 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Compressive Classification Framework for High-Dimensional Data
May 09, 2020
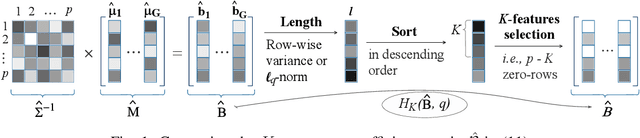
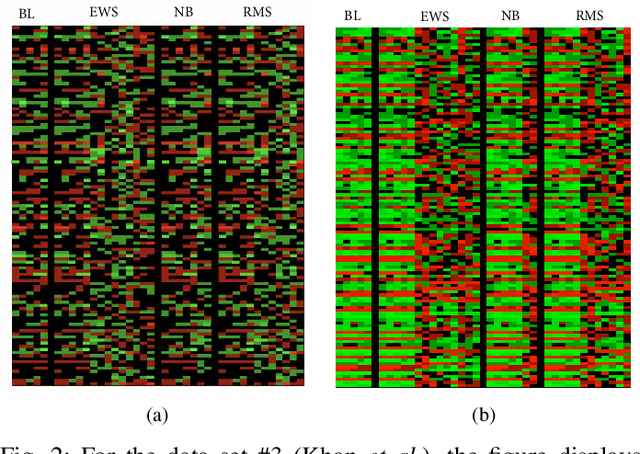
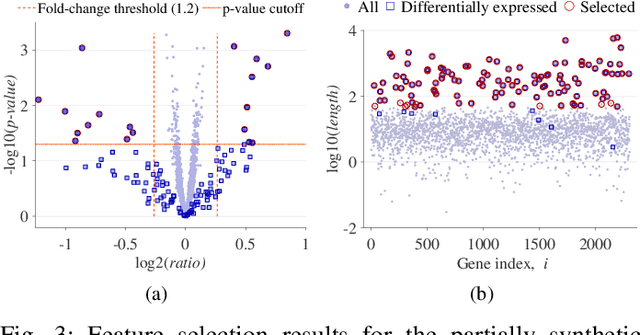
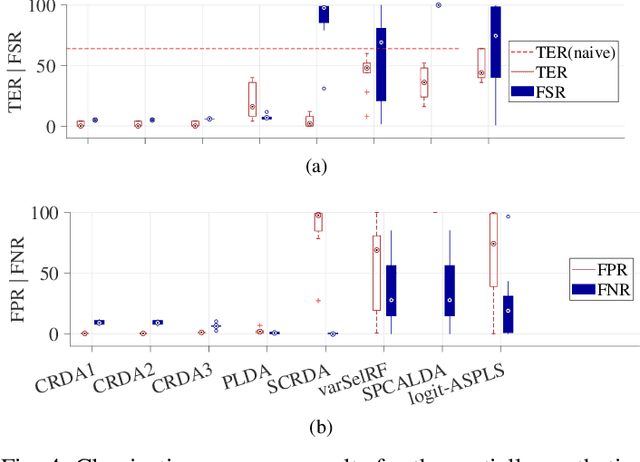
We propose a compressive classification framework for settings where the data dimensionality is significantly higher than the sample size. The proposed method, referred to as compressive regularized discriminant analysis (CRDA) is based on linear discriminant analysis and has the ability to select significant features by using joint-sparsity promoting hard thresholding in the discriminant rule. Since the number of features is larger than the sample size, the method also uses state-of-the-art regularized sample covariance matrix estimators. Several analysis examples on real data sets, including image, speech signal and gene expression data illustrate the promising improvements offered by the proposed CRDA classifier in practise. Overall, the proposed method gives fewer misclassification errors than its competitors, while at the same time achieving accurate feature selection results. The open-source R package and MATLAB toolbox of the proposed method (named compressiveRDA) is freely available.
Unsupervised Learning of Video Representations via Dense Trajectory Clustering
Jun 28, 2020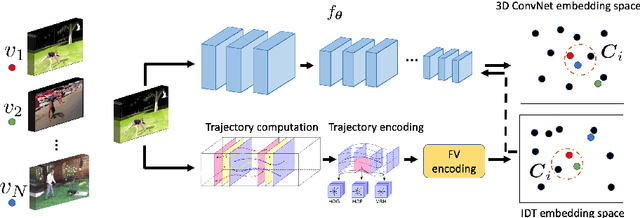
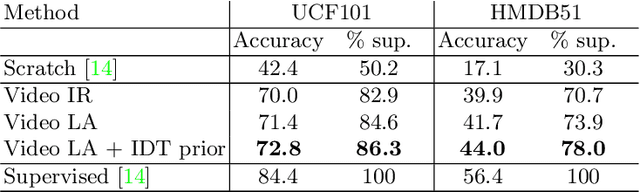
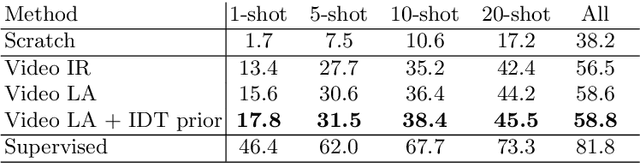

This paper addresses the task of unsupervised learning of representations for action recognition in videos. Previous works proposed to utilize future prediction, or other domain-specific objectives to train a network, but achieved only limited success. In contrast, in the relevant field of image representation learning, simpler, discrimination-based methods have recently bridged the gap to fully-supervised performance. We first propose to adapt two top performing objectives in this class - instance recognition and local aggregation, to the video domain. In particular, the latter approach iterates between clustering the videos in the feature space of a network and updating it to respect the cluster with a non-parametric classification loss. We observe promising performance, but qualitative analysis shows that the learned representations fail to capture motion patterns, grouping the videos based on appearance. To mitigate this issue, we turn to the heuristic-based IDT descriptors, that were manually designed to encode motion patterns in videos. We form the clusters in the IDT space, using these descriptors as a an unsupervised prior in the iterative local aggregation algorithm. Our experiments demonstrates that this approach outperform prior work on UCF101 and HMDB51 action recognition benchmarks. We also qualitatively analyze the learned representations and show that they successfully capture video dynamics.
An Investigation of Why Overparameterization Exacerbates Spurious Correlations
May 09, 2020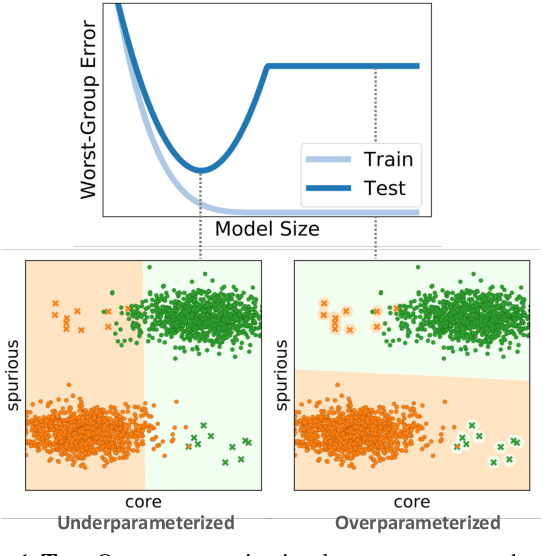
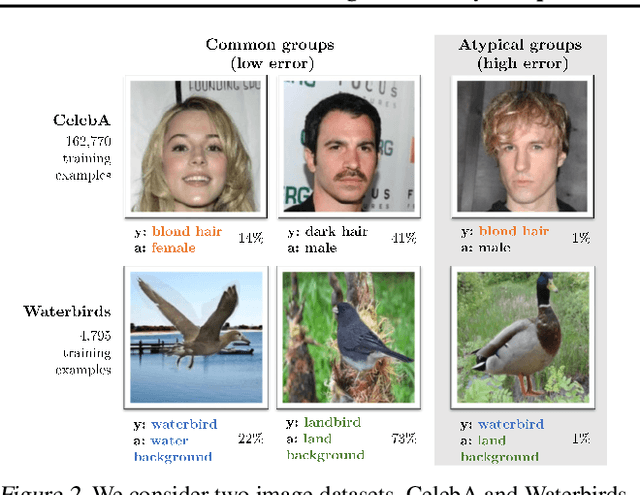
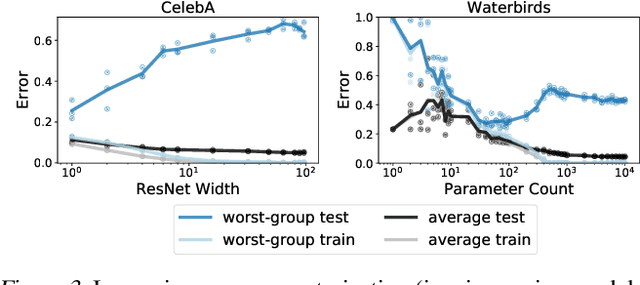
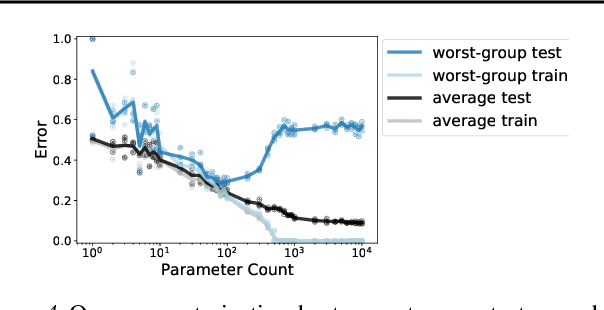
We study why overparameterization -- increasing model size well beyond the point of zero training error -- can hurt test error on minority groups despite improving average test error when there are spurious correlations in the data. Through simulations and experiments on two image datasets, we identify two key properties of the training data that drive this behavior: the proportions of majority versus minority groups, and the signal-to-noise ratio of the spurious correlations. We then analyze a linear setting and show theoretically how the inductive bias of models towards "memorizing" fewer examples can cause overparameterization to hurt. Our analysis leads to a counterintuitive approach of subsampling the majority group, which empirically achieves low minority error in the overparameterized regime, even though the standard approach of upweighting the minority fails. Overall, our results suggest a tension between using overparameterized models versus using all the training data for achieving low worst-group error.
A Triangular Network For Density Estimation
Apr 30, 2020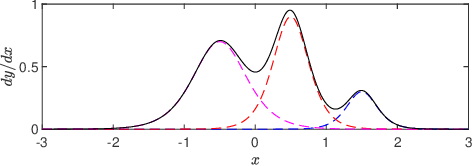


In this paper, triangular networks refer to feedforward neural networks with triangular block matrices as their connection weights, and they are studied for density estimation. A special two layer triangular monotonic neural network unit is designed and shown to be universal approximator for invertible mappings with triangular Jacobians based on the simple observation that positively weighted sum of monotonically increasing functions is still monotonic. Then, deep invertible neural networks consisting of stacked such monotonic triangular network units and permutations are proposed as universal density estimators. Our method is most closely related to neural autoregressive density estimations, especially the block neural autoregressive flow. But, unlike many autoregressive models, our designs are highly modular, parameter economy, computationally efficient, and applicable to density estimation of data with high dimensions. Experimental results on image density estimation benchmarks are reported for performance comparisons.
CheXbert: Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT
Apr 30, 2020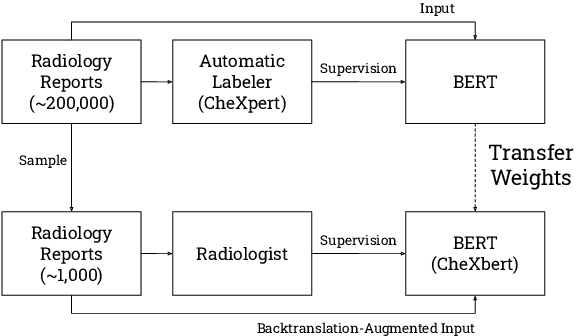
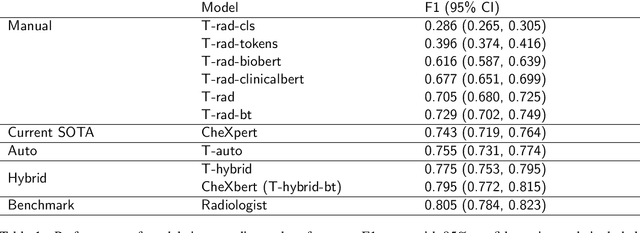
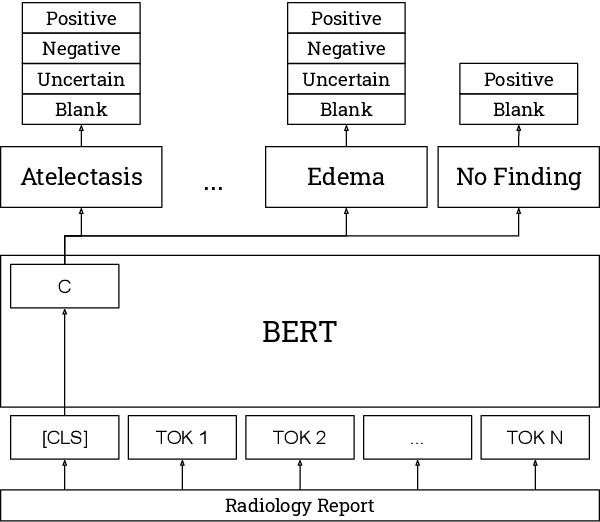
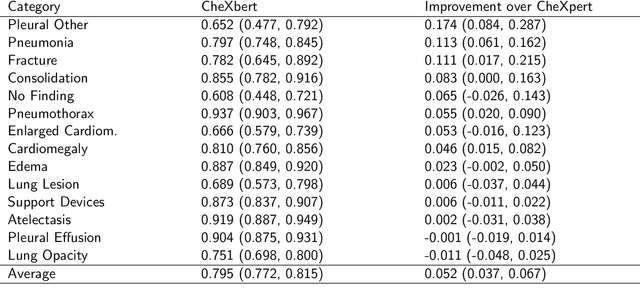
The extraction of labels from radiology text reports enables large-scale training of medical imaging models. Existing approaches to report labeling typically rely either on sophisticated feature engineering based on medical domain knowledge or manual annotations by experts. In this work, we introduce a BERT-based approach to medical image report labeling that exploits both the scale of available rule-based systems and the quality of expert annotations. We demonstrate superior performance of a biomedically pretrained BERT model first trained on annotations of a rule-based labeler and then finetuned on a small set of expert annotations augmented with automated backtranslation. We find that our final model, CheXbert, is able to outperform the previous best rules-based labeler with statistical significance, setting a new SOTA for report labeling on one of the largest datasets of chest x-rays.
Co-occurrence Based Texture Synthesis
May 17, 2020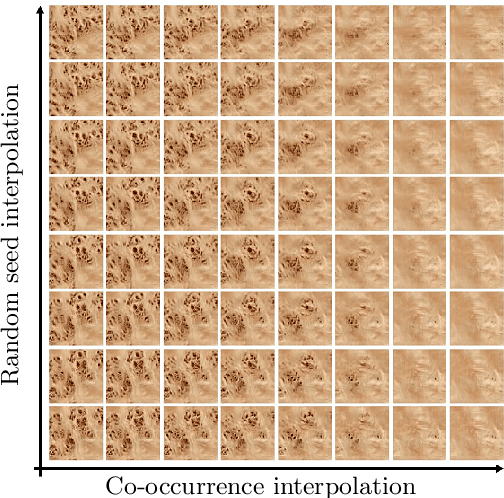
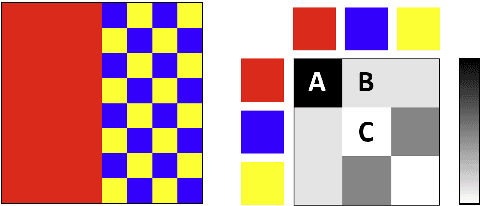
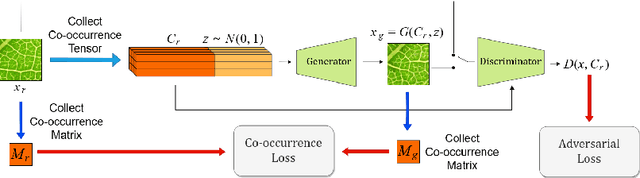

We model local texture patterns using the co-occurrence statistics of pixel values. We then train a generative adversarial network, conditioned on co-occurrence statistics, to synthesize new textures from the co-occurrence statistics and a random noise seed. Co-occurrences have long been used to measure similarity between textures. That is, two textures are considered similar if their corresponding co-occurrence matrices are similar. By the same token, we show that multiple textures generated from the same co-occurrence matrix are similar to each other. This gives rise to a new texture synthesis algorithm. We show that co-occurrences offer a stable, intuitive and interpretable latent representation for texture synthesis. Our technique can be used to generate a smooth texture morph between two textures, by interpolating between their corresponding co-occurrence matrices. We further show an interactive texture tool that allows a user to adjust local characteristics of the synthesized texture image using the co-occurrence values directly.
MRI Reconstruction Using Deep Bayesian Inference
Sep 03, 2019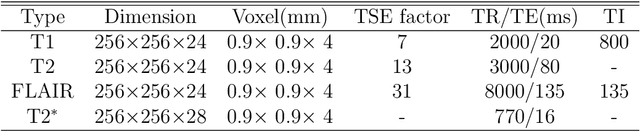
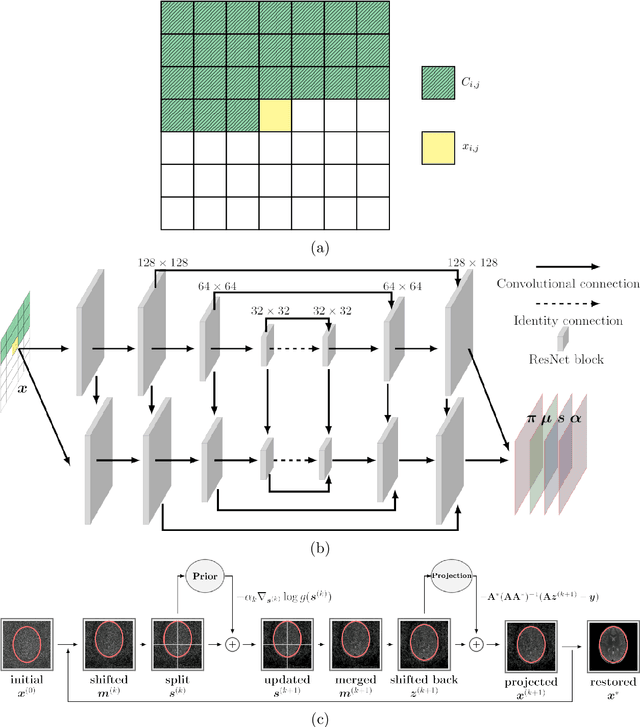
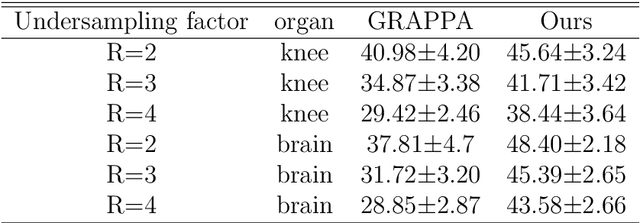
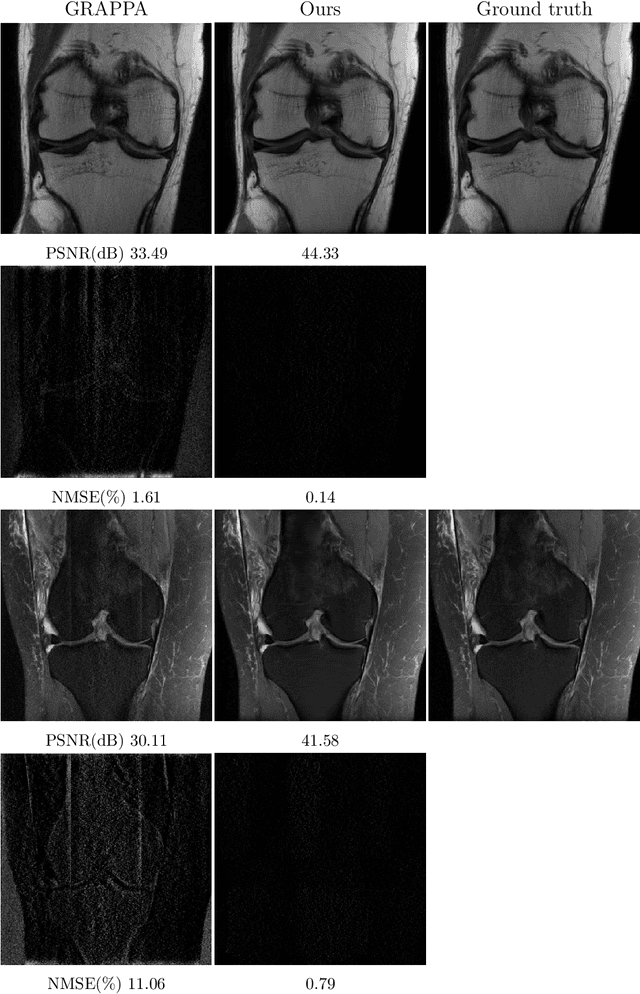
Purpose: To develop a deep learning-based Bayesian inference for MRI reconstruction. Methods: We modeled the MRI reconstruction problem with Bayes's theorem, following the recently proposed PixelCNN++ method. The image reconstruction from incomplete k-space measurement was obtained by maximizing the posterior possibility. A generative network was utilized as the image prior, which was computationally tractable, and the k-space data fidelity was enforced by using an equality constraint. The stochastic backpropagation was utilized to calculate the descent gradient in the process of maximum a posterior, and a projected subgradient method was used to impose the equality constraint. In contrast to the other deep learning reconstruction methods, the proposed one used the likelihood of prior as the training loss and the objective function in reconstruction to improve the image quality. Results: The proposed method showed an improved performance in preserving image details and reducing aliasing artifacts, compared with GRAPPA, $\ell_1$-ESPRiT, and MODL, a state-of-the-art deep learning reconstruction method. The proposed method generally achieved more than 5 dB peak signal-to-noise ratio improvement for compressed sensing and parallel imaging reconstructions compared with the other methods. Conclusion: The Bayesian inference significantly improved the reconstruction performance, compared with the conventional $\ell_1$-sparsity prior in compressed sensing reconstruction tasks. More importantly, the proposed reconstruction framework can be generalized for most MRI reconstruction scenarios.
Multimodal Age and Gender Classification Using Ear and Profile Face Images
Jul 23, 2019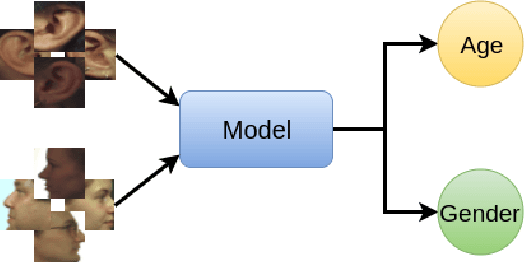

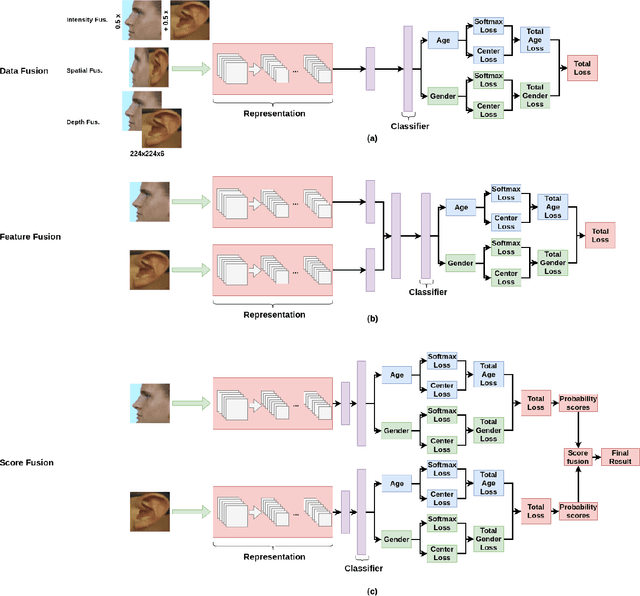
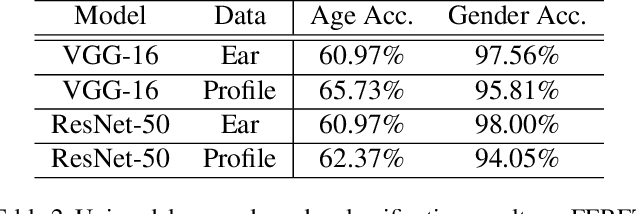
In this paper, we present multimodal deep neural network frameworks for age and gender classification, which take input a profile face image as well as an ear image. Our main objective is to enhance the accuracy of soft biometric trait extraction from profile face images by additionally utilizing a promising biometric modality: ear appearance. For this purpose, we provided end-to-end multimodal deep learning frameworks. We explored different multimodal strategies by employing data, feature, and score level fusion. To increase representation and discrimination capability of the deep neural networks, we benefited from domain adaptation and employed center loss besides softmax loss. We conducted extensive experiments on the UND-F, UND-J2, and FERET datasets. Experimental results indicated that profile face images contain a rich source of information for age and gender classification. We found that the presented multimodal system achieves very high age and gender classification accuracies. Moreover, we attained superior results compared to the state-of-the-art profile face image or ear image-based age and gender classification methods.
Sparse aNETT for Solving Inverse Problems with Deep Learning
Apr 20, 2020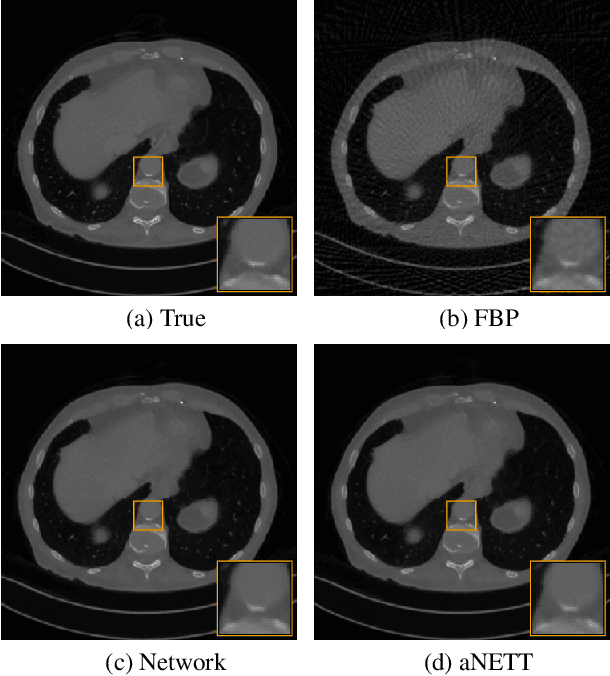

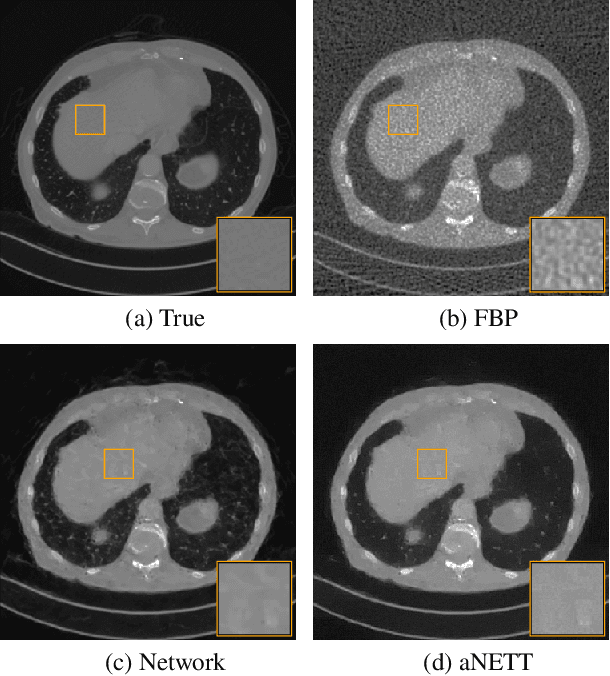
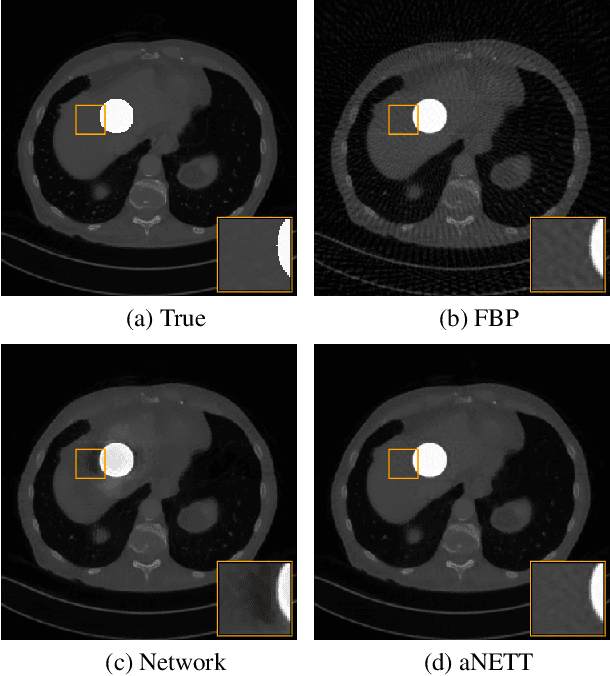
We propose a sparse reconstruction framework (aNETT) for solving inverse problems. Opposed to existing sparse reconstruction techniques that are based on linear sparsifying transforms, we train an autoencoder network $D \circ E$ with $E$ acting as a nonlinear sparsifying transform and minimize a Tikhonov functional with learned regularizer formed by the $\ell^q$-norm of the encoder coefficients and a penalty for the distance to the data manifold. We propose a strategy for training an autoencoder based on a sample set of the underlying image class such that the autoencoder is independent of the forward operator and is subsequently adapted to the specific forward model. Numerical results are presented for sparse view CT, which clearly demonstrate the feasibility, robustness and the improved generalization capability and stability of aNETT over post-processing networks.
Latent Domain Learning with Dynamic Residual Adapters
Jun 01, 2020

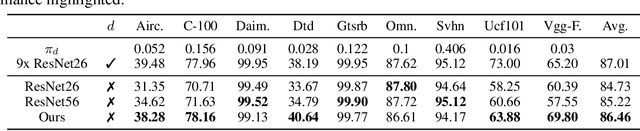
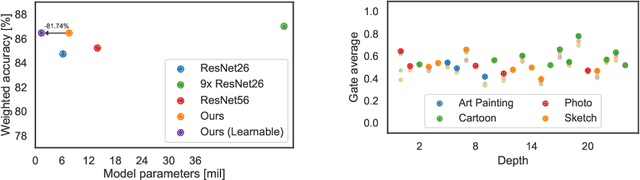
A practical shortcoming of deep neural networks is their specialization to a single task and domain. While recent techniques in domain adaptation and multi-domain learning enable the learning of more domain-agnostic features, their success relies on the presence of domain labels, typically requiring manual annotation and careful curation of datasets. Here we focus on a less explored, but more realistic case: learning from data from multiple domains, without access to domain annotations. In this scenario, standard model training leads to the overfitting of large domains, while disregarding smaller ones. We address this limitation via dynamic residual adapters, an adaptive gating mechanism that helps account for latent domains, coupled with an augmentation strategy inspired by recent style transfer techniques. Our proposed approach is examined on image classification tasks containing multiple latent domains, and we showcase its ability to obtain robust performance across these. Dynamic residual adapters significantly outperform off-the-shelf networks with much larger capacity, and can be incorporated seamlessly with existing architectures in an end-to-end manner.