 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An Online Platform for Automatic Skull Defect Restoration and Cranial Implant Design
Jun 01, 2020
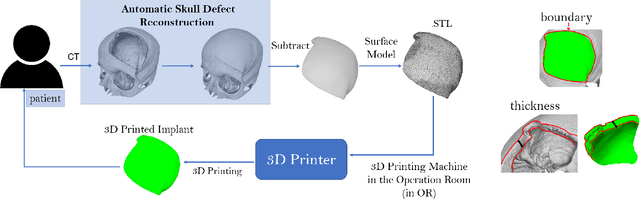
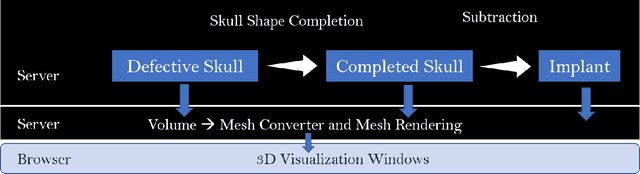
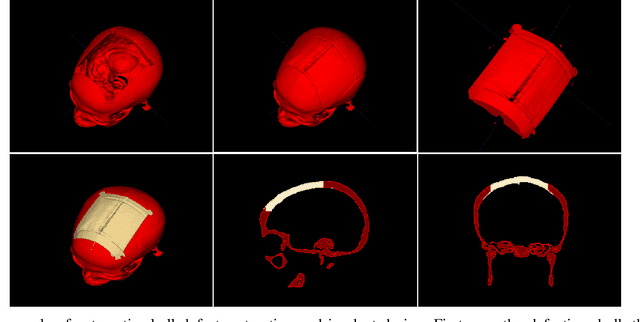
We introduce a fully automatic system for cranial implant design, a common task in cranioplasty operations. The system is currently integrated in Studierfenster (http://studierfenster.tugraz.at/), an online, cloud-based medical image processing platform for medical imaging applications. Enhanced by deep learning algorithms, the system automatically restores the missing part of a skull (i.e., skull shape completion) and generates the desired implant by subtracting the defective skull from the completed skull. The generated implant can be downloaded in the STereoLithography (.stl) format directly via the browser interface of the system. The implant model can then be sent to a 3D printer for in loco implant manufacturing. Furthermore, thanks to the standard format, the user can thereafter load the model into another application for post-processing whenever necessary. Such an automatic cranial implant design system can be integrated into the clinical practice to improve the current routine for surgeries related to skull defect repair (e.g., cranioplasty). Our system, although currently intended for educational and research use only, can be seen as an application of additive manufacturing for fast, patient-specific implant design.
DR-KFD: A Differentiable Visual Metric for 3D Shape Reconstruction
Nov 20, 2019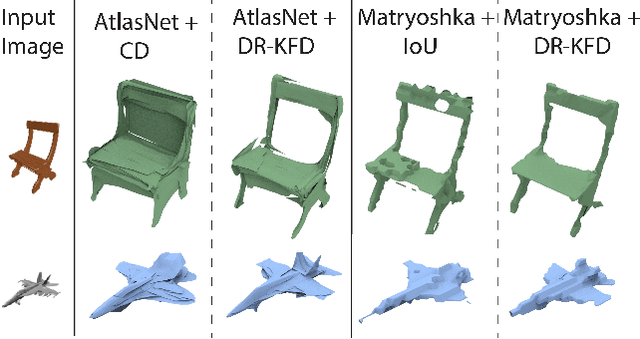
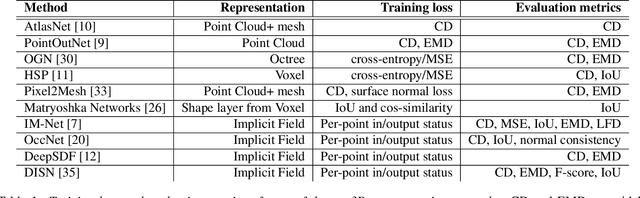
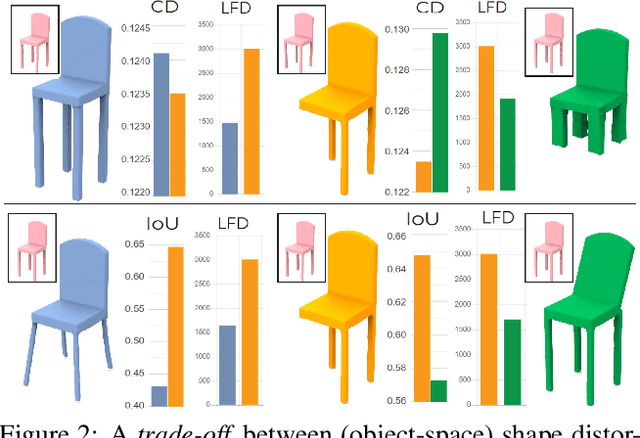
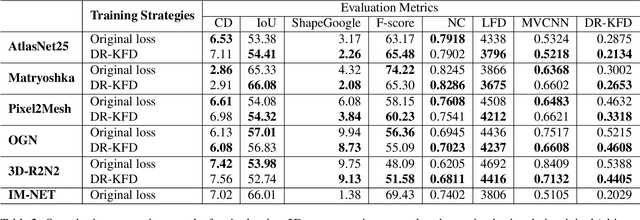
We advocate the use of differential visual shape metrics to train deep neural networks for 3D reconstruction. We introduce such a metric which compares two 3D shapes by measuring visual, image-space differences between multiview images differentiably rendered from the shapes. Furthermore, we develop a differentiable image-space distance based on mean-squared errors defined over Hard- Net features computed from probabilistic keypoint maps of the compared images. Our differential visual shape metric can be easily plugged into various reconstruction networks, replacing the object-space distortion measures, such as Chamfer or Earth Mover distances, so as to optimize the network weights to produce reconstruction results with better structural fidelity and visual quality. We demonstrate this both objectively, using well-known visual shape metrics for retrieval and classification tasks that are independent from our new metric, and subjectively through a perceptual study.
CheXbert: Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT
Apr 20, 2020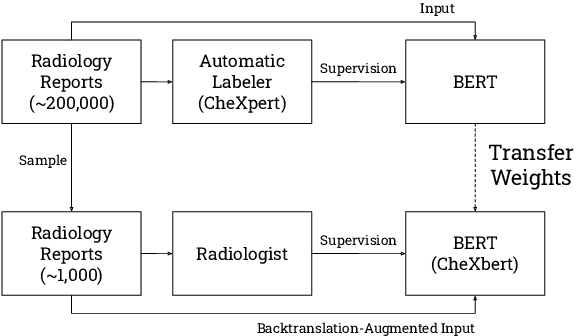
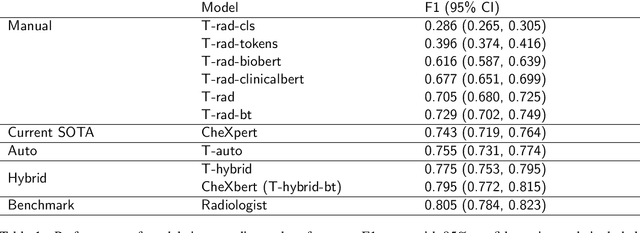
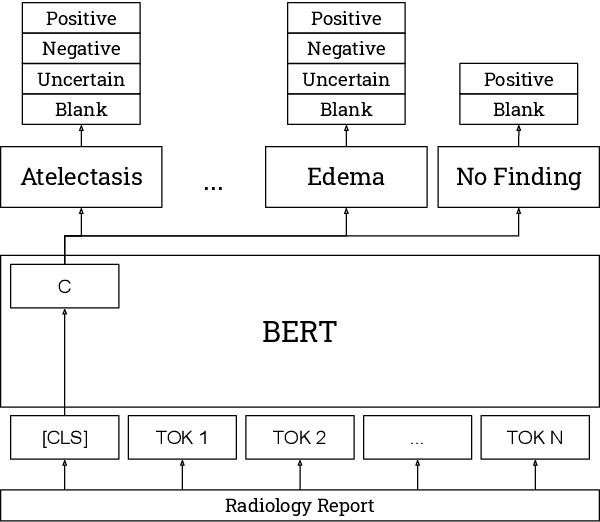
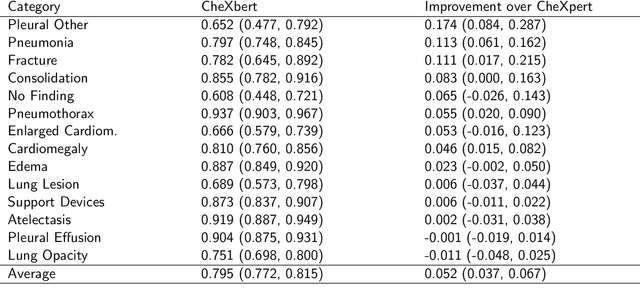
The extraction of labels from radiology text reports enables large-scale training of medical imaging models. Existing approaches to report labeling typically rely either on sophisticated feature engineering based on medical domain knowledge or manual annotations by experts. In this work, we investigate BERT-based approaches to medical image report labeling that exploit both the scale of available rule-based systems and the quality of expert annotations. We demonstrate superior performance of a BERT model first trained on annotations of a rule-based labeler and then finetuned on a small set of expert annotations augmented with automated backtranslation. We find that our final model, CheXbert, is able to outperform the previous best rules-based labeler with statistical significance, setting a new SOTA for report labeling on one of the largest datasets of chest x-rays.
Stochastic gradient descent with random learning rate
Apr 10, 2020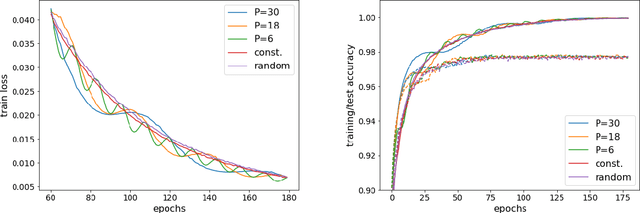
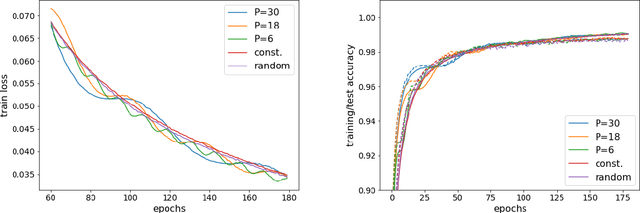
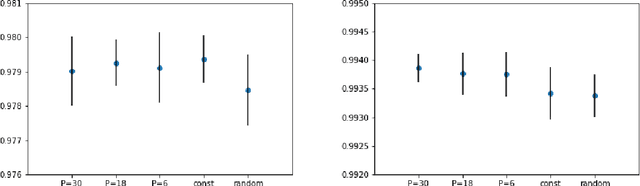
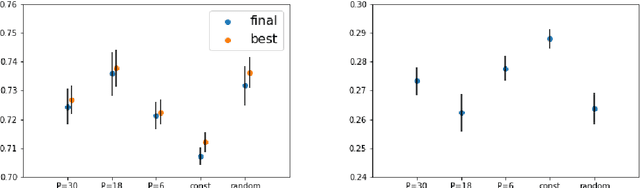
We propose to optimize neural networks with a uniformly-distributed random learning rate. The associated stochastic gradient descent algorithm can be approximated by continuous stochastic equations and analyzed with the Fokker-Planck formalism. In the small learning rate approximation, the training process is characterized by an effective temperature which depends on the average learning rate, the mini-batch size and the momentum of the optimization algorithm. By comparing the random learning rate protocol with cyclic and constant protocols, we suggest that the random choice is generically the best strategy in the small learning rate regime, yielding better regularization without extra computational cost. We provide supporting evidence through experiments on both shallow, fully-connected and deep, convolutional neural networks for image classification on the MNIST and CIFAR10 datasets.
FakeLocator: Robust Localization of GAN-Based Face Manipulations via Semantic Segmentation Networks with Bells and Whistles
Jan 27, 2020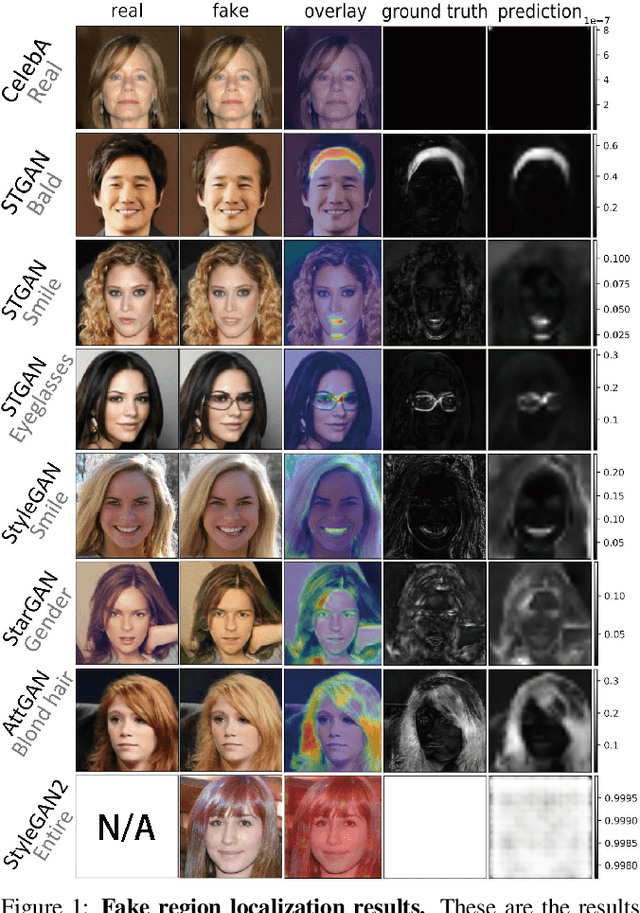
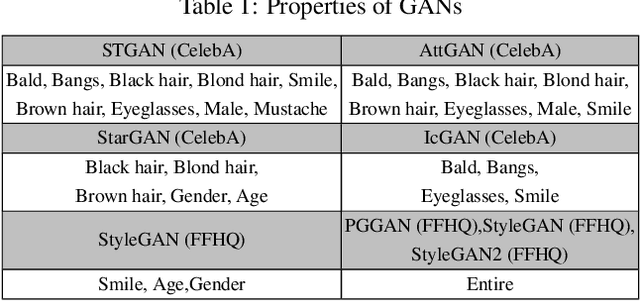
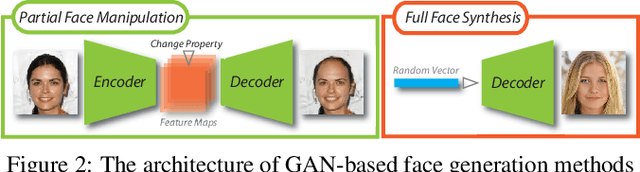
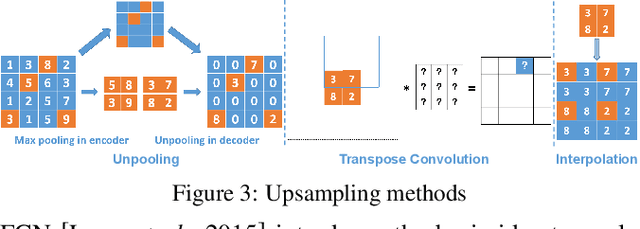
Nowadays, full face synthesis and partial face manipulation by virtue of the generative adversarial networks (GANs) have raised wide public concern. In the digital media forensics area, detecting and ultimately locating the image forgery have become imperative. Although many methods focus on fake detection, only a few put emphasis on the localization of the fake regions. Through analyzing the imperfection in the upsampling procedures of the GAN-based methods and recasting the fake localization problem as a modified semantic segmentation one, our proposed FakeLocator can obtain high localization accuracy, at full resolution, on manipulated facial images. To the best of our knowledge, this is the very first attempt to solve the GAN-based fake localization problem with a semantic segmentation map. As an improvement, the real-numbered segmentation map proposed by us preserves more information of fake regions. For this new type segmentation map, we also find suitable loss functions for it. Experimental results on the CelebA and FFHQ databases with seven different SOTA GAN-based face generation methods show the effectiveness of our method. Compared with the baseline, our method performs several times better on various metrics. Moreover, the proposed method is robust against various real-world facial image degradations such as JPEG compression, low-resolution, noise, and blur.
Multi-scale Cloud Detection in Remote Sensing Images using a Dual Convolutional Neural Network
Jun 01, 2020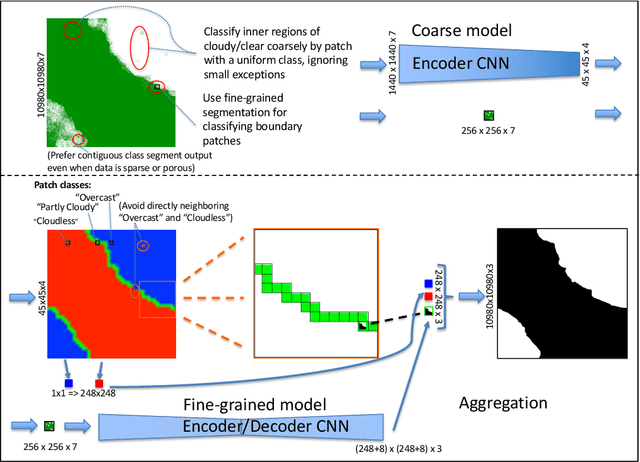
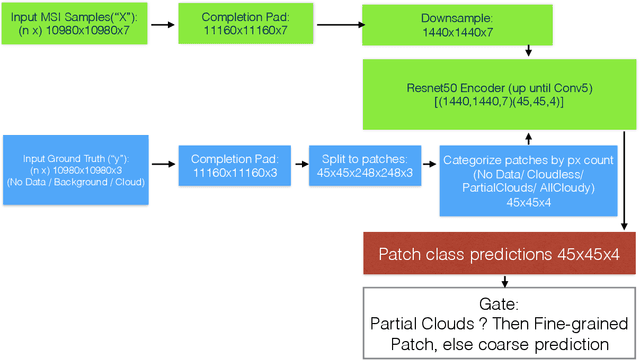
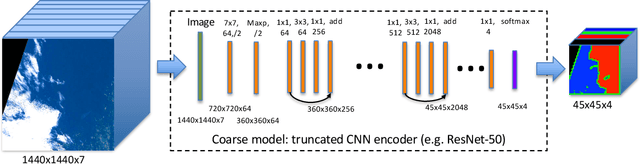
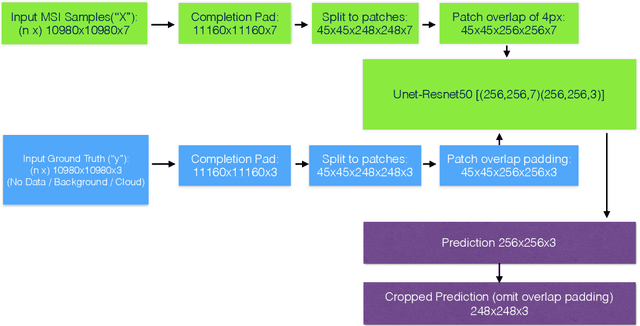
Semantic segmentation by convolutional neural networks (CNN) has advanced the state of the art in pixel-level classification of remote sensing images. However, processing large images typically requires analyzing the image in small patches, and hence features that have large spatial extent still cause challenges in tasks such as cloud masking. To support a wider scale of spatial features while simultaneously reducing computational requirements for large satellite images, we propose an architecture of two cascaded CNN model components successively processing undersampled and full resolution images. The first component distinguishes between patches in the inner cloud area from patches at the cloud's boundary region. For the cloud-ambiguous edge patches requiring further segmentation, the framework then delegates computation to a fine-grained model component. We apply the architecture to a cloud detection dataset of complete Sentinel-2 multispectral images, approximately annotated for minimal false negatives in a land use application. On this specific task and data, we achieve a 16\% relative improvement in pixel accuracy over a CNN baseline based on patching.
LANCE: Efficient Low-Precision Quantized Winograd Convolution for Neural Networks Based on Graphics Processing Units
Mar 20, 2020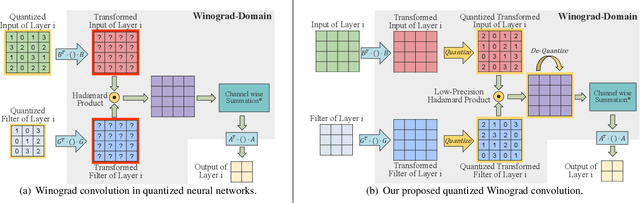
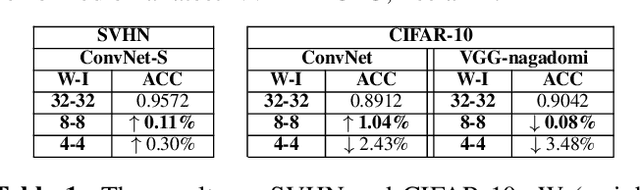
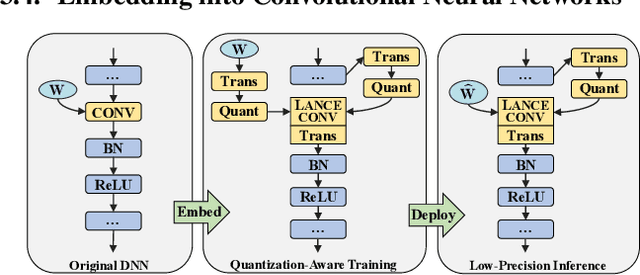

Accelerating deep convolutional neural networks has become an active topic and sparked an interest in academia and industry. In this paper, we propose an efficient low-precision quantized Winograd convolution algorithm, called LANCE, which combines the advantages of fast convolution and quantization techniques. By embedding linear quantization operations into the Winograd-domain, the fast convolution can be performed efficiently under low-precision computation on graphics processing units. We test neural network models with LANCE on representative image classification datasets, including SVHN, CIFAR, and ImageNet. The experimental results show that our 8-bit quantized Winograd convolution improves the performance by up to 2.40x over the full-precision convolution with trivial accuracy loss.
Mitigating Gender Bias in Captioning Systems
Jun 15, 2020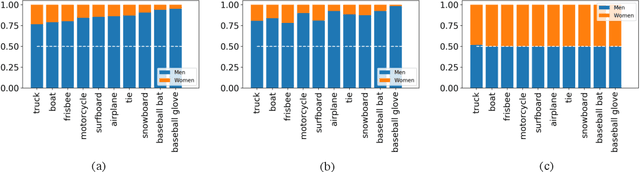
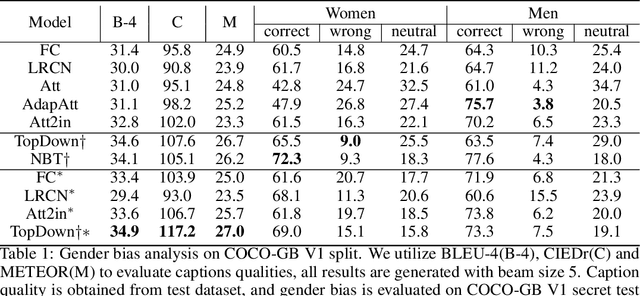
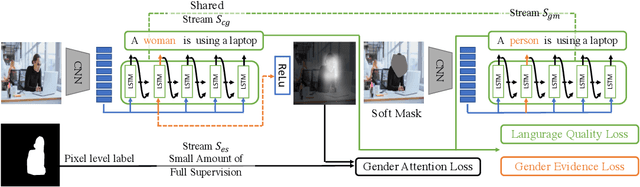
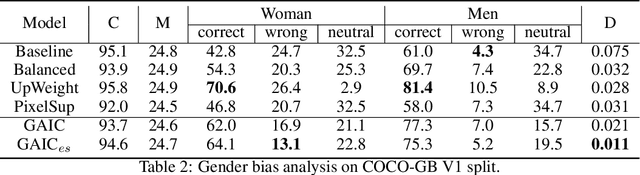
Recent studies have shown that captioning datasets, such as the COCO dataset, may contain severe social bias which could potentially lead to unintentional discrimination in learning models. In this work, we specifically focus on the gender bias problem. The existing dataset fails to quantify bias because models that intrinsically memorize gender bias from training data could still achieve a competitive performance on the biased test dataset. To bridge the gap, we create two new splits: COCO-GB v1 and v2 to quantify the inherent gender bias which could be learned by models. Several widely used baselines are evaluated on our new settings, and experimental results indicate that most models learn gender bias from the training data, leading to an undesirable gender prediction error towards women. To overcome the unwanted bias, we propose a novel Guided Attention Image Captioning model (GAIC) which provides self-guidance on visual attention to encourage the model to explore correct gender visual evidence. Experimental results validate that GAIC can significantly reduce gender prediction error, with a competitive caption quality. Our codes and the designed benchmark datasets are available at https://github.com/CaptionGenderBias2020.
RTOP: A Conceptual and Computational Framework for General Intelligence
Oct 23, 2019



A novel general intelligence model is proposed with three types of learning. A unified sequence of the foreground percept trace and the command trace translates into direct and time-hop observation paths to form the basis of Raw learning. Raw learning includes the formation of image-image associations, which lead to the perception of temporal and spatial relationships among objects and object parts; and the formation of image-audio associations, which serve as the building blocks of language. Offline identification of similar segments in the observation paths and their subsequent reduction into a common segment through merging of memory nodes leads to Generalized learning. Generalization includes the formation of interpolated sensory nodes for robust and generic matching, the formation of sensory properties nodes for specific matching and superimposition, and the formation of group nodes for simpler logic pathways. Online superimposition of memory nodes across multiple predictions, primarily the superimposition of images on the internal projection canvas, gives rise to Innovative learning and thought. The learning of actions happens the same way as raw learning while the action determination happens through the utility model built into the raw learnings, the utility function being the pleasure and pain of the physical senses.
Five Modulus Method For Image Compression
Nov 19, 2012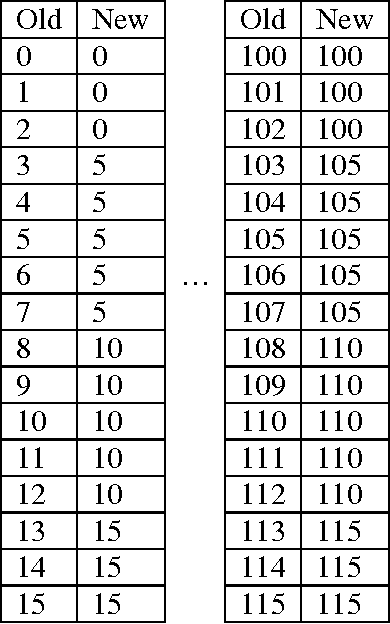
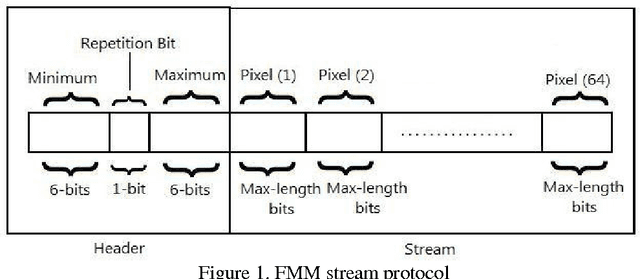
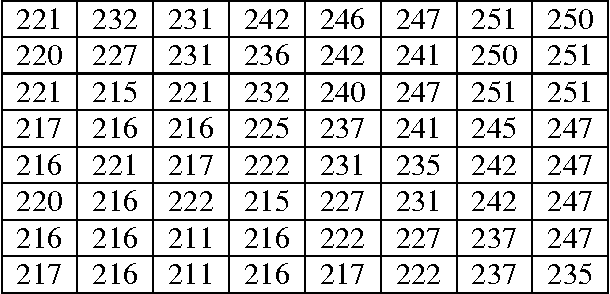

Data is compressed by reducing its redundancy, but this also makes the data less reliable, more prone to errors. In this paper a novel approach of image compression based on a new method that has been created for image compression which is called Five Modulus Method (FMM). The new method consists of converting each pixel value in an 8-by-8 block into a multiple of 5 for each of the R, G and B arrays. After that, the new values could be divided by 5 to get new values which are 6-bit length for each pixel and it is less in storage space than the original value which is 8-bits. Also, a new protocol for compression of the new values as a stream of bits has been presented that gives the opportunity to store and transfer the new compressed image easily.
* 10 pages, 2 figures, 9 tables