 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Iterative Thresholded Bi-Histogram Equalization for Medical Image Enhancement
Aug 24, 2015
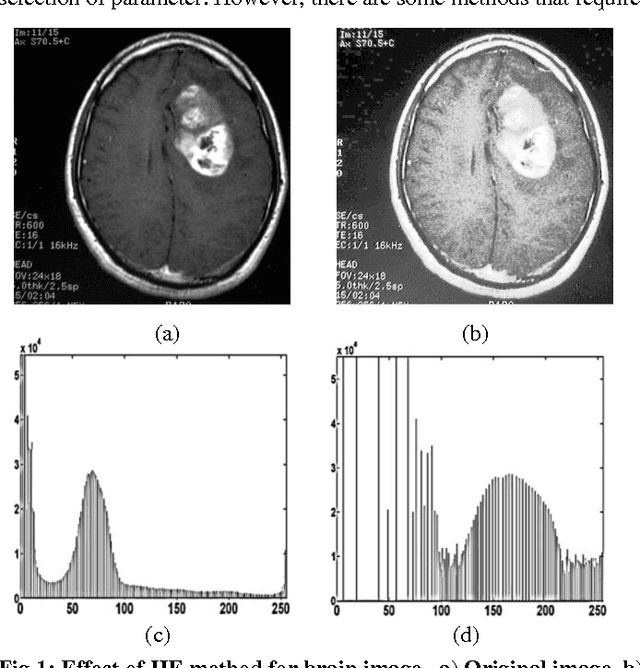
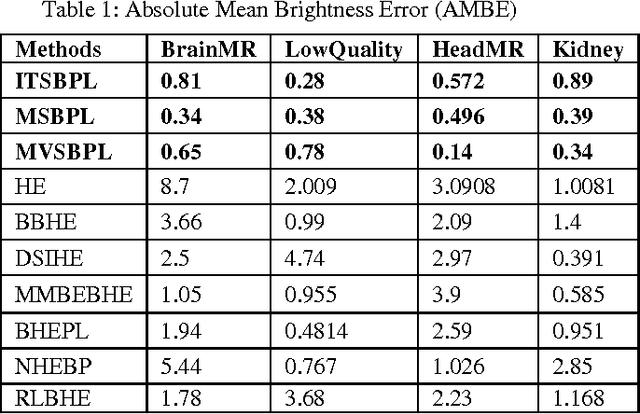
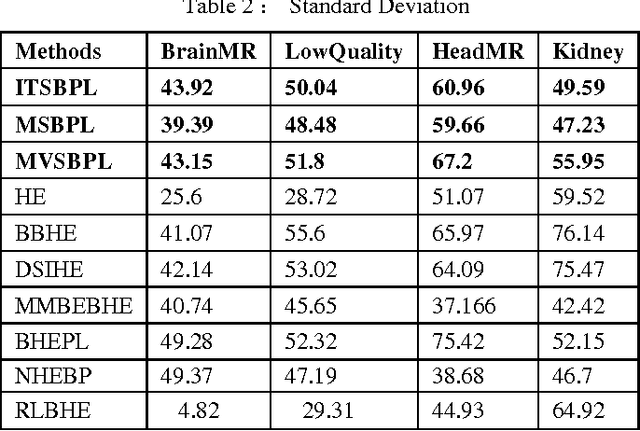
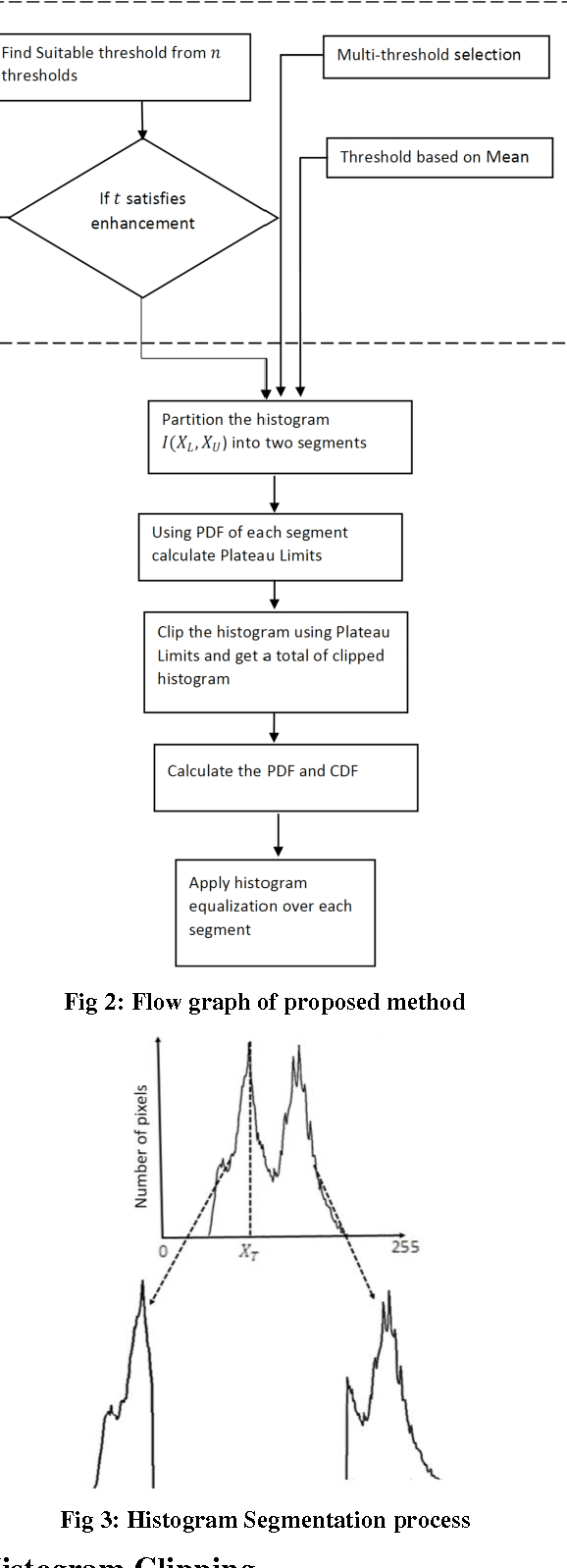
Enhancement of human vision to get an insight to information content is of vital importance. The traditional histogram equalization methods have been suffering from amplified contrast with the addition of artifacts and a surprising unnatural visibility of the processed images. In order to overcome these drawbacks, this paper proposes interative, mean, and multi-threshold selection criterion with plateau limits, which consist of histogram segmentation, clipping and transformation modules. The histogram partition consists of multiple thresholding processes that divide the histogram into two parts, whereas the clipping process nicely enhances the contrast by having a check on the rate of enhancement that could be tuned. Histogram equalization to each segmented sub-histogram provides the output image with preserved brightness and enhanced contrast. Results of the present study showed that the proposed method efficiently handles the noise amplification. Further, it also preserves the brightness by retaining natural look of targeted image.
* 8 Pages, 8 Figures, International Journal of Computer Applications (IJCA)
Invariant Tensor Feature Coding
Jun 05, 2019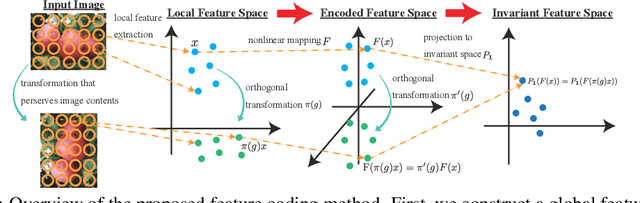
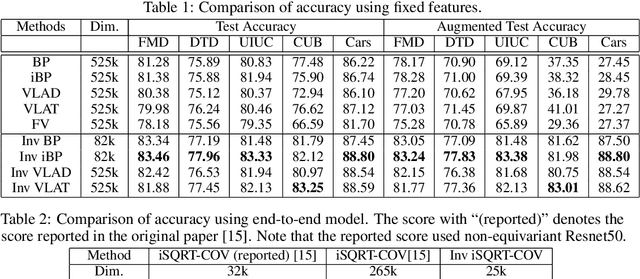
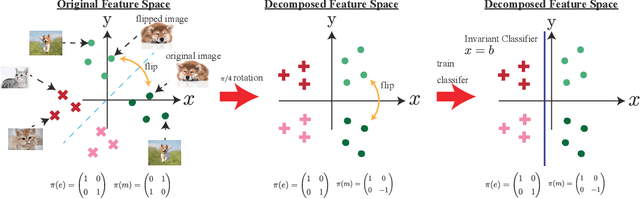
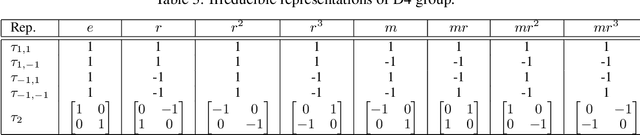
We propose a novel feature coding method that exploits invariance. We consider the setting where the transformations that preserve the image contents compose a finite group of orthogonal matrices. This is the case in many image transformations such as image rotations and image flipping. We prove that the group-invariant feature vector contains sufficient discriminative information when we learn a linear classifier using convex loss minimization. From this result, we propose a novel feature modeling for principal component analysis, and k-means clustering, which are used for most feature coding methods, and global feature functions that explicitly consider the group action. Although the global feature functions are complex nonlinear functions in general, we can calculate the group action on this space easily by constructing the functions as the tensor product representations of basic representations, resulting in the explicit form of invariant feature functions. We demonstrate the effectiveness of our methods on several image datasets.
Learn to synthesize and synthesize to learn
May 01, 2019
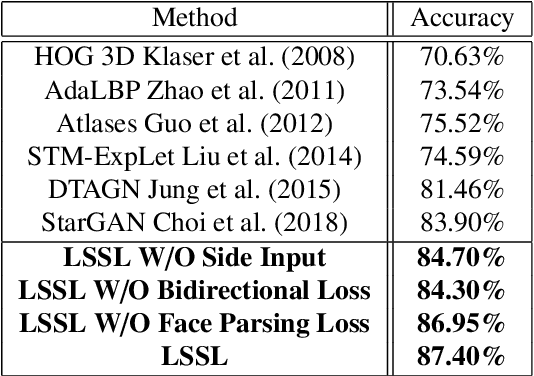

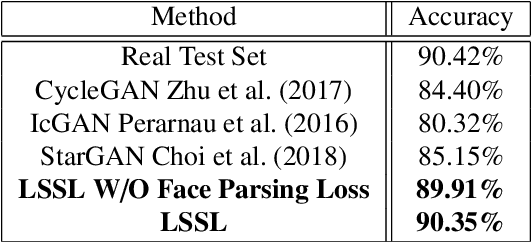
Attribute guided face image synthesis aims to manipulate attributes on a face image. Most existing methods for image-to-image translation can either perform a fixed translation between any two image domains using a single attribute or require training data with the attributes of interest for each subject. Therefore, these methods could only train one specific model for each pair of image domains, which limits their ability in dealing with more than two domains. Another disadvantage of these methods is that they often suffer from the common problem of mode collapse that degrades the quality of the generated images. To overcome these shortcomings, we propose attribute guided face image generation method using a single model, which is capable to synthesize multiple photo-realistic face images conditioned on the attributes of interest. In addition, we adopt the proposed model to increase the realism of the simulated face images while preserving the face characteristics. Compared to existing models, synthetic face images generated by our method present a good photorealistic quality on several face datasets. Finally, we demonstrate that generated facial images can be used for synthetic data augmentation, and improve the performance of the classifier used for facial expression recognition.
Image Retrieval based on Bag-of-Words model
Apr 18, 2013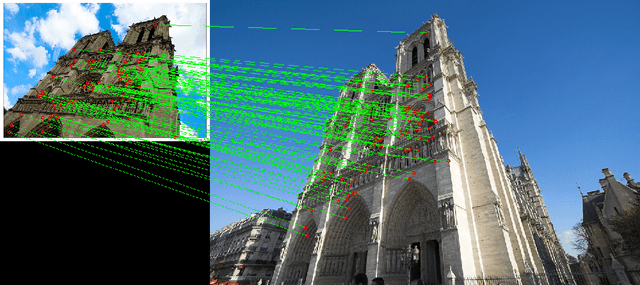
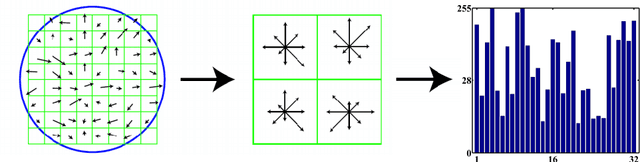
This article gives a survey for bag-of-words (BoW) or bag-of-features model in image retrieval system. In recent years, large-scale image retrieval shows significant potential in both industry applications and research problems. As local descriptors like SIFT demonstrate great discriminative power in solving vision problems like object recognition, image classification and annotation, more and more state-of-the-art large scale image retrieval systems are trying to rely on them. A common way to achieve this is first quantizing local descriptors into visual words, and then applying scalable textual indexing and retrieval schemes. We call this model as bag-of-words or bag-of-features model. The goal of this survey is to give an overview of this model and introduce different strategies when building the system based on this model.
A Study of Compositional Generalization in Neural Models
Jul 08, 2020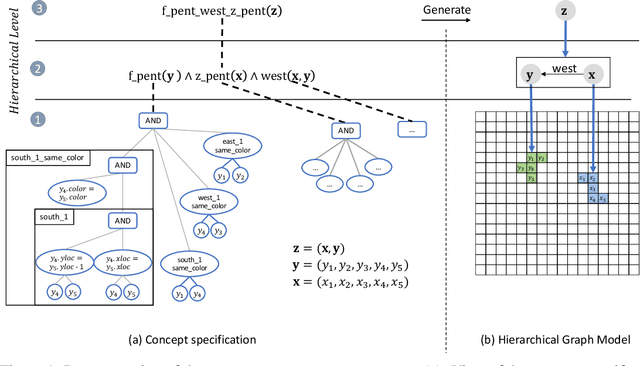
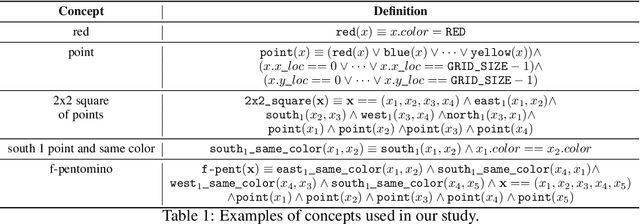
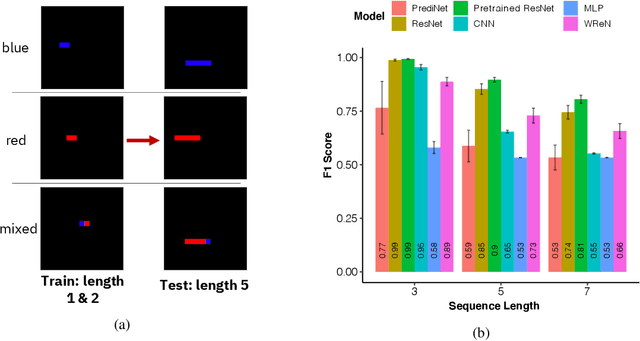
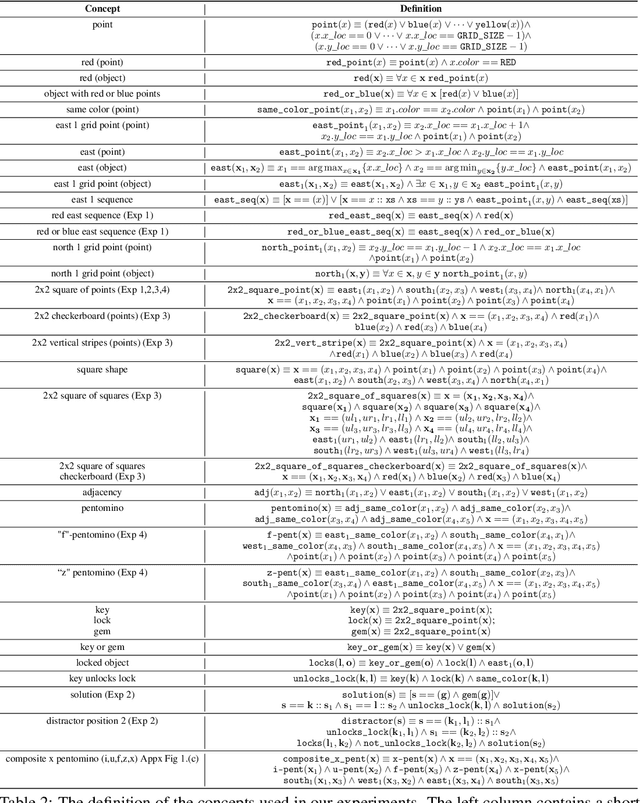
Compositional and relational learning is a hallmark of human intelligence, but one which presents challenges for neural models. One difficulty in the development of such models is the lack of benchmarks with clear compositional and relational task structure on which to systematically evaluate them. In this paper, we introduce an environment called ConceptWorld, which enables the generation of images from compositional and relational concepts, defined using a logical domain specific language. We use it to generate images for a variety of compositional structures: 2x2 squares, pentominoes, sequences, scenes involving these objects, and other more complex concepts. We perform experiments to test the ability of standard neural architectures to generalize on relations with compositional arguments as the compositional depth of those arguments increases and under substitution. We compare standard neural networks such as MLP, CNN and ResNet, as well as state-of-the-art relational networks including WReN and PrediNet in a multi-class image classification setting. For simple problems, all models generalize well to close concepts but struggle with longer compositional chains. For more complex tests involving substitutivity, all models struggle, even with short chains. In highlighting these difficulties and providing an environment for further experimentation, we hope to encourage the development of models which are able to generalize effectively in compositional, relational domains.
Expressing Visual Relationships via Language
Jun 19, 2019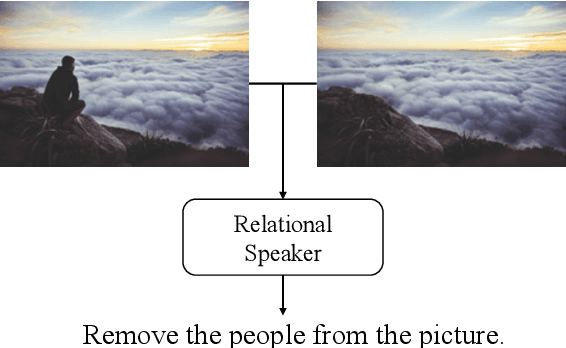
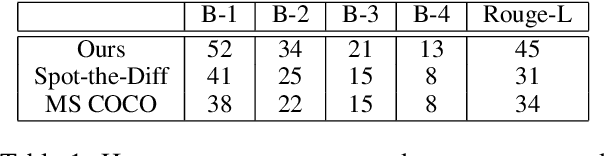
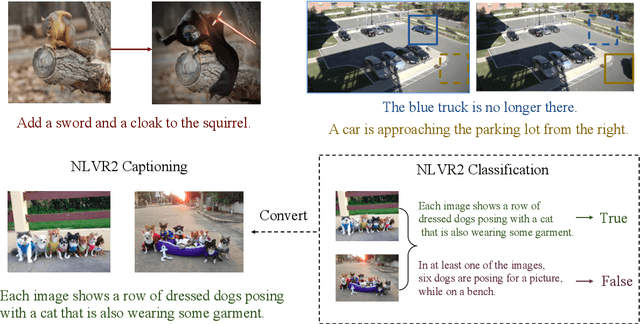
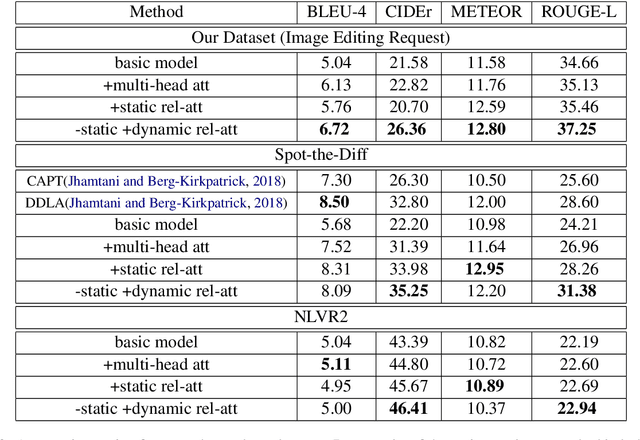
Describing images with text is a fundamental problem in vision-language research. Current studies in this domain mostly focus on single image captioning. However, in various real applications (e.g., image editing, difference interpretation, and retrieval), generating relational captions for two images, can also be very useful. This important problem has not been explored mostly due to lack of datasets and effective models. To push forward the research in this direction, we first introduce a new language-guided image editing dataset that contains a large number of real image pairs with corresponding editing instructions. We then propose a new relational speaker model based on an encoder-decoder architecture with static relational attention and sequential multi-head attention. We also extend the model with dynamic relational attention, which calculates visual alignment while decoding. Our models are evaluated on our newly collected and two public datasets consisting of image pairs annotated with relationship sentences. Experimental results, based on both automatic and human evaluation, demonstrate that our model outperforms all baselines and existing methods on all the datasets.
Image Analysis Using a Dual-Tree $M$-Band Wavelet Transform
Feb 27, 2017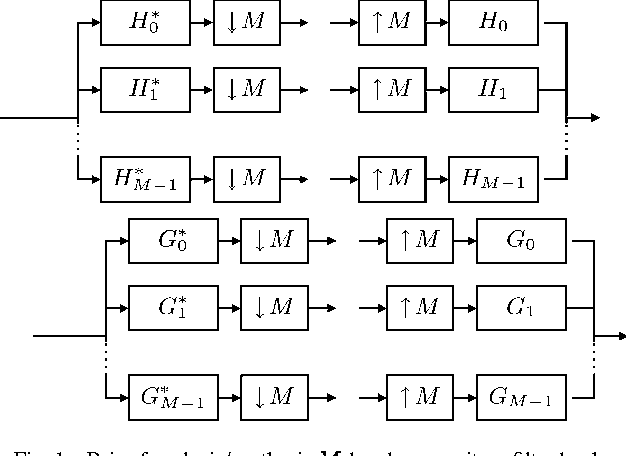
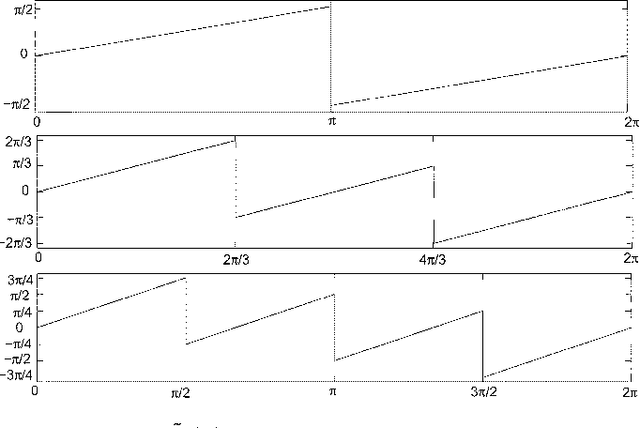
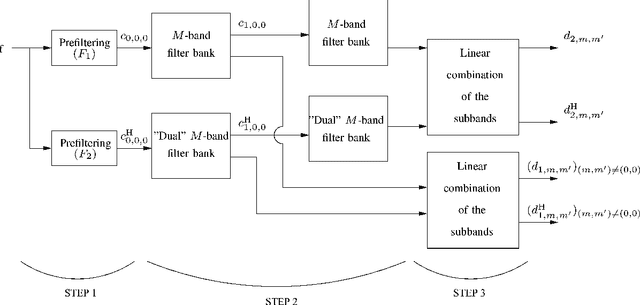
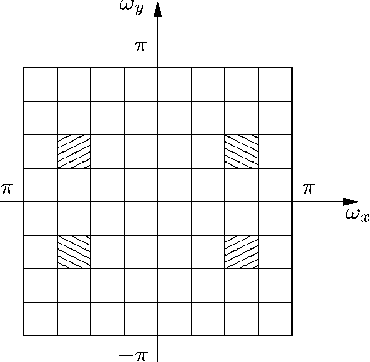
We propose a 2D generalization to the $M$-band case of the dual-tree decomposition structure (initially proposed by N. Kingsbury and further investigated by I. Selesnick) based on a Hilbert pair of wavelets. We particularly address (\textit{i}) the construction of the dual basis and (\textit{ii}) the resulting directional analysis. We also revisit the necessary pre-processing stage in the $M$-band case. While several reconstructions are possible because of the redundancy of the representation, we propose a new optimal signal reconstruction technique, which minimizes potential estimation errors. The effectiveness of the proposed $M$-band decomposition is demonstrated via denoising comparisons on several image types (natural, texture, seismics), with various $M$-band wavelets and thresholding strategies. Significant improvements in terms of both overall noise reduction and direction preservation are observed.
A causal view of compositional zero-shot recognition
Jun 25, 2020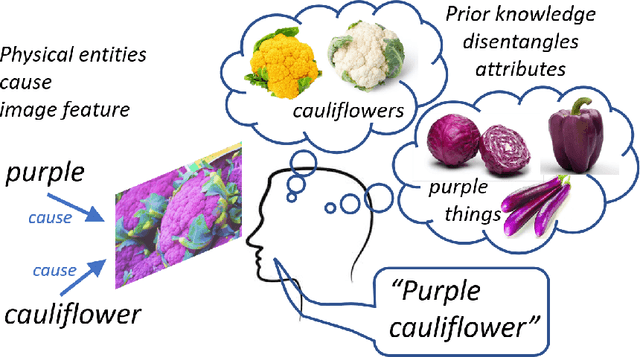
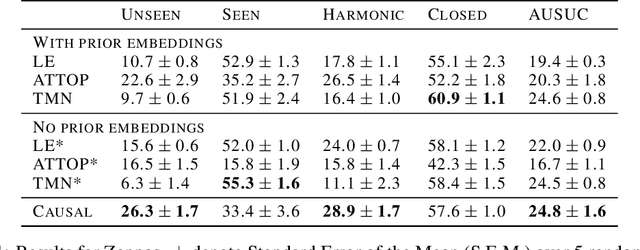
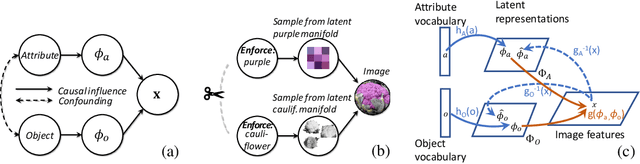

People easily recognize new visual categories that are new combinations of known components. This compositional generalization capacity is critical for learning in real-world domains like vision and language because the long tail of new combinations dominates the distribution. Unfortunately, learning systems struggle with compositional generalization because they often build on features that are correlated with class labels even if they are not "essential" for the class. This leads to consistent misclassification of samples from a new distribution, like new combinations of known components. Here we describe an approach for compositional generalization that builds on causal ideas. First, we describe compositional zero-shot learning from a causal perspective, and propose to view zero-shot inference as finding "which intervention caused the image?". Second, we present a causal-inspired embedding model that learns disentangled representations of elementary components of visual objects from correlated (confounded) training data. We evaluate this approach on two datasets for predicting new combinations of attribute-object pairs: A well-controlled synthesized images dataset and a real world dataset which consists of fine-grained types of shoes. We show improvements compared to strong baselines.
Text Extraction and Restoration of Old Handwritten Documents
Jan 23, 2020
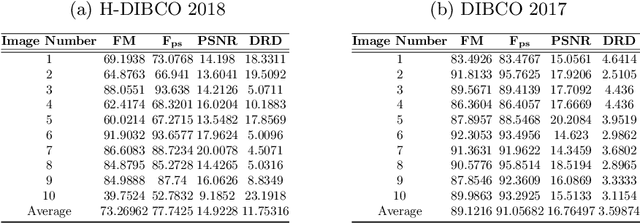


Image restoration is very crucial computer vision task. This paper describes two novel methods for the restoration of old degraded handwritten documents using deep neural network. In addition to that, a small-scale dataset of 26 heritage letters images is introduced. The ground truth data to train the desired network is generated semi automatically involving a pragmatic combination of color transformation, Gaussian mixture model based segmentation and shape correction by using mathematical morphological operators. In the first approach, a deep neural network has been used for text extraction from the document image and later background reconstruction has been done using Gaussian mixture modeling. But Gaussian mixture modelling requires to set parameters manually, to alleviate this we propose a second approach where the background reconstruction and foreground extraction (which which includes extracting text with its original colour) both has been done using deep neural network. Experiments demonstrate that the proposed systems perform well on handwritten document images with severe degradations, even when trained with small dataset. Hence, the proposed methods are ideally suited for digital heritage preservation repositories. It is worth mentioning that, these methods can be extended easily for printed degraded documents.
PAI-Conv: Permutable Anisotropic Convolutional Networks for Learning on Point Clouds
May 27, 2020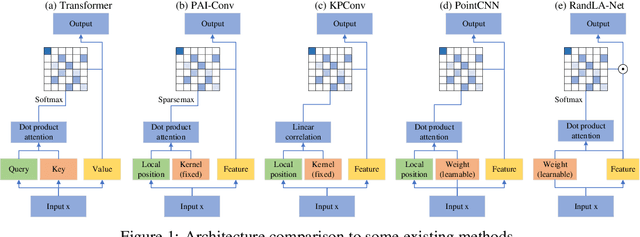
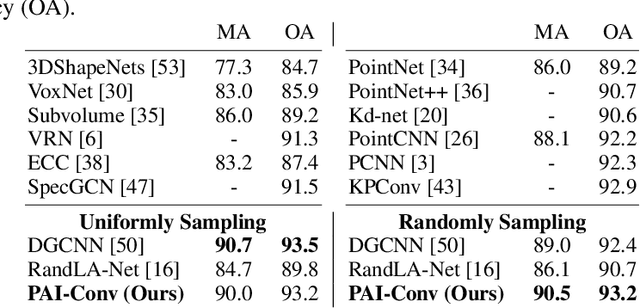
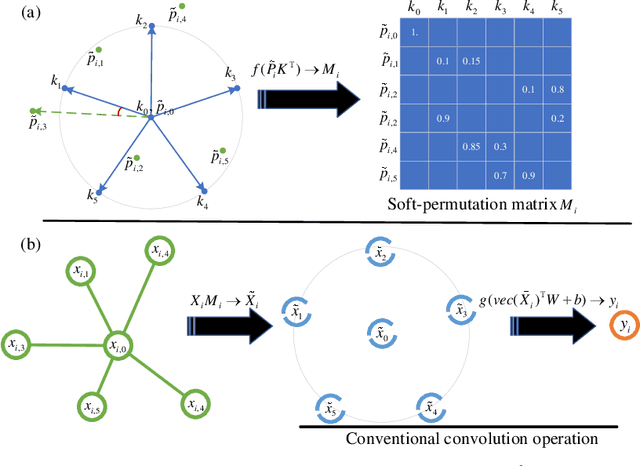
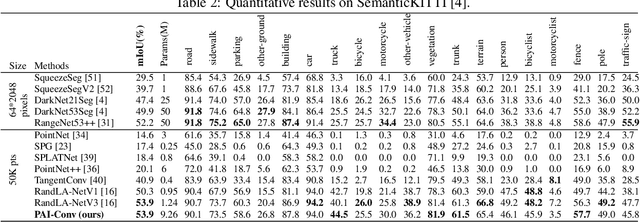
Demand for efficient representation learning on point clouds is increasing in many 3D computer vision applications. The recent success of convolutional neural networks (CNNs) for image analysis suggests the value of adapting insight from CNN to point clouds. However, unlike images that are Euclidean structured, point clouds are irregular since each point's neighbors vary from one to another. Various point neural networks have been developed using isotropic filters or applying weighting matrices to overcome the structure inconsistency on point clouds. However, isotropic filters or weighting matrices limit the representation power. In this paper, we propose a permutable anisotropic convolutional operation (PAI-Conv) that calculates soft-permutation matrices for each point according to a set of evenly distributed kernel points on a sphere's surface and performs shared anisotropic filters as CNN does. PAI-Conv is physically meaningful and can efficiently cooperate with random point sampling method. Comprehensive experiments demonstrate that PAI-Conv produces competitive results in classification and semantic segmentation tasks compared to state-of-the-art methods.