 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Probabilistic Spatial Transformers for Bayesian Data Augmentation
Apr 07, 2020
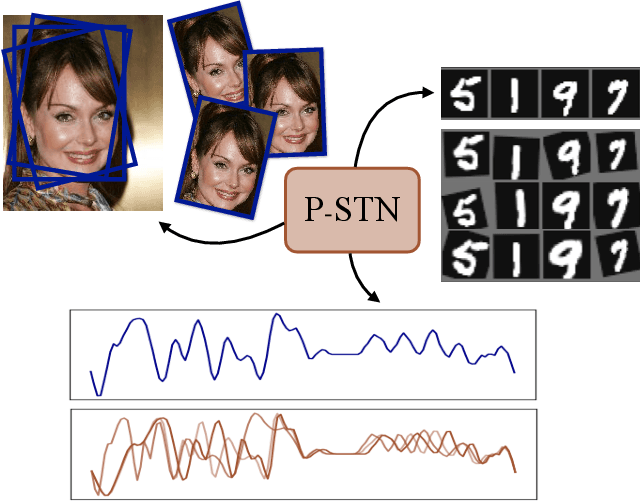
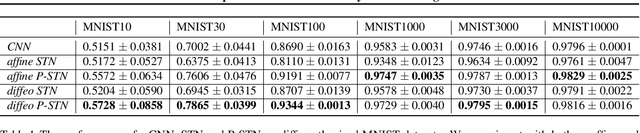
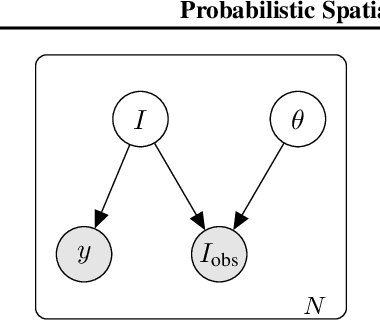

High-capacity models require vast amounts of data, and data augmentation is a common remedy when this resource is limited. Standard augmentation techniques apply small hand-tuned transformations to existing data, which is a brittle process that realistically only allows for simple transformations. We propose a Bayesian interpretation of data augmentation where the transformations are modelled as latent variables to be marginalized, and show how these can be inferred variationally in an end-to-end fashion. This allows for significantly more complex transformations than manual tuning, and the marginalization implies a form of test-time data augmentation. The resulting model can be interpreted as a probabilistic extension of spatial transformer networks. Experimentally, we demonstrate improvements in accuracy and uncertainty quantification in image and time series classification tasks.
Synthetic-to-Real Domain Adaptation for Lane Detection
Jul 08, 2020
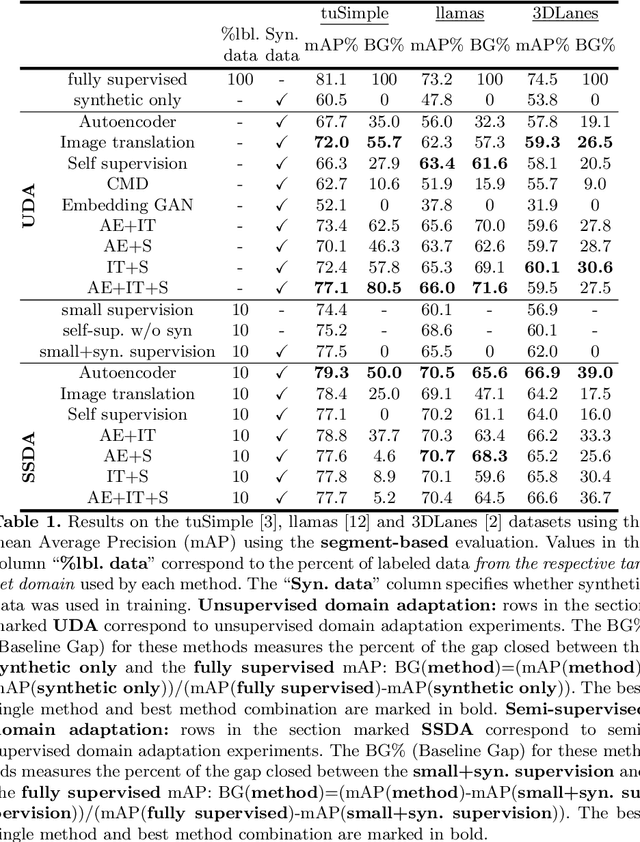
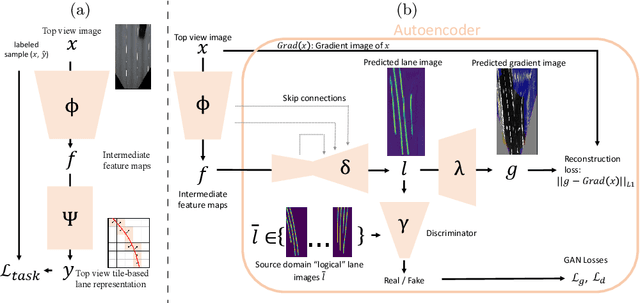
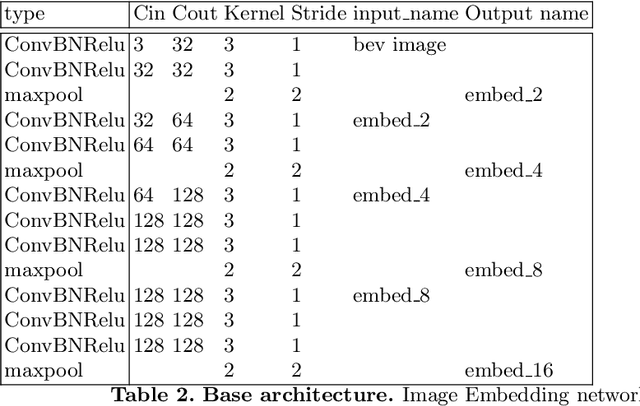
Accurate lane detection, a crucial enabler for autonomous driving, currently relies on obtaining a large and diverse labeled training dataset. In this work, we explore learning from abundant, randomly generated synthetic data, together with unlabeled or partially labeled target domain data, instead. Randomly generated synthetic data has the advantage of controlled variability in the lane geometry and lighting, but it is limited in terms of photo-realism. This poses the challenge of adapting models learned on the unrealistic synthetic domain to real images. To this end we develop a novel autoencoder-based approach that uses synthetic labels unaligned with particular images for adapting to target domain data. In addition, we explore existing domain adaptation approaches, such as image translation and self-supervision, and adjust them to the lane detection task. We test all approaches in the unsupervised domain adaptation setting in which no target domain labels are available and in the semi-supervised setting in which a small portion of the target images are labeled. In extensive experiments using three different datasets, we demonstrate the possibility to save costly target domain labeling efforts. For example, using our proposed autoencoder approach on the llamas and tuSimple lane datasets, we can almost recover the fully supervised accuracy with only 10% of the labeled data. In addition, our autoencoder approach outperforms all other methods in the semi-supervised domain adaptation scenario.
Multiform Fonts-to-Fonts Translation via Style and Content Disentangled Representations of Chinese Character
Mar 28, 2020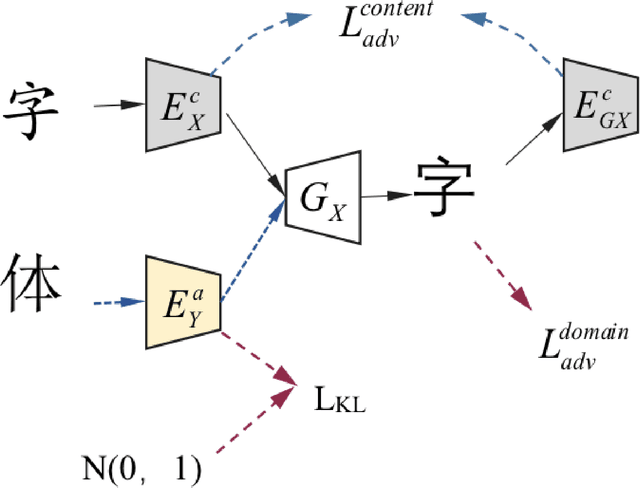
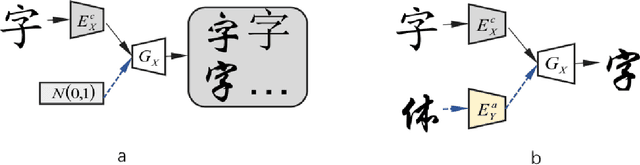
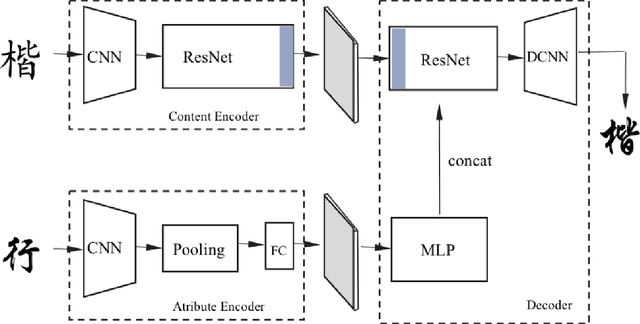

This paper mainly discusses the generation of personalized fonts as the problem of image style transfer. The main purpose of this paper is to design a network framework that can extract and recombine the content and style of the characters. These attempts can be used to synthesize the entire set of fonts with only a small amount of characters. The paper combines various depth networks such as Convolutional Neural Network, Multi-layer Perceptron and Residual Network to find the optimal model to extract the features of the fonts character. The result shows that those characters we have generated is very close to real characters, using Structural Similarity index and Peak Signal-to-Noise Ratio evaluation criterions.
Layerwise learning for quantum neural networks
Jun 26, 2020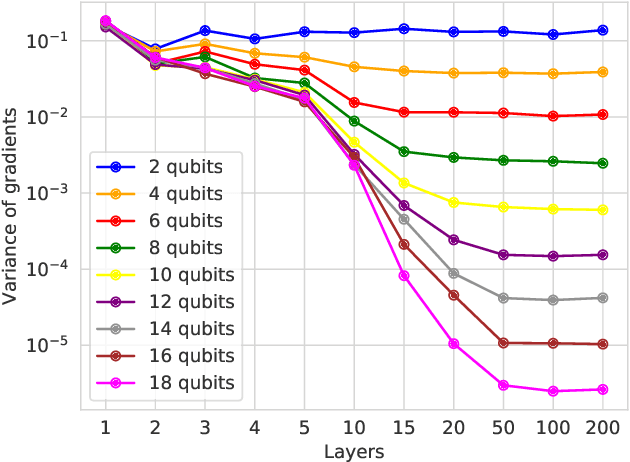
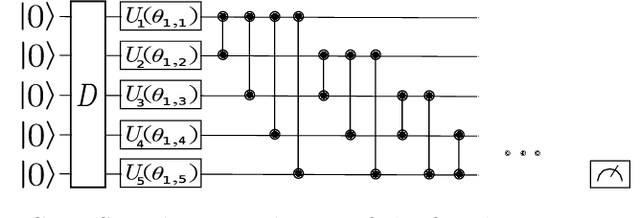
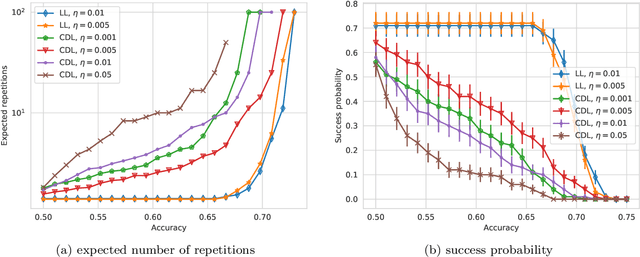
With the increased focus on quantum circuit learning for near-term applications on quantum devices, in conjunction with unique challenges presented by cost function landscapes of parametrized quantum circuits, strategies for effective training are becoming increasingly important. In order to ameliorate some of these challenges, we investigate a layerwise learning strategy for parametrized quantum circuits. The circuit depth is incrementally grown during optimization, and only subsets of parameters are updated in each training step. We show that when considering sampling noise, this strategy can help avoid the problem of barren plateaus of the error surface due to the low depth of circuits, low number of parameters trained in one step, and larger magnitude of gradients compared to training the full circuit. These properties make our algorithm preferable for execution on noisy intermediate-scale quantum devices. We demonstrate our approach on an image-classification task on handwritten digits, and show that layerwise learning attains an 8% lower generalization error on average in comparison to standard learning schemes for training quantum circuits of the same size. Additionally, the percentage of runs that reach lower test errors is up to 40% larger compared to training the full circuit, which is susceptible to creeping onto a plateau during training.
Faster AutoAugment: Learning Augmentation Strategies using Backpropagation
Nov 16, 2019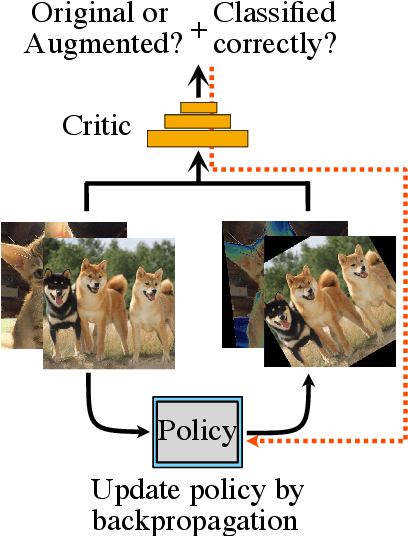
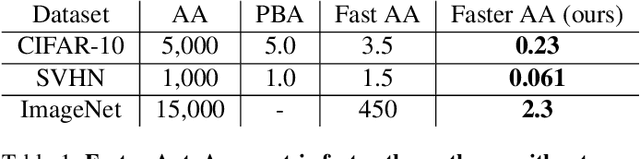
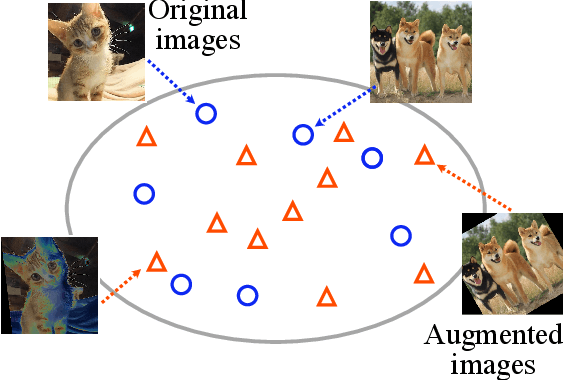
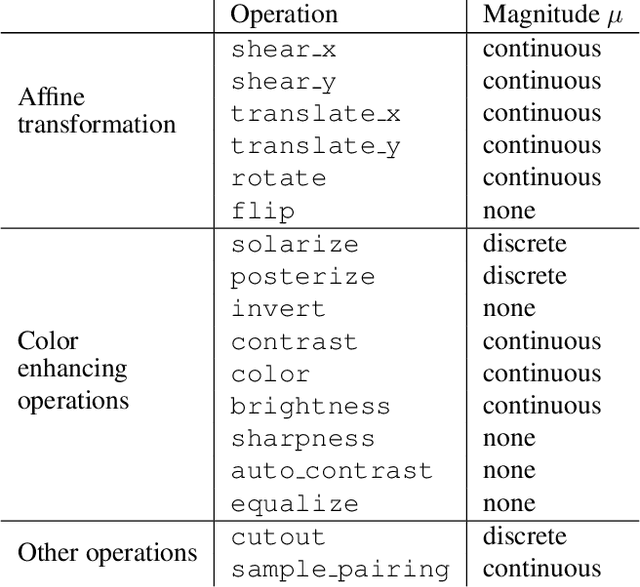
Data augmentation methods are indispensable heuristics to boost the performance of deep neural networks, especially in image recognition tasks. Recently, several studies have shown that augmentation strategies found by search algorithms outperform hand-made strategies. Such methods employ black-box search algorithms over image transformations with continuous or discrete parameters and require a long time to obtain better strategies. In this paper, we propose a differentiable policy search pipeline for data augmentation, which is much faster than previous methods. We introduce approximate gradients for several transformation operations with discrete parameters as well as the differentiable mechanism for selecting operations. As the objective of training, we minimize the distance between the distributions of augmented data and the original data, which can be differentiated. We show that our method, Faster AutoAugment, achieves significantly faster searching than prior work without a performance drop.
Synthesizing lesions using contextual GANs improves breast cancer classification on mammograms
May 29, 2020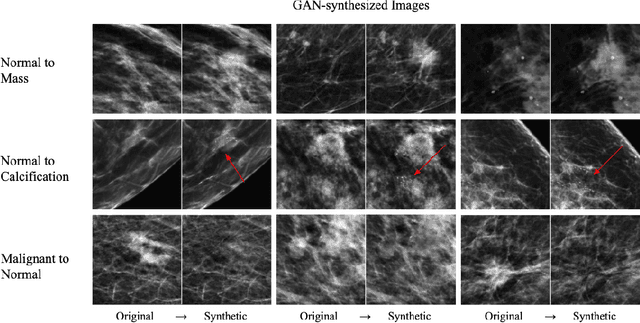
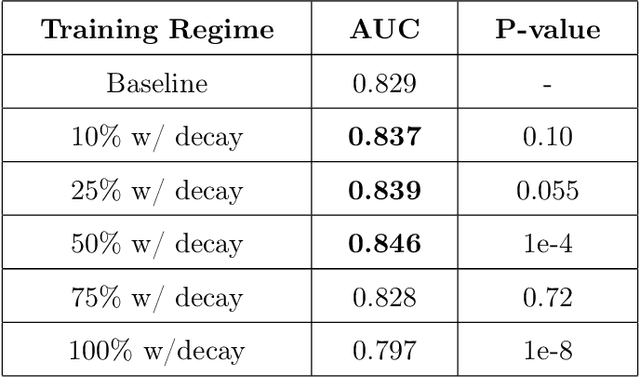
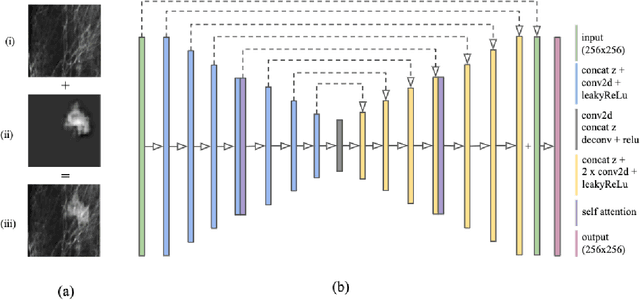
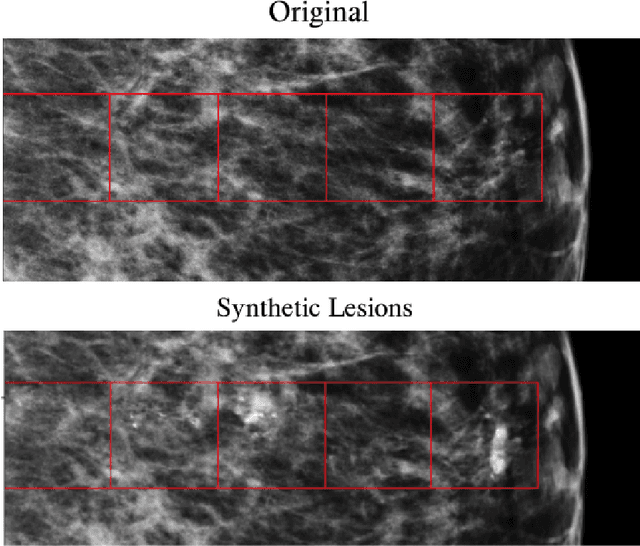
Data scarcity and class imbalance are two fundamental challenges in many machine learning applications to healthcare. Breast cancer classification in mammography exemplifies these challenges, with a malignancy rate of around 0.5% in a screening population, which is compounded by the relatively small size of lesions (~1% of the image) in malignant cases. Simultaneously, the prevalence of screening mammography creates a potential abundance of non-cancer exams to use for training. Altogether, these characteristics lead to overfitting on cancer cases, while under-utilizing non-cancer data. Here, we present a novel generative adversarial network (GAN) model for data augmentation that can realistically synthesize and remove lesions on mammograms. With self-attention and semi-supervised learning components, the U-net-based architecture can generate high resolution (256x256px) outputs, as necessary for mammography. When augmenting the original training set with the GAN-generated samples, we find a significant improvement in malignancy classification performance on a test set of real mammogram patches. Overall, the empirical results of our algorithm and the relevance to other medical imaging paradigms point to potentially fruitful further applications.
Super-Resolution of Brain MRI Images using Overcomplete Dictionaries and Nonlocal Similarity
Feb 13, 2019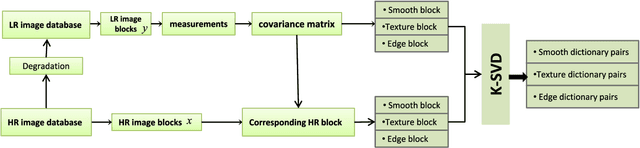
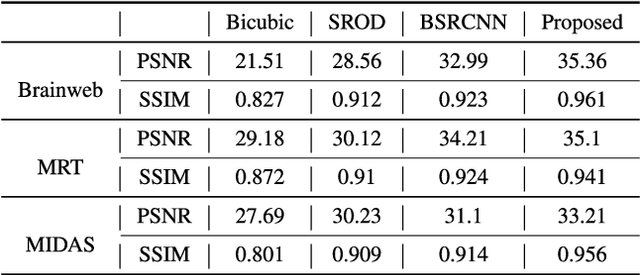
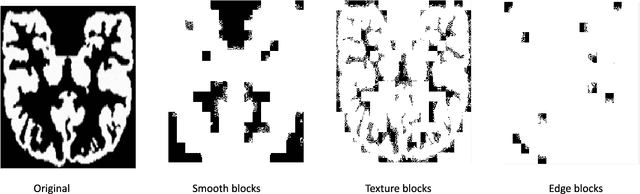
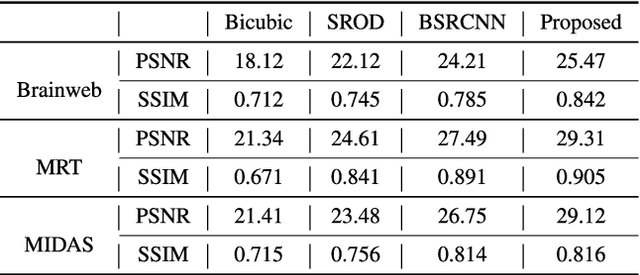
Recently, the Magnetic Resonance Imaging (MRI) images have limited and unsatisfactory resolutions due to various constraints such as physical, technological and economic considerations. Super-resolution techniques can obtain high-resolution MRI images. The traditional methods obtained the resolution enhancement of brain MRI by interpolations, affecting the accuracy of the following diagnose process. The requirement for brain image quality is fast increasing. In this paper, we propose an image super-resolution (SR) method based on overcomplete dictionaries and inherent similarity of an image to recover the high-resolution (HR) image from a single low-resolution (LR) image. We explore the nonlocal similarity of the image to tentatively search for similar blocks in the whole image and present a joint reconstruction method based on compressive sensing (CS) and similarity constraints. The sparsity and self-similarity of the image blocks are taken as the constraints. The proposed method is summarized in the following steps. First, a dictionary classification method based on the measurement domain is presented. The image blocks are classified into smooth, texture and edge parts by analyzing their features in the measurement domain. Then, the corresponding dictionaries are trained using the classified image blocks. Equally important, in the reconstruction part, we use the CS reconstruction method to recover the HR brain MRI image, considering both nonlocal similarity and the sparsity of an image as the constraints. This method performs better both visually and quantitatively than some existing methods.
Gray Level Image Enhancement Using Polygonal Functions
Dec 18, 2014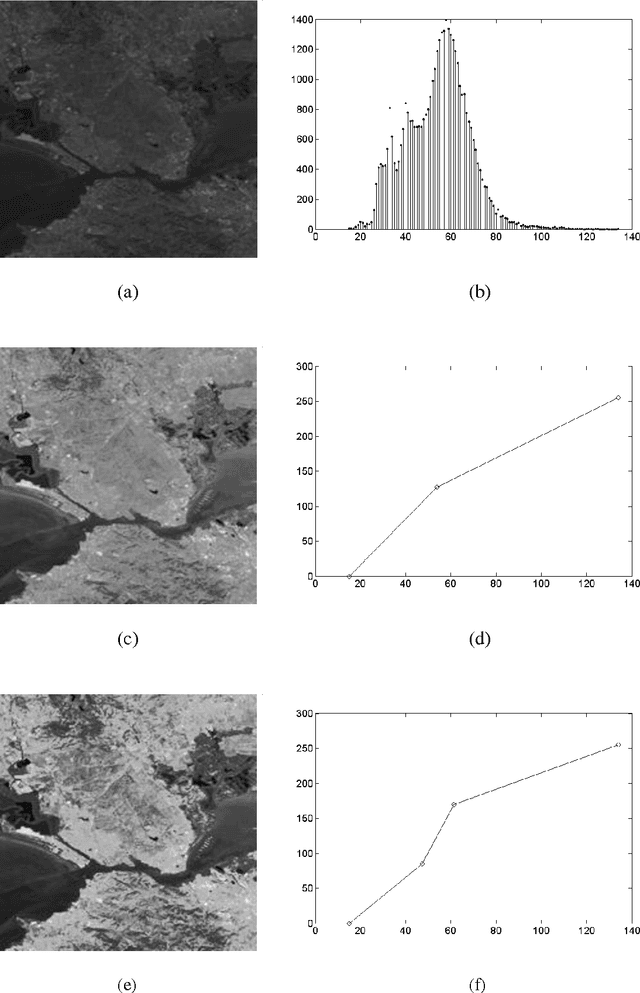
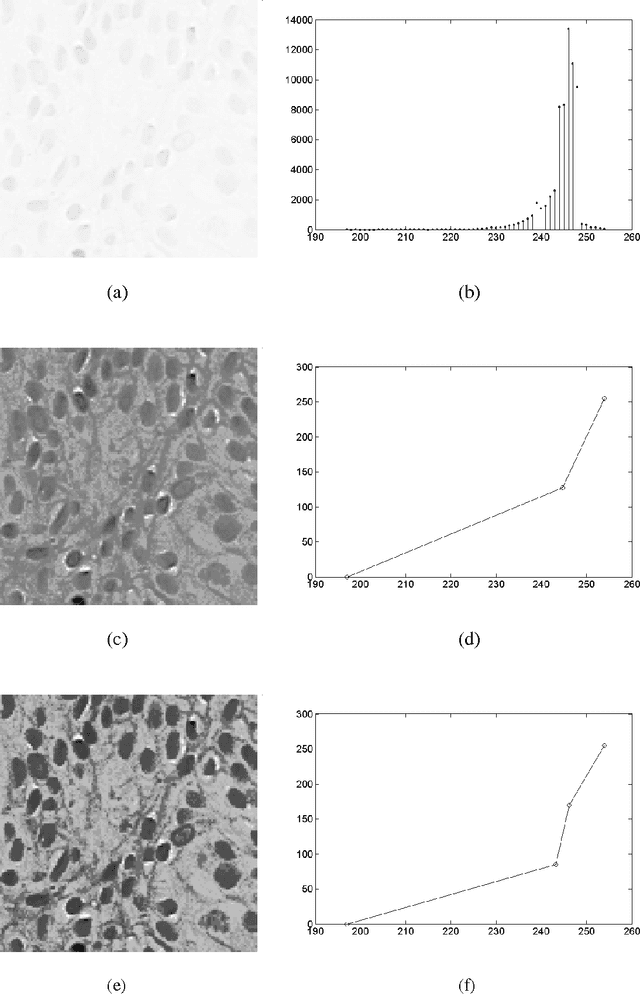
This paper presents a method for enhancing the gray level images. This method takes part from the category of point transforms and it is based on interpolation functions. The latter have a graphic represented by polygonal lines. The interpolation nodes of these functions are calculated taking into account the statistics of gray levels belonging to the image.
Image-level Classification in Hyperspectral Images using Feature Descriptors, with Application to Face Recognition
May 11, 2016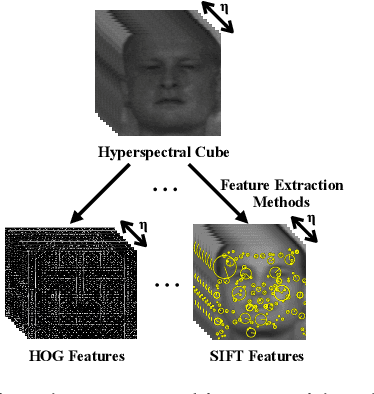

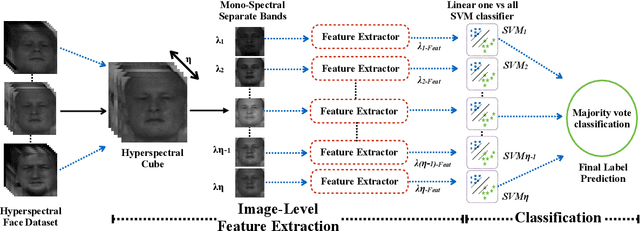
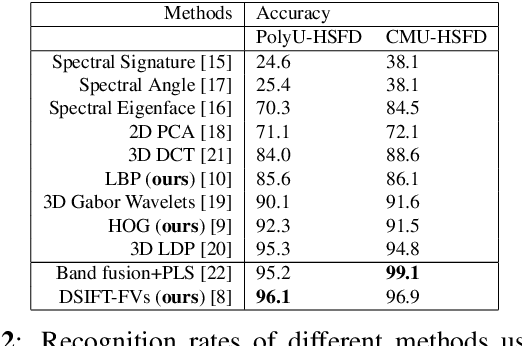
In this paper, we proposed a novel pipeline for image-level classification in the hyperspectral images. By doing this, we show that the discriminative spectral information at image-level features lead to significantly improved performance in a face recognition task. We also explored the potential of traditional feature descriptors in the hyperspectral images. From our evaluations, we observe that SIFT features outperform the state-of-the-art hyperspectral face recognition methods, and also the other descriptors. With the increasing deployment of hyperspectral sensors in a multitude of applications, we believe that our approach can effectively exploit the spectral information in hyperspectral images, thus beneficial to more accurate classification.
A Computation-Efficient CNN System for High-Quality Brain Tumor Segmentation
Aug 07, 2020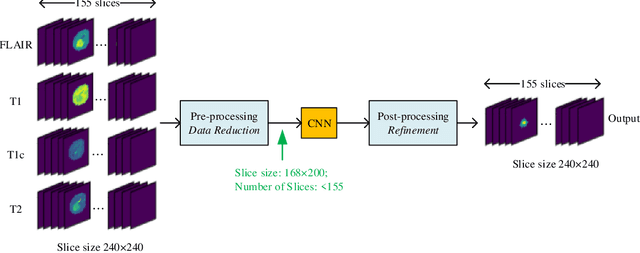
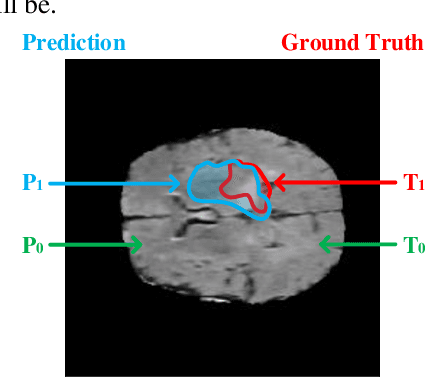
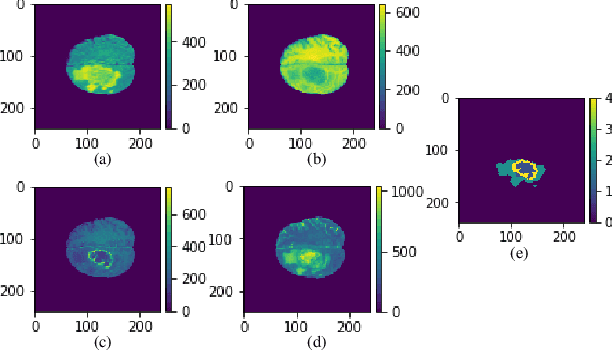
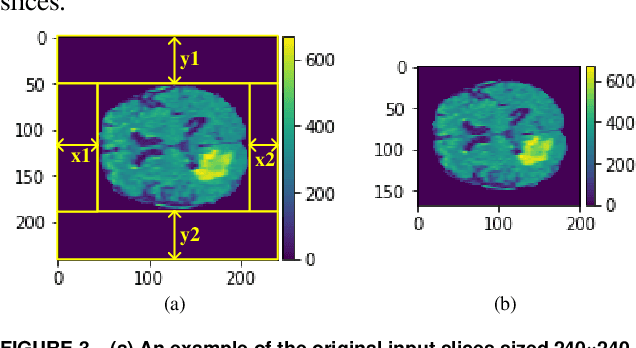
In this paper, a Convolutional Neural Network (CNN) system is proposed for brain tumor segmentation. The system consists of three parts, a pre-processing block to reduce the data volume, an application-specific CNN(ASCNN) to segment tumor areas precisely, and a refinement block to detect/remove false positive pixels. The CNN, designed specifically for the task, has 7 convolution layers, 16 channels per layer, requiring only 11716 parameters. The convolutions combined with max-pooling in the first half of the CNN are performed to localize tumor areas. Two convolution modes, namely depthwise convolution and standard convolution, are performed in parallel in the first 2 layers to extract elementary features efficiently. For a fine classification of pixel-wise precision in the second half of the CNN, the feature maps are modulated by adding the individually weighted local feature maps generated in the first half of the CNN. The performance of the proposed system has been evaluated by an online platform with dataset of Multimodal Brain Tumor Image Segmentation Benchmark (BRATS) 2018. Requiring a very low computation volume, the proposed system delivers a high segmentation quality indicated by its average Dice scores of 0.75, 0.88 and 0.76 for enhancing tumor, whole tumor and tumor core, respectively, and also by the median Dice scores of 0.85, 0.92, and 0.86. The consistency in system performance has also been measured, demonstrating that the system is able to reproduce almost the same output to the same input after retraining. The simple structure of the proposed system facilitates its implementation in computation restricted environment, and a wide range of applications can thus be expected.