 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Training for Domain Adaptive Scene Text Detection
May 23, 2020
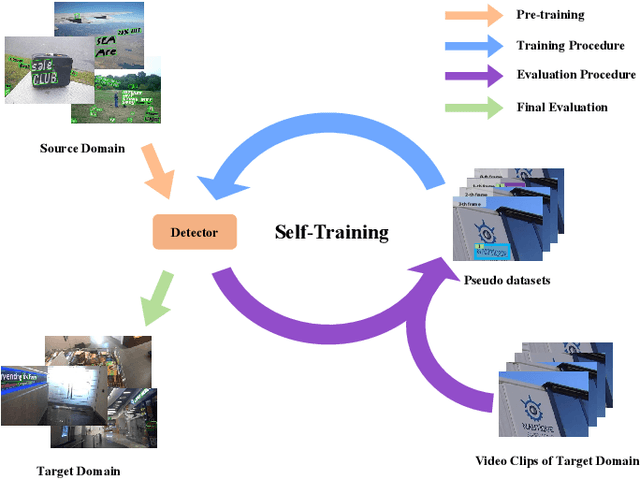
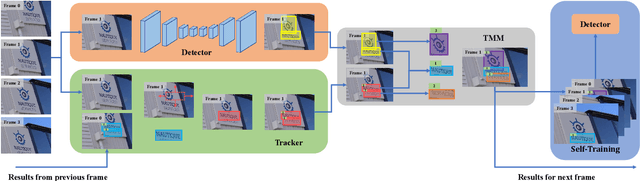
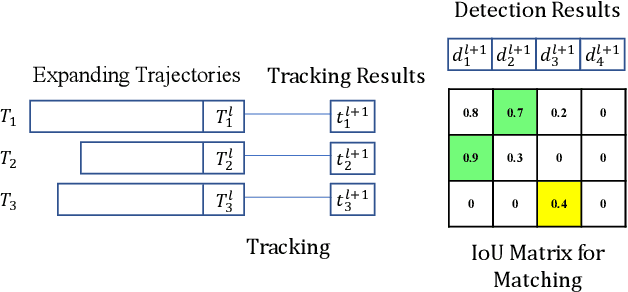

Though deep learning based scene text detection has achieved great progress, well-trained detectors suffer from severe performance degradation for different domains. In general, a tremendous amount of data is indispensable to train the detector in the target domain. However, data collection and annotation are expensive and time-consuming. To address this problem, we propose a self-training framework to automatically mine hard examples with pseudo-labels from unannotated videos or images. To reduce the noise of hard examples, a novel text mining module is implemented based on the fusion of detection and tracking results. Then, an image-to-video generation method is designed for the tasks that videos are unavailable and only images can be used. Experimental results on standard benchmarks, including ICDAR2015, MSRA-TD500, ICDAR2017 MLT, demonstrate the effectiveness of our self-training method. The simple Mask R-CNN adapted with self-training and fine-tuned on real data can achieve comparable or even superior results with the state-of-the-art methods.
Semantic Segmentation for Compound figures
Dec 16, 2019

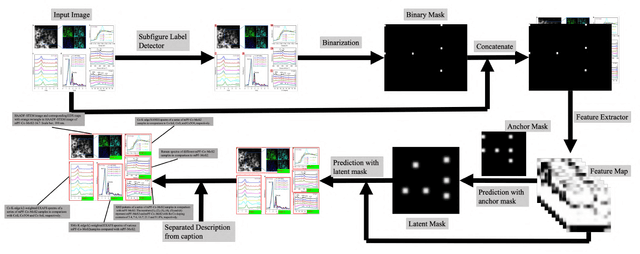

Scientific literature contains large volumes of unstructured data,with over 30\% of figures constructed as a combination of multiple images, these compound figures cannot be analyzed directly with existing information retrieval tools. In this paper, we propose a semantic segmentation approach for compound figure separation, decomposing the compound figures into "master images". Each master image is one part of a compound figure governed by a subfigure label (typically "(a), (b), (c), etc"). In this way, the separated subfigures can be easily associated with the description information in the caption. In particular, we propose an anchor-based master image detection algorithm, which leverages the correlation between master images and subfigure labels and locates the master images in a two-step manner. First, a subfigure label detector is built to extract the global layout information of the compound figure. Second, the layout information is combined with local features to locate the master images. We validate the effectiveness of proposed method on our labeled testing dataset both quantitatively and qualitatively.
AdaLAM: Revisiting Handcrafted Outlier Detection
Jun 07, 2020
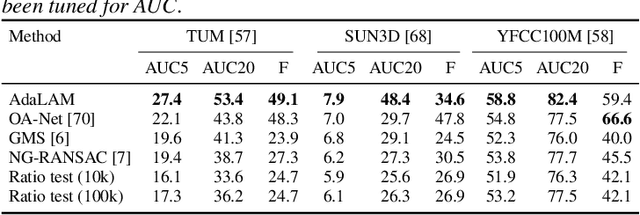

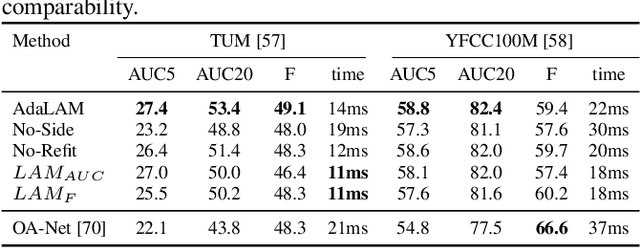
Local feature matching is a critical component of many computer vision pipelines, including among others Structure-from-Motion, SLAM, and Visual Localization. However, due to limitations in the descriptors, raw matches are often contaminated by a majority of outliers. As a result, outlier detection is a fundamental problem in computer vision, and a wide range of approaches have been proposed over the last decades. In this paper we revisit handcrafted approaches to outlier filtering. Based on best practices, we propose a hierarchical pipeline for effective outlier detection as well as integrate novel ideas which in sum lead to AdaLAM, an efficient and competitive approach to outlier rejection. AdaLAM is designed to effectively exploit modern parallel hardware, resulting in a very fast, yet very accurate, outlier filter. We validate AdaLAM on multiple large and diverse datasets, and we submit to the Image Matching Challenge (CVPR2020), obtaining competitive results with simple baseline descriptors. We show that AdaLAM is more than competitive to current state of the art, both in terms of efficiency and effectiveness.
DuDoNet++: Encoding mask projection to reduce CT metal artifacts
Jan 18, 2020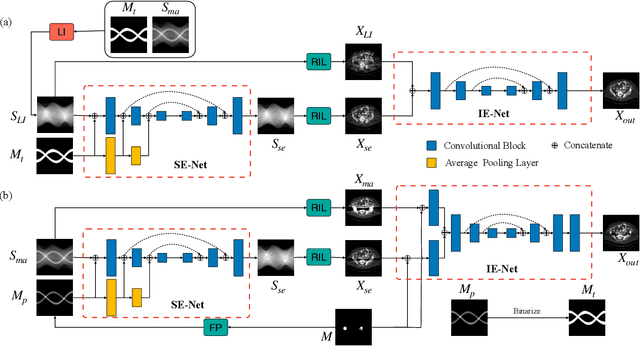

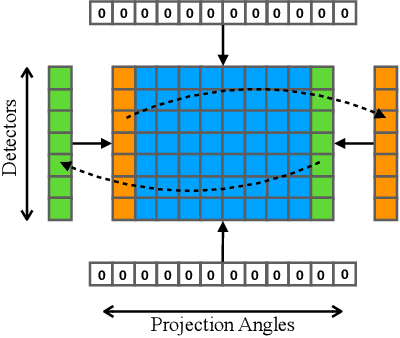

CT metal artifact reduction (MAR) is a notoriously challenging task because the artifacts are structured and non-local in the image domain. However, they are inherently local in the sinogram domain. DuDoNet is the state-of-the-art MAR algorithm which exploits the latter characteristic by learning to reduce artifacts in the sinogram and image domain jointly. By design, DuDoNet treats the metal-affected regions in sinogram as missing and replaces them with the surrogate data generated by a neural network. Since fine-grained details within the metal-affected regions are completely ignored, the artifact-reduced CT images by DuDoNet tend to be over-smoothed and distorted. In this work, we investigate the issue by theoretical derivation. We propose to address the problem by (1) retaining the metal-affected regions in sinogram and (2) replacing the binarized metal trace with the metal mask projection such that the geometry information of metal implants is encoded. Extensive experiments on simulated datasets and expert evaluations on clinical images demonstrate that our network called DuDoNet++ yields anatomically more precise artifact-reduced images than DuDoNet, especially when the metallic objects are large.
FilterNet: A Neighborhood Relationship Enhanced Fully Convolutional Network for Calf Muscle Compartment Segmentation
Jun 21, 2020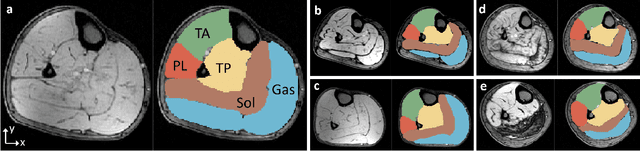
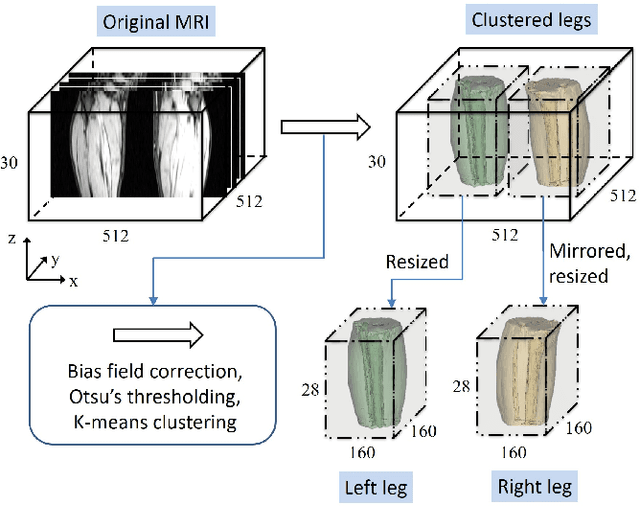
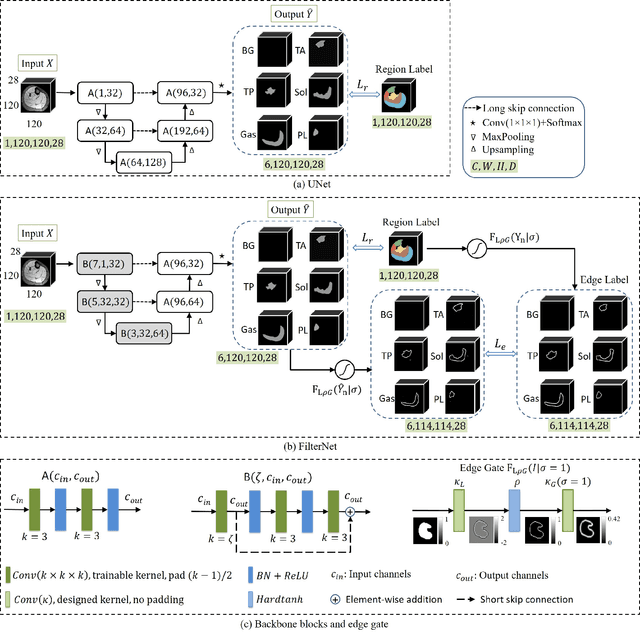

Automated segmentation of individual calf muscle compartments from 3D magnetic resonance (MR) images is essential for developing quantitative biomarkers for muscular disease progression and its prediction. Achieving clinically acceptable results is a challenging task due to large variations in muscle shape and MR appearance. Although deep convolutional neural networks (DCNNs) achieved improved accuracy in various image segmentation tasks, certain problems such as utilizing long-range information and incorporating high-level constraints remain unsolved. We present a novel fully convolutional network (FCN), called FilterNet, that utilizes contextual information in a large neighborhood and embeds edge-aware constraints for individual calf muscle compartment segmentations. An encoder-decoder architecture with flexible backbone blocks is used to systematically enlarge convolution receptive field and preserve information at all resolutions. Edge positions derived from the FCN output muscle probability maps are explicitly regularized using kernel-based edge detection in an end-to-end optimization framework. Our FilterNet was evaluated on 40 T1-weighted MR images of 10 healthy and 30 diseased subjects by 4-fold cross-validation. Mean DICE coefficients of 88.00%--91.29% and mean absolute surface positioning errors of 1.04--1.66 mm were achieved for the five 3D muscle compartments.
IV-SLAM: Introspective Vision for Simultaneous Localization and Mapping
Aug 06, 2020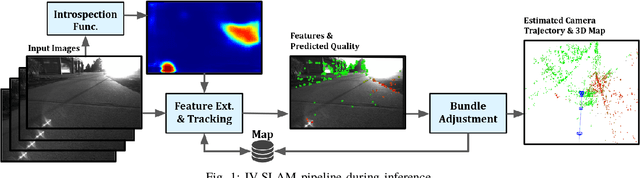

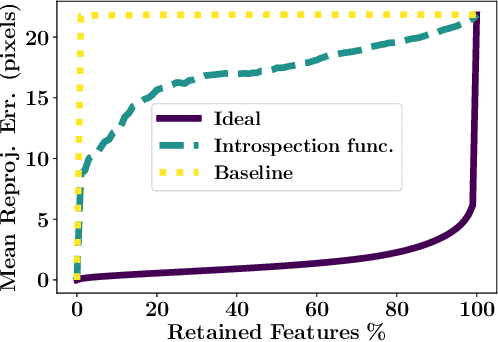
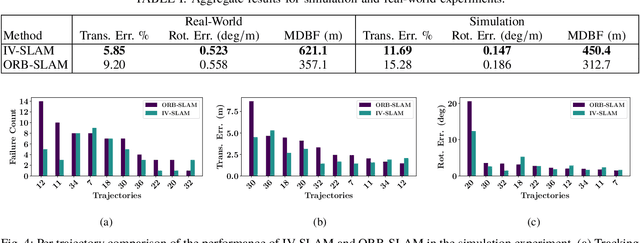
Existing solutions to visual simultaneous localization and mapping (V-SLAM) assume that errors in feature extraction and matching are independent and identically distributed (i.i.d), but this assumption is known to not be true -- features extracted from low-contrast regions of images exhibit wider error distributions than features from sharp corners. Furthermore, V-SLAM algorithms are prone to catastrophic tracking failures when sensed images include challenging conditions such as specular reflections, lens flare, or shadows of dynamic objects. To address such failures, previous work has focused on building more robust visual frontends, to filter out challenging features. In this paper, we present introspective vision for SLAM (IV-SLAM), a fundamentally different approach for addressing these challenges. IV-SLAM explicitly models the noise process of reprojection errors from visual features to be context-dependent, and hence non-i.i.d. We introduce an autonomously supervised approach for IV-SLAM to collect training data to learn such a context-aware noise model. Using this learned noise model, IV-SLAM guides feature extraction to select more features from parts of the image that are likely to result in lower noise, and further incorporate the learned noise model into the joint maximum likelihood estimation, thus making it robust to the aforementioned types of errors. We present empirical results to demonstrate that IV-SLAM 1) is able to accurately predict sources of error in input images, 2) reduces tracking error compared to V-SLAM, and 3) increases the mean distance between tracking failures by more than 70% on challenging real robot data compared to V-SLAM.
Traffic Sign Detection and Recognition for Autonomous Driving in Virtual Simulation Environment
Oct 27, 2019

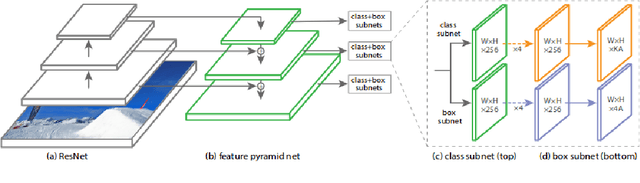

This study developed a traffic sign detection and recognition algorithm based on the RetinaNet. Two main aspects were revised to improve the detection of traffic signs: image cropping to address the issue of large image and small traffic signs; and using more anchors with various scales to detect traffic signs with different sizes and shapes. The proposed algorithm was trained and tested in a series of autonomous driving front-view images in a virtual simulation environment. Results show that the algorithm performed extremely well under good illumination and weather conditions. Its drawbacks are that it sometimes failed to detect object under bad weather conditions like snow and failed to distinguish speed limits signs with different limit values.
Improving Visual Question Answering by Referring to Generated Paragraph Captions
Jun 14, 2019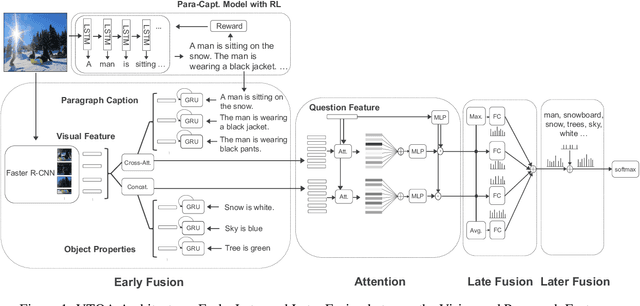


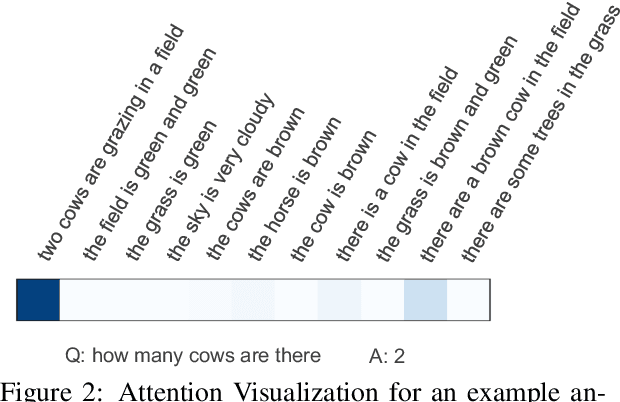
Paragraph-style image captions describe diverse aspects of an image as opposed to the more common single-sentence captions that only provide an abstract description of the image. These paragraph captions can hence contain substantial information of the image for tasks such as visual question answering. Moreover, this textual information is complementary with visual information present in the image because it can discuss both more abstract concepts and more explicit, intermediate symbolic information about objects, events, and scenes that can directly be matched with the textual question and copied into the textual answer (i.e., via easier modality match). Hence, we propose a combined Visual and Textual Question Answering (VTQA) model which takes as input a paragraph caption as well as the corresponding image, and answers the given question based on both inputs. In our model, the inputs are fused to extract related information by cross-attention (early fusion), then fused again in the form of consensus (late fusion), and finally expected answers are given an extra score to enhance the chance of selection (later fusion). Empirical results show that paragraph captions, even when automatically generated (via an RL-based encoder-decoder model), help correctly answer more visual questions. Overall, our joint model, when trained on the Visual Genome dataset, significantly improves the VQA performance over a strong baseline model.
Radio Access Technology Characterisation Through Object Detection
Jul 27, 2020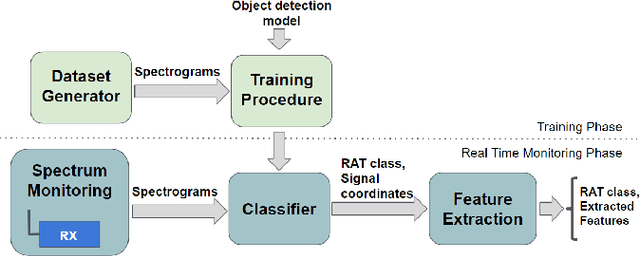
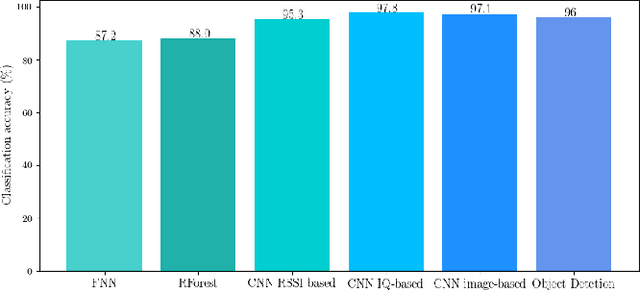

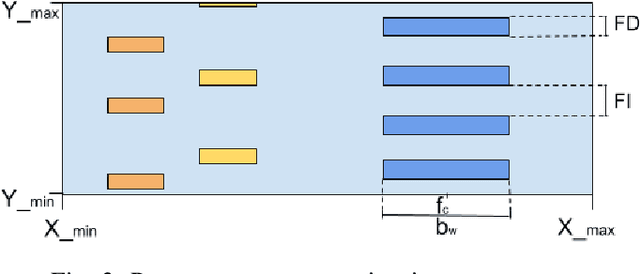
\ac{RAT} classification and monitoring are essential for efficient coexistence of different communication systems in shared spectrum. Shared spectrum, including operation in license-exempt bands, is envisioned in the \ac{5G} standards (e.g., 3GPP Rel. 16). In this paper, we propose a \ac{ML} approach to characterise the spectrum utilisation and facilitate the dynamic access to it. Recent advances in \acp{CNN} enable us to perform waveform classification by processing spectrograms as images. In contrast to other \ac{ML} methods that can only provide the class of the monitored \acp{RAT}, the solution we propose can recognise not only different \acp{RAT} in shared spectrum, but also identify critical parameters such as inter-frame duration, frame duration, centre frequency, and signal bandwidth by using object detection and a feature extraction module to extract features from spectrograms. We have implemented and evaluated our solution using a dataset of commercial transmissions, as well as in a \ac{SDR} testbed environment. The scenario evaluated was the coexistence of WiFi and LTE transmissions in shared spectrum. Our results show that our approach has an accuracy of 96\% in the classification of \acp{RAT} from a dataset that captures transmissions of regular user communications. It also shows that the extracted features can be precise within a margin of 2\%, %of the size of the image, and is capable of detect above 94\% of objects under a broad range of transmission power levels and interference conditions.
Learning pose variations within shape population by constrained mixtures of factor analyzers
Jun 07, 2020
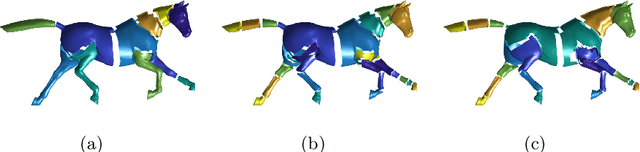

Mining and learning the shape variability of underlying population has benefited the applications including parametric shape modeling, 3D animation, and image segmentation. The current statistical shape modeling method works well on learning unstructured shape variations without obvious pose changes (relative rotations of the body parts). Studying the pose variations within a shape population involves segmenting the shapes into different articulated parts and learning the transformations of the segmented parts. This paper formulates the pose learning problem as mixtures of factor analyzers. The segmentation is obtained by components posterior probabilities and the rotations in pose variations are learned by the factor loading matrices. To guarantee that the factor loading matrices are composed by rotation matrices, constraints are imposed and the corresponding closed form optimal solution is derived. Based on the proposed method, the pose variations are automatically learned from the given shape populations. The method is applied in motion animation where new poses are generated by interpolating the existing poses in the training set. The obtained results are smooth and realistic.