 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Patient-Specific Domain Adaptation for Fast Optical Flow Based on Teacher-Student Knowledge Transfer
Jul 09, 2020
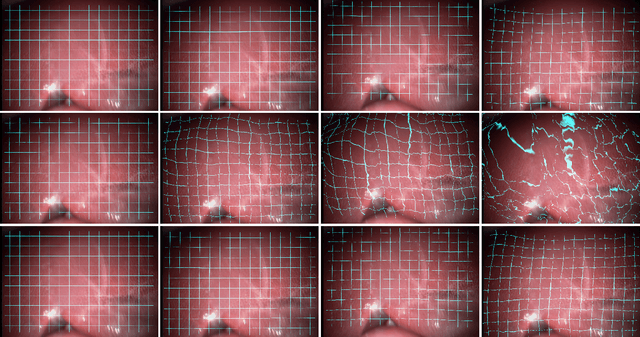

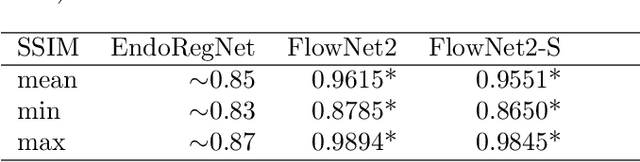
Fast motion feedback is crucial in computer-aided surgery (CAS) on moving tissue. Image-assistance in safety-critical vision applications requires a dense tracking of tissue motion. This can be done using optical flow (OF). Accurate motion predictions at high processing rates lead to higher patient safety. Current deep learning OF models show the common speed vs. accuracy trade-off. To achieve high accuracy at high processing rates, we propose patient-specific fine-tuning of a fast model. This minimizes the domain gap between training and application data, while reducing the target domain to the capability of the lower complex, fast model. We propose to obtain training sequences pre-operatively in the operation room. We handle missing ground truth, by employing teacher-student learning. Using flow estimations from teacher model FlowNet2 we specialize a fast student model FlowNet2S on the patient-specific domain. Evaluation is performed on sequences from the Hamlyn dataset. Our student model shows very good performance after fine-tuning. Tracking accuracy is comparable to the teacher model at a speed up of factor six. Fine-tuning can be performed within minutes, making it feasible for the operation room. Our method allows to use a real-time capable model that was previously not suited for this task. This method is laying the path for improved patient-specific motion estimation in CAS.
DR-KFD: A Differentiable Visual Metric for 3D Shape Reconstruction
Nov 20, 2019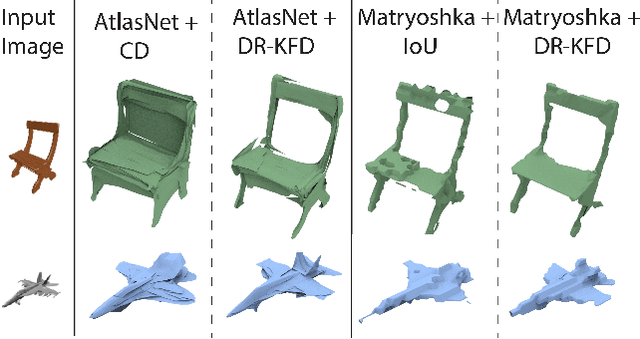
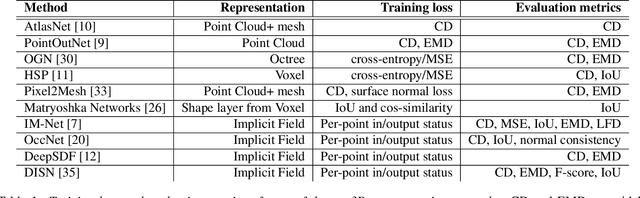
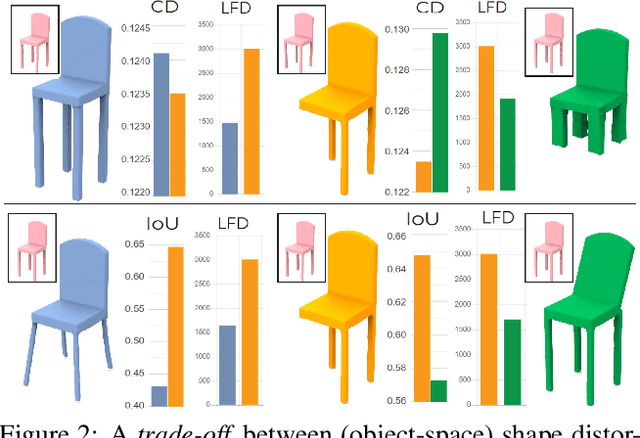
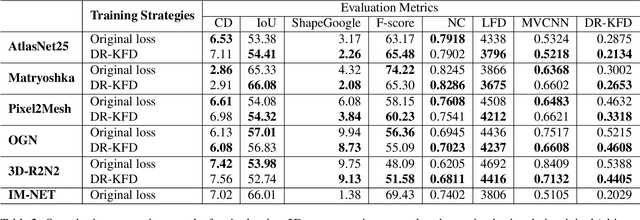
We advocate the use of differential visual shape metrics to train deep neural networks for 3D reconstruction. We introduce such a metric which compares two 3D shapes by measuring visual, image-space differences between multiview images differentiably rendered from the shapes. Furthermore, we develop a differentiable image-space distance based on mean-squared errors defined over Hard- Net features computed from probabilistic keypoint maps of the compared images. Our differential visual shape metric can be easily plugged into various reconstruction networks, replacing the object-space distortion measures, such as Chamfer or Earth Mover distances, so as to optimize the network weights to produce reconstruction results with better structural fidelity and visual quality. We demonstrate this both objectively, using well-known visual shape metrics for retrieval and classification tasks that are independent from our new metric, and subjectively through a perceptual study.
Low Dose CT Denoising via Joint Bilateral Filtering and Intelligent Parameter Optimization
Jul 09, 2020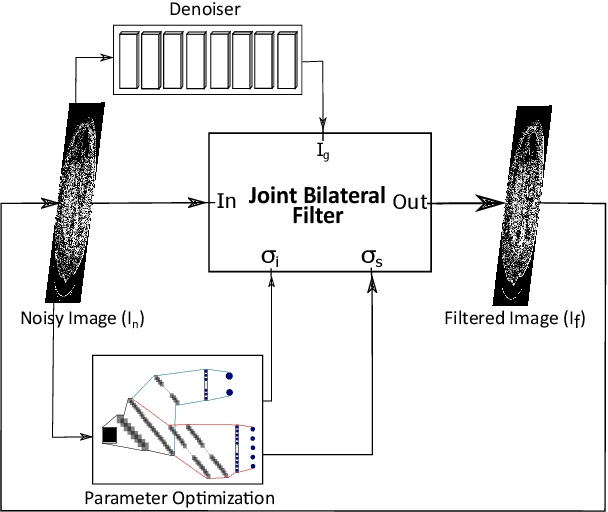
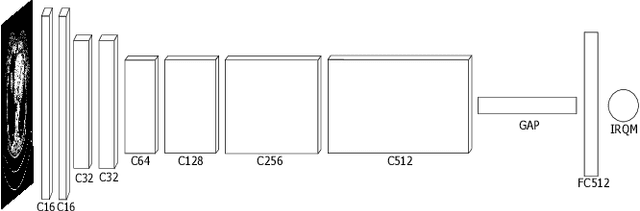
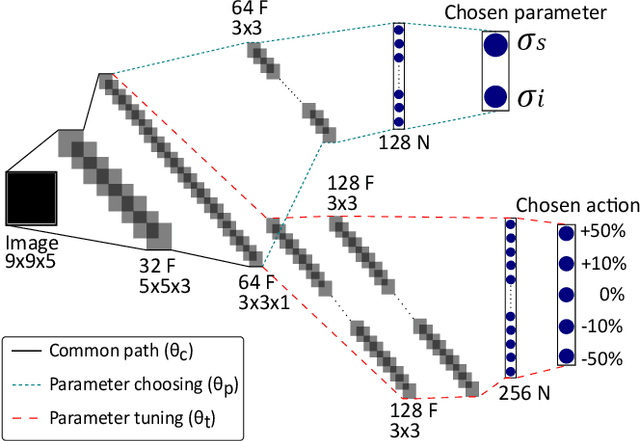
Denoising of clinical CT images is an active area for deep learning research. Current clinically approved methods use iterative reconstruction methods to reduce the noise in CT images. Iterative reconstruction techniques require multiple forward and backward projections, which are time-consuming and computationally expensive. Recently, deep learning methods have been successfully used to denoise CT images. However, conventional deep learning methods suffer from the 'black box' problem. They have low accountability, which is necessary for use in clinical imaging situations. In this paper, we use a Joint Bilateral Filter (JBF) to denoise our CT images. The guidance image of the JBF is estimated using a deep residual convolutional neural network (CNN). The range smoothing and spatial smoothing parameters of the JBF are tuned by a deep reinforcement learning task. Our actor first chooses a parameter, and subsequently chooses an action to tune the value of the parameter. A reward network is designed to direct the reinforcement learning task. Our denoising method demonstrates good denoising performance, while retaining structural information. Our method significantly outperforms state of the art deep neural networks. Moreover, our method has only two parameters, which makes it significantly more interpretable and reduces the 'black box' problem. We experimentally measure the impact of our intelligent parameter optimization and our reward network. Our studies show that our current setup yields the best results in terms of structural preservation.
JBFnet -- Low Dose CT Denoising by Trainable Joint Bilateral Filtering
Jul 09, 2020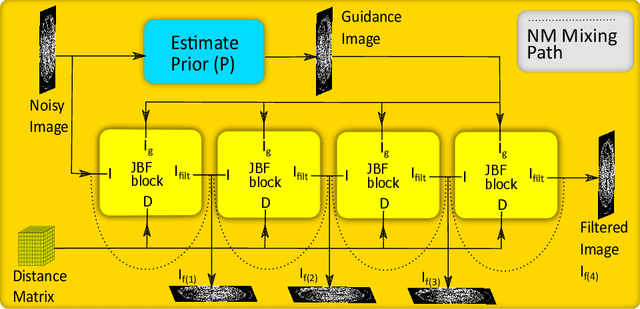
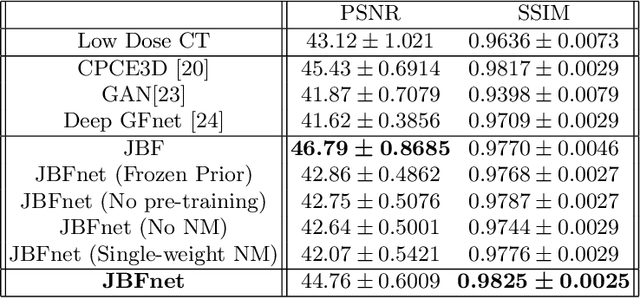
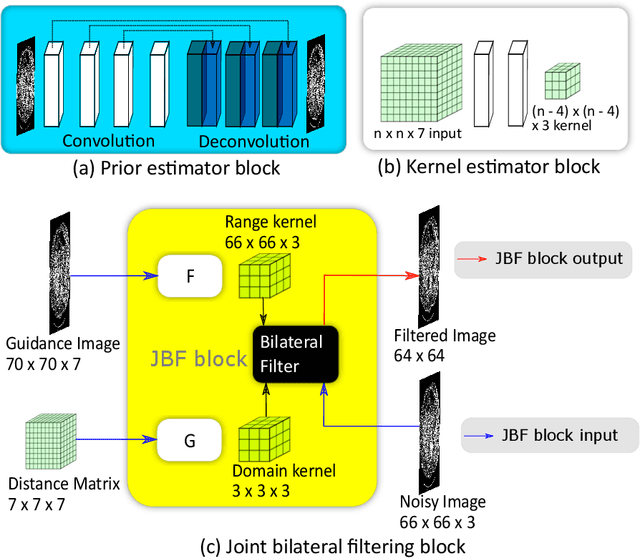
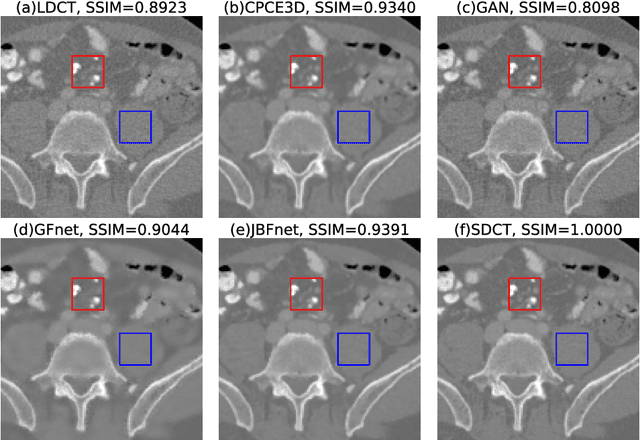
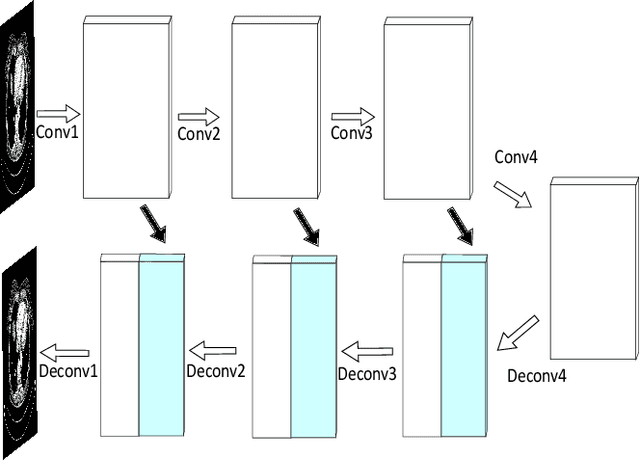
Deep neural networks have shown great success in low dose CT denoising. However, most of these deep neural networks have several hundred thousand trainable parameters. This, combined with the inherent non-linearity of the neural network, makes the deep neural network diffcult to understand with low accountability. In this study we introduce JBFnet, a neural network for low dose CT denoising. The architecture of JBFnet implements iterative bilateral filtering. The filter functions of the Joint Bilateral Filter (JBF) are learned via shallow convolutional networks. The guidance image is estimated by a deep neural network. JBFnet is split into four filtering blocks, each of which performs Joint Bilateral Filtering. Each JBF block consists of 112 trainable parameters, making the noise removal process comprehendable. The Noise Map (NM) is added after filtering to preserve high level features. We train JBFnet with the data from the body scans of 10 patients, and test it on the AAPM low dose CT Grand Challenge dataset. We compare JBFnet with state-of-the-art deep learning networks. JBFnet outperforms CPCE3D, GAN and deep GFnet on the test dataset in terms of noise removal while preserving structures. We conduct several ablation studies to test the performance of our network architecture and training method. Our current setup achieves the best performance, while still maintaining behavioural accountability.
An Improved Image Mosaicing Algorithm for Damaged Documents
Mar 07, 2015

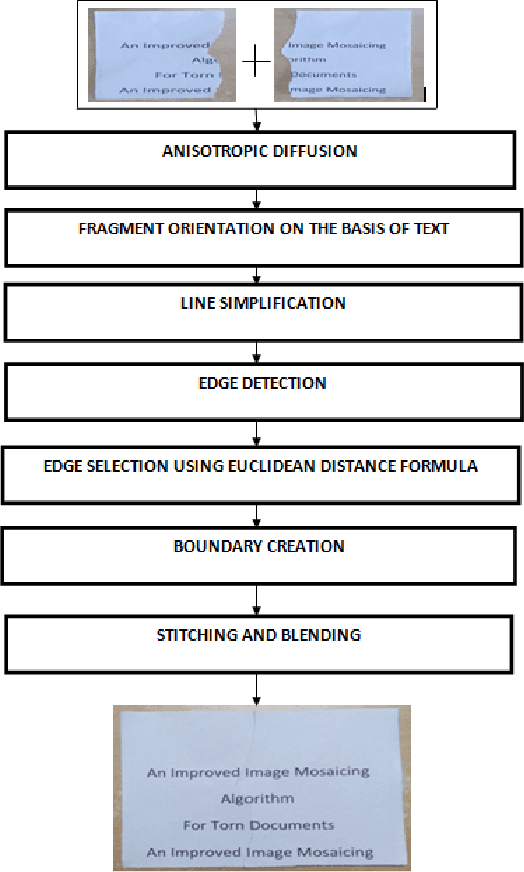
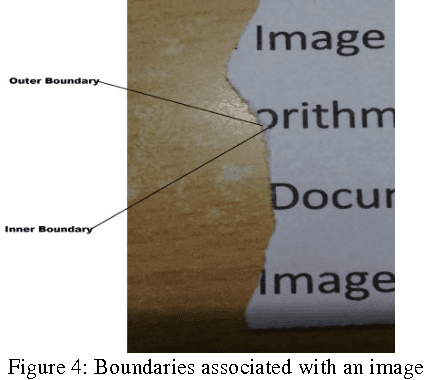
It is a common phenomenon in day to day life; where in some of the document gets damaged. Out of several reasons, the main reason for documents getting damaged is shredding by hands. Recovery of such documents is essential. Manual recovery of such damaged document is tedious and time consuming task. In this paper, we are describing an algorithm which recovers the original document from such shredded pieces of the same. In order to implement this, we are using a simple technique called Image Mosaicing. In this technique a complete new image is developed using two or more torn fragments. For simplicity of implementation, we are considering only two torn pieces of a document that will be mosaiced together. The successful implementation of this algorithm would lead to recovery of important information which in turn would be beneficial in various fields such as forensic sciences, archival study, etc
* 6 pages, 10 figures
Road Mapping in Low Data Environments with OpenStreetMap
Jun 14, 2020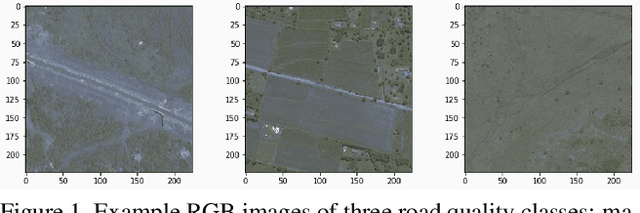
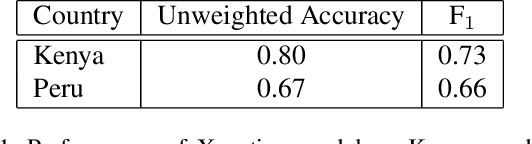
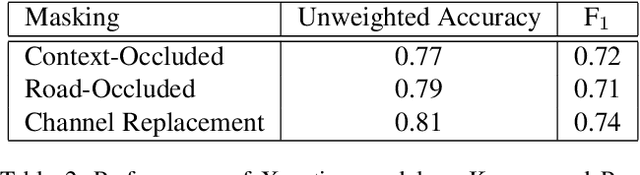
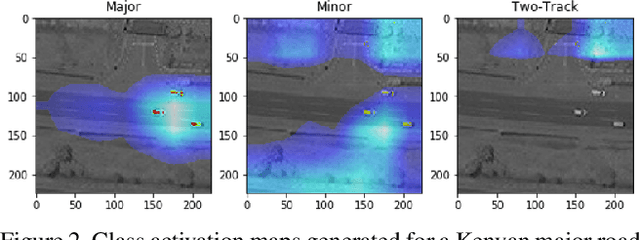
Roads are among the most essential components of any country's infrastructure. By facilitating the movement and exchange of people, ideas, and goods, they support economic and cultural activity both within and across local and international borders. A comprehensive, up-to-date mapping of the geographical distribution of roads and their quality thus has the potential to act as an indicator for broader economic development. Such an indicator has a variety of high-impact applications, particularly in the planning of rural development projects where up-to-date infrastructure information is not available. This work investigates the viability of high resolution satellite imagery and crowd-sourced resources like OpenStreetMap in the construction of such a mapping. We experiment with state-of-the-art deep learning methods to explore the utility of OpenStreetMap data in road classification and segmentation tasks. We also compare the performance of models in different mask occlusion scenarios as well as out-of-country domains. Our comparison raises important pitfalls to consider in image-based infrastructure classification tasks, and shows the need for local training data specific to regions of interest for reliable performance.
Geodesic-HOF: 3D Reconstruction Without Cutting Corners
Jun 14, 2020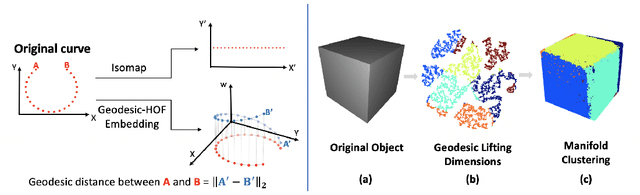
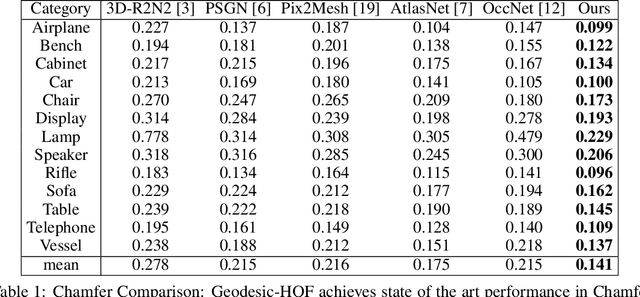
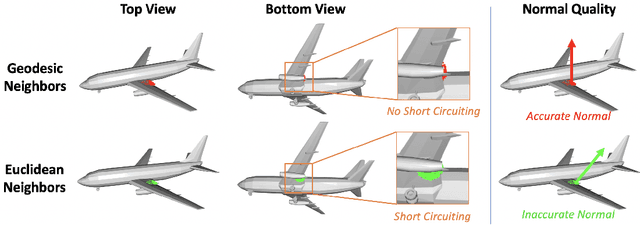
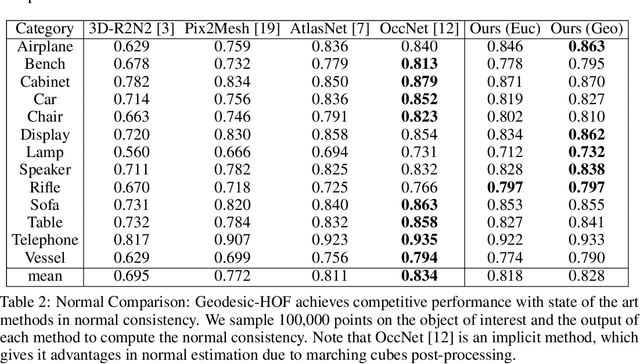
Single-view 3D object reconstruction is a challenging fundamental problem in computer vision, largely due to the morphological diversity of objects in the natural world. In particular, high curvature regions are not always captured effectively by methods trained using only set-based loss functions, resulting in reconstructions short-circuiting the surface or cutting corners. In particular, high curvature regions are not always captured effectively by methods trained using only set-based loss functions, resulting in reconstructions short-circuiting the surface or cutting corners. To address this issue, we propose learning an image-conditioned mapping function from a canonical sampling domain to a high dimensional space where the Euclidean distance is equal to the geodesic distance on the object. The first three dimensions of a mapped sample correspond to its 3D coordinates. The additional lifted components contain information about the underlying geodesic structure. Our results show that taking advantage of these learned lifted coordinates yields better performance for estimating surface normals and generating surfaces than using point cloud reconstructions alone. Further, we find that this learned geodesic embedding space provides useful information for applications such as unsupervised object decomposition.
Abdominal multi-organ segmentation with cascaded convolutional and adversarial deep networks
Jan 26, 2020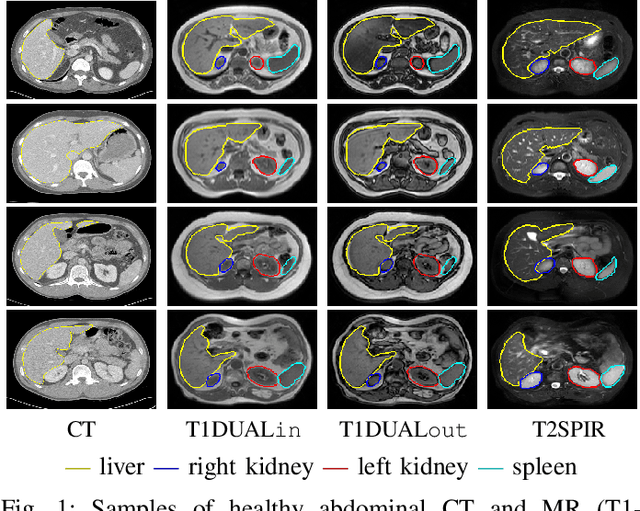
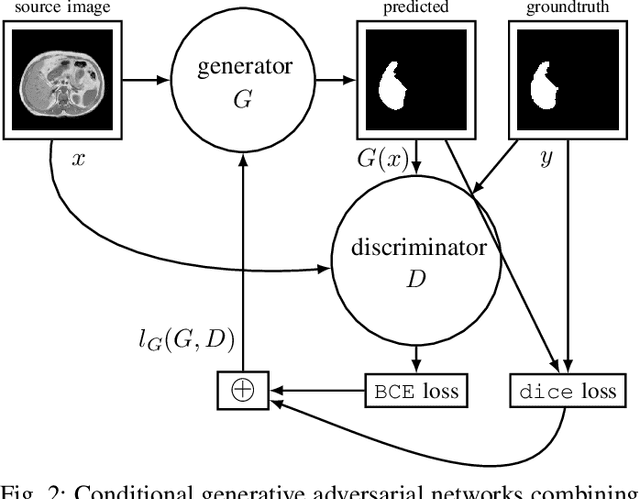
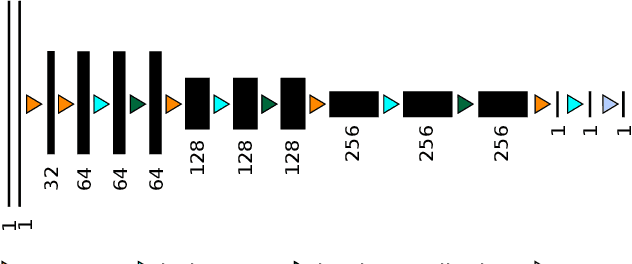
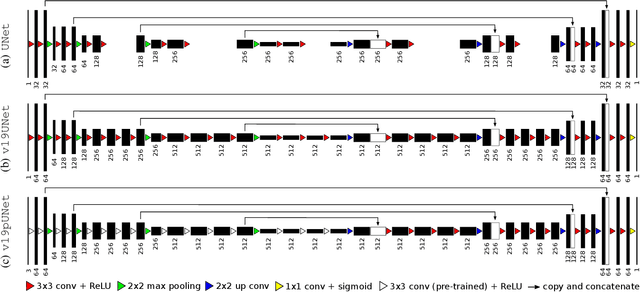
Objective : Abdominal anatomy segmentation is crucial for numerous applications from computer-assisted diagnosis to image-guided surgery. In this context, we address fully-automated multi-organ segmentation from abdominal CT and MR images using deep learning. Methods: The proposed model extends standard conditional generative adversarial networks. Additionally to the discriminator which enforces the model to create realistic organ delineations, it embeds cascaded partially pre-trained convolutional encoder-decoders as generator. Encoder fine-tuning from a large amount of non-medical images alleviates data scarcity limitations. The network is trained end-to-end to benefit from simultaneous multi-level segmentation refinements using auto-context. Results : Employed for healthy liver, kidneys and spleen segmentation, our pipeline provides promising results by outperforming state-of-the-art encoder-decoder schemes. Followed for the Combined Healthy Abdominal Organ Segmentation (CHAOS) challenge organized in conjunction with the IEEE International Symposium on Biomedical Imaging 2019, it gave us the first rank for three competition categories: liver CT, liver MR and multi-organ MR segmentation. Conclusion : Combining cascaded convolutional and adversarial networks strengthens the ability of deep learning pipelines to automatically delineate multiple abdominal organs, with good generalization capability. Significance : The comprehensive evaluation provided suggests that better guidance could be achieved to help clinicians in abdominal image interpretation and clinical decision making.
Feature Extraction for Hyperspectral Imagery: The Evolution from Shallow to Deep
Mar 06, 2020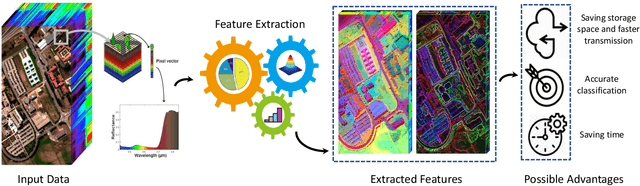
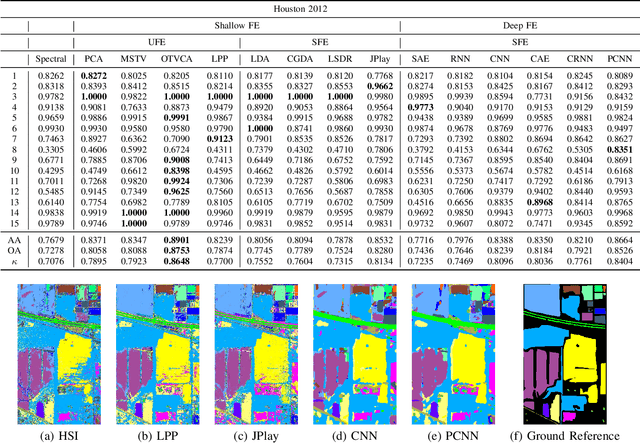
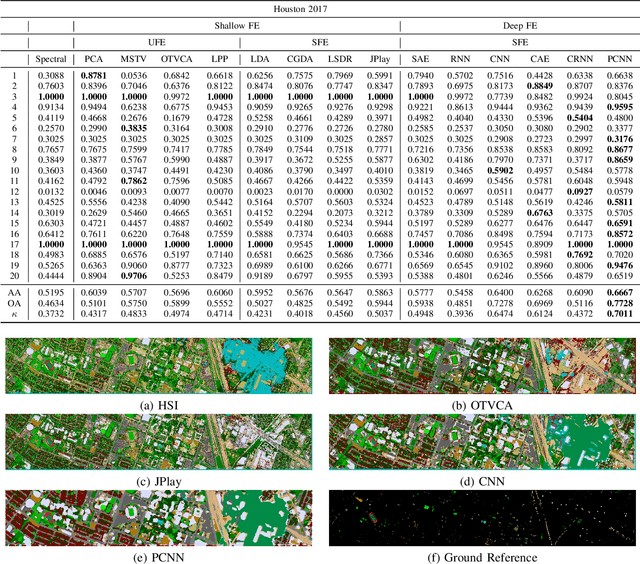

Hyperspectral images provide detailed spectral information through hundreds of (narrow) spectral channels (also known as dimensionality or bands) with continuous spectral information that can accurately classify diverse materials of interest. The increased dimensionality of such data makes it possible to significantly improve data information content but provides a challenge to the conventional techniques (the so-called curse of dimensionality) for accurate analysis of hyperspectral images. Feature extraction, as a vibrant field of research in the hyperspectral community, evolved through decades of research to address this issue and extract informative features suitable for data representation and classification. The advances in feature extraction have been inspired by two fields of research, including the popularization of image and signal processing as well as machine (deep) learning, leading to two types of feature extraction approaches named shallow and deep techniques. This article outlines the advances in feature extraction approaches for hyperspectral imagery by providing a technical overview of the state-of-the-art techniques, providing useful entry points for researchers at different levels, including students, researchers, and senior researchers, willing to explore novel investigations on this challenging topic. In more detail, this paper provides a bird's eye view over shallow (both supervised and unsupervised) and deep feature extraction approaches specifically dedicated to the topic of hyperspectral feature extraction and its application on hyperspectral image classification. Additionally, this paper compares 15 advanced techniques with an emphasis on their methodological foundations in terms of classification accuracies. Furthermore, the codes and libraries are shared at https://github.com/BehnoodRasti/HyFTech-Hyperspectral-Shallow-Deep-Feature-Extraction-Toolbox.
Deep Nearest Neighbor Anomaly Detection
Feb 24, 2020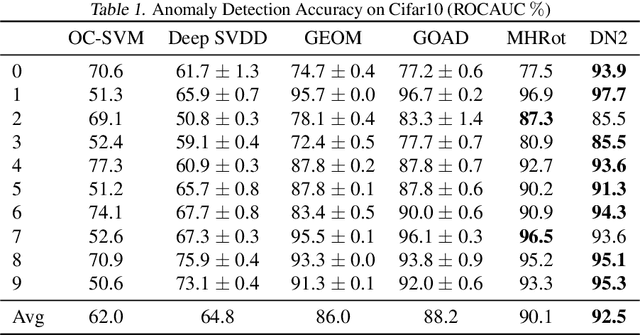
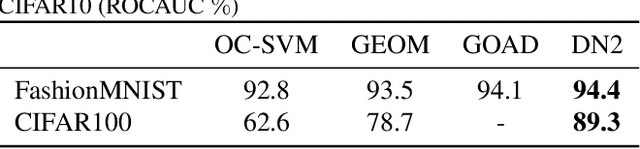
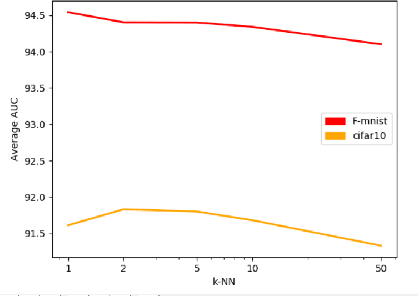
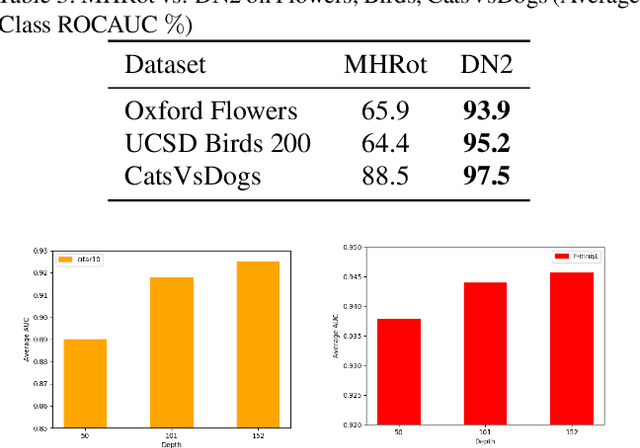
Nearest neighbors is a successful and long-standing technique for anomaly detection. Significant progress has been recently achieved by self-supervised deep methods (e.g. RotNet). Self-supervised features however typically under-perform Imagenet pre-trained features. In this work, we investigate whether the recent progress can indeed outperform nearest-neighbor methods operating on an Imagenet pretrained feature space. The simple nearest-neighbor based-approach is experimentally shown to outperform self-supervised methods in: accuracy, few shot generalization, training time and noise robustness while making fewer assumptions on image distributions.