 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HistomicsML2.0: Fast interactive machine learning for whole slide imaging data
Jan 30, 2020
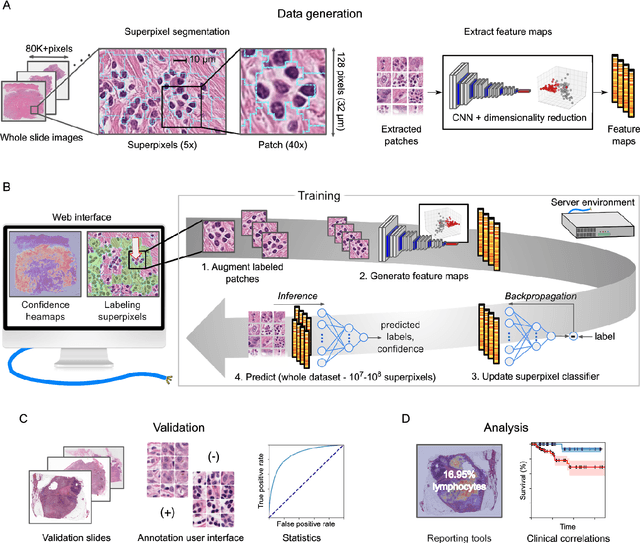
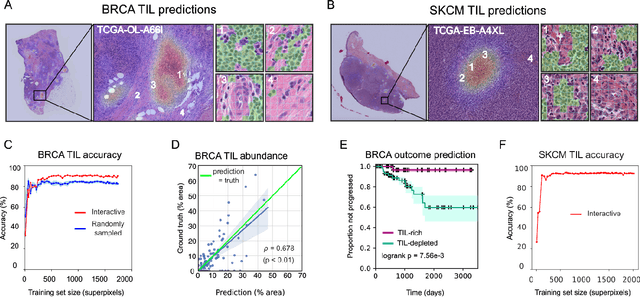
Extracting quantitative phenotypic information from whole-slide images presents significant challenges for investigators who are not experienced in developing image analysis algorithms. We present new software that enables rapid learn-by-example training of machine learning classifiers for detection of histologic patterns in whole-slide imaging datasets. HistomicsML2.0 uses convolutional networks to be readily adaptable to a variety of applications, provides a web-based user interface, and is available as a software container to simplify deployment.
Multiscale Self Attentive Convolutions for Vision and Language Modeling
Dec 03, 2019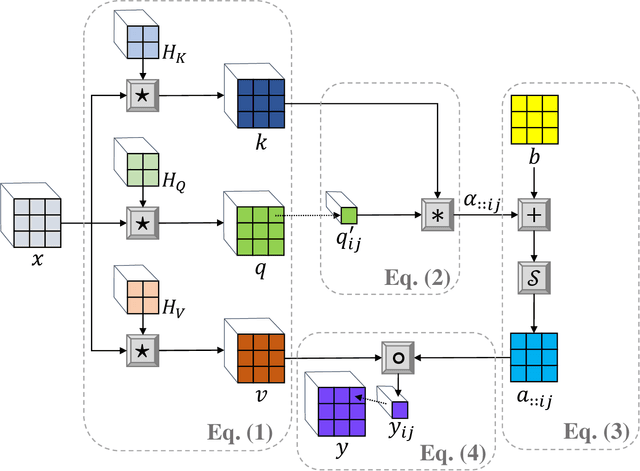
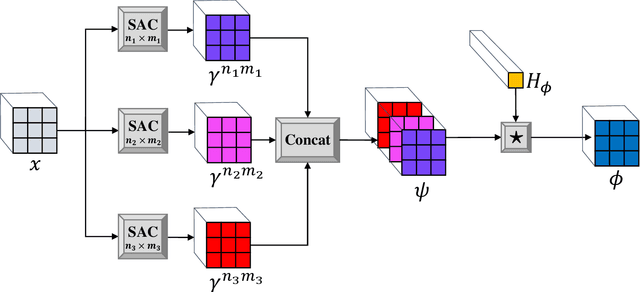
Self attention mechanisms have become a key building block in many state-of-the-art language understanding models. In this paper, we show that the self attention operator can be formulated in terms of 1x1 convolution operations. Following this observation, we propose several novel operators: First, we introduce a 2D version of self attention that is applicable for 2D signals such as images. Second, we present the 1D and 2D Self Attentive Convolutions (SAC) operator that generalizes self attention beyond 1x1 convolutions to 1xm and nxm convolutions, respectively. While 1D and 2D self attention operate on individual words and pixels, SAC operates on m-grams and image patches, respectively. Third, we present a multiscale version of SAC (MSAC) which analyzes the input by employing multiple SAC operators that vary by filter size, in parallel. Finally, we explain how MSAC can be utilized for vision and language modeling, and further harness MSAC to form a cross attentive image similarity machinery.
Explaining Neural Networks by Decoding Layer Activations
May 27, 2020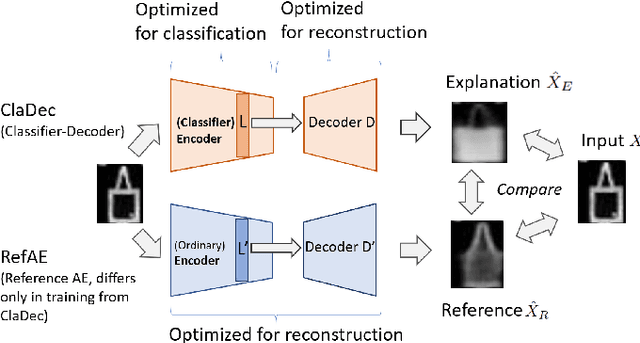
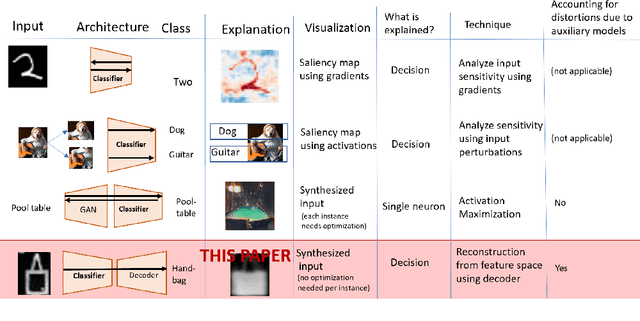
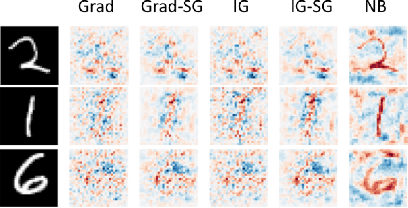
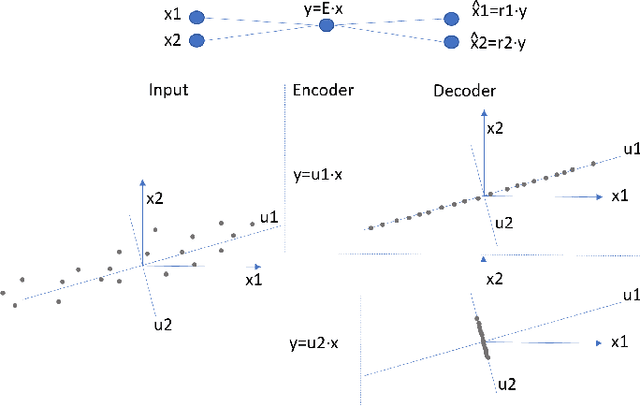
To derive explanations for deep learning models, ie. classifiers, we propose a `CLAssifier-DECoder' architecture (\emph{ClaDec}). \emph{ClaDec} allows to explain the output of an arbitrary layer. To this end, it uses a decoder that transforms the non-interpretable representation of the given layer to a representation that is more similar to training data. One can recognize what information a layer maintains by contrasting reconstructed images of \emph{ClaDec} with those of a conventional auto-encoder(AE) serving as reference. Our extended version also allows to trade human interpretability and fidelity to customize explanations to individual needs. We evaluate our approach for image classification using CNNs. In alignment with our theoretical motivation, the qualitative evaluation highlights that reconstructed images (of the network to be explained) tend to replace specific objects with more generic object templates and provide smoother reconstructions. We also show quantitatively that reconstructed visualizations using encodings from a classifier do capture more relevant information for classification than conventional AEs despite the fact that the latter contain more information on the original input.
Anomaly Detection and Prototype Selection Using Polyhedron Curvature
Apr 05, 2020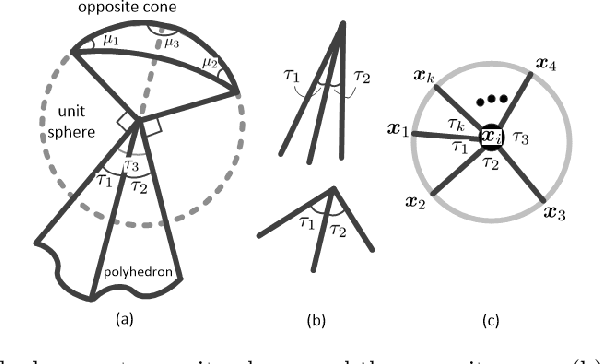
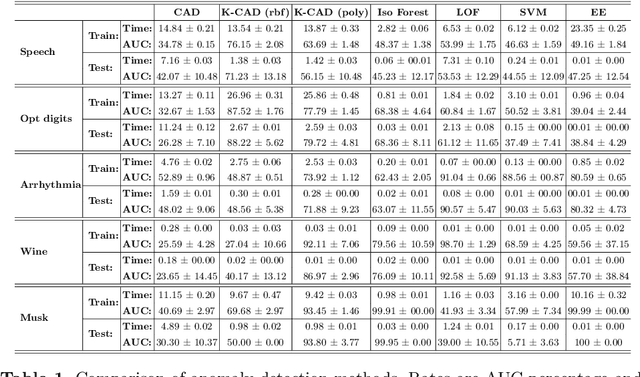

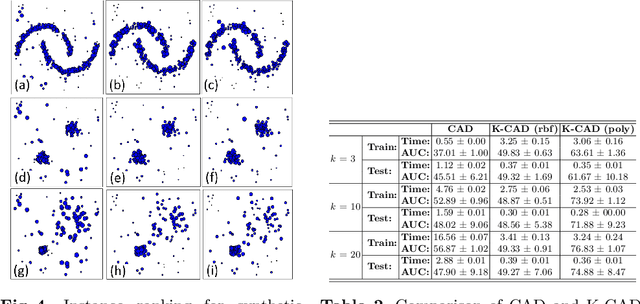
We propose a novel approach to anomaly detection called Curvature Anomaly Detection (CAD) and Kernel CAD based on the idea of polyhedron curvature. Using the nearest neighbors for a point, we consider every data point as the vertex of a polyhedron where the more anomalous point has more curvature. We also propose inverse CAD (iCAD) and Kernel iCAD for instance ranking and prototype selection by looking at CAD from an opposite perspective. We define the concept of anomaly landscape and anomaly path and we demonstrate an application for it which is image denoising. The proposed methods are straightforward and easy to implement. Our experiments on different benchmarks show that the proposed methods are effective for anomaly detection and prototype selection.
Scene recognition based on DNN and game theory with its applications in human-robot interaction
Dec 03, 2019


Scene recognition model based on the DNN and game theory with its applications in human-robot interaction is proposed in this paper. The use of deep learning methods in the field of image scene recognition is still in its infancy, but has become an important trend in the future. As the innovative idea of the paper, we propose the following novelties. (1) In this paper, the discrete displacement field is used to represent deformation. The registration problem is transformed into a problem of minimum energy in random field to finalize the image pre-processing task. (2) We select neighboring homogeneous sample features and the neighboring heterogeneous sample features for the extracted sample features to build a triple and modify the traditional neural network to propose the novel DNN for scene understanding. (3) The robot control is well combined to guide the robot vision for multiple tasks. The experiment is then conducted to validate the overall performance.
Point-to-set distance functions for weakly supervised segmentation
Jul 27, 2020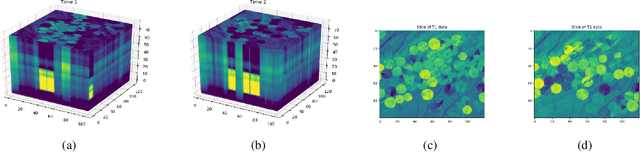
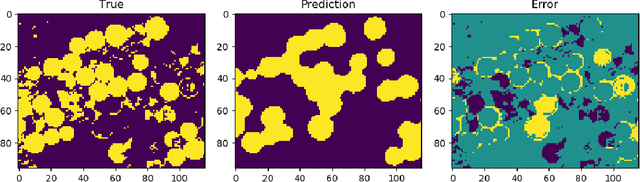
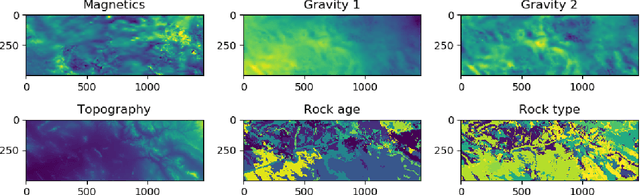

When pixel-level masks or partial annotations are not available for training neural networks for semantic segmentation, it is possible to use higher-level information in the form of bounding boxes, or image tags. In the imaging sciences, many applications do not have an object-background structure and bounding boxes are not available. Any available annotation typically comes from ground truth or domain experts. A direct way to train without masks is using prior knowledge on the size of objects/classes in the segmentation. We present a new algorithm to include such information via constraints on the network output, implemented via projection-based point-to-set distance functions. This type of distance functions always has the same functional form of the derivative, and avoids the need to adapt penalty functions to different constraints, as well as issues related to constraining properties typically associated with non-differentiable functions. Whereas object size information is known to enable object segmentation from bounding boxes from datasets with many general and medical images, we show that the applications extend to the imaging sciences where data represents indirect measurements, even in the case of single examples. We illustrate the capabilities in case of a) one or more classes do not have any annotation; b) there is no annotation at all; c) there are bounding boxes. We use data for hyperspectral time-lapse imaging, object segmentation in corrupted images, and sub-surface aquifer mapping from airborne-geophysical remote-sensing data. The examples verify that the developed methodology alleviates difficulties with annotating non-visual imagery for a range of experimental settings.
Evaluating Defensive Distillation For Defending Text Processing Neural Networks Against Adversarial Examples
Aug 21, 2019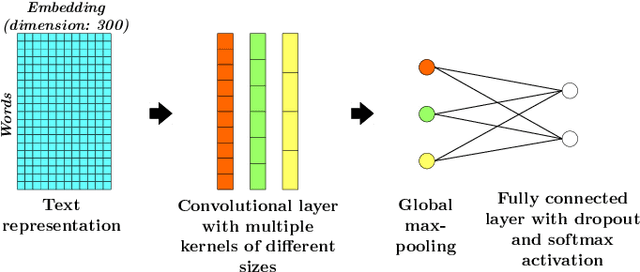


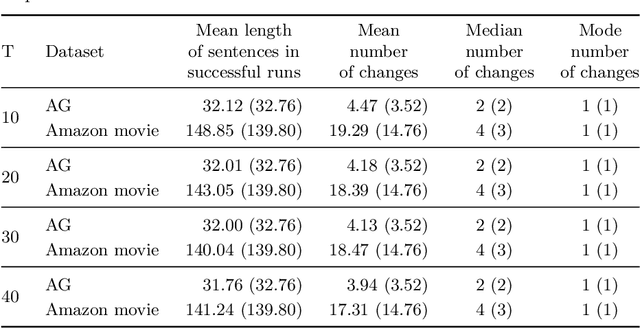
Adversarial examples are artificially modified input samples which lead to misclassifications, while not being detectable by humans. These adversarial examples are a challenge for many tasks such as image and text classification, especially as research shows that many adversarial examples are transferable between different classifiers. In this work, we evaluate the performance of a popular defensive strategy for adversarial examples called defensive distillation, which can be successful in hardening neural networks against adversarial examples in the image domain. However, instead of applying defensive distillation to networks for image classification, we examine, for the first time, its performance on text classification tasks and also evaluate its effect on the transferability of adversarial text examples. Our results indicate that defensive distillation only has a minimal impact on text classifying neural networks and does neither help with increasing their robustness against adversarial examples nor prevent the transferability of adversarial examples between neural networks.
Identity Document to Selfie Face Matching Across Adolescence
Dec 20, 2019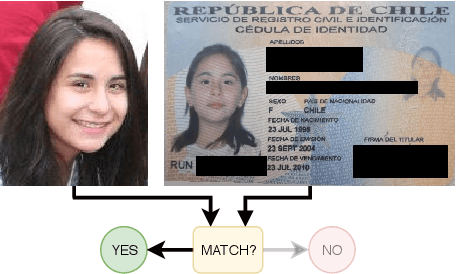
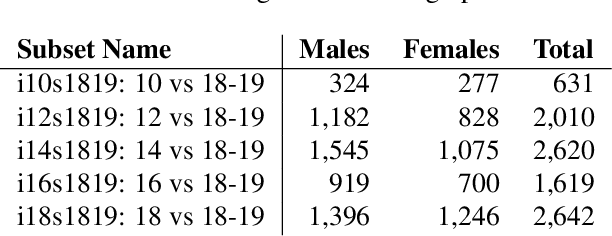
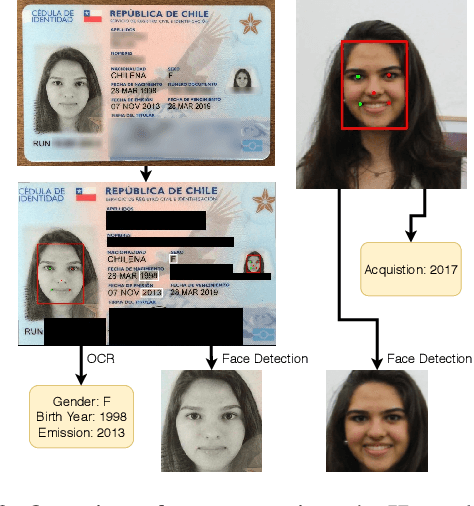
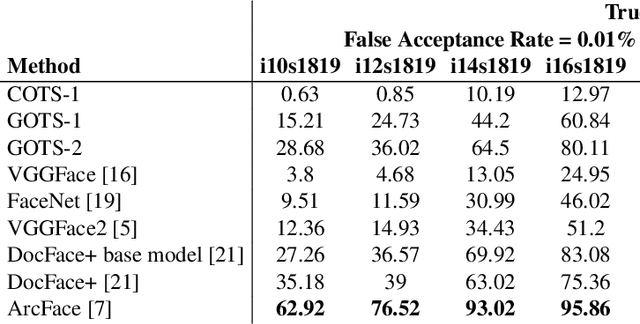
Matching live images (``selfies'') to images from ID documents is a problem that can arise in various applications. A challenging instance of the problem arises when the face image on the ID document is from early adolescence and the live image is from later adolescence. We explore this problem using a private dataset called Chilean Young Adult (CHIYA) dataset, where we match live face images taken at age 18-19 to face images on ID documents created at ages 9 to 18. State-of-the-art deep learning face matchers (e.g., ArcFace) have relatively poor accuracy for document-to-selfie face matching. To achieve higher accuracy, we fine-tune the best available open-source model with triplet loss for a few-shot learning. Experiments show that our approach achieves higher accuracy than the DocFace+ model recently developed for this problem. Our fine-tuned model was able to improve the true acceptance rate for the most difficult (largest age span) subset from 62.92% to 96.67% at a false acceptance rate of 0.01%. Our fine-tuned model is available for use by other researchers.
Accelerating Neural Network Inference by Overflow Aware Quantization
May 27, 2020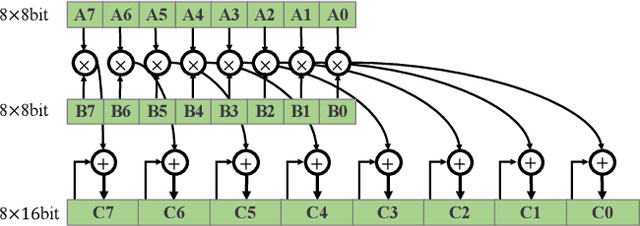
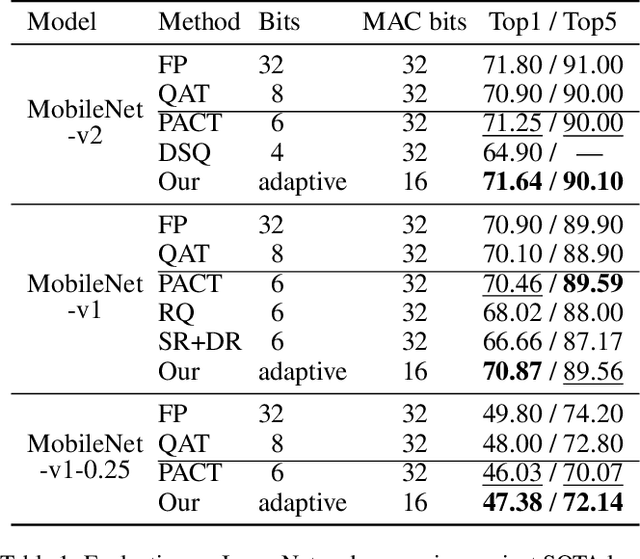
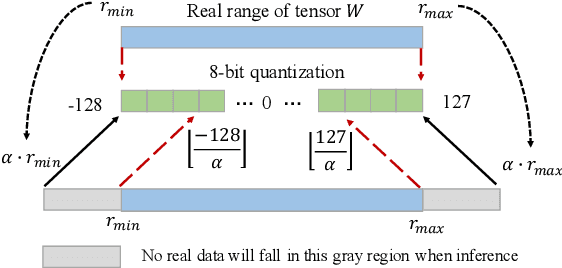
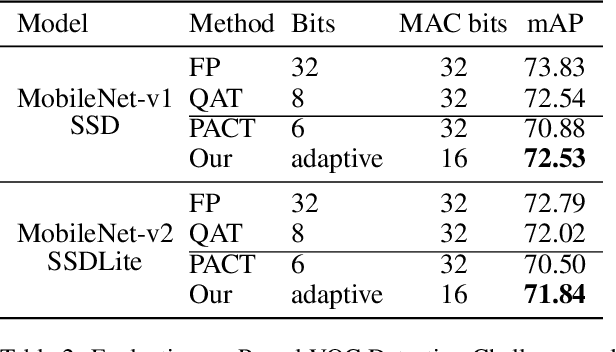
The inherent heavy computation of deep neural networks prevents their widespread applications. A widely used method for accelerating model inference is quantization, by replacing the input operands of a network using fixed-point values. Then the majority of computation costs focus on the integer matrix multiplication accumulation. In fact, high-bit accumulator leads to partially wasted computation and low-bit one typically suffers from numerical overflow. To address this problem, we propose an overflow aware quantization method by designing trainable adaptive fixed-point representation, to optimize the number of bits for each input tensor while prohibiting numeric overflow during the computation. With the proposed method, we are able to fully utilize the computing power to minimize the quantization loss and obtain optimized inference performance. To verify the effectiveness of our method, we conduct image classification, object detection, and semantic segmentation tasks on ImageNet, Pascal VOC, and COCO datasets, respectively. Experimental results demonstrate that the proposed method can achieve comparable performance with state-of-the-art quantization methods while accelerating the inference process by about 2 times.
Learning Bijective Feature Maps for Linear ICA
Feb 19, 2020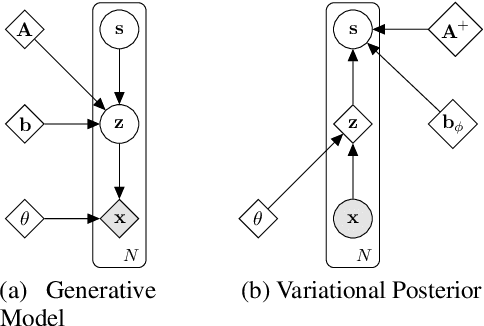
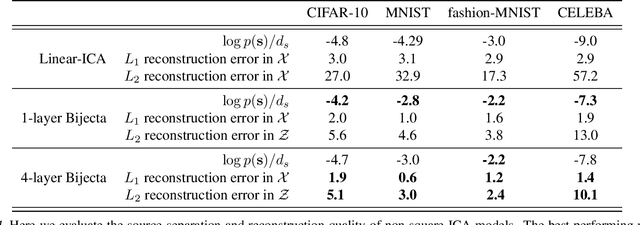

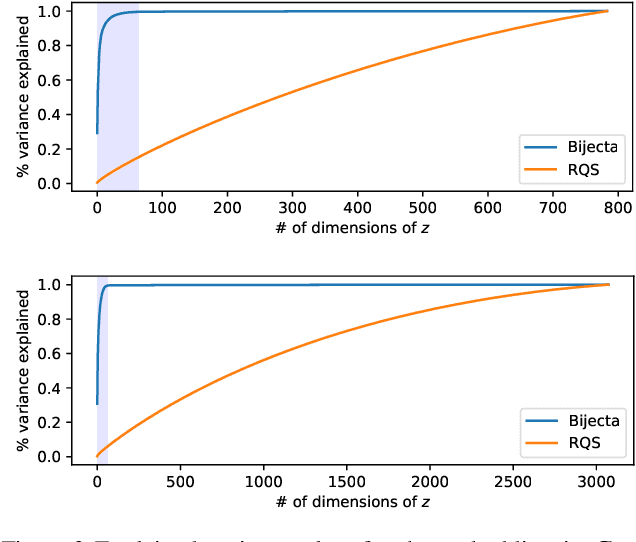
Separating high-dimensional data like images into independent latent factors remains an open research problem. Here we develop a method that jointly learns a linear independent component analysis (ICA) model with non-linear bijective feature maps. By combining these two methods, ICA can learn interpretable latent structure for images. For non-square ICA, where we assume the number of sources is less than the dimensionality of data, we achieve better unsupervised latent factor discovery than flow-based models and linear ICA. This performance scales to large image datasets such as CelebA.