 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Novel Distributed Approximate Nearest Neighbor Method for Real-time Face Recognition
May 12, 2020
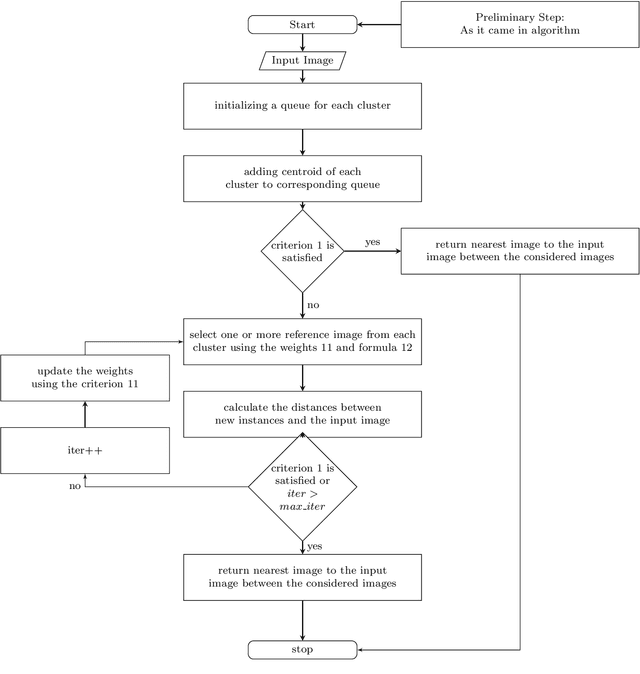

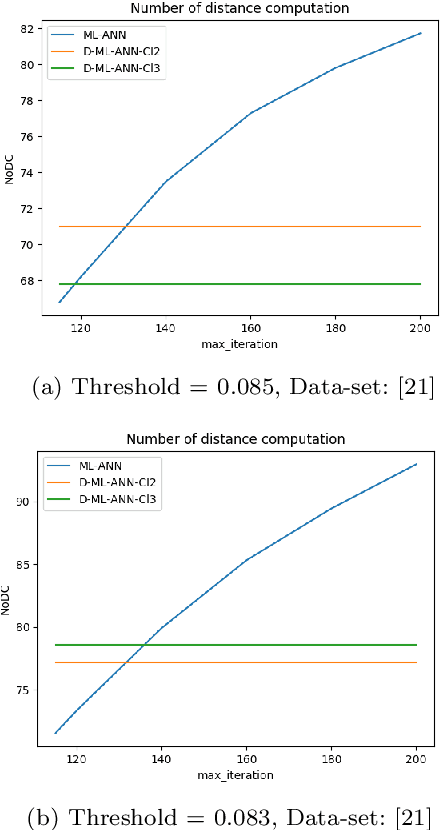
Nowadays face recognition and more generally, image recognition have many applications in the modern world and are widely used in our daily tasks. In this paper, we propose a novel distributed approximate nearest neighbor (ANN) method for real-time face recognition with a big data-set that involves a lot of classes. The proposed approach is based on using a clustering method to separate the data-set into different clusters, and specifying the importance of each cluster by defining cluster weights. Reference instances are selected from each cluster based on the cluster weights and by using a maximum likelihood approach. This process leads to a more informed selection of instances, and so enhances the performance of the algorithm. Experimental results confirm the efficiency of the proposed method and its out-performance in terms of accuracy and processing time.
A cascaded dual-domain deep learning reconstruction method for sparsely spaced multidetector helical CT
Oct 23, 2019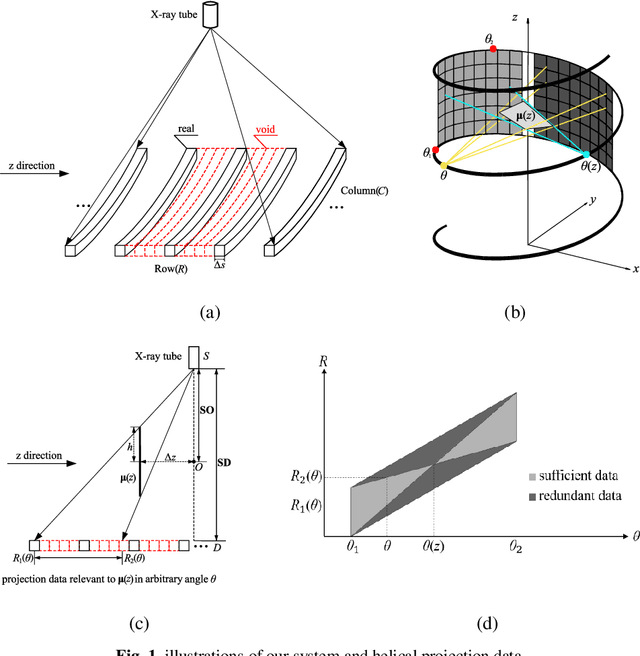

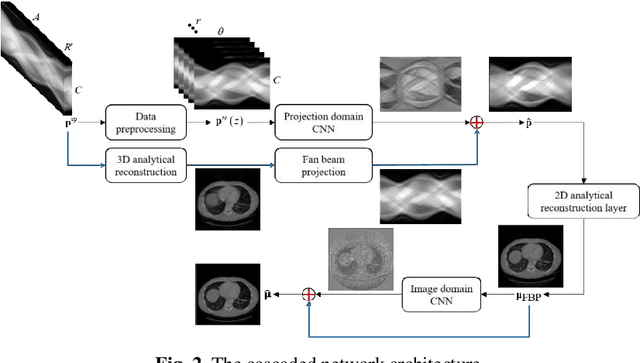
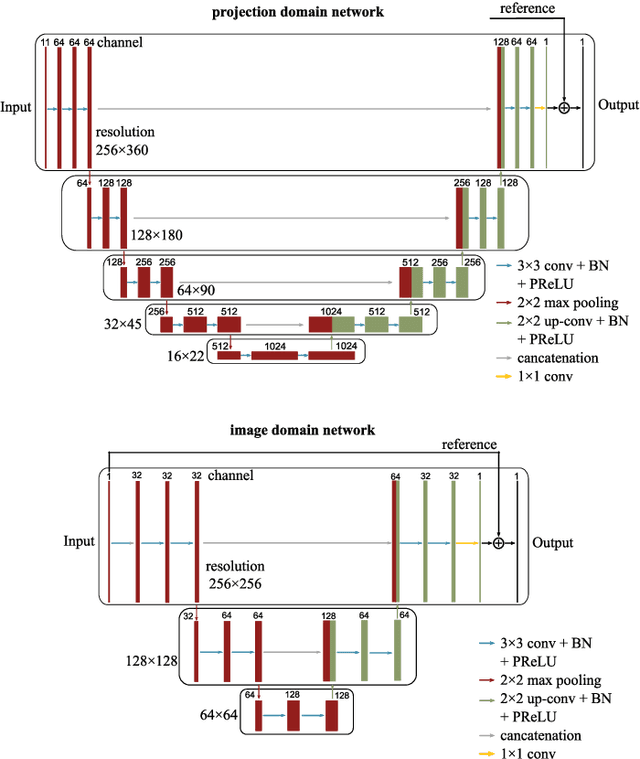
Helical CT has been widely used in clinical diagnosis. Sparsely spaced multidetector in z direction can increase the coverage of the detector provided limited detector rows. It can speed up volumetric CT scan, lower the radiation dose and reduce motion artifacts. However, it leads to insufficient data for reconstruction. That means reconstructions from general analytical methods will have severe artifacts. Iterative reconstruction methods might be able to deal with this situation but with the cost of huge computational load. In this work, we propose a cascaded dual-domain deep learning method that completes both data transformation in projection domain and error reduction in image domain. First, a convolutional neural network (CNN) in projection domain is constructed to estimate missing helical projection data and converting helical projection data to 2D fan-beam projection data. This step is to suppress helical artifacts and reduce the following computational cost. Then, an analytical linear operator is followed to transfer the data from projection domain to image domain. Finally, an image domain CNN is added to improve image quality further. These three steps work as an entirety and can be trained end to end. The overall network is trained using a simulated lung CT dataset with Poisson noise from 25 patients. We evaluate the trained network on another three patients and obtain very encouraging results with both visual examination and quantitative comparison. The resulting RRMSE is 6.56% and the SSIM is 99.60%. In addition, we test the trained network on the lung CT dataset with different noise level and a new dental CT dataset to demonstrate the generalization and robustness of our method.
AIM 2019 Challenge on Constrained Super-Resolution: Methods and Results
Nov 04, 2019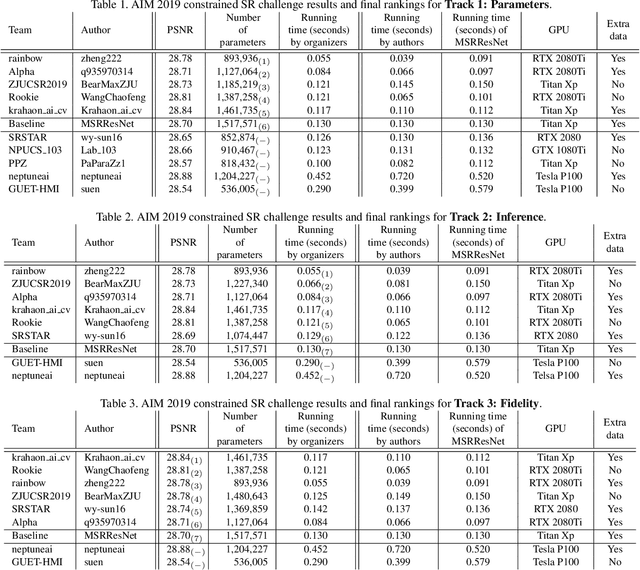
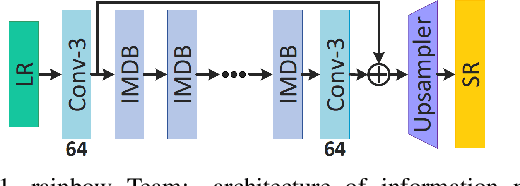
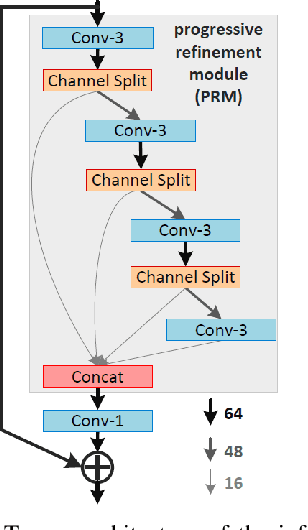
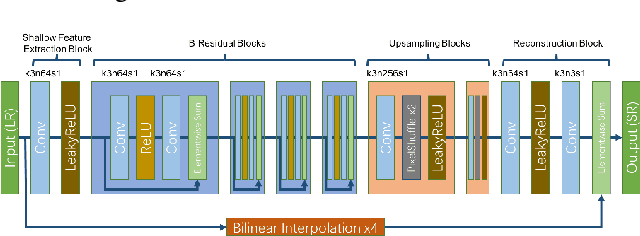
This paper reviews the AIM 2019 challenge on constrained example-based single image super-resolution with focus on proposed solutions and results. The challenge had 3 tracks. Taking the three main aspects (i.e., number of parameters, inference/running time, fidelity (PSNR)) of MSRResNet as the baseline, Track 1 aims to reduce the amount of parameters while being constrained to maintain or improve the running time and the PSNR result, Tracks 2 and 3 aim to optimize running time and PSNR result with constrain of the other two aspects, respectively. Each track had an average of 64 registered participants, and 12 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
Tunnel Surface 3D Reconstruction from Unoriented Image Sequences
May 22, 2015
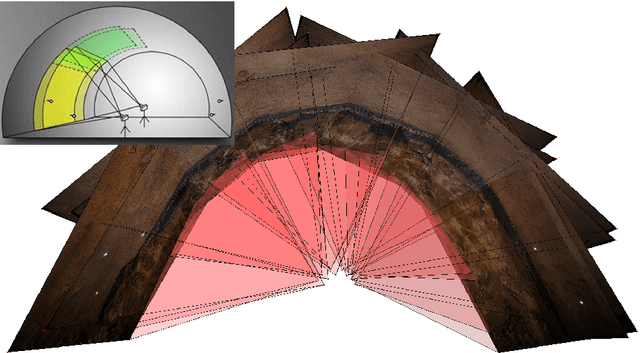
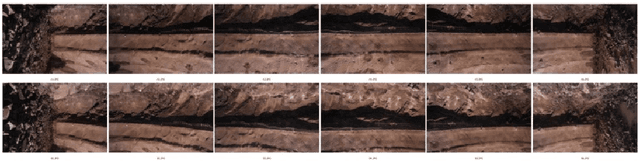
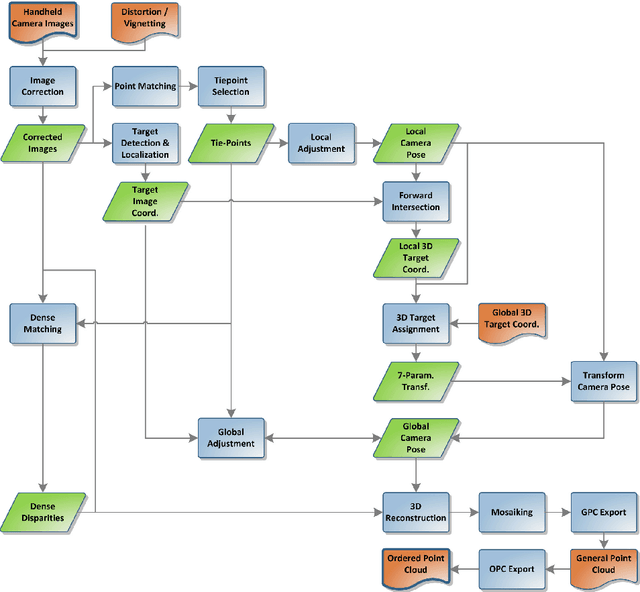
The 3D documentation of the tunnel surface during construction requires fast and robust measurement systems. In the solution proposed in this paper, during tunnel advance a single camera is taking pictures of the tunnel surface from several positions. The recorded images are automatically processed to gain a 3D tunnel surface model. Image acquisition is realized by the tunneling/advance/driving personnel close to the tunnel face (= the front end of the advance). Based on the following fully automatic analysis/evaluation, a decision on the quality of the outbreak can be made within a few minutes. This paper describes the image recording system and conditions as well as the stereo-photogrammetry based workflow for the continuously merged dense 3D reconstruction of the entire advance region. Geo-reference is realized by means of signalized targets that are automatically detected in the images. We report on the results of recent testing under real construction conditions, and conclude with prospects for further development in terms of on-site performance.
Automated Stitching of Coral Reef Images and Extraction of Features for Damselfish Shoaling Behavior Analysis
Jun 28, 2020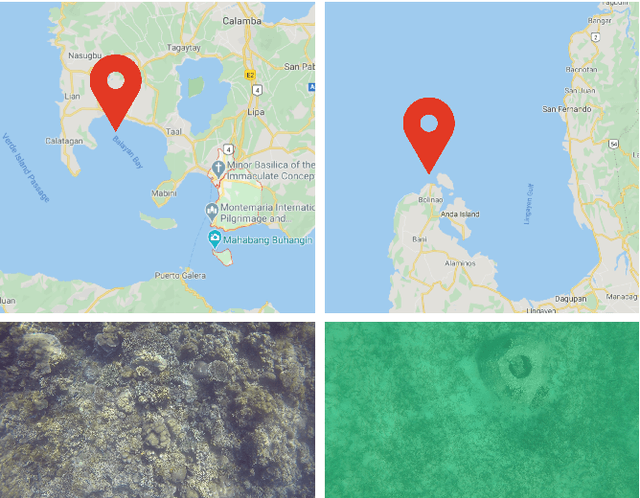
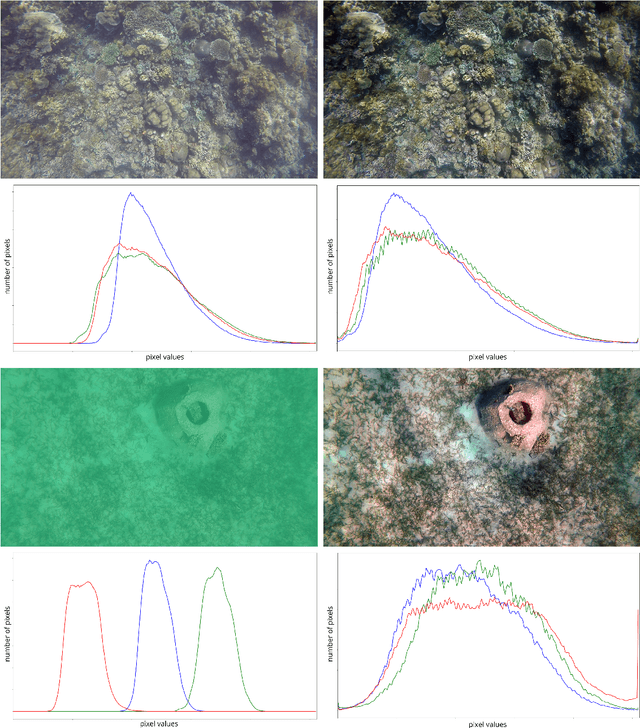


Behavior analysis of animals involves the observation of intraspecific and interspecific interactions among various organisms in the environment. Collective behavior such as herding in farm animals, flocking of birds, and shoaling and schooling of fish provide information on its benefits on collective survival, fitness, reproductive patterns, group decision-making, and effects in animal epidemiology. In marine ethology, the investigation of behavioral patterns in schooling species can provide supplemental information in the planning and management of marine resources. Currently, damselfish species, although prevalent in tropical waters, have no adequate established base behavior information. This limits reef managers in efficiently planning for stress and disaster responses in protecting the reef. Visual marine data captured in the wild are scarce and prone to multiple scene variations, primarily caused by motion and changes in the natural environment. The gathered videos of damselfish by this research exhibit several scene distortions caused by erratic camera motions during acquisition. To effectively analyze shoaling behavior given the issues posed by capturing data in the wild, we propose a pre-processing system that utilizes color correction and image stitching techniques and extracts behavior features for manual analysis.
TorchIO: a Python library for efficient loading, preprocessing, augmentation and patch-based sampling of medical images in deep learning
Mar 09, 2020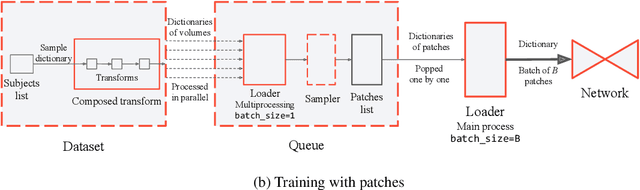
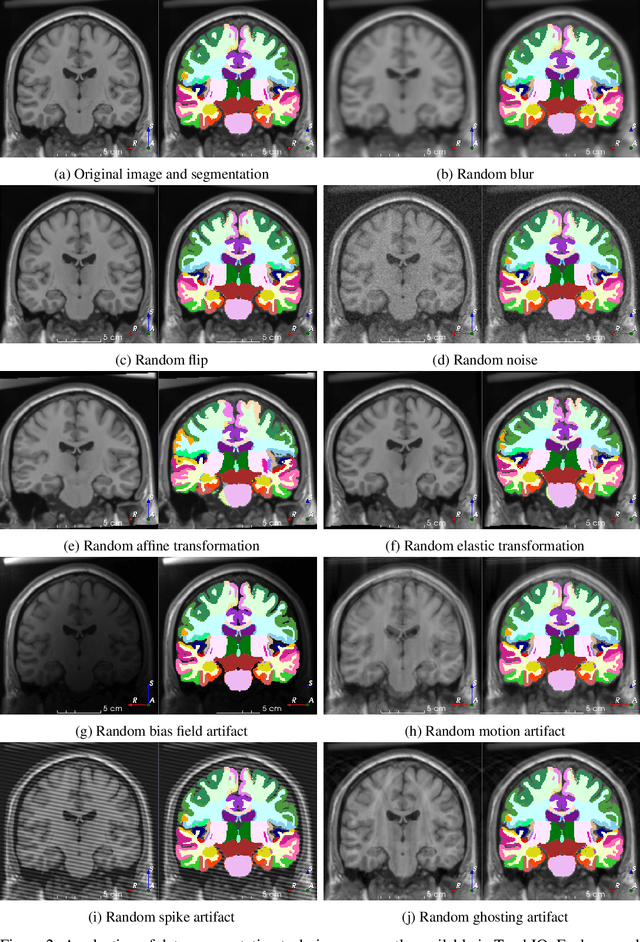
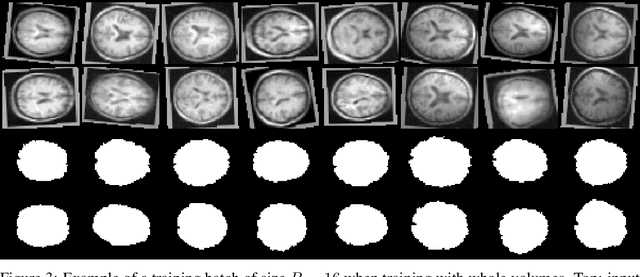
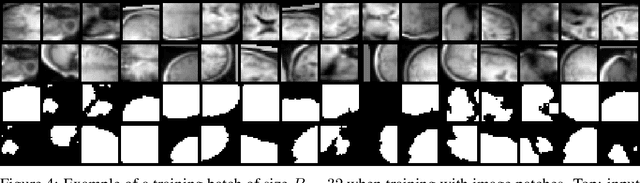
We present TorchIO, an open-source Python library for efficient loading, preprocessing, augmentation and patch-based sampling of medical images for deep learning. It follows the design of PyTorch and relies on standard medical image processing libraries such as SimpleITK or NiBabel to efficiently process large 3D images during the training of convolutional neural networks. We provide multiple generic as well as magnetic-resonance-imaging-specific operations for preprocessing and augmentation of medical images. TorchIO is an open-source project with code, comprehensive examples and extensive documentation shared at https://github.com/fepegar/torchio.
Object Detection under Rainy Conditions for Autonomous Vehicles
Jul 10, 2020

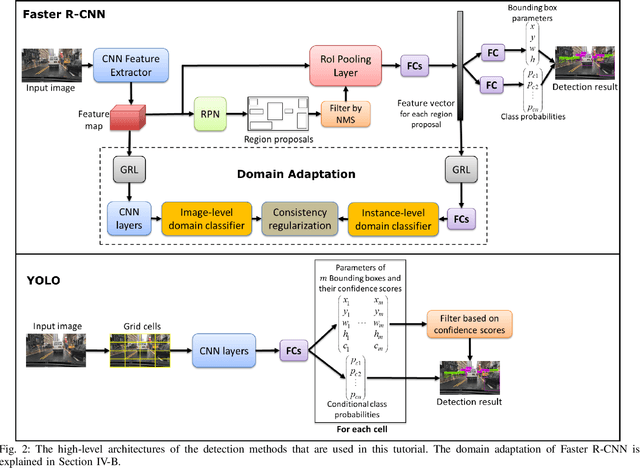

Advanced automotive active-safety systems, in general, and autonomous vehicles, in particular, rely heavily on visual data to classify and localize objects such as pedestrians, traffic signs and lights, and other nearby cars, to assist the corresponding vehicles maneuver safely in their environments. However, the performance of object detection methods could degrade rather significantly under challenging weather scenarios including rainy conditions. Despite major advancements in the development of deraining approaches, the impact of rain on object detection has largely been understudied, especially in the context of autonomous driving. The main objective of this paper is to present a tutorial on state-of-the-art and emerging techniques that represent leading candidates for mitigating the influence of rainy conditions on an autonomous vehicle's ability to detect objects. Our goal includes surveying and analyzing the performance of object detection methods trained and tested using visual data captured under clear and rainy conditions. Moreover, we survey and evaluate the efficacy and limitations of leading deraining approaches, deep-learning based domain adaptation, and image translation frameworks that are being considered for addressing the problem of object detection under rainy conditions. Experimental results of a variety of the surveyed techniques are presented as part of this tutorial.
Sperm detection and tracking in phase-contrast microscopy image sequences using deep learning and modified CSR-DCF
Feb 11, 2020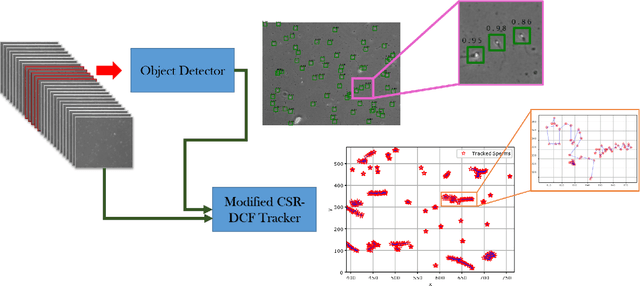
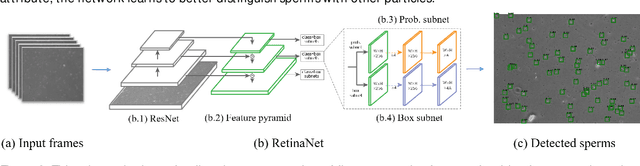
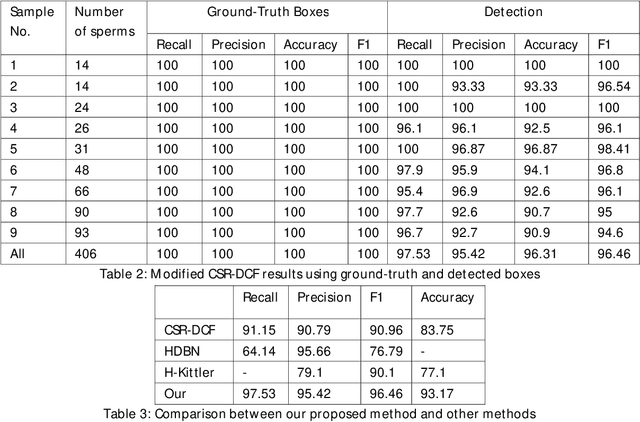
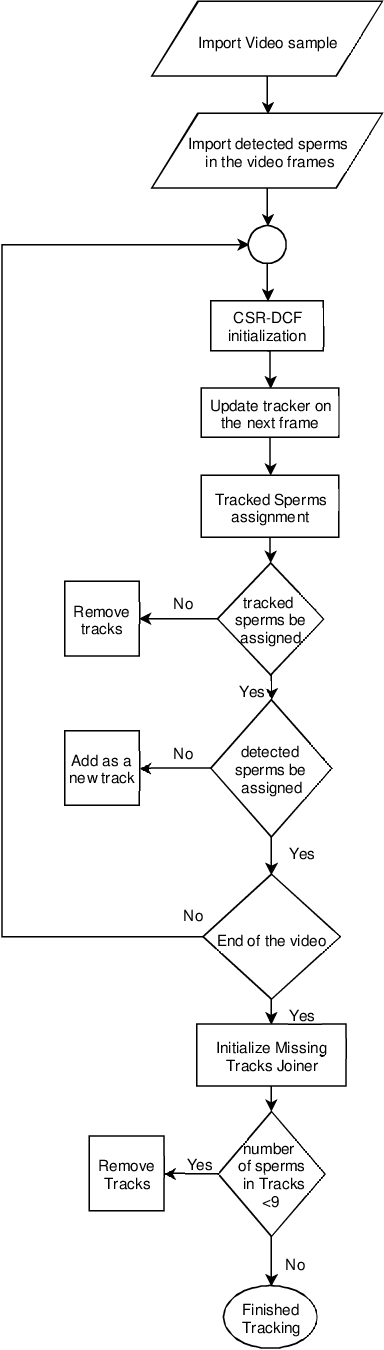
Nowadays, computer-aided sperm analysis (CASA) systems have made a big leap in extracting the characteristics of spermatozoa for studies or measuring human fertility. The first step in sperm characteristics analysis is sperm detection in the frames of the video sample. In this article, we used a deep fully convolutional network, as the object detector. Sperms are small objects with few attributes, that makes the detection more difficult in high-density samples and especially when there are other particles in semen, which could be like sperm heads. One of the main attributes of sperms is their movement, but this attribute cannot be extracted when only one frame would be fed to the network. To improve the performance of the sperm detection network, we concatenated some consecutive frames to use as the input of the network. With this method, the motility attribute has also been extracted, and then with the help of deep convolutional layers, we have achieved high accuracy in sperm detection. In the tracking phase, we modify the CSR-DCF algorithm. This method also has shown excellent results in sperm tracking even in high-density sperm samples, occlusions, sperm colliding, and when sperms exit from a frame and re-enter in the next frames. The average precision of the detection phase is 99.1%, and the F1 score of the tracking method evaluation is 97.06%. These results can be a great help in studies investigating sperm behavior and analyzing fertility possibility.
Detecting CNN-Generated Facial Images in Real-World Scenarios
May 12, 2020
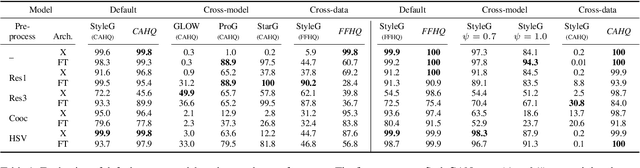
Artificial, CNN-generated images are now of such high quality that humans have trouble distinguishing them from real images. Several algorithmic detection methods have been proposed, but these appear to generalize poorly to data from unknown sources, making them infeasible for real-world scenarios. In this work, we present a framework for evaluating detection methods under real-world conditions, consisting of cross-model, cross-data, and post-processing evaluation, and we evaluate state-of-the-art detection methods using the proposed framework. Furthermore, we examine the usefulness of commonly used image pre-processing methods. Lastly, we evaluate human performance on detecting CNN-generated images, along with factors that influence this performance, by conducting an online survey. Our results suggest that CNN-based detection methods are not yet robust enough to be used in real-world scenarios.
Training Auto-encoder-based Optimizers for Terahertz Image Reconstruction
Jul 02, 2019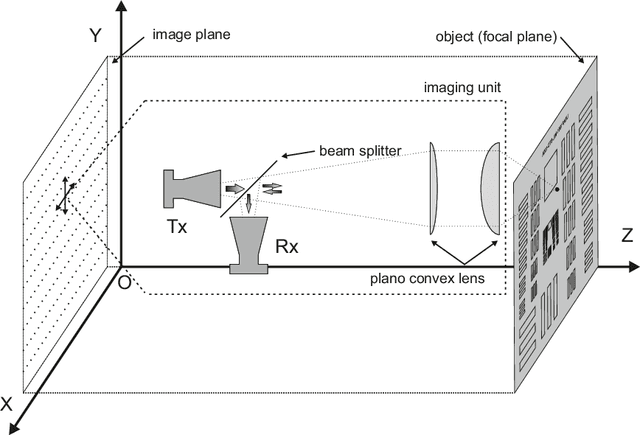
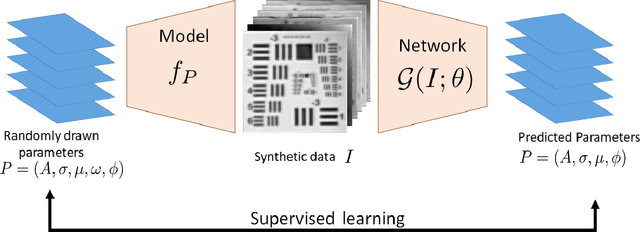
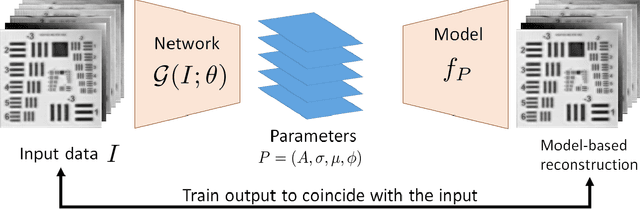
Terahertz (THz) sensing is a promising imaging technology for a wide variety of different applications. Extracting the interpretable and physically meaningful parameters for such applications, however, requires solving an inverse problem in which a model function determined by these parameters needs to be fitted to the measured data. Since the underlying optimization problem is nonconvex and very costly to solve, we propose learning the prediction of suitable parameters from the measured data directly. More precisely, we develop a model-based autoencoder in which the encoder network predicts suitable parameters and the decoder is fixed to a physically meaningful model function, such that we can train the encoding network in an unsupervised way. We illustrate numerically that the resulting network is more than 140 times faster than classical optimization techniques while making predictions with only slightly higher objective values. Using such predictions as starting points of local optimization techniques allows us to converge to better local minima about twice as fast as optimization without the network-based initialization.