 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Extreme Augmentation : Can deep learning based medical image segmentation be trained using a single manually delineated scan?
Oct 03, 2018
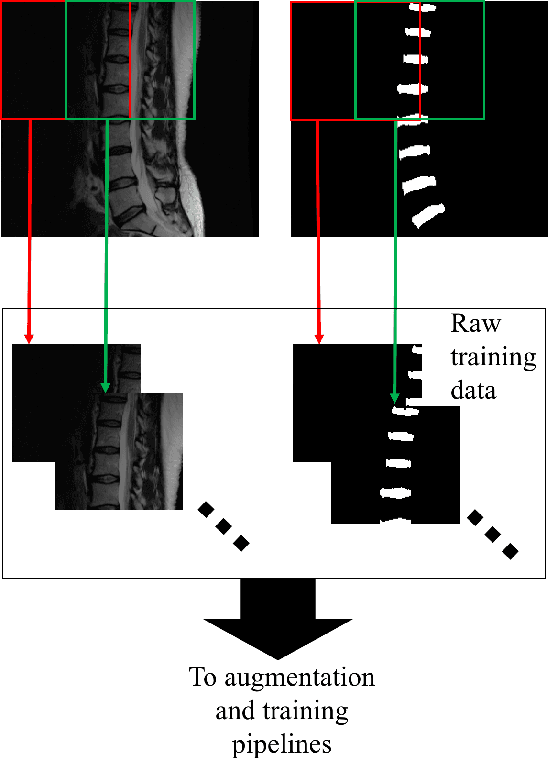
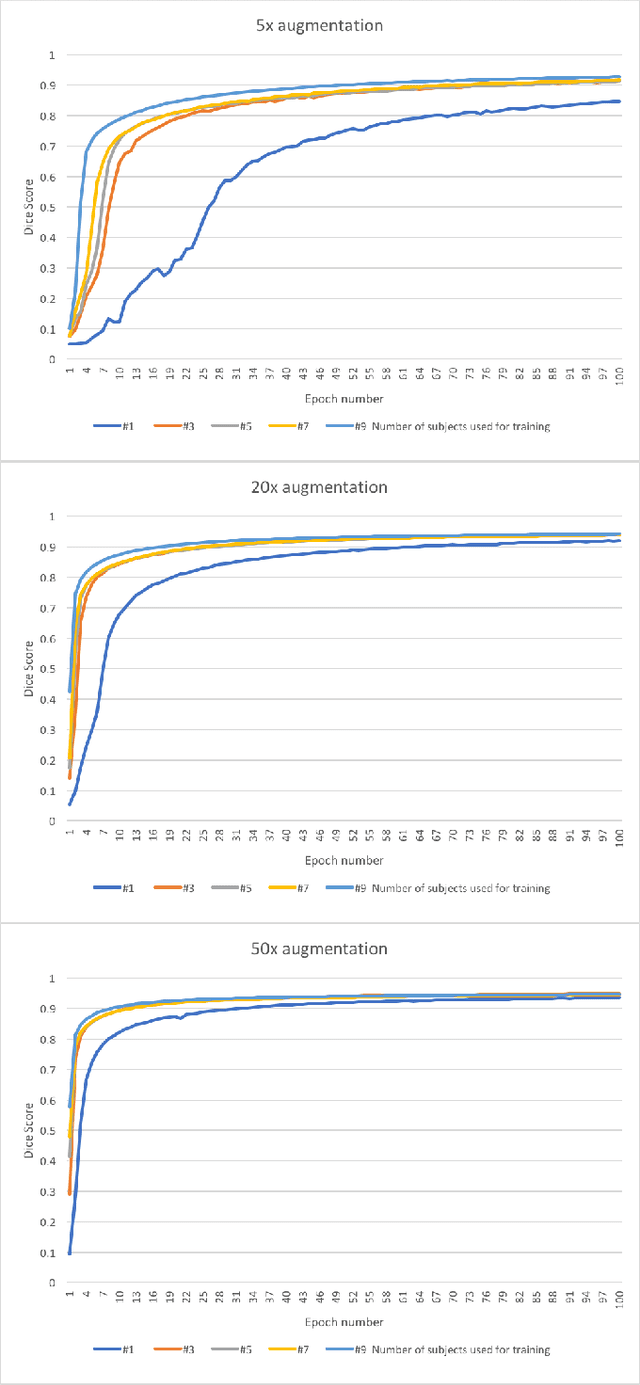
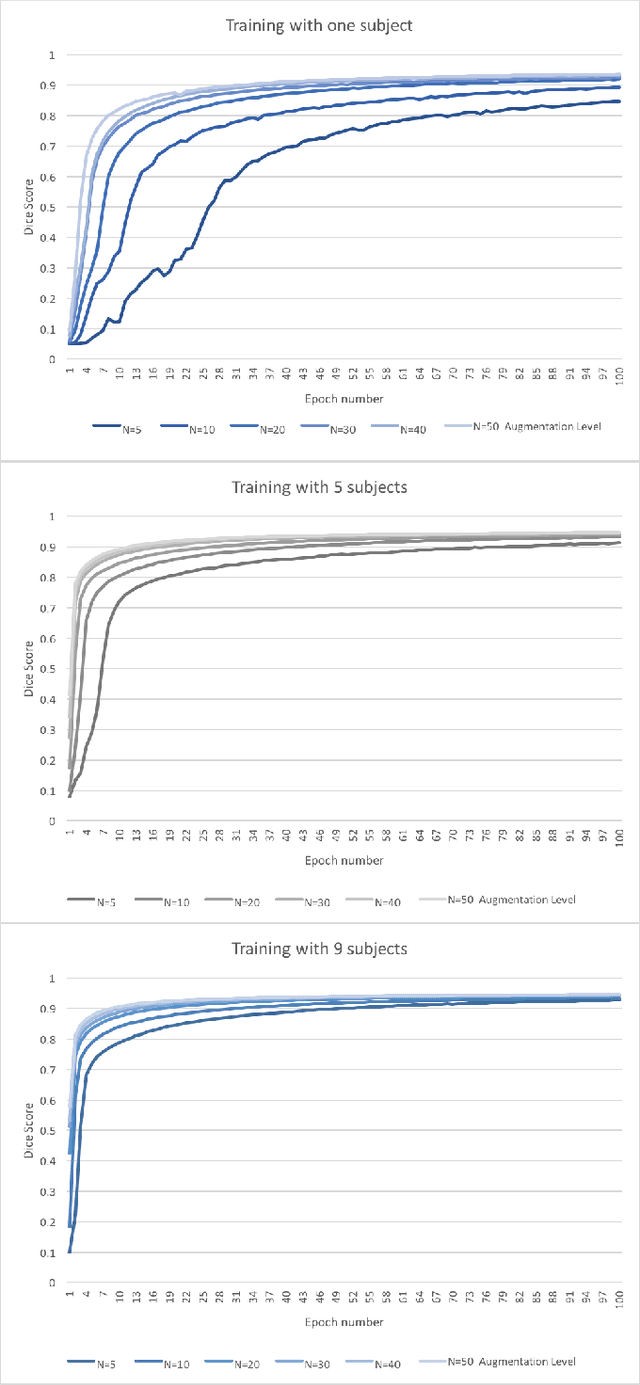
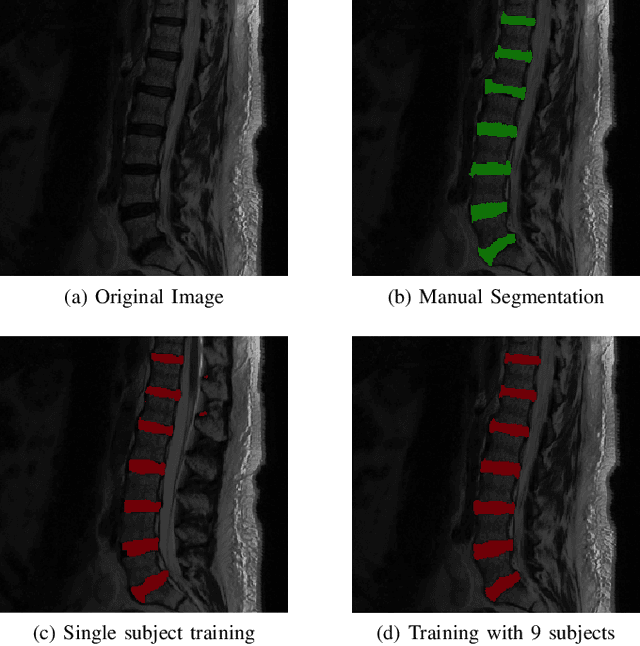
Yes, it can. Data augmentation is perhaps the oldest preprocessing step in computer vision literature. Almost every computer vision model trained on imaging data uses some form of augmentation. In this paper, we use the inter-vertebral disk segmentation task alongside a deep residual U-Net as the learning model, to explore the effectiveness of augmentation. In the extreme, we observed that a model trained on patches extracted from just one scan, with each patch augmented 50 times; achieved a Dice score of 0.73 in a validation set of 40 cases. Qualitative evaluation indicated a clinically usable segmentation algorithm, which appropriately segments regions of interest, alongside limited false positive specks. When the initial patches are extracted from nine scans the average Dice coefficient jumps to 0.86 and most of the false positives disappear. While this still falls short of state-of-the-art deep learning based segmentation of discs reported in literature, qualitative examination reveals that it does yield segmentation, which can be amended by expert clinicians with minimal effort to generate additional data for training improved deep models. Extreme augmentation of training data, should thus be construed as a strategy for training deep learning based algorithms, when very little manually annotated data is available to work with. Models trained with extreme augmentation can then be used to accelerate the generation of manually labelled data. Hence, we show that extreme augmentation can be a valuable tool in addressing scaling up small imaging data sets to address medical image segmentation tasks.
Multi-level Wavelet Convolutional Neural Networks
Jul 06, 2019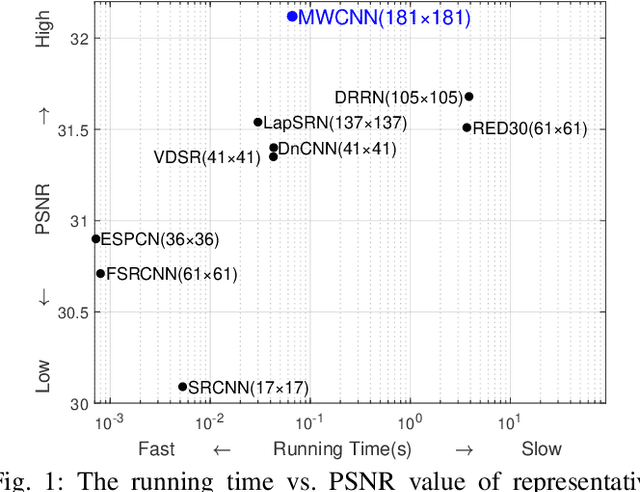
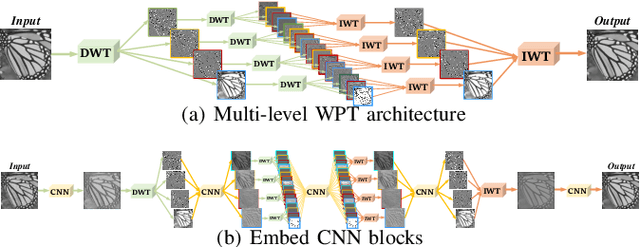
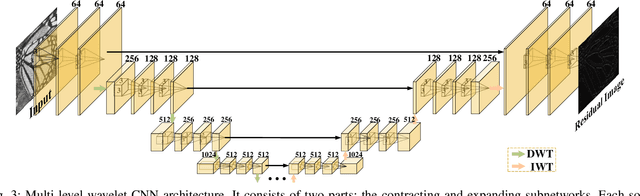
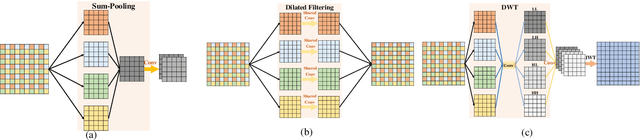
In computer vision, convolutional networks (CNNs) often adopts pooling to enlarge receptive field which has the advantage of low computational complexity. However, pooling can cause information loss and thus is detrimental to further operations such as features extraction and analysis. Recently, dilated filter has been proposed to trade off between receptive field size and efficiency. But the accompanying gridding effect can cause a sparse sampling of input images with checkerboard patterns. To address this problem, in this paper, we propose a novel multi-level wavelet CNN (MWCNN) model to achieve better trade-off between receptive field size and computational efficiency. The core idea is to embed wavelet transform into CNN architecture to reduce the resolution of feature maps while at the same time, increasing receptive field. Specifically, MWCNN for image restoration is based on U-Net architecture, and inverse wavelet transform (IWT) is deployed to reconstruct the high resolution (HR) feature maps. The proposed MWCNN can also be viewed as an improvement of dilated filter and a generalization of average pooling, and can be applied to not only image restoration tasks, but also any CNNs requiring a pooling operation. The experimental results demonstrate effectiveness of the proposed MWCNN for tasks such as image denoising, single image super-resolution, JPEG image artifacts removal and object classification.
Inception Augmentation Generative Adversarial Network
Jun 05, 2020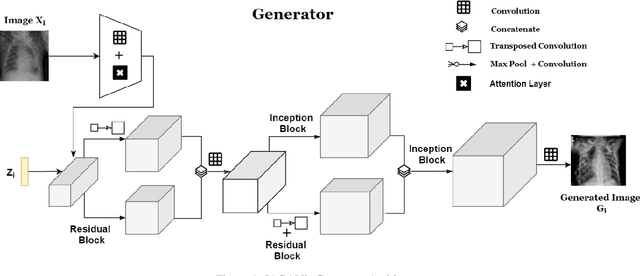
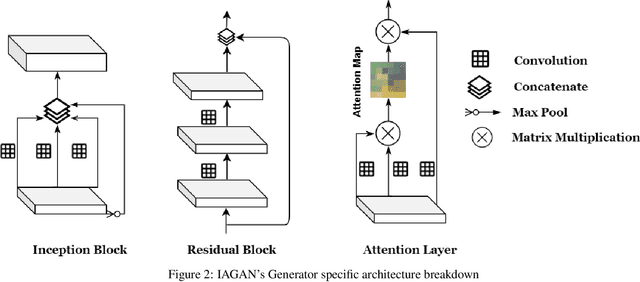
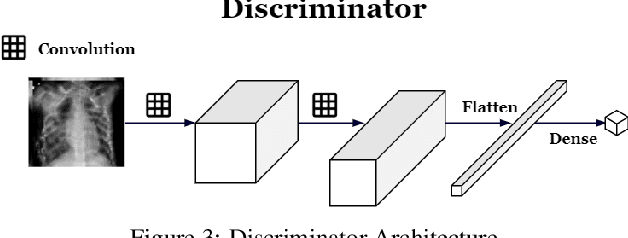
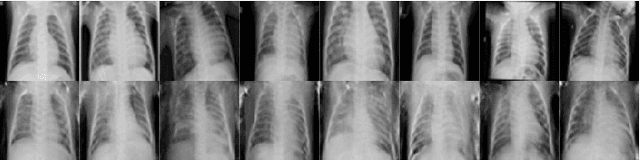
Successful training of convolutional neural networks (CNNs) requires a substantial amount of data. With small datasets, networks generalize poorly. Data Augmentation techniques improve the generalizability of neural networks by using existing training data more effectively. Standard data augmentation methods, however, produce limited plausible alternative data. Generative Adversarial Networks (GANs) have been utilized to generate new data and improve CNN performance. Nevertheless, generative models have not been used for augmenting data to improve the training of another generative model. In this work, we propose a new GAN architecture for semi-supervised augmentation of chest X-rays for the detection of pneumonia. We show that the proposed GAN can augment data for a specific class of images (pneumonia) using images from both classes (pneumonia and normal) in an image domain (chest X-rays). We demonstrate that using our proposed GAN-based data augmentation method significantly improves the performance of the state-of-the-art anomaly detection architecture, AnoGAN, in detecting pneumonia in chest X-rays, increasing AUC from 0.83 to 0.88.
Five Modulus Method For Image Compression
Nov 19, 2012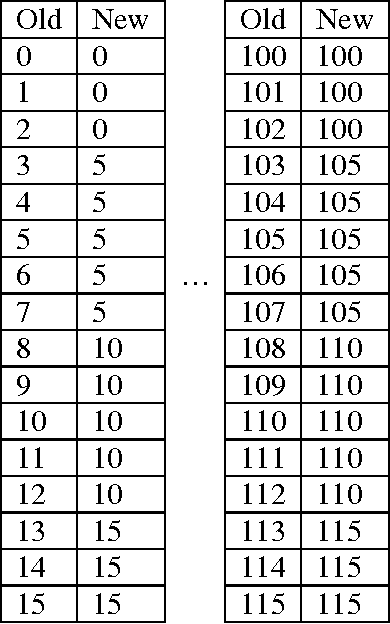
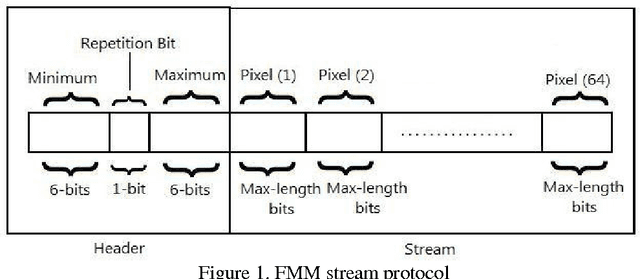

Data is compressed by reducing its redundancy, but this also makes the data less reliable, more prone to errors. In this paper a novel approach of image compression based on a new method that has been created for image compression which is called Five Modulus Method (FMM). The new method consists of converting each pixel value in an 8-by-8 block into a multiple of 5 for each of the R, G and B arrays. After that, the new values could be divided by 5 to get new values which are 6-bit length for each pixel and it is less in storage space than the original value which is 8-bits. Also, a new protocol for compression of the new values as a stream of bits has been presented that gives the opportunity to store and transfer the new compressed image easily.
* 10 pages, 2 figures, 9 tables
Solving Optimization Problems through Fully Convolutional Networks: an Application to the Travelling Salesman Problem
Oct 27, 2019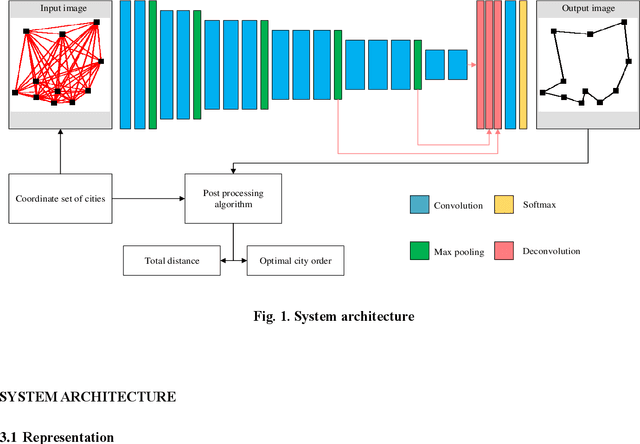
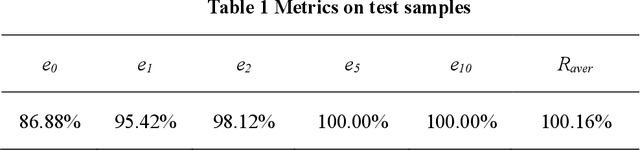
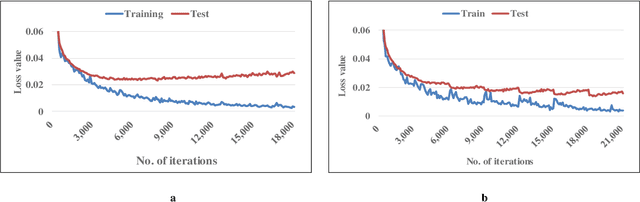

In the new wave of artificial intelligence, deep learning is impacting various industries. As a closely related area, optimization algorithms greatly contribute to the development of deep learning. But the reverse applications are still insufficient. Is there any efficient way to solve certain optimization problem through deep learning? The key is to convert the optimization to a representation suitable for deep learning. In this paper, a traveling salesman problem (TSP) is studied. Considering that deep learning is good at image processing, an image representation method is proposed to transfer a TSP to an image. Based on samples of a 10 city TSP, a fully convolutional network (FCN) is used to learn the mapping from a feasible region to an optimal solution. The training process is analyzed and interpreted through stages. A visualization method is presented to show how a FCN can understand the training task of a TSP. Once the training is completed, no significant effort is required to solve a new TSP and the prediction is obtained on the scale of milliseconds. The results show good performance in finding the global optimal solution. Moreover, the developed FCN model has been demonstrated on TSP's with different city numbers, proving excellent generalization performance.
Compressed Sensing Microscopy with Scanning Line Probes
Sep 26, 2019

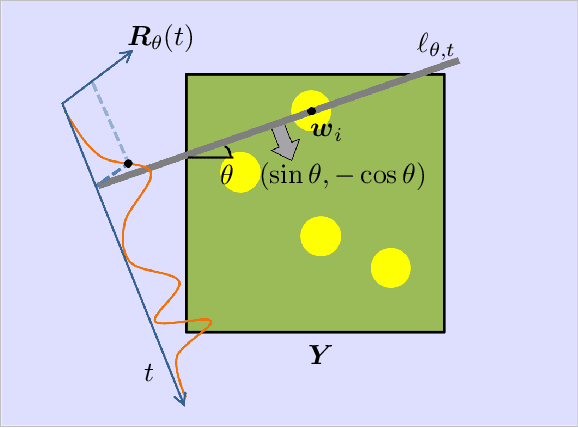
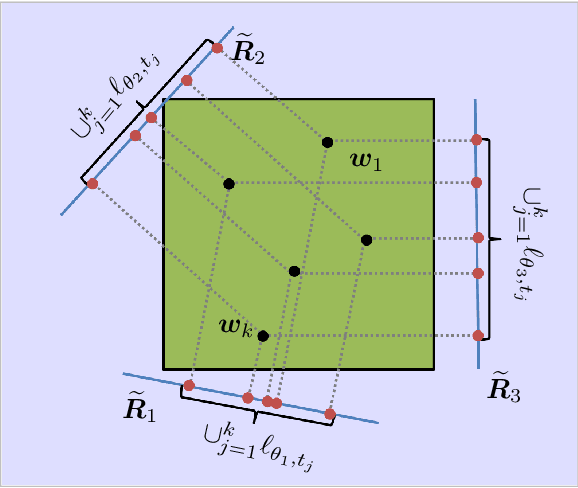
In applications of scanning probe microscopy, images are acquired by raster scanning a point probe across a sample. Viewed from the perspective of compressed sensing (CS), this pointwise sampling scheme is inefficient, especially when the target image is structured. While replacing point measurements with delocalized, incoherent measurements has the potential to yield order-of-magnitude improvements in scan time, implementing the delocalized measurements of CS theory is challenging. In this paper we study a partially delocalized probe construction, in which the point probe is replaced with a continuous line, creating a sensor which essentially acquires line integrals of the target image. We show through simulations, rudimentary theoretical analysis, and experiments, that these line measurements can image sparse samples far more efficiently than traditional point measurements, provided the local features in the sample are enough separated. Despite this promise, practical reconstruction from line measurements poses additional difficulties: the measurements are partially coherent, and real measurements exhibit nonidealities. We show how to overcome these limitations using natural strategies (reweighting to cope with coherence, blind calibration for nonidealities), culminating in an end-to-end demonstration.
Dynamic Graph Attention for Referring Expression Comprehension
Sep 18, 2019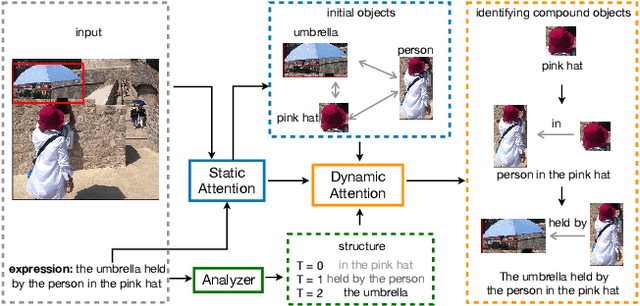
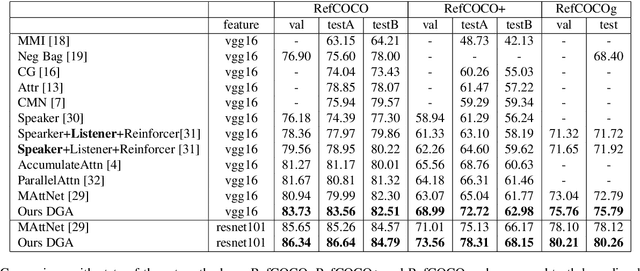
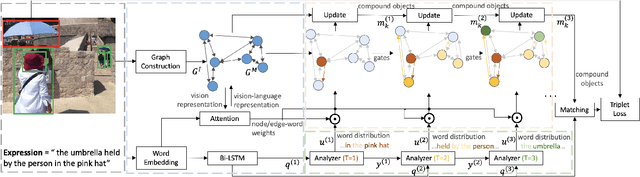
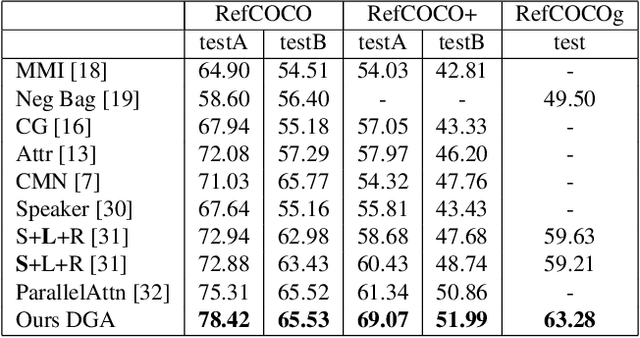
Referring expression comprehension aims to locate the object instance described by a natural language referring expression in an image. This task is compositional and inherently requires visual reasoning on top of the relationships among the objects in the image. Meanwhile, the visual reasoning process is guided by the linguistic structure of the referring expression. However, existing approaches treat the objects in isolation or only explore the first-order relationships between objects without being aligned with the potential complexity of the expression. Thus it is hard for them to adapt to the grounding of complex referring expressions. In this paper, we explore the problem of referring expression comprehension from the perspective of language-driven visual reasoning, and propose a dynamic graph attention network to perform multi-step reasoning by modeling both the relationships among the objects in the image and the linguistic structure of the expression. In particular, we construct a graph for the image with the nodes and edges corresponding to the objects and their relationships respectively, propose a differential analyzer to predict a language-guided visual reasoning process, and perform stepwise reasoning on top of the graph to update the compound object representation at every node. Experimental results demonstrate that the proposed method can not only significantly surpass all existing state-of-the-art algorithms across three common benchmark datasets, but also generate interpretable visual evidences for stepwisely locating the objects referred to in complex language descriptions.
Conv-MPN: Convolutional Message Passing Neural Network for Structured Outdoor Architecture Reconstruction
Dec 04, 2019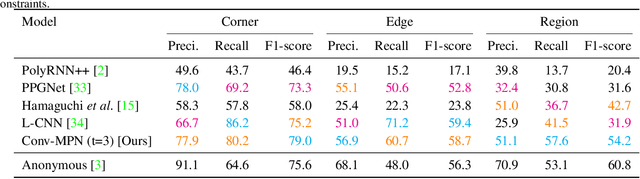

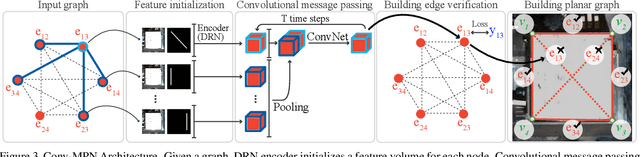
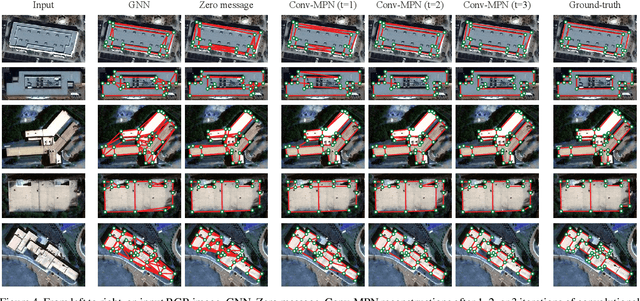
This paper proposes a novel message passing neural (MPN) architecture Conv-MPN, which reconstructs an outdoor building as a planar graph from a single RGB image. Conv-MPN is specifically designed for cases where nodes of a graph have explicit spatial embedding. In our problem, nodes correspond to building edges in an image. Conv-MPN is different from MPN in that 1) the feature associated with a node is represented as a feature volume instead of a 1D vector; and 2) convolutions encode messages instead of fully connected layers. Conv-MPN learns to select a true subset of nodes (i.e., building edges) to reconstruct a building planar graph. Our qualitative and quantitative evaluations over 2,000 buildings show that Conv-MPN makes significant improvements over the existing fully neural solutions. We believe that the paper has a potential to open a new line of graph neural network research for structured geometry reconstruction.
TopoAct: Exploring the Shape of Activations in Deep Learning
Dec 13, 2019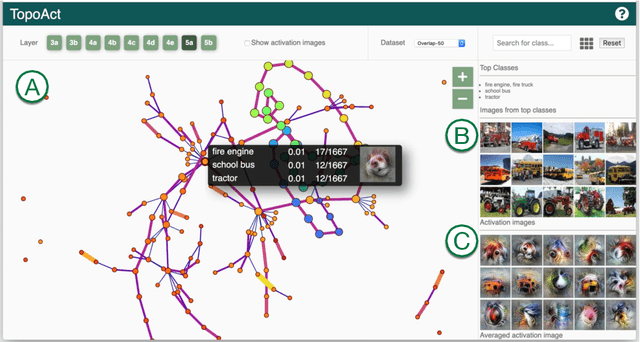
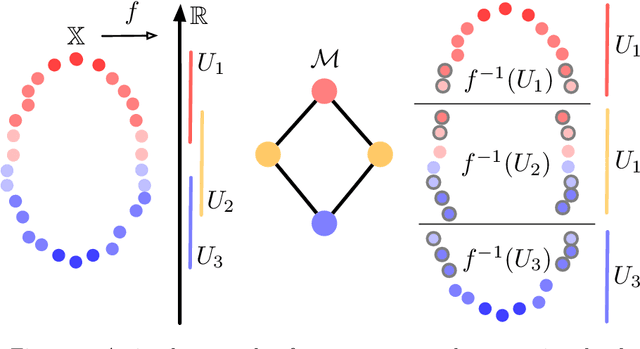
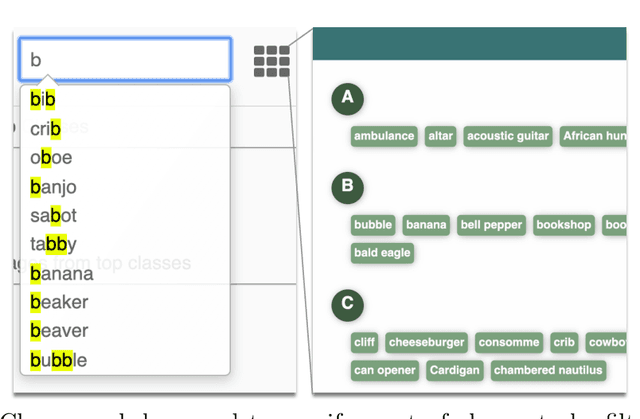
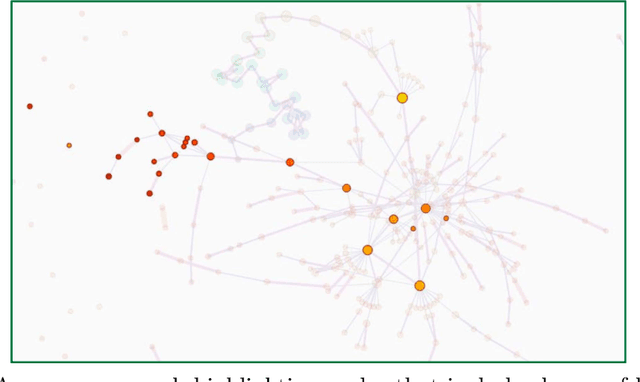
Deep neural networks such as GoogLeNet and ResNet have achieved superhuman performance in tasks like image classification. To understand how such superior performance is achieved, we can probe a trained deep neural network by studying neuron activations, that is, combinations of neuron firings, at any layer of the network in response to a particular input. With a large set of input images, we aim to obtain a global view of what neurons detect by studying their activations. We ask the following questions: What is the shape of the space of activations? That is, what is the organizational principle behind neuron activations, and how are the activations related within a layer and across layers? Applying tools from topological data analysis, we present TopoAct, a visual exploration system used to study topological summaries of activation vectors for a single layer as well as the evolution of such summaries across multiple layers. We present visual exploration scenarios using TopoAct that provide valuable insights towards learned representations of an image classifier.
Embedded Encoder-Decoder in Convolutional Networks Towards Explainable AI
Jun 19, 2020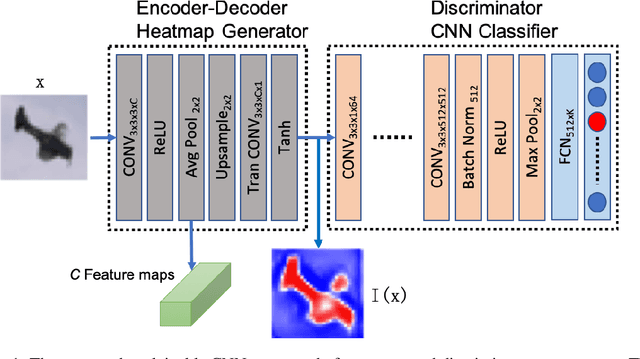


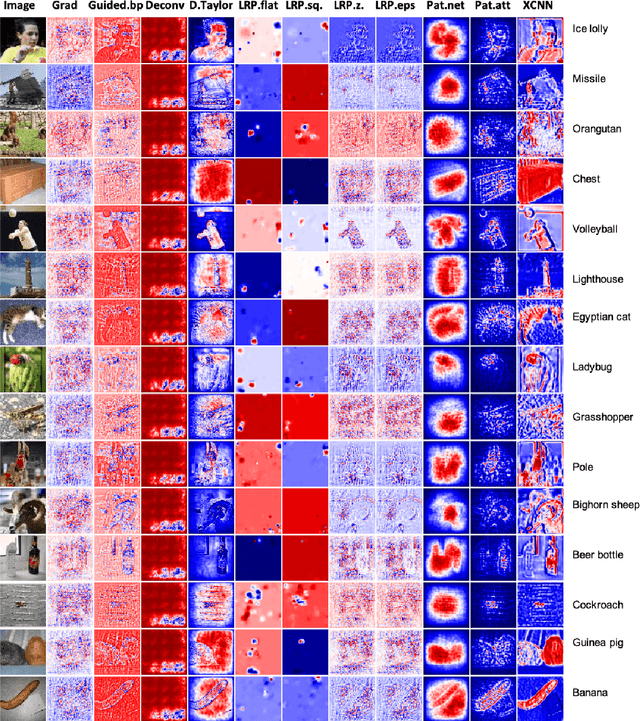
Understanding intermediate layers of a deep learning model and discovering the driving features of stimuli have attracted much interest, recently. Explainable artificial intelligence (XAI) provides a new way to open an AI black box and makes a transparent and interpretable decision. This paper proposes a new explainable convolutional neural network (XCNN) which represents important and driving visual features of stimuli in an end-to-end model architecture. This network employs encoder-decoder neural networks in a CNN architecture to represent regions of interest in an image based on its category. The proposed model is trained without localization labels and generates a heat-map as part of the network architecture without extra post-processing steps. The experimental results on the CIFAR-10, Tiny ImageNet, and MNIST datasets showed the success of our algorithm (XCNN) to make CNNs explainable. Based on visual assessment, the proposed model outperforms the current algorithms in class-specific feature representation and interpretable heatmap generation while providing a simple and flexible network architecture. The initial success of this approach warrants further study to enhance weakly supervised localization and semantic segmentation in explainable frameworks.