 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Features for Ground Texture Based Localization -- A Survey
Mar 03, 2020


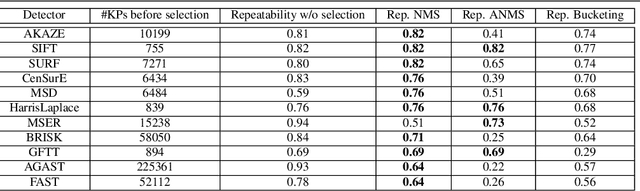
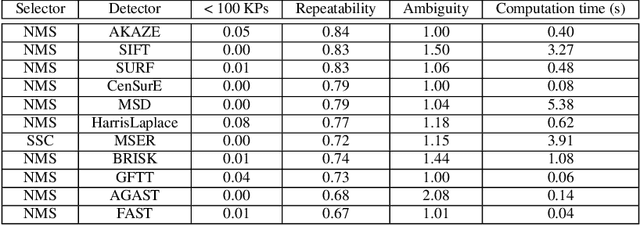
Ground texture based vehicle localization using feature-based methods is a promising approach to achieve infrastructure-free high-accuracy localization. In this paper, we provide the first extensive evaluation of available feature extraction methods for this task, using separately taken image pairs as well as synthetic transformations. We identify AKAZE, SURF and CenSurE as best performing keypoint detectors, and find pairings of CenSurE with the ORB, BRIEF and LATCH feature descriptors to achieve greatest success rates for incremental localization, while SIFT stands out when considering severe synthetic transformations as they might occur during absolute localization.
Pix2Vox++: Multi-scale Context-aware 3D Object Reconstruction from Single and Multiple Images
Jun 22, 2020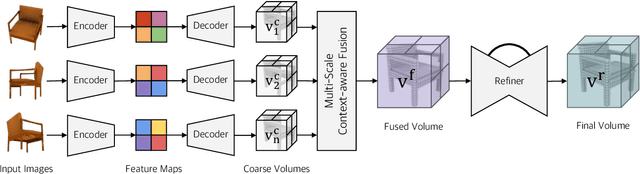
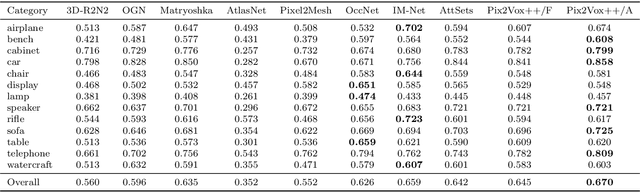
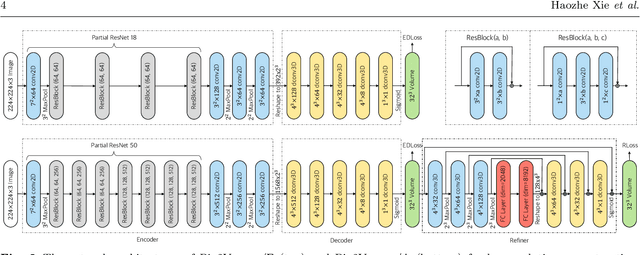
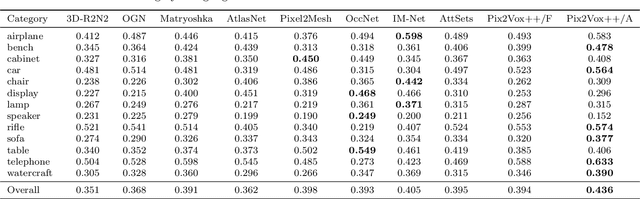
Recovering the 3D shape of an object from single or multiple images with deep neural networks has been attracting increasing attention in the past few years. Mainstream works (e.g. 3D-R2N2) use recurrent neural networks (RNNs) to sequentially fuse feature maps of input images. However, RNN-based approaches are unable to produce consistent reconstruction results when given the same input images with different orders. Moreover, RNNs may forget important features from early input images due to long-term memory loss. To address these issues, we propose a novel framework for single-view and multi-view 3D object reconstruction, named Pix2Vox++. By using a well-designed encoder-decoder, it generates a coarse 3D volume from each input image. A multi-scale context-aware fusion module is then introduced to adaptively select high-quality reconstructions for different parts from all coarse 3D volumes to obtain a fused 3D volume. To further correct the wrongly recovered parts in the fused 3D volume, a refiner is adopted to generate the final output. Experimental results on the ShapeNet, Pix3D, and Things3D benchmarks show that Pix2Vox++ performs favorably against state-of-the-art methods in terms of both accuracy and efficiency.
Generating Memorable Images Based on Human Visual Memory Schemas
May 06, 2020
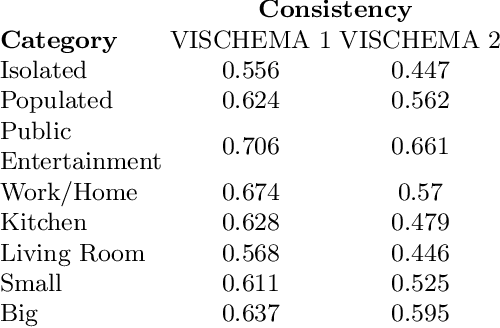
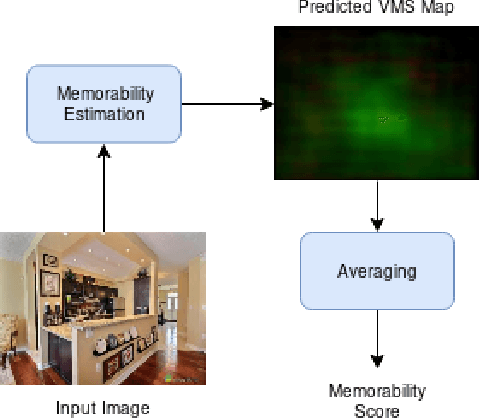
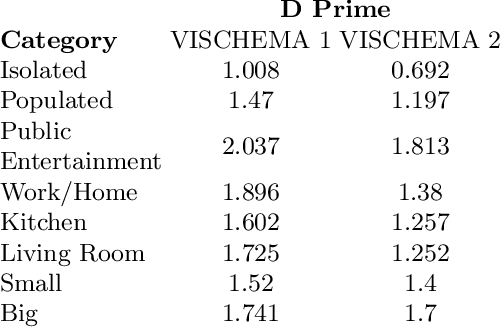
This research study proposes using Generative Adversarial Networks (GAN) that incorporate a two-dimensional measure of human memorability to generate memorable or non-memorable images of scenes. The memorability of the generated images is evaluated by modelling Visual Memory Schemas (VMS), which correspond to mental representations that human observers use to encode an image into memory. The VMS model is based upon the results of memory experiments conducted on human observers, and provides a 2D map of memorability. We impose a memorability constraint upon the latent space of a GAN by employing a VMS map prediction model as an auxiliary loss. We assess the difference in memorability between images generated to be memorable or non-memorable through an independent computational measure of memorability, and additionally assess the effect of memorability on the realness of the generated images.
Learning Guided Convolutional Network for Depth Completion
Aug 03, 2019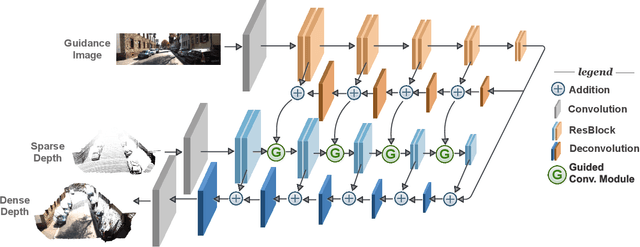
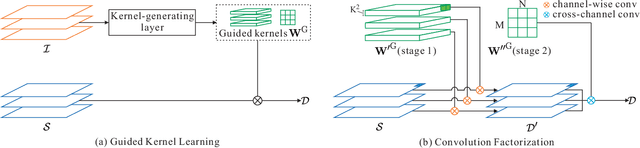


Dense depth perception is critical for autonomous driving and other robotics applications. However, modern LiDAR sensors only provide sparse depth measurement. It is thus necessary to complete the sparse LiDAR data, where a synchronized guidance RGB image is often used to facilitate this completion. Many neural networks have been designed for this task. However, they often na\"{\i}vely fuse the LiDAR data and RGB image information by performing feature concatenation or element-wise addition. Inspired by the guided image filtering, we design a novel guided network to predict kernel weights from the guidance image. These predicted kernels are then applied to extract the depth image features. In this way, our network generates content-dependent and spatially-variant kernels for multi-modal feature fusion. Dynamically generated spatially-variant kernels could lead to prohibitive GPU memory consumption and computation overhead. We further design a convolution factorization to reduce computation and memory consumption. The GPU memory reduction makes it possible for feature fusion to work in multi-stage scheme. We conduct comprehensive experiments to verify our method on real-world outdoor, indoor and synthetic datasets. Our method produces strong results. It outperforms state-of-the-art methods on the NYUv2 dataset and ranks 1st on the KITTI depth completion benchmark at the time of submission. It also presents strong generalization capability under different 3D point densities, various lighting and weather conditions as well as cross-dataset evaluations. The code will be released for reproduction.
AVID: Learning Multi-Stage Tasks via Pixel-Level Translation of Human Videos
Dec 10, 2019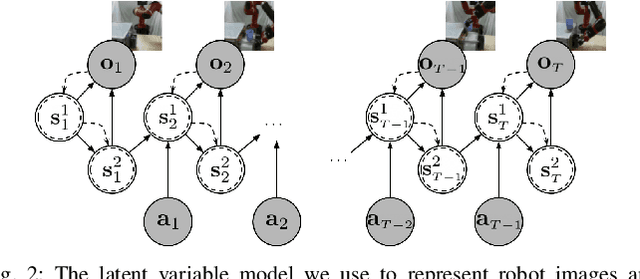



Robotic reinforcement learning (RL) holds the promise of enabling robots to learn complex behaviors through experience. However, realizing this promise requires not only effective and scalable RL algorithms, but also mechanisms to reduce human burden in terms of defining the task and resetting the environment. In this paper, we study how these challenges can be alleviated with an automated robotic learning framework, in which multi-stage tasks are defined simply by providing videos of a human demonstrator and then learned autonomously by the robot from raw image observations. A central challenge in imitating human videos is the difference in morphology between the human and robot, which typically requires manual correspondence. We instead take an automated approach and perform pixel-level image translation via CycleGAN to convert the human demonstration into a video of a robot, which can then be used to construct a reward function for a model-based RL algorithm. The robot then learns the task one stage at a time, automatically learning how to reset each stage to retry it multiple times without human-provided resets. This makes the learning process largely automatic, from intuitive task specification via a video to automated training with minimal human intervention. We demonstrate that our approach is capable of learning complex tasks, such as operating a coffee machine, directly from raw image observations, requiring only 20 minutes to provide human demonstrations and about 180 minutes of robot interaction with the environment. A supplementary video depicting the experimental setup, learning process, and our method's final performance is available from https://sites.google.com/view/icra20avid
ORGB: Offset Correction in RGB Color Space for Illumination-Robust Image Processing
Aug 03, 2017
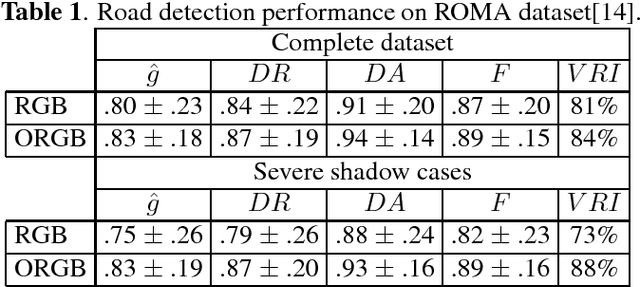
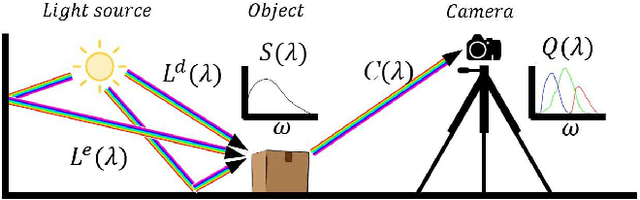
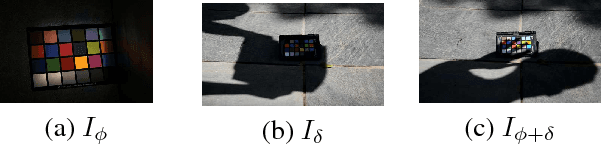
Single materials have colors which form straight lines in RGB space. However, in severe shadow cases, those lines do not intersect the origin, which is inconsistent with the description of most literature. This paper is concerned with the detection and correction of the offset between the intersection and origin. First, we analyze the reason for forming that offset via an optical imaging model. Second, we present a simple and effective way to detect and remove the offset. The resulting images, named ORGB, have almost the same appearance as the original RGB images while are more illumination-robust for color space conversion. Besides, image processing using ORGB instead of RGB is free from the interference of shadows. Finally, the proposed offset correction method is applied to road detection task, improving the performance both in quantitative and qualitative evaluations.
A Neural Dirichlet Process Mixture Model for Task-Free Continual Learning
Jan 03, 2020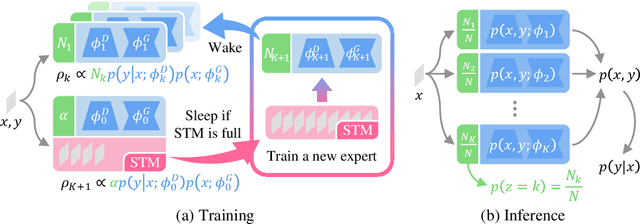
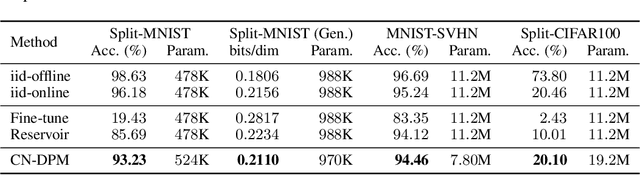
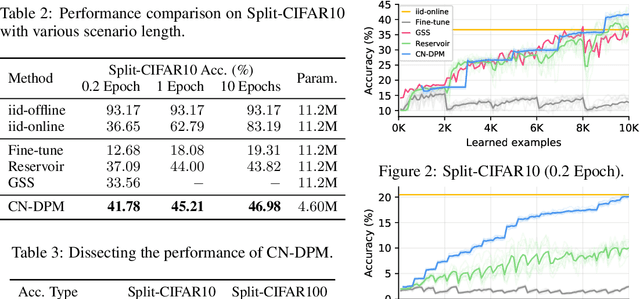
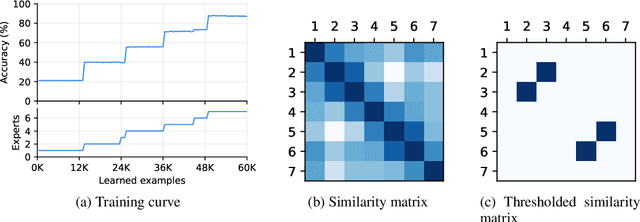
Despite the growing interest in continual learning, most of its contemporary works have been studied in a rather restricted setting where tasks are clearly distinguishable, and task boundaries are known during training. However, if our goal is to develop an algorithm that learns as humans do, this setting is far from realistic, and it is essential to develop a methodology that works in a task-free manner. Meanwhile, among several branches of continual learning, expansion-based methods have the advantage of eliminating catastrophic forgetting by allocating new resources to learn new data. In this work, we propose an expansion-based approach for task-free continual learning. Our model, named Continual Neural Dirichlet Process Mixture (CN-DPM), consists of a set of neural network experts that are in charge of a subset of the data. CN-DPM expands the number of experts in a principled way under the Bayesian nonparametric framework. With extensive experiments, we show that our model successfully performs task-free continual learning for both discriminative and generative tasks such as image classification and image generation.
Raiders of the Lost Art
Sep 10, 2019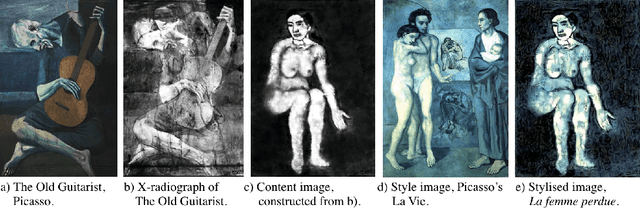



Neural style transfer, first proposed by Gatys et al. (2015), can be used to create novel artistic work through rendering a content image in the form of a style image. We present a novel method of reconstructing lost artwork, by applying neural style transfer to x-radiographs of artwork with secondary interior artwork beneath a primary exterior, so as to reconstruct lost artwork. Finally we reflect on AI art exhibitions and discuss the social, cultural, ethical, and philosophical impact of these technical innovations.
Super-resolution of multispectral satellite images using convolutional neural networks
Feb 03, 2020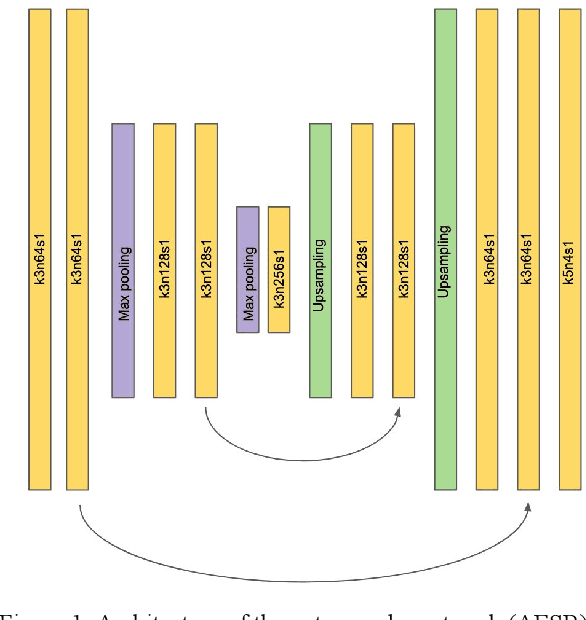
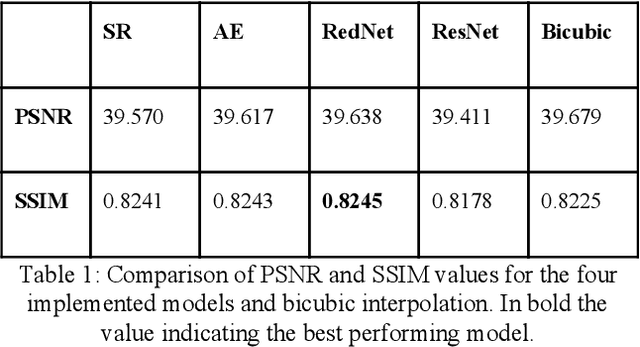
Super-resolution aims at increasing image resolution by algorithmic means and has progressed over the recent years due to advances in the fields of computer vision and deep learning. Convolutional Neural Networks based on a variety of architectures have been applied to the problem, e.g. autoencoders and residual networks. While most research focuses on the processing of photographs consisting only of RGB color channels, little work can be found concentrating on multi-band, analytic satellite imagery. Satellite images often include a panchromatic band, which has higher spatial resolution but lower spectral resolution than the other bands. In the field of remote sensing, there is a long tradition of applying pan-sharpening to satellite images, i.e. bringing the multispectral bands to the higher spatial resolution by merging them with the panchromatic band. To our knowledge there are so far no approaches to super-resolution which take advantage of the panchromatic band. In this paper we propose a method to train state-of-the-art CNNs using pairs of lower-resolution multispectral and high-resolution pan-sharpened image tiles in order to create super-resolved analytic images. The derived quality metrics show that the method improves information content of the processed images. We compare the results created by four CNN architectures, with RedNet30 performing best.
DO-Conv: Depthwise Over-parameterized Convolutional Layer
Jun 22, 2020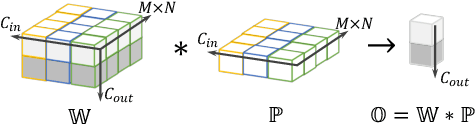
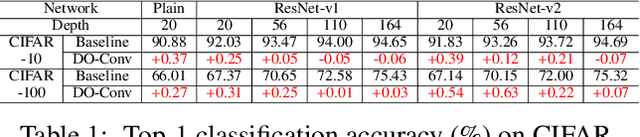

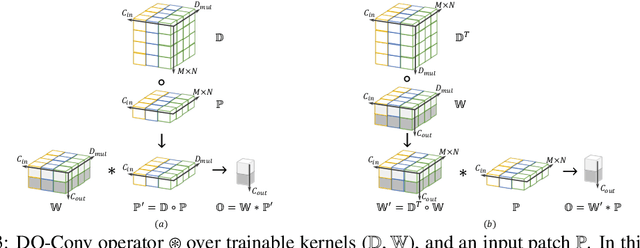
Convolutional layers are the core building blocks of Convolutional Neural Networks (CNNs). In this paper, we propose to augment a convolutional layer with an additional depthwise convolution, where each input channel is convolved with a different 2D kernel. The composition of the two convolutions constitutes an over-parameterization, since it adds learnable parameters, while the resulting linear operation can be expressed by a single convolution layer. We refer to this depthwise over-parameterized convolutional layer as DO-Conv. We show with extensive experiments that the mere replacement of conventional convolutional layers with DO-Conv layers boosts the performance of CNNs on many classical vision tasks, such as image classification, detection, and segmentation. Moreover, in the inference phase, the depthwise convolution is folded into the conventional convolution, reducing the computation to be exactly equivalent to that of a convolutional layer without over-parameterization. As DO-Conv introduces performance gains without incurring any computational complexity increase for inference, we advocate it as an alternative to the conventional convolutional layer. We open-source a reference implementation of DO-Conv in Tensorflow, PyTorch and GluonCV at https://github.com/yangyanli/DO-Conv.