 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Some Theoretical Insights into Wasserstein GANs
Jun 04, 2020
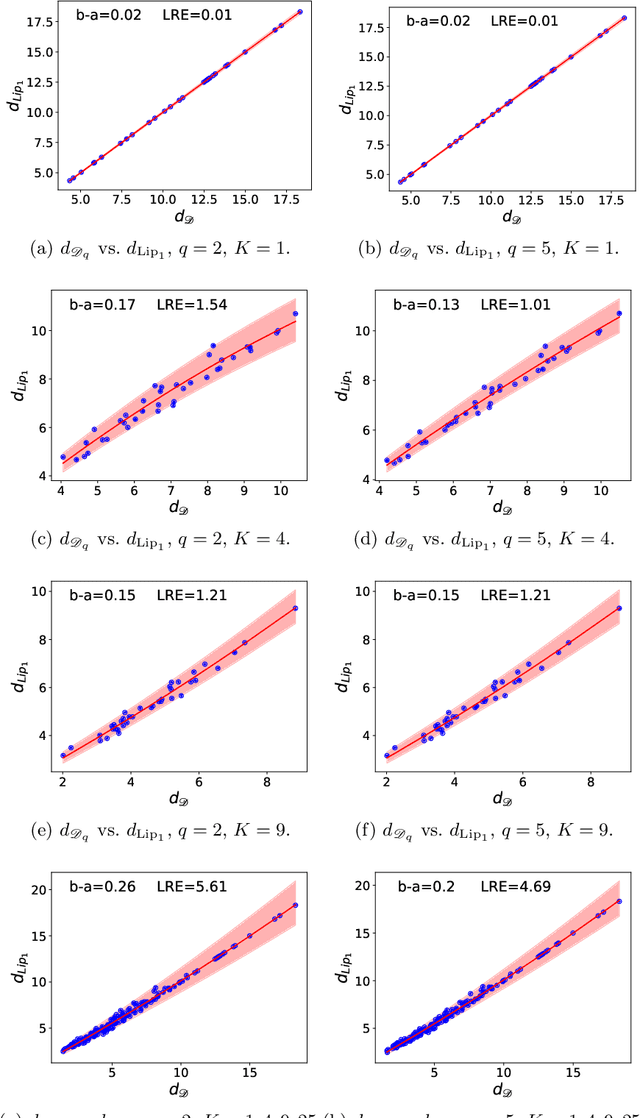
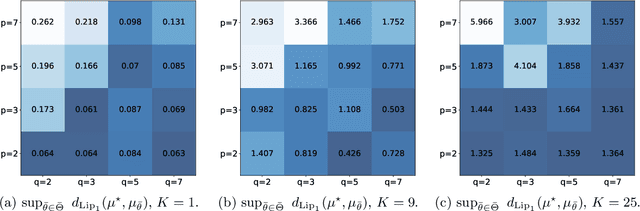
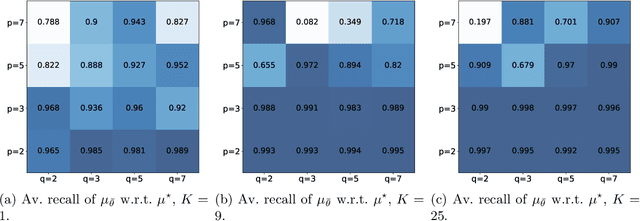
Generative Adversarial Networks (GANs) have been successful in producing outstanding results in areas as diverse as image, video, and text generation. Building on these successes, a large number of empirical studies have validated the benefits of the cousin approach called Wasserstein GANs (WGANs), which brings stabilization in the training process. In the present paper, we add a new stone to the edifice by proposing some theoretical advances in the properties of WGANs. First, we properly define the architecture of WGANs in the context of integral probability metrics parameterized by neural networks and highlight some of their basic mathematical features. We stress in particular interesting optimization properties arising from the use of a parametric 1-Lipschitz discriminator. Then, in a statistically-driven approach, we study the convergence of empirical WGANs as the sample size tends to infinity, and clarify the adversarial effects of the generator and the discrimi-nator by underlining some trade-off properties. These features are finally illustrated with experiments using both synthetic and real-world datasets.
Projection Inpainting Using Partial Convolution for Metal Artifact Reduction
May 02, 2020
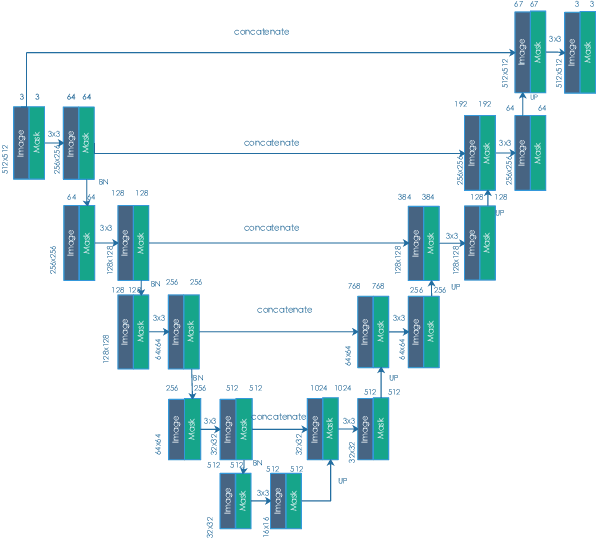
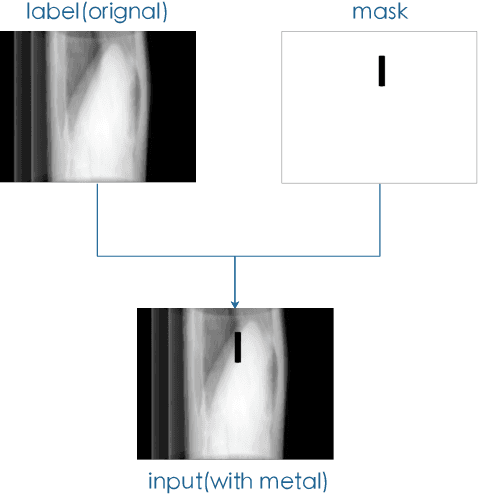
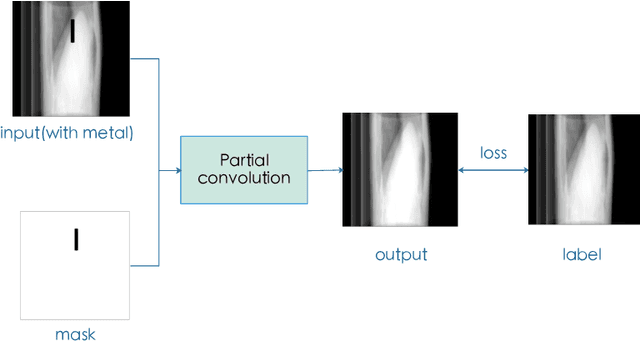
In computer tomography, due to the presence of metal implants in the patient body, reconstructed images will suffer from metal artifacts. In order to reduce metal artifacts, metals are typically removed in projection images. Therefore, the metal corrupted projection areas need to be inpainted. For deep learning inpainting methods, convolutional neural networks (CNNs) are widely used, for example, the U-Net. However, such CNNs use convolutional filter responses on both valid and corrupted pixel values, resulting in unsatisfactory image quality. In this work, partial convolution is applied for projection inpainting, which only relies on valid pixels values. The U-Net with partial convolution and conventional convolution are compared for metal artifact reduction. Our experiments demonstrate that the U-Net with partial convolution is able to inpaint the metal corrupted areas better than that with conventional convolution.
Deep Learning COVID-19 Features on CXR using Limited Training Data Sets
Apr 13, 2020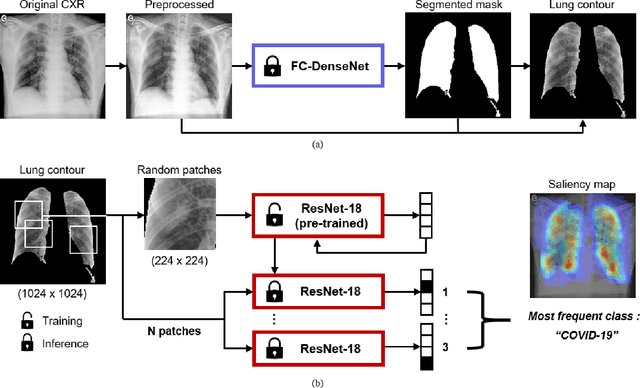
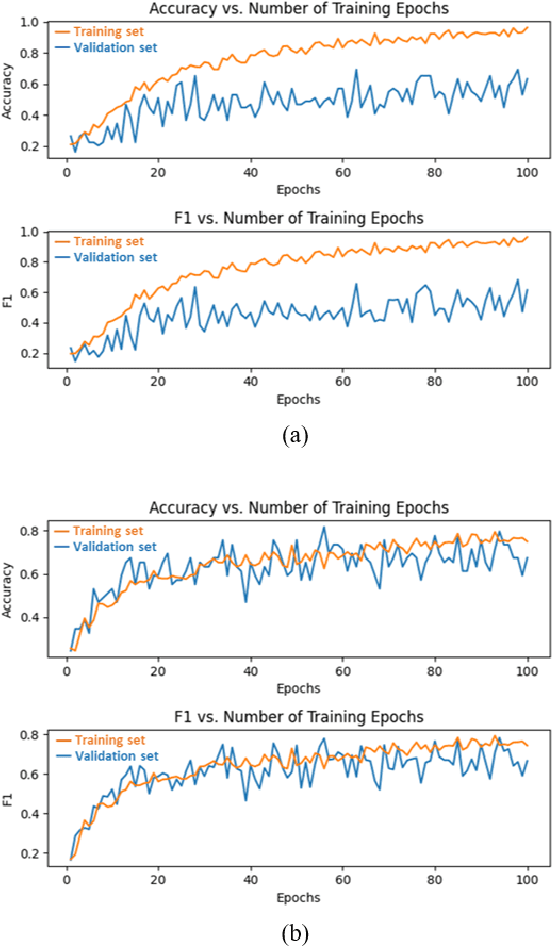
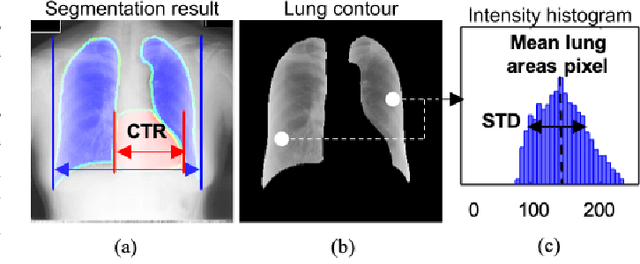
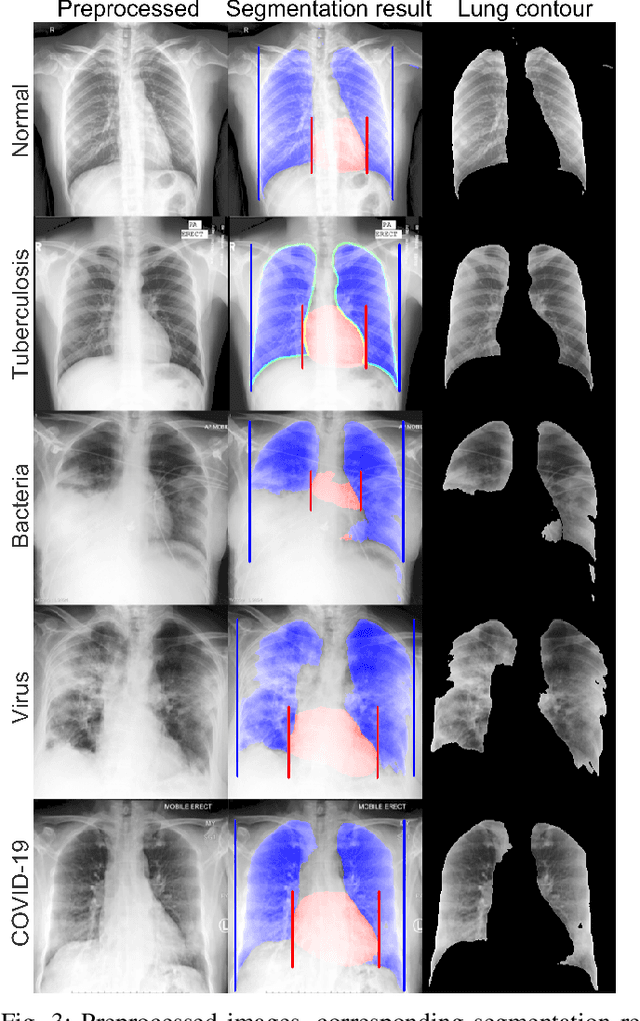
Under the global pandemic of COVID-19, the use of artificial intelligence to analyze chest X-ray (CXR) image for COVID-19 diagnosis and patient triage is becoming important. Unfortunately, due to the emergent nature of the COVID-19 pandemic, a systematic collection of the CXR data set for deep neural network training is difficult. To address this problem, here we propose a patch-based convolutional neural network approach with a relatively small number of trainable parameters for COVID-19 diagnosis. The proposed method is inspired by our statistical analysis of the potential imaging biomarkers of the CXR radiographs. Experimental results show that our method achieves state-of-the-art performance and provides clinically interpretable saliency maps, which are useful for COVID-19 diagnosis and patient triage.
Built Infrastructure Monitoring and Inspection Using UAVs and Vision-based Algorithms
May 19, 2020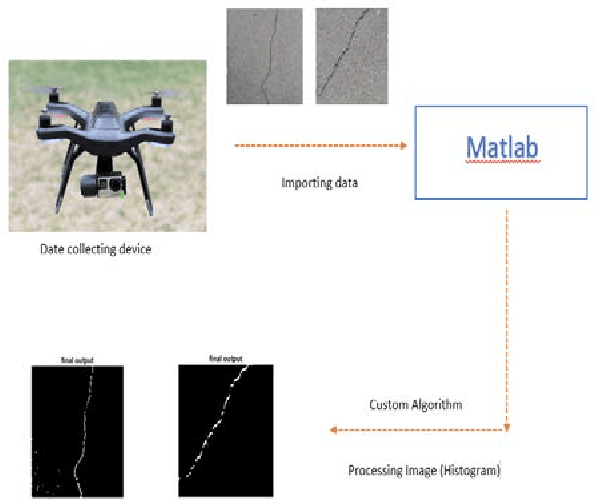


This study presents an inspecting system using real-time control unmanned aerial vehicles (UAVs) to investigate structural surfaces. The system operates under favourable weather conditions to inspect a target structure, which is the Wentworth light rail base structure in this study. The system includes a drone, a GoPro HERO4 camera, a controller and a mobile phone. The drone takes off the ground manually in the testing field to collect the data requiring for later analysis. The images are taken through HERO 4 camera and then transferred in real time to the remote processing unit such as a ground control station by the wireless connection established by a Wi-Fi router. An image processing method has been proposed to detect defects or damages such as cracks. The method based on intensity histogram algorithms to exploit the pixel group related to the crack contained in the low intensity interval. Experiments, simulation and comparisons have been conducted to evaluate the performance and validity of the proposed system.
A hierarchical approach to deep learning and its application to tomographic reconstruction
Dec 16, 2019
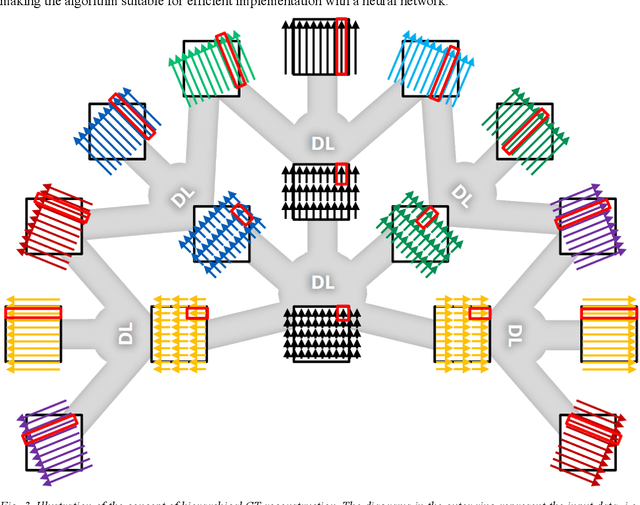

Deep learning (DL) has shown unprecedented performance for many image analysis and image enhancement tasks. Yet, solving large-scale inverse problems like tomographic reconstruction remains challenging for DL. These problems involve non-local and space-variant integral transforms between the input and output domains, for which no efficient neural network models have been found. A prior attempt to solve such problems with supervised learning relied on a brute-force fully connected network and applied it to reconstruction for a $128^4$ system matrix size. This cannot practically scale to realistic data sizes such as $512^4$ and $512^6$ for three-dimensional data sets. Here we present a novel framework to solve such problems with deep learning by casting the original problem as a continuum of intermediate representations between the input and output data. The original problem is broken down into a sequence of simpler transformations that can be well mapped onto an efficient hierarchical network architecture, with exponentially fewer parameters than a generic network would need. We applied the approach to computed tomography (CT) image reconstruction for a $512^4$ system matrix size. To our knowledge, this enabled the first data-driven DL solver for full-size CT reconstruction without relying on the structure of direct (analytical) or iterative (numerical) inversion techniques. The proposed approach is applicable to other imaging problems such as emission and magnetic resonance reconstruction. More broadly, hierarchical DL opens the door to a new class of solvers for general inverse problems, which could potentially lead to improved signal-to-noise ratio, spatial resolution and computational efficiency in various areas.
Component Analysis for Visual Question Answering Architectures
Feb 12, 2020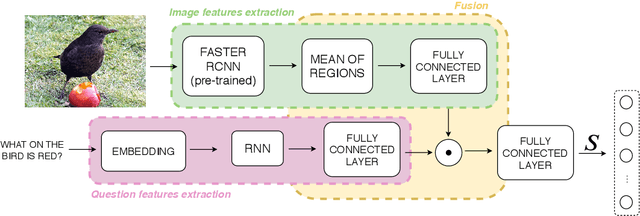
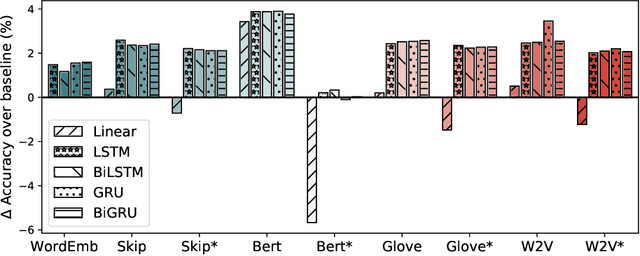
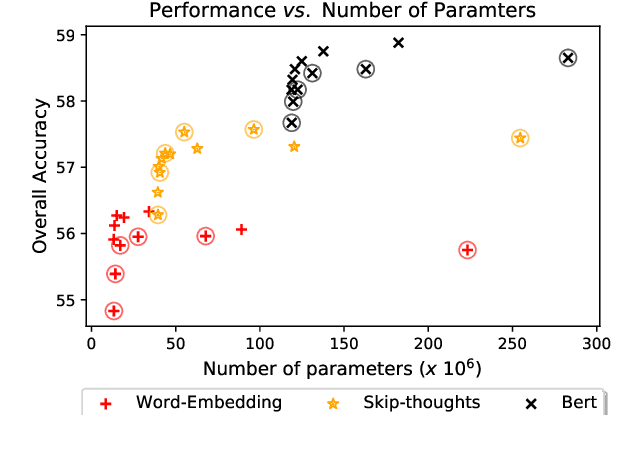
Recent research advances in Computer Vision and Natural Language Processing have introduced novel tasks that are paving the way for solving AI-complete problems. One of those tasks is called Visual Question Answering (VQA). A VQA system must take an image and a free-form, open-ended natural language question about the image, and produce a natural language answer as the output. Such a task has drawn great attention from the scientific community, which generated a plethora of approaches that aim to improve the VQA predictive accuracy. Most of them comprise three major components: (i) independent representation learning of images and questions; (ii) feature fusion so the model can use information from both sources to answer visual questions; and (iii) the generation of the correct answer in natural language. With so many approaches being recently introduced, it became unclear the real contribution of each component for the ultimate performance of the model. The main goal of this paper is to provide a comprehensive analysis regarding the impact of each component in VQA models. Our extensive set of experiments cover both visual and textual elements, as well as the combination of these representations in form of fusion and attention mechanisms. Our major contribution is to identify core components for training VQA models so as to maximize their predictive performance.
Bayesian optimization for modular black-box systems with switching costs
Jun 04, 2020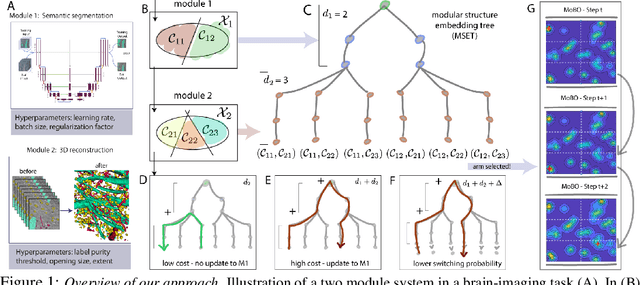
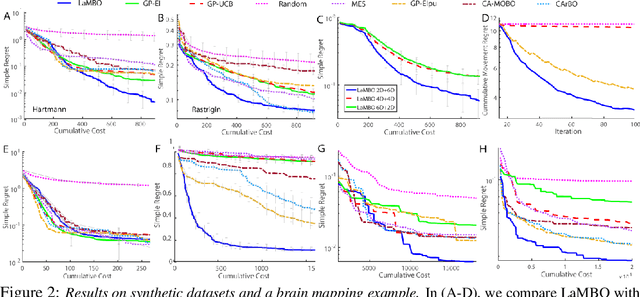
Most existing black-box optimization methods assume that all variables in the system being optimized have equal cost and can change freely at each iteration. However, in many real world systems, inputs are passed through a sequence of different operations or modules, making variables in earlier stages of processing more costly to update. Such structure imposes a cost on switching variables in early parts of a data processing pipeline. In this work, we propose a new algorithm for switch cost-aware optimization called Lazy Modular Bayesian Optimization (LaMBO). This method efficiently identifies the global optimum while minimizing cost through a passive change of variables in early modules. The method is theoretical grounded and achieves vanishing regret when augmented with switching cost. We apply LaMBO to multiple synthetic functions and a three-stage image segmentation pipeline used in a neuroscience application, where we obtain promising improvements over prevailing cost-aware Bayesian optimization algorithms. Our results demonstrate that LaMBO is an effective strategy for black-box optimization that is capable of minimizing switching costs in modular systems.
GAT-GMM: Generative Adversarial Training for Gaussian Mixture Models
Jun 18, 2020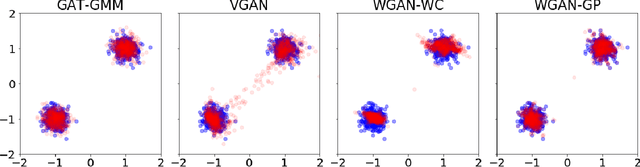
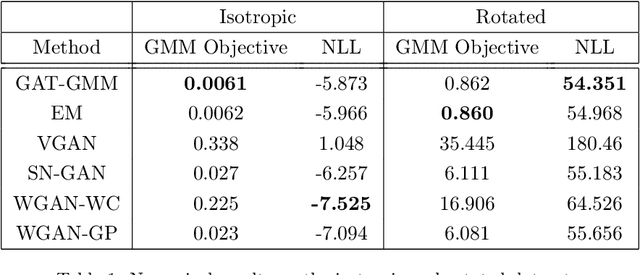
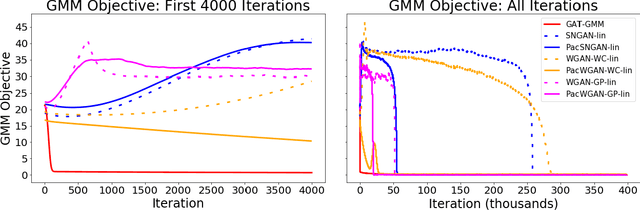
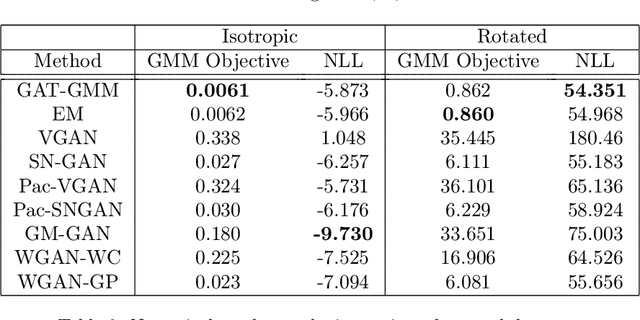
Generative adversarial networks (GANs) learn the distribution of observed samples through a zero-sum game between two machine players, a generator and a discriminator. While GANs achieve great success in learning the complex distribution of image, sound, and text data, they perform suboptimally in learning multi-modal distribution-learning benchmarks including Gaussian mixture models (GMMs). In this paper, we propose Generative Adversarial Training for Gaussian Mixture Models (GAT-GMM), a minimax GAN framework for learning GMMs. Motivated by optimal transport theory, we design the zero-sum game in GAT-GMM using a random linear generator and a softmax-based quadratic discriminator architecture, which leads to a non-convex concave minimax optimization problem. We show that a Gradient Descent Ascent (GDA) method converges to an approximate stationary minimax point of the GAT-GMM optimization problem. In the benchmark case of a mixture of two symmetric, well-separated Gaussians, we further show this stationary point recovers the true parameters of the underlying GMM. We numerically support our theoretical findings by performing several experiments, which demonstrate that GAT-GMM can perform as well as the expectation-maximization algorithm in learning mixtures of two Gaussians.
Explainable Deep Learning for Video Recognition Tasks: A Framework & Recommendations
Sep 07, 2019The popularity of Deep Learning for real-world applications is ever-growing. With the introduction of high performance hardware, applications are no longer limited to image recognition. With the introduction of more complex problems comes more and more complex solutions, and the increasing need for explainable AI. Deep Neural Networks for Video tasks are amongst the most complex models, with at least twice the parameters of their Image counterparts. However, explanations for these models are often ill-adapted to the video domain. The current work in explainability for video models is still overshadowed by Image techniques, while Video Deep Learning itself is quickly gaining on methods for still images. This paper seeks to highlight the need for explainability methods designed with video deep learning models, and by association spatio-temporal input in mind, by first illustrating the cutting edge for video deep learning, and then noting the scarcity of research into explanations for these methods.
Features for Ground Texture Based Localization -- A Survey
Feb 27, 2020

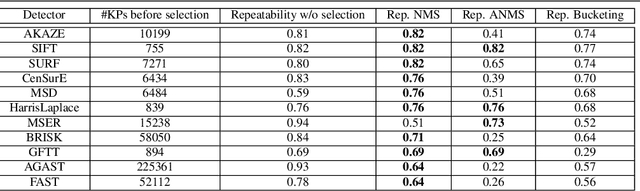
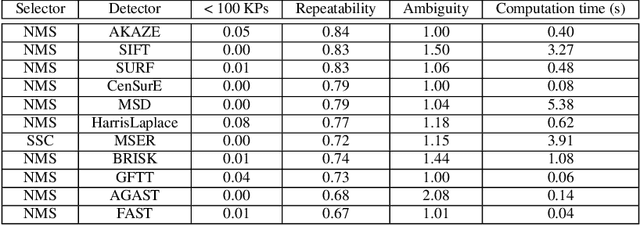
Ground texture based vehicle localization using feature-based methods is a promising approach to achieve infrastructure-free high-accuracy localization. In this paper, we provide the first extensive evaluation of available feature extraction methods for this task, using separately taken image pairs as well as synthetic transformations. We identify AKAZE, SURF and CenSurE as best performing keypoint detectors, and find pairings of CenSurE with the ORB, BRIEF and LATCH feature descriptors to achieve greatest success rates for incremental localization, while SIFT stands out when considering severe synthetic transformations as they might occur during absolute localization.