 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fine granularity access in interactive compression of 360-degree images based on rate adaptive channel codes
Jun 25, 2020

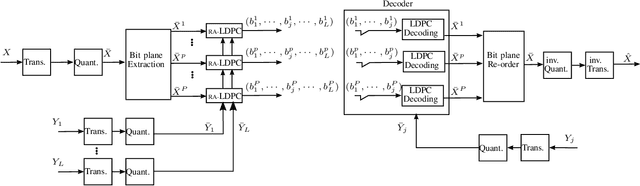

In this paper, we propose a new interactive compression scheme for omnidirectional images. This requires two characteristics: efficient compression of data, to lower the storage cost, and random access ability to extract part of the compressed stream requested by the user (for reducing the transmission rate). For efficient compression, data needs to be predicted by a series of references that have been pre-defined and compressed. This contrasts with the spirit of random accessibility. We propose a solution for this problem based on incremental codes implemented by rate adaptive channel codes. This scheme encodes the image while adapting to any user request and leads to an efficient coding that is flexible in extracting data depending on the available information at the decoder. Therefore, only the information that is needed to be displayed at the user's side is transmitted during the user's request as if the request was already known at the encoder. The experimental results demonstrate that our coder obtains better transmission rate than the state-of-the-art tile-based methods at a small cost in storage. Moreover, the transmission rate grows gradually with the size of the request and avoids a staircase effect, which shows the perfect suitability of our coder for interactive transmission.
Kernel Nonnegative Matrix Factorization Without the Curse of the Pre-image - Application to Unmixing Hyperspectral Images
Mar 27, 2016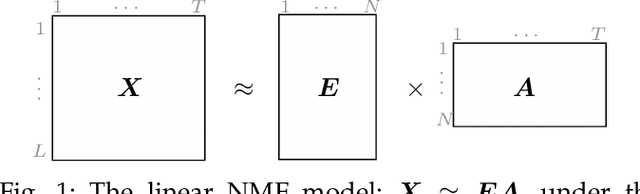
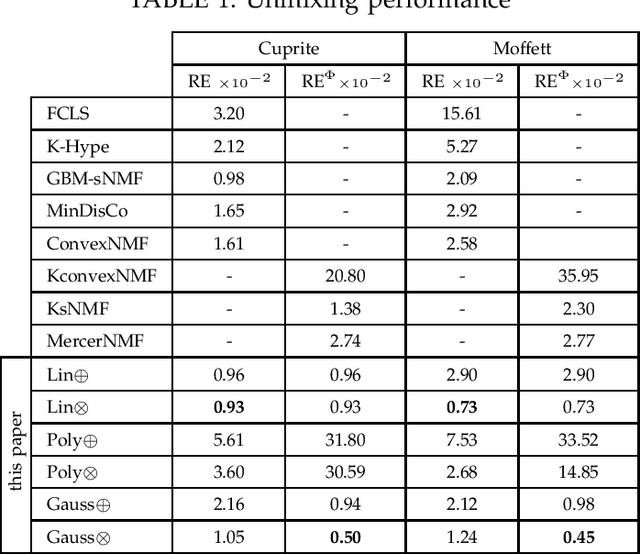
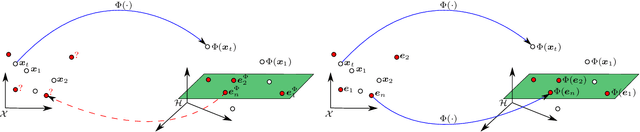
The nonnegative matrix factorization (NMF) is widely used in signal and image processing, including bio-informatics, blind source separation and hyperspectral image analysis in remote sensing. A great challenge arises when dealing with a nonlinear formulation of the NMF. Within the framework of kernel machines, the models suggested in the literature do not allow the representation of the factorization matrices, which is a fallout of the curse of the pre-image. In this paper, we propose a novel kernel-based model for the NMF that does not suffer from the pre-image problem, by investigating the estimation of the factorization matrices directly in the input space. For different kernel functions, we describe two schemes for iterative algorithms: an additive update rule based on a gradient descent scheme and a multiplicative update rule in the same spirit as in the Lee and Seung algorithm. Within the proposed framework, we develop several extensions to incorporate constraints, including sparseness, smoothness, and spatial regularization with a total-variation-like penalty. The effectiveness of the proposed method is demonstrated with the problem of unmixing hyperspectral images, using well-known real images and results with state-of-the-art techniques.
HUSE: Hierarchical Universal Semantic Embeddings
Nov 14, 2019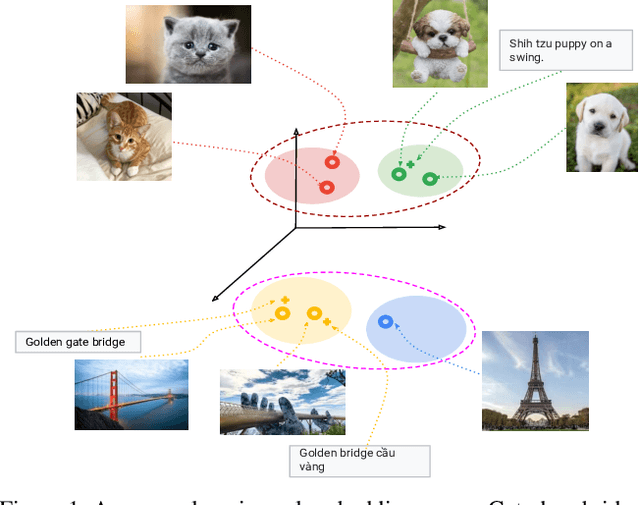
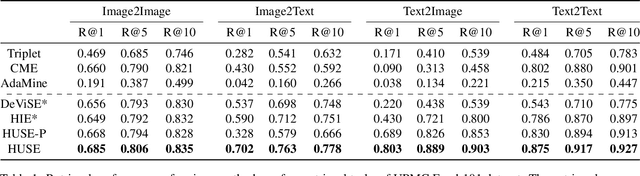
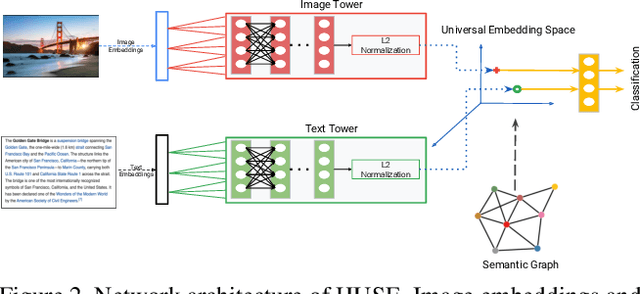
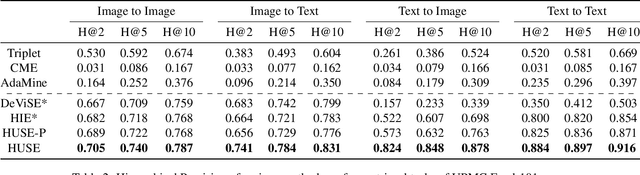
There is a recent surge of interest in cross-modal representation learning corresponding to images and text. The main challenge lies in mapping images and text to a shared latent space where the embeddings corresponding to a similar semantic concept lie closer to each other than the embeddings corresponding to different semantic concepts, irrespective of the modality. Ranking losses are commonly used to create such shared latent space -- however, they do not impose any constraints on inter-class relationships resulting in neighboring clusters to be completely unrelated. The works in the domain of visual semantic embeddings address this problem by first constructing a semantic embedding space based on some external knowledge and projecting image embeddings onto this fixed semantic embedding space. These works are confined only to image domain and constraining the embeddings to a fixed space adds additional burden on learning. This paper proposes a novel method, HUSE, to learn cross-modal representation with semantic information. HUSE learns a shared latent space where the distance between any two universal embeddings is similar to the distance between their corresponding class embeddings in the semantic embedding space. HUSE also uses a classification objective with a shared classification layer to make sure that the image and text embeddings are in the same shared latent space. Experiments on UPMC Food-101 show our method outperforms previous state-of-the-art on retrieval, hierarchical precision and classification results.
Deep Learning based Switching Filter for Impulsive Noise Removal in Color Images
Dec 03, 2019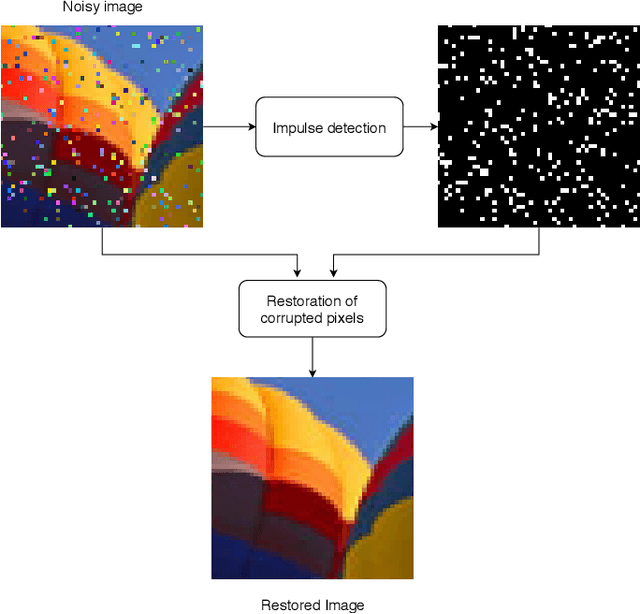

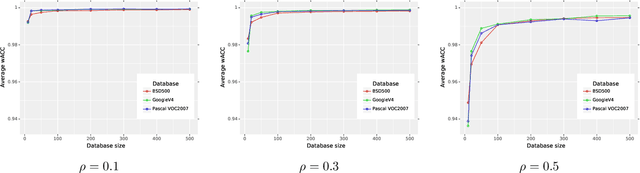

Noise reduction is one the most important and still active research topic in low-level image processing due to its high impact on object detection and scene understanding for computer vision systems. Recently, we can observe a substantial increase of interest in the application of deep learning algorithms in many computer vision problems due to its impressive capability of automatic feature extraction and classification. These methods have been also successfully applied in image denoising, significantly improving the performance, but most of the proposed approaches were designed for Gaussian noise suppression. In this paper, we present a switching filtering design intended for impulsive noise removal using deep learning. In the proposed method, the impulses are identified using a novel deep neural network architecture and noisy pixels are restored using the fast adaptive mean filter. The performed experiments show that the proposed approach is superior to the state-of-the-art filters designed for impulsive noise removal in digital color images.
On the Benefits of Models with Perceptually-Aligned Gradients
May 04, 2020



Adversarial robust models have been shown to learn more robust and interpretable features than standard trained models. As shown in [\cite{tsipras2018robustness}], such robust models inherit useful interpretable properties where the gradient aligns perceptually well with images, and adding a large targeted adversarial perturbation leads to an image resembling the target class. We perform experiments to show that interpretable and perceptually aligned gradients are present even in models that do not show high robustness to adversarial attacks. Specifically, we perform adversarial training with attack for different max-perturbation bound. Adversarial training with low max-perturbation bound results in models that have interpretable features with only slight drop in performance over clean samples. In this paper, we leverage models with interpretable perceptually-aligned features and show that adversarial training with low max-perturbation bound can improve the performance of models for zero-shot and weakly supervised localization tasks.
Addressing target shift in zero-shot learning using grouped adversarial learning
Mar 02, 2020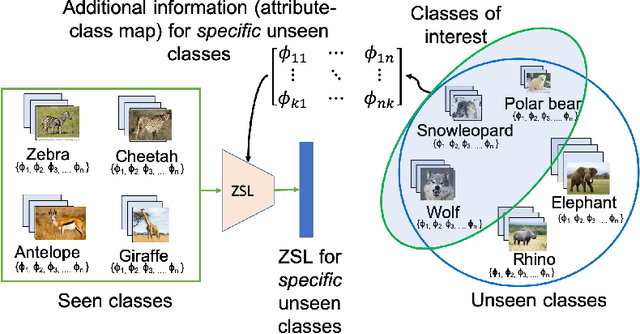
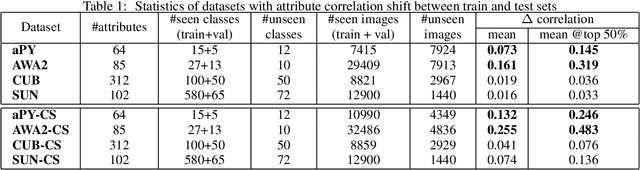
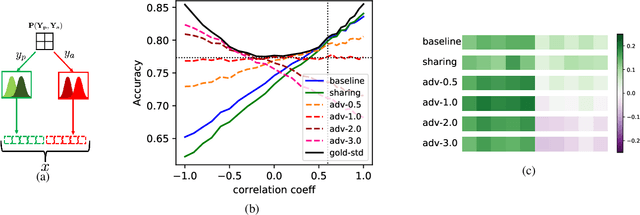
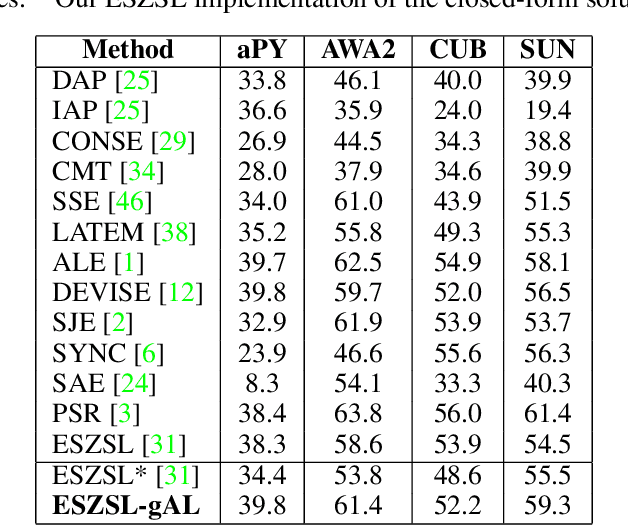
In this paper, we present a new paradigm to zero-shot learning (ZSL) that is trained by utilizing additional information (such as attribute-class mapping) for specific set of unseen classes. We conjecture that such additional information about unseen classes is more readily available than unsupervised image sets. Further, on close examination of the underlying attribute predictors of popular ZSL algorithms, we find that they often leverage attribute correlations to make predictions. While attribute correlations that remain intact in the unseen classes (test) benefit the prediction of difficult attributes, change in correlations can have an adverse effect on ZSL performance. For example, detecting an attribute 'brown' may be the same as detecting 'fur' over an animals' image dataset captured in the tropics. However, such a model might fail on unseen images of Arctic animals. To address this effect, termed target-shift in ZSL, we utilize our proposed framework to design grouped adversarial learning. We introduce grouping of attributes to enable the model to continue to benefit from useful correlations, while restricting cross-group correlations that may be harmful for generalization. Our analysis shows that it is possible to not only constrain the model from leveraging unwanted correlations, but also adjust them to specific test setting using only the additional information (the already available attribute-class mapping). We show empirical results for zero-shot predictions on standard benchmark datasets, namely, aPY, AwA2, SUN and CUB datasets. We further introduce to the research community, a new experimental train-test split that maximizes target-shift to further study its effects.
MCMLSD: A Probabilistic Algorithm and Evaluation Framework for Line Segment Detection
Jan 06, 2020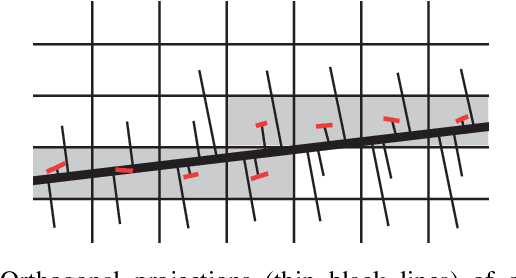
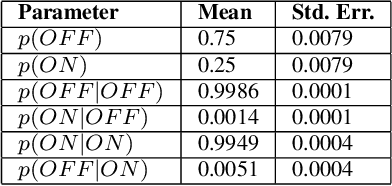
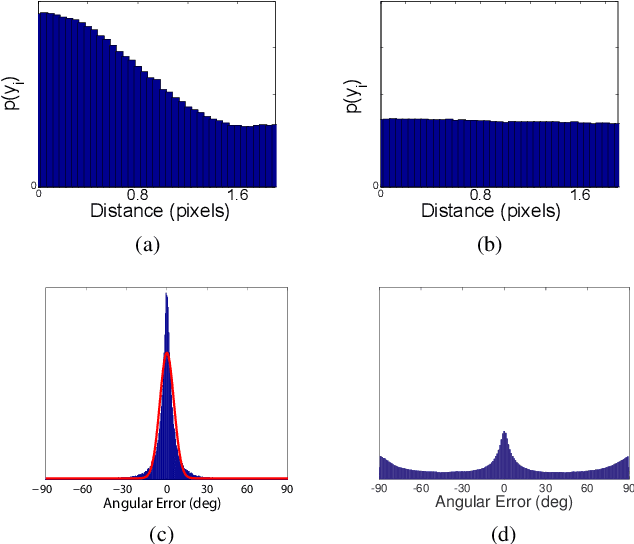
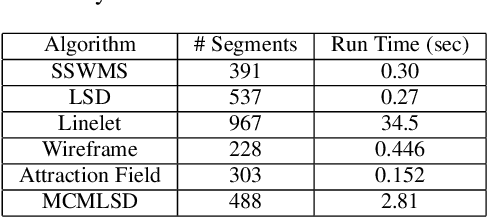
Traditional approaches to line segment detection typically involve perceptual grouping in the image domain and/or global accumulation in the Hough domain. Here we propose a probabilistic algorithm that merges the advantages of both approaches. In a first stage lines are detected using a global probabilistic Hough approach. In the second stage each detected line is analyzed in the image domain to localize the line segments that generated the peak in the Hough map. By limiting search to a line, the distribution of segments over the sequence of points on the line can be modeled as a Markov chain, and a probabilistically optimal labelling can be computed exactly using a standard dynamic programming algorithm, in linear time. The Markov assumption also leads to an intuitive ranking method that uses the local marginal posterior probabilities to estimate the expected number of correctly labelled points on a segment. To assess the resulting Markov Chain Marginal Line Segment Detector (MCMLSD) we develop and apply a novel quantitative evaluation methodology that controls for under- and over-segmentation. Evaluation on the YorkUrbanDB and Wireframe datasets shows that the proposed MCMLSD method outperforms prior traditional approaches, as well as more recent deep learning methods.
TraDE: Transformers for Density Estimation
Apr 06, 2020



We present TraDE, an attention-based architecture for auto-regressive density estimation. In addition to a Maximum Likelihood loss we employ a Maximum Mean Discrepancy (MMD) two-sample loss to ensure that samples from the estimate resemble the training data. The use of attention means that the model need not retain conditional sufficient statistics during the process beyond what is needed for each covariate. TraDE performs significantly better than existing approaches such differentiable flow based estimators on standard tabular and image-based benchmarks in terms of the log-likelihood on held out data. TraDE works well wide range of tasks that includes classification methods to ascertain the quality of generated samples, out of distribution sample detection, and handling outliers in the training data.
Classification of Spam Emails through Hierarchical Clustering and Supervised Learning
May 28, 2020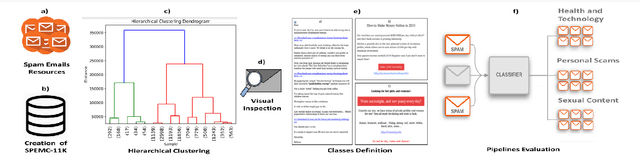
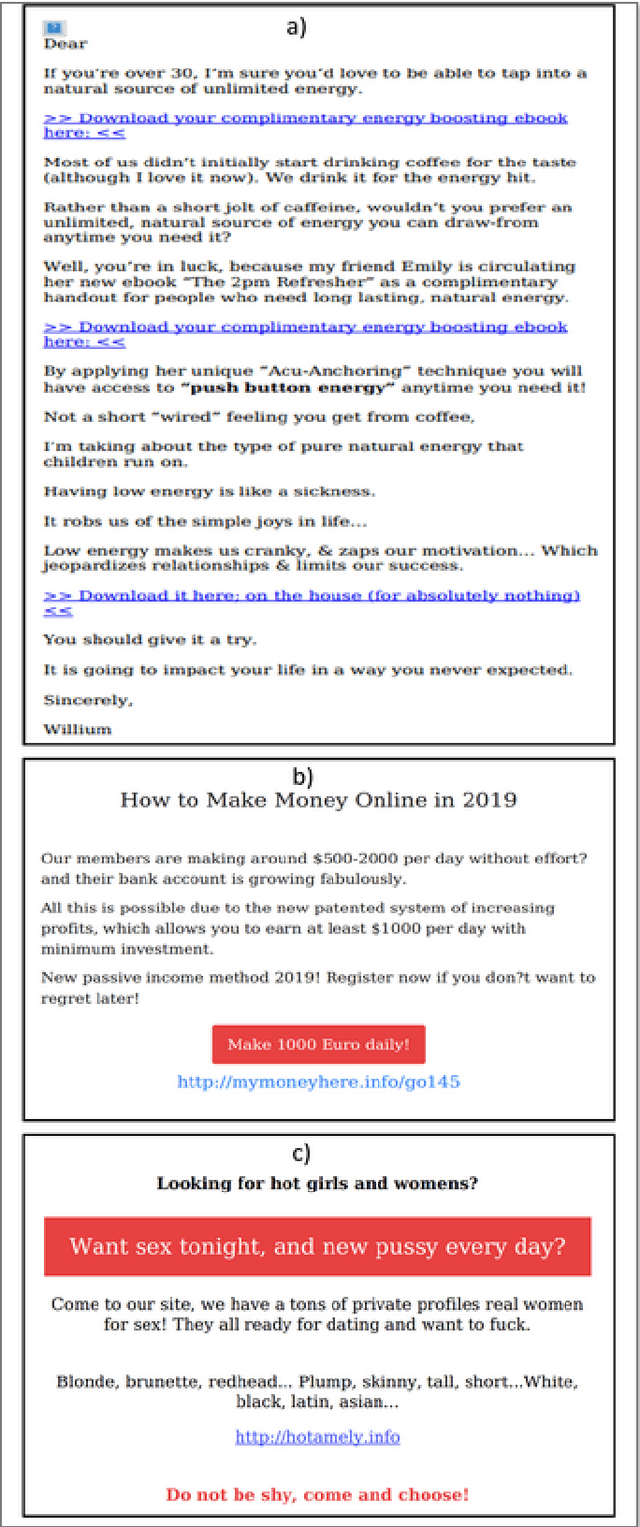
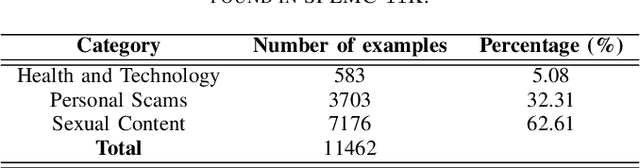
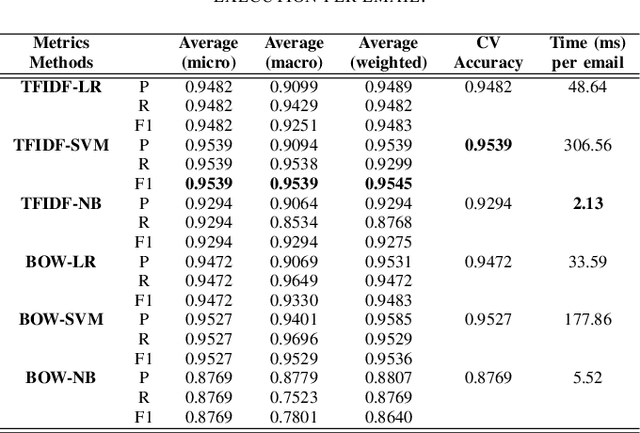
Spammers take advantage of email popularity to send indiscriminately unsolicited emails. Although researchers and organizations continuously develop anti-spam filters based on binary classification, spammers bypass them through new strategies, like word obfuscation or image-based spam. For the first time in literature, we propose to classify spam email in categories to improve the handle of already detected spam emails, instead of just using a binary model. First, we applied a hierarchical clustering algorithm to create SPEMC-$11$K (SPam EMail Classification), the first multi-class dataset, which contains three types of spam emails: Health and Technology, Personal Scams, and Sexual Content. Then, we used SPEMC-$11$K to evaluate the combination of TF-IDF and BOW encodings with Na\"ive Bayes, Decision Trees and SVM classifiers. Finally, we recommend for the task of multi-class spam classification the use of (i) TF-IDF combined with SVM for the best micro F1 score performance, $95.39\%$, and (ii) TD-IDF along with NB for the fastest spam classification, analyzing an email in $2.13$ms.
Evaluating Defensive Distillation For Defending Text Processing Neural Networks Against Adversarial Examples
Aug 21, 2019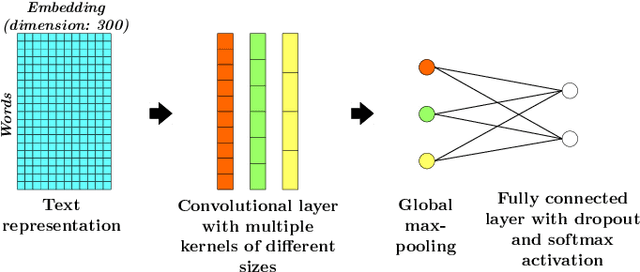


Adversarial examples are artificially modified input samples which lead to misclassifications, while not being detectable by humans. These adversarial examples are a challenge for many tasks such as image and text classification, especially as research shows that many adversarial examples are transferable between different classifiers. In this work, we evaluate the performance of a popular defensive strategy for adversarial examples called defensive distillation, which can be successful in hardening neural networks against adversarial examples in the image domain. However, instead of applying defensive distillation to networks for image classification, we examine, for the first time, its performance on text classification tasks and also evaluate its effect on the transferability of adversarial text examples. Our results indicate that defensive distillation only has a minimal impact on text classifying neural networks and does neither help with increasing their robustness against adversarial examples nor prevent the transferability of adversarial examples between neural networks.