 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NestedVAE: Isolating Common Factors via Weak Supervision
Feb 26, 2020
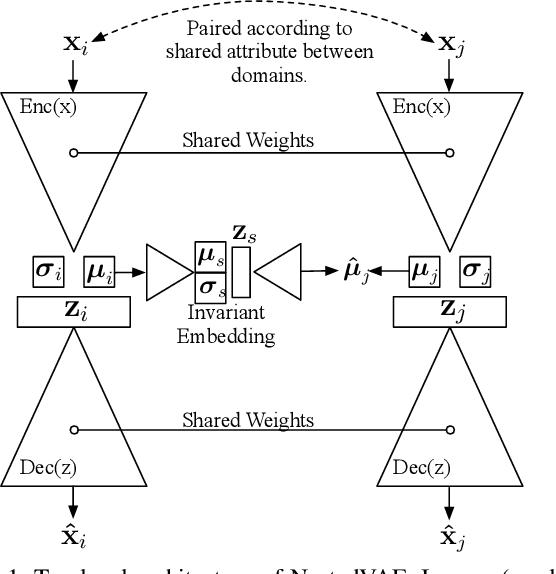
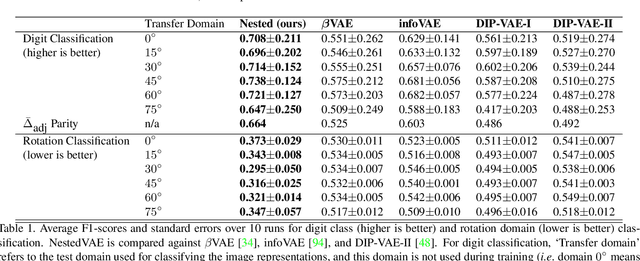
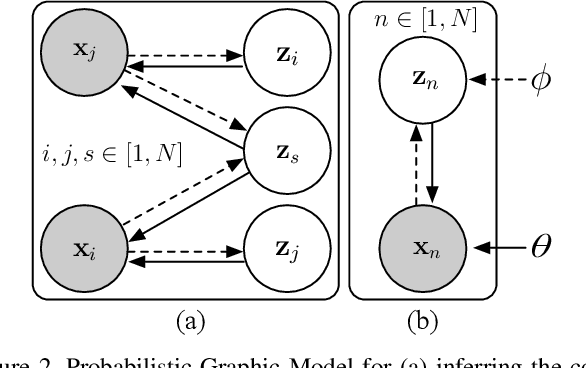
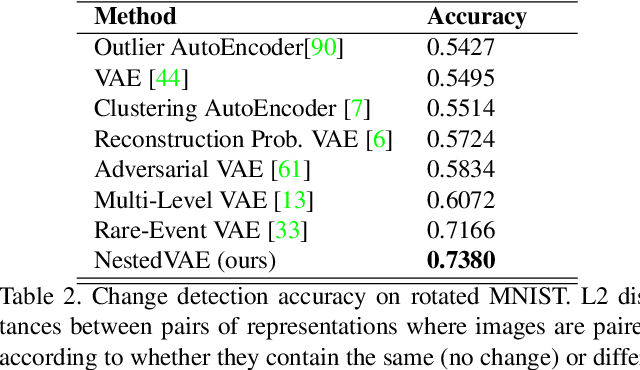
Fair and unbiased machine learning is an important and active field of research, as decision processes are increasingly driven by models that learn from data. Unfortunately, any biases present in the data may be learned by the model, thereby inappropriately transferring that bias into the decision making process. We identify the connection between the task of bias reduction and that of isolating factors common between domains whilst encouraging domain specific invariance. To isolate the common factors we combine the theory of deep latent variable models with information bottleneck theory for scenarios whereby data may be naturally paired across domains and no additional supervision is required. The result is the Nested Variational AutoEncoder (NestedVAE). Two outer VAEs with shared weights attempt to reconstruct the input and infer a latent space, whilst a nested VAE attempts to reconstruct the latent representation of one image, from the latent representation of its paired image. In so doing, the nested VAE isolates the common latent factors/causes and becomes invariant to unwanted factors that are not shared between paired images. We also propose a new metric to provide a balanced method of evaluating consistency and classifier performance across domains which we refer to as the Adjusted Parity metric. An evaluation of NestedVAE on both domain and attribute invariance, change detection, and learning common factors for the prediction of biological sex demonstrates that NestedVAE significantly outperforms alternative methods.
Object Discovery with a Copy-Pasting GAN
May 27, 2019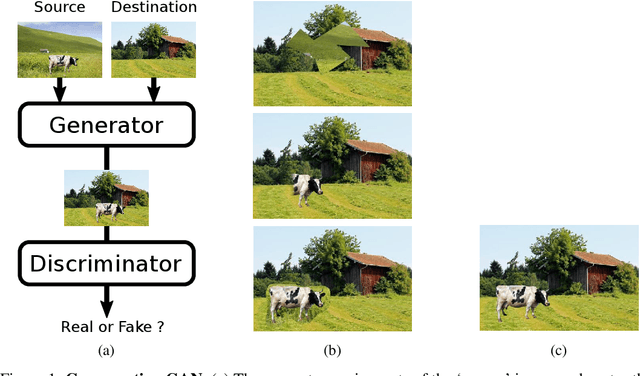
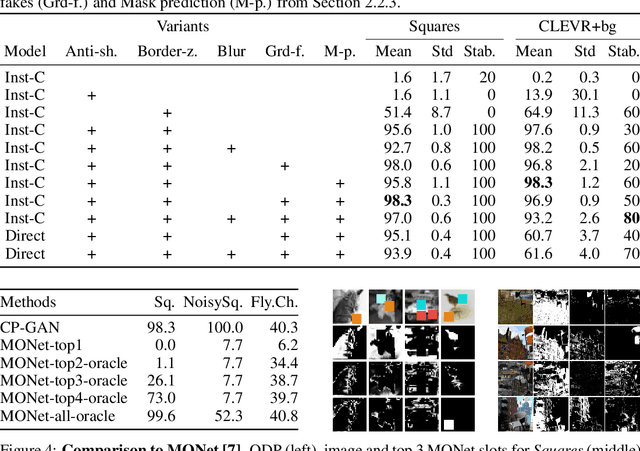
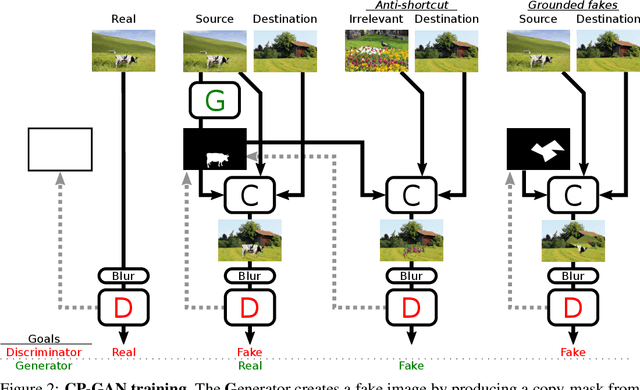

We tackle the problem of object discovery, where objects are segmented for a given input image, and the system is trained without using any direct supervision whatsoever. A novel copy-pasting GAN framework is proposed, where the generator learns to discover an object in one image by compositing it into another image such that the discriminator cannot tell that the resulting image is fake. After carefully addressing subtle issues, such as preventing the generator from `cheating', this game results in the generator learning to select objects, as copy-pasting objects is most likely to fool the discriminator. The system is shown to work well on four very different datasets, including large object appearance variations in challenging cluttered backgrounds.
DS6: Deformation-aware learning for small vessel segmentation with small, imperfectly labeled dataset
Jun 18, 2020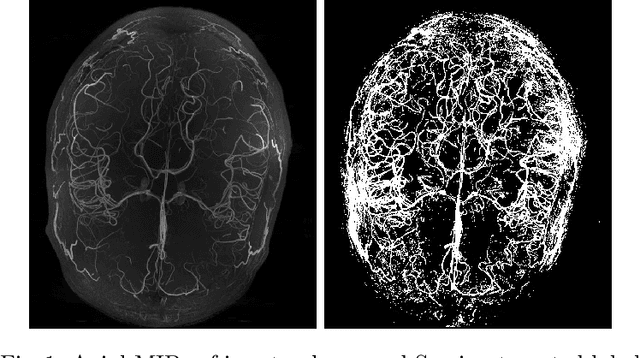
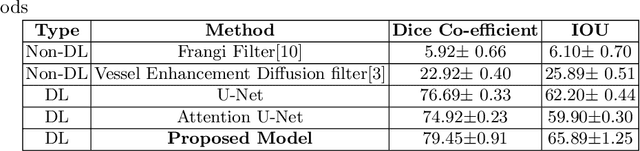


Originating from the initial segment of the middle cerebral artery of the human brain, Lenticulostriate Arteries (LSA) are a collection of perforating vessels that supply blood to the basal ganglia region. With the advancement of 7 Tesla scanner, we are able to detect these LSA which are linked to Small Vessel Diseases(SVD) and potentially a cause for neurodegenerative diseases. Segmentation of LSA with traditional approaches like Frangi or semi-automated/manual techniques can depict medium to large vessels but fail to depict the small vessels. Also, semi-automated/manual approaches are time-consuming. In this paper, we put forth a study that incorporates deep learning techniques to automatically segment these LSA using 3D 7 Tesla Time-of-fight Magnetic Resonance Angiogram images. The algorithm is trained and evaluated on a small dataset of 11 volumes. Deep learning models based on Multi-Scale Supervision U-Net accompanied by elastic deformations to give equivariance to the model, were utilized for the vessel segmentation using semi-automated labeled images. We make a qualitative analysis of the output with the original image and also on imperfect semi-manual labels to confirm the presence and continuity of small vessels.
An Efficient Explorative Sampling Considering the Generative Boundaries of Deep Generative Neural Networks
Dec 12, 2019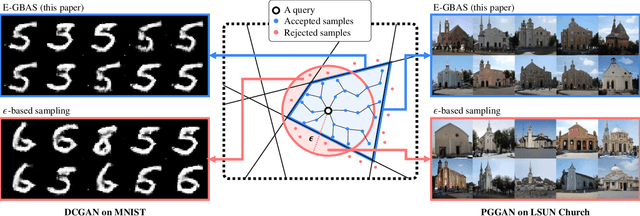


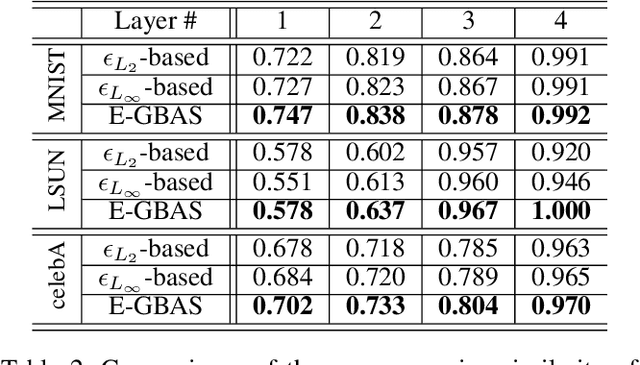
Deep generative neural networks (DGNNs) have achieved realistic and high-quality data generation. In particular, the adversarial training scheme has been applied to many DGNNs and has exhibited powerful performance. Despite of recent advances in generative networks, identifying the image generation mechanism still remains challenging. In this paper, we present an explorative sampling algorithm to analyze generation mechanism of DGNNs. Our method efficiently obtains samples with identical attributes from a query image in a perspective of the trained model. We define generative boundaries which determine the activation of nodes in the internal layer and probe inside the model with this information. To handle a large number of boundaries, we obtain the essential set of boundaries using optimization. By gathering samples within the region surrounded by generative boundaries, we can empirically reveal the characteristics of the internal layers of DGNNs. We also demonstrate that our algorithm can find more homogeneous, the model specific samples compared to the variations of {\epsilon}-based sampling method.
AUTSL: A Large Scale Multi-modal Turkish Sign Language Dataset and Baseline Methods
Aug 03, 2020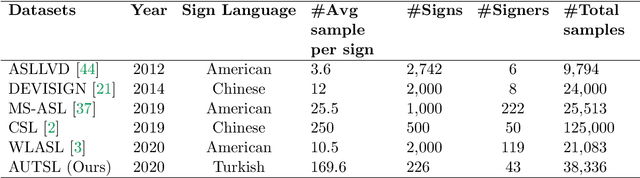

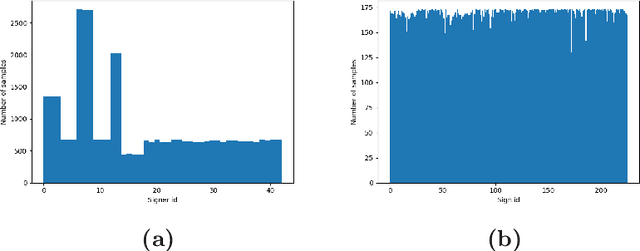

Sign language recognition is a challenging problem where signs are identified by simultaneous local and global articulations of multiple sources, i.e. hand shape and orientation, hand movements, body posture and facial expressions. Solving this problem computationally for a large vocabulary of signs in real life settings is still a challenge, even with the state-of-the-art models. In this study, we present a new large-scale multi-modal Turkish Sign Language dataset (AUTSL) with a benchmark and provide baseline models for performance evaluations. Our dataset consists of 226 signs performed by 43 different signers and 38,336 isolated sign video samples in total. Samples contain a wide variety of backgrounds recorded in indoor and outdoor environments. Moreover, spatial positions and the postures of signers also vary in the recordings. Each sample is recorded with Microsoft Kinect v2 and contains color image (RGB), depth and skeleton data modalities. We prepared benchmark training and test sets for user independent assessments of the models. We trained several deep learning based models and provide empirical evaluations using the benchmark; we used Convolutional Neural Networks (CNNs) to extract features, unidirectional and bidirectional Long Short-Term Memory (LSTM) models to characterize temporal information. We also incorporated feature pooling modules and temporal attention to our models to improve the performances. Using the benchmark test set, we obtained 62.02% accuracy with RGB+Depth data and 47.62% accuracy with RGB only data with the CNN+FPM+BLSTM+Attention model. Our dataset will be made publicly available at https://cvml.ankara.edu.tr.
Set Distribution Networks: a Generative Model for Sets of Images
Jun 18, 2020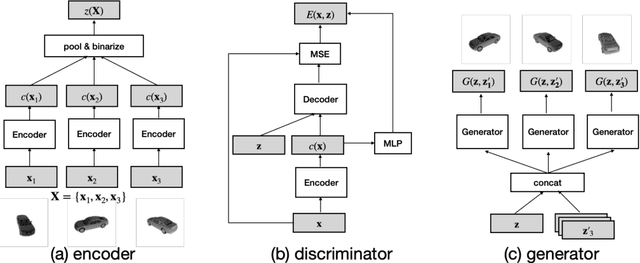
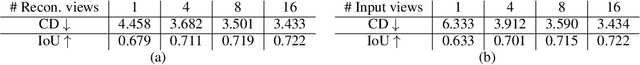


Images with shared characteristics naturally form sets. For example, in a face verification benchmark, images of the same identity form sets. For generative models, the standard way of dealing with sets is to represent each as a one hot vector, and learn a conditional generative model $p(\mathbf{x}|\mathbf{y})$. This representation assumes that the number of sets is limited and known, such that the distribution over sets reduces to a simple multinomial distribution. In contrast, we study a more generic problem where the number of sets is large and unknown. We introduce Set Distribution Networks (SDNs), a novel framework that learns to autoencode and freely generate sets. We achieve this by jointly learning a set encoder, set discriminator, set generator, and set prior. We show that SDNs are able to reconstruct image sets that preserve salient attributes of the inputs in our benchmark datasets, and are also able to generate novel objects/identities. We examine the sets generated by SDN with a pre-trained 3D reconstruction network and a face verification network, respectively, as a novel way to evaluate the quality of generated sets of images.
SemanticAdv: Generating Adversarial Examples via Attribute-conditional Image Editing
Jun 19, 2019

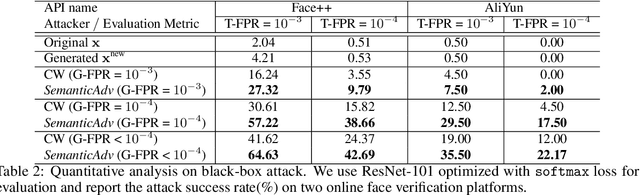
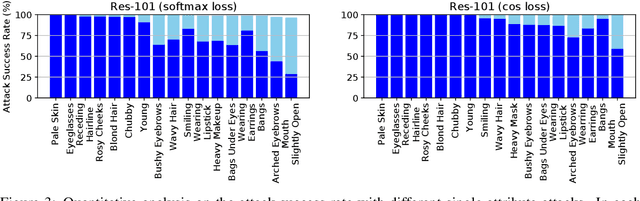
Deep neural networks (DNNs) have achieved great success in various applications due to their strong expressive power. However, recent studies have shown that DNNs are vulnerable to adversarial examples which are manipulated instances targeting to mislead DNNs to make incorrect predictions. Currently, most such adversarial examples try to guarantee "subtle perturbation" by limiting its $L_p$ norm. In this paper, we aim to explore the impact of semantic manipulation on DNNs predictions by manipulating the semantic attributes of images and generate "unrestricted adversarial examples". Such semantic based perturbation is more practical compared with pixel level manipulation. In particular, we propose an algorithm SemanticAdv which leverages disentangled semantic factors to generate adversarial perturbation via altering either single or a combination of semantic attributes. We conduct extensive experiments to show that the semantic based adversarial examples can not only fool different learning tasks such as face verification and landmark detection, but also achieve high attack success rate against real-world black-box services such as Azure face verification service. Such structured adversarial examples with controlled semantic manipulation can shed light on further understanding about vulnerabilities of DNNs as well as potential defensive approaches.
A deep active learning system for species identification and counting in camera trap images
Oct 22, 2019

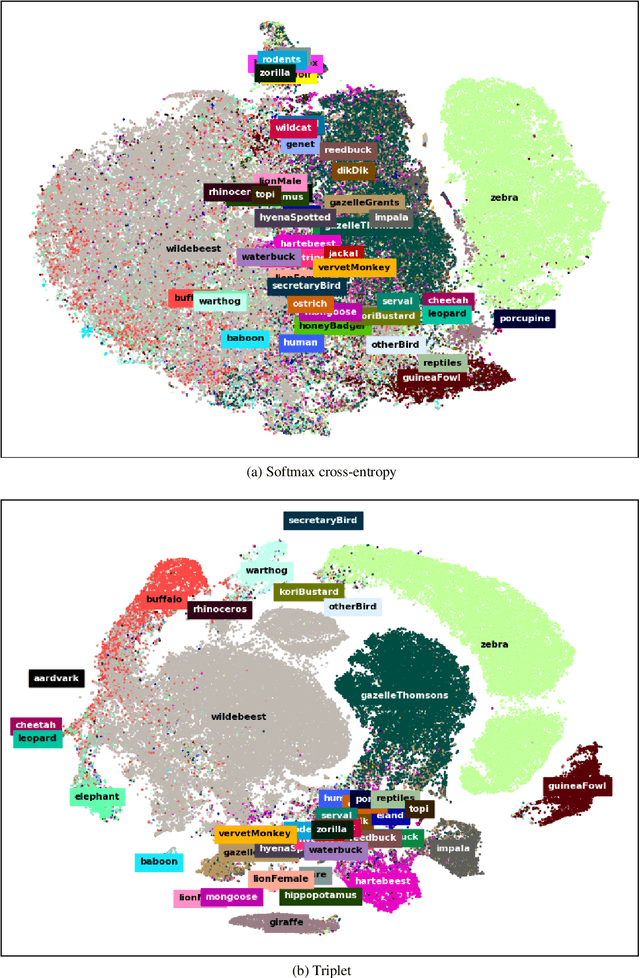
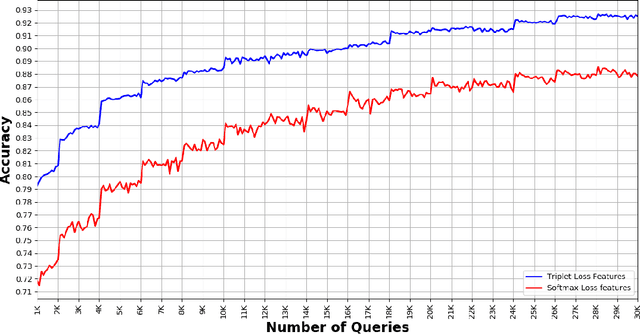
Biodiversity conservation depends on accurate, up-to-date information about wildlife population distributions. Motion-activated cameras, also known as camera traps, are a critical tool for population surveys, as they are cheap and non-intrusive. However, extracting useful information from camera trap images is a cumbersome process: a typical camera trap survey may produce millions of images that require slow, expensive manual review. Consequently, critical information is often lost due to resource limitations, and critical conservation questions may be answered too slowly to support decision-making. Computer vision is poised to dramatically increase efficiency in image-based biodiversity surveys, and recent studies have harnessed deep learning techniques for automatic information extraction from camera trap images. However, the accuracy of results depends on the amount, quality, and diversity of the data available to train models, and the literature has focused on projects with millions of relevant, labeled training images. Many camera trap projects do not have a large set of labeled images and hence cannot benefit from existing machine learning techniques. Furthermore, even projects that do have labeled data from similar ecosystems have struggled to adopt deep learning methods because image classification models overfit to specific image backgrounds (i.e., camera locations). In this paper, we focus not on automating the labeling of camera trap images, but on accelerating this process. We combine the power of machine intelligence and human intelligence to build a scalable, fast, and accurate active learning system to minimize the manual work required to identify and count animals in camera trap images. Our proposed scheme can match the state of the art accuracy on a 3.2 million image dataset with as few as 14,100 manual labels, which means decreasing manual labeling effort by over 99.5%.
Neural Human Video Rendering: Joint Learning of Dynamic Textures and Rendering-to-Video Translation
Jan 14, 2020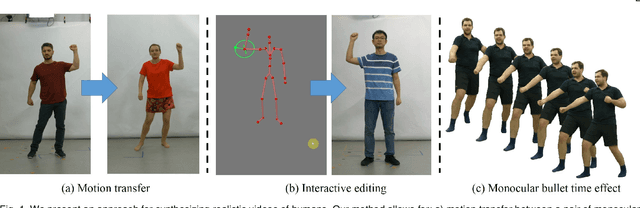
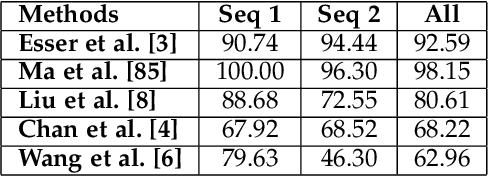
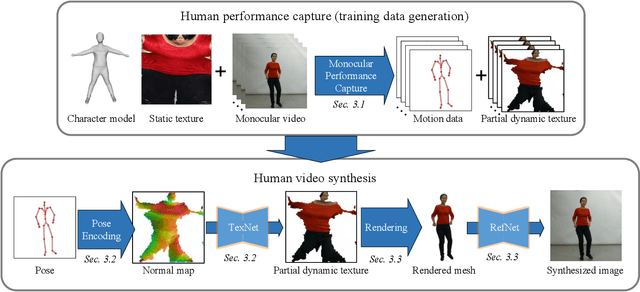
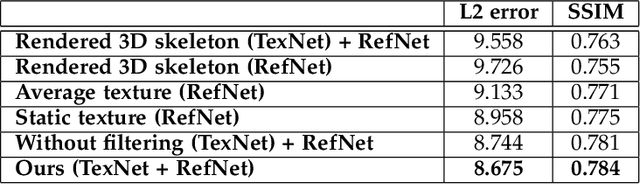
Synthesizing realistic videos of humans using neural networks has been a popular alternative to the conventional graphics-based rendering pipeline due to its high efficiency. Existing works typically formulate this as an image-to-image translation problem in 2D screen space, which leads to artifacts such as over-smoothing, missing body parts, and temporal instability of fine-scale detail, such as pose-dependent wrinkles in the clothing. In this paper, we propose a novel human video synthesis method that approaches these limiting factors by explicitly disentangling the learning of time-coherent fine-scale details from the embedding of the human in 2D screen space. More specifically, our method relies on the combination of two convolutional neural networks (CNNs). Given the pose information, the first CNN predicts a dynamic texture map that contains time-coherent high-frequency details, and the second CNN conditions the generation of the final video on the temporally coherent output of the first CNN. We demonstrate several applications of our approach, such as human reenactment and novel view synthesis from monocular video, where we show significant improvement over the state of the art both qualitatively and quantitatively.
Multimodal Age and Gender Classification Using Ear and Profile Face Images
Jul 23, 2019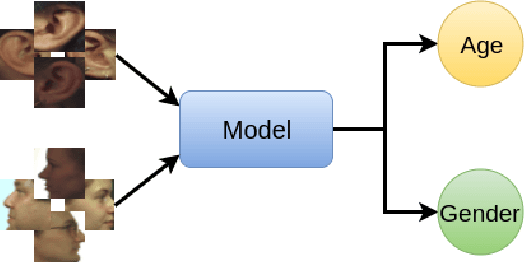

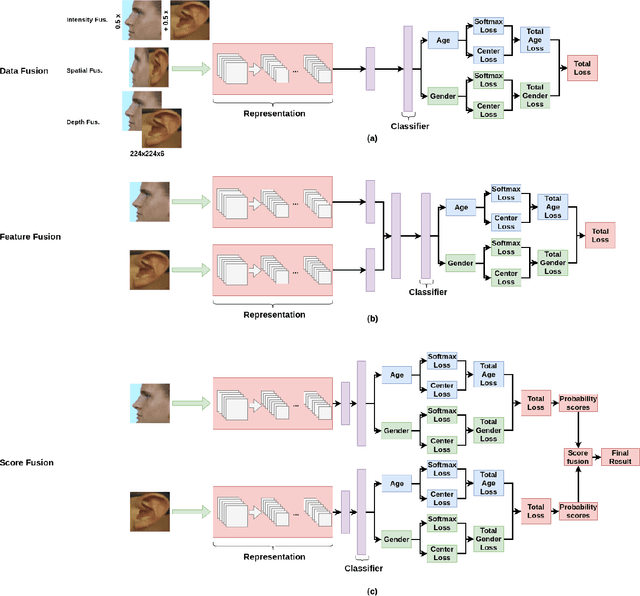
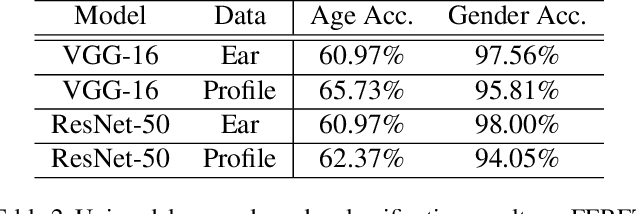
In this paper, we present multimodal deep neural network frameworks for age and gender classification, which take input a profile face image as well as an ear image. Our main objective is to enhance the accuracy of soft biometric trait extraction from profile face images by additionally utilizing a promising biometric modality: ear appearance. For this purpose, we provided end-to-end multimodal deep learning frameworks. We explored different multimodal strategies by employing data, feature, and score level fusion. To increase representation and discrimination capability of the deep neural networks, we benefited from domain adaptation and employed center loss besides softmax loss. We conducted extensive experiments on the UND-F, UND-J2, and FERET datasets. Experimental results indicated that profile face images contain a rich source of information for age and gender classification. We found that the presented multimodal system achieves very high age and gender classification accuracies. Moreover, we attained superior results compared to the state-of-the-art profile face image or ear image-based age and gender classification methods.