 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Defense Against Adversarial Images using Web-Scale Nearest-Neighbor Search
Mar 05, 2019
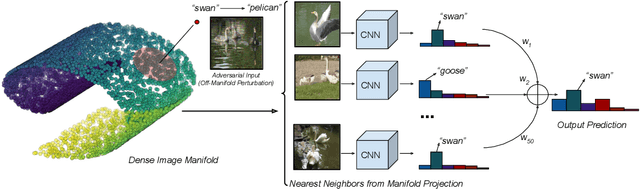


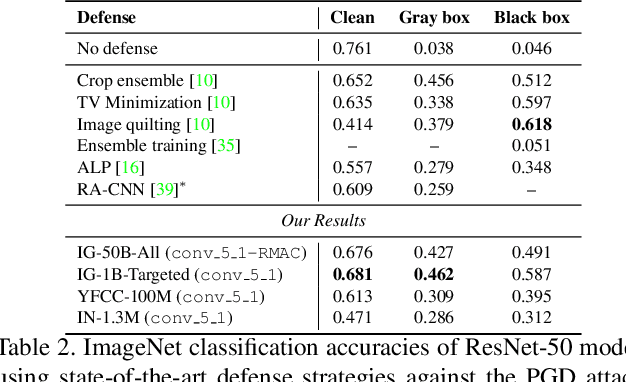
A plethora of recent work has shown that convolutional networks are not robust to adversarial images: images that are created by perturbing a sample from the data distribution as to maximize the loss on the perturbed example. In this work, we hypothesize that adversarial perturbations move the image away from the image manifold in the sense that there exists no physical process that could have produced the adversarial image. This hypothesis suggests that a successful defense mechanism against adversarial images should aim to project the images back onto the image manifold. We study such defense mechanisms, which approximate the projection onto the unknown image manifold by a nearest-neighbor search against a web-scale image database containing tens of billions of images. Empirical evaluations of this defense strategy on ImageNet suggest that it is very effective in attack settings in which the adversary does not have access to the image database. We also propose two novel attack methods to break nearest-neighbor defenses, and demonstrate conditions under which nearest-neighbor defense fails. We perform a series of ablation experiments, which suggest that there is a trade-off between robustness and accuracy in our defenses, that a large image database (with hundreds of millions of images) is crucial to get good performance, and that careful construction the image database is important to be robust against attacks tailored to circumvent our defenses.
A Topological "Reading" Lesson: Classification of MNIST using TDA
Oct 22, 2019
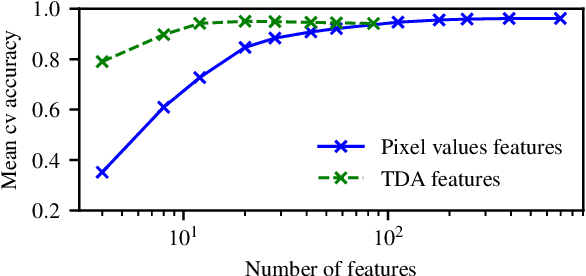
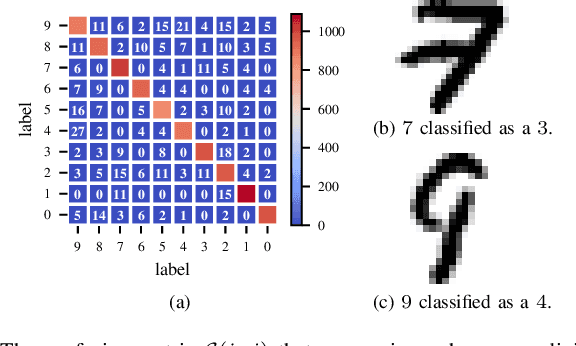
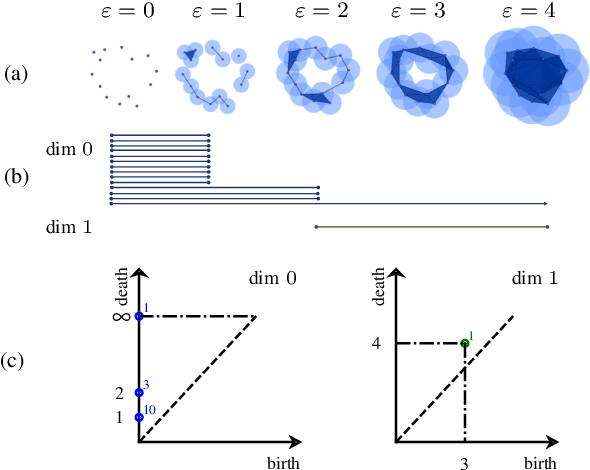
We present a way to use Topological Data Analysis (TDA) for machine learning tasks on grayscale images. We apply persistent homology to generate a wide range of topological features using a point cloud obtained from an image, its natural grayscale filtration, and different filtrations defined on the binarized image. We show that this topological machine learning pipeline can be used as a highly relevant dimensionality reduction by applying it to the MNIST digits dataset. We conduct a feature selection and study their correlations while providing an intuitive interpretation of their importance, which is relevant in both machine learning and TDA. Finally, we show that we can classify digit images while reducing the size of the feature set by a factor 5 compared to the grayscale pixel value features and maintain similar accuracy.
Augmented Reality on the Large Scene Based on a Markerless Registration Framework
Mar 03, 2020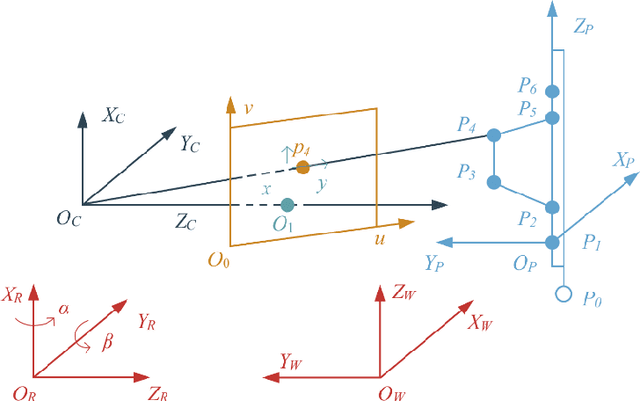

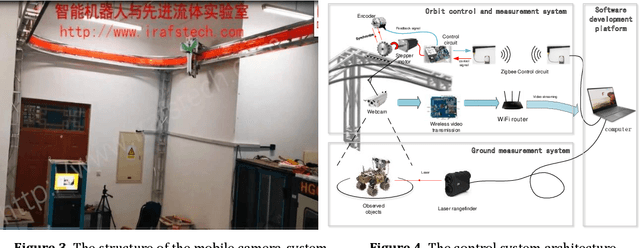
In this paper, a mobile camera positioning method based on forward and inverse kinematics of robot is proposed, which can realize far point positioning of imaging position and attitude tracking in large scene enhancement. Orbit precision motion through the framework overhead cameras and combining with the ground system of sensor array object such as mobile robot platform of various sensors, realize the good 3 d image registration, solve any artifacts that is mobile robot in the large space position initialization problem, effectively implement the large space no marks augmented reality, human-computer interaction, and information summary. Finally, the feasibility and effectiveness of the method are verified by experiments.
Simultaneous Segmentation and Recognition: Towards more accurate Ego Gesture Recognition
Sep 18, 2019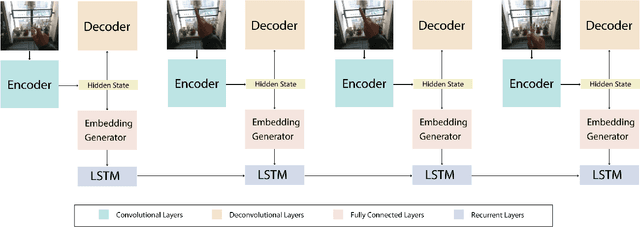
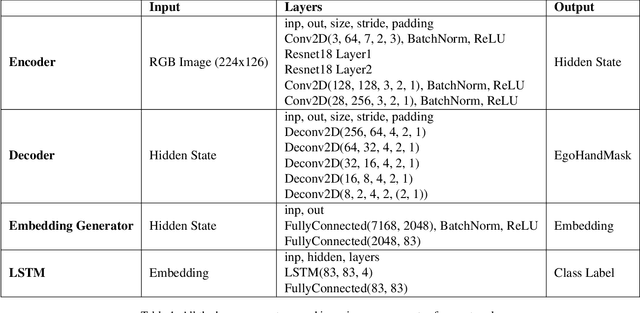
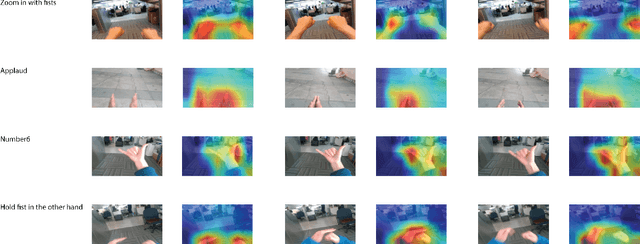

Ego hand gestures can be used as an interface in AR and VR environments. While the context of an image is important for tasks like scene understanding, object recognition, image caption generation and activity recognition, it plays a minimal role in ego hand gesture recognition. An ego hand gesture used for AR and VR environments conveys the same information regardless of the background. With this idea in mind, we present our work on ego hand gesture recognition that produces embeddings from RBG images with ego hands, which are simultaneously used for ego hand segmentation and ego gesture recognition. To this extent, we achieved better recognition accuracy (96.9%) compared to the state of the art (92.2%) on the biggest ego hand gesture dataset available publicly. We present a gesture recognition deep neural network which recognises ego hand gestures from videos (videos containing a single gesture) by generating and recognising embeddings of ego hands from image sequences of varying length. We introduce the concept of simultaneous segmentation and recognition applied to ego hand gestures, present the network architecture, the training procedure and the results compared to the state of the art on the EgoGesture dataset
FragNet: Writer Identification using Deep Fragment Networks
Mar 24, 2020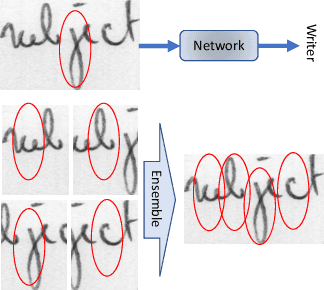
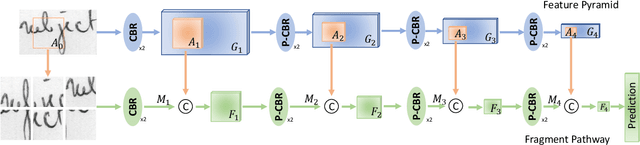
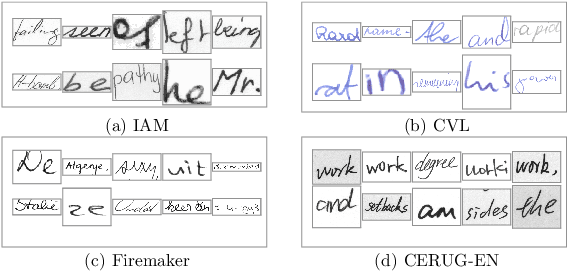
Writer identification based on a small amount of text is a challenging problem. In this paper, we propose a new benchmark study for writer identification based on word or text block images which approximately contain one word. In order to extract powerful features on these word images, a deep neural network, named FragNet, is proposed. The FragNet has two pathways: feature pyramid which is used to extract feature maps and fragment pathway which is trained to predict the writer identity based on fragments extracted from the input image and the feature maps on the feature pyramid. We conduct experiments on four benchmark datasets, which show that our proposed method can generate efficient and robust deep representations for writer identification based on both word and page images.
Model-based Asynchronous Hyperparameter Optimization
Mar 24, 2020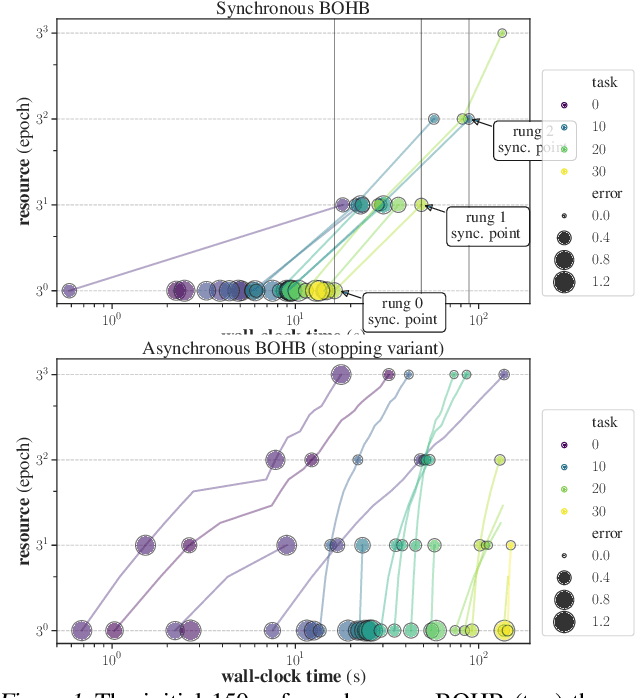


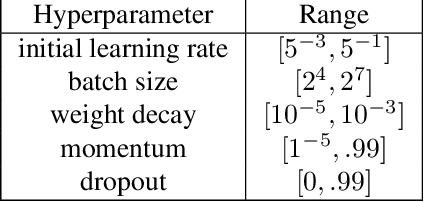
We introduce a model-based asynchronous multi-fidelity hyperparameter optimization (HPO) method, combining strengths of asynchronous Hyperband and Gaussian process-based Bayesian optimization. Our method obtains substantial speed-ups in wall-clock time over, both, synchronous and asynchronous Hyperband, as well as a prior model-based extension of the former. Candidate hyperparameters to evaluate are selected by a novel jointly dependent Gaussian process-based surrogate model over all resource levels, allowing evaluations at one level to be informed by evaluations gathered at all others. We benchmark several covariance functions and conduct extensive experiments on hyperparameter tuning for multi-layer perceptrons on tabular data, convolutional networks on image classification, and recurrent networks on language modelling, demonstrating the benefits of our approach.
A Cascaded Learning Strategy for Robust COVID-19 Pneumonia Chest X-Ray Screening
Apr 30, 2020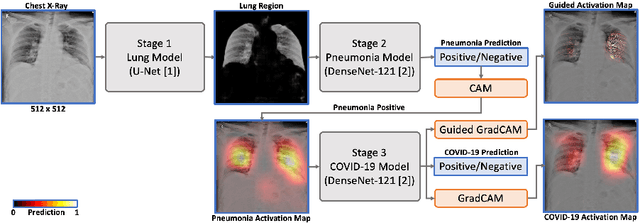
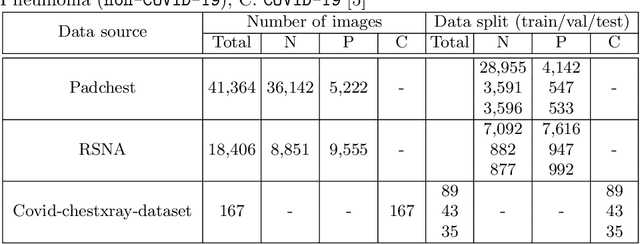
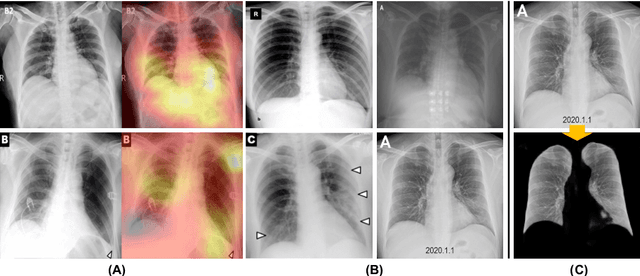
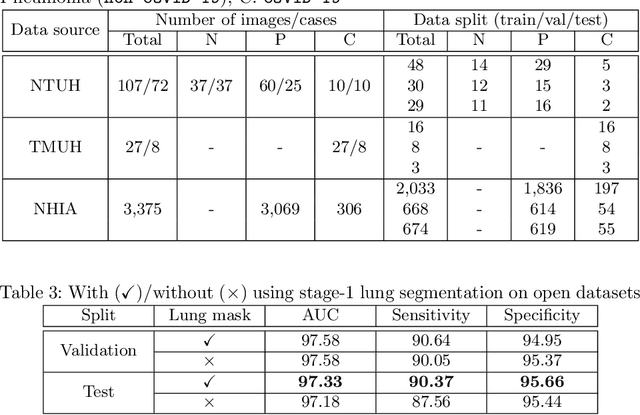
We introduce a comprehensive screening platform for the COVID-19 (a.k.a., SARS-CoV-2) pneumonia. The proposed AI-based system works on chest x-ray (CXR) images to predict whether a patient is infected with the COVID-19 disease. Although the recent international joint effort on making the availability of all sorts of open data, the public collection of CXR images is still relatively small for reliably training a deep neural network (DNN) to carry out COVID-19 prediction. To better address such inefficiency, we design a cascaded learning strategy to improve both the sensitivity and the specificity of the resulting DNN classification model. Our approach leverages a large CXR image dataset of non-COVID-19 pneumonia to generalize the original well-trained classification model via a cascaded learning scheme. The resulting screening system is shown to achieve good classification performance on the expanded dataset, including those newly added COVID-19 CXR images.
COCAS: A Large-Scale Clothes Changing Person Dataset for Re-identification
May 16, 2020

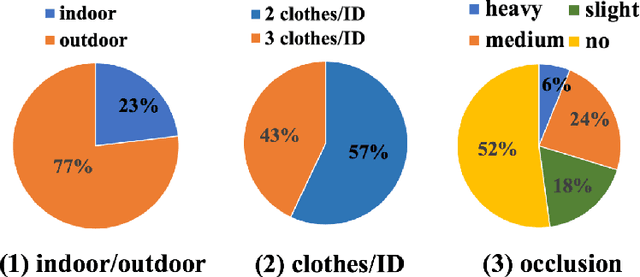
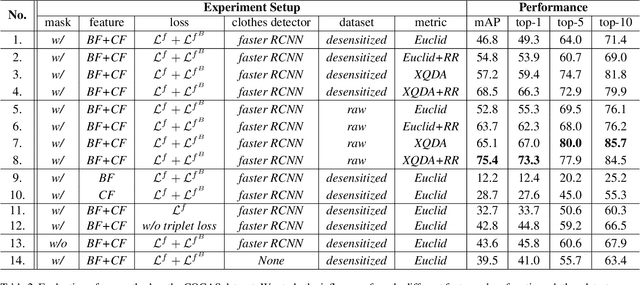
Recent years have witnessed great progress in person re-identification (re-id). Several academic benchmarks such as Market1501, CUHK03 and DukeMTMC play important roles to promote the re-id research. To our best knowledge, all the existing benchmarks assume the same person will have the same clothes. While in real-world scenarios, it is very often for a person to change clothes. To address the clothes changing person re-id problem, we construct a novel large-scale re-id benchmark named ClOthes ChAnging Person Set (COCAS), which provides multiple images of the same identity with different clothes. COCAS totally contains 62,382 body images from 5,266 persons. Based on COCAS, we introduce a new person re-id setting for clothes changing problem, where the query includes both a clothes template and a person image taking another clothes. Moreover, we propose a two-branch network named Biometric-Clothes Network (BC-Net) which can effectively integrate biometric and clothes feature for re-id under our setting. Experiments show that it is feasible for clothes changing re-id with clothes templates.
Predicting Mechanical Ventilation Requirement and Mortality in COVID-19 using Radiomics and Deep Learning on Chest Radiographs: A Multi-Institutional Study
Jul 15, 2020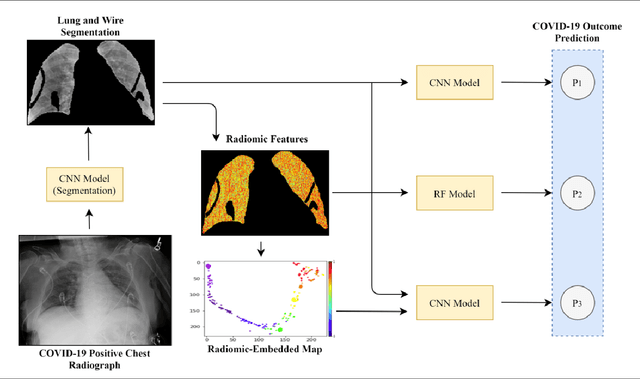

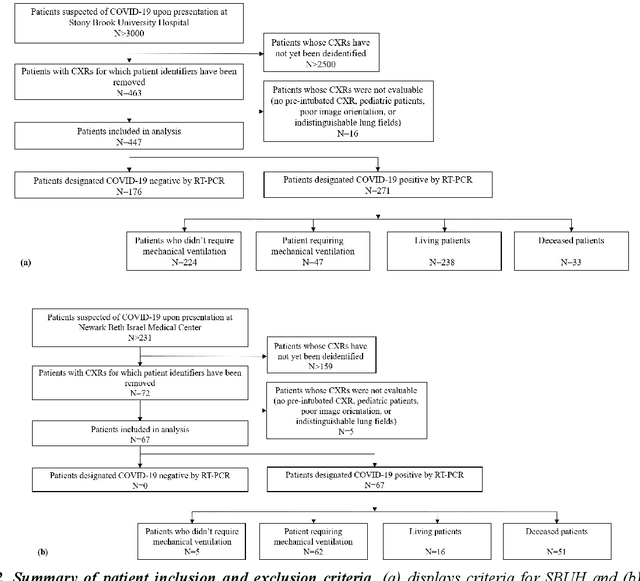
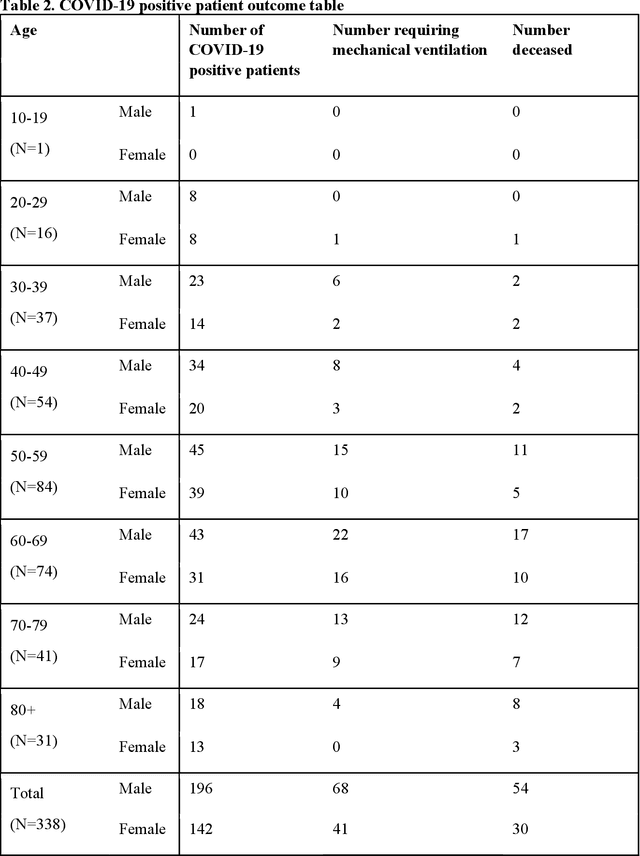
Objectives: To predict mechanical ventilation requirement and mortality using computational modeling of chest radiographs (CXR) for coronavirus disease 2019 (COVID-19) patients. We also investigate the relative advantages of deep learning (DL), radiomics, and DL of radiomic-embedded feature maps in predicting these outcomes. Methods: This two-center, retrospective study analyzed deidentified CXRs taken from 514 patients suspected of COVID-19 infection on presentation at Stony Brook University Hospital (SBUH) and Newark Beth Israel Medical Center (NBIMC) between the months of March and June 2020. A DL segmentation pipeline was developed to generate masks for both lung fields and artifacts for each CXR. Machine learning classifiers to predict mechanical ventilation requirement and mortality were trained and evaluated on 353 baseline CXRs taken from COVID-19 positive patients. A novel radiomic embedding framework is also explored for outcome prediction. Results: Classification models for mechanical ventilation requirement (test N=154) and mortality (test N=190) had AUCs of up to 0.904 and 0.936, respectively. We also found that the inclusion of radiomic-embedded maps improved DL model predictions of clinical outcomes. Conclusions: We demonstrate the potential for computerized analysis of baseline CXR in predicting disease outcomes in COVID-19 patients. Our results also suggest that radiomic embedding improves DL models in medical image analysis, a technique that might be explored further in other pathologies. The models proposed in this study and the prognostic information they provide, complementary to other clinical data, might be used to aid physician decision making and resource allocation during the COVID-19 pandemic.
Automatic Frame Selection Using MLP Neural Network in Ultrasound Elastography
Nov 13, 2019
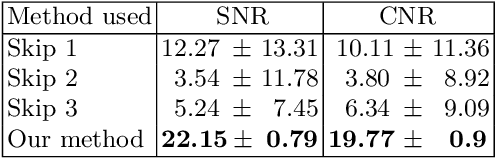
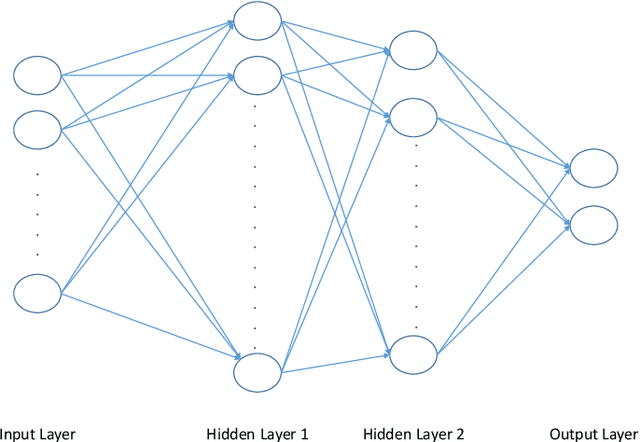
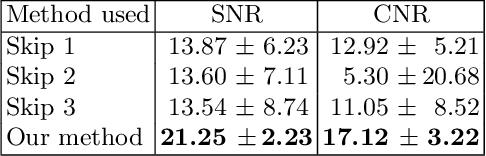
Ultrasound elastography estimates the mechanical properties of the tissue from two Radio-Frequency (RF) frames collected before and after tissue deformation due to an external or internal force. This work focuses on strain imaging in quasi-static elastography, where the tissue undergoes slow deformations and strain images are estimated as a surrogate for elasticity modulus. The quality of the strain image depends heavily on the underlying deformation, and even the best strain estimation algorithms cannot estimate a good strain image if the underlying deformation is not suitable. Herein, we introduce a new method for tracking the RF frames and selecting automatically the best possible pair. We achieve this by decomposing the axial displacement image into a linear combination of principal components (which are calculated offline) multiplied by their corresponding weights. We then use the calculated weights as the input feature vector to a multi-layer perceptron (MLP) classifier. The output is a binary decision, either 1 which refers to good frames, or 0 which refers to bad frames. Our MLP model is trained on in-vivo dataset and tested on different datasets of both in-vivo and phantom data. Results show that by using our technique, we would be able to achieve higher quality strain images compared to the traditional methods of picking up pairs that are 1, 2 or 3 frames apart. The training phase of our algorithm is computationally expensive and takes few hours, but it is only done once. The testing phase chooses the optimal pair of frames in only 1.9 ms.