 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Text Extraction and Restoration of Old Handwritten Documents
Jan 23, 2020

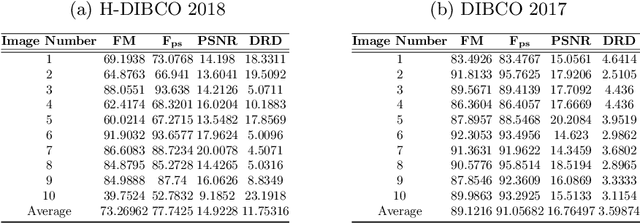


Image restoration is very crucial computer vision task. This paper describes two novel methods for the restoration of old degraded handwritten documents using deep neural network. In addition to that, a small-scale dataset of 26 heritage letters images is introduced. The ground truth data to train the desired network is generated semi automatically involving a pragmatic combination of color transformation, Gaussian mixture model based segmentation and shape correction by using mathematical morphological operators. In the first approach, a deep neural network has been used for text extraction from the document image and later background reconstruction has been done using Gaussian mixture modeling. But Gaussian mixture modelling requires to set parameters manually, to alleviate this we propose a second approach where the background reconstruction and foreground extraction (which which includes extracting text with its original colour) both has been done using deep neural network. Experiments demonstrate that the proposed systems perform well on handwritten document images with severe degradations, even when trained with small dataset. Hence, the proposed methods are ideally suited for digital heritage preservation repositories. It is worth mentioning that, these methods can be extended easily for printed degraded documents.
A Study of Compositional Generalization in Neural Models
Jul 08, 2020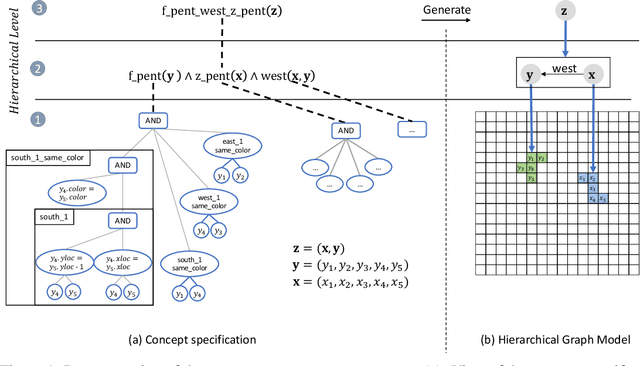
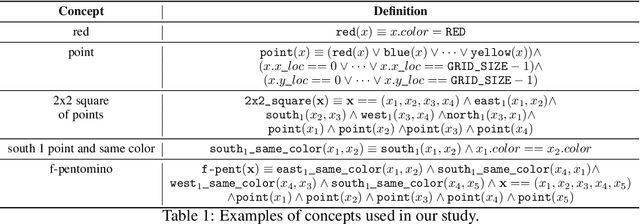
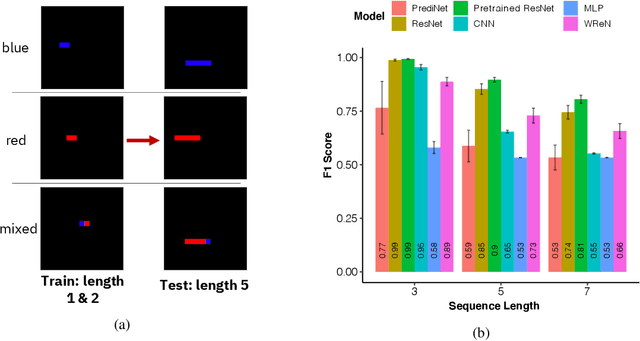
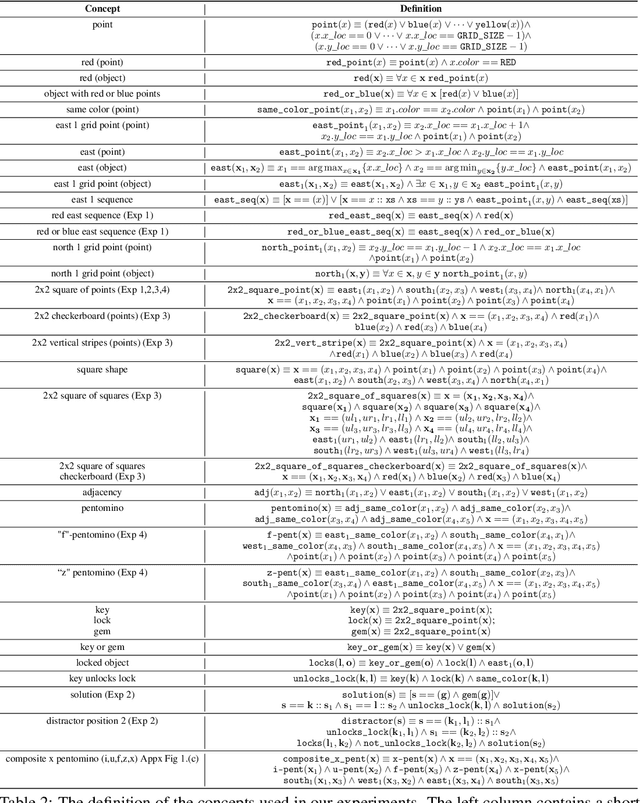
Compositional and relational learning is a hallmark of human intelligence, but one which presents challenges for neural models. One difficulty in the development of such models is the lack of benchmarks with clear compositional and relational task structure on which to systematically evaluate them. In this paper, we introduce an environment called ConceptWorld, which enables the generation of images from compositional and relational concepts, defined using a logical domain specific language. We use it to generate images for a variety of compositional structures: 2x2 squares, pentominoes, sequences, scenes involving these objects, and other more complex concepts. We perform experiments to test the ability of standard neural architectures to generalize on relations with compositional arguments as the compositional depth of those arguments increases and under substitution. We compare standard neural networks such as MLP, CNN and ResNet, as well as state-of-the-art relational networks including WReN and PrediNet in a multi-class image classification setting. For simple problems, all models generalize well to close concepts but struggle with longer compositional chains. For more complex tests involving substitutivity, all models struggle, even with short chains. In highlighting these difficulties and providing an environment for further experimentation, we hope to encourage the development of models which are able to generalize effectively in compositional, relational domains.
A causal view of compositional zero-shot recognition
Jun 25, 2020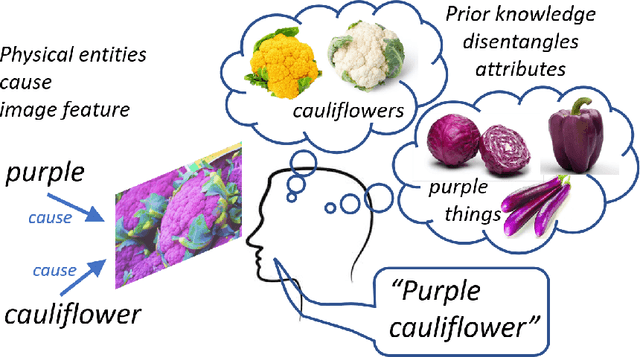
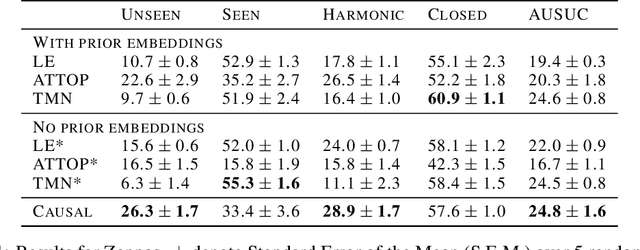
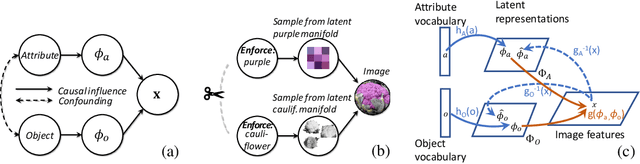

People easily recognize new visual categories that are new combinations of known components. This compositional generalization capacity is critical for learning in real-world domains like vision and language because the long tail of new combinations dominates the distribution. Unfortunately, learning systems struggle with compositional generalization because they often build on features that are correlated with class labels even if they are not "essential" for the class. This leads to consistent misclassification of samples from a new distribution, like new combinations of known components. Here we describe an approach for compositional generalization that builds on causal ideas. First, we describe compositional zero-shot learning from a causal perspective, and propose to view zero-shot inference as finding "which intervention caused the image?". Second, we present a causal-inspired embedding model that learns disentangled representations of elementary components of visual objects from correlated (confounded) training data. We evaluate this approach on two datasets for predicting new combinations of attribute-object pairs: A well-controlled synthesized images dataset and a real world dataset which consists of fine-grained types of shoes. We show improvements compared to strong baselines.
FOSNet: An End-to-End Trainable Deep Neural Network for Scene Recognition
Jul 18, 2019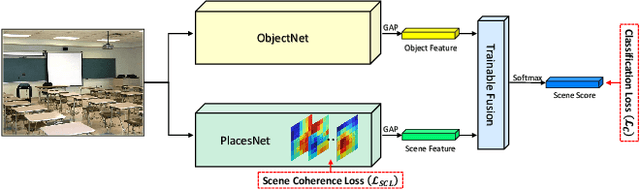
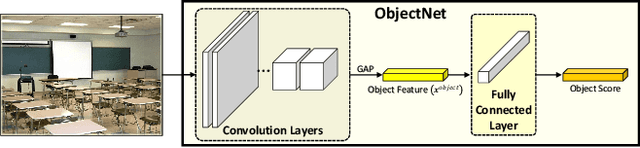
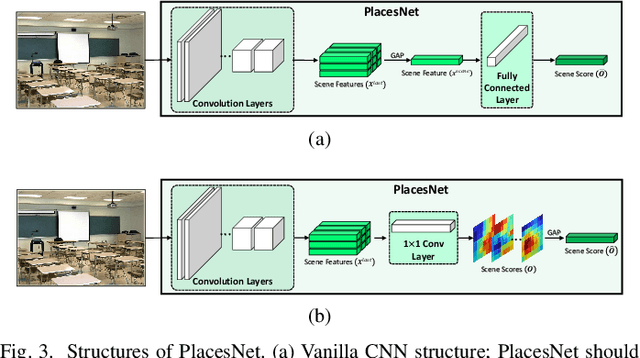
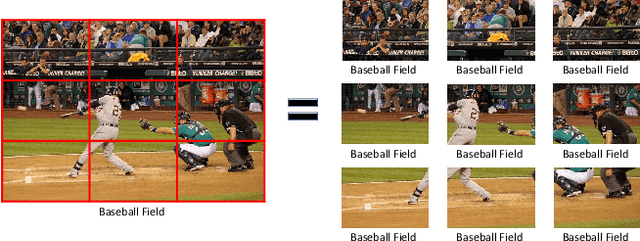
Scene recognition is an image recognition problem aimed at predicting the category of the place at which the image is taken. In this paper, a new scene recognition method using the convolutional neural network (CNN) is proposed. The proposed method is based on the fusion of the object and the scene information in the given image and the CNN framework is named as FOS (fusion of object and scene) Net. In addition, a new loss named scene coherence loss (SCL) is developed to train the FOSNet and to improve the scene recognition performance. The proposed SCL is based on the unique traits of the scene that the 'sceneness' spreads and the scene class does not change all over the image. The proposed FOSNet was experimented with three most popular scene recognition datasets, and their state-of-the-art performance is obtained in two sets: 60.14% on Places 2 and 90.37% on MIT indoor 67. The second highest performance of 77.28% is obtained on SUN 397.
PAI-Conv: Permutable Anisotropic Convolutional Networks for Learning on Point Clouds
May 27, 2020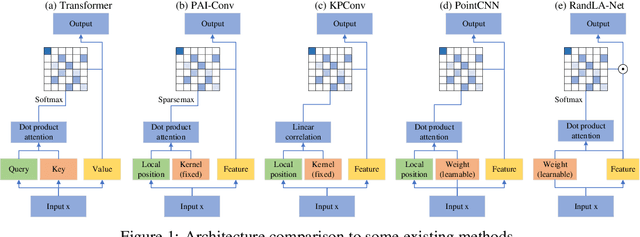
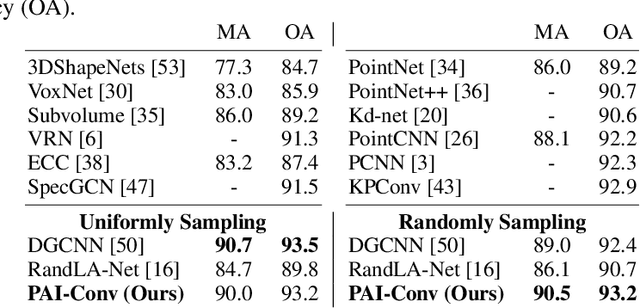
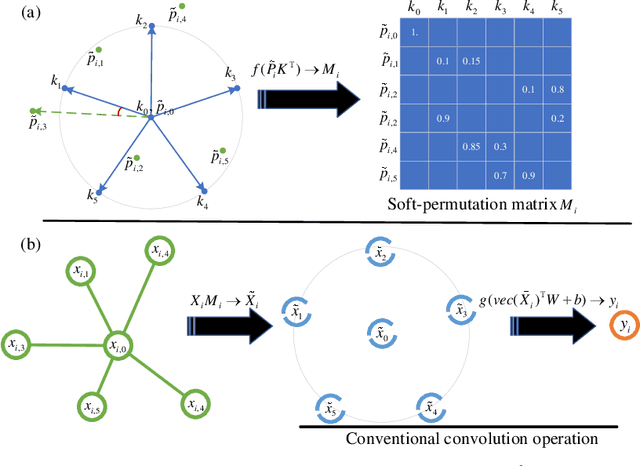
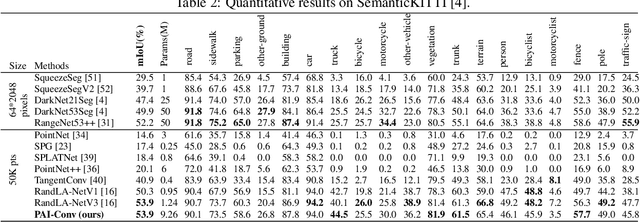
Demand for efficient representation learning on point clouds is increasing in many 3D computer vision applications. The recent success of convolutional neural networks (CNNs) for image analysis suggests the value of adapting insight from CNN to point clouds. However, unlike images that are Euclidean structured, point clouds are irregular since each point's neighbors vary from one to another. Various point neural networks have been developed using isotropic filters or applying weighting matrices to overcome the structure inconsistency on point clouds. However, isotropic filters or weighting matrices limit the representation power. In this paper, we propose a permutable anisotropic convolutional operation (PAI-Conv) that calculates soft-permutation matrices for each point according to a set of evenly distributed kernel points on a sphere's surface and performs shared anisotropic filters as CNN does. PAI-Conv is physically meaningful and can efficiently cooperate with random point sampling method. Comprehensive experiments demonstrate that PAI-Conv produces competitive results in classification and semantic segmentation tasks compared to state-of-the-art methods.
MarmoNet: a pipeline for automated projection mapping of the common marmoset brain from whole-brain serial two-photon tomography
Aug 02, 2019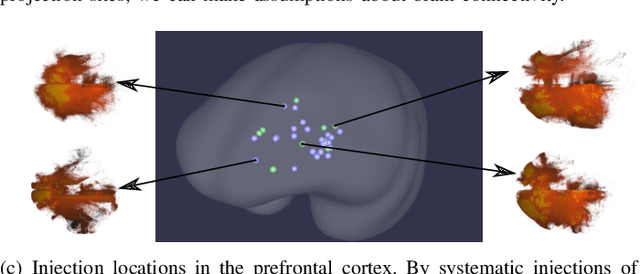
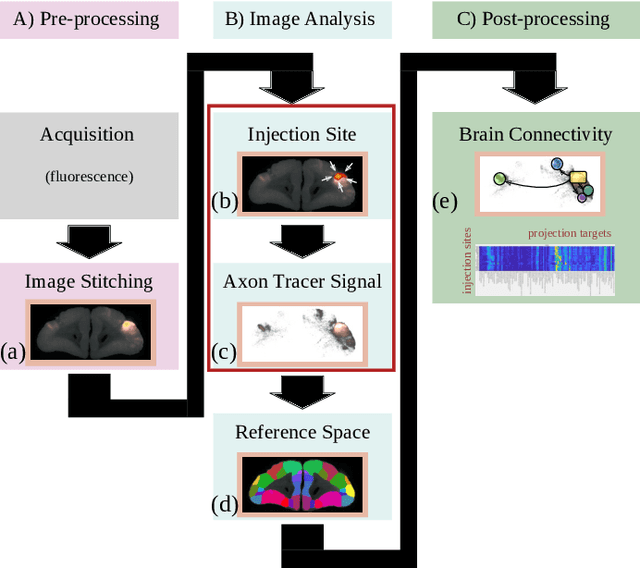

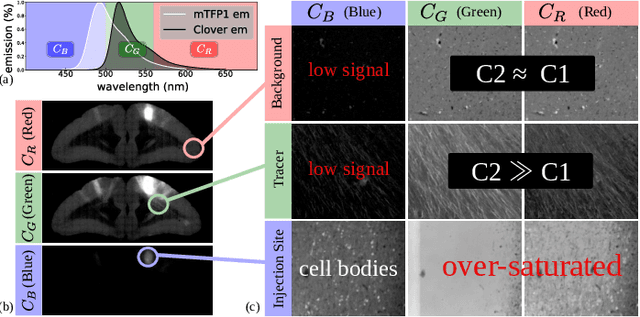
Understanding the connectivity in the brain is an important prerequisite for understanding how the brain processes information. In the Brain/MINDS project, a connectivity study on marmoset brains uses two-photon microscopy fluorescence images of axonal projections to collect the neuron connectivity from defined brain regions at the mesoscopic scale. The processing of the images requires the detection and segmentation of the axonal tracer signal. The objective is to detect as much tracer signal as possible while not misclassifying other background structures as the signal. This can be challenging because of imaging noise, a cluttered image background, distortions or varying image contrast cause problems. We are developing MarmoNet, a pipeline that processes and analyzes tracer image data of the common marmoset brain. The pipeline incorporates state-of-the-art machine learning techniques based on artificial convolutional neural networks (CNN) and image registration techniques to extract and map all relevant information in a robust manner. The pipeline processes new images in a fully automated way. This report introduces the current state of the tracer signal analysis part of the pipeline.
Evolutionary NAS with Gene Expression Programming of Cellular Encoding
May 27, 2020

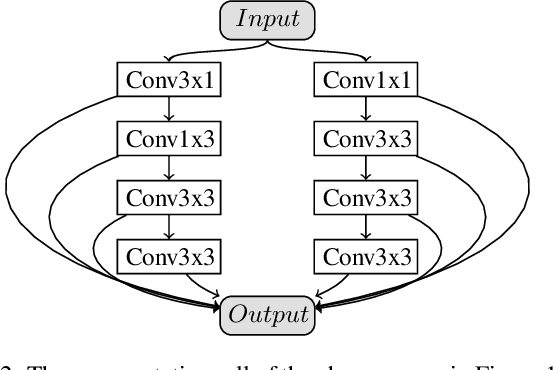

The renaissance of neural architecture search (NAS) has seen classical methods such as genetic algorithms (GA) and genetic programming (GP) being exploited for convolutional neural network (CNN) architectures. While recent work have achieved promising performance on visual perception tasks, the direct encoding scheme of both GA and GP has functional complexity deficiency and does not scale well on large architectures like CNN. To address this, we present a new generative encoding scheme -- $symbolic\ linear\ generative\ encoding$ (SLGE) -- simple, yet powerful scheme which embeds local graph transformations in chromosomes of linear fixed-length string to develop CNN architectures of variant shapes and sizes via evolutionary process of gene expression programming. In experiments, the effectiveness of SLGE is shown in discovering architectures that improve the performance of the state-of-the-art handcrafted CNN architectures on CIFAR-10 and CIFAR-100 image classification tasks; and achieves a competitive classification error rate with the existing NAS methods using less GPU resources.
Using a Generative Adversarial Network for CT Normalization and its Impact on Radiomic Features
Jan 22, 2020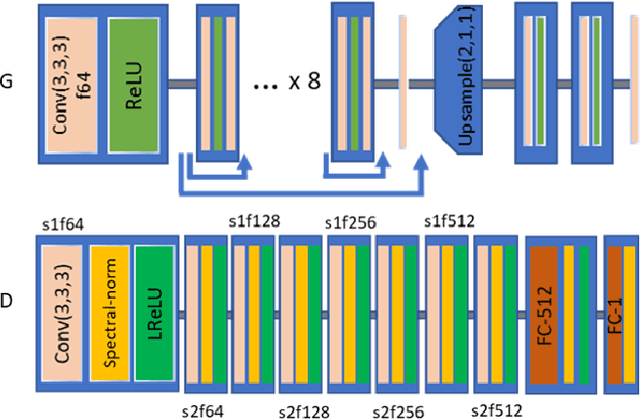
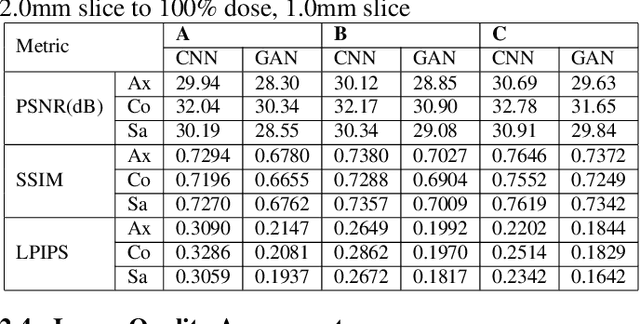
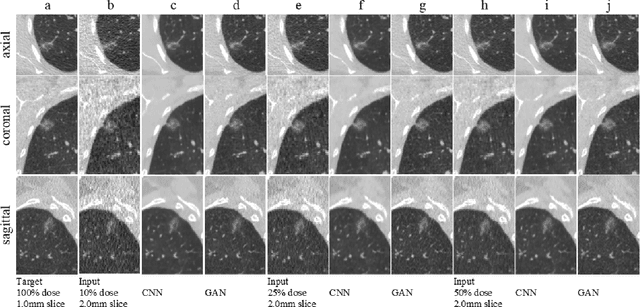
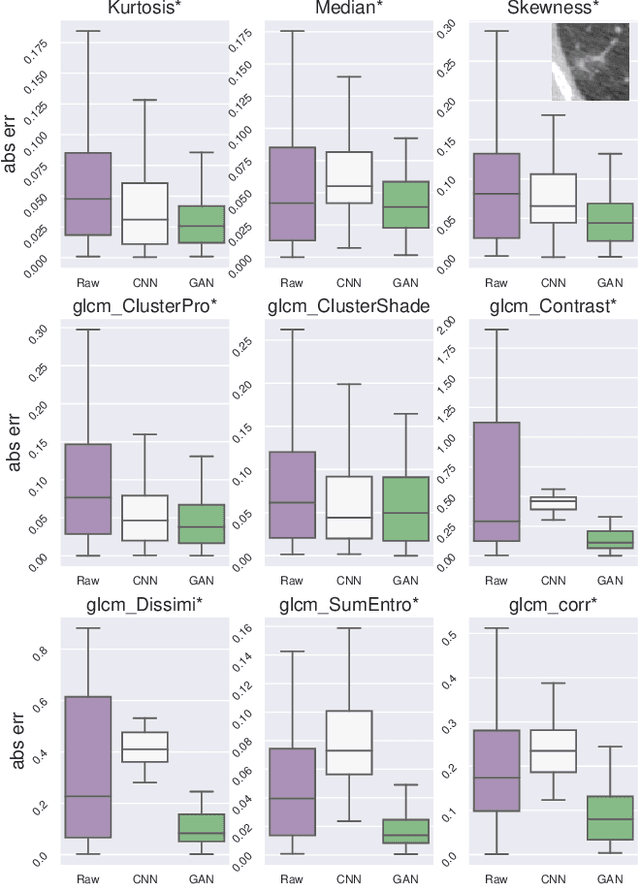
Computer-Aided-Diagnosis (CADx) systems assist radiologists with identifying and classifying potentially malignant pulmonary nodules on chest CT scans using morphology and texture-based (radiomic) features. However, radiomic features are sensitive to differences in acquisitions due to variations in dose levels and slice thickness. This study investigates the feasibility of generating a normalized scan from heterogeneous CT scans as input. We obtained projection data from 40 low-dose chest CT scans, simulating acquisitions at 10%, 25% and 50% dose and reconstructing the scans at 1.0mm and 2.0mm slice thickness. A 3D generative adversarial network (GAN) was used to simultaneously normalize reduced dose, thick slice (2.0mm) images to normal dose (100%), thinner slice (1.0mm) images. We evaluated the normalized image quality using peak signal-to-noise ratio (PSNR), structural similarity index (SSIM) and Learned Perceptual Image Patch Similarity (LPIPS). Our GAN improved perceptual similarity by 35%, compared to a baseline CNN method. Our analysis also shows that the GAN-based approach led to a significantly smaller error (p-value < 0.05) in nine studied radiomic features. These results indicated that GANs could be used to normalize heterogeneous CT images and reduce the variability in radiomic feature values.
Learning Low Dimensional Convolutional Neural Networks for High-Resolution Remote Sensing Image Retrieval
Dec 30, 2016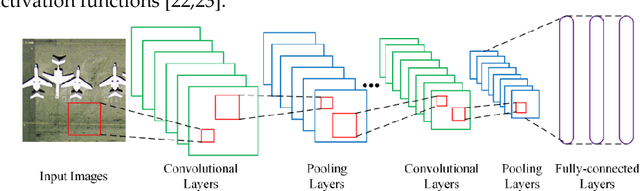
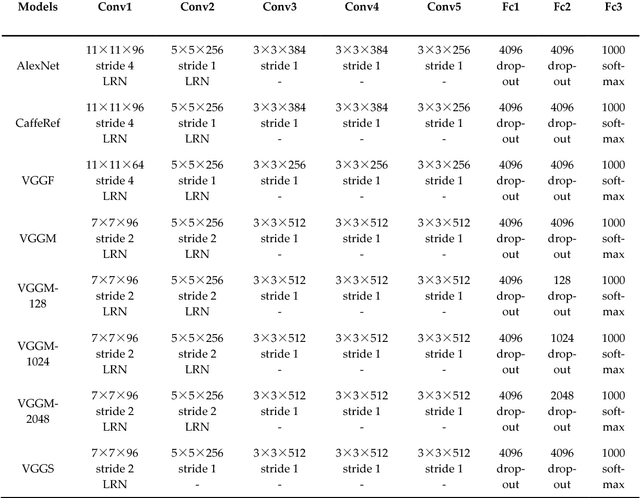
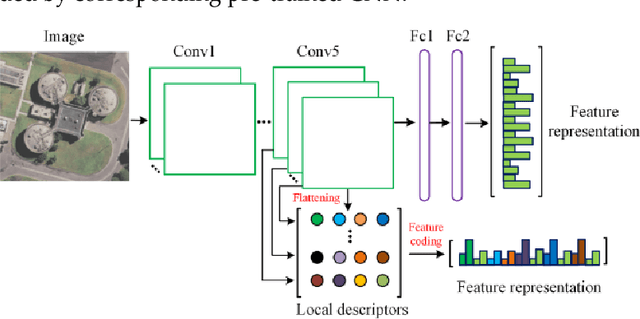
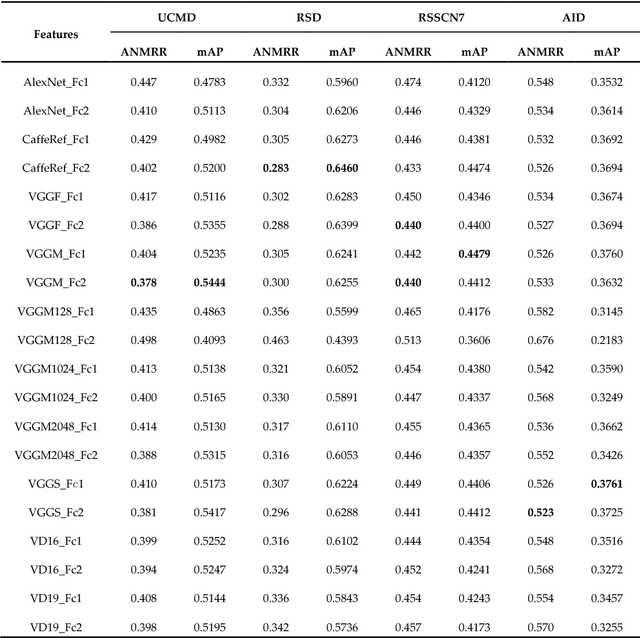
Learning powerful feature representations for image retrieval has always been a challenging task in the field of remote sensing. Traditional methods focus on extracting low-level hand-crafted features which are not only time-consuming but also tend to achieve unsatisfactory performance due to the content complexity of remote sensing images. In this paper, we investigate how to extract deep feature representations based on convolutional neural networks (CNN) for high-resolution remote sensing image retrieval (HRRSIR). To this end, two effective schemes are proposed to generate powerful feature representations for HRRSIR. In the first scheme, the deep features are extracted from the fully-connected and convolutional layers of the pre-trained CNN models, respectively; in the second scheme, we propose a novel CNN architecture based on conventional convolution layers and a three-layer perceptron. The novel CNN model is then trained on a large remote sensing dataset to learn low dimensional features. The two schemes are evaluated on several public and challenging datasets, and the results indicate that the proposed schemes and in particular the novel CNN are able to achieve state-of-the-art performance.
Interpretable Foreground Object Search As Knowledge Distillation
Jul 20, 2020

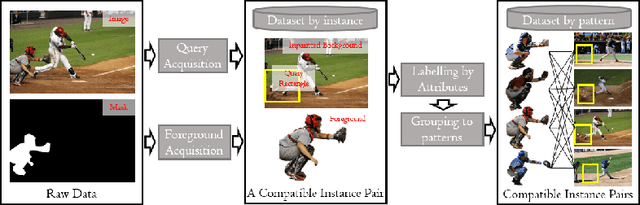

This paper proposes a knowledge distillation method for foreground object search (FoS). Given a background and a rectangle specifying the foreground location and scale, FoS retrieves compatible foregrounds in a certain category for later image composition. Foregrounds within the same category can be grouped into a small number of patterns. Instances within each pattern are compatible with \textit{any} query input interchangeably. These instances are referred to as \textit{interchangeable foregrounds}. We first present a pipeline to build pattern-level FoS dataset containing labels of interchangeable foregrounds. We then establish a benchmark dataset for further training and testing following the pipeline. As for the proposed method, we first train a foreground encoder to learn representations of interchangeable foregrounds. We then train a query encoder to learn query-foreground compatibility following a knowledge distillation framework. It aims to transfer knowledge from interchangeable foregrounds to supervise representation learning of compatibility. The query feature representation is projected to the same latent space as interchangeable foregrounds, enabling very efficient and interpretable instance-level search. Furthermore, pattern-level search is feasible to retrieve more controllable, reasonable and diverse foregrounds. The proposed method outperforms the previous state-of-the-art by $10.42\%$ in absolute difference and $24.06\%$ in relative improvement evaluated by mean average precision (mAP). Extensive experimental results also demonstrate its efficacy from various aspects. The benchmark dataset and code will be release shortly.