 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
YouMakeup VQA Challenge: Towards Fine-grained Action Understanding in Domain-Specific Videos
Apr 12, 2020

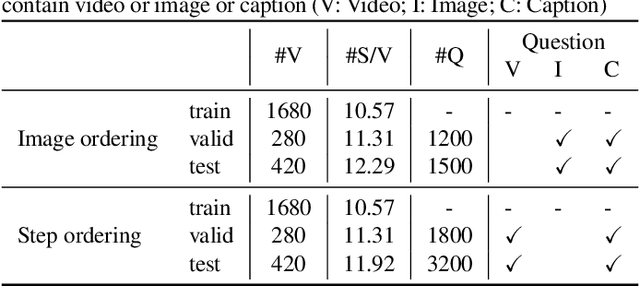

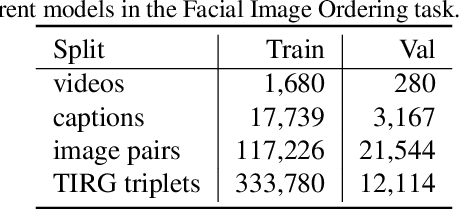
The goal of the YouMakeup VQA Challenge 2020 is to provide a common benchmark for fine-grained action understanding in domain-specific videos e.g. makeup instructional videos. We propose two novel question-answering tasks to evaluate models' fine-grained action understanding abilities. The first task is \textbf{Facial Image Ordering}, which aims to understand visual effects of different actions expressed in natural language to the facial object. The second task is \textbf{Step Ordering}, which aims to measure cross-modal semantic alignments between untrimmed videos and multi-sentence texts. In this paper, we present the challenge guidelines, the dataset used, and performances of baseline models on the two proposed tasks. The baseline codes and models are released at \url{https://github.com/AIM3-RUC/YouMakeup_Baseline}.
Driver Gaze Estimation in the Real World: Overcoming the Eyeglass Challenge
Feb 11, 2020

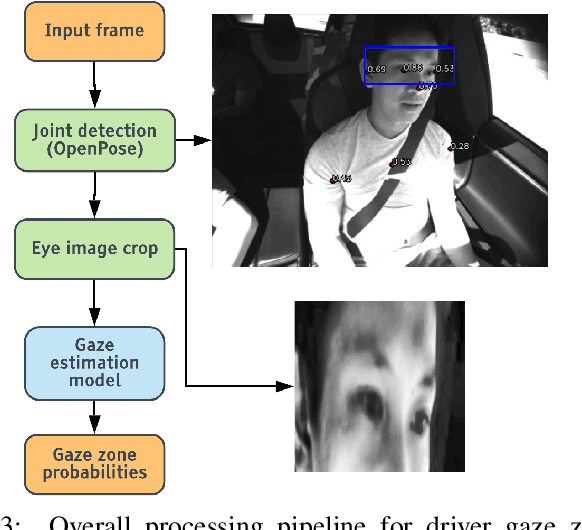
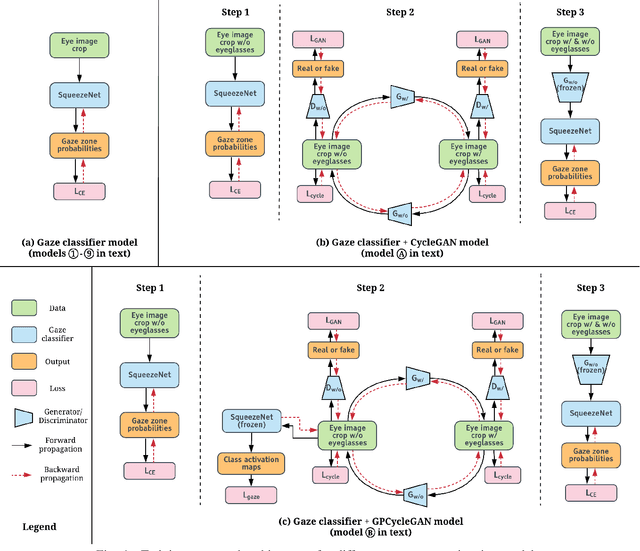
A driver's gaze is critical for determining the driver's attention level, state, situational awareness, and readiness to take over control from partially and fully automated vehicles. Tracking both the head and eyes (pupils) can provide reliable estimation of a driver's gaze using face images under ideal conditions. However, the vehicular environment introduces a variety of challenges that are usually unaccounted for - harsh illumination, nighttime conditions, and reflective/dark eyeglasses. Unfortunately, relying on head pose alone under such conditions can prove to be unreliable owing to significant eye movements. In this study, we offer solutions to address these problems encountered in the real world. To solve issues with lighting, we demonstrate that using an infrared camera with suitable equalization and normalization usually suffices. To handle eyeglasses and their corresponding artifacts, we adopt the idea of image-to-image translation using generative adversarial networks (GANs) to pre-process images prior to gaze estimation. To this end, we propose the Gaze Preserving CycleGAN (GPCycleGAN). As the name suggests, this network preserves the driver's gaze while removing potential eyeglasses from infrared face images. GPCycleGAN is based on the well-known CycleGAN approach, with the addition of a gaze classifier and a gaze consistency loss for additional supervision. Our approach exhibits improved performance and robustness on challenging real-world data spanning 13 subjects and a variety of driving conditions.
Multi-Modality Information Fusion for Radiomics-based Neural Architecture Search
Jul 12, 2020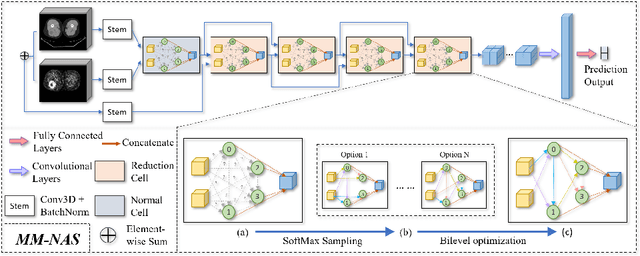
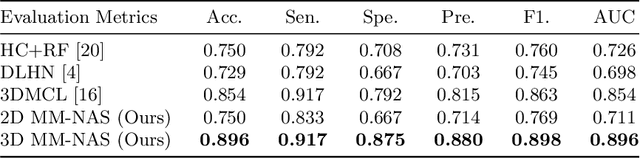
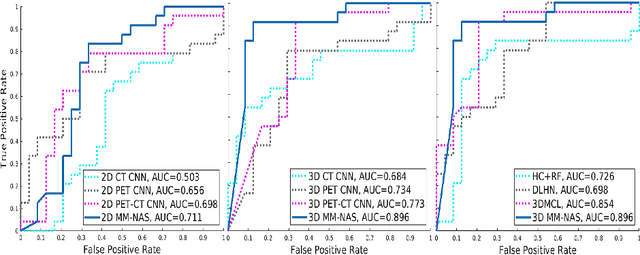
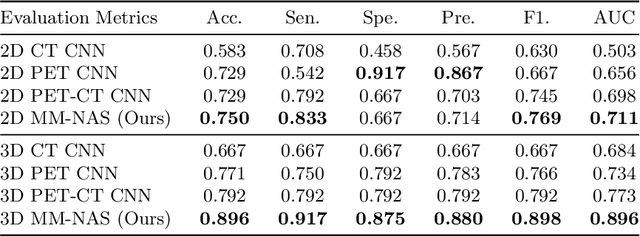
'Radiomics' is a method that extracts mineable quantitative features from radiographic images. These features can then be used to determine prognosis, for example, predicting the development of distant metastases (DM). Existing radiomics methods, however, require complex manual effort including the design of hand-crafted radiomic features and their extraction and selection. Recent radiomics methods, based on convolutional neural networks (CNNs), also require manual input in network architecture design and hyper-parameter tuning. Radiomic complexity is further compounded when there are multiple imaging modalities, for example, combined positron emission tomography - computed tomography (PET-CT) where there is functional information from PET and complementary anatomical localization information from computed tomography (CT). Existing multi-modality radiomics methods manually fuse the data that are extracted separately. Reliance on manual fusion often results in sub-optimal fusion because they are dependent on an 'expert's' understanding of medical images. In this study, we propose a multi-modality neural architecture search method (MM-NAS) to automatically derive optimal multi-modality image features for radiomics and thus negate the dependence on a manual process. We evaluated our MM-NAS on the ability to predict DM using a public PET-CT dataset of patients with soft-tissue sarcomas (STSs). Our results show that our MM-NAS had a higher prediction accuracy when compared to state-of-the-art radiomics methods.
Cross-filter compression for CNN inference acceleration
May 18, 2020
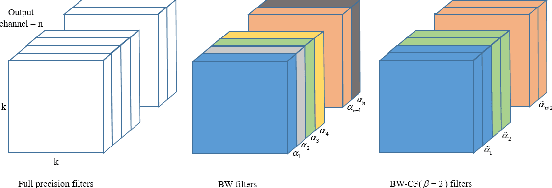
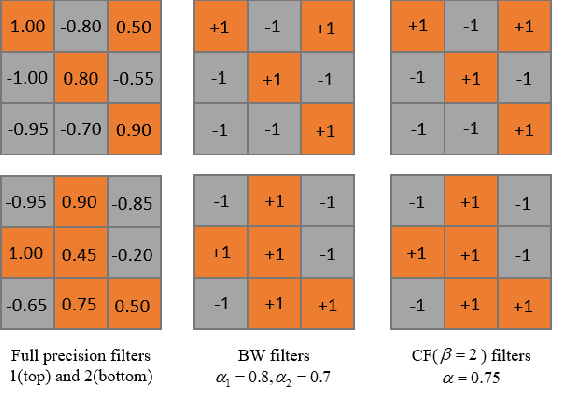
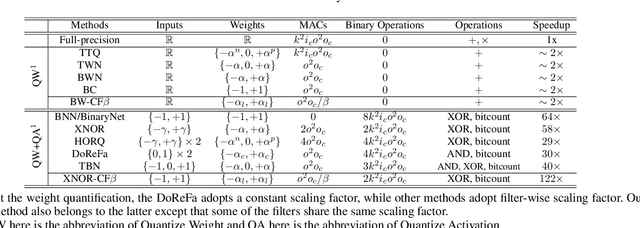
Convolution neural network demonstrates great capability for multiple tasks, such as image classification and many others. However, much resource is required to train a network. Hence much effort has been made to accelerate neural network by reducing precision of weights, activation, and gradient. However, these filter-wise quantification methods exist a natural upper limit, caused by the size of the kernel. Meanwhile, with the popularity of small kernel, the natural limit further decrease. To address this issue, we propose a new cross-filter compression method that can provide $\sim32\times$ memory savings and $122\times$ speed up in convolution operations. In our method, all convolution filters are quantized to given bits and spatially adjacent filters share the same scaling factor. Our compression method, based on Binary-Weight and XNOR-Net separately, is evaluated on CIFAR-10 and ImageNet dataset with widely used network structures, such as ResNet and VGG, and witness tolerable accuracy loss compared to state-of-the-art quantification methods.
A cascaded dual-domain deep learning reconstruction method for sparsely spaced multidetector helical CT
Oct 09, 2019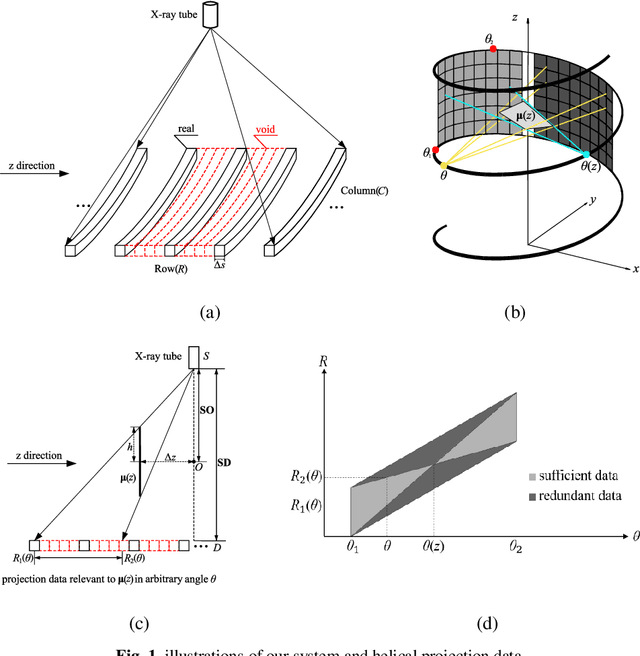

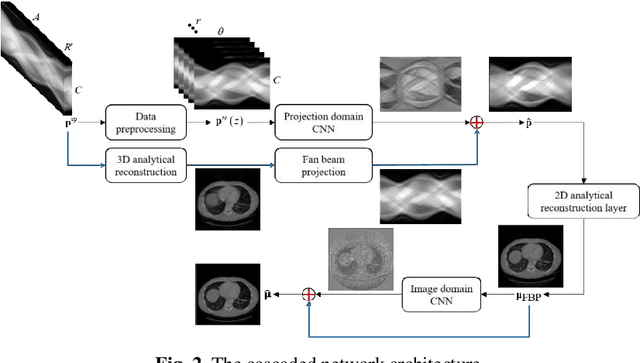
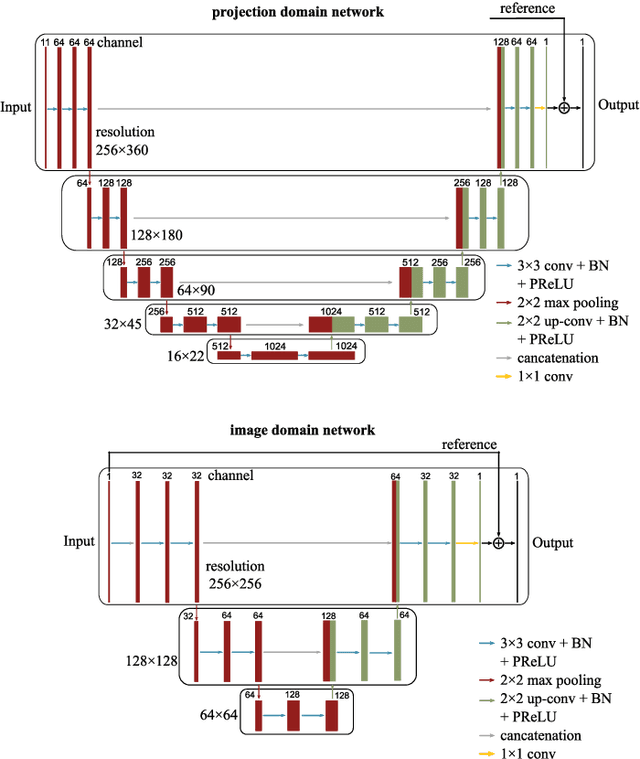
Helical CT has been widely used in clinical diagnosis. Sparsely spaced multidetector in z direction can increase the coverage of the detector provided limited detector rows. It can speed up volumetric CT scan, lower the radiation dose and reduce motion artifacts. However, it leads to insufficient data for reconstruction. That means reconstructions from general analytical methods will have severe artifacts. Iterative reconstruction methods might be able to deal with this situation but with the cost of huge computational load. In this work, we propose a cascaded dual-domain deep learning method that completes both data transformation in projection domain and error reduction in image domain. First, a convolutional neural network (CNN) in projection domain is constructed to estimate missing helical projection data and converting helical projection data to 2D fan-beam projection data. This step is to suppress helical artifacts and reduce the following computational cost. Then, an analytical linear operator is followed to transfer the data from projection domain to image domain. Finally, an image domain CNN is added to improve image quality further. These three steps work as an entirety and can be trained end to end. The overall network is trained using a simulated lung CT dataset with Poisson noise from 25 patients. We evaluate the trained network on another three patients and obtain very encouraging results with both visual examination and quantitative comparison. The resulting RRMSE is 6.56% and the SSIM is 99.60%. In addition, we test the trained network on the lung CT dataset with different noise level and a new dental CT dataset to demonstrate the generalization and robustness of our method.
Graph-based Kinship Reasoning Network
Apr 22, 2020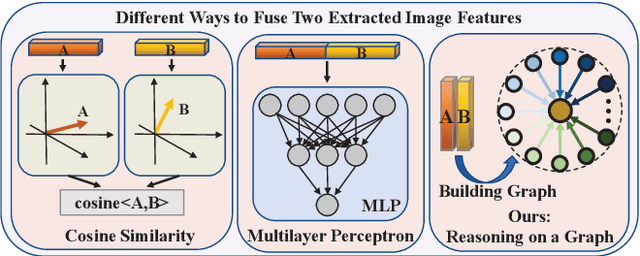
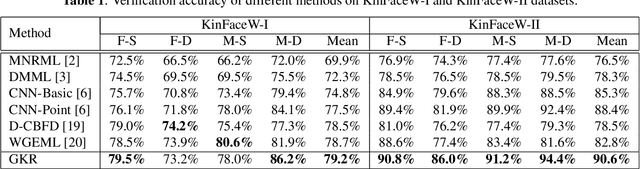
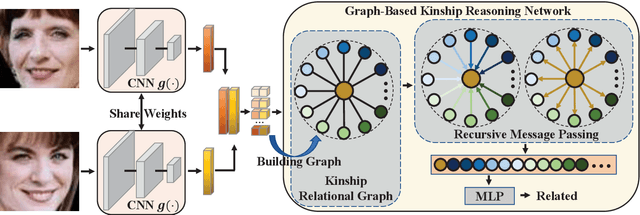
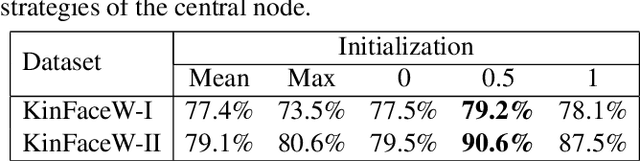
In this paper, we propose a graph-based kinship reasoning (GKR) network for kinship verification, which aims to effectively perform relational reasoning on the extracted features of an image pair. Unlike most existing methods which mainly focus on how to learn discriminative features, our method considers how to compare and fuse the extracted feature pair to reason about the kin relations. The proposed GKR constructs a star graph called kinship relational graph where each peripheral node represents the information comparison in one feature dimension and the central node is used as a bridge for information communication among peripheral nodes. Then the GKR performs relational reasoning on this graph with recursive message passing. Extensive experimental results on the KinFaceW-I and KinFaceW-II datasets show that the proposed GKR outperforms the state-of-the-art methods.
U$^2$-Net: Going Deeper with Nested U-Structure for Salient Object Detection
May 18, 2020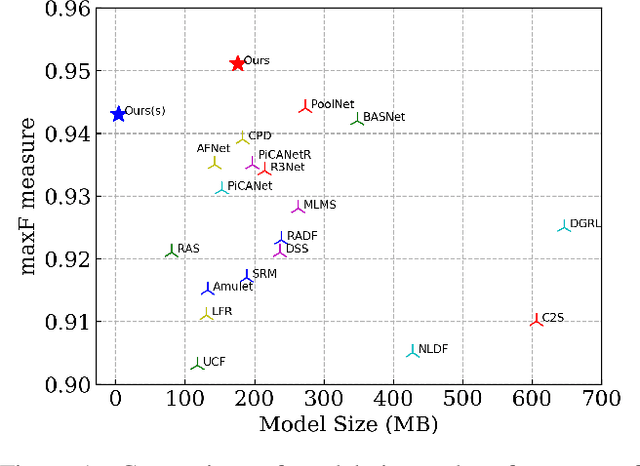
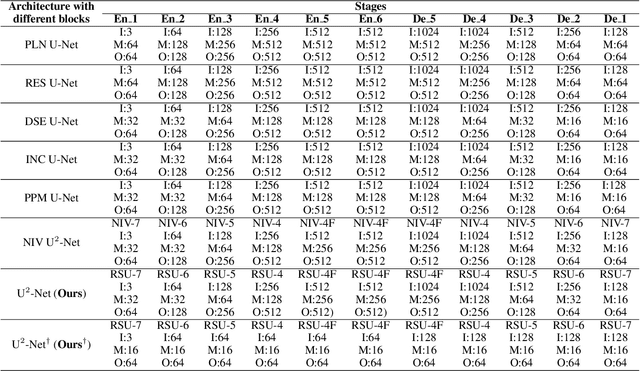
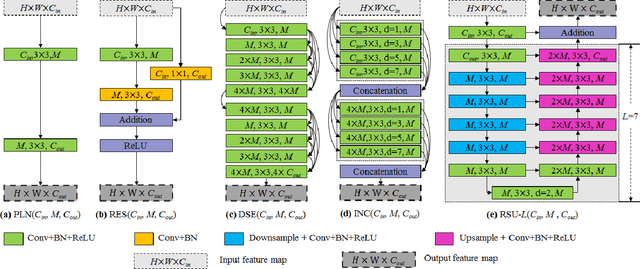
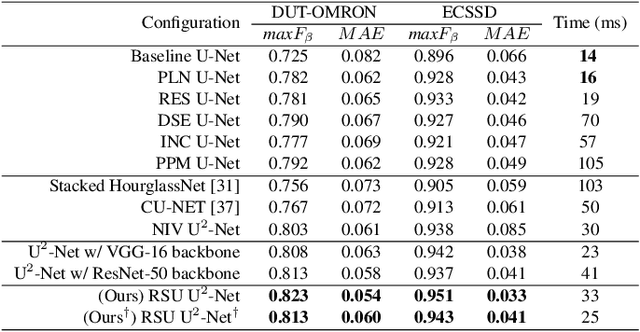
In this paper, we design a simple yet powerful deep network architecture, U$^2$-Net, for salient object detection (SOD). The architecture of our U$^2$-Net is a two-level nested U-structure. The design has the following advantages: (1) it is able to capture more contextual information from different scales thanks to the mixture of receptive fields of different sizes in our proposed ReSidual U-blocks (RSU), (2) it increases the depth of the whole architecture without significantly increasing the computational cost because of the pooling operations used in these RSU blocks. This architecture enables us to train a deep network from scratch without using backbones from image classification tasks. We instantiate two models of the proposed architecture, U$^2$-Net (176.3 MB, 30 FPS on GTX 1080Ti GPU) and U$^2$-Net$^{\dagger}$ (4.7 MB, 40 FPS), to facilitate the usage in different environments. Both models achieve competitive performance on six SOD datasets. The code is available: https://github.com/NathanUA/U-2-Net.
Geometric VLAD for Large Scale Image Search
Mar 15, 2014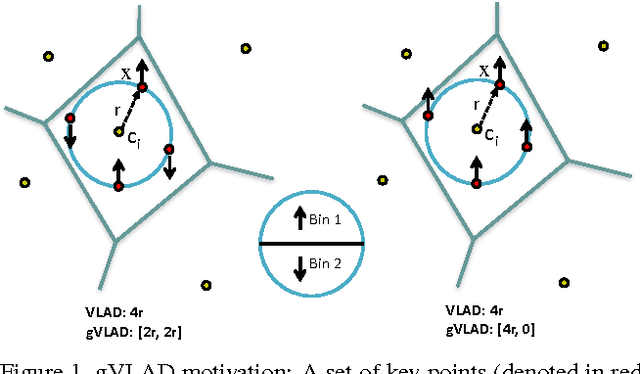


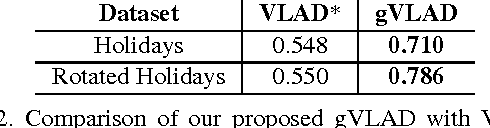
We present a novel compact image descriptor for large scale image search. Our proposed descriptor - Geometric VLAD (gVLAD) is an extension of VLAD (Vector of Locally Aggregated Descriptors) that incorporates weak geometry information into the VLAD framework. The proposed geometry cues are derived as a membership function over keypoint angles which contain evident and informative information but yet often discarded. A principled technique for learning the membership function by clustering angles is also presented. Further, to address the overhead of iterative codebook training over real-time datasets, a novel codebook adaptation strategy is outlined. Finally, we demonstrate the efficacy of proposed gVLAD based retrieval framework where we achieve more than 15% improvement in mAP over existing benchmarks.
Soft Prototyping Camera Designs for Car Detection Based on a Convolutional Neural Network
Oct 24, 2019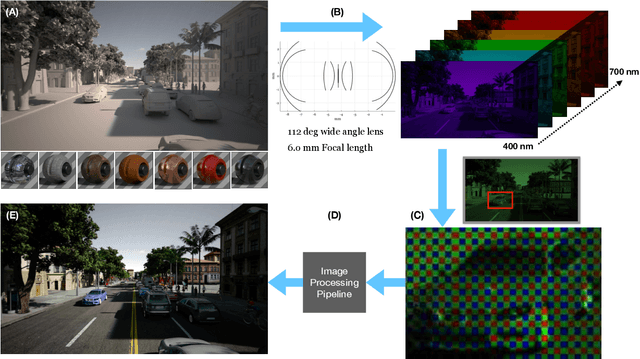
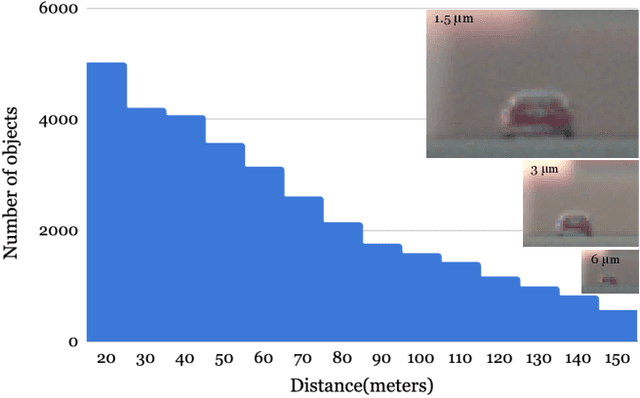
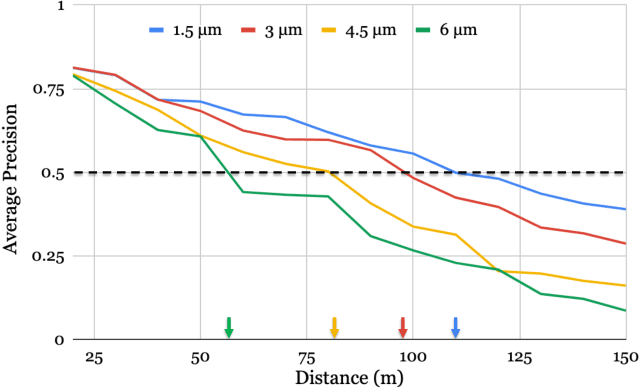
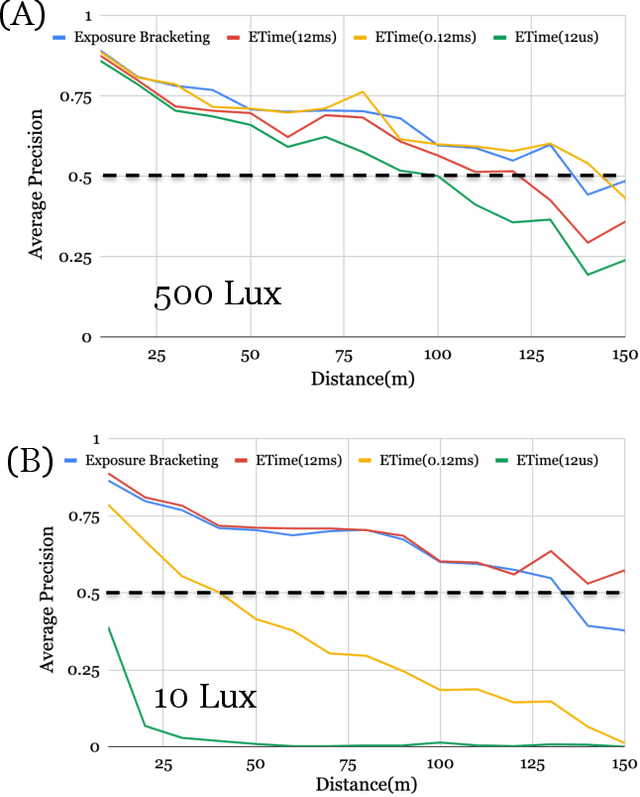
Imaging systems are increasingly used as input to convolutional neural networks (CNN) for object detection; we would like to design cameras that are optimized for this purpose. It is impractical to build different cameras and then acquire and label the necessary data for every potential camera design; creating software simulations of the camera in context (soft prototyping) is the only realistic approach. We implemented soft-prototyping tools that can quantitatively simulate image radiance and camera designs to create realistic images that are input to a convolutional neural network for car detection. We used these methods to quantify the effect that critical hardware components (pixel size), sensor control (exposure algorithms) and image processing (gamma and demosaicing algorithms) have upon average precision of car detection. We quantify (a) the relationship between pixel size and the ability to detect cars at different distances, (b) the penalty for choosing a poor exposure duration, and (c) the ability of the CNN to perform car detection for a variety of post-acquisition processing algorithms. These results show that the optimal choices for car detection are not constrained by the same metrics used for image quality in consumer photography. It is better to evaluate camera designs for CNN applications using soft prototyping with task-specific metrics rather than consumer photography metrics.
Adversarial Defense by Suppressing High-frequency Components
Sep 03, 2019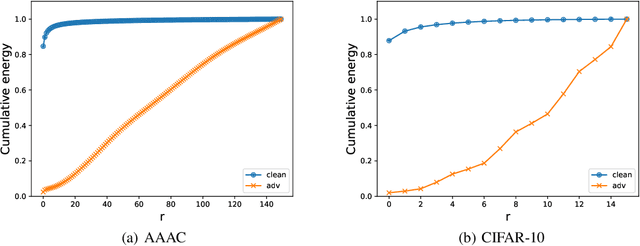

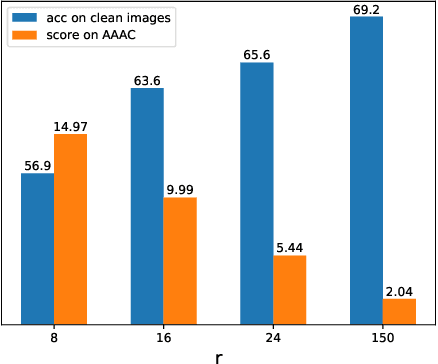
Recent works show that deep neural networks trained on image classification dataset bias towards textures. Those models are easily fooled by applying small high-frequency perturbations to clean images. In this paper, we learn robust image classification models by removing high-frequency components. Specifically, we develop a differentiable high-frequency suppression module based on discrete Fourier transform (DFT). Combining with adversarial training, we won the 5th place in the IJCAI-2019 Alibaba Adversarial AI Challenge. Our code is available online.