 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MRI Super-Resolution with Ensemble Learning and Complementary Priors
Jul 06, 2019
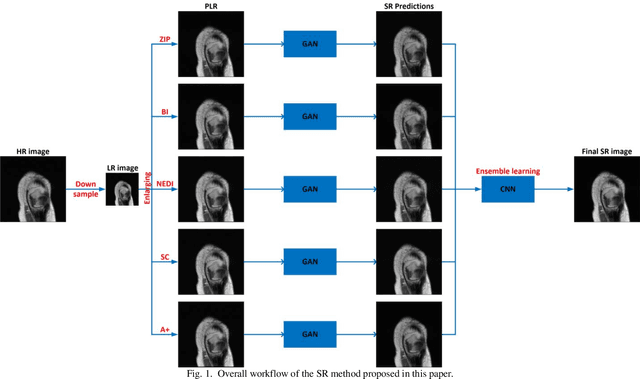
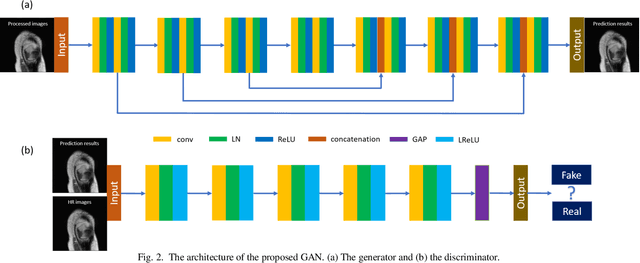
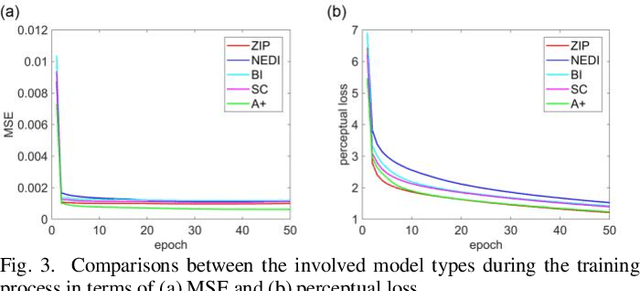

Magnetic resonance imaging (MRI) is a widely used medical imaging modality. However, due to the limitations in hardware, scan time, and throughput, it is often clinically challenging to obtain high-quality MR images. The super-resolution approach is potentially promising to improve MR image quality without any hardware upgrade. In this paper, we propose an ensemble learning and deep learning framework for MR image super-resolution. In our study, we first enlarged low resolution images using 5 commonly used super-resolution algorithms and obtained differentially enlarged image datasets with complementary priors. Then, a generative adversarial network (GAN) is trained with each dataset to generate super-resolution MR images. Finally, a convolutional neural network is used for ensemble learning that synergizes the outputs of GANs into the final MR super-resolution images. According to our results, the ensemble learning results outcome any one of GAN outputs. Compared with some state-of-the-art deep learning-based super-resolution methods, our approach is advantageous in suppressing artifacts and keeping more image details.
Adversarial Perturbations Prevail in the Y-Channel of the YCbCr Color Space
Feb 25, 2020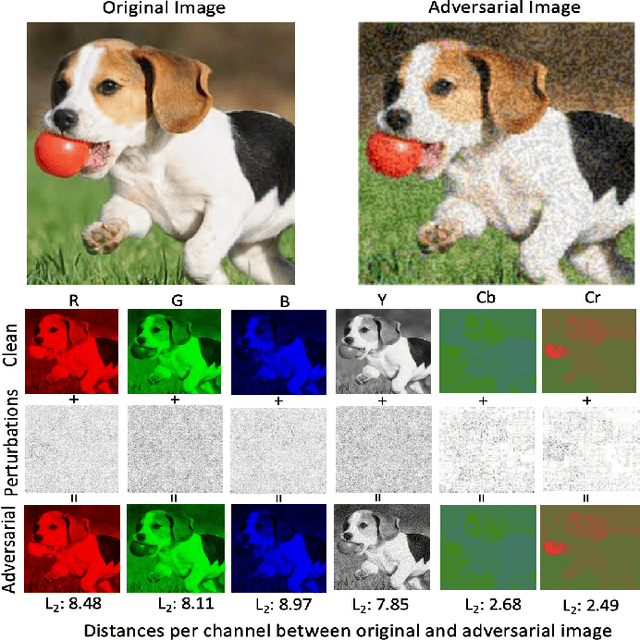
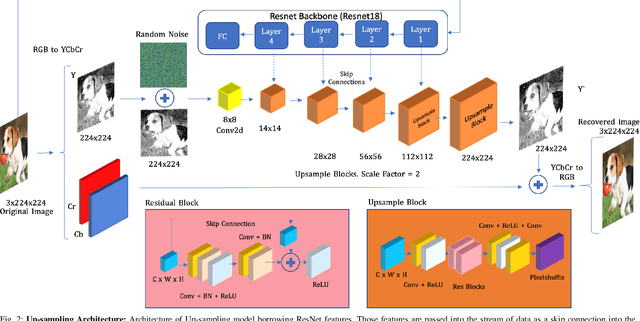
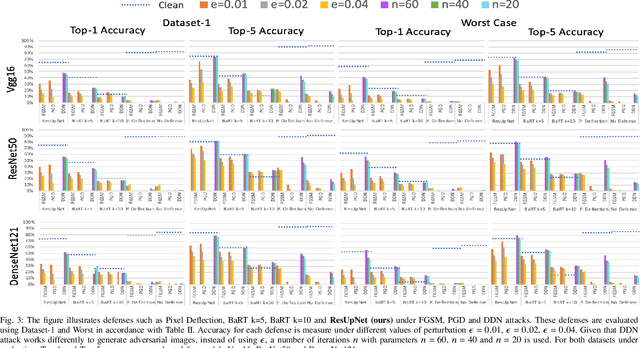

Deep learning offers state of the art solutions for image recognition. However, deep models are vulnerable to adversarial perturbations in images that are subtle but significantly change the model's prediction. In a white-box attack, these perturbations are generally learned for deep models that operate on RGB images and, hence, the perturbations are equally distributed in the RGB color space. In this paper, we show that the adversarial perturbations prevail in the Y-channel of the YCbCr space. Our finding is motivated from the fact that the human vision and deep models are more responsive to shape and texture rather than color. Based on our finding, we propose a defense against adversarial images. Our defence, coined ResUpNet, removes perturbations only from the Y-channel by exploiting ResNet features in an upsampling framework without the need for a bottleneck. At the final stage, the untouched CbCr-channels are combined with the refined Y-channel to restore the clean image. Note that ResUpNet is model agnostic as it does not modify the DNN structure. ResUpNet is trained end-to-end in Pytorch and the results are compared to existing defence techniques in the input transformation category. Our results show that our approach achieves the best balance between defence against adversarial attacks such as FGSM, PGD and DDN and maintaining the original accuracies of VGG-16, ResNet50 and DenseNet121 on clean images. We perform another experiment to show that learning adversarial perturbations only for the Y-channel results in higher fooling rates for the same perturbation magnitude.
Predicting Neural Network Accuracy from Weights
Feb 26, 2020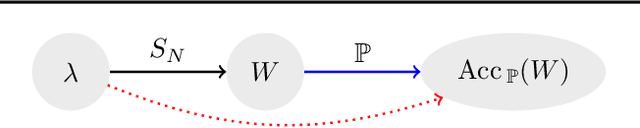
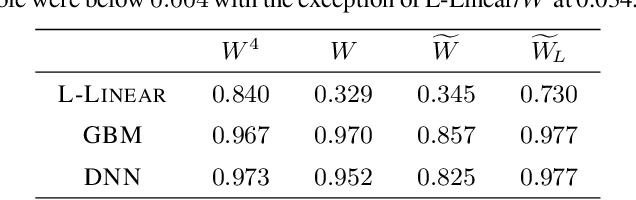
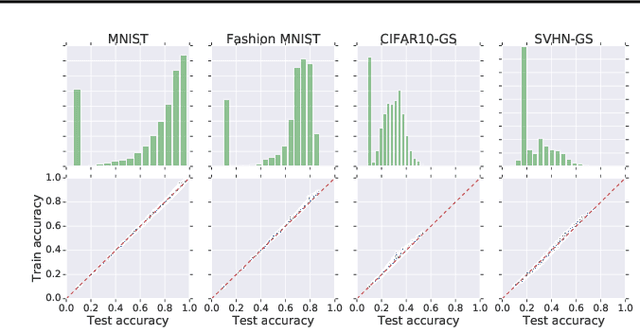
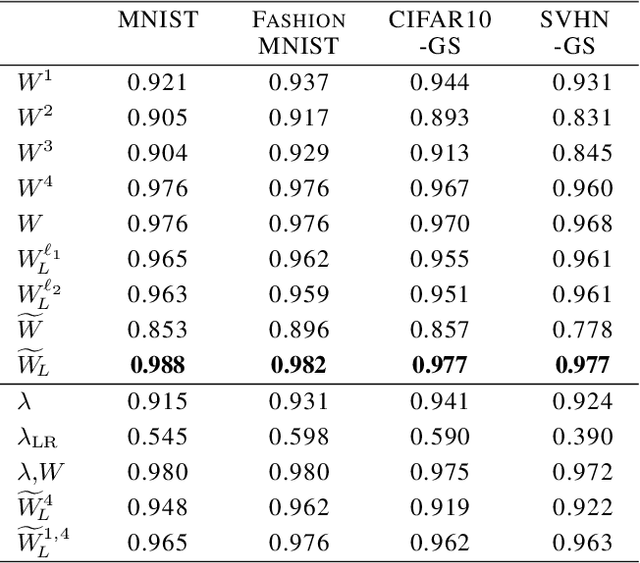
We study the prediction of the accuracy of a neural network given only its weights with the goal of better understanding network training and performance. To do so, we propose a formal setting which frames this task and connects to previous work in this area. We collect (and release) a large dataset of almost 80k convolutional neural networks trained on four image datasets. We demonstrate that strong predictors of accuracy exist. Moreover, they can achieve good predictions while only using simple statistics of the weights. Surprisingly, these predictors are able to rank networks trained on unobserved datasets or using different architectures.
MBA-RainGAN: Multi-branch Attention Generative Adversarial Network for Mixture of Rain Removal from Single Images
May 23, 2020


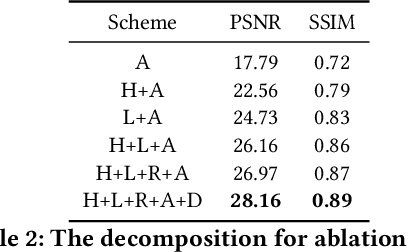
Rain severely hampers the visibility of scene objects when images are captured through glass in heavily rainy days. We observe three intriguing phenomenons that, 1) rain is a mixture of raindrops, rain streaks and rainy haze; 2) the depth from the camera determines the degrees of object visibility, where objects nearby and faraway are visually blocked by rain streaks and rainy haze, respectively; and 3) raindrops on the glass randomly affect the object visibility of the whole image space. We for the first time consider that, the overall visibility of objects is determined by the mixture of rain (MOR). However, existing solutions and established datasets lack full consideration of the MOR. In this work, we first formulate a new rain imaging model; by then, we enrich the popular RainCityscapes by considering raindrops, named RainCityscapes++. Furthermore, we propose a multi-branch attention generative adversarial network (termed an MBA-RainGAN) to fully remove the MOR. The experiment shows clear visual and numerical improvements of our approach over the state-of-the-arts on RainCityscapes++. The code and dataset will be available.
AutoSpeech: Neural Architecture Search for Speaker Recognition
May 07, 2020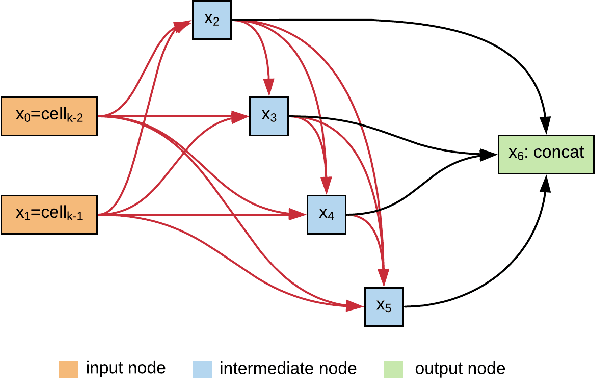
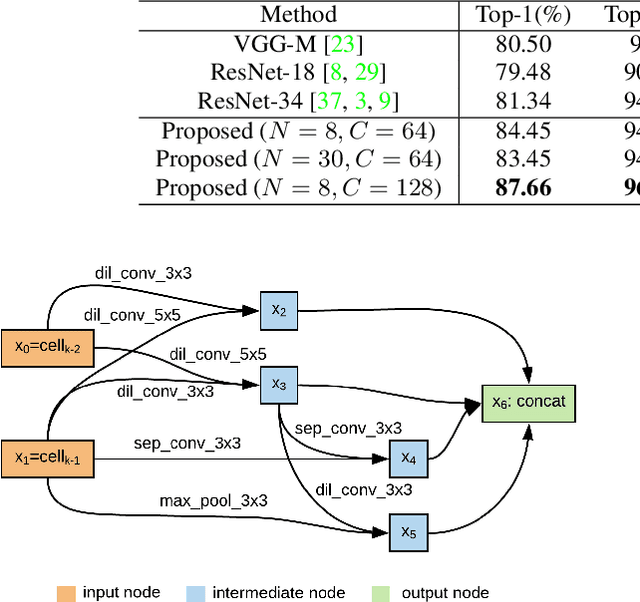
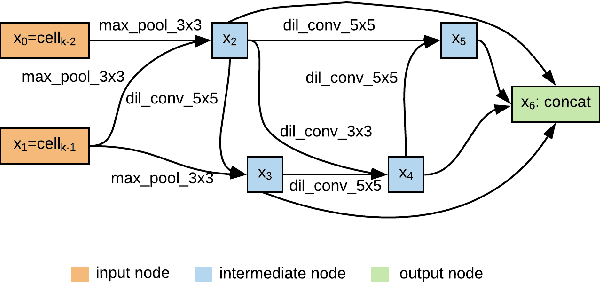
Speaker recognition systems based on Convolutional Neural Networks (CNNs) are often built with off-the-shelf backbones such as VGG-Net or ResNet. However, these backbones were originally proposed for image classification, and therefore may not be naturally fit for speaker recognition. Due to the prohibitive complexity of manually exploring the design space, we propose the first neural architecture search approach approach for the speaker recognition tasks, named as AutoSpeech. Our algorithm first identifies the optimal operation combination in a neural cell and then derives a CNN model by stacking the neural cell for multiple times. The final speaker recognition model can be obtained by training the derived CNN model through the standard scheme. To evaluate the proposed approach, we conduct experiments on both speaker identification and speaker verification tasks using the VoxCeleb1 dataset. Results demonstrate that the derived CNN architectures from the proposed approach significantly outperform current speaker recognition systems based on VGG-M, ResNet-18, and ResNet-34 back-bones, while enjoying lower model complexity.
A New Distance Measure for Non-Identical Data with Application to Image Classification
Oct 31, 2016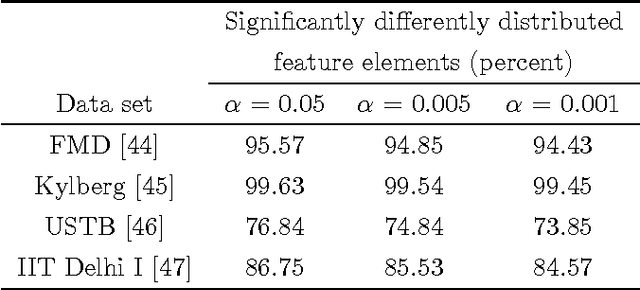
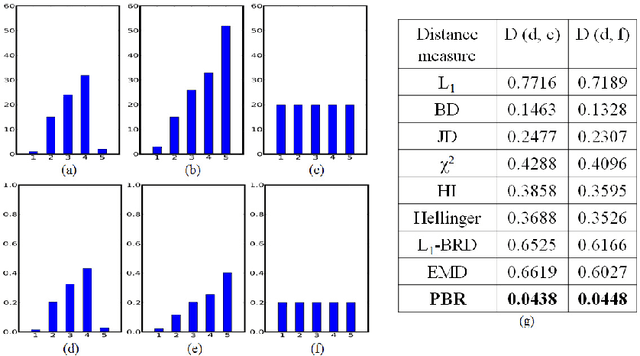
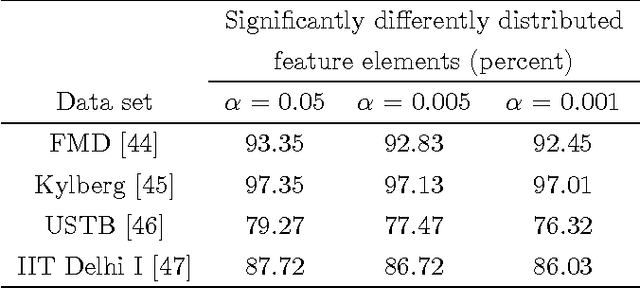
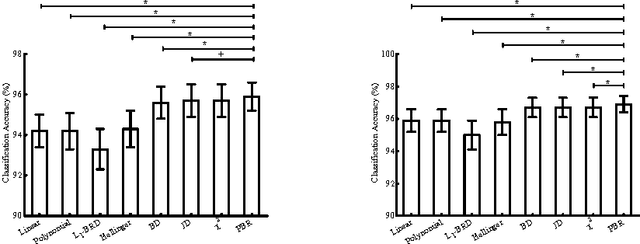
Distance measures are part and parcel of many computer vision algorithms. The underlying assumption in all existing distance measures is that feature elements are independent and identically distributed. However, in real-world settings, data generally originate from heterogeneous sources even if they do possess a common data-generating mechanism. Since these sources are not identically distributed by necessity, the assumption of identical distribution is inappropriate. Here, we use statistical analysis to show that feature elements of local image descriptors are indeed non-identically distributed. To test the effect of omitting the unified distribution assumption, we created a new distance measure called the Poisson-Binomial Radius (PBR). PBR is a bin-to-bin distance which accounts for the dispersion of bin-to-bin information. PBR's performance was evaluated on twelve benchmark data sets covering six different classification and recognition applications: texture, material, leaf, scene, ear biometrics and category-level image classification. Results from these experiments demonstrate that PBR outperforms state-of-the-art distance measures for most of the data sets and achieves comparable performance on the rest, suggesting that accounting for different distributions in distance measures can improve performance in classification and recognition tasks.
Fast Color Constancy with Patch-wise Bright Pixels
Nov 17, 2019
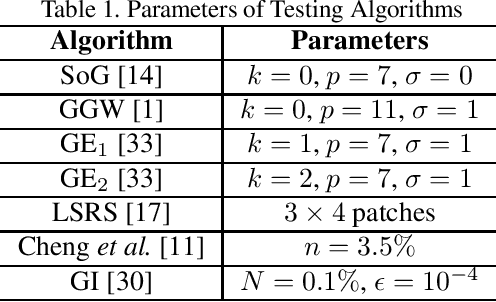
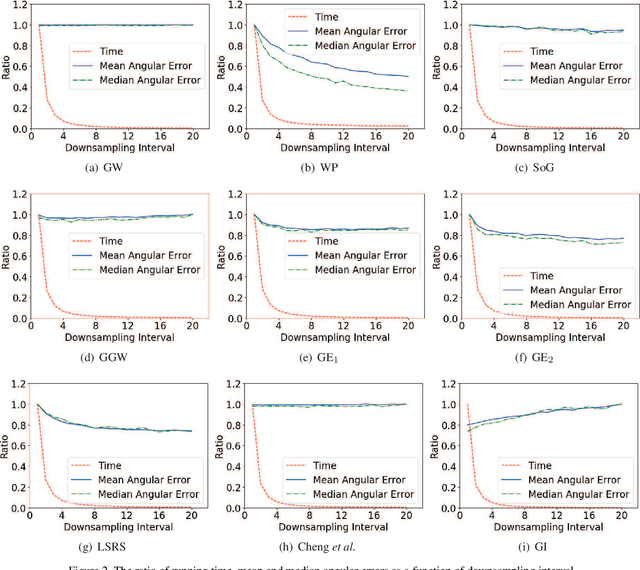

In this paper, a learning-free color constancy algorithm called the Patch-wise Bright Pixels (PBP) is proposed. In this algorithm, an input image is first downsampled and then cut equally into a few patches. After that, according to the modified brightness of each patch, a proper fraction of brightest pixels in the patch is selected. Finally, Gray World (GW)-based methods are applied to the selected bright pixels to estimate the illuminant of the scene. Experiments on NUS $8$-Camera Dataset show that the PBP algorithm outperforms the state-of-the-art learning-free methods as well as a broad range of learning-based ones. In particular, PBP processes a $1080$p image within two milliseconds, which is hundreds of times faster than the existing learning-free ones. Our algorithm offers a potential solution to the full-screen smart phones whose screen-to-body ratio is $100$\%.
Train, Learn, Expand, Repeat
Apr 19, 2020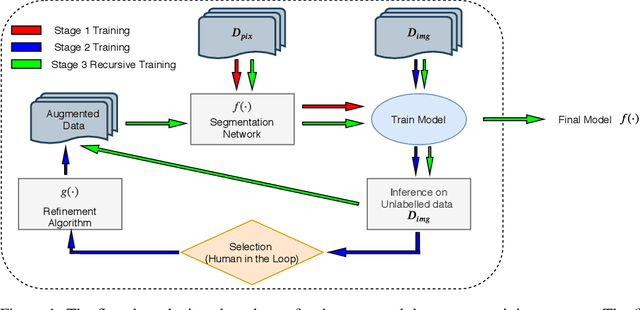
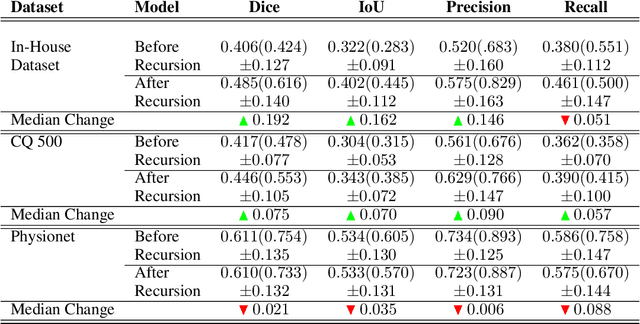
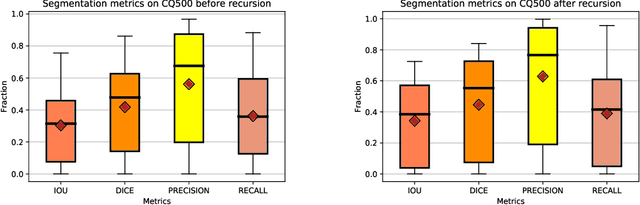
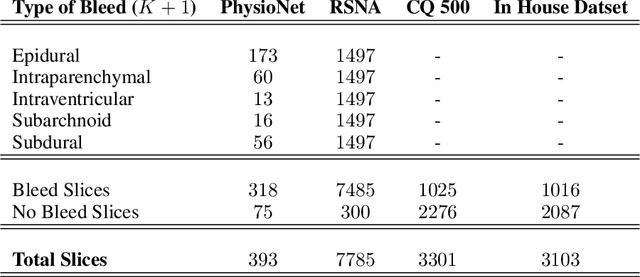
High-quality labeled data is essential to successfully train supervised machine learning models. Although a large amount of unlabeled data is present in the medical domain, labeling poses a major challenge: medical professionals who can expertly label the data are a scarce and expensive resource. Making matters worse, voxel-wise delineation of data (e.g. for segmentation tasks) is tedious and suffers from high inter-rater variance, thus dramatically limiting available training data. We propose a recursive training strategy to perform the task of semantic segmentation given only very few training samples with pixel-level annotations. We expand on this small training set having cheaper image-level annotations using a recursive training strategy. We apply this technique on the segmentation of intracranial hemorrhage (ICH) in CT (computed tomography) scans of the brain, where typically few annotated data is available.
Unsupervised Microvascular Image Segmentation Using an Active Contours Mimicking Neural Network
Aug 16, 2019
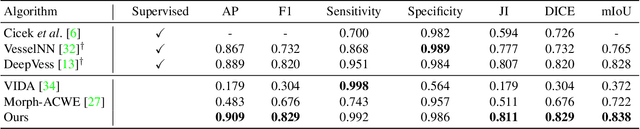
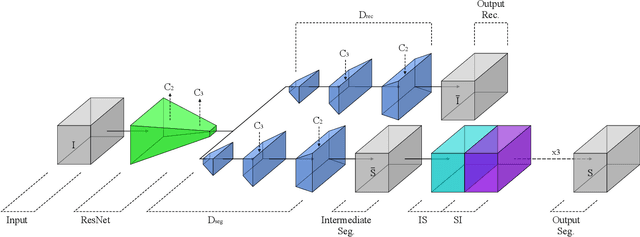

The task of blood vessel segmentation in microscopy images is crucial for many diagnostic and research applications. However, vessels can look vastly different, depending on the transient imaging conditions, and collecting data for supervised training is laborious. We present a novel deep learning method for unsupervised segmentation of blood vessels. The method is inspired by the field of active contours and we introduce a new loss term, which is based on the morphological Active Contours Without Edges (ACWE) optimization method. The role of the morphological operators is played by novel pooling layers that are incorporated to the network's architecture. We demonstrate the challenges that are faced by previous supervised learning solutions, when the imaging conditions shift. Our unsupervised method is able to outperform such previous methods in both the labeled dataset, and when applied to similar but different datasets. Our code, as well as efficient PyTorch reimplementations of the baseline methods VesselNN and DeepVess is available on GitHub - https://github.com/shirgur/UMIS.
Adversarial Defense by Suppressing High-frequency Components
Aug 19, 2019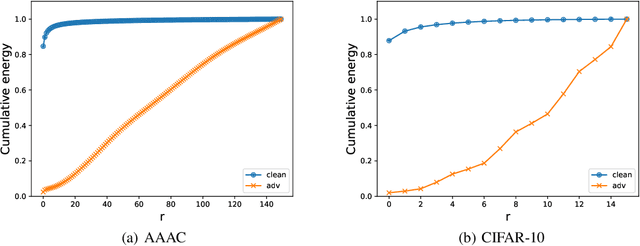

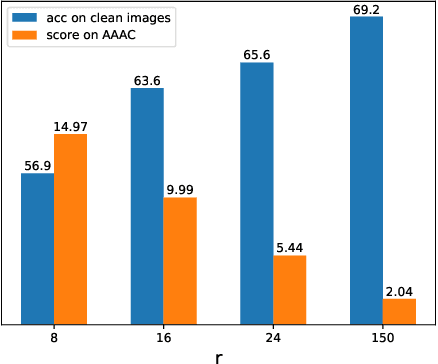
Recent works show that deep neural networks trained on image classification dataset bias towards textures. Those models are easily fooled by applying small high-frequency perturbations to the clean images. In this paper, we learn robust image classification models by removing high-frequency components. Specifically, we develop a differentiable high-frequency suppression module based on the discrete Fourier transform (DFT). Combining with adversarial training, we won the 5th place in the IJCAI-2019 Alibaba Adversarial AI Challenge. Our code is available online.