 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DR-KFD: A Differentiable Visual Metric for 3D Shape Reconstruction
Nov 20, 2019
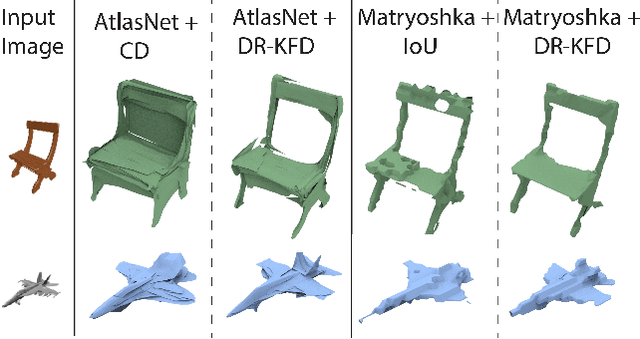
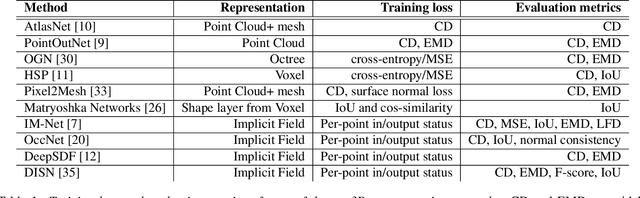
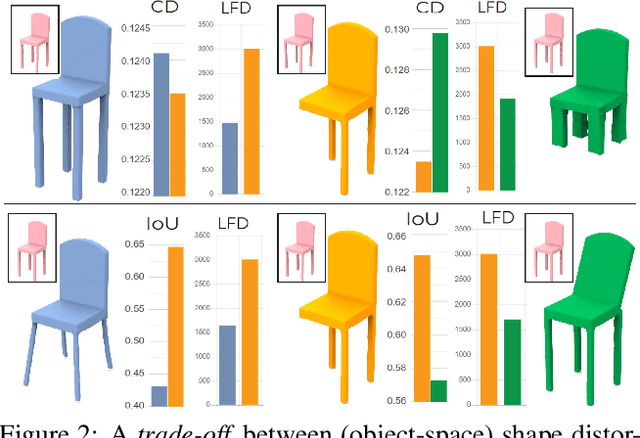
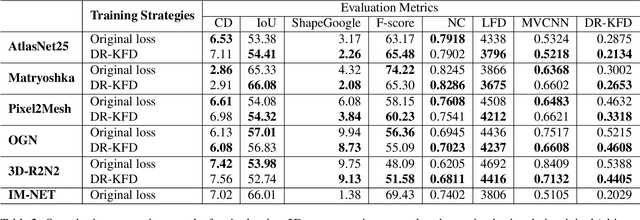
We advocate the use of differential visual shape metrics to train deep neural networks for 3D reconstruction. We introduce such a metric which compares two 3D shapes by measuring visual, image-space differences between multiview images differentiably rendered from the shapes. Furthermore, we develop a differentiable image-space distance based on mean-squared errors defined over Hard- Net features computed from probabilistic keypoint maps of the compared images. Our differential visual shape metric can be easily plugged into various reconstruction networks, replacing the object-space distortion measures, such as Chamfer or Earth Mover distances, so as to optimize the network weights to produce reconstruction results with better structural fidelity and visual quality. We demonstrate this both objectively, using well-known visual shape metrics for retrieval and classification tasks that are independent from our new metric, and subjectively through a perceptual study.
Rice grain disease identification using dual phase convolutional neural network-based system aimed at small dataset
Apr 21, 2020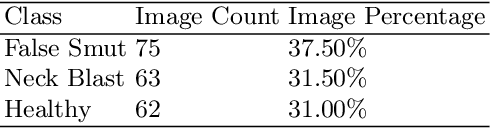

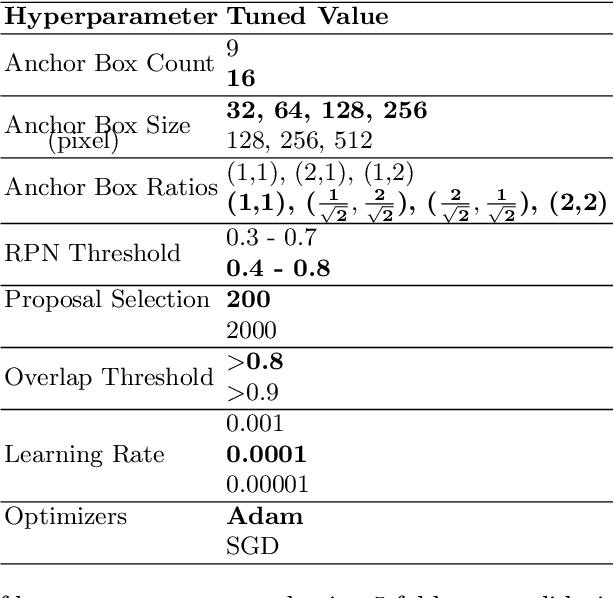
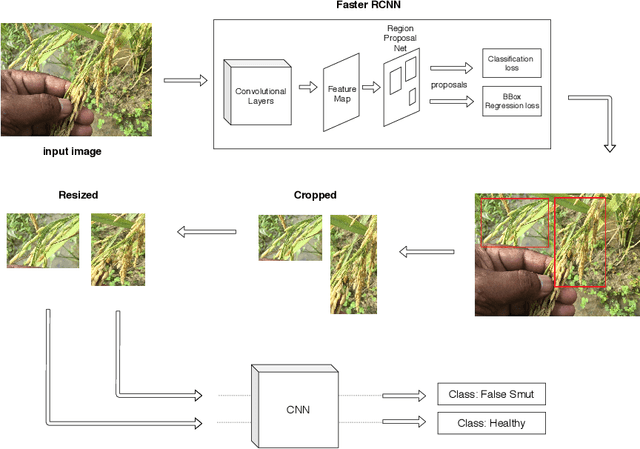
Although Convolutional neural networks (CNNs) are widely used for plant disease detection, they require a large number of training samples when dealing with wide variety of heterogeneous background. In this work, a CNN based dual phase method has been proposed which can work effectively on small rice grain disease dataset with heterogeneity. At the first phase, Faster RCNN method is applied for cropping out the significant portion (rice grain) from the image. This initial phase results in a secondary dataset of rice grains devoid of heterogeneous background. Disease classification is performed on such derived and simplified samples using CNN architecture. Comparison of the dual phase approach with straight forward application of CNN on the small grain dataset shows the effectiveness of the proposed method which provides a 5 fold cross validation accuracy of 88.07%.
Rethinking Class Relations: Absolute-relative Few-shot Learning
Jan 12, 2020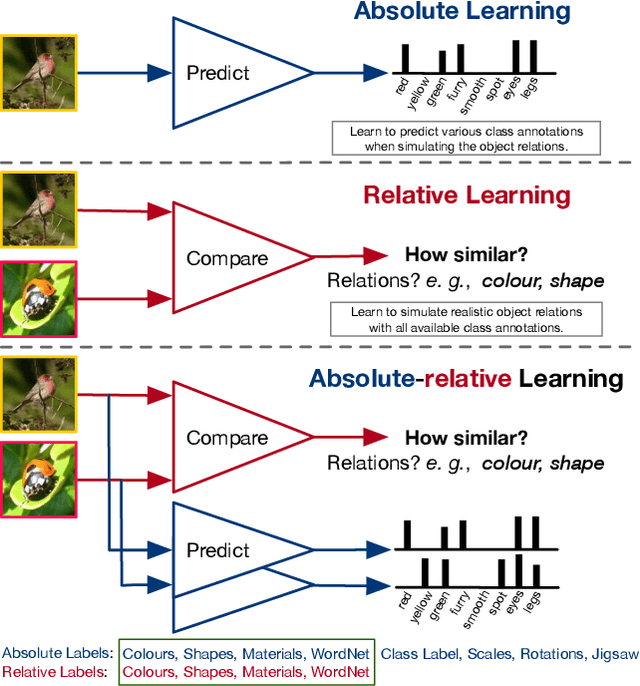
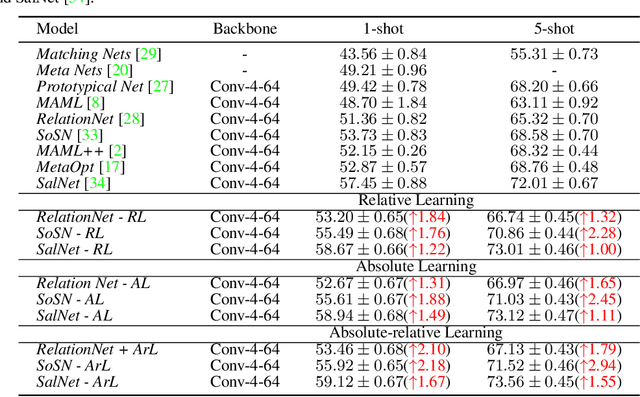
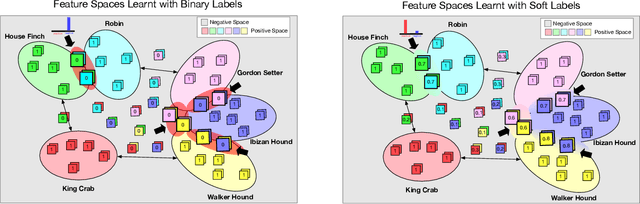
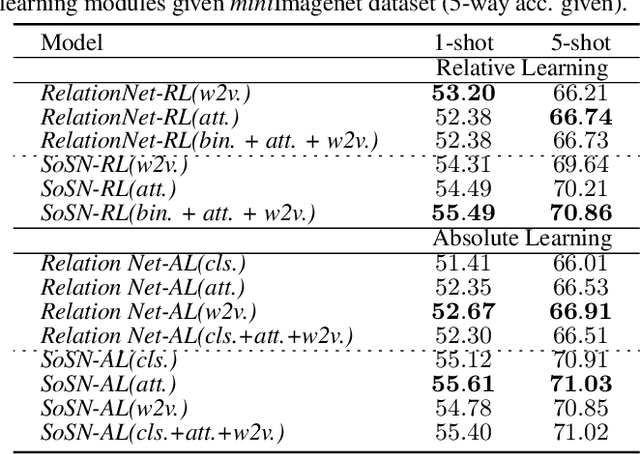
The majority of existing few-shot learning describe image relations with {0,1} binary labels. However, such binary relations are insufficient to teach the network complicated real-world relations, due to the lack of decision smoothness. Furthermore, current few-shot learning models capture only the similarity via relation labels, but they are not exposed to class concepts associated with objects, which is likely detrimental to the classification performance due to underutilization of the available class labels. To paraphrase, while children learn the concept of tiger from a few of examples with ease, and while they learn from comparisons of tiger to other animals, they are also taught the actual concept names. Thus, we hypothesize that in fact both similarity and class concept learning must be occurring simultaneously. With these observations at hand, we study the fundamental problem of simplistic class modeling in current few-shot learning, we rethink the relations between class concepts, and propose a novel absolute-relative learning paradigm to fully take advantage of label information to refine the image representations and correct the relation understanding. Our proposed absolute-relative learning paradigm improves the performance of several the state-of-the-art models on publicly available datasets.
CRF Learning with CNN Features for Image Segmentation
Mar 28, 2015

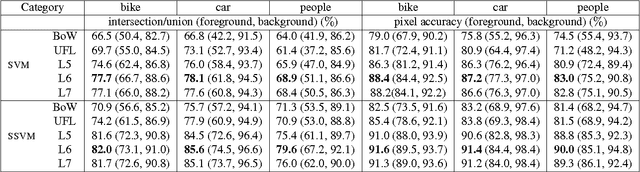

Conditional Random Rields (CRF) have been widely applied in image segmentations. While most studies rely on hand-crafted features, we here propose to exploit a pre-trained large convolutional neural network (CNN) to generate deep features for CRF learning. The deep CNN is trained on the ImageNet dataset and transferred to image segmentations here for constructing potentials of superpixels. Then the CRF parameters are learnt using a structured support vector machine (SSVM). To fully exploit context information in inference, we construct spatially related co-occurrence pairwise potentials and incorporate them into the energy function. This prefers labelling of object pairs that frequently co-occur in a certain spatial layout and at the same time avoids implausible labellings during the inference. Extensive experiments on binary and multi-class segmentation benchmarks demonstrate the promise of the proposed method. We thus provide new baselines for the segmentation performance on the Weizmann horse, Graz-02, MSRC-21, Stanford Background and PASCAL VOC 2011 datasets.
FocusLiteNN: High Efficiency Focus Quality Assessment for Digital Pathology
Jul 11, 2020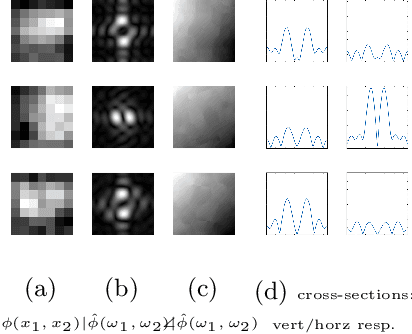
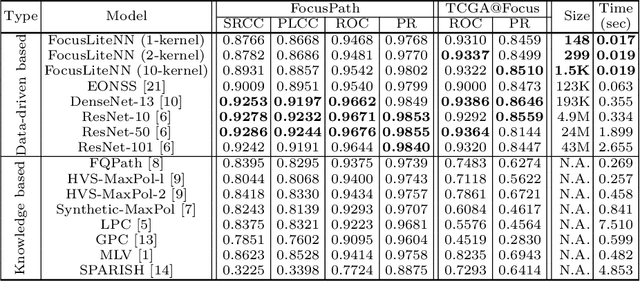
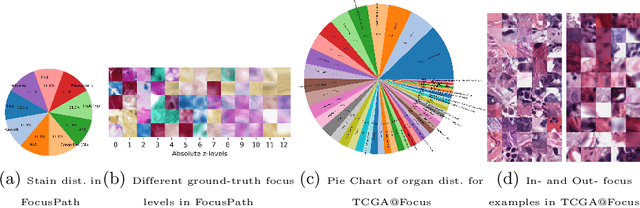
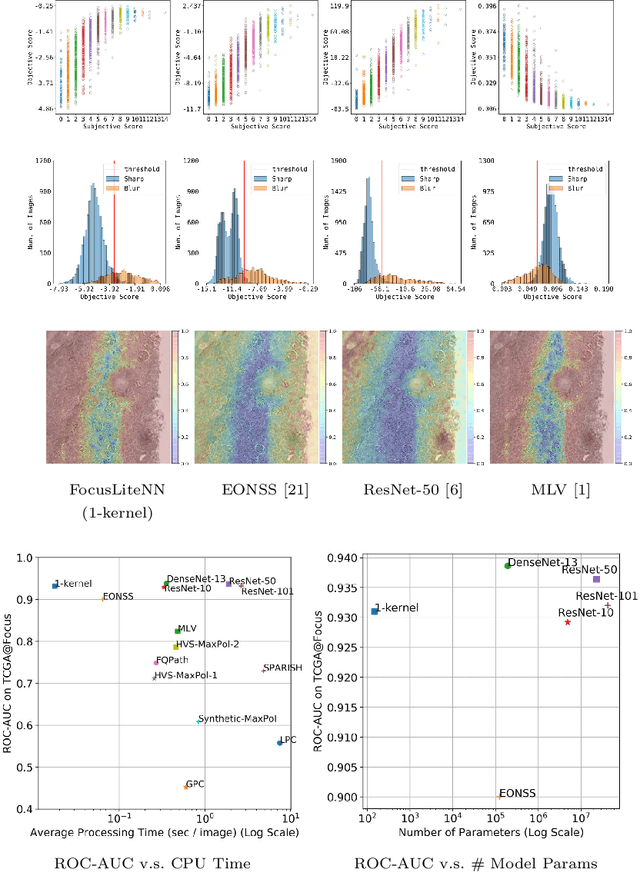
Out-of-focus microscopy lens in digital pathology is a critical bottleneck in high-throughput Whole Slide Image (WSI) scanning platforms, for which pixel-level automated Focus Quality Assessment (FQA) methods are highly desirable to help significantly accelerate the clinical workflows. Existing FQA methods include both knowledge-driven and data-driven approaches. While data-driven approaches such as Convolutional Neural Network (CNN) based methods have shown great promises, they are difficult to use in practice due to their high computational complexity and lack of transferability. Here, we propose a highly efficient CNN-based model that maintains fast computations similar to the knowledge-driven methods without excessive hardware requirements such as GPUs. We create a training dataset using FocusPath which encompasses diverse tissue slides across nine different stain colors, where the stain diversity greatly helps the model to learn diverse color spectrum and tissue structures. In our attempt to reduce the CNN complexity, we find with surprise that even trimming down the CNN to the minimal level, it still achieves a highly competitive performance. We introduce a novel comprehensive evaluation dataset, the largest of its kind, annotated and compiled from TCGA repository for model assessment and comparison, for which the proposed method exhibits superior precision-speed trade-off when compared with existing knowledge-driven and data-driven FQA approaches.
Red-GAN: Attacking class imbalance via conditioned generation. Yet another medical imaging perspective
Apr 30, 2020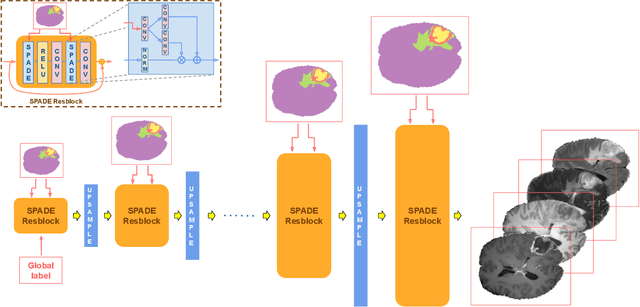

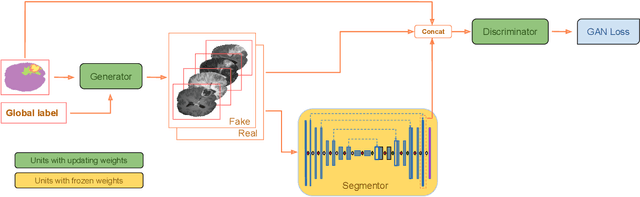
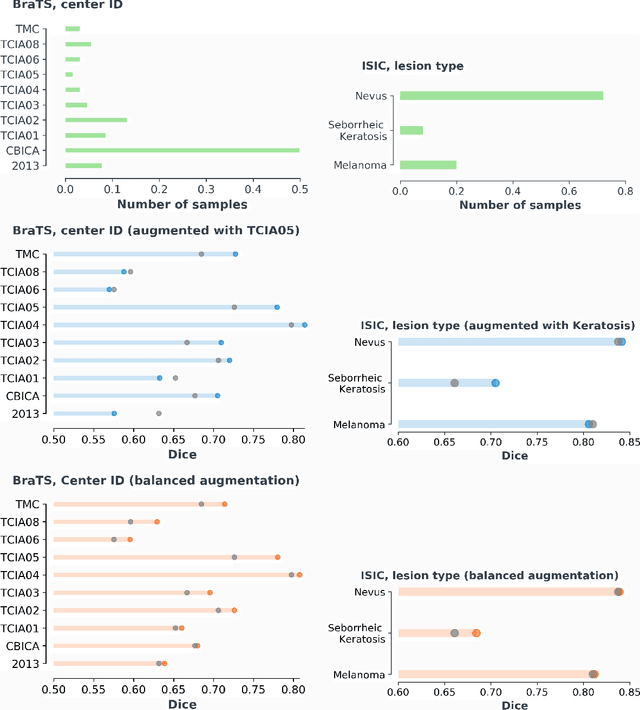
Exploiting learning algorithms under scarce data regimes is a limitation and a reality of the medical imaging field. In an attempt to mitigate the problem, we propose a data augmentation protocol based on generative adversarial networks. We condition the networks at a pixel-level (segmentation mask) and at a global-level information (acquisition environment or lesion type). Such conditioning provides immediate access to the image-label pairs while controlling global class specific appearance of the synthesized images. To stimulate synthesis of the features relevant for the segmentation task, an additional passive player in a form of segmentor is introduced into the the adversarial game. We validate the approach on two medical datasets: BraTS, ISIC. By controlling the class distribution through injection of synthetic images into the training set we achieve control over the accuracy levels of the datasets' classes.
RTOP: A Conceptual and Computational Framework for General Intelligence
Oct 23, 2019



A novel general intelligence model is proposed with three types of learning. A unified sequence of the foreground percept trace and the command trace translates into direct and time-hop observation paths to form the basis of Raw learning. Raw learning includes the formation of image-image associations, which lead to the perception of temporal and spatial relationships among objects and object parts; and the formation of image-audio associations, which serve as the building blocks of language. Offline identification of similar segments in the observation paths and their subsequent reduction into a common segment through merging of memory nodes leads to Generalized learning. Generalization includes the formation of interpolated sensory nodes for robust and generic matching, the formation of sensory properties nodes for specific matching and superimposition, and the formation of group nodes for simpler logic pathways. Online superimposition of memory nodes across multiple predictions, primarily the superimposition of images on the internal projection canvas, gives rise to Innovative learning and thought. The learning of actions happens the same way as raw learning while the action determination happens through the utility model built into the raw learnings, the utility function being the pleasure and pain of the physical senses.
Streaming Networks: Enable A Robust Classification of Noise-Corrupted Images
Oct 23, 2019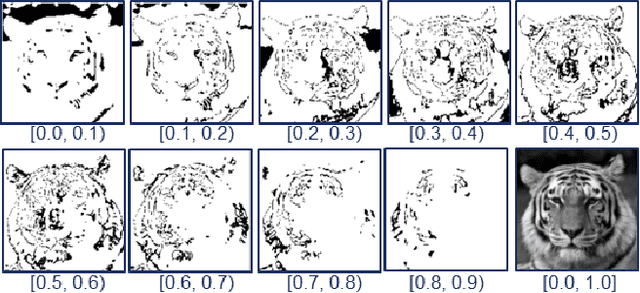
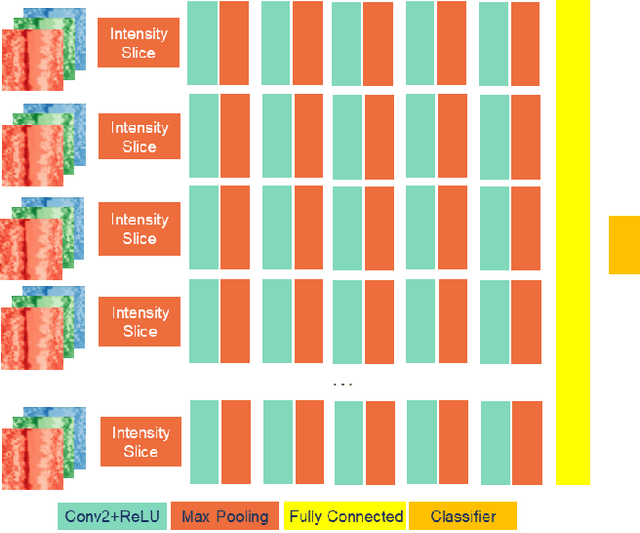
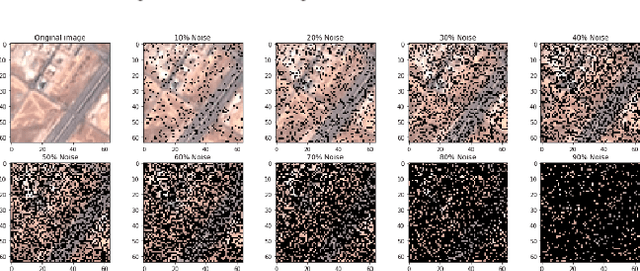
The convolution neural nets (conv nets) have achieved a state-of-the-art performance in many applications of image and video processing. The most recent studies illustrate that the conv nets are fragile in terms of recognition accuracy to various image distortions such as noise, scaling, rotation, etc. In this study we focus on the problem of robust recognition accuracy of random noise distorted images. A common solution to this problem is either to add a lot of noisy images into a training dataset, which can be very costly, or use sophisticated loss function and denoising techniques. We introduce a novel conv net architecture with multiple streams. Each stream is taking a certain intensity slice of the original image as an input, and stream parameters are trained independently. We call this novel network a "Streaming Net". Our results indicate that Streaming Net outperforms 1-stream conv net (employed as a single stream) and 1-stream wide conv net (employs the same number of filters as Streaming Net) in recognition accuracy of noise-corrupted images, while producing the same or higher recognition accuracy of no noise images in almost all of the tests. Thus, we introduce a new simple method to increase robustness of recognition of noisy images without using data generation or sophisticated training techniques.
Adversarial Robustness on In- and Out-Distribution Improves Explainability
Mar 20, 2020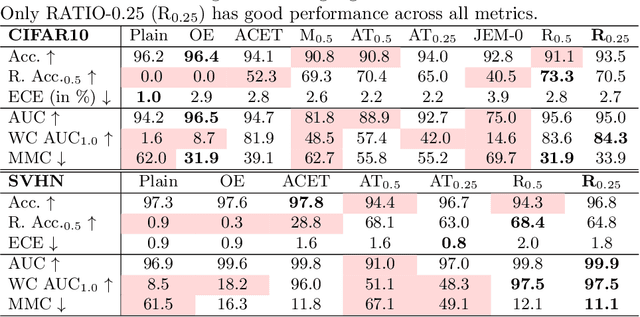


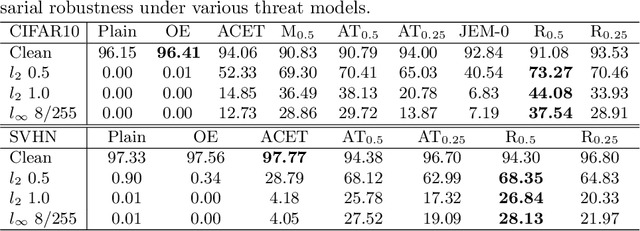
Neural networks have led to major improvements in image classification but suffer from being non-robust to adversarial changes, unreliable uncertainty estimates on out-distribution samples and their inscrutable black-box decisions. In this work we propose RATIO, a training procedure for Robustness via Adversarial Training on In- and Out-distribution, which leads to robust models with reliable and robust confidence estimates on the out-distribution. RATIO has similar generative properties to adversarial training so that visual counterfactuals produce class specific features. While adversarial training comes at the price of lower clean accuracy, RATIO achieves state-of-the-art $l_2$-adversarial robustness on CIFAR10 and maintains better clean accuracy.
GA-GAN: CT reconstruction from Biplanar DRRs using GAN with Guided Attention
Sep 27, 2019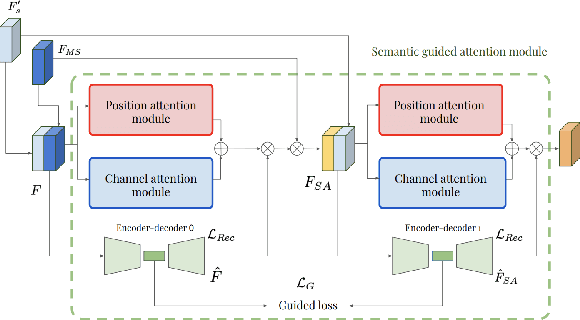
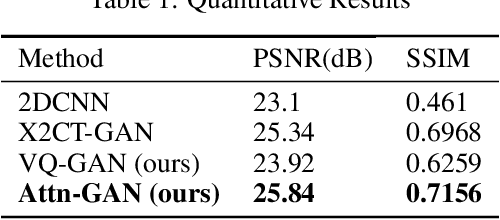
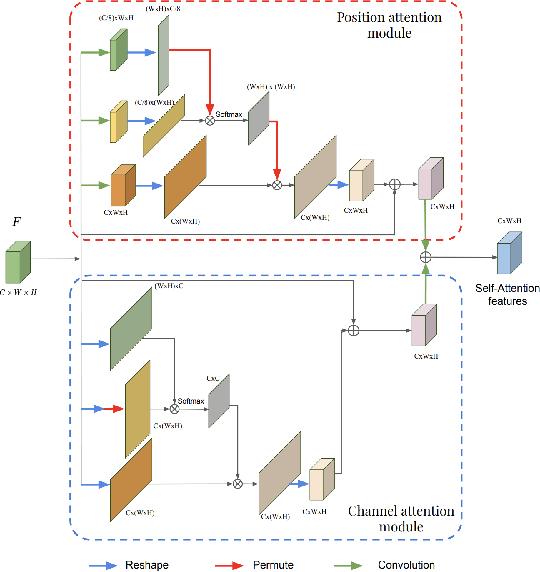
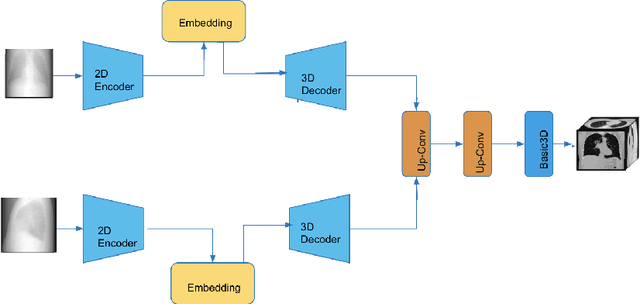
This work investigates the use of guided attention in the reconstruction of CTvolumes from biplanar DRRs. We try to improve the visual image quality of the CT reconstruction using Guided Attention based GANs (GA-GAN). We also consider the use of Vector Quantization (VQ) for the CT reconstruction so that the memory usage can be reduced, maintaining the same visual image quality. To the best of our knowledge no work has been done before that explores the Vector Quantization for this purpose. Although our findings show that our approaches outperform the previous works, still there is a lot of room for improvement.