 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Generative 3D Shape Learning from Natural Images
Oct 01, 2019
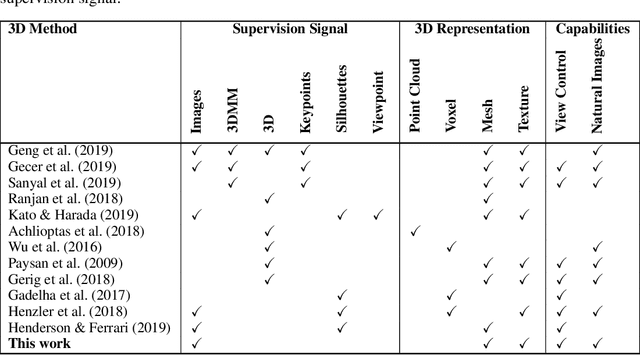
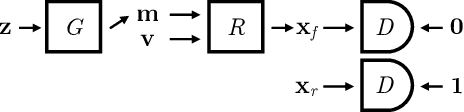


In this paper we present, to the best of our knowledge, the first method to learn a generative model of 3D shapes from natural images in a fully unsupervised way. For example, we do not use any ground truth 3D or 2D annotations, stereo video, and ego-motion during the training. Our approach follows the general strategy of Generative Adversarial Networks, where an image generator network learns to create image samples that are realistic enough to fool a discriminator network into believing that they are natural images. In contrast, in our approach the image generation is split into 2 stages. In the first stage a generator network outputs 3D objects. In the second, a differentiable renderer produces an image of the 3D objects from random viewpoints. The key observation is that a realistic 3D object should yield a realistic rendering from any plausible viewpoint. Thus, by randomizing the choice of the viewpoint our proposed training forces the generator network to learn an interpretable 3D representation disentangled from the viewpoint. In this work, a 3D representation consists of a triangle mesh and a texture map that is used to color the triangle surface by using the UV-mapping technique. We provide analysis of our learning approach, expose its ambiguities and show how to overcome them. Experimentally, we demonstrate that our method can learn realistic 3D shapes of faces by using only the natural images of the FFHQ dataset.
Harnessing Adversarial Distances to Discover High-Confidence Errors
Jun 29, 2020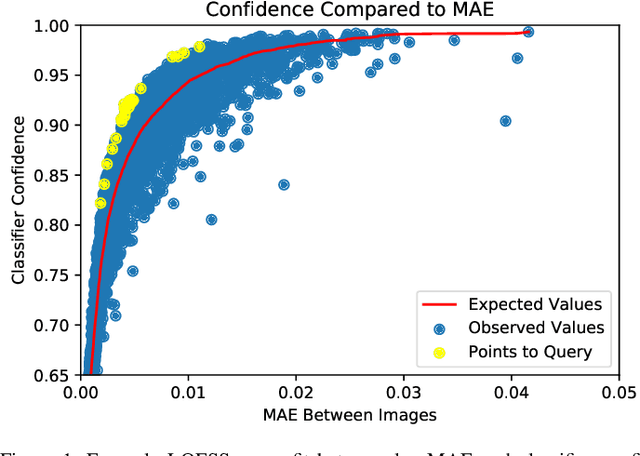
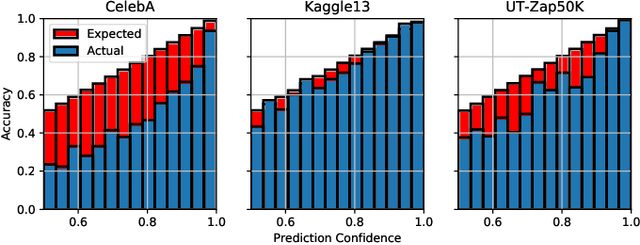
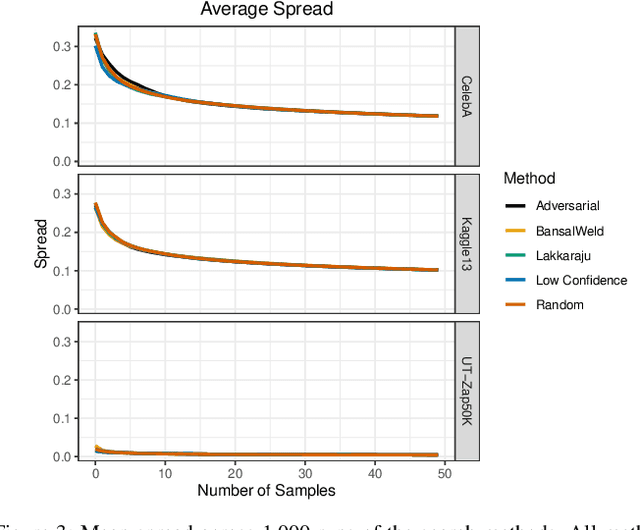
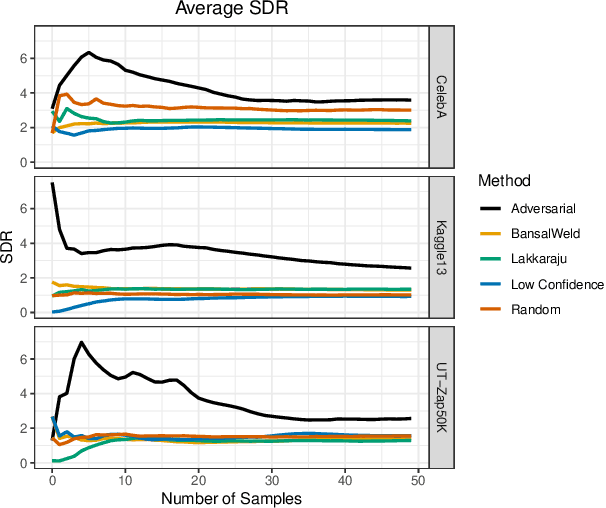
Given a deep neural network image classification model that we treat as a black box, and an unlabeled evaluation dataset, we develop an efficient strategy by which the classifier can be evaluated. Randomly sampling and labeling instances from an unlabeled evaluation dataset allows traditional performance measures like accuracy, precision, and recall to be estimated. However, random sampling may miss rare errors for which the model is highly confident in its prediction, but wrong. These high-confidence errors can represent costly mistakes, and therefore should be explicitly searched for. Past works have developed search techniques to find classification errors above a specified confidence threshold, but ignore the fact that errors should be expected at confidence levels anywhere below 100\%. In this work, we investigate the problem of finding errors at rates greater than expected given model confidence. Additionally, we propose a query-efficient and novel search technique that is guided by adversarial perturbations to find these mistakes in black box models. Through rigorous empirical experimentation, we demonstrate that our Adversarial Distance search discovers high-confidence errors at a rate greater than expected given model confidence.
Pixel Invisibility: Detecting Objects Invisible in Color Images
Jun 15, 2020
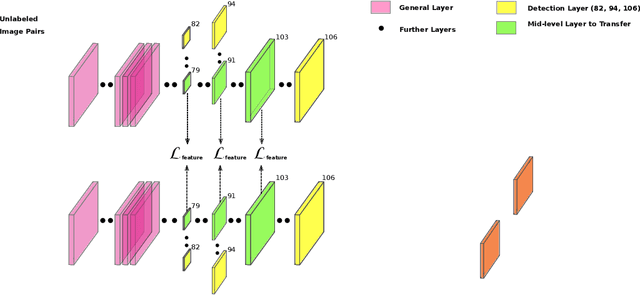

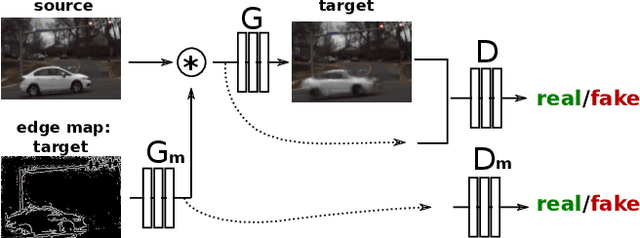
Despite recent success of object detectors using deep neural networks, their deployment on safety-critical applications such as self-driving cars remains questionable. This is partly due to the absence of reliable estimation for detectors' failure under operational conditions such as night, fog, dusk, dawn and glare. Such unquantifiable failures could lead to safety violations. In order to solve this problem, we created an algorithm that predicts a pixel-level invisibility map for color images that does not require manual labeling - that computes the probability that a pixel/region contains objects that are invisible in color domain, during various lighting conditions such as day, night and fog. We propose a novel use of cross modal knowledge distillation from color to infra-red domain using weakly-aligned image pairs from the day and construct indicators for the pixel-level invisibility based on the distances of their intermediate-level features. Quantitative experiments show the great performance of our pixel-level invisibility mask and also the effectiveness of distilled mid-level features on object detection in infra-red imagery.
Semantic Scene Completion from a Single Depth Image
Nov 28, 2016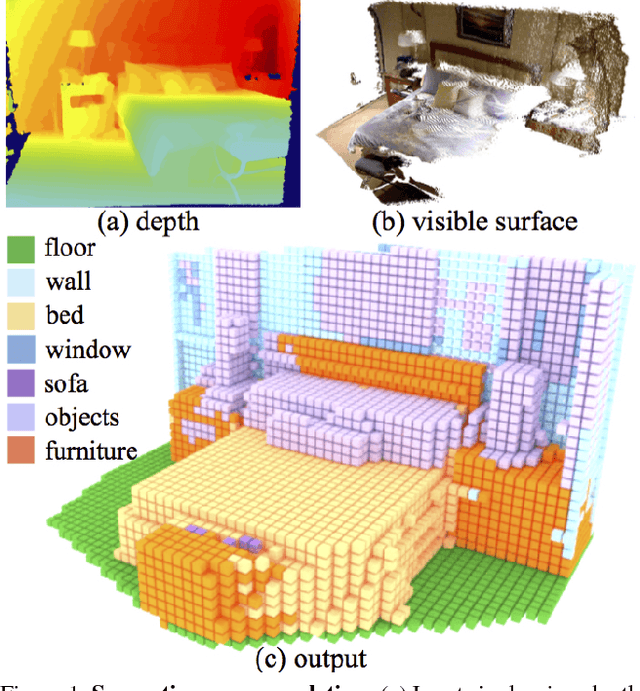

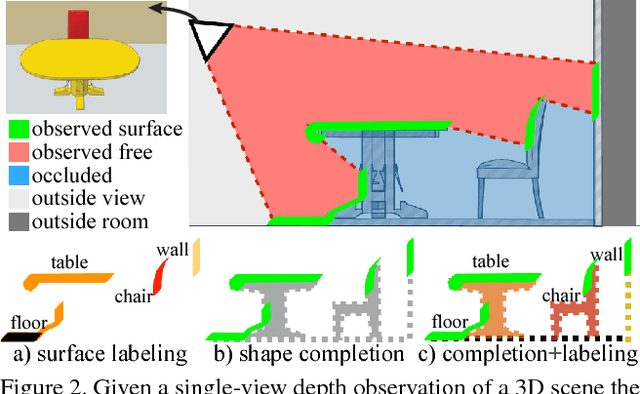
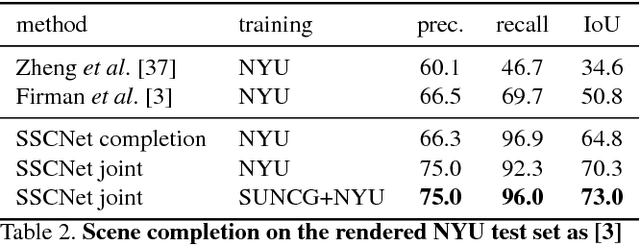
This paper focuses on semantic scene completion, a task for producing a complete 3D voxel representation of volumetric occupancy and semantic labels for a scene from a single-view depth map observation. Previous work has considered scene completion and semantic labeling of depth maps separately. However, we observe that these two problems are tightly intertwined. To leverage the coupled nature of these two tasks, we introduce the semantic scene completion network (SSCNet), an end-to-end 3D convolutional network that takes a single depth image as input and simultaneously outputs occupancy and semantic labels for all voxels in the camera view frustum. Our network uses a dilation-based 3D context module to efficiently expand the receptive field and enable 3D context learning. To train our network, we construct SUNCG - a manually created large-scale dataset of synthetic 3D scenes with dense volumetric annotations. Our experiments demonstrate that the joint model outperforms methods addressing each task in isolation and outperforms alternative approaches on the semantic scene completion task.
Subjective Annotation for a Frame Interpolation Benchmark using Artifact Amplification
Jan 10, 2020



Current benchmarks for optical flow algorithms evaluate the estimation either directly by comparing the predicted flow fields with the ground truth or indirectly by using the predicted flow fields for frame interpolation and then comparing the interpolated frames with the actual frames. In the latter case, objective quality measures such as the mean squared error are typically employed. However, it is well known that for image quality assessment, the actual quality experienced by the user cannot be fully deduced from such simple measures. Hence, we conducted a subjective quality assessment crowdscouring study for the interpolated frames provided by one of the optical flow benchmarks, the Middlebury benchmark. It contains interpolated frames from 155 methods applied to each of 8 contents. We collected forced choice paired comparisons between interpolated images and corresponding ground truth. To increase the sensitivity of observers when judging minute difference in paired comparisons we introduced a new method to the field of full-reference quality assessment, called artifact amplification. From the crowdsourcing data we reconstructed absolute quality scale values according to Thurstone's model. As a result, we obtained a re-ranking of the 155 participating algorithms w.r.t. the visual quality of the interpolated frames. This re-ranking not only shows the necessity of visual quality assessment as another evaluation metric for optical flow and frame interpolation benchmarks, the results also provide the ground truth for designing novel image quality assessment (IQA) methods dedicated to perceptual quality of interpolated images. As a first step, we proposed such a new full-reference method, called WAE-IQA. By weighing the local differences between an interpolated image and its ground truth WAE-IQA performed slightly better than the currently best FR-IQA approach from the literature.
Hierarchized block wise image approximation by greedy pursuit strategies
Aug 27, 2013
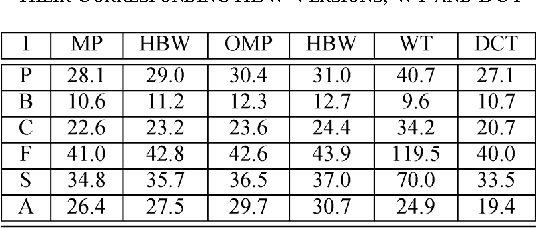
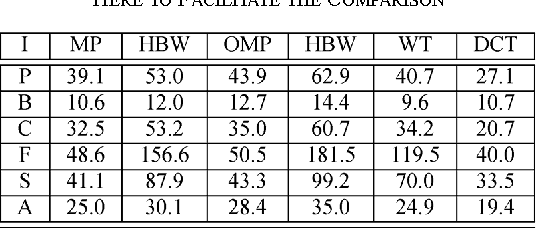
An approach for effective implementation of greedy selection methodologies, to approximate an image partitioned into blocks, is proposed. The method is specially designed for approximating partitions on a transformed image. It evolves by selecting, at each iteration step, i) the elements for approximating each of the blocks partitioning the image and ii) the hierarchized sequence in which the blocks are approximated to reach the required global condition on sparsity.
Adversarial Graph Representation Adaptation for Cross-Domain Facial Expression Recognition
Aug 03, 2020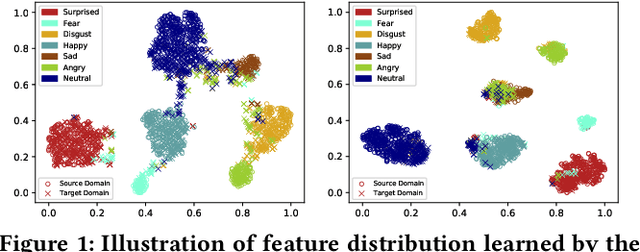
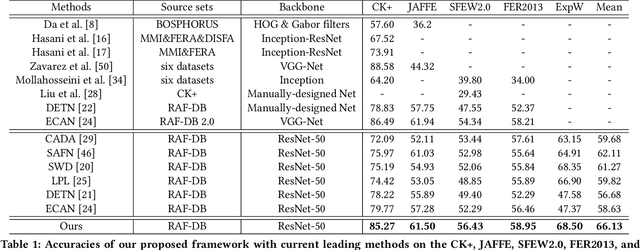
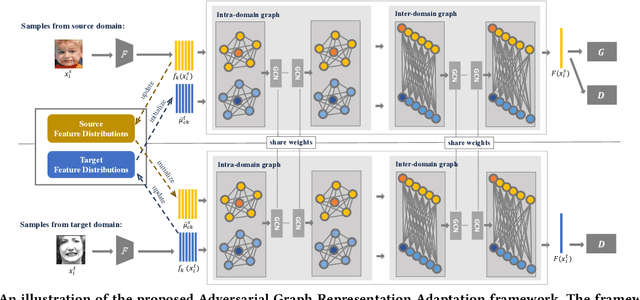
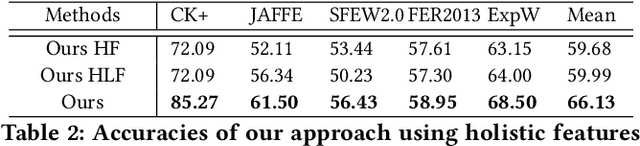
Data inconsistency and bias are inevitable among different facial expression recognition (FER) datasets due to subjective annotating process and different collecting conditions. Recent works resort to adversarial mechanisms that learn domain-invariant features to mitigate domain shift. However, most of these works focus on holistic feature adaptation, and they ignore local features that are more transferable across different datasets. Moreover, local features carry more detailed and discriminative content for expression recognition, and thus integrating local features may enable fine-grained adaptation. In this work, we propose a novel Adversarial Graph Representation Adaptation (AGRA) framework that unifies graph representation propagation with adversarial learning for cross-domain holistic-local feature co-adaptation. To achieve this, we first build a graph to correlate holistic and local regions within each domain and another graph to correlate these regions across different domains. Then, we learn the per-class statistical distribution of each domain and extract holistic-local features from the input image to initialize the corresponding graph nodes. Finally, we introduce two stacked graph convolution networks to propagate holistic-local feature within each domain to explore their interaction and across different domains for holistic-local feature co-adaptation. In this way, the AGRA framework can adaptively learn fine-grained domain-invariant features and thus facilitate cross-domain expression recognition. We conduct extensive and fair experiments on several popular benchmarks and show that the proposed AGRA framework achieves superior performance over previous state-of-the-art methods.
Disentangling Human Error from the Ground Truth in Segmentation of Medical Images
Aug 03, 2020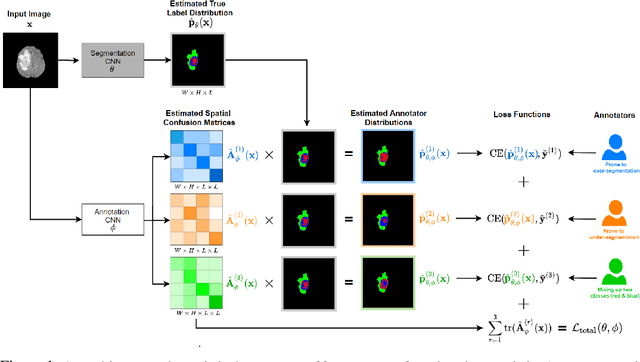



Recent years have seen increasing use of supervised learning methods for segmentation tasks. However, the predictive performance of these algorithms depends on the quality of labels. This problem is particularly pertinent in the medical image domain, where both the annotation cost and inter-observer variability are high. In a typical label acquisition process, different human experts provide their estimates of the 'true' segmentation labels under the influence of their own biases and competence levels. Treating these noisy labels blindly as the ground truth limits the performance that automatic segmentation algorithms can achieve. In this work, we present a method for jointly learning, from purely noisy observations alone, the reliability of individual annotators and the true segmentation label distributions, using two coupled CNNs. The separation of the two is achieved by encouraging the estimated annotators to be maximally unreliable while achieving high fidelity with the noisy training data. We first define a toy segmentation dataset based on MNIST and study the properties of the proposed algorithm. We then demonstrate the utility of the method on three public medical imaging segmentation datasets with simulated (when necessary) and real diverse annotations: 1) MSLSC (multiple-sclerosis lesions); 2) BraTS (brain tumours); 3) LIDC-IDRI (lung abnormalities). In all cases, our method outperforms competing methods and relevant baselines particularly in cases where the number of annotations is small and the amount of disagreement is large. The experiments also show strong ability to capture the complex spatial characteristics of annotators' mistakes.
Is Image Super-resolution Helpful for Other Vision Tasks?
Jan 28, 2016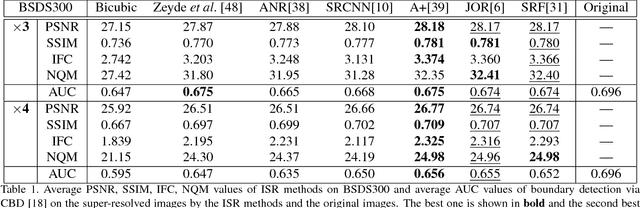
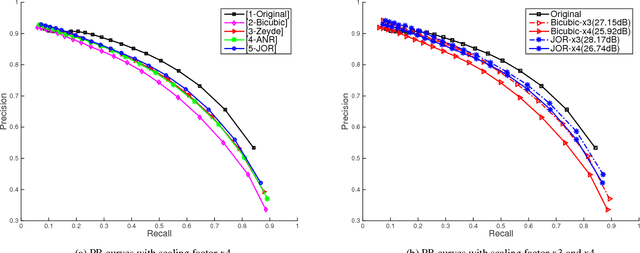

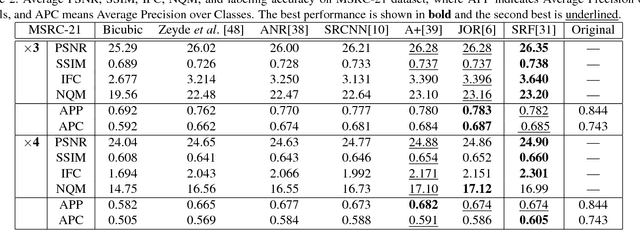
Despite the great advances made in the field of image super-resolution (ISR) during the last years, the performance has merely been evaluated perceptually. Thus, it is still unclear whether ISR is helpful for other vision tasks. In this paper, we present the first comprehensive study and analysis of the usefulness of ISR for other vision applications. In particular, six ISR methods are evaluated on four popular vision tasks, namely edge detection, semantic image segmentation, digit recognition, and scene recognition. We show that applying ISR to input images of other vision systems does improve their performance when the input images are of low-resolution. We also study the correlation between four standard perceptual evaluation criteria (namely PSNR, SSIM, IFC, and NQM) and the usefulness of ISR to the vision tasks. Experiments show that they correlate well with each other in general, but perceptual criteria are still not accurate enough to be used as full proxies for the usefulness. We hope this work will inspire the community to evaluate ISR methods also in real vision applications, and to adopt ISR as a pre-processing step of other vision tasks if the resolution of their input images is low.
Geo-PIFu: Geometry and Pixel Aligned Implicit Functions for Single-view Human Reconstruction
Jun 15, 2020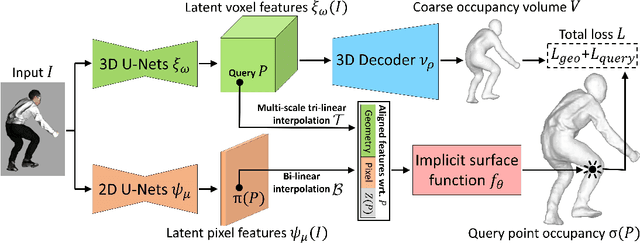
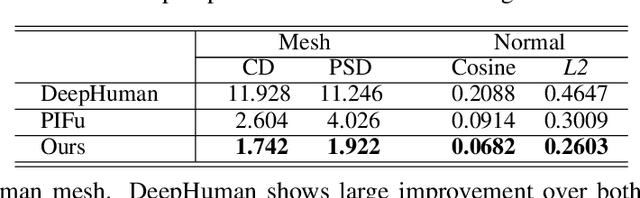

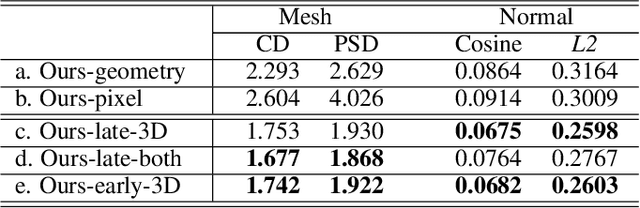
We propose Geo-PIFu, a method to recover a 3D mesh from a monocular color image of a clothed person. Our method is based on a deep implicit function-based representation to learn latent voxel features using a structure-aware 3D U-Net, to constrain the model in two ways: first, to resolve feature ambiguities in query point encoding, second, to serve as a coarse human shape proxy to regularize the high-resolution mesh and encourage global shape regularity. We show that, by both encoding query points and constraining global shape using latent voxel features, the reconstruction we obtain for clothed human meshes exhibits less shape distortion and improved surface details compared to competing methods. We evaluate Geo-PIFu on a recent human mesh public dataset that is $10 \times$ larger than the private commercial dataset used in PIFu and previous derivative work. On average, we exceed the state of the art by $42.7\%$ reduction in Chamfer and Point-to-Surface Distances, and $19.4\%$ reduction in normal estimation errors.