 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Low Dimensional Convolutional Neural Networks for High-Resolution Remote Sensing Image Retrieval
Dec 30, 2016
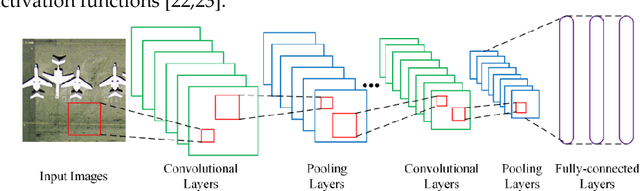
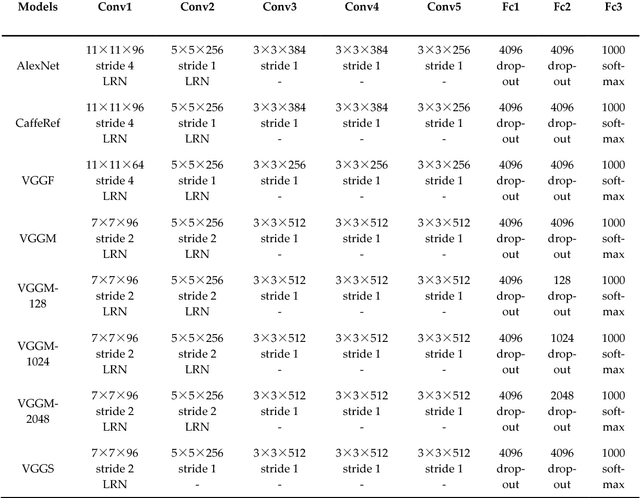
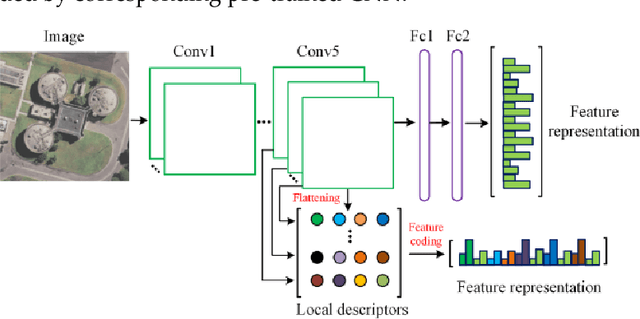
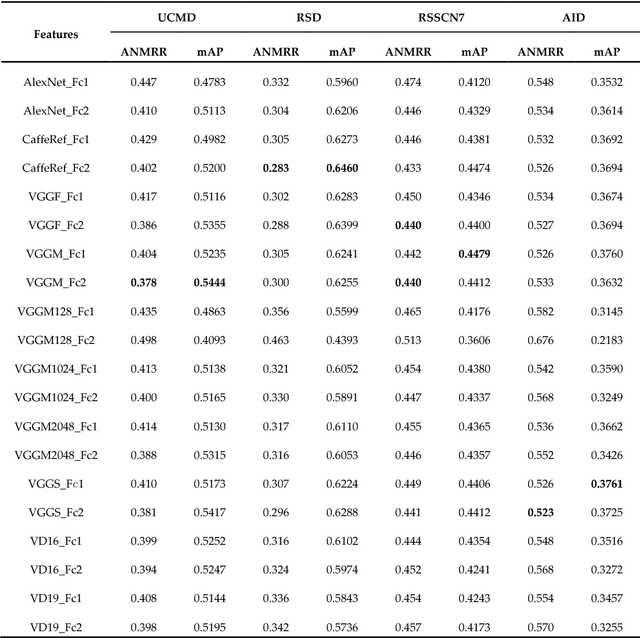
Learning powerful feature representations for image retrieval has always been a challenging task in the field of remote sensing. Traditional methods focus on extracting low-level hand-crafted features which are not only time-consuming but also tend to achieve unsatisfactory performance due to the content complexity of remote sensing images. In this paper, we investigate how to extract deep feature representations based on convolutional neural networks (CNN) for high-resolution remote sensing image retrieval (HRRSIR). To this end, two effective schemes are proposed to generate powerful feature representations for HRRSIR. In the first scheme, the deep features are extracted from the fully-connected and convolutional layers of the pre-trained CNN models, respectively; in the second scheme, we propose a novel CNN architecture based on conventional convolution layers and a three-layer perceptron. The novel CNN model is then trained on a large remote sensing dataset to learn low dimensional features. The two schemes are evaluated on several public and challenging datasets, and the results indicate that the proposed schemes and in particular the novel CNN are able to achieve state-of-the-art performance.
Enriching Visual with Verbal Explanations for Relational Concepts -- Combining LIME with Aleph
Oct 04, 2019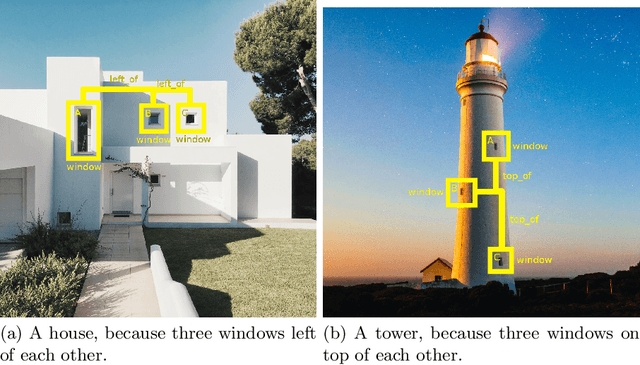
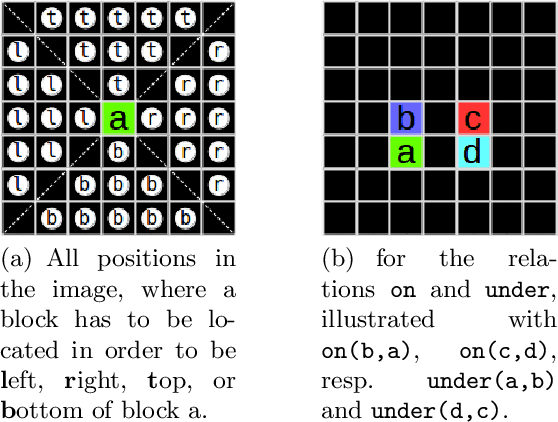
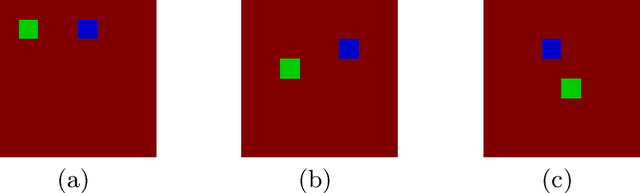
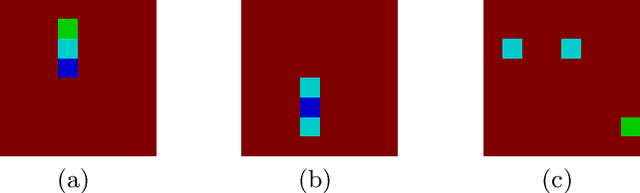
With the increasing number of deep learning applications, there is a growing demand for explanations. Visual explanations provide information about which parts of an image are relevant for a classifier's decision. However, highlighting of image parts (e.g., an eye) cannot capture the relevance of a specific feature value for a class (e.g., that the eye is wide open). Furthermore, highlighting cannot convey whether the classification depends on the mere presence of parts or on a specific spatial relation between them. Consequently, we present an approach that is capable of explaining a classifier's decision in terms of logic rules obtained by the Inductive Logic Programming system Aleph. The examples and the background knowledge needed for Aleph are based on the explanation generation method LIME. We demonstrate our approach with images of a blocksworld domain. First, we show that our approach is capable of identifying a single relation as important explanatory construct. Afterwards, we present the more complex relational concept of towers. Finally, we show how the generated relational rules can be explicitly related with the input image, resulting in richer explanations.
Discovering Salient Anatomical Landmarks by Predicting Human Gaze
Jan 22, 2020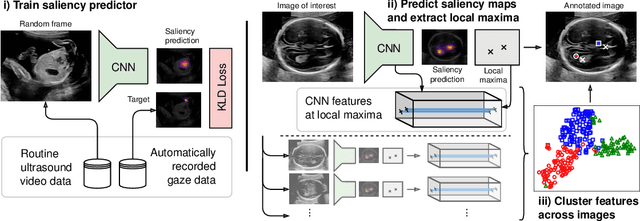
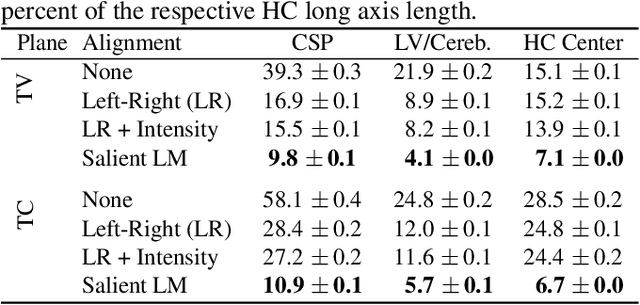
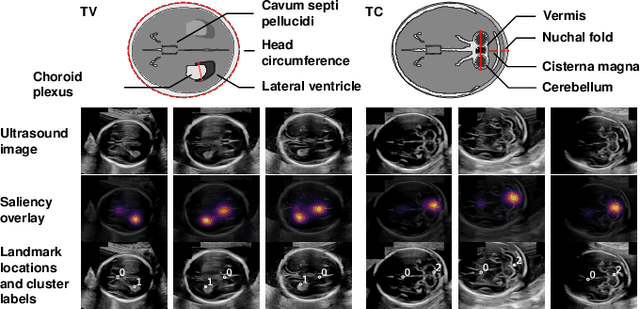
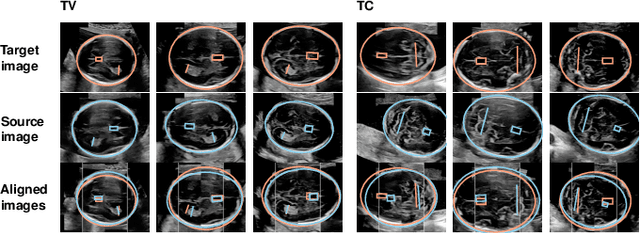
Anatomical landmarks are a crucial prerequisite for many medical imaging tasks. Usually, the set of landmarks for a given task is predefined by experts. The landmark locations for a given image are then annotated manually or via machine learning methods trained on manual annotations. In this paper, in contrast, we present a method to automatically discover and localize anatomical landmarks in medical images. Specifically, we consider landmarks that attract the visual attention of humans, which we term visually salient landmarks. We illustrate the method for fetal neurosonographic images. First, full-length clinical fetal ultrasound scans are recorded with live sonographer gaze-tracking. Next, a convolutional neural network (CNN) is trained to predict the gaze point distribution (saliency map) of the sonographers on scan video frames. The CNN is then used to predict saliency maps of unseen fetal neurosonographic images, and the landmarks are extracted as the local maxima of these saliency maps. Finally, the landmarks are matched across images by clustering the landmark CNN features. We show that the discovered landmarks can be used within affine image registration, with average landmark alignment errors between 4.1% and 10.9% of the fetal head long axis length.
Content-Aware Unsupervised Deep Homography Estimation
Sep 12, 2019
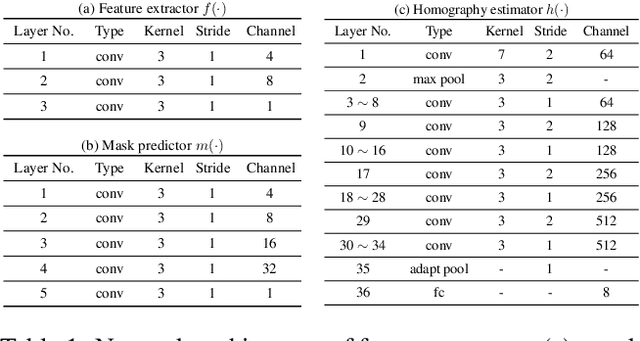
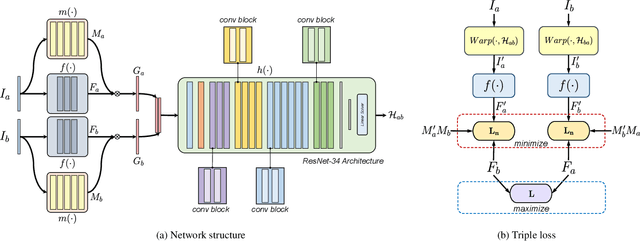
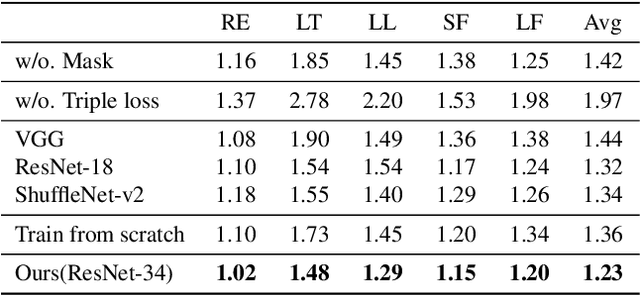
Robust homography estimation between two images is a fundamental task which has been widely applied to various vision applications. Traditional feature based methods often detect image features and fit a homography according to matched features with RANSAC outlier removal. However, the quality of homography heavily relies on the quality of image features, which are prone to errors with respect to low light and low texture images. On the other hand, previous deep homography approaches either synthesize images for supervised learning or adopt aerial images for unsupervised learning, both ignoring the importance of depth disparities in homography estimation. Moreover, they treat the image content equally, including regions of dynamic objects and near-range foregrounds, which further decreases the quality of estimation. In this work, to overcome such problems, we propose an unsupervised deep homography method with a new architecture design. We learn a mask during the estimation to reject outlier regions. In addition, we calculate loss with respect to our learned deep features instead of directly comparing the image contents as did previously. Moreover, a comprehensive dataset is presented, covering both regular and challenging cases, such as poor textures and non-planar interferences. The effectiveness of our method is validated through comparisons with both feature-based and previous deep-based methods. Code will be soon available at Github.
War: Detecting adversarial examples by pre-processing input data
May 15, 2019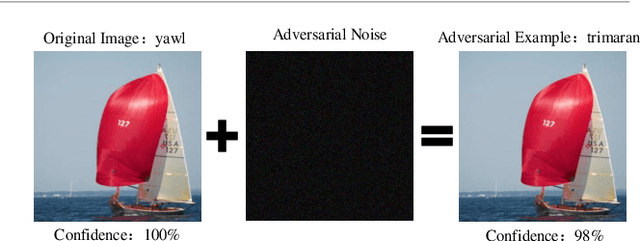
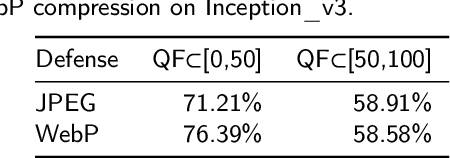
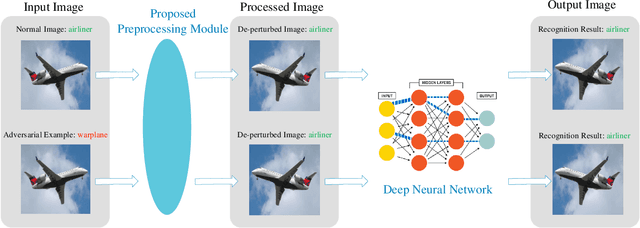

Deep neural networks (DNNs) have demonstrated their outstanding performance in many fields such as image classification and speech recognition. However, DNNs image classifiers are susceptible to interference from adversarial examples, which ultimately leads to incorrect classification output of neural network models. Based on this, this paper proposes a method based on War (WebPcompression and resize) to detect adversarial examples. The method takes WebP compression as the core, firstly performs WebP compression on the input image, and then appropriately resizes the compressed image, so that the label of the adversarial example changes, thereby detecting the existence of the adversarial image. The experimental results show that the proposed method can effectively resist IFGSM, DeepFool and C&W attacks, and the recognition accuracy is improved by more than 10% compared with the HGD method, the detection success rate of adversarial examples is 5% higher than that of the Feature Squeezing method. The method in this paper can effectively reduce the small noise disturbance in the adversarial image, and accurately detect the adversarial example according to the change of the samplelabelwhileensuringtheaccuracyoftheoriginalsampleidentification.
NVAE: A Deep Hierarchical Variational Autoencoder
Jul 08, 2020
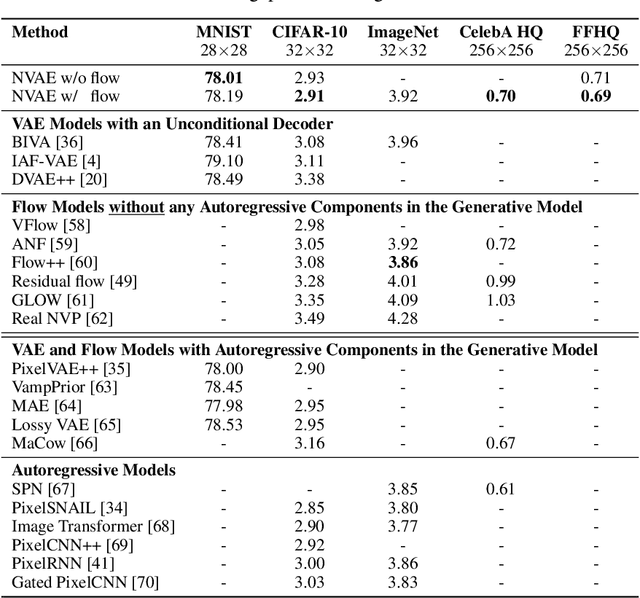
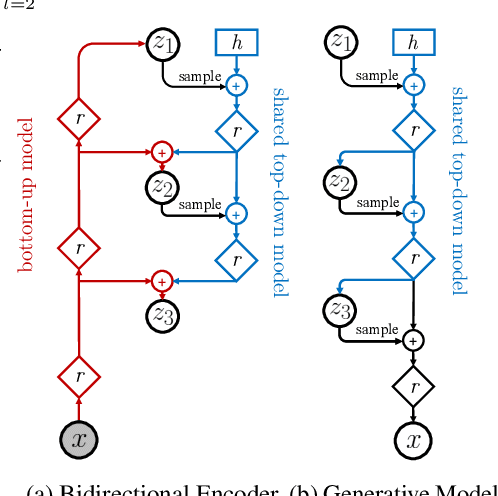
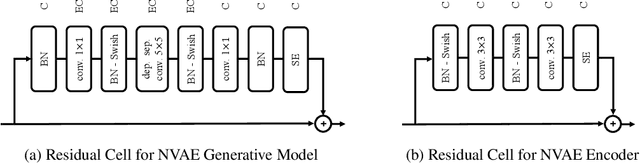
Normalizing flows, autoregressive models, variational autoencoders (VAEs), and deep energy-based models are among competing likelihood-based frameworks for deep generative learning. Among them, VAEs have the advantage of fast and tractable sampling and easy-to-access encoding networks. However, they are currently outperformed by other models such as normalizing flows and autoregressive models. While the majority of the research in VAEs is focused on the statistical challenges, we explore the orthogonal direction of carefully designing neural architectures for hierarchical VAEs. We propose Nouveau VAE (NVAE), a deep hierarchical VAE built for image generation using depth-wise separable convolutions and batch normalization. NVAE is equipped with a residual parameterization of Normal distributions and its training is stabilized by spectral regularization. We show that NVAE achieves state-of-the-art results among non-autoregressive likelihood-based models on the MNIST, CIFAR-10, and CelebA HQ datasets and it provides a strong baseline on FFHQ. For example, on CIFAR-10, NVAE pushes the state-of-the-art from 2.98 to 2.91 bits per dimension, and it produces high-quality images on CelebA HQ as shown in Fig. 1. To the best of our knowledge, NVAE is the first successful VAE applied to natural images as large as 256$\times$256 pixels.
Hyperspectral Super-Resolution via Coupled Tensor Ring Factorization
Jan 06, 2020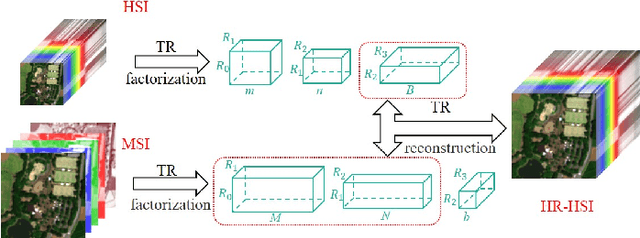
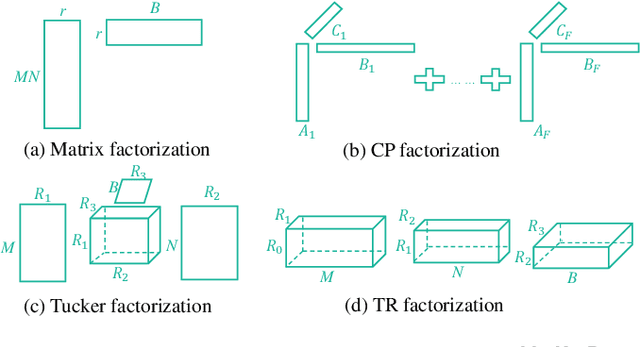
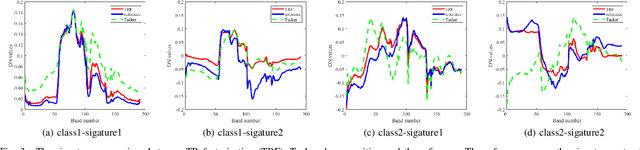
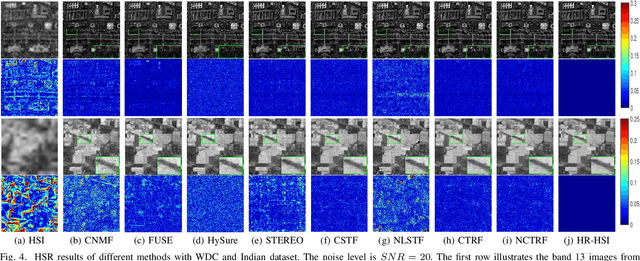
Hyperspectral super-resolution (HSR) fuses a low-resolution hyperspectral image (HSI) and a high-resolution multispectral image (MSI) to obtain a high-resolution HSI (HR-HSI). In this paper, we propose a new model, named coupled tensor ring factorization (CTRF), for HSR. The proposed CTRF approach simultaneously learns high spectral resolution core tensor from the HSI and high spatial resolution core tensors from the MSI, and reconstructs the HR-HSI via tensor ring (TR) representation (Figure~\ref{fig:framework}). The CTRF model can separately exploit the low-rank property of each class (Section \ref{sec:analysis}), which has been never explored in the previous coupled tensor model. Meanwhile, it inherits the simple representation of coupled matrix/CP factorization and flexible low-rank exploration of coupled Tucker factorization. Guided by Theorem~\ref{th:1}, we further propose a spectral nuclear norm regularization to explore the global spectral low-rank property. The experiments have demonstrated the advantage of the proposed nuclear norm regularized CTRF (NCTRF) as compared to previous matrix/tensor and deep learning methods.
Weak Edge Identification Nets for Ocean Front Detection
Sep 17, 2019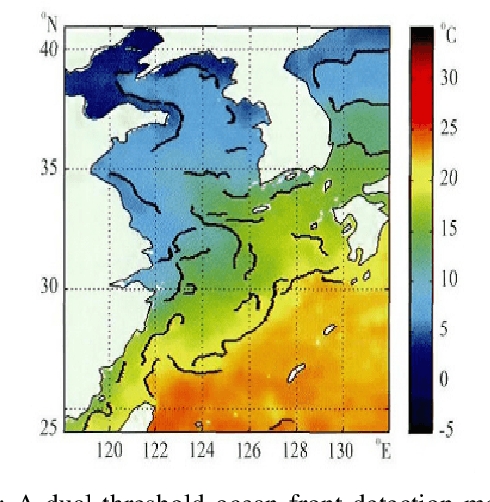
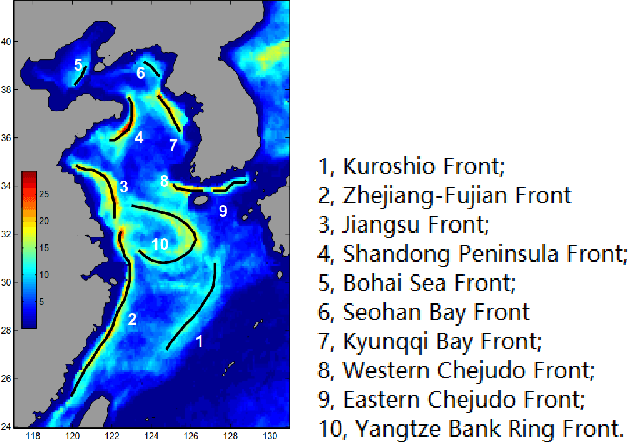
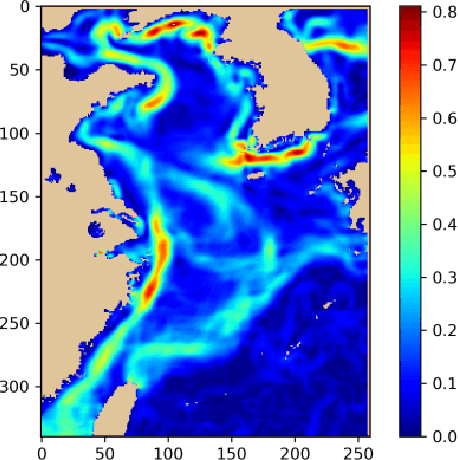
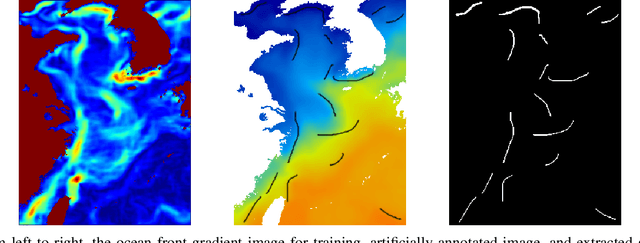
The ocean front has an important impact in many areas, it is meaningful to obtain accurate ocean front positioning, therefore, ocean front detection is a very important task. However, the traditional edge detection algorithm does not detect the weak edge information of the ocean front very well. In response to this problem, we collected relevant ocean front gradient images and found relevant experts to calibrate the ocean front data to obtain groundtruth, and proposed a weak edge identification nets(WEIN) for ocean front detection. Whether it is qualitative or quantitative, our methods perform best. The method uses a welltrained deep learning model to accurately extract the ocean front from the ocean front gradient image. The detection network is divided into multiple stages, and the final output is a multi-stage output image fusion. The method uses the stochastic gradient descent and the correlation loss function to obtain a good ocean front image output.
Image Fusion Technologies In Commercial Remote Sensing Packages
Jul 09, 2013
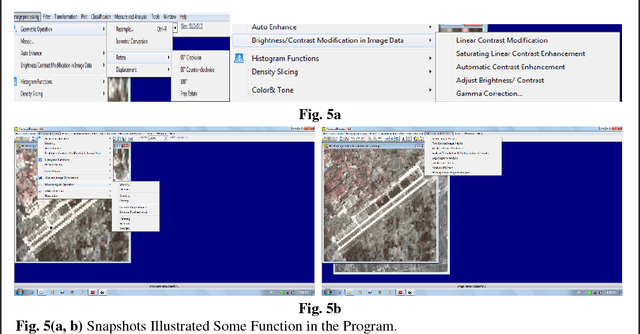
Several remote sensing software packages are used to the explicit purpose of analyzing and visualizing remotely sensed data, with the developing of remote sensing sensor technologies from last ten years. Accord-ing to literature, the remote sensing is still the lack of software tools for effective information extraction from remote sensing data. So, this paper provides a state-of-art of multi-sensor image fusion technologies as well as review on the quality evaluation of the single image or fused images in the commercial remote sensing pack-ages. It also introduces program (ALwassaiProcess) developed for image fusion and classification.
* Keywords: Commercial Processing Systems, Image Fusion, quality evaluation
APB2Face: Audio-guided face reenactment with auxiliary pose and blink signals
Apr 30, 2020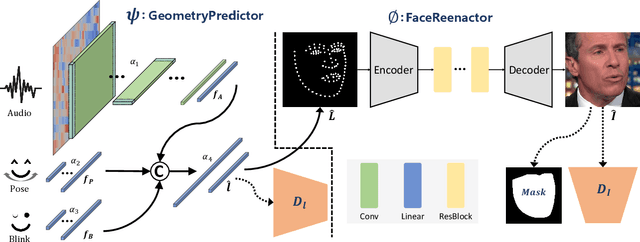
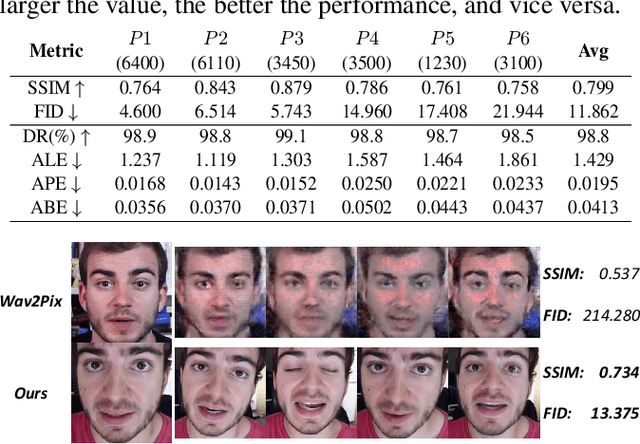

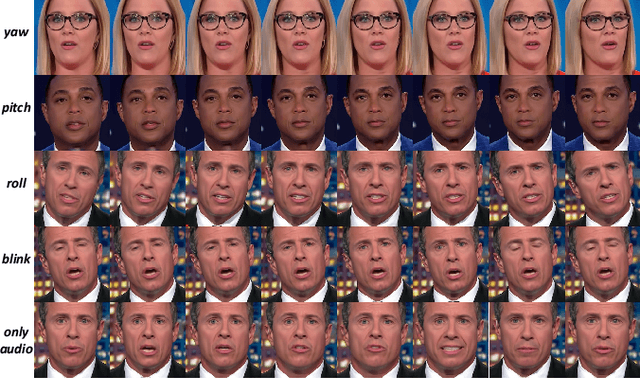
Audio-guided face reenactment aims at generating photorealistic faces using audio information while maintaining the same facial movement as when speaking to a real person. However, existing methods can not generate vivid face images or only reenact low-resolution faces, which limits the application value. To solve those problems, we propose a novel deep neural network named APB2Face, which consists of GeometryPredictor and FaceReenactor modules. GeometryPredictor uses extra head pose and blink state signals as well as audio to predict the latent landmark geometry information, while FaceReenactor inputs the face landmark image to reenact the photorealistic face. A new dataset AnnVI collected from YouTube is presented to support the approach, and experimental results indicate the superiority of our method than state-of-the-arts, whether in authenticity or controllability.