 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
High-Resolution Network for Photorealistic Style Transfer
Apr 25, 2019


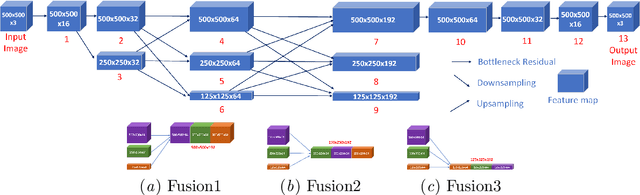

Photorealistic style transfer aims to transfer the style of one image to another, but preserves the original structure and detail outline of the content image, which makes the content image still look like a real shot after the style transfer. Although some realistic image styling methods have been proposed, these methods are vulnerable to lose the details of the content image and produce some irregular distortion structures. In this paper, we use a high-resolution network as the image generation network. Compared to other methods, which reduce the resolution and then restore the high resolution, our generation network maintains high resolution throughout the process. By connecting high-resolution subnets to low-resolution subnets in parallel and repeatedly multi-scale fusion, high-resolution subnets can continuously receive information from low-resolution subnets. This allows our network to discard less information contained in the image, so the generated images may have a more elaborate structure and less distortion, which is crucial to the visual quality. We conducted extensive experiments and compared the results with existing methods. The experimental results show that our model is effective and produces better results than existing methods for photorealistic image stylization. Our source code with PyTorch framework will be publicly available at https://github.com/limingcv/Photorealistic-Style-Transfer
Can We Learn Heuristics For Graphical Model Inference Using Reinforcement Learning?
May 05, 2020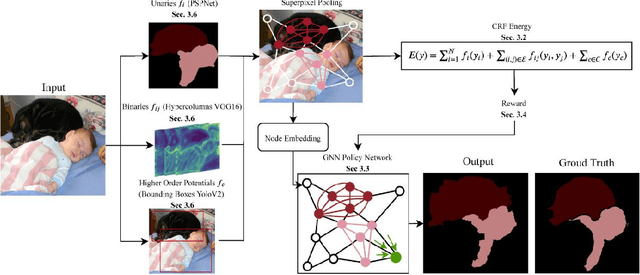

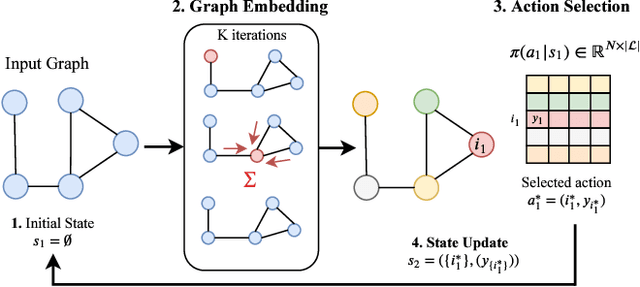
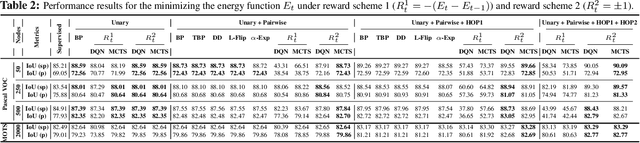
Combinatorial optimization is frequently used in computer vision. For instance, in applications like semantic segmentation, human pose estimation and action recognition, programs are formulated for solving inference in Conditional Random Fields (CRFs) to produce a structured output that is consistent with visual features of the image. However, solving inference in CRFs is in general intractable, and approximation methods are computationally demanding and limited to unary, pairwise and hand-crafted forms of higher order potentials. In this paper, we show that we can learn program heuristics, i.e., policies, for solving inference in higher order CRFs for the task of semantic segmentation, using reinforcement learning. Our method solves inference tasks efficiently without imposing any constraints on the form of the potentials. We show compelling results on the Pascal VOC and MOTS datasets.
Simplifying Models with Unlabeled Output Data
Jun 29, 2020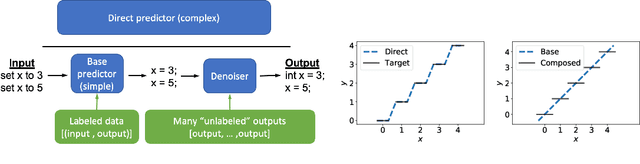


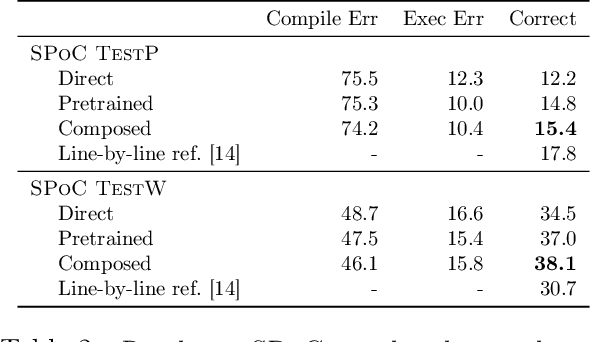
We focus on prediction problems with high-dimensional outputs that are subject to output validity constraints, e.g. a pseudocode-to-code translation task where the code must compile. For these problems, labeled input-output pairs are expensive to obtain, but "unlabeled" outputs, i.e. outputs without corresponding inputs, are freely available and provide information about output validity (e.g. code on GitHub). In this paper, we present predict-and-denoise, a framework that can leverage unlabeled outputs. Specifically, we first train a denoiser to map possibly invalid outputs to valid outputs using synthetic perturbations of the unlabeled outputs. Second, we train a predictor composed with this fixed denoiser. We show theoretically that for a family of functions with a discrete valid output space, composing with a denoiser reduces the complexity of a 2-layer ReLU network needed to represent the function and that this complexity gap can be arbitrarily large. We evaluate the framework empirically on several datasets, including image generation from attributes and pseudocode-to-code translation. On the SPoC~pseudocode-to-code dataset, our framework improves the proportion of code outputs that pass all test cases by 3-4% over a baseline Transformer.
Image reconstruction from limited range projections using orthogonal moments
Mar 12, 2014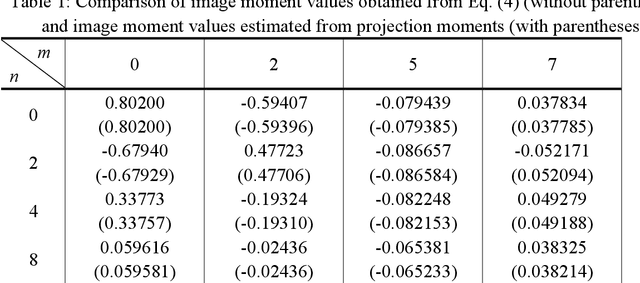

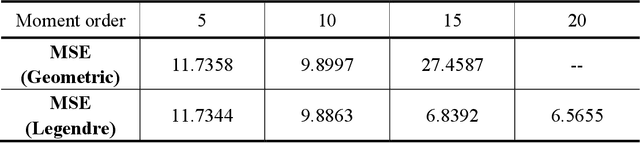
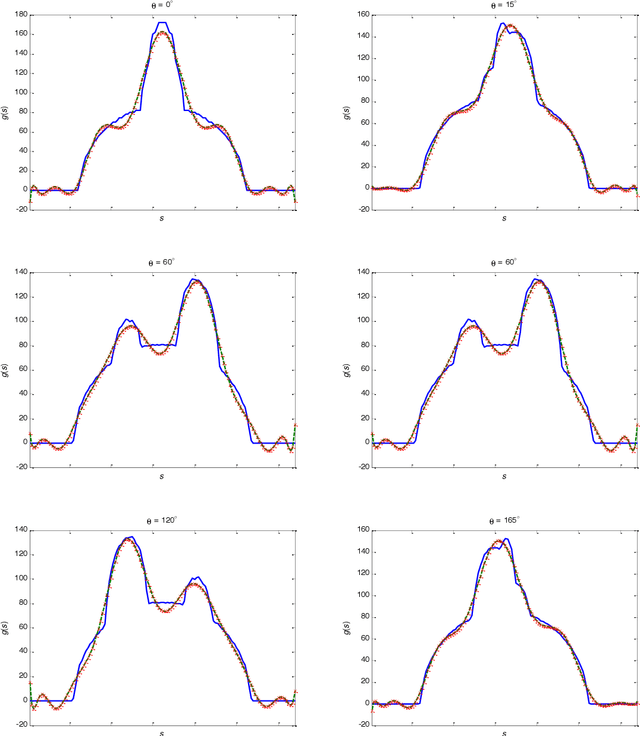
A set of orthonormal polynomials is proposed for image reconstruction from projection data. The relationship between the projection moments and image moments is discussed in detail, and some interesting properties are demonstrated. Simulation results are provided to validate the method and to compare its performance with previous works.
Y-Net: A Hybrid Deep Learning Reconstruction Framework for Photoacoustic Imaging in vivo
Aug 02, 2019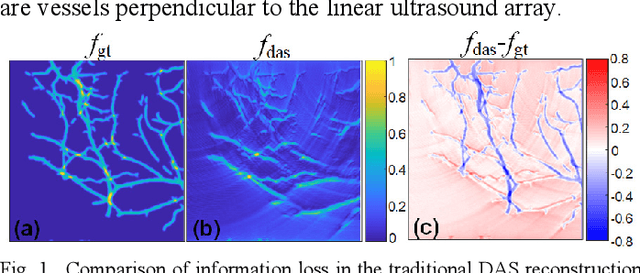
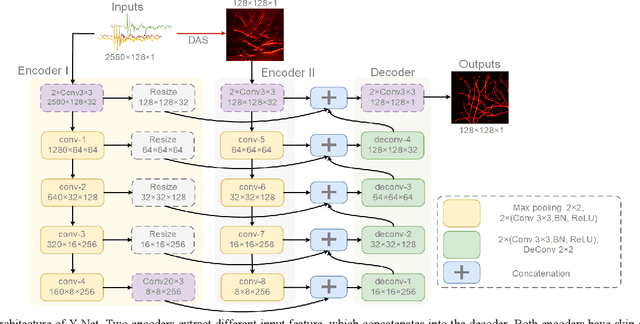
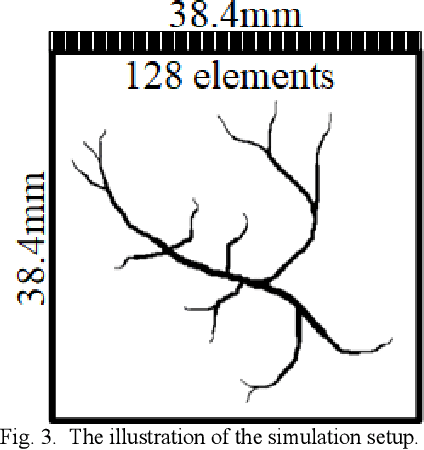

Photoacoustic imaging (PAI) is an emerging non-invasive imaging modality combining the advantages of deep ultrasound penetration and high optical contrast. Image reconstruction is an essential topic in PAI, which is unfortunately an ill-posed problem due to the complex and unknown optical/acoustic parameters in tissue. Conventional algorithms used in PAI (e.g., delay-and-sum) provide a fast solution while many artifacts remain, especially for linear array probe with limited-view issue. Convolutional neural network (CNN) has shown state-of-the-art results in computer vision, and more and more work based on CNN has been studied in medical image processing recently. In this paper, we present a non-iterative scheme filling the gap between existing direct-processing and post-processing methods, and propose a new framework Y-Net: a CNN architecture to reconstruct the PA image by optimizing both raw data and beamformed images once. The network connected two encoders with one decoder path, which optimally utilizes more information from raw data and beamformed image. The results of the test set showed good performance compared with conventional reconstruction algorithms and other deep learning methods. Our method is also validated with experiments both in-vitro and in vivo, which still performs better than other existing methods. The proposed Y-Net architecture also has high potential in medical image reconstruction for other imaging modalities beyond PAI.
Extreme Relative Pose Network under Hybrid Representations
Dec 25, 2019
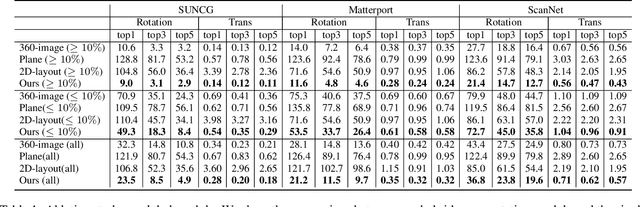
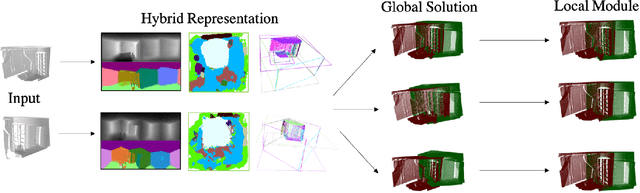
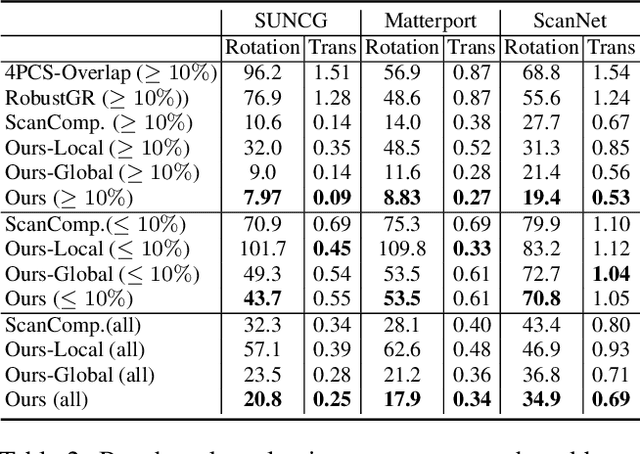
In this paper, we introduce a novel RGB-D based relative pose estimation approach that is suitable for small-overlapping or non-overlapping scans and can output multiple relative poses. Our method performs scene completion and matches the completed scans. However, instead of using a fixed representation for completion, the key idea is to utilize hybrid representations that combine 360-image, 2D image-based layout, and planar patches. This approach offers adaptively feature representations for relative pose estimation. Besides, we introduce a global-2-local matching procedure, which utilizes initial relative poses obtained during the global phase to detect and then integrate geometric relations for pose refinement. Experimental results justify the potential of this approach across a wide range of benchmark datasets. For example, on ScanNet, the rotation translation errors of the top-1/top-5 predictions of our approach are 34.9/0.69m and 19.6/0.57m, respectively. Our approach also considerably boosts the performance of multi-scan reconstruction in few-view reconstruction settings.
Harnessing Adversarial Distances to Discover High-Confidence Errors
Jun 29, 2020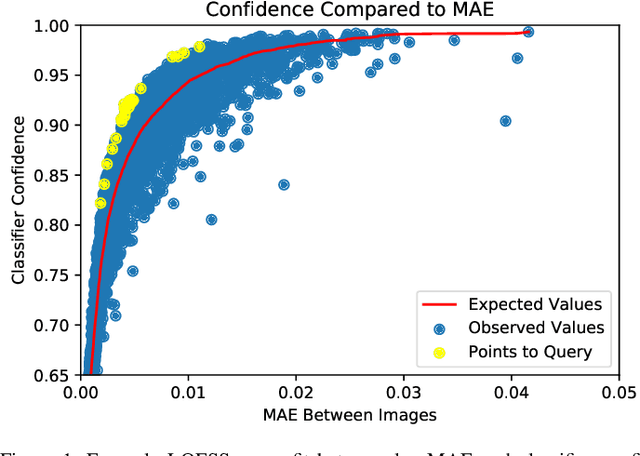
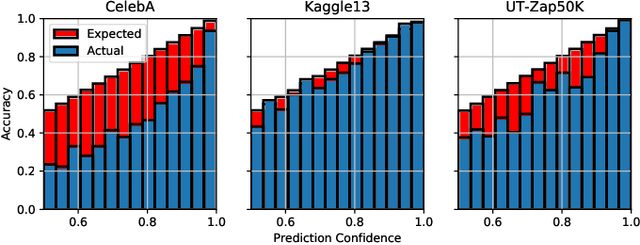
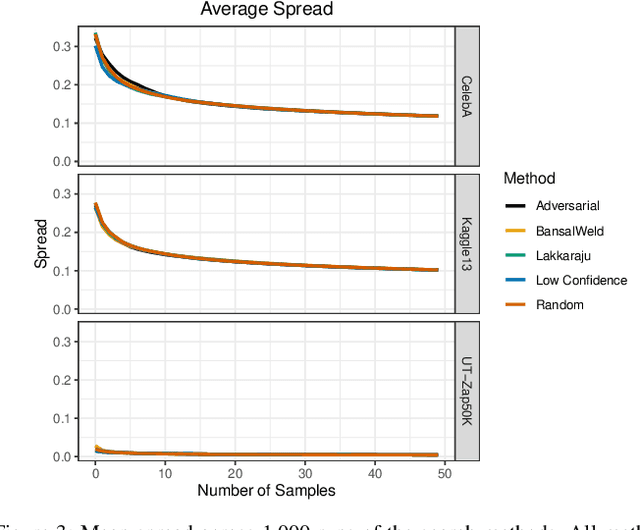
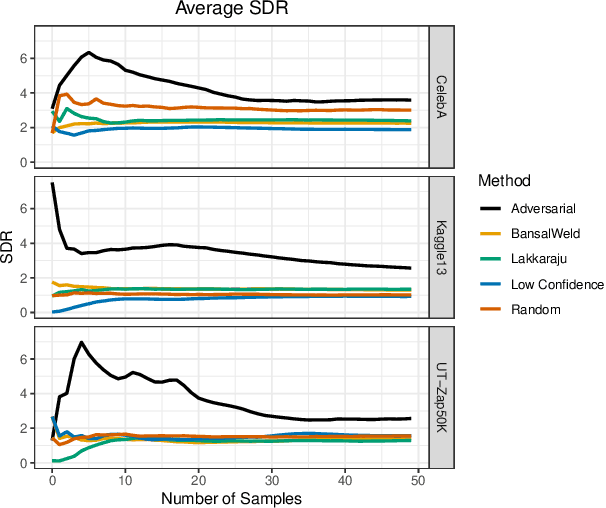
Given a deep neural network image classification model that we treat as a black box, and an unlabeled evaluation dataset, we develop an efficient strategy by which the classifier can be evaluated. Randomly sampling and labeling instances from an unlabeled evaluation dataset allows traditional performance measures like accuracy, precision, and recall to be estimated. However, random sampling may miss rare errors for which the model is highly confident in its prediction, but wrong. These high-confidence errors can represent costly mistakes, and therefore should be explicitly searched for. Past works have developed search techniques to find classification errors above a specified confidence threshold, but ignore the fact that errors should be expected at confidence levels anywhere below 100\%. In this work, we investigate the problem of finding errors at rates greater than expected given model confidence. Additionally, we propose a query-efficient and novel search technique that is guided by adversarial perturbations to find these mistakes in black box models. Through rigorous empirical experimentation, we demonstrate that our Adversarial Distance search discovers high-confidence errors at a rate greater than expected given model confidence.
Pixel Invisibility: Detecting Objects Invisible in Color Images
Jun 15, 2020
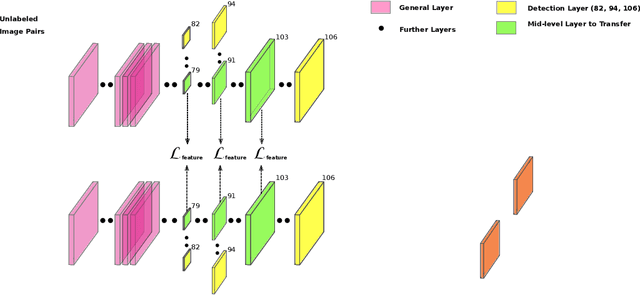

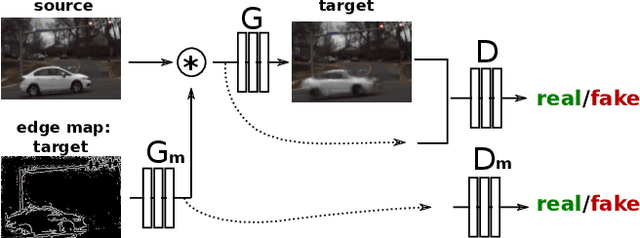
Despite recent success of object detectors using deep neural networks, their deployment on safety-critical applications such as self-driving cars remains questionable. This is partly due to the absence of reliable estimation for detectors' failure under operational conditions such as night, fog, dusk, dawn and glare. Such unquantifiable failures could lead to safety violations. In order to solve this problem, we created an algorithm that predicts a pixel-level invisibility map for color images that does not require manual labeling - that computes the probability that a pixel/region contains objects that are invisible in color domain, during various lighting conditions such as day, night and fog. We propose a novel use of cross modal knowledge distillation from color to infra-red domain using weakly-aligned image pairs from the day and construct indicators for the pixel-level invisibility based on the distances of their intermediate-level features. Quantitative experiments show the great performance of our pixel-level invisibility mask and also the effectiveness of distilled mid-level features on object detection in infra-red imagery.
A Deep Generative Deconvolutional Image Model
Dec 23, 2015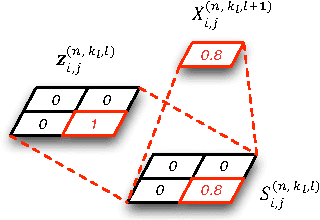
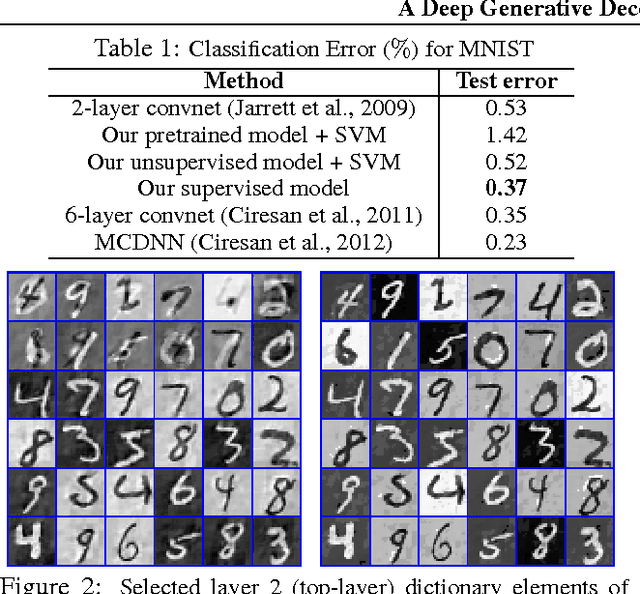
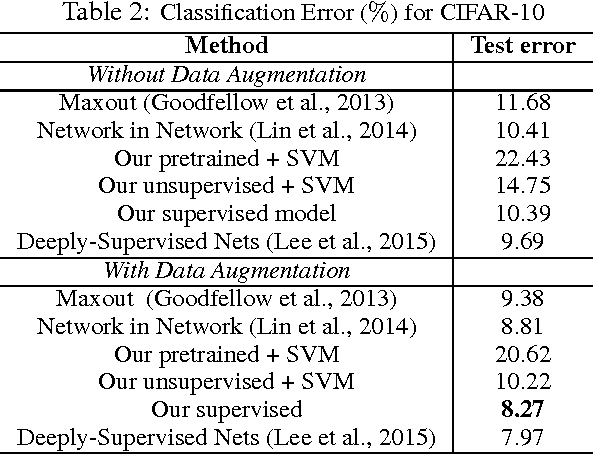

A deep generative model is developed for representation and analysis of images, based on a hierarchical convolutional dictionary-learning framework. Stochastic {\em unpooling} is employed to link consecutive layers in the model, yielding top-down image generation. A Bayesian support vector machine is linked to the top-layer features, yielding max-margin discrimination. Deep deconvolutional inference is employed when testing, to infer the latent features, and the top-layer features are connected with the max-margin classifier for discrimination tasks. The model is efficiently trained using a Monte Carlo expectation-maximization (MCEM) algorithm, with implementation on graphical processor units (GPUs) for efficient large-scale learning, and fast testing. Excellent results are obtained on several benchmark datasets, including ImageNet, demonstrating that the proposed model achieves results that are highly competitive with similarly sized convolutional neural networks.
Unsupervised Generative 3D Shape Learning from Natural Images
Oct 01, 2019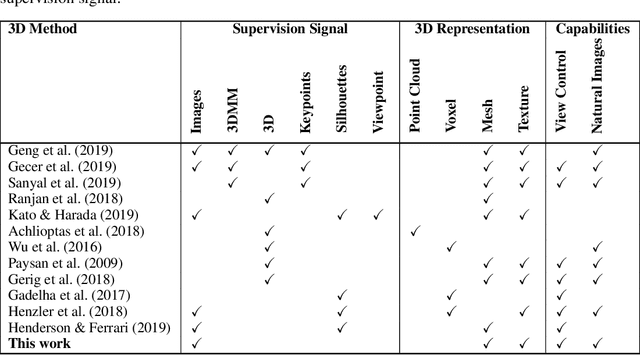
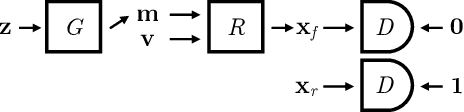


In this paper we present, to the best of our knowledge, the first method to learn a generative model of 3D shapes from natural images in a fully unsupervised way. For example, we do not use any ground truth 3D or 2D annotations, stereo video, and ego-motion during the training. Our approach follows the general strategy of Generative Adversarial Networks, where an image generator network learns to create image samples that are realistic enough to fool a discriminator network into believing that they are natural images. In contrast, in our approach the image generation is split into 2 stages. In the first stage a generator network outputs 3D objects. In the second, a differentiable renderer produces an image of the 3D objects from random viewpoints. The key observation is that a realistic 3D object should yield a realistic rendering from any plausible viewpoint. Thus, by randomizing the choice of the viewpoint our proposed training forces the generator network to learn an interpretable 3D representation disentangled from the viewpoint. In this work, a 3D representation consists of a triangle mesh and a texture map that is used to color the triangle surface by using the UV-mapping technique. We provide analysis of our learning approach, expose its ambiguities and show how to overcome them. Experimentally, we demonstrate that our method can learn realistic 3D shapes of faces by using only the natural images of the FFHQ dataset.