 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Feature Extraction for Hyperspectral Imagery: The Evolution from Shallow to Deep
Mar 05, 2020
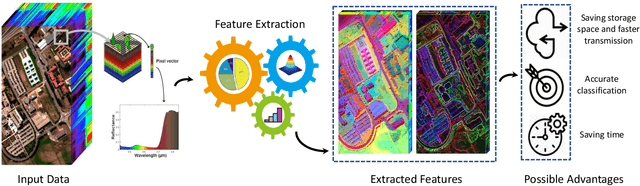
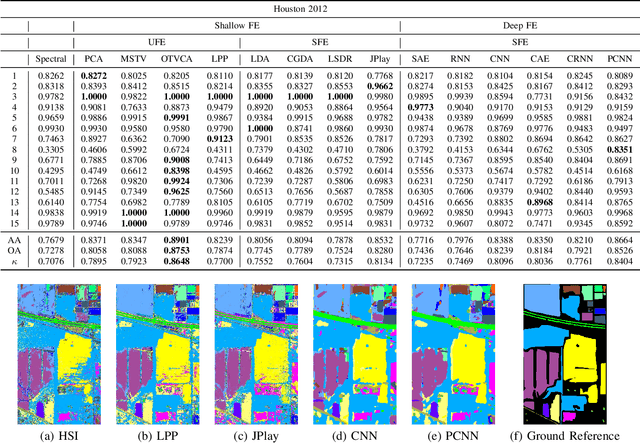
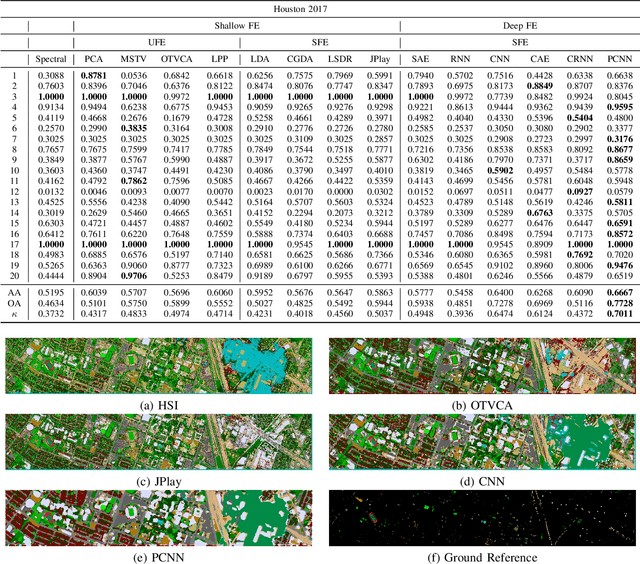

Hyperspectral images provide detailed spectral information through hundreds of (narrow) spectral channels (also known as dimensionality or bands) with continuous spectral information that can accurately classify diverse materials of interest. The increased dimensionality of such data makes it possible to significantly improve data information content but provides a challenge to the conventional techniques (the so-called curse of dimensionality) for accurate analysis of hyperspectral images. Feature extraction, as a vibrant field of research in the hyperspectral community, evolved through decades of research to address this issue and extract informative features suitable for data representation and classification. The advances in feature extraction have been inspired by two fields of research, including the popularization of image and signal processing as well as machine (deep) learning, leading to two types of feature extraction approaches named shallow and deep techniques. This article outlines the advances in feature extraction approaches for hyperspectral imagery by providing a technical overview of the state-of-the-art techniques, providing useful entry points for researchers at different levels, including students, researchers, and senior researchers, willing to explore novel investigations on this challenging topic. % by supplying a rich amount of detail and references. In more detail, this paper provides a bird's eye view over shallow (both supervised and unsupervised) and deep feature extraction approaches specifically dedicated to the topic of hyperspectral feature extraction and its application on hyperspectral image classification. Additionally, this paper compares 15 advanced techniques with an emphasis on their methodological foundations in terms of classification accuracies.
FCSR-GAN: Joint Face Completion and Super-resolution via Multi-task Learning
Nov 04, 2019
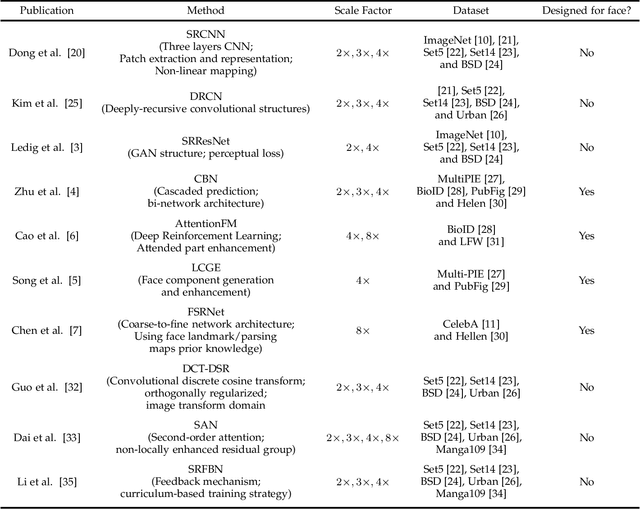
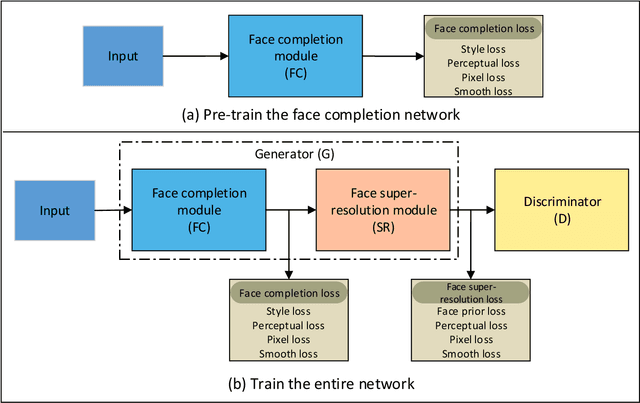
Combined variations containing low-resolution and occlusion often present in face images in the wild, e.g., under the scenario of video surveillance. While most of the existing face image recovery approaches can handle only one type of variation per model, in this work, we propose a deep generative adversarial network (FCSR-GAN) for performing joint face completion and face super-resolution via multi-task learning. The generator of FCSR-GAN aims to recover a high-resolution face image without occlusion given an input low-resolution face image with occlusion. The discriminator of FCSR-GAN uses a set of carefully designed losses (an adversarial loss, a perceptual loss, a pixel loss, a smooth loss, a style loss, and a face prior loss) to assure the high quality of the recovered high-resolution face images without occlusion. The whole network of FCSR-GAN can be trained end-to-end using our two-stage training strategy. Experimental results on the public-domain CelebA and Helen databases show that the proposed approach outperforms the state-of-the-art methods in jointly performing face super-resolution (up to 8 $\times$) and face completion, and shows good generalization ability in cross-database testing. Our FCSR-GAN is also useful for improving face identification performance when there are low-resolution and occlusion in face images.
Near-Infrared Image Dehazing Via Color Regularization
Oct 01, 2016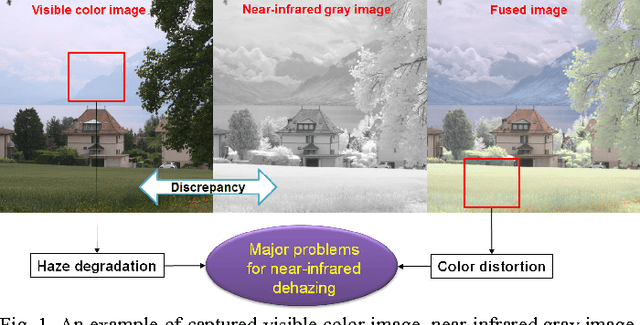



Near-infrared imaging can capture haze-free near-infrared gray images and visible color images, according to physical scattering models, e.g., Rayleigh or Mie models. However, there exist serious discrepancies in brightness and image structures between the near-infrared gray images and the visible color images. The direct use of the near-infrared gray images brings about another color distortion problem in the dehazed images. Therefore, the color distortion should also be considered for near-infrared dehazing. To reflect this point, this paper presents an approach of adding a new color regularization to conventional dehazing framework. The proposed color regularization can model the color prior for unknown haze-free images from two captured images. Thus, natural-looking colors and fine details can be induced on the dehazed images. The experimental results show that the proposed color regularization model can help remove the color distortion and the haze at the same time. Also, the effectiveness of the proposed color regularization is verified by comparing with other conventional regularizations. It is also shown that the proposed color regularization can remove the edge artifacts which arise from the use of the conventional dark prior model.
LightConvPoint: convolution for points
Apr 09, 2020
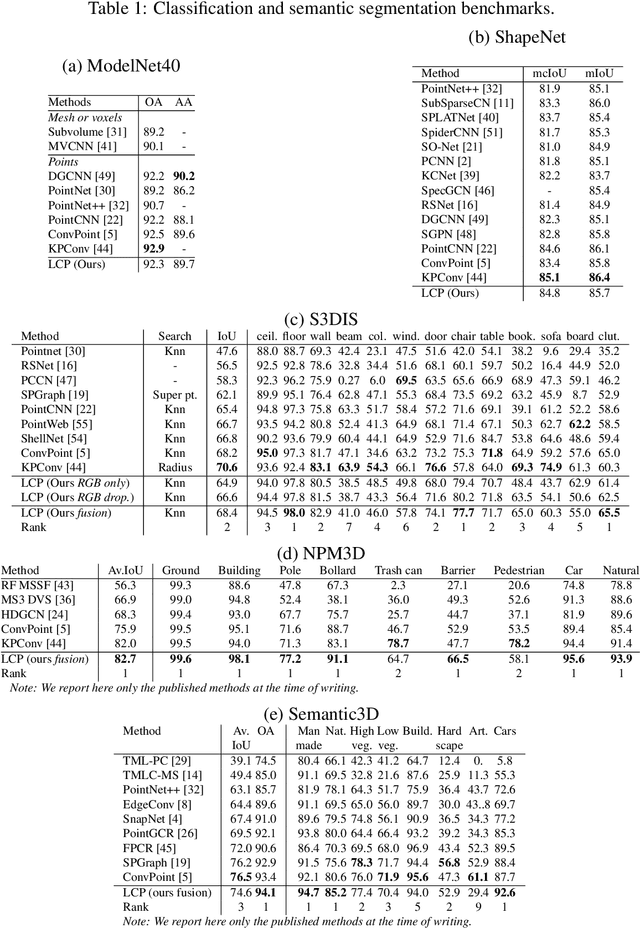
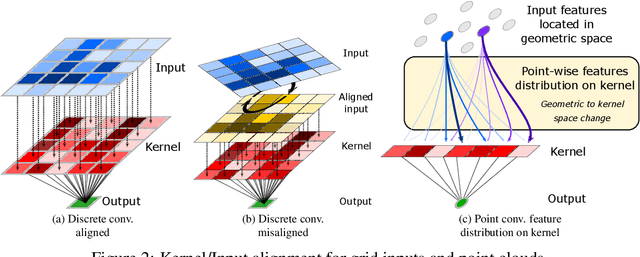
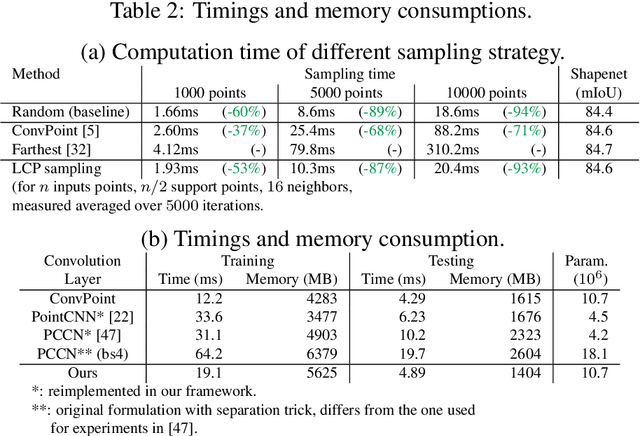
Recent state-of-the-art methods for point cloud semantic segmentation are based on convolution defined for point clouds. In this paper, we propose a formulation of the convolution for point cloud directly designed from the discrete convolution in image processing. The resulting formulation underlines the separation between the discrete kernel space and the geometric space where the points lies. The link between the two space is done by a change space matrix $\mathbf{A}$ which distributes the input features on the convolution kernel. Several existing methods fall under this formulation. We show that the matrix $\mathbf{A}$ can be easily estimated with neural networks. Finally, we show competitive results on several semantic segmentation benchmarks while being efficient both in computation time and memory.
Deep Learning Improves Contrast in Low-Fluence Photoacoustic Imaging
Apr 19, 2020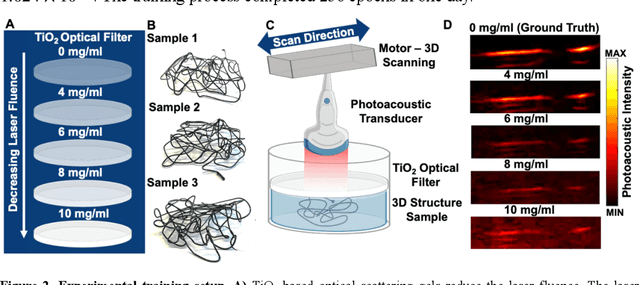
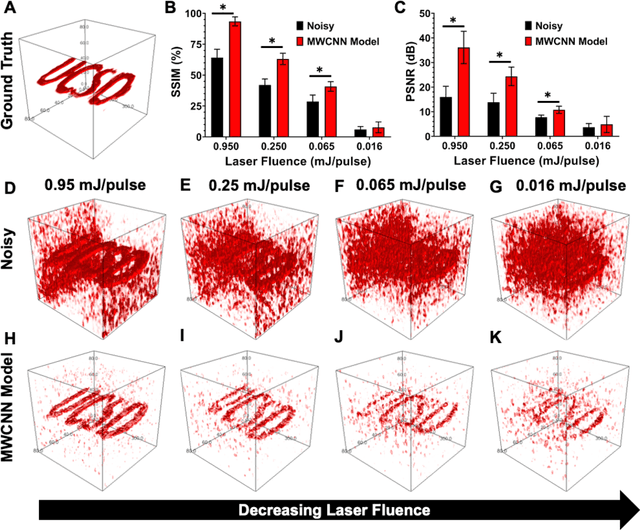
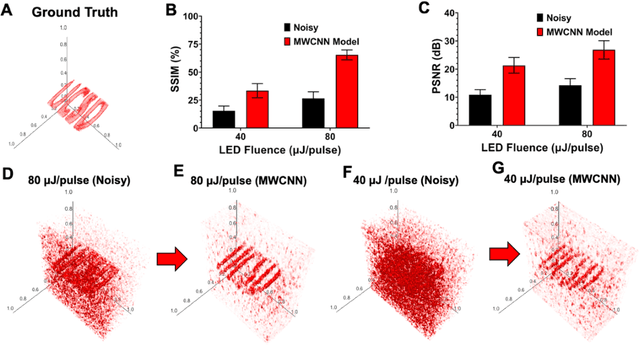
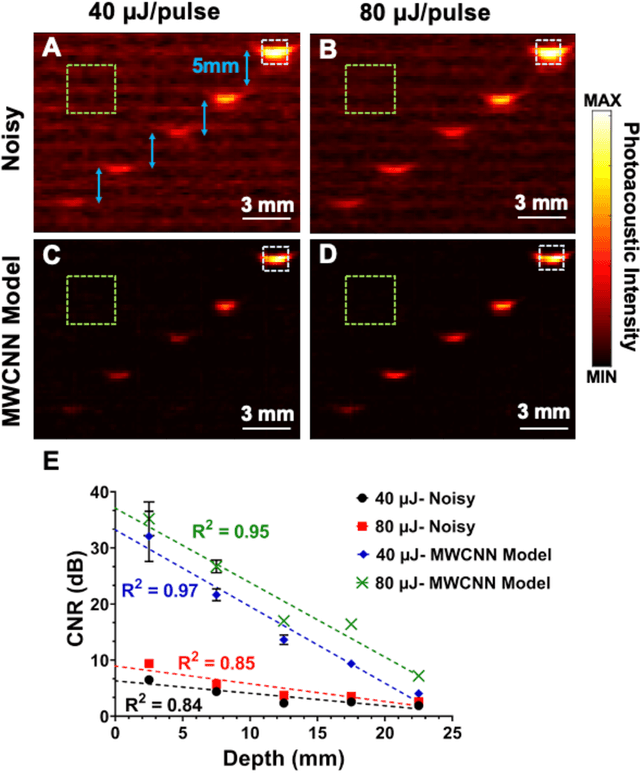
Low fluence illumination sources can facilitate clinical transition of photoacoustic imaging because they are rugged, portable, affordable, and safe. However, these sources also decrease image quality due to their low fluence. Here, we propose a denoising method using a multi-level wavelet-convolutional neural network to map low fluence illumination source images to its corresponding high fluence excitation map. Quantitative and qualitative results show a significant potential to remove the background noise and preserve the structures of target. Substantial improvements up to 2.20, 2.25, and 4.3-fold for PSNR, SSIM, and CNR metrics were observed, respectively. We also observed enhanced contrast (up to 1.76-fold) in an in vivo application using our proposed methods. We suggest that this tool can improve the value of such sources in photoacoustic imaging.
Towards Diverse and Natural Image Descriptions via a Conditional GAN
Aug 11, 2017
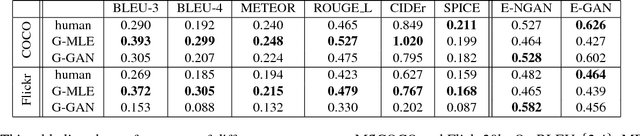
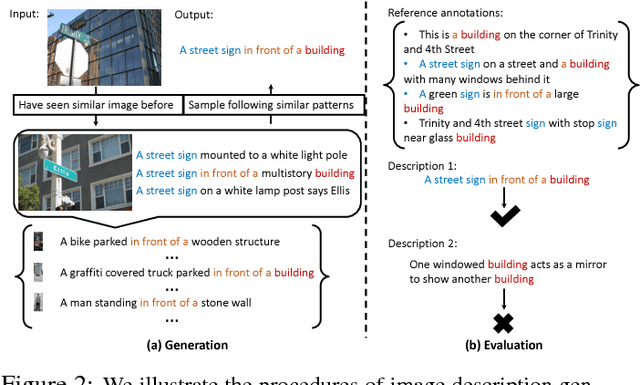

Despite the substantial progress in recent years, the image captioning techniques are still far from being perfect.Sentences produced by existing methods, e.g. those based on RNNs, are often overly rigid and lacking in variability. This issue is related to a learning principle widely used in practice, that is, to maximize the likelihood of training samples. This principle encourages high resemblance to the "ground-truth" captions while suppressing other reasonable descriptions. Conventional evaluation metrics, e.g. BLEU and METEOR, also favor such restrictive methods. In this paper, we explore an alternative approach, with the aim to improve the naturalness and diversity -- two essential properties of human expression. Specifically, we propose a new framework based on Conditional Generative Adversarial Networks (CGAN), which jointly learns a generator to produce descriptions conditioned on images and an evaluator to assess how well a description fits the visual content. It is noteworthy that training a sequence generator is nontrivial. We overcome the difficulty by Policy Gradient, a strategy stemming from Reinforcement Learning, which allows the generator to receive early feedback along the way. We tested our method on two large datasets, where it performed competitively against real people in our user study and outperformed other methods on various tasks.
Spiking Machine Intelligence: What we can learn from biology and how spiking Neural Networks can help to improve Machine Learning
Apr 28, 2020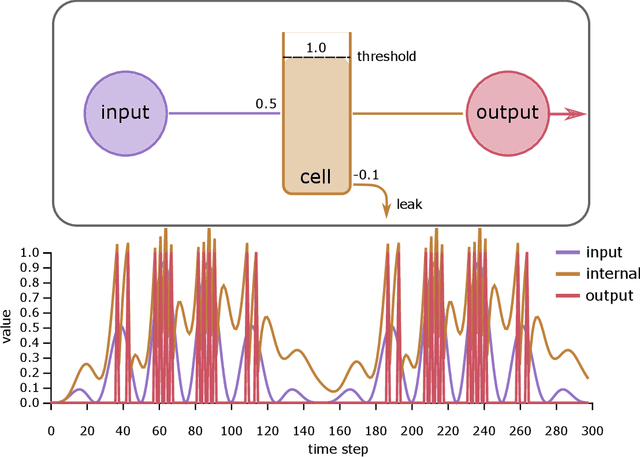
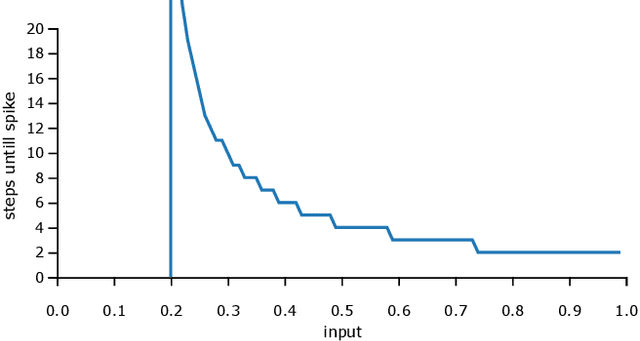
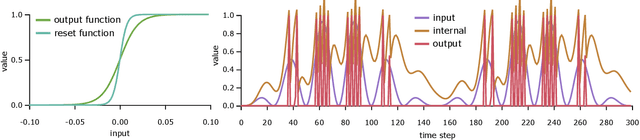
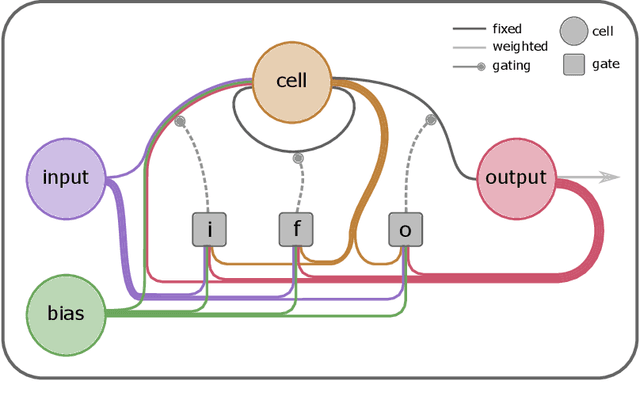
Up to now, modern Machine Learning is based on fitting high dimensional functions to enormous data sets, taking advantage of huge hardware resources. We show that biologically inspired neuron models such as the Integrate-and-Fire (LIF) neurons provide novel and efficient ways of information encoding. They can be integrated in Machine Learning models, and are a potential target to improve Machine Learning performance. Thus, we systematically analyze the LIF neuron. We start by deriving simple integration equations to which even a gradient can be assigned. Additionally, we prove that a Long-Short-Term-Memory unit can be tuned to show similar spiking properties. Additionally, LIF units are applied to an image classification task, trained with backpropagation. With this study we want to contribute to the current efforts to enhance Machine Intelligence by integrating principles from biology.
Contact Area Detector using Cross View Projection Consistency for COVID-19 Projects
Aug 18, 2020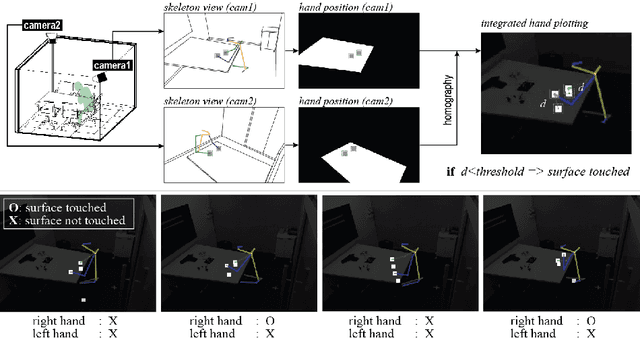

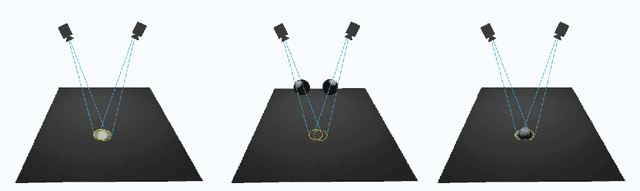
The ability to determine what parts of objects and surfaces people touch as they go about their daily lives would be useful in understanding how the COVID-19 virus spreads. To determine whether a person has touched an object or surface using visual data, images, or videos, is a hard problem. Computer vision 3D reconstruction approaches project objects and the human body from the 2D image domain to 3D and perform 3D space intersection directly. However, this solution would not meet the accuracy requirement in applications due to projection error. Another standard approach is to train a neural network to infer touch actions from the collected visual data. This strategy would require significant amounts of training data to generalize over scale and viewpoint variations. A different approach to this problem is to identify whether a person has touched a defined object. In this work, we show that the solution to this problem can be straightforward. Specifically, we show that the contact between an object and a static surface can be identified by projecting the object onto the static surface through two different viewpoints and analyzing their 2D intersection. The object contacts the surface when the projected points are close to each other; we call this cross view projection consistency. Instead of doing 3D scene reconstruction or transfer learning from deep networks, a mapping from the surface in the two camera views to the surface space is the only requirement. For planar space, this mapping is the Homography transformation. This simple method can be easily adapted to real-life applications. In this paper, we apply our method to do office occupancy detection for studying the COVID-19 transmission pattern from an office desk in a meeting room using the contact information.
UnMask: Adversarial Detection and Defense Through Robust Feature Alignment
Feb 21, 2020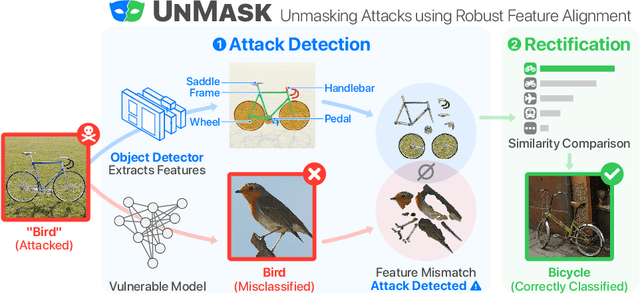
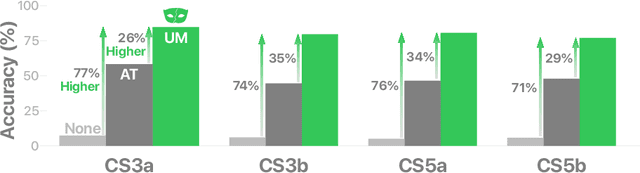
Deep learning models are being integrated into a wide range of high-impact, security-critical systems, from self-driving cars to medical diagnosis. However, recent research has demonstrated that many of these deep learning architectures are vulnerable to adversarial attacks--highlighting the vital need for defensive techniques to detect and mitigate these attacks before they occur. To combat these adversarial attacks, we developed UnMask, an adversarial detection and defense framework based on robust feature alignment. The core idea behind UnMask is to protect these models by verifying that an image's predicted class ("bird") contains the expected robust features (e.g., beak, wings, eyes). For example, if an image is classified as "bird", but the extracted features are wheel, saddle and frame, the model may be under attack. UnMask detects such attacks and defends the model by rectifying the misclassification, re-classifying the image based on its robust features. Our extensive evaluation shows that UnMask (1) detects up to 96.75% of attacks, with a false positive rate of 9.66% and (2) defends the model by correctly classifying up to 93% of adversarial images produced by the current strongest attack, Projected Gradient Descent, in the gray-box setting. UnMask provides significantly better protection than adversarial training across 8 attack vectors, averaging 31.18% higher accuracy. Our proposed method is architecture agnostic and fast. We open source the code repository and data with this paper: https://github.com/unmaskd/unmask.
Road Mapping in Low Data Environments with OpenStreetMap
Jun 14, 2020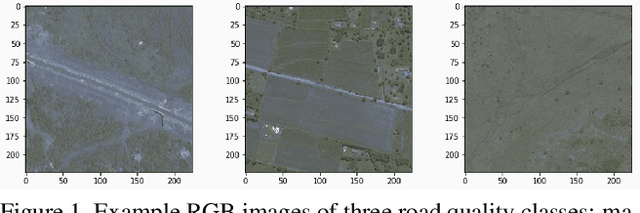
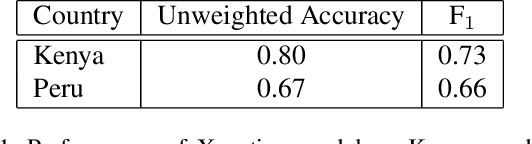
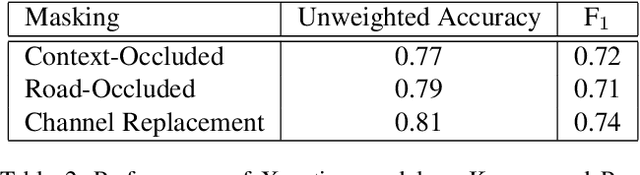
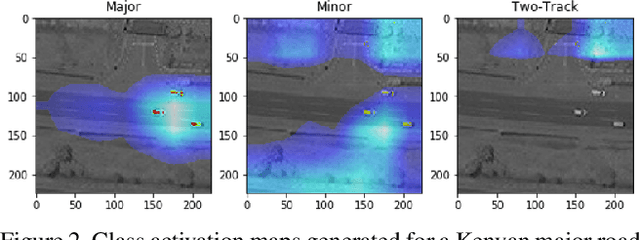
Roads are among the most essential components of any country's infrastructure. By facilitating the movement and exchange of people, ideas, and goods, they support economic and cultural activity both within and across local and international borders. A comprehensive, up-to-date mapping of the geographical distribution of roads and their quality thus has the potential to act as an indicator for broader economic development. Such an indicator has a variety of high-impact applications, particularly in the planning of rural development projects where up-to-date infrastructure information is not available. This work investigates the viability of high resolution satellite imagery and crowd-sourced resources like OpenStreetMap in the construction of such a mapping. We experiment with state-of-the-art deep learning methods to explore the utility of OpenStreetMap data in road classification and segmentation tasks. We also compare the performance of models in different mask occlusion scenarios as well as out-of-country domains. Our comparison raises important pitfalls to consider in image-based infrastructure classification tasks, and shows the need for local training data specific to regions of interest for reliable performance.