 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adversarial AutoMixup
Dec 19, 2023
Data mixing augmentation has been widely applied to improve the generalization ability of deep neural networks. Recently, offline data mixing augmentation, e.g. handcrafted and saliency information-based mixup, has been gradually replaced by automatic mixing approaches. Through minimizing two sub-tasks, namely, mixed sample generation and mixup classification in an end-to-end way, AutoMix significantly improves accuracy on image classification tasks. However, as the optimization objective is consistent for the two sub-tasks, this approach is prone to generating consistent instead of diverse mixed samples, which results in overfitting for target task training. In this paper, we propose AdAutomixup, an adversarial automatic mixup augmentation approach that generates challenging samples to train a robust classifier for image classification, by alternatively optimizing the classifier and the mixup sample generator. AdAutomixup comprises two modules, a mixed example generator, and a target classifier. The mixed sample generator aims to produce hard mixed examples to challenge the target classifier while the target classifier`s aim is to learn robust features from hard mixed examples to improve generalization. To prevent the collapse of the inherent meanings of images, we further introduce an exponential moving average (EMA) teacher and cosine similarity to train AdAutomixup in an end-to-end way. Extensive experiments on seven image benchmarks consistently prove that our approach outperforms the state of the art in various classification scenarios.
3D Pose Estimation of Two Interacting Hands from a Monocular Event Camera
Dec 21, 20233D hand tracking from a monocular video is a very challenging problem due to hand interactions, occlusions, left-right hand ambiguity, and fast motion. Most existing methods rely on RGB inputs, which have severe limitations under low-light conditions and suffer from motion blur. In contrast, event cameras capture local brightness changes instead of full image frames and do not suffer from the described effects. Unfortunately, existing image-based techniques cannot be directly applied to events due to significant differences in the data modalities. In response to these challenges, this paper introduces the first framework for 3D tracking of two fast-moving and interacting hands from a single monocular event camera. Our approach tackles the left-right hand ambiguity with a novel semi-supervised feature-wise attention mechanism and integrates an intersection loss to fix hand collisions. To facilitate advances in this research domain, we release a new synthetic large-scale dataset of two interacting hands, Ev2Hands-S, and a new real benchmark with real event streams and ground-truth 3D annotations, Ev2Hands-R. Our approach outperforms existing methods in terms of the 3D reconstruction accuracy and generalises to real data under severe light conditions.
* 17 pages, 12 figures, 7 tables; project page: https://4dqv.mpi-inf.mpg.de/Ev2Hands/
PhenDiff: Revealing Invisible Phenotypes with Conditional Diffusion Models
Dec 13, 2023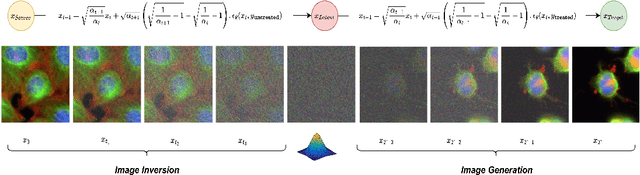
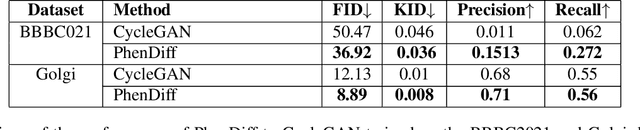
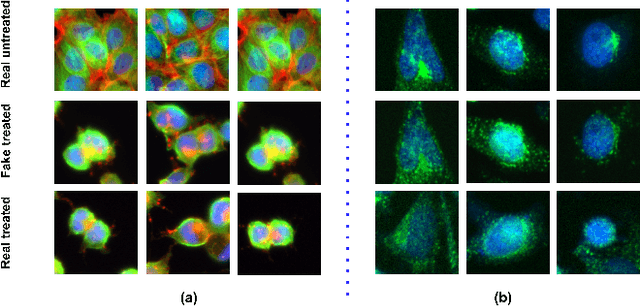
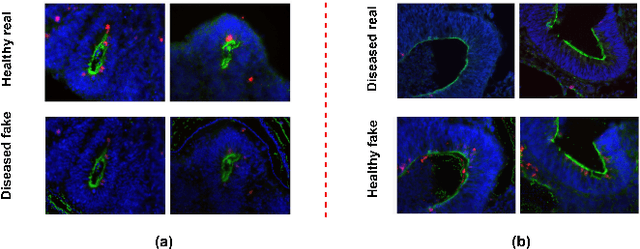
Over the last five years, deep generative models have gradually been adopted for various tasks in biological research. Notably, image-to-image translation methods showed to be effective in revealing subtle phenotypic cell variations otherwise invisible to the human eye. Current methods to achieve this goal mainly rely on Generative Adversarial Networks (GANs). However, these models are known to suffer from some shortcomings such as training instability and mode collapse. Furthermore, the lack of robustness to invert a real image into the latent of a trained GAN prevents flexible editing of real images. In this work, we propose PhenDiff, an image-to-image translation method based on conditional diffusion models to identify subtle phenotypes in microscopy images. We evaluate this approach on biological datasets against previous work such as CycleGAN. We show that PhenDiff outperforms this baseline in terms of quality and diversity of the generated images. We then apply this method to display invisible phenotypic changes triggered by a rare neurodevelopmental disorder on microscopy images of organoids. Altogether, we demonstrate that PhenDiff is able to perform high quality biological image-to-image translation allowing to spot subtle phenotype variations on a real image.
EAFP-Med: An Efficient Adaptive Feature Processing Module Based on Prompts for Medical Image Detection
Nov 27, 2023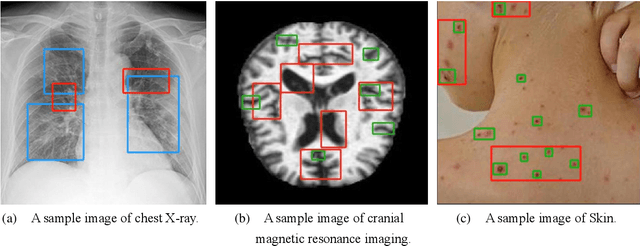
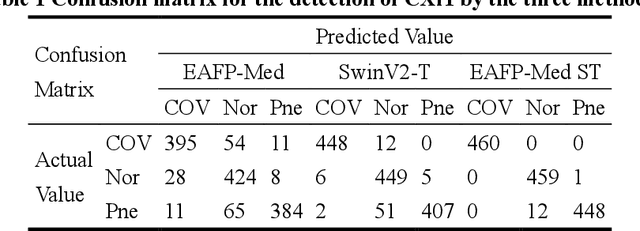
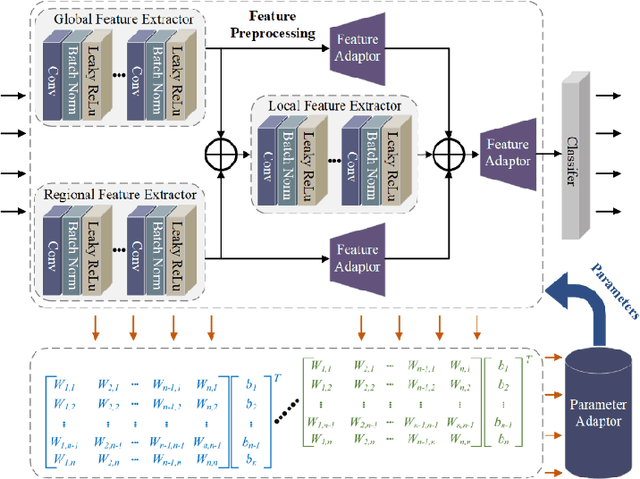
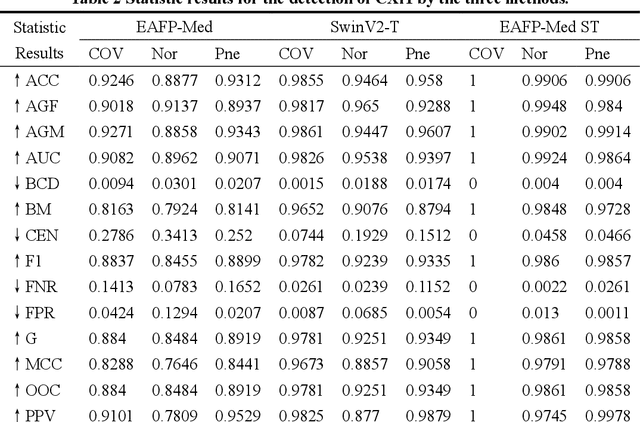
In the face of rapid advances in medical imaging, cross-domain adaptive medical image detection is challenging due to the differences in lesion representations across various medical imaging technologies. To address this issue, we draw inspiration from large language models to propose EAFP-Med, an efficient adaptive feature processing module based on prompts for medical image detection. EAFP-Med can efficiently extract lesion features of different scales from a diverse range of medical images based on prompts while being flexible and not limited by specific imaging techniques. Furthermore, it serves as a feature preprocessing module that can be connected to any model front-end to enhance the lesion features in input images. Moreover, we propose a novel adaptive disease detection model named EAFP-Med ST, which utilizes the Swin Transformer V2 - Tiny (SwinV2-T) as its backbone and connects it to EAFP-Med. We have compared our method to nine state-of-the-art methods. Experimental results demonstrate that EAFP-Med ST achieves the best performance on all three datasets (chest X-ray images, cranial magnetic resonance imaging images, and skin images). EAFP-Med can efficiently extract lesion features from various medical images based on prompts, enhancing the model's performance. This holds significant potential for improving medical image analysis and diagnosis.
Bezier-based Regression Feature Descriptor for Deformable Linear Objects
Dec 27, 2023In this paper, a feature extraction approach for the deformable linear object is presented, which uses a Bezier curve to represent the original geometric shape. The proposed extraction strategy is combined with a parameterization technique, the goal is to compute the regression features from the visual-feedback RGB image, and finally obtain the efficient shape feature in the low-dimensional latent space. Existing works of literature often fail to capture the complex characteristics in a unified framework. They also struggle in scenarios where only local shape descriptors are used to guide the robot to complete the manipulation. To address these challenges, we propose a feature extraction technique using a parameterization approach to generate the regression features, which leverages the power of the Bezier curve and linear regression. The proposed extraction method effectively captures topological features and node characteristics, making it well-suited for the deformation object manipulation task. Large mount of simulations are conducted to evaluate the presented method. Our results demonstrate that the proposed method outperforms existing methods in terms of prediction accuracy, robustness, and computational efficiency. Furthermore, our approach enables the extraction of meaningful insights from the predicted links, thereby contributing to a better understanding of the shape of the deformable linear objects. Overall, this work represents a significant step forward in the use of Bezier curve for shape representation.
Learning Interpretable Queries for Explainable Image Classification with Information Pursuit
Dec 16, 2023Information Pursuit (IP) is an explainable prediction algorithm that greedily selects a sequence of interpretable queries about the data in order of information gain, updating its posterior at each step based on observed query-answer pairs. The standard paradigm uses hand-crafted dictionaries of potential data queries curated by a domain expert or a large language model after a human prompt. However, in practice, hand-crafted dictionaries are limited by the expertise of the curator and the heuristics of prompt engineering. This paper introduces a novel approach: learning a dictionary of interpretable queries directly from the dataset. Our query dictionary learning problem is formulated as an optimization problem by augmenting IP's variational formulation with learnable dictionary parameters. To formulate learnable and interpretable queries, we leverage the latent space of large vision and language models like CLIP. To solve the optimization problem, we propose a new query dictionary learning algorithm inspired by classical sparse dictionary learning. Our experiments demonstrate that learned dictionaries significantly outperform hand-crafted dictionaries generated with large language models.
TDiffDe: A Truncated Diffusion Model for Remote Sensing Hyperspectral Image Denoising
Nov 22, 2023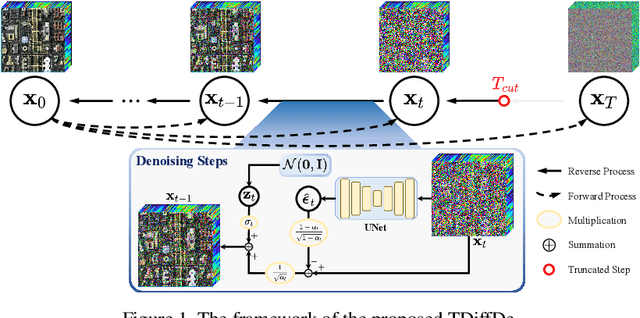
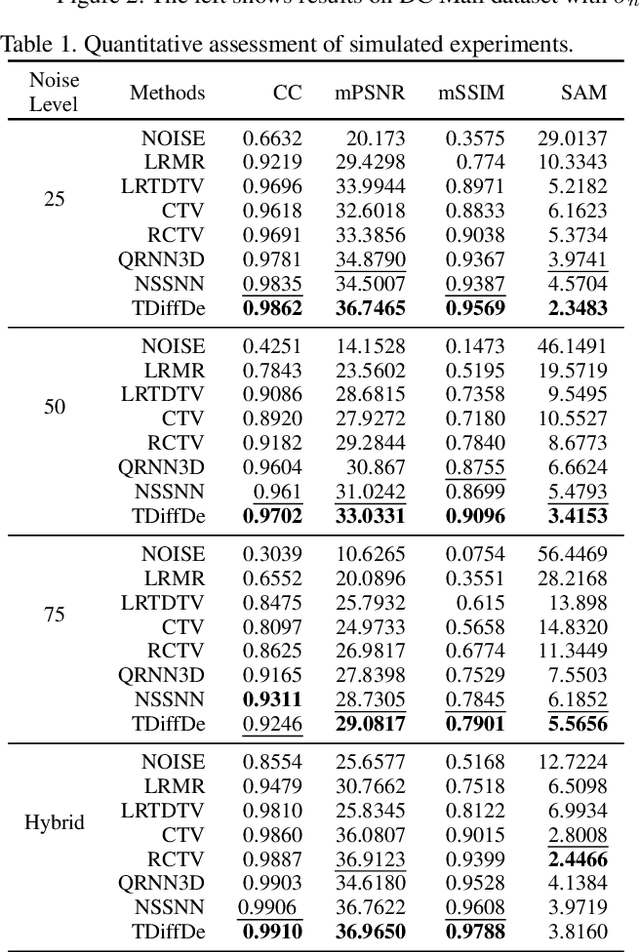

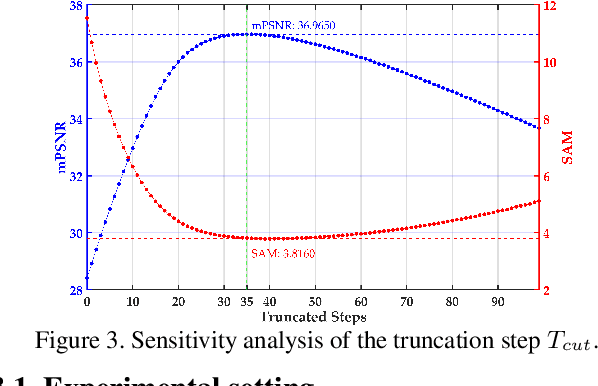
Hyperspectral images play a crucial role in precision agriculture, environmental monitoring or ecological analysis. However, due to sensor equipment and the imaging environment, the observed hyperspectral images are often inevitably corrupted by various noise. In this study, we proposed a truncated diffusion model, called TDiffDe, to recover the useful information in hyperspectral images gradually. Rather than starting from a pure noise, the input data contains image information in hyperspectral image denoising. Thus, we cut the trained diffusion model from small steps to avoid the destroy of valid information.
Wavelet-based Fourier Information Interaction with Frequency Diffusion Adjustment for Underwater Image Restoration
Nov 28, 2023Underwater images are subject to intricate and diverse degradation, inevitably affecting the effectiveness of underwater visual tasks. However, most approaches primarily operate in the raw pixel space of images, which limits the exploration of the frequency characteristics of underwater images, leading to an inadequate utilization of deep models' representational capabilities in producing high-quality images. In this paper, we introduce a novel Underwater Image Enhancement (UIE) framework, named WF-Diff, designed to fully leverage the characteristics of frequency domain information and diffusion models. WF-Diff consists of two detachable networks: Wavelet-based Fourier information interaction network (WFI2-net) and Frequency Residual Diffusion Adjustment Module (FRDAM). With our full exploration of the frequency domain information, WFI2-net aims to achieve preliminary enhancement of frequency information in the wavelet space. Our proposed FRDAM can further refine the high- and low-frequency information of the initial enhanced images, which can be viewed as a plug-and-play universal module to adjust the detail of the underwater images. With the above techniques, our algorithm can show SOTA performance on real-world underwater image datasets, and achieves competitive performance in visual quality.
Data-Efficient Multimodal Fusion on a Single GPU
Dec 15, 2023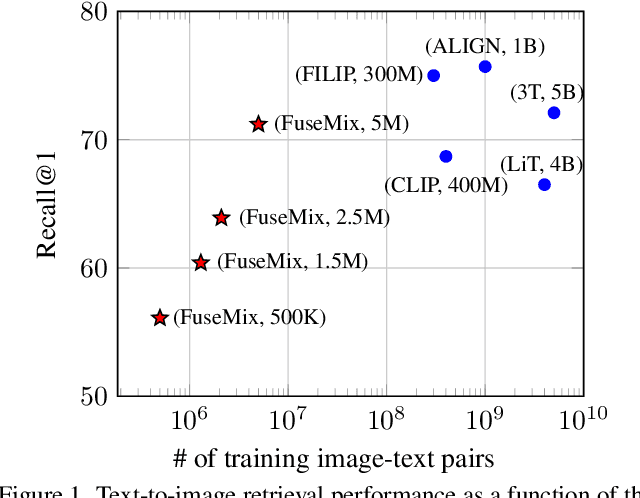
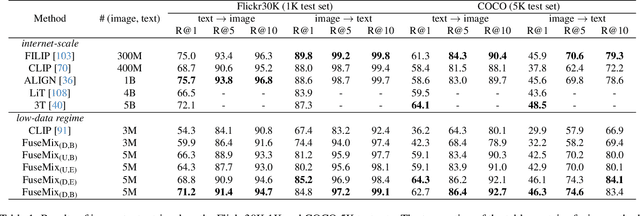
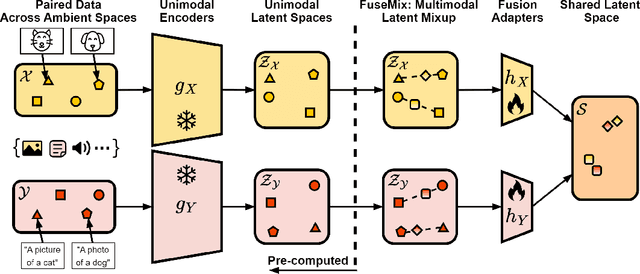
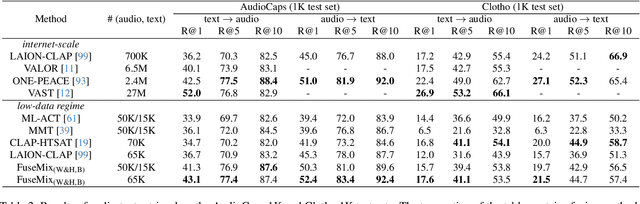
The goal of multimodal alignment is to learn a single latent space that is shared between multimodal inputs. The most powerful models in this space have been trained using massive datasets of paired inputs and large-scale computational resources, making them prohibitively expensive to train in many practical scenarios. We surmise that existing unimodal encoders pre-trained on large amounts of unimodal data should provide an effective bootstrap to create multimodal models from unimodal ones at much lower costs. We therefore propose FuseMix, a multimodal augmentation scheme that operates on the latent spaces of arbitrary pre-trained unimodal encoders. Using FuseMix for multimodal alignment, we achieve competitive performance -- and in certain cases outperform state-of-the art methods -- in both image-text and audio-text retrieval, with orders of magnitude less compute and data: for example, we outperform CLIP on the Flickr30K text-to-image retrieval task with $\sim \! 600\times$ fewer GPU days and $\sim \! 80\times$ fewer image-text pairs. Additionally, we show how our method can be applied to convert pre-trained text-to-image generative models into audio-to-image ones. Code is available at: https://github.com/layer6ai-labs/fusemix.
Holographic Imaging with XL-MIMO and RIS: Illumination and Reflection Design
Dec 18, 2023This paper addresses a near-field imaging problem utilizing extremely large-scale multiple-input multiple-output (XL-MIMO) antennas and reconfigurable intelligent surfaces (RISs) already in place for wireless communications. To this end, we consider a system with a fixed transmitting antenna array illuminating a region of interest (ROI) and a fixed receiving antenna array inferring the ROI's scattering coefficients. Leveraging XL-MIMO and high frequencies, the ROI is situated in the radiating near-field region of both antenna arrays, thus enhancing the degrees of freedom (DoF) of the illuminating and sensing channels available for imaging, here referred to as holographic imaging. To further boost the imaging performance, we optimize the illuminating waveform by solving a min-max optimization problem having the upper bound of the mean squared error (MSE) of the image estimate as the objective function. Additionally, we address the challenge of non-line-of-sight (NLOS) scenarios by considering the presence of a RIS and deriving its optimal reflection coefficients. Numerical results investigate the interplay between illumination optimization, geometric configuration (monostatic and bistatic), the DoF of the illuminating and sensing channels, image estimation accuracy, and image complexity.