 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Make-A-Character: High Quality Text-to-3D Character Generation within Minutes
Dec 24, 2023
There is a growing demand for customized and expressive 3D characters with the emergence of AI agents and Metaverse, but creating 3D characters using traditional computer graphics tools is a complex and time-consuming task. To address these challenges, we propose a user-friendly framework named Make-A-Character (Mach) to create lifelike 3D avatars from text descriptions. The framework leverages the power of large language and vision models for textual intention understanding and intermediate image generation, followed by a series of human-oriented visual perception and 3D generation modules. Our system offers an intuitive approach for users to craft controllable, realistic, fully-realized 3D characters that meet their expectations within 2 minutes, while also enabling easy integration with existing CG pipeline for dynamic expressiveness. For more information, please visit the project page at https://human3daigc.github.io/MACH/.
Open-Set: ID Card Presentation Attack Detection using Neural Transfer Style
Dec 21, 2023The accurate detection of ID card Presentation Attacks (PA) is becoming increasingly important due to the rising number of online/remote services that require the presentation of digital photographs of ID cards for digital onboarding or authentication. Furthermore, cybercriminals are continuously searching for innovative ways to fool authentication systems to gain unauthorized access to these services. Although advances in neural network design and training have pushed image classification to the state of the art, one of the main challenges faced by the development of fraud detection systems is the curation of representative datasets for training and evaluation. The handcrafted creation of representative presentation attack samples often requires expertise and is very time-consuming, thus an automatic process of obtaining high-quality data is highly desirable. This work explores ID card Presentation Attack Instruments (PAI) in order to improve the generation of samples with four Generative Adversarial Networks (GANs) based image translation models and analyses the effectiveness of the generated data for training fraud detection systems. Using open-source data, we show that synthetic attack presentations are an adequate complement for additional real attack presentations, where we obtain an EER performance increase of 0.63% points for print attacks and a loss of 0.29% for screen capture attacks.
Secure Information Embedding in Images with Hybrid Firefly Algorithm
Dec 21, 2023Various methods have been proposed to secure access to sensitive information over time, such as the many cryptographic methods in use to facilitate secure communications on the internet. But other methods like steganography have been overlooked which may be more suitable in cases where the act of transmission of sensitive information itself should remain a secret. Multiple techniques that are commonly discussed for such scenarios suffer from low capacity and high distortion in the output signal. This research introduces a novel steganographic approach for concealing a confidential portable document format (PDF) document within a host image by employing the Hybrid Firefly algorithm (HFA) proposed to select the pixel arrangement. This algorithm combines two widely used optimization algorithms to improve their performance. The suggested methodology utilizes the HFA algorithm to conduct a search for optimal pixel placements in the spatial domain. The purpose of this search is to accomplish two main goals: increasing the host image's capacity and reducing distortion. Moreover, the proposed approach intends to reduce the time required for the embedding procedure. The findings indicate a decrease in image distortion and an accelerated rate of convergence in the search process. The resultant embeddings exhibit robustness against steganalytic assaults, hence rendering the identification of the embedded data a formidable undertaking.
Towards Flexible, Scalable, and Adaptive Multi-Modal Conditioned Face Synthesis
Dec 26, 2023Recent progress in multi-modal conditioned face synthesis has enabled the creation of visually striking and accurately aligned facial images. Yet, current methods still face issues with scalability, limited flexibility, and a one-size-fits-all approach to control strength, not accounting for the differing levels of conditional entropy, a measure of unpredictability in data given some condition, across modalities. To address these challenges, we introduce a novel uni-modal training approach with modal surrogates, coupled with an entropy-aware modal-adaptive modulation, to support flexible, scalable, and scalable multi-modal conditioned face synthesis network. Our uni-modal training with modal surrogate that only leverage uni-modal data, use modal surrogate to decorate condition with modal-specific characteristic and serve as linker for inter-modal collaboration , fully learns each modality control in face synthesis process as well as inter-modal collaboration. The entropy-aware modal-adaptive modulation finely adjust diffusion noise according to modal-specific characteristics and given conditions, enabling well-informed step along denoising trajectory and ultimately leading to synthesis results of high fidelity and quality. Our framework improves multi-modal face synthesis under various conditions, surpassing current methods in image quality and fidelity, as demonstrated by our thorough experimental results.
FAAC: Facial Animation Generation with Anchor Frame and Conditional Control for Superior Fidelity and Editability
Dec 20, 2023Over recent years, diffusion models have facilitated significant advancements in video generation. Yet, the creation of face-related videos still confronts issues such as low facial fidelity, lack of frame consistency, limited editability and uncontrollable human poses. To address these challenges, we introduce a facial animation generation method that enhances both face identity fidelity and editing capabilities while ensuring frame consistency. This approach incorporates the concept of an anchor frame to counteract the degradation of generative ability in original text-to-image models when incorporating a motion module. We propose two strategies towards this objective: training-free and training-based anchor frame methods. Our method's efficacy has been validated on multiple representative DreamBooth and LoRA models, delivering substantial improvements over the original outcomes in terms of facial fidelity, text-to-image editability, and video motion. Moreover, we introduce conditional control using a 3D parametric face model to capture accurate facial movements and expressions. This solution augments the creative possibilities for facial animation generation through the integration of multiple control signals. For additional samples, please visit https://paper-faac.github.io/.
EmbAu: A Novel Technique to Embed Audio Data Using Shuffled Frog Leaping Algorithm
Dec 13, 2023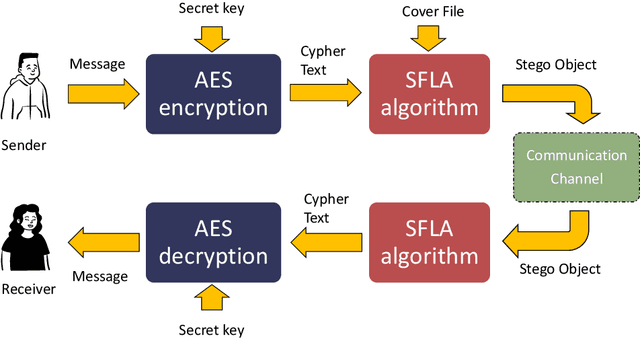



The aim of steganographic algorithms is to identify the appropriate pixel positions in the host or cover image, where bits of sensitive information can be concealed for data encryption. Work is being done to improve the capacity to integrate sensitive information and to maintain the visual appearance of the steganographic image. Consequently, steganography is a challenging research area. In our currently proposed image steganographic technique, we used the Shuffled Frog Leaping Algorithm (SFLA) to determine the order of pixels by which sensitive information can be placed in the cover image. To achieve greater embedding capacity, pixels from the spatial domain of the cover image are carefully chosen and used for placing the sensitive data. Bolstered via image steganography, the final image after embedding is resistant to steganalytic attacks. The SFLA algorithm serves in the optimal pixels selection of any colored (RGB) cover image for secret bit embedding. Using the fitness function, the SFLA benefits by reaching a minimum cost value in an acceptable amount of time. The pixels for embedding are meticulously chosen to minimize the host image's distortion upon embedding. Moreover, an effort has been taken to make the detection of embedded data in the steganographic image a formidable challenge. Due to the enormous need for audio data encryption in the current world, we feel that our suggested method has significant potential in real-world applications. In this paper, we propose and compare our strategy to existing steganographic methods.
Progressive Feature Self-reinforcement for Weakly Supervised Semantic Segmentation
Dec 18, 2023Compared to conventional semantic segmentation with pixel-level supervision, Weakly Supervised Semantic Segmentation (WSSS) with image-level labels poses the challenge that it always focuses on the most discriminative regions, resulting in a disparity between fully supervised conditions. A typical manifestation is the diminished precision on the object boundaries, leading to a deteriorated accuracy of WSSS. To alleviate this issue, we propose to adaptively partition the image content into deterministic regions (e.g., confident foreground and background) and uncertain regions (e.g., object boundaries and misclassified categories) for separate processing. For uncertain cues, we employ an activation-based masking strategy and seek to recover the local information with self-distilled knowledge. We further assume that the unmasked confident regions should be robust enough to preserve the global semantics. Building upon this, we introduce a complementary self-enhancement method that constrains the semantic consistency between these confident regions and an augmented image with the same class labels. Extensive experiments conducted on PASCAL VOC 2012 and MS COCO 2014 demonstrate that our proposed single-stage approach for WSSS not only outperforms state-of-the-art benchmarks remarkably but also surpasses multi-stage methodologies that trade complexity for accuracy. The code can be found at \url{https://github.com/Jessie459/feature-self-reinforcement}.
CLOVA: A Closed-Loop Visual Assistant with Tool Usage and Update
Dec 18, 2023Leveraging large language models (LLMs) to integrate off-the-shelf tools (e.g., visual models and image processing functions) is a promising research direction to build powerful visual assistants for solving diverse visual tasks. However, the learning capability is rarely explored in existing methods, as they freeze the used tools after deployment, thereby limiting the generalization to new environments requiring specific knowledge. In this paper, we propose CLOVA, a Closed-LOop Visual Assistant to address this limitation, which encompasses inference, reflection, and learning phases in a closed-loop framework. During inference, LLMs generate programs and execute corresponding tools to accomplish given tasks. The reflection phase introduces a multimodal global-local reflection scheme to analyze whether and which tool needs to be updated based on environmental feedback. Lastly, the learning phase uses three flexible manners to collect training data in real-time and introduces a novel prompt tuning scheme to update the tools, enabling CLOVA to efficiently learn specific knowledge for new environments without human involvement. Experiments show that CLOVA outperforms tool-usage methods by 5% in visual question answering and multiple-image reasoning tasks, by 10% in knowledge tagging tasks, and by 20% in image editing tasks, highlighting the significance of the learning capability for general visual assistants.
Painterly Image Harmonization via Adversarial Residual Learning
Nov 15, 2023Image compositing plays a vital role in photo editing. After inserting a foreground object into another background image, the composite image may look unnatural and inharmonious. When the foreground is photorealistic and the background is an artistic painting, painterly image harmonization aims to transfer the style of background painting to the foreground object, which is a challenging task due to the large domain gap between foreground and background. In this work, we employ adversarial learning to bridge the domain gap between foreground feature map and background feature map. Specifically, we design a dual-encoder generator, in which the residual encoder produces the residual features added to the foreground feature map from main encoder. Then, a pixel-wise discriminator plays against the generator, encouraging the refined foreground feature map to be indistinguishable from background feature map. Extensive experiments demonstrate that our method could achieve more harmonious and visually appealing results than previous methods.
Harnessing Diffusion Models for Visual Perception with Meta Prompts
Dec 22, 2023The issue of generative pretraining for vision models has persisted as a long-standing conundrum. At present, the text-to-image (T2I) diffusion model demonstrates remarkable proficiency in generating high-definition images matching textual inputs, a feat made possible through its pre-training on large-scale image-text pairs. This leads to a natural inquiry: can diffusion models be utilized to tackle visual perception tasks? In this paper, we propose a simple yet effective scheme to harness a diffusion model for visual perception tasks. Our key insight is to introduce learnable embeddings (meta prompts) to the pre-trained diffusion models to extract proper features for perception. The effect of meta prompts are two-fold. First, as a direct replacement of the text embeddings in the T2I models, it can activate task-relevant features during feature extraction. Second, it will be used to re-arrange the extracted features to ensures that the model focuses on the most pertinent features for the task on hand. Additionally, we design a recurrent refinement training strategy that fully leverages the property of diffusion models, thereby yielding stronger visual features. Extensive experiments across various benchmarks validate the effectiveness of our approach. Our approach achieves new performance records in depth estimation tasks on NYU depth V2 and KITTI, and in semantic segmentation task on CityScapes. Concurrently, the proposed method attains results comparable to the current state-of-the-art in semantic segmentation on ADE20K and pose estimation on COCO datasets, further exemplifying its robustness and versatility.