 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Consistent Video Depth Estimation
Apr 30, 2020
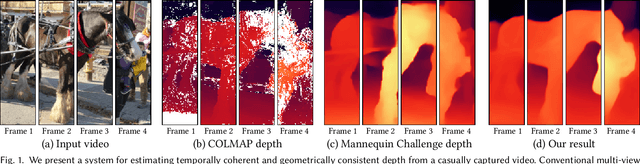
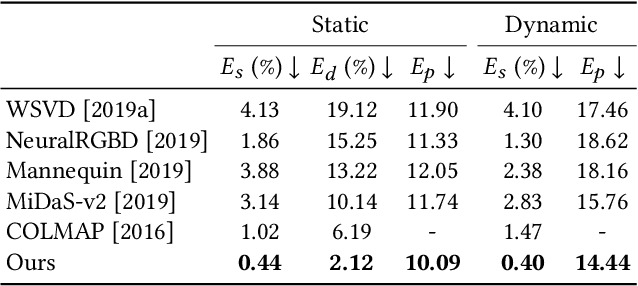
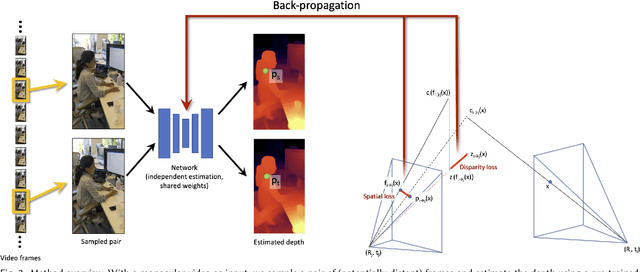
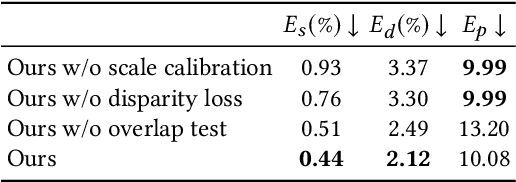
We present an algorithm for reconstructing dense, geometrically consistent depth for all pixels in a monocular video. We leverage a conventional structure-from-motion reconstruction to establish geometric constraints on pixels in the video. Unlike the ad-hoc priors in classical reconstruction, we use a learning-based prior, i.e., a convolutional neural network trained for single-image depth estimation. At test time, we fine-tune this network to satisfy the geometric constraints of a particular input video, while retaining its ability to synthesize plausible depth details in parts of the video that are less constrained. We show through quantitative validation that our method achieves higher accuracy and a higher degree of geometric consistency than previous monocular reconstruction methods. Visually, our results appear more stable. Our algorithm is able to handle challenging hand-held captured input videos with a moderate degree of dynamic motion. The improved quality of the reconstruction enables several applications, such as scene reconstruction and advanced video-based visual effects.
Benchmarking the Robustness of Semantic Segmentation Models
Aug 14, 2019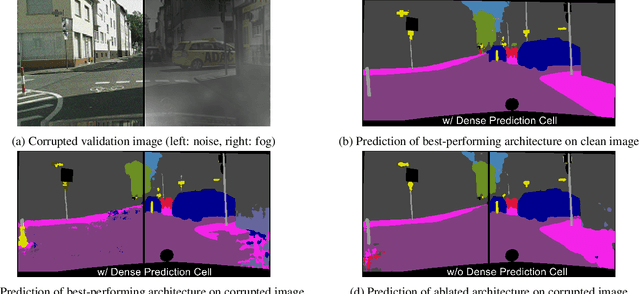


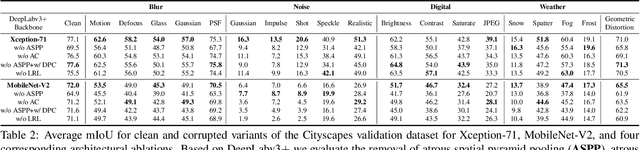
When designing a semantic segmentation module for a practical application, such as autonomous driving, it is crucial to understand the robustness of the module with respect to a wide range of image corruptions. While there are recent robustness studies for full-image classification, we are the first to present an exhaustive study for semantic segmentation, based on the state-of-the-art model DeepLabv3$+$. To increase the realism of our study, we utilize almost 200,000 images generated from Cityscapes and PASCAL VOC 2012, and we furthermore present a realistic noise model, imitating HDR camera noise. Based on the benchmark study we gain several new insights. Firstly, model robustness increases with model performance, in most cases. Secondly, some architecture properties affect robustness significantly, such as a Dense Prediction Cell which was designed to maximize performance on clean data only. Thirdly, to achieve good generalization with respect to various types of image noise, it is recommended to train DeepLabv3+ with our realistic noise model.
Semi Supervised Phrase Localization in a Bidirectional Caption-Image Retrieval Framework
Aug 08, 2019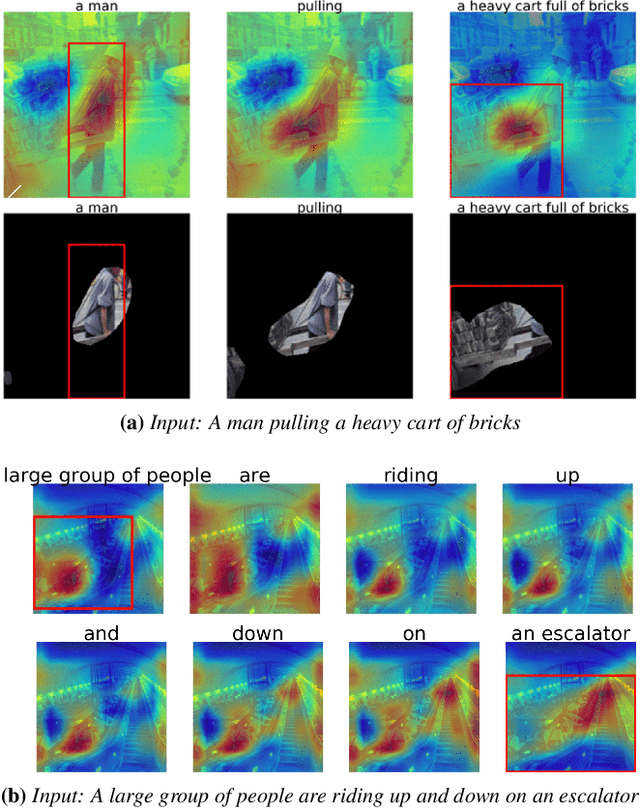
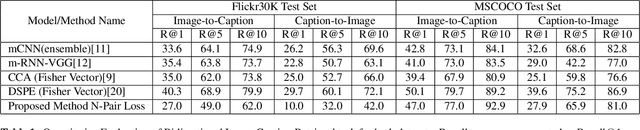
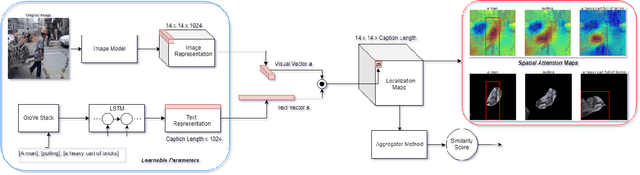
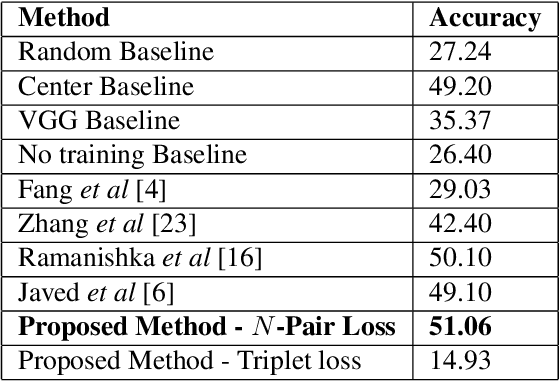
We introduce a novel deep neural network architecture that links visual regions to corresponding textual segments including phrases and words. To accomplish this task, our architecture makes use of the rich semantic information available in a joint embedding space of multi-modal data. From this joint embedding space, we extract the associative localization maps that develop naturally, without explicitly providing supervision during training for the localization task. The joint space is learned using a bidirectional ranking objective that is optimized using a $N$-Pair loss formulation. This training mechanism demonstrates the idea that localization information is learned inherently while optimizing a Bidirectional Retrieval objective. The model's retrieval and localization performance is evaluated on MSCOCO and Flickr30K Entities datasets. This architecture outperforms the state of the art results in the semi-supervised phrase localization setting.
Optimization of Clustering for Clustering-based Image Denoising
Oct 28, 2013In this paper, the problem of de-noising of an image contaminated with additive white Gaussian noise (AWGN) is studied. This subject has been continued to be an open problem in signal processing for more than 50 years. In the present paper, we suggest a method based on global clustering of image constructing blocks. Noting that the type of clustering plays an important role in clustering-based de-noising methods, we address two questions about the clustering. First, which parts of data should be considered for clustering? Second, what data clustering method is suitable for de-noising? Clustering is exploited to learn an over complete dictionary. By obtaining sparse decomposition of the noisy image blocks in terms of the dictionary atoms, the de-noised version is achieved. Experimental results show that our dictionary learning framework outperforms traditional dictionary learning methods such as K-SVD.
Harmonizing Maximum Likelihood with GANs for Multimodal Conditional Generation
Feb 25, 2019
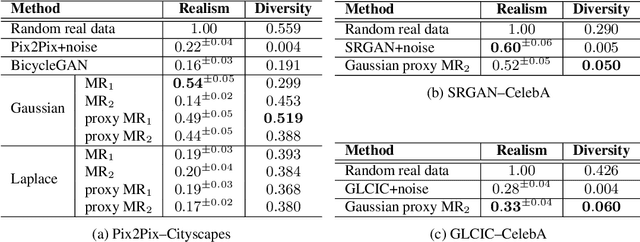
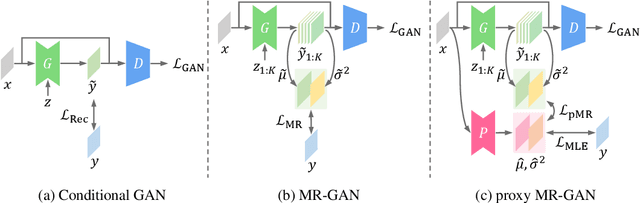

Recent advances in conditional image generation tasks, such as image-to-image translation and image inpainting, are largely accounted to the success of conditional GAN models, which are often optimized by the joint use of the GAN loss with the reconstruction loss. However, we reveal that this training recipe shared by almost all existing methods causes one critical side effect: lack of diversity in output samples. In order to accomplish both training stability and multimodal output generation, we propose novel training schemes with a new set of losses named moment reconstruction losses that simply replace the reconstruction loss. We show that our approach is applicable to any conditional generation tasks by performing thorough experiments on image-to-image translation, super-resolution and image inpainting using Cityscapes and CelebA dataset. Quantitative evaluations also confirm that our methods achieve a great diversity in outputs while retaining or even improving the visual fidelity of generated samples.
Bi-Directional ConvLSTM U-Net with Densley Connected Convolutions
Aug 31, 2019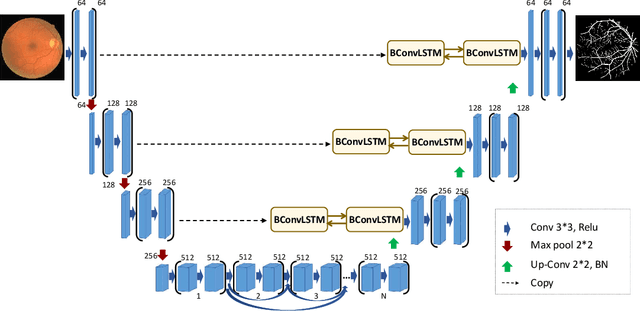
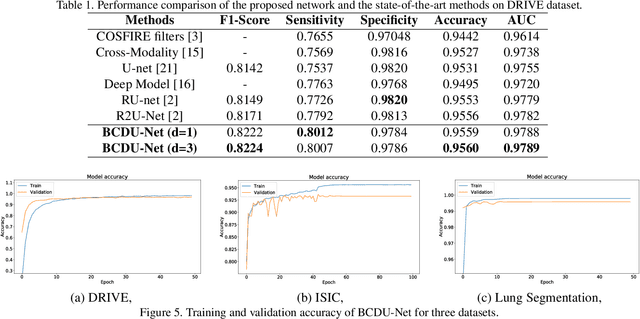

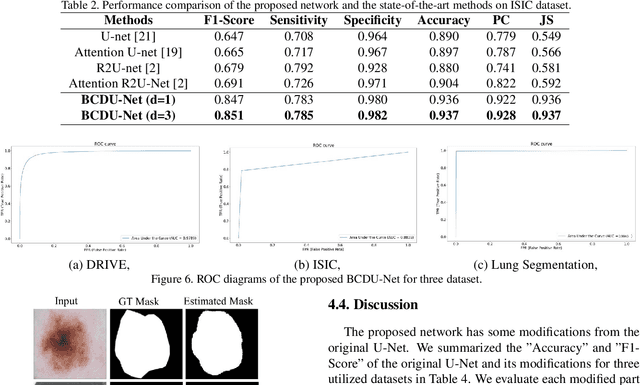
In recent years, deep learning-based networks have achieved state-of-the-art performance in medical image segmentation. Among the existing networks, U-Net has been successfully applied on medical image segmentation. In this paper, we propose an extension of U-Net, Bi-directional ConvLSTM U-Net with Densely connected convolutions (BCDU-Net), for medical image segmentation, in which we take full advantages of U-Net, bi-directional ConvLSTM (BConvLSTM) and the mechanism of dense convolutions. Instead of a simple concatenation in the skip connection of U-Net, we employ BConvLSTM to combine the feature maps extracted from the corresponding encoding path and the previous decoding up-convolutional layer in a non-linear way. To strengthen feature propagation and encourage feature reuse, we use densely connected convolutions in the last convolutional layer of the encoding path. Finally, we can accelerate the convergence speed of the proposed network by employing batch normalization (BN). The proposed model is evaluated on three datasets of: retinal blood vessel segmentation, skin lesion segmentation, and lung nodule segmentation, achieving state-of-the-art performance.
An Effective Image Feature Classiffication using an improved SOM
Jan 08, 2015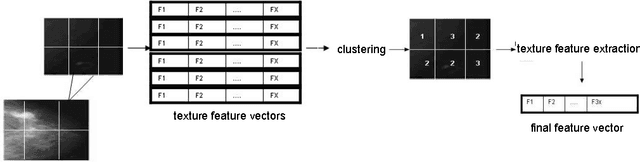
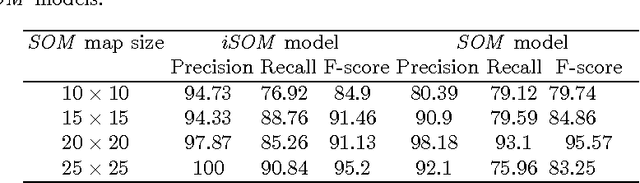
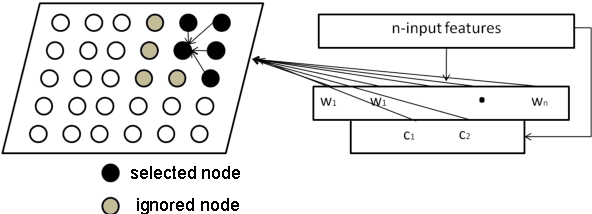
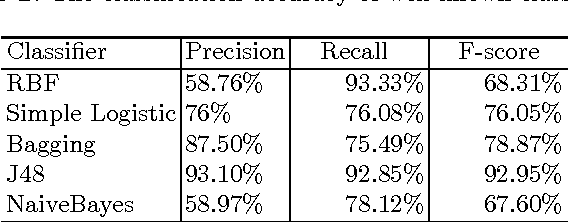
Image feature classification is a challenging problem in many computer vision applications, specifically, in the fields of remote sensing, image analysis and pattern recognition. In this paper, a novel Self Organizing Map, termed improved SOM (iSOM), is proposed with the aim of effectively classifying Mammographic images based on their texture feature representation. The main contribution of the iSOM is to introduce a new node structure for the map representation and adopting a learning technique based on Kohonen SOM accordingly. The main idea is to control, in an unsupervised fashion, the weight updating procedure depending on the class reliability of the node, during the weight update time. Experiments held on a real Mammographic images. Results showed high accuracy compared to classical SOM and other state-of-art classifiers.
Learning Fully Dense Neural Networks for Image Semantic Segmentation
May 22, 2019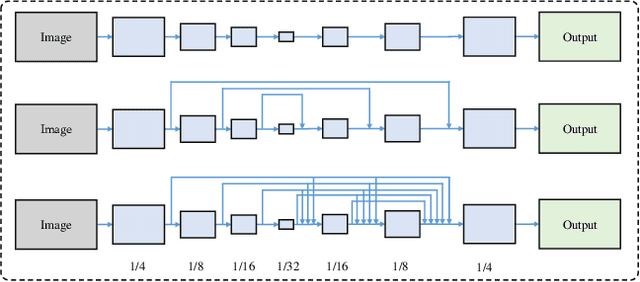
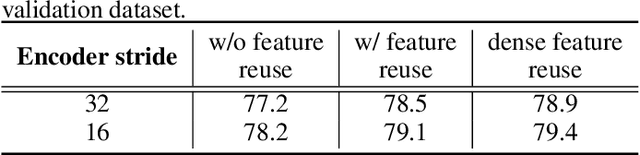

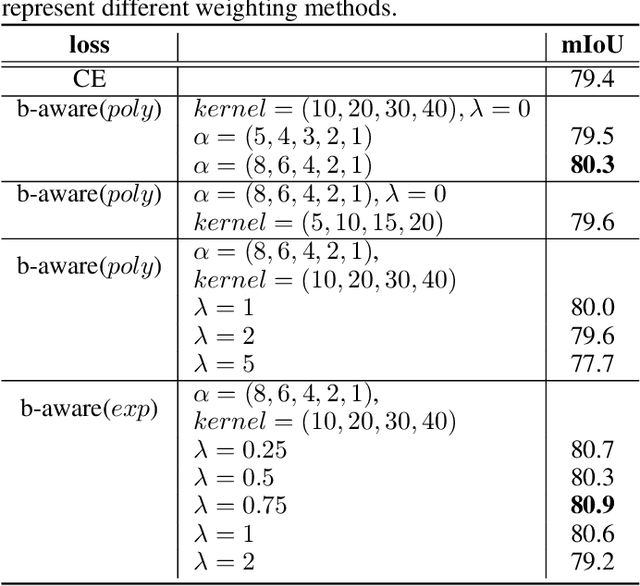
Semantic segmentation is pixel-wise classification which retains critical spatial information. The "feature map reuse" has been commonly adopted in CNN based approaches to take advantage of feature maps in the early layers for the later spatial reconstruction. Along this direction, we go a step further by proposing a fully dense neural network with an encoder-decoder structure that we abbreviate as FDNet. For each stage in the decoder module, feature maps of all the previous blocks are adaptively aggregated to feed-forward as input. On the one hand, it reconstructs the spatial boundaries accurately. On the other hand, it learns more efficiently with the more efficient gradient backpropagation. In addition, we propose the boundary-aware loss function to focus more attention on the pixels near the boundary, which boosts the "hard examples" labeling. We have demonstrated the best performance of the FDNet on the two benchmark datasets: PASCAL VOC 2012, NYUDv2 over previous works when not considering training on other datasets.
A Cascaded Learning Strategy for Robust COVID-19 Pneumonia Chest X-Ray Screening
Apr 30, 2020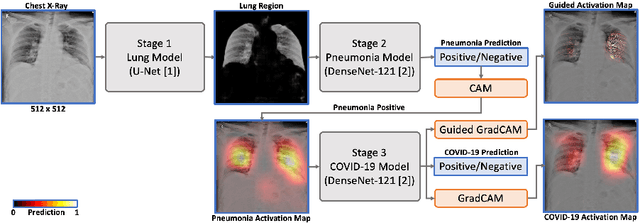
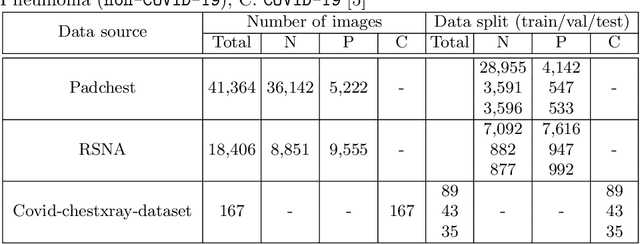
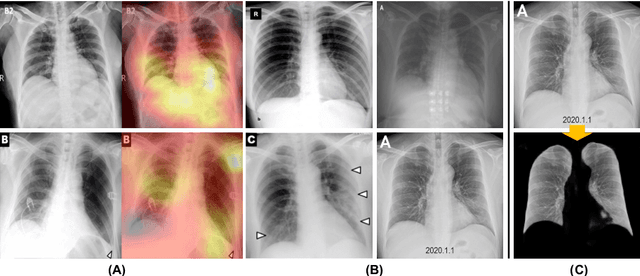
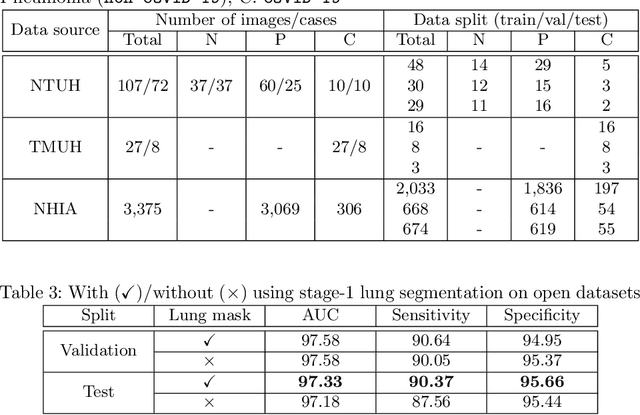
We introduce a comprehensive screening platform for the COVID-19 (a.k.a., SARS-CoV-2) pneumonia. The proposed AI-based system works on chest x-ray (CXR) images to predict whether a patient is infected with the COVID-19 disease. Although the recent international joint effort on making the availability of all sorts of open data, the public collection of CXR images is still relatively small for reliably training a deep neural network (DNN) to carry out COVID-19 prediction. To better address such inefficiency, we design a cascaded learning strategy to improve both the sensitivity and the specificity of the resulting DNN classification model. Our approach leverages a large CXR image dataset of non-COVID-19 pneumonia to generalize the original well-trained classification model via a cascaded learning scheme. The resulting screening system is shown to achieve good classification performance on the expanded dataset, including those newly added COVID-19 CXR images.
Video Object Grounding using Semantic Roles in Language Description
Mar 24, 2020
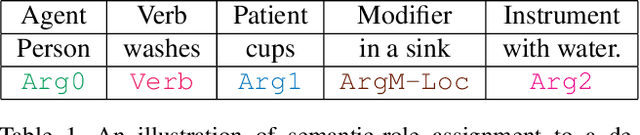


We explore the task of Video Object Grounding (VOG), which grounds objects in videos referred to in natural language descriptions. Previous methods apply image grounding based algorithms to address VOG, fail to explore the object relation information and suffer from limited generalization. Here, we investigate the role of object relations in VOG and propose a novel framework VOGNet to encode multi-modal object relations via self-attention with relative position encoding. To evaluate VOGNet, we propose novel contrasting sampling methods to generate more challenging grounding input samples, and construct a new dataset called ActivityNet-SRL (ASRL) based on existing caption and grounding datasets. Experiments on ASRL validate the need of encoding object relations in VOG, and our VOGNet outperforms competitive baselines by a significant margin.