Transformer for multi-step reasoning (MR). Our architecture separates the complexity of multimodal feature fusion from that of inference, which allows simpler design of the inference engine. IP based SeqDialN is our baseline with a simple 2-layer LSTM design that achieves decent performance. MR based SeqDialN, on the other hand, recurrently refines the semantic question/history representations through the self-attention stack of Transformer and produces promising results on the visual dialog task. On VisDial v1.0 test-std dataset, our best single generative SeqDialN achieves 62.54% NDCG and 48.63% MRR; our ensemble generative SeqDialN achieves 63.78% NDCG and 49.98% MRR, which set a new state-of-the-art generative visual dialog model. We fine-tune discriminative SeqDialN with dense annotations and boost the performance up to 72.41% NDCG and 55.11% MRR. In this work, we discuss the extensive experiments we have conducted to demonstrate the effectiveness of our model components. We also provide visualization for the reasoning process from the relevant conversation rounds and discuss our fine-tuning methods. Our code is available at https://github.com/xiaoxiaoheimei/SeqDialN
Structured GANs
Jan 15, 2020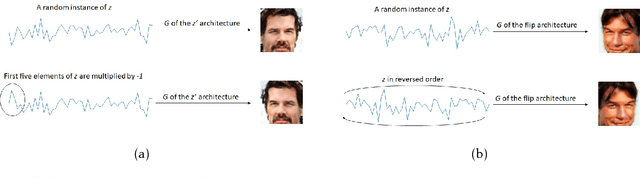

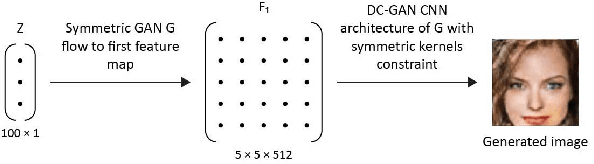
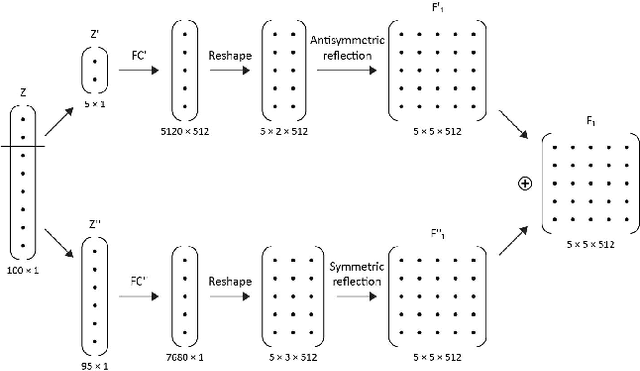
We present Generative Adversarial Networks (GANs), in which the symmetric property of the generated images is controlled. This is obtained through the generator network's architecture, while the training procedure and the loss remain the same. The symmetric GANs are applied to face image synthesis in order to generate novel faces with a varying amount of symmetry. We also present an unsupervised face rotation capability, which is based on the novel notion of one-shot fine tuning.
Multivariate Confidence Calibration for Object Detection
Apr 28, 2020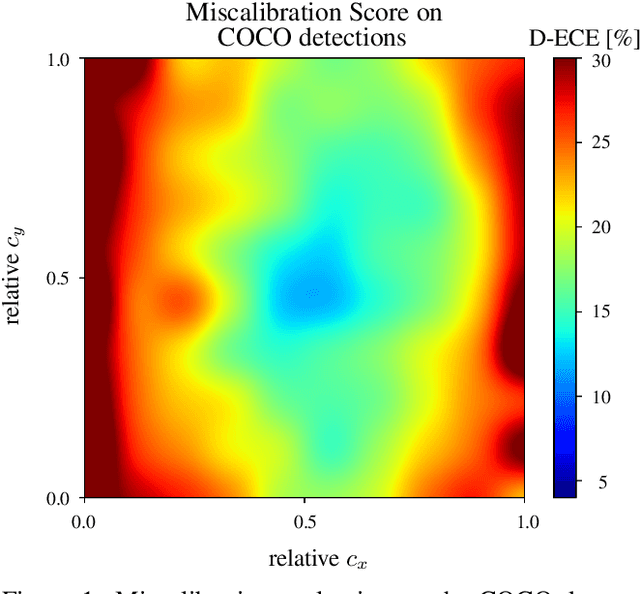
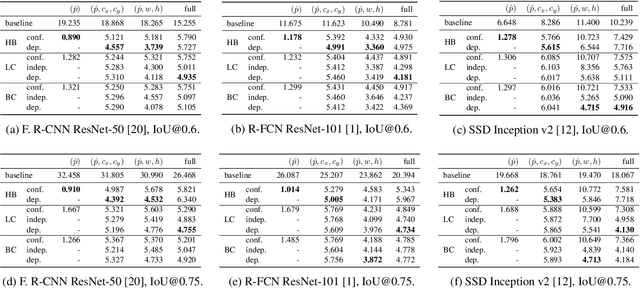

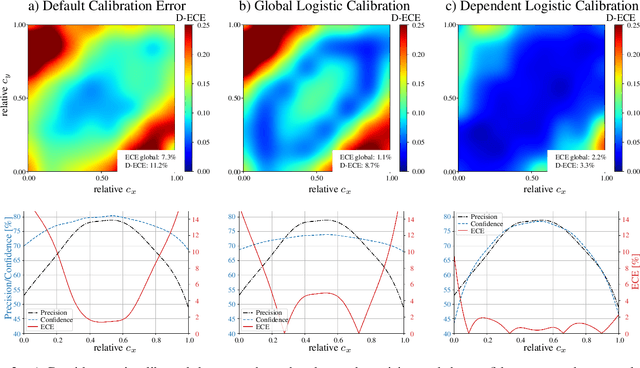
Unbiased confidence estimates of neural networks are crucial especially for safety-critical applications. Many methods have been developed to calibrate biased confidence estimates. Though there is a variety of methods for classification, the field of object detection has not been addressed yet. Therefore, we present a novel framework to measure and calibrate biased (or miscalibrated) confidence estimates of object detection methods. The main difference to related work in the field of classifier calibration is that we also use additional information of the regression output of an object detector for calibration. Our approach allows, for the first time, to obtain calibrated confidence estimates with respect to image location and box scale. In addition, we propose a new measure to evaluate miscalibration of object detectors. Finally, we show that our developed methods outperform state-of-the-art calibration models for the task of object detection and provides reliable confidence estimates across different locations and scales.
A Deep Cascade of Convolutional Neural Networks for MR Image Reconstruction
Mar 01, 2017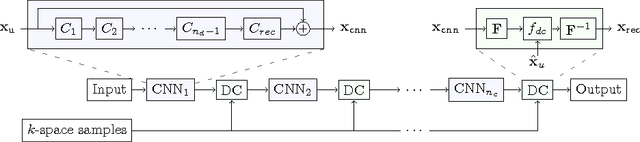


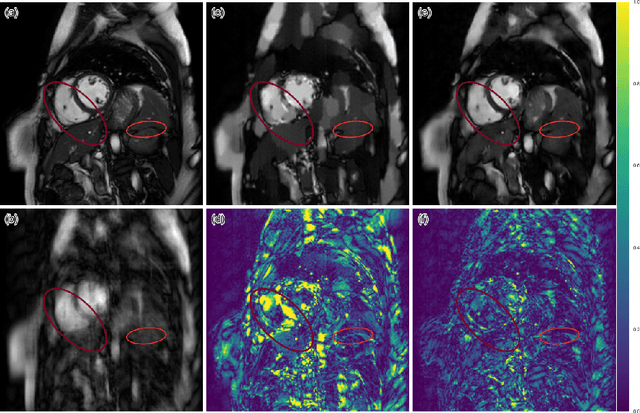
The acquisition of Magnetic Resonance Imaging (MRI) is inherently slow. Inspired by recent advances in deep learning, we propose a framework for reconstructing MR images from undersampled data using a deep cascade of convolutional neural networks to accelerate the data acquisition process. We show that for Cartesian undersampling of 2D cardiac MR images, the proposed method outperforms the state-of-the-art compressed sensing approaches, such as dictionary learning-based MRI (DLMRI) reconstruction, in terms of reconstruction error, perceptual quality and reconstruction speed for both 3-fold and 6-fold undersampling. Compared to DLMRI, the error produced by the method proposed is approximately twice as small, allowing to preserve anatomical structures more faithfully. Using our method, each image can be reconstructed in 23 ms, which is fast enough to enable real-time applications.
Countering Inconsistent Labelling by Google's Vision API for Rotated Images
Nov 17, 2019

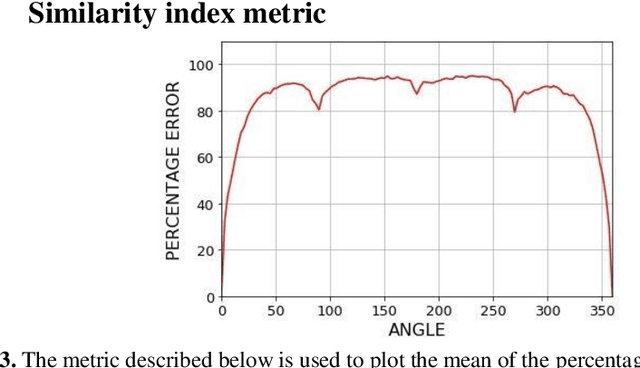
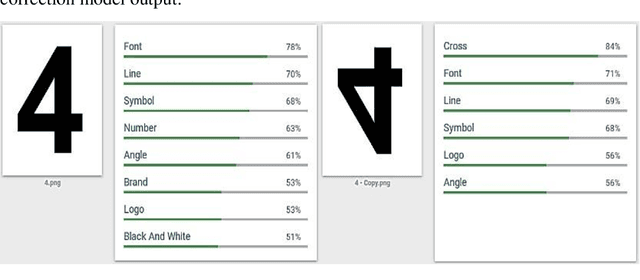
Google's Vision API analyses images and provides a variety of output predictions, one such type is context-based labelling. In this paper, it is shown that adversarial examples that cause incorrect label prediction and spoofing can be generated by rotating the images. Due to the black-boxed nature of the API, a modular context-based pre-processing pipeline is proposed consisting of a Res-Net50 model, that predicts the angle by which the image must be rotated to correct its orientation. The pipeline successfully performs the correction whilst maintaining the image's resolution and feeds it to the API which generates labels similar to the original correctly oriented image and using a Percentage Error metric, the performance of the corrected images as compared to its rotated counter-parts is found to be significantly higher. These observations imply that the API can benefit from such a pre-processing pipeline to increase robustness to rotational perturbances.
Post-hoc Calibration of Neural Networks
Jun 23, 2020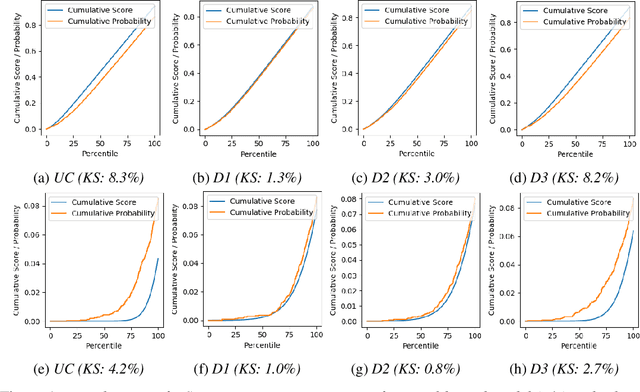

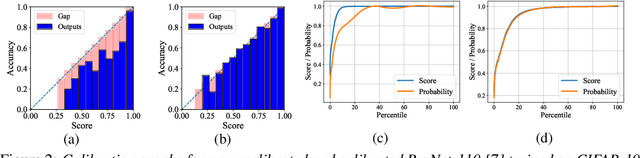
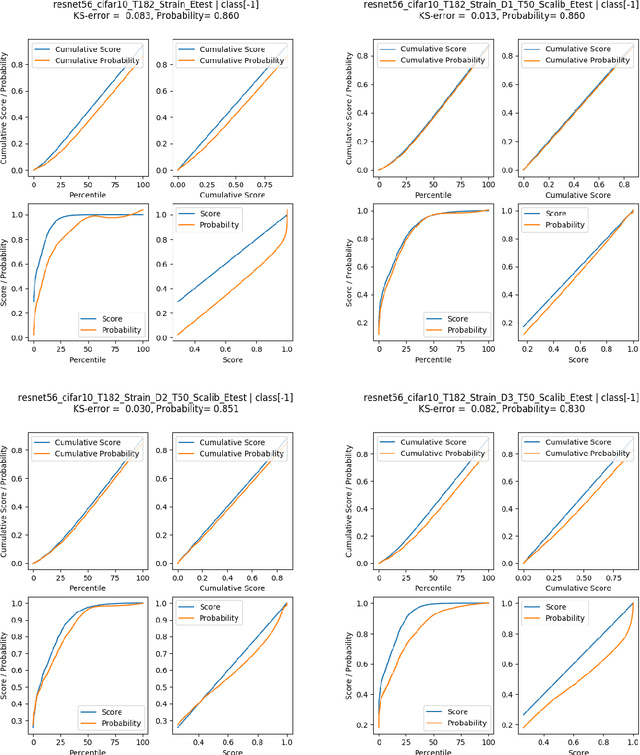
Calibration of neural networks is a critical aspect to consider when incorporating machine learning models in real-world decision-making systems where the confidence of decisions are equally important as the decisions themselves. In recent years, there is a surge of research on neural network calibration and the majority of the works can be categorized into post-hoc calibration methods, defined as methods that learn an additional function to calibrate an already trained base network. In this work, we intend to understand the post-hoc calibration methods from a theoretical point of view. Especially, it is known that minimizing Negative Log-Likelihood (NLL) will lead to a calibrated network on the training set if the global optimum is attained (Bishop, 1994). Nevertheless, it is not clear learning an additional function in a post-hoc manner would lead to calibration in the theoretical sense. To this end, we prove that even though the base network ($f$) does not lead to the global optimum of NLL, by adding additional layers ($g$) and minimizing NLL by optimizing the parameters of $g$ one can obtain a calibrated network $g \circ f$. This not only provides a less stringent condition to obtain a calibrated network but also provides a theoretical justification of post-hoc calibration methods. Our experiments on various image classification benchmarks confirm the theory.
Transposer: Universal Texture Synthesis Using Feature Maps as Transposed Convolution Filter
Jul 14, 2020
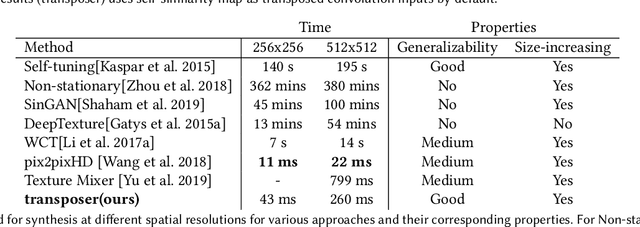

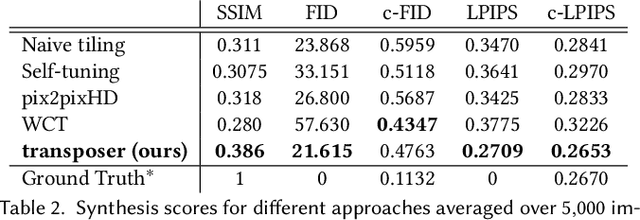
Conventional CNNs for texture synthesis consist of a sequence of (de)-convolution and up/down-sampling layers, where each layer operates locally and lacks the ability to capture the long-term structural dependency required by texture synthesis. Thus, they often simply enlarge the input texture, rather than perform reasonable synthesis. As a compromise, many recent methods sacrifice generalizability by training and testing on the same single (or fixed set of) texture image(s), resulting in huge re-training time costs for unseen images. In this work, based on the discovery that the assembling/stitching operation in traditional texture synthesis is analogous to a transposed convolution operation, we propose a novel way of using transposed convolution operation. Specifically, we directly treat the whole encoded feature map of the input texture as transposed convolution filters and the features' self-similarity map, which captures the auto-correlation information, as input to the transposed convolution. Such a design allows our framework, once trained, to be generalizable to perform synthesis of unseen textures with a single forward pass in nearly real-time. Our method achieves state-of-the-art texture synthesis quality based on various metrics. While self-similarity helps preserve the input textures' regular structural patterns, our framework can also take random noise maps for irregular input textures instead of self-similarity maps as transposed convolution inputs. It allows to get more diverse results as well as generate arbitrarily large texture outputs by directly sampling large noise maps in a single pass as well.
Generating Semantic Adversarial Examples via Feature Manipulation
Jan 06, 2020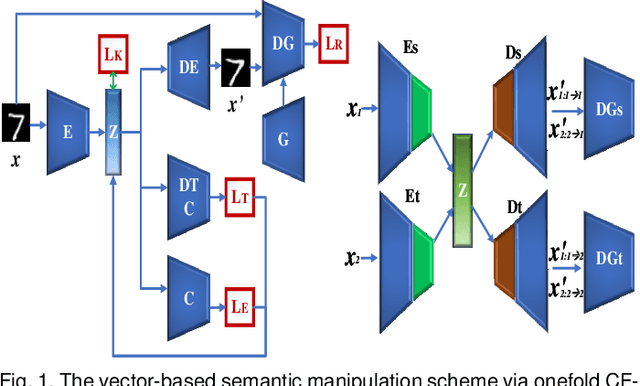
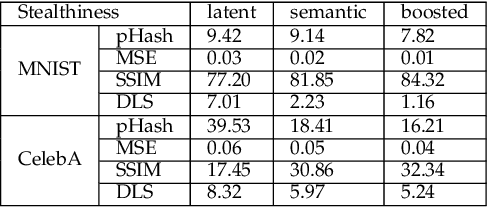
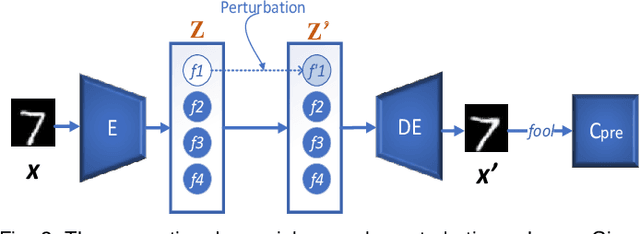
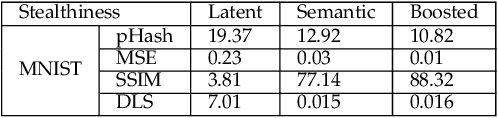
The vulnerability of deep neural networks to adversarial attacks has been widely demonstrated (e.g., adversarial example attacks). Traditional attacks perform unstructured pixel-wise perturbation to fool the classifier. An alternative approach is to have perturbations in the latent space. However, such perturbations are hard to control due to the lack of interpretability and disentanglement. In this paper, we propose a more practical adversarial attack by designing structured perturbation with semantic meanings. Our proposed technique manipulates the semantic attributes of images via the disentangled latent codes. The intuition behind our technique is that images in similar domains have some commonly shared but theme-independent semantic attributes, e.g. thickness of lines in handwritten digits, that can be bidirectionally mapped to disentangled latent codes. We generate adversarial perturbation by manipulating a single or a combination of these latent codes and propose two unsupervised semantic manipulation approaches: vector-based disentangled representation and feature map-based disentangled representation, in terms of the complexity of the latent codes and smoothness of the reconstructed images. We conduct extensive experimental evaluations on real-world image data to demonstrate the power of our attacks for black-box classifiers. We further demonstrate the existence of a universal, image-agnostic semantic adversarial example.
End-to-end Learning Improves Static Object Geo-localization in Monocular Video
Apr 10, 2020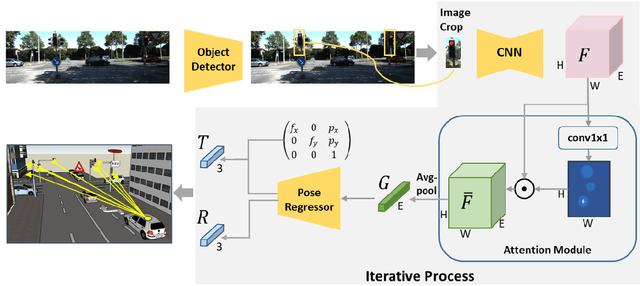
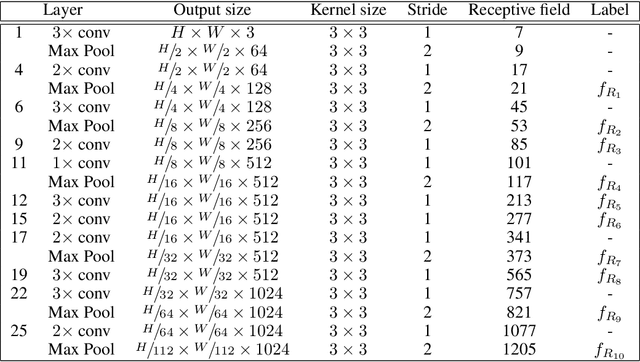
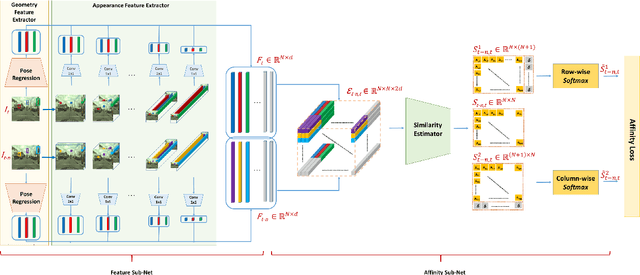
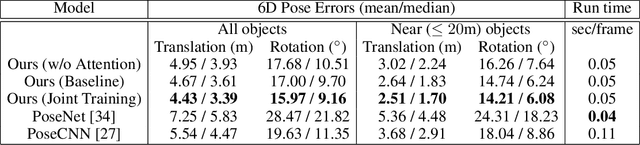
Accurately estimating the position of static objects, such as traffic lights, from the moving camera of a self-driving car is a challenging problem. In this work, we present a system that improves the localization of static objects by jointly-optimizing the components of the system via learning. Our system is comprised of networks that perform: 1) 6DoF object pose estimation from a single image, 2) association of objects between pairs of frames, and 3) multi-object tracking to produce the final geo-localization of the static objects within the scene. We evaluate our approach using a publicly-available data set, focusing on traffic lights due to data availability. For each component, we compare against contemporary alternatives and show significantly-improved performance. We also show that the end-to-end system performance is further improved via joint-training of the constituent models.
Photorealistic Image Synthesis for Object Instance Detection
Feb 09, 2019
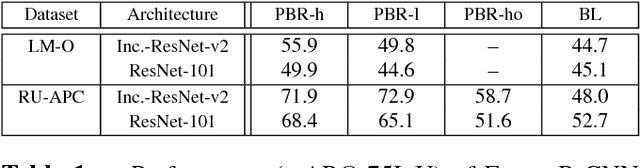


We present an approach to synthesize highly photorealistic images of 3D object models, which we use to train a convolutional neural network for detecting the objects in real images. The proposed approach has three key ingredients: (1) 3D object models are rendered in 3D models of complete scenes with realistic materials and lighting, (2) plausible geometric configuration of objects and cameras in a scene is generated using physics simulations, and (3) high photorealism of the synthesized images achieved by physically based rendering. When trained on images synthesized by the proposed approach, the Faster R-CNN object detector achieves a 24% absolute improvement of mAP@.75IoU on Rutgers APC and 11% on LineMod-Occluded datasets, compared to a baseline where the training images are synthesized by rendering object models on top of random photographs. This work is a step towards being able to effectively train object detectors without capturing or annotating any real images. A dataset of 600K synthetic images with ground truth annotations for various computer vision tasks will be released on the project website: thodan.github.io/objectsynth.