 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
X-ray Photon-Counting Data Correction through Deep Learning
Jul 06, 2020
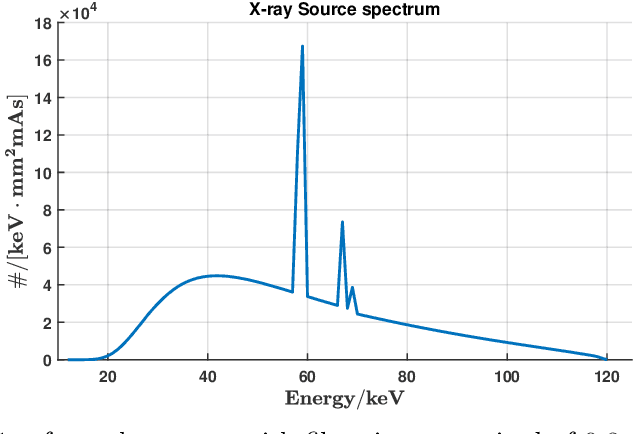
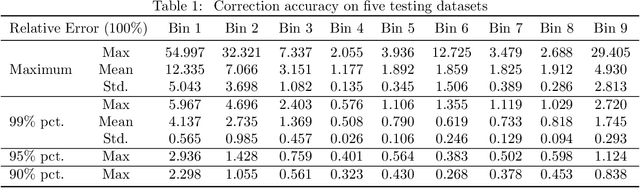
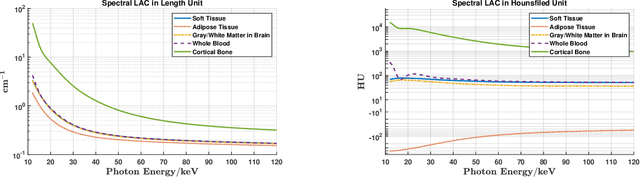

X-ray photon-counting detectors (PCDs) are drawing an increasing attention in recent years due to their low noise and energy discrimination capabilities. The energy/spectral dimension associated with PCDs potentially brings great benefits such as for material decomposition, beam hardening and metal artifact reduction, as well as low-dose CT imaging. However, X-ray PCDs are currently limited by several technical issues, particularly charge splitting (including charge sharing and K-shell fluorescence re-absorption or escaping) and pulse pile-up effects which distort the energy spectrum and compromise the data quality. Correction of raw PCD measurements with hardware improvement and analytic modeling is rather expensive and complicated. Hence, here we proposed a deep neural network based PCD data correction approach which directly maps imperfect data to the ideal data in the supervised learning mode. In this work, we first establish a complete simulation model incorporating the charge splitting and pulse pile-up effects. The simulated PCD data and the ground truth counterparts are then fed to a specially designed deep adversarial network for PCD data correction. Next, the trained network is used to correct separately generated PCD data. The test results demonstrate that the trained network successfully recovers the ideal spectrum from the distorted measurement within $\pm6\%$ relative error. Significant data and image fidelity improvements are clearly observed in both projection and reconstruction domains.
Heidelberg Colorectal Data Set for Surgical Data Science in the Sensor Operating Room
May 28, 2020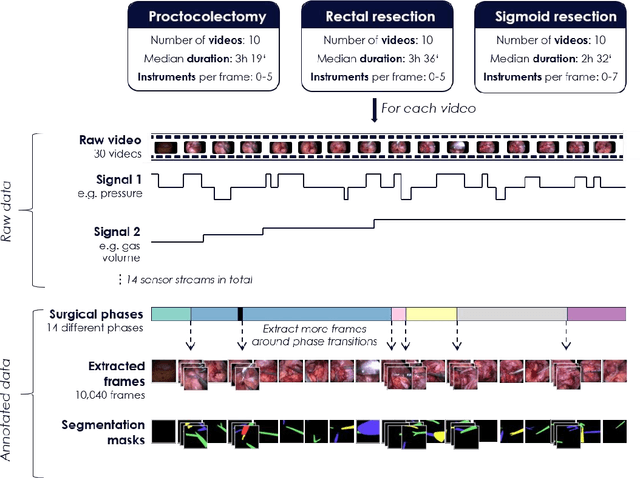
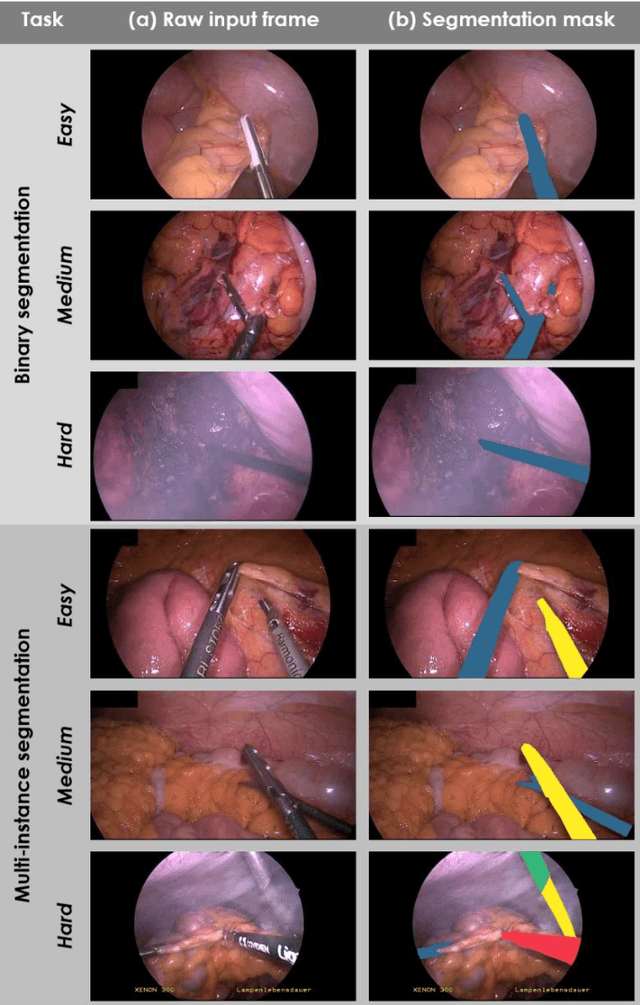
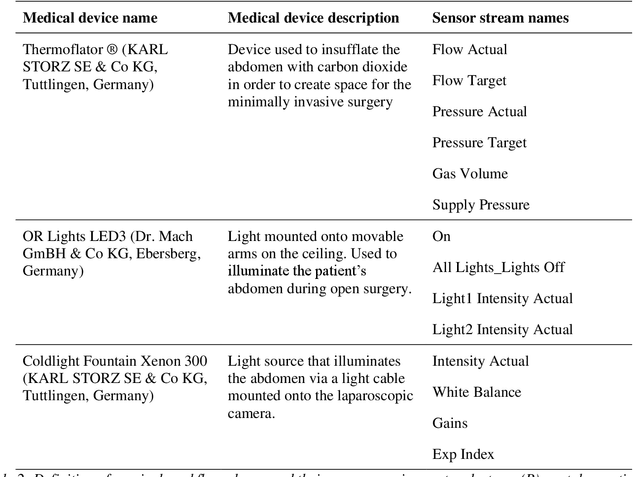
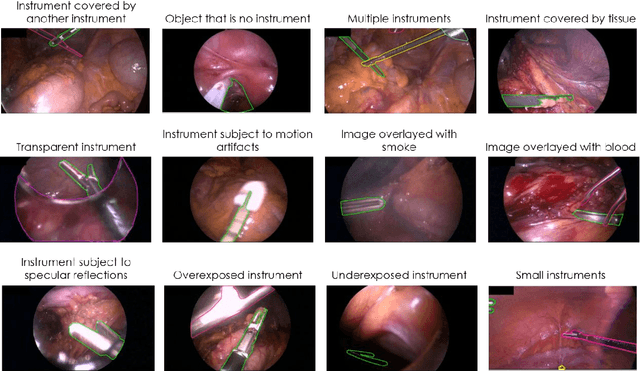
Image-based tracking of medical instruments is an integral part of many surgical data science applications. Previous research has addressed the tasks of detecting, segmenting and tracking medical instruments based on laparoscopic video data. However, the methods proposed still tend to fail when applied to challenging images and do not generalize well to data they have not been trained on. This paper introduces the Heidelberg Colorectal (HeiCo) data set - the first publicly available data set enabling comprehensive benchmarking of medical instrument detection and segmentation algorithms with a specific emphasis on robustness and generalization capabilities of the methods. Our data set comprises 30 laparoscopic videos and corresponding sensor data from medical devices in the operating room for three different types of laparoscopic surgery. Annotations include surgical phase labels for all frames in the videos as well as instance-wise segmentation masks for surgical instruments in more than 10,000 individual frames. The data has successfully been used to organize international competitions in the scope of the Endoscopic Vision Challenges (EndoVis) 2017 and 2019.
Planning to Explore via Self-Supervised World Models
May 12, 2020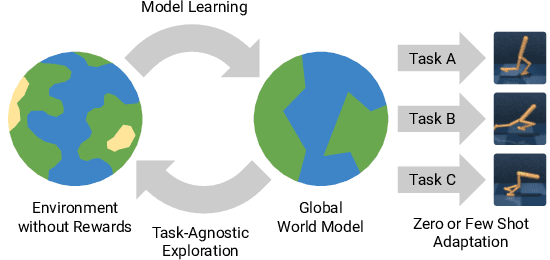
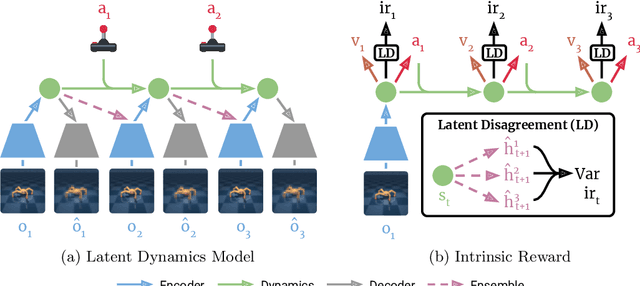
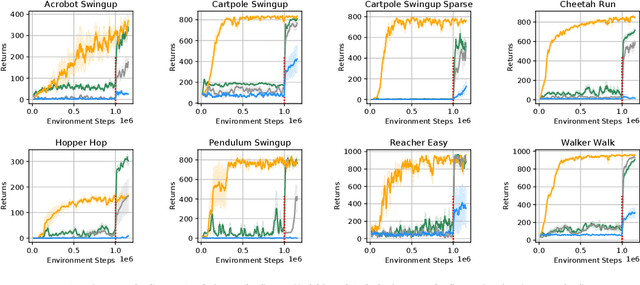
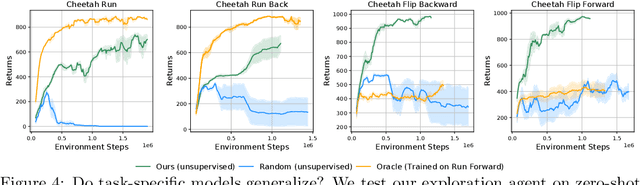
Reinforcement learning allows solving complex tasks, however, the learning tends to be task-specific and the sample efficiency remains a challenge. We present Plan2Explore, a self-supervised reinforcement learning agent that tackles both these challenges through a new approach to self-supervised exploration and fast adaptation to new tasks, which need not be known during exploration. During exploration, unlike prior methods which retrospectively compute the novelty of observations after the agent has already reached them, our agent acts efficiently by leveraging planning to seek out expected future novelty. After exploration, the agent quickly adapts to multiple downstream tasks in a zero or a few-shot manner. We evaluate on challenging control tasks from high-dimensional image inputs. Without any training supervision or task-specific interaction, Plan2Explore outperforms prior self-supervised exploration methods, and in fact, almost matches the performances oracle which has access to rewards. Videos and code at https://ramanans1.github.io/plan2explore/
Direct high-order edge-preserving regularization for tomographic image reconstruction
Sep 15, 2015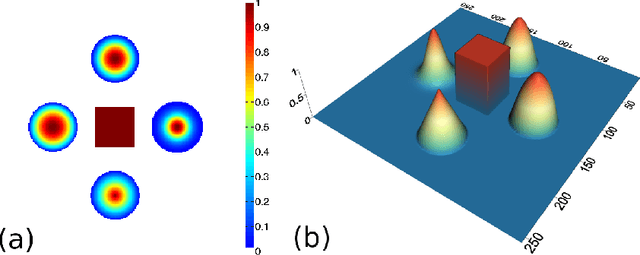

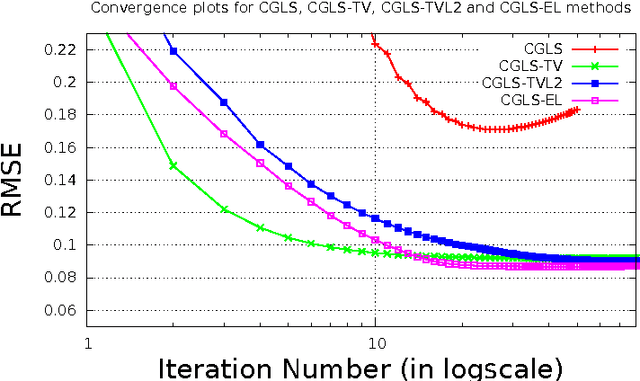
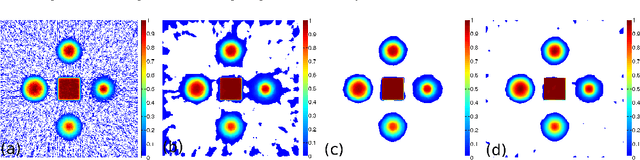
In this paper we present a new two-level iterative algorithm for tomographic image reconstruction. The algorithm uses a regularization technique, which we call edge-preserving Laplacian, that preserves sharp edges between objects while damping spurious oscillations in the areas where the reconstructed image is smooth. Our numerical simulations demonstrate that the proposed method outperforms total variation (TV) regularization and it is competitive with the combined TV-L2 penalty. Obtained reconstructed images show increased signal-to-noise ratio and visually appealing structural features. Computer implementation and parameter control of the proposed technique is straightforward, which increases the feasibility of it across many tomographic applications. In this paper, we applied our method to the under-sampled computed tomography (CT) projection data and also considered a case of reconstruction in emission tomography The MATLAB code is provided to support obtained results.
End-to-end learning of energy-based representations for irregularly-sampled signals and images
Oct 01, 2019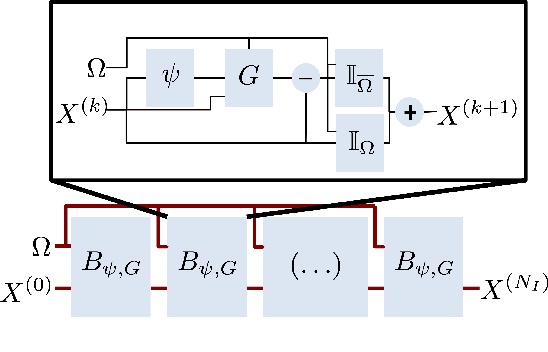
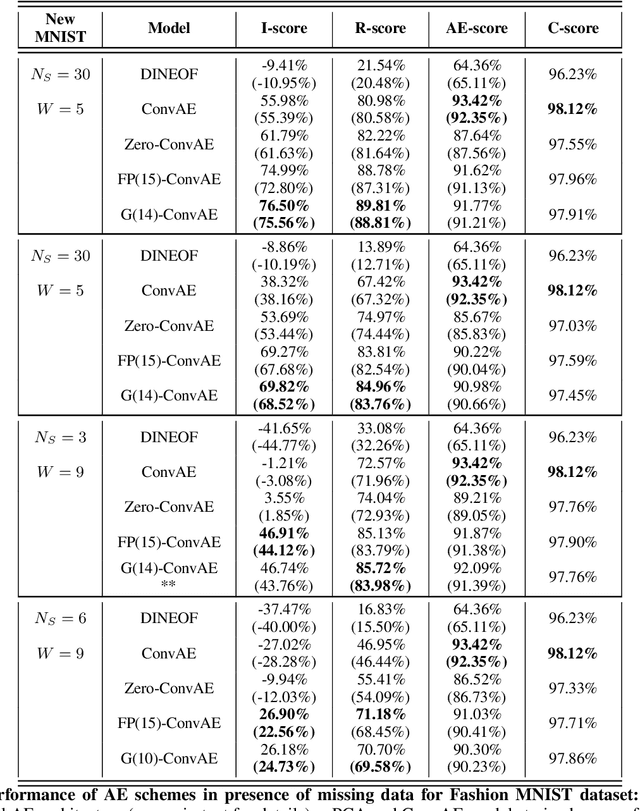

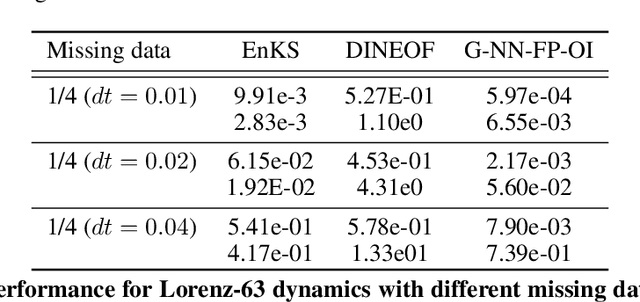
For numerous domains, including for instance earth observation, medical imaging, astrophysics,..., available image and signal datasets often involve irregular space-time sampling patterns and large missing data rates. These sampling properties may be critical to apply state-of-the-art learning-based (e.g., auto-encoders, CNNs,...), fully benefit from the available large-scale observations and reach breakthroughs in the reconstruction and identification of processes of interest. In this paper, we address the end-to-end learning of representations of signals, images and image sequences from irregularly-sampled data, i.e. when the training data involved missing data. From an analogy to Bayesian formulation, we consider energy-based representations. Two energy forms are investigated: one derived from auto-encoders and one relating to Gibbs priors. The learning stage of these energy-based representations (or priors) involve a joint interpolation issue, which amounts to solving an energy minimization problem under observation constraints. Using a neural-network-based implementation of the considered energy forms, we can state an end-to-end learning scheme from irregularly-sampled data. We demonstrate the relevance of the proposed representations for different case-studies: namely, multivariate time series, 2D images and image sequences.
Motion-supervised Co-Part Segmentation
Apr 15, 2020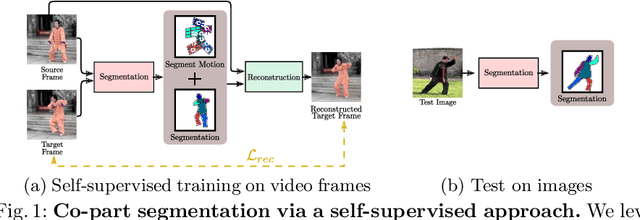

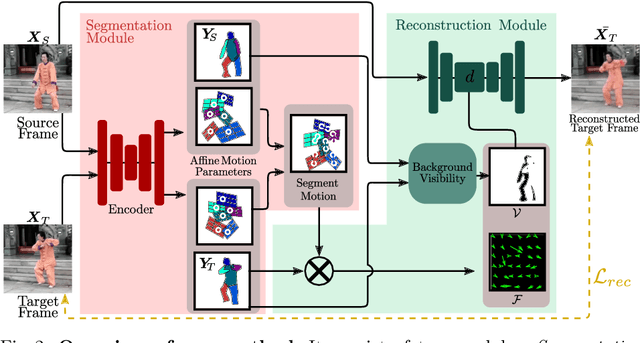
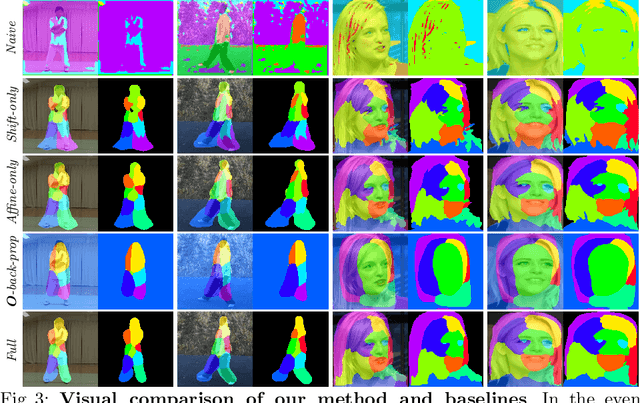
Recent co-part segmentation methods mostly operate in a supervised learning setting, which requires a large amount of annotated data for training. To overcome this limitation, we propose a self-supervised deep learning method for co-part segmentation. Differently from previous works, our approach develops the idea that motion information inferred from videos can be leveraged to discover meaningful object parts. To this end, our method relies on pairs of frames sampled from the same video. The network learns to predict part segments together with a representation of the motion between two frames, which permits reconstruction of the target image. Through extensive experimental evaluation on publicly available video sequences we demonstrate that our approach can produce improved segmentation maps with respect to previous self-supervised co-part segmentation approaches.
Interpretable Visualizations with Differentiating Embedding Networks
Jun 11, 2020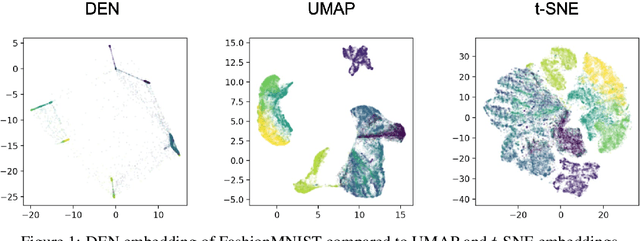
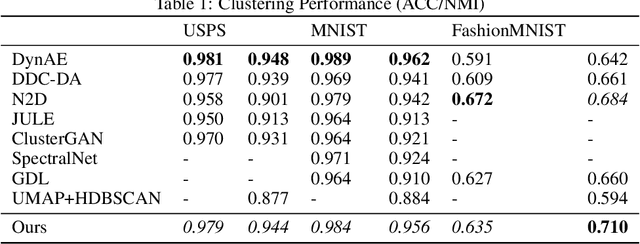
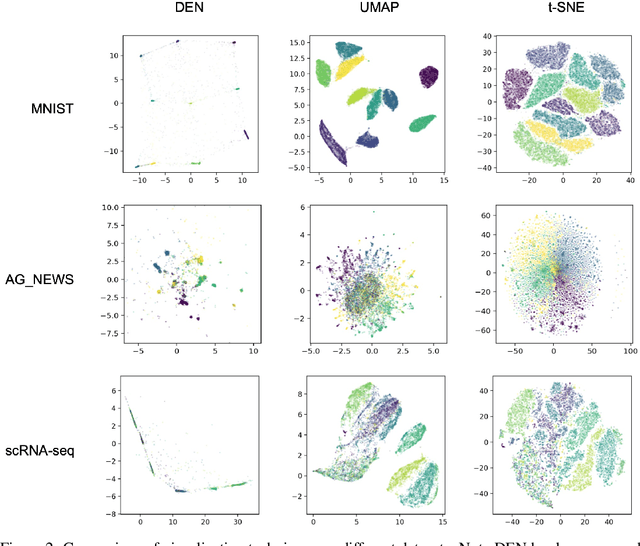
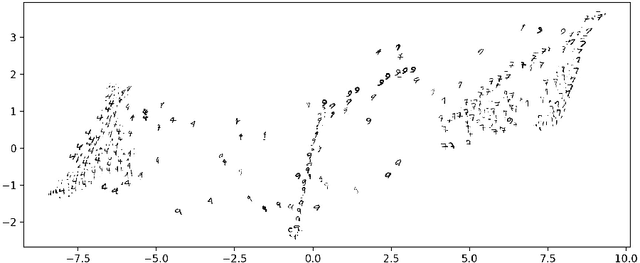
We present a visualization algorithm based on a novel unsupervised Siamese neural network training regime and loss function, called Differentiating Embedding Networks (DEN). The Siamese neural network finds differentiating or similar features between specific pairs of samples in a dataset, and uses these features to embed the dataset in a lower dimensional space where it can be visualized. Unlike existing visualization algorithms such as UMAP or $t$-SNE, DEN is parametric, meaning it can be interpreted by techniques such as SHAP. To interpret DEN, we create an end-to-end parametric clustering algorithm on top of the visualization, and then leverage SHAP scores to determine which features in the sample space are important for understanding the structures shown in the visualization based on the clusters found. We compare DEN visualizations with existing techniques on a variety of datasets, including image and scRNA-seq data. We then show that our clustering algorithm performs similarly to the state of the art despite not having prior knowledge of the number of clusters, and sets a new state of the art on FashionMNIST. Finally, we demonstrate finding differentiating features of a dataset. Code available at https://github.com/isaacrob/DEN
Gibbs Sampling with People
Aug 06, 2020
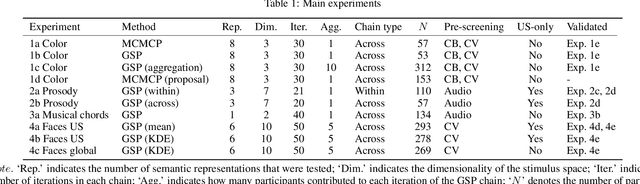
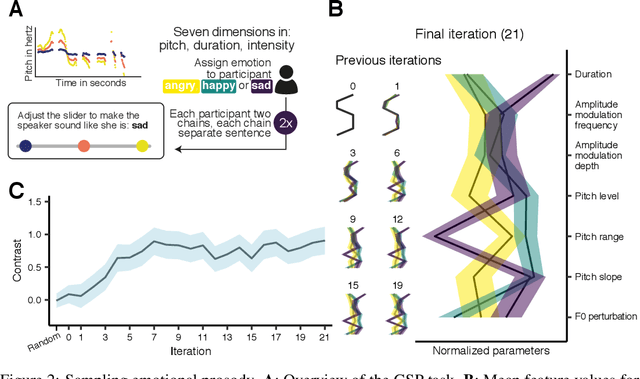
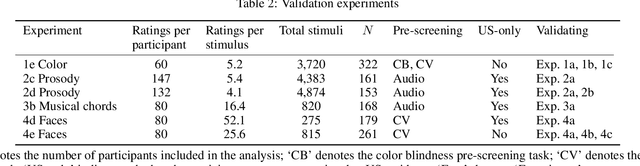
A core problem in cognitive science and machine learning is to understand how humans derive semantic representations from perceptual objects, such as color from an apple, pleasantness from a musical chord, or trustworthiness from a face. Markov Chain Monte Carlo with People (MCMCP) is a prominent method for studying such representations, in which participants are presented with binary choice trials constructed such that the decisions follow a Markov Chain Monte Carlo acceptance rule. However, MCMCP's binary choice paradigm generates relatively little information per trial, and its local proposal function makes it slow to explore the parameter space and find the modes of the distribution. Here we therefore generalize MCMCP to a continuous-sampling paradigm, where in each iteration the participant uses a slider to continuously manipulate a single stimulus dimension to optimize a given criterion such as 'pleasantness'. We formulate both methods from a utility-theory perspective, and show that the new method can be interpreted as 'Gibbs Sampling with People' (GSP). Further, we introduce an aggregation parameter to the transition step, and show that this parameter can be manipulated to flexibly shift between Gibbs sampling and deterministic optimization. In an initial study, we show GSP clearly outperforming MCMCP; we then show that GSP provides novel and interpretable results in three other domains, namely musical chords, vocal emotions, and faces. We validate these results through large-scale perceptual rating experiments. The final experiments combine GSP with a state-of-the-art image synthesis network (StyleGAN) and a recent network interpretability technique (GANSpace), enabling GSP to efficiently explore high-dimensional perceptual spaces, and demonstrating how GSP can be a powerful tool for jointly characterizing semantic representations in humans and machines.
HDD-Net: Hybrid Detector Descriptor with Mutual Interactive Learning
May 12, 2020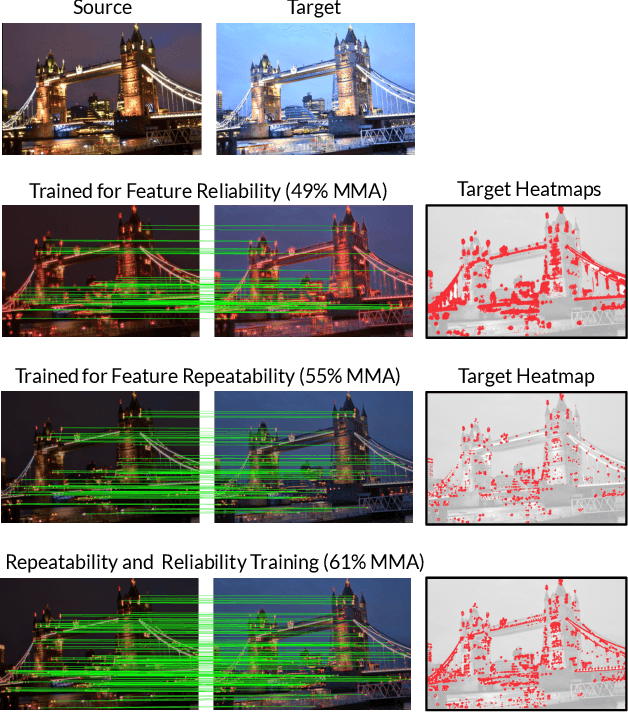

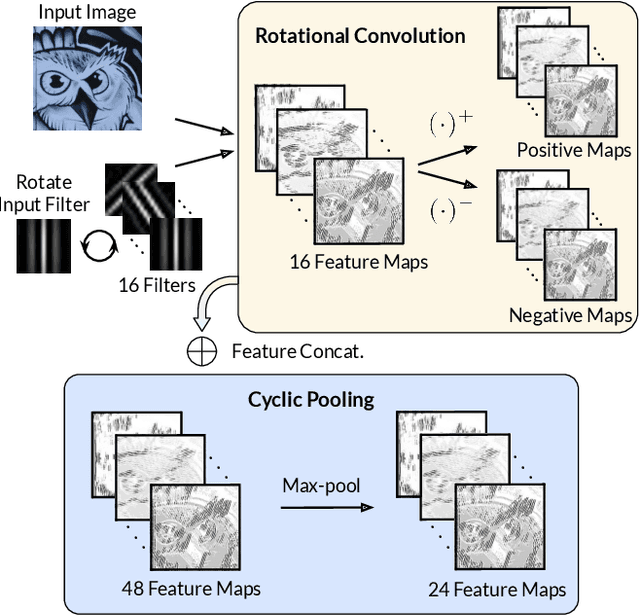

Local feature extraction remains an active research area due to the advances in fields such as SLAM, 3D reconstructions, or AR applications. The success in these applications relies on the performance of the feature detector and descriptor. While the detector-descriptor interaction of most methods is based on unifying in single network detections and descriptors, we propose a method that treats both extractions independently and focuses on their interaction in the learning process rather than by parameter sharing. We formulate the classical hard-mining triplet loss as a new detector optimisation term to refine candidate positions based on the descriptor map. We propose a dense descriptor that uses a multi-scale approach and a hybrid combination of hand-crafted and learned features to obtain rotation and scale robustness by design. We evaluate our method extensively on different benchmarks and show improvements over the state of the art in terms of image matching on HPatches and 3D reconstruction quality while keeping on par on camera localisation tasks.
Identity Document to Selfie Face Matching Across Adolescence
Dec 20, 2019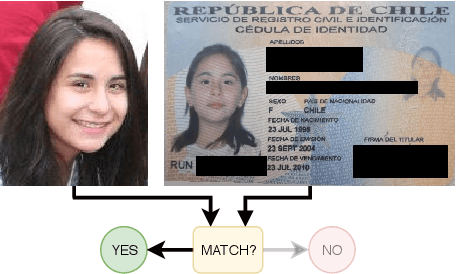
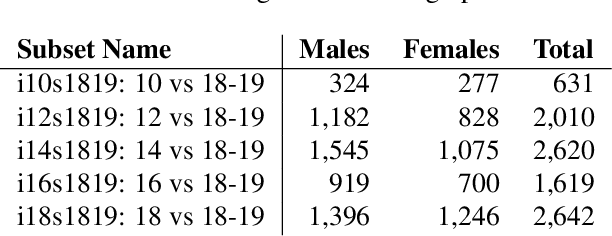
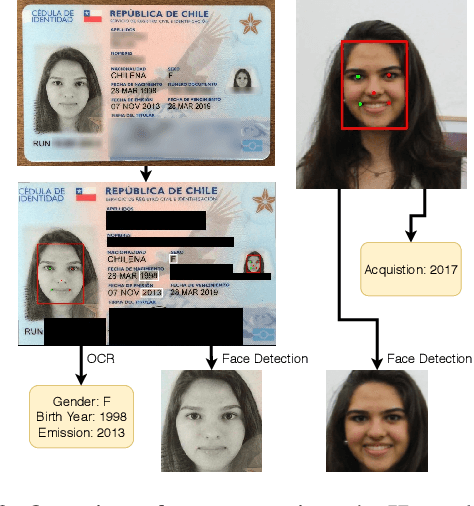
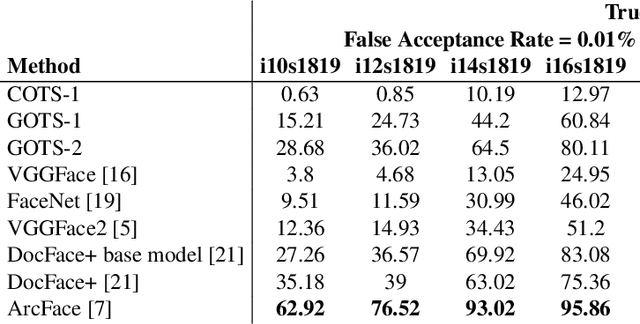
Matching live images (``selfies'') to images from ID documents is a problem that can arise in various applications. A challenging instance of the problem arises when the face image on the ID document is from early adolescence and the live image is from later adolescence. We explore this problem using a private dataset called Chilean Young Adult (CHIYA) dataset, where we match live face images taken at age 18-19 to face images on ID documents created at ages 9 to 18. State-of-the-art deep learning face matchers (e.g., ArcFace) have relatively poor accuracy for document-to-selfie face matching. To achieve higher accuracy, we fine-tune the best available open-source model with triplet loss for a few-shot learning. Experiments show that our approach achieves higher accuracy than the DocFace+ model recently developed for this problem. Our fine-tuned model was able to improve the true acceptance rate for the most difficult (largest age span) subset from 62.92% to 96.67% at a false acceptance rate of 0.01%. Our fine-tuned model is available for use by other researchers.