 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep 3D Pan via adaptive "t-shaped" convolutions with global and local adaptive dilations
Oct 02, 2019

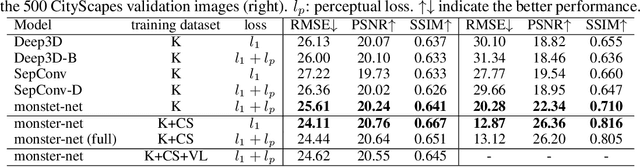
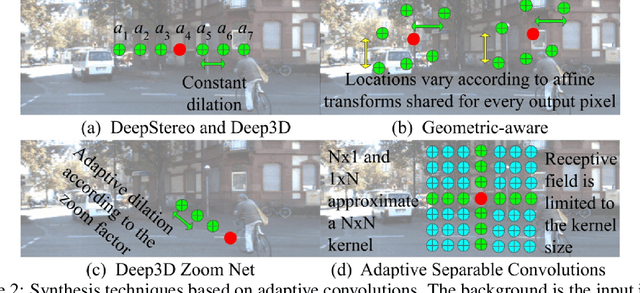
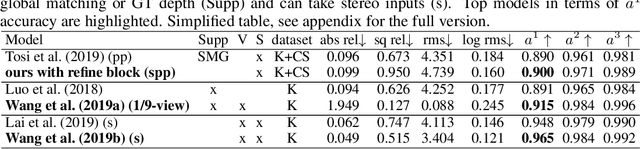
Recent advances in deep learning have shown promising results in many low-level vision tasks. However, solving the single-image-based view synthesis is still an open problem. In particular, the generation of new images at parallel camera views given a single input image is of great interest, as it enables 3D visualization of the 2D input scenery. We propose a novel network architecture to perform stereoscopic view synthesis at arbitrary camera positions along the X-axis, or Deep 3D Pan, with "t-shaped" adaptive kernels equipped with globally and locally adaptive dilations. Our proposed network architecture, the monster-net, is devised with a novel "t-shaped" adaptive kernel with globally and locally adaptive dilation, which can efficiently incorporate global camera shift into and handle local 3D geometries of the target image's pixels for the synthesis of naturally looking 3D panned views when a 2-D input image is given. Extensive experiments were performed on the KITTI, CityScapes and our VICLAB_STEREO indoors dataset to prove the efficacy of our method. Our monster-net significantly outperforms the state-of-the-art method, SOTA, by a large margin in all metrics of RMSE, PSNR, and SSIM. Our proposed monster-net is capable of reconstructing more reliable image structures in synthesized images with coherent geometry. Moreover, the disparity information that can be extracted from the "t-shaped" kernel is much more reliable than that of the SOTA for the unsupervised monocular depth estimation task, confirming the effectiveness of our method.
Sperm Detection and Tracking in Phase-Contrast Microscopy Image Sequences using Deep Learning and Modified CSR-DCF
Feb 13, 2020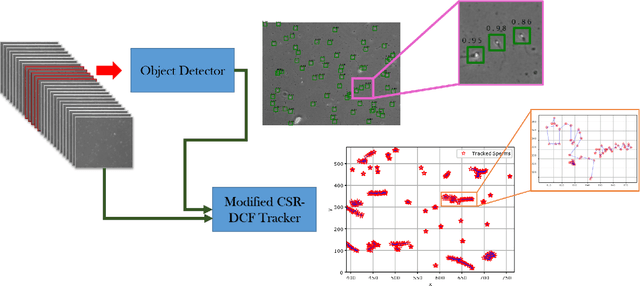
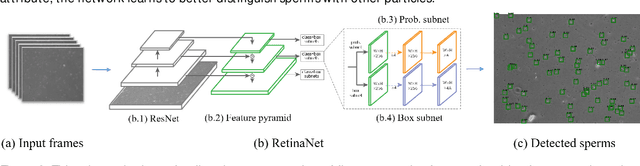
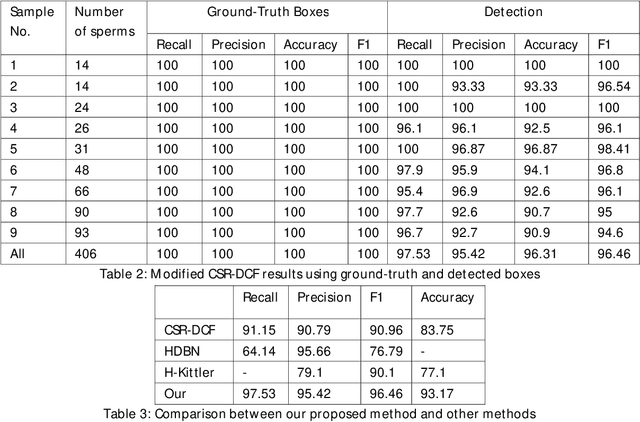
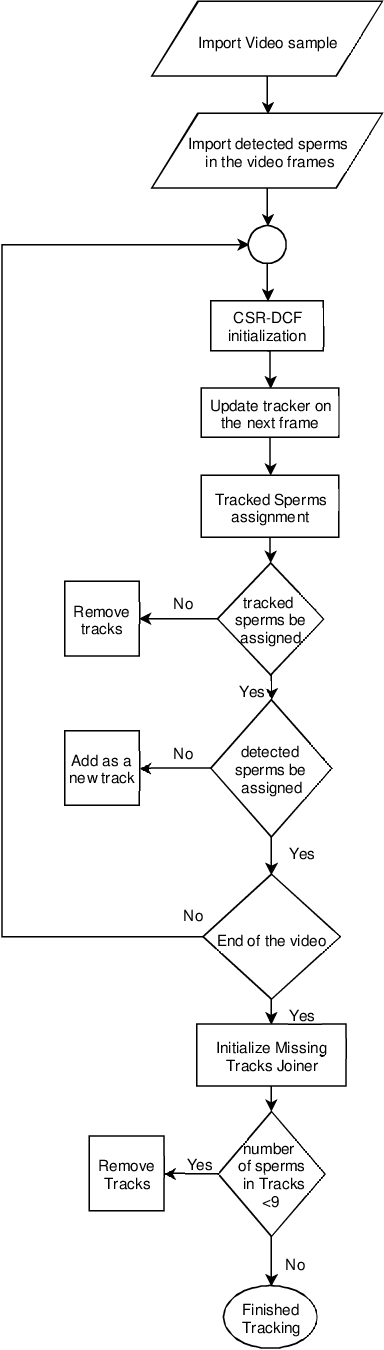
Nowadays, computer-aided sperm analysis (CASA) systems have made a big leap in extracting the characteristics of spermatozoa for studies or measuring human fertility. The first step in sperm characteristics analysis is sperm detection in the frames of the video sample. In this article, we used a deep fully convolutional network, as the object detector. Sperms are small objects with few attributes, that makes the detection more difficult in high-density samples and especially when there are other particles in semen, which could be like sperm heads. One of the main attributes of sperms is their movement, but this attribute cannot be extracted when only one frame would be fed to the network. To improve the performance of the sperm detection network, we concatenated some consecutive frames to use as the input of the network. With this method, the motility attribute has also been extracted, and then with the help of deep convolutional layers, we have achieved high accuracy in sperm detection. In the tracking phase, we modify the CSR-DCF algorithm. This method also has shown excellent results in sperm tracking even in high-density sperm samples, occlusions, sperm colliding, and when sperms exit from a frame and re-enter in the next frames. The average precision of the detection phase is 99.1%, and the F1 score of the tracking method evaluation is 97.06%. These results can be a great help in studies investigating sperm behavior and analyzing fertility possibility.
A Holistic Approach for Modeling and Synthesis of Image Processing Applications for Heterogeneous Computing Architectures
Feb 26, 2015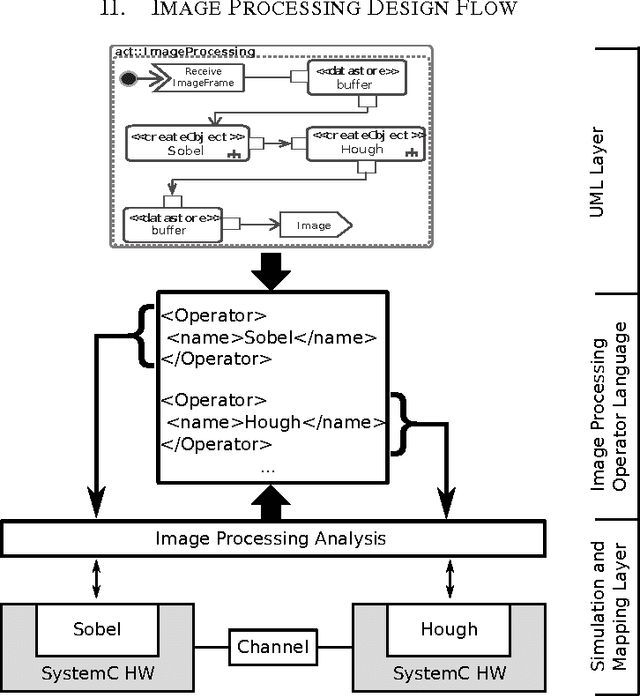
Image processing applications are common in every field of our daily life. However, most of them are very complex and contain several tasks with different complexities which result in varying requirements for computing architectures. Nevertheless, a general processing scheme in every image processing application has a similar structure, called image processing pipeline: (1) capturing an image, (2) pre-processing using local operators, (3) processing with global operators and (4) post-processing using complex operations. Therefore, application-specialized hardware solutions based on heterogeneous architectures are used for image processing. Unfortunately the development of applications for heterogeneous hardware architectures is challenging due to the distribution of computational tasks among processors and programmable logic units. Nowadays, image processing systems are started from scratch which is time-consuming, error-prone and inflexible. A new methodology for modeling and implementing is needed in order to reduce the development time of heterogenous image processing systems. This paper introduces a new holistic top down approach for image processing systems. Two challenges have to be investigated. First, designers ought to be able to model their complete image processing pipeline on an abstract layer using UML. Second, we want to close the gap between the abstract system and the system architecture.
Real-World Multi-Domain Data Applications for Generalizations to Clinical Settings
Jul 24, 2020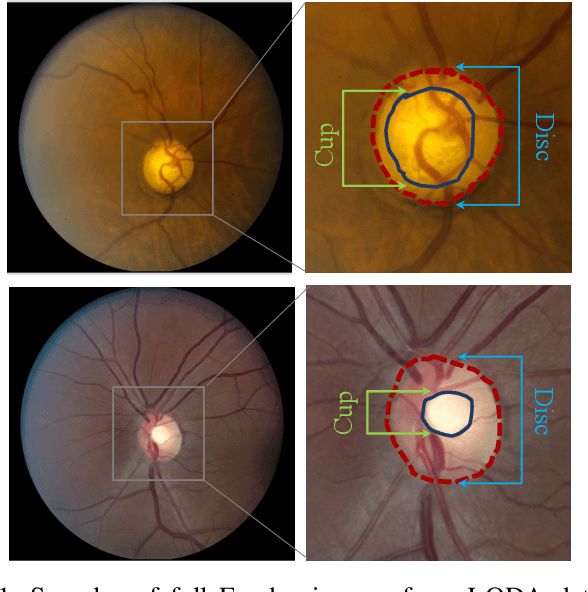
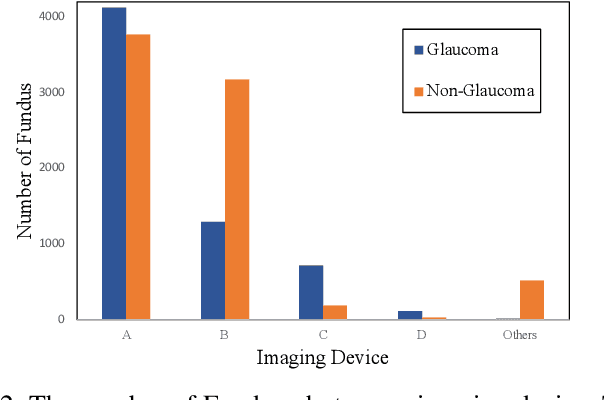
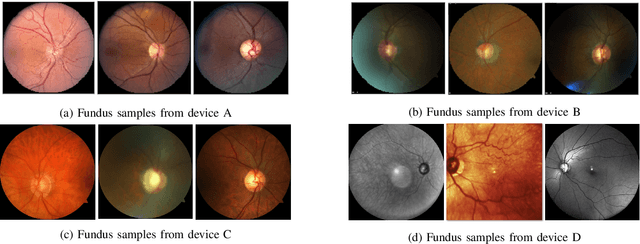
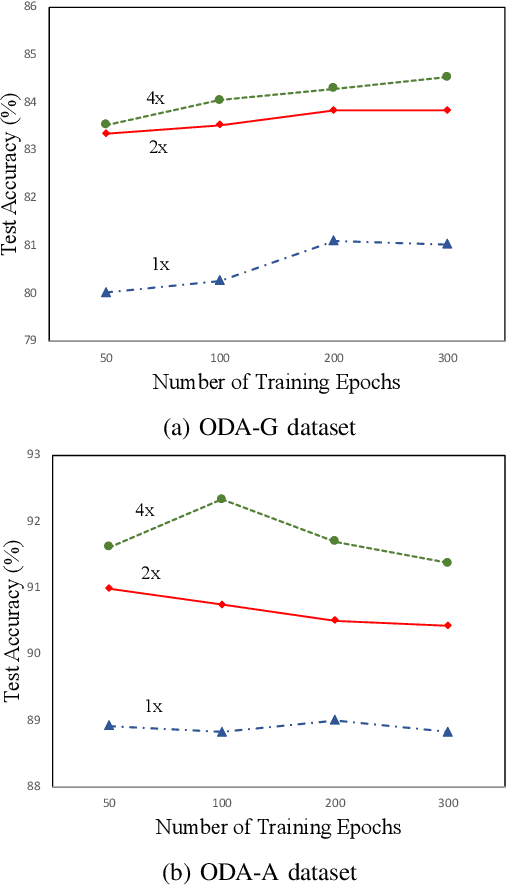
With promising results of machine learning based models in computer vision, applications on medical imaging data have been increasing exponentially. However, generalizations to complex real-world clinical data is a persistent problem. Deep learning models perform well when trained on standardized datasets from artificial settings, such as clinical trials. However, real-world data is different and translations are yielding varying results. The complexity of real-world applications in healthcare could emanate from a mixture of different data distributions across multiple device domains alongside the inevitable noise sourced from varying image resolutions, human errors, and the lack of manual gradings. In addition, healthcare applications not only suffer from the scarcity of labeled data, but also face limited access to unlabeled data due to HIPAA regulations, patient privacy, ambiguity in data ownership, and challenges in collecting data from different sources. These limitations pose additional challenges to applying deep learning algorithms in healthcare and clinical translations. In this paper, we utilize self-supervised representation learning methods, formulated effectively in transfer learning settings, to address limited data availability. Our experiments verify the importance of diverse real-world data for generalization to clinical settings. We show that by employing a self-supervised approach with transfer learning on a multi-domain real-world dataset, we can achieve 16% relative improvement on a standardized dataset over supervised baselines.
Active Contour Models for Manifold Valued Image Segmentation
Nov 11, 2013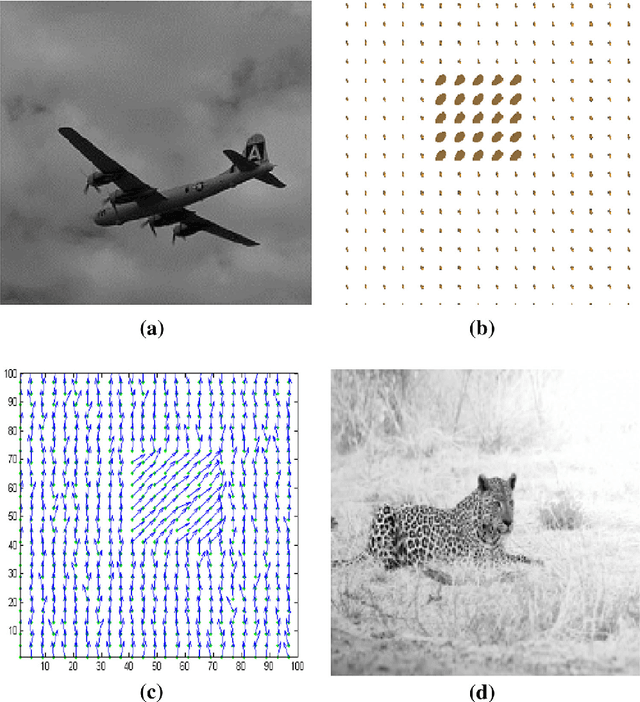
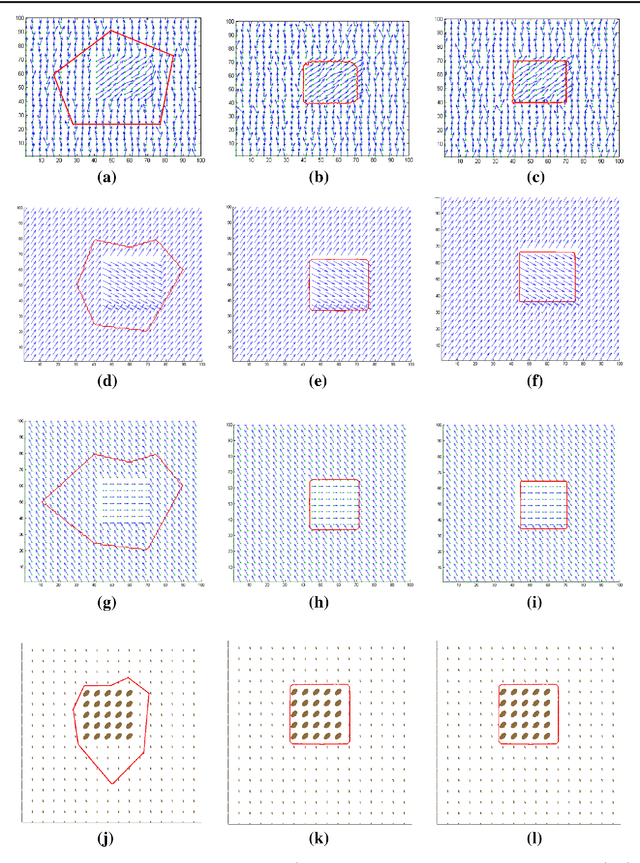
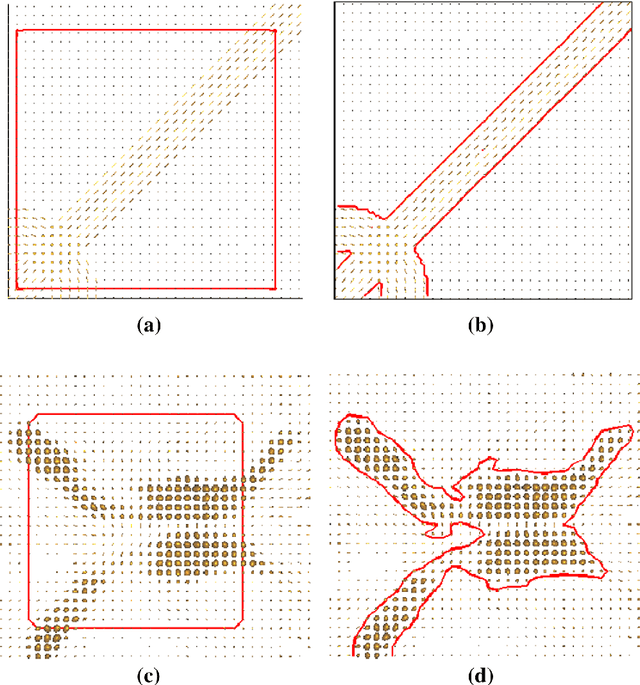
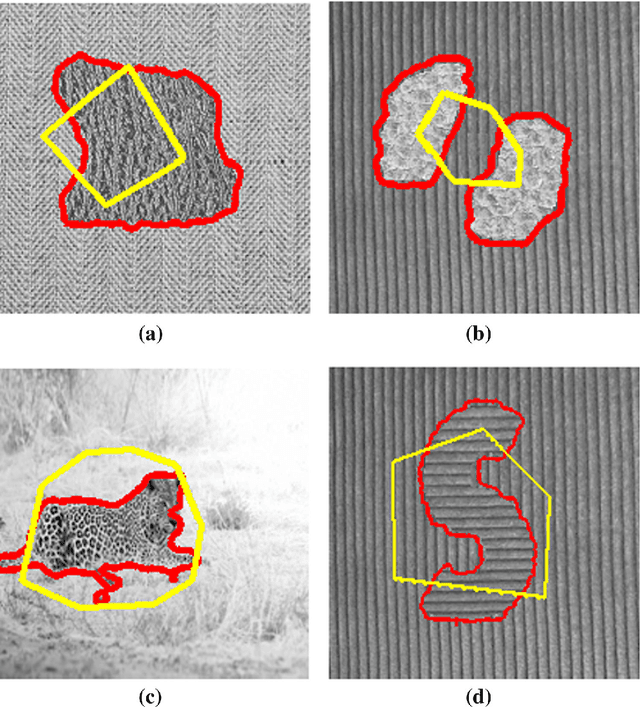
Image segmentation is the process of partitioning a image into different regions or groups based on some characteristics like color, texture, motion or shape etc. Active contours is a popular variational method for object segmentation in images, in which the user initializes a contour which evolves in order to optimize an objective function designed such that the desired object boundary is the optimal solution. Recently, imaging modalities that produce Manifold valued images have come up, for example, DT-MRI images, vector fields. The traditional active contour model does not work on such images. In this paper, we generalize the active contour model to work on Manifold valued images. As expected, our algorithm detects regions with similar Manifold values in the image. Our algorithm also produces expected results on usual gray-scale images, since these are nothing but trivial examples of Manifold valued images. As another application of our general active contour model, we perform texture segmentation on gray-scale images by first creating an appropriate Manifold valued image. We demonstrate segmentation results for manifold valued images and texture images.
Cross-Modality Attention with Semantic Graph Embedding for Multi-Label Classification
Dec 17, 2019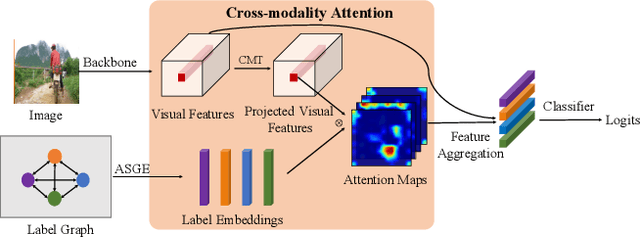
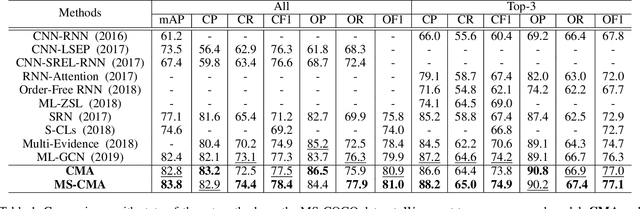
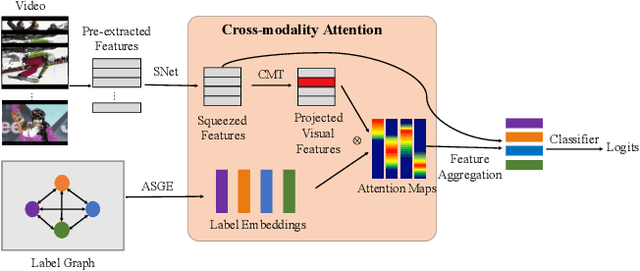
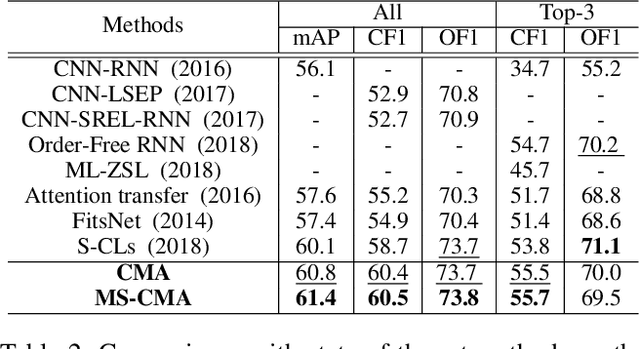
Multi-label image and video classification are fundamental yet challenging tasks in computer vision. The main challenges lie in capturing spatial or temporal dependencies between labels and discovering the locations of discriminative features for each class. In order to overcome these challenges, we propose to use cross-modality attention with semantic graph embedding for multi label classification. Based on the constructed label graph, we propose an adjacency-based similarity graph embedding method to learn semantic label embeddings, which explicitly exploit label relationships. Then our novel cross-modality attention maps are generated with the guidance of learned label embeddings. Experiments on two multi-label image classification datasets (MS-COCO and NUS-WIDE) show our method outperforms other existing state-of-the-arts. In addition, we validate our method on a large multi-label video classification dataset (YouTube-8M Segments) and the evaluation results demonstrate the generalization capability of our method.
Depth by Poking: Learning to Estimate Depth from Self-Supervised Grasping
Jun 16, 2020


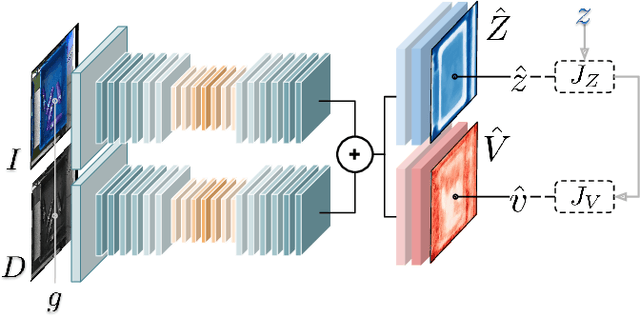
Accurate depth estimation remains an open problem for robotic manipulation; even state of the art techniques including structured light and LiDAR sensors fail on reflective or transparent surfaces. We address this problem by training a neural network model to estimate depth from RGB-D images, using labels from physical interactions between a robot and its environment. Our network predicts, for each pixel in an input image, the z position that a robot's end effector would reach if it attempted to grasp or poke at the corresponding position. Given an autonomous grasping policy, our approach is self-supervised as end effector position labels can be recovered through forward kinematics, without human annotation. Although gathering such physical interaction data is expensive, it is necessary for training and routine operation of state of the art manipulation systems. Therefore, this depth estimator comes ``for free'' while collecting data for other tasks (e.g., grasping, pushing, placing). We show our approach achieves significantly lower root mean squared error than traditional structured light sensors and unsupervised deep learning methods on difficult, industry-scale jumbled bin datasets.
Vehicle Re-ID for Surround-view Camera System
Jun 30, 2020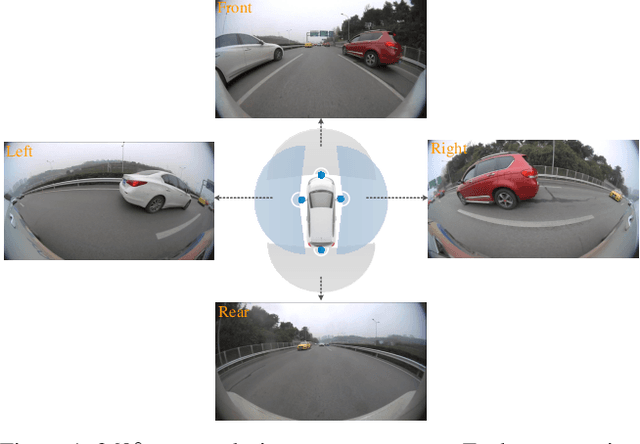
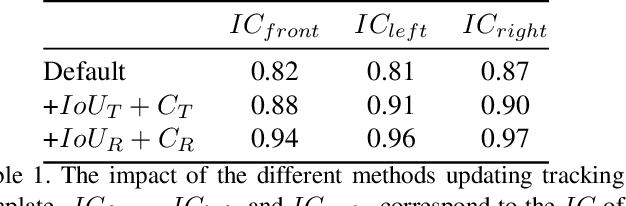

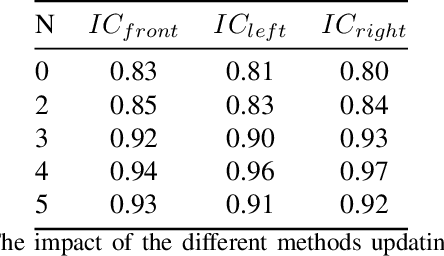
The vehicle re-identification (ReID) plays a critical role in the perception system of autonomous driving, which attracts more and more attention in recent years. However, to our best knowledge, there is no existing complete solution for the surround-view system mounted on the vehicle. In this paper, we argue two main challenges in above scenario: i) In single camera view, it is difficult to recognize the same vehicle from the past image frames due to the fisheye distortion, occlusion, truncation, etc. ii) In multi-camera view, the appearance of the same vehicle varies greatly from different camera's viewpoints. Thus, we present an integral vehicle Re-ID solution to address these problems. Specifically, we propose a novel quality evaluation mechanism to balance the effect of tracking box's drift and target's consistency. Besides, we take advantage of the Re-ID network based on attention mechanism, then combined with a spatial constraint strategy to further boost the performance between different cameras. The experiments demonstrate that our solution achieves state-of-the-art accuracy while being real-time in practice. Besides, we will release the code and annotated fisheye dataset for the benefit of community.
Thick Cloud Removal of Remote Sensing Images Using Temporal Smoothness and Sparsity-Regularized Tensor Optimization
Sep 01, 2020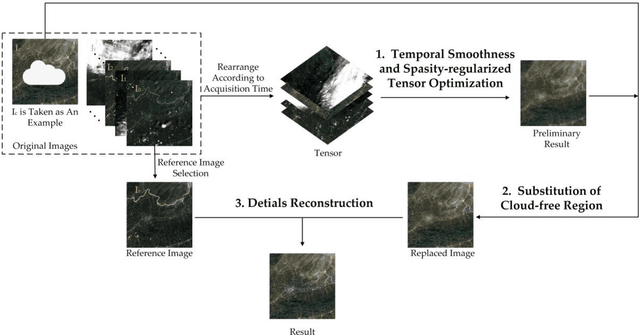
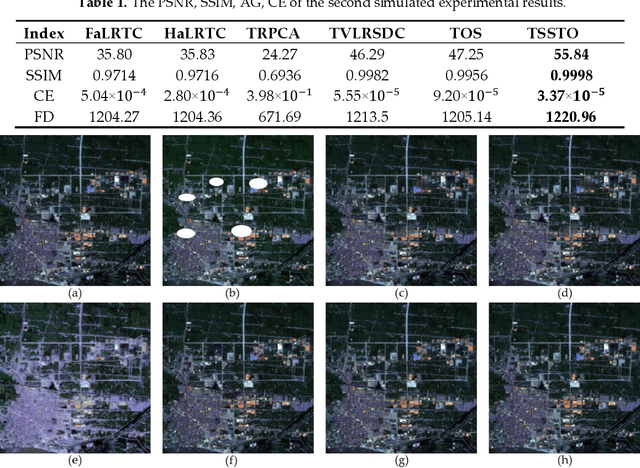


In remote sensing images, the presence of thick cloud accompanying cloud shadow is a high probability event, which can affect the quality of subsequent processing and limit the scenarios of application. Hence, removing the thick cloud and cloud shadow as well as recovering the cloud-contaminated pixels is indispensable to make good use of remote sensing images. In this paper, a novel thick cloud removal method for remote sensing images based on temporal smoothness and sparsity-regularized tensor optimization (TSSTO) is proposed. The basic idea of TSSTO is that the thick cloud and cloud shadow are not only sparse but also smooth along the horizontal and vertical direction in images while the clean images are smooth along the temporal direction between images. Therefore, the sparsity norm is used to boost the sparsity of the cloud and cloud shadow, and unidirectional total variation (UTV) regularizers are applied to ensure the unidirectional smoothness. This paper utilizes alternation direction method of multipliers to solve the presented model and generate the cloud and cloud shadow element as well as the clean element. The cloud and cloud shadow element is purified to get the cloud area and cloud shadow area. Then, the clean area of the original cloud-contaminated images is replaced to the corresponding area of the clean element. Finally, the reference image is selected to reconstruct details of the cloud area and cloud shadow area using the information cloning method. A series of experiments are conducted both on simulated and real cloud-contaminated images from different sensors and with different resolutions, and the results demonstrate the potential of the proposed TSSTO method for removing cloud and cloud shadow from both qualitative and quantitative viewpoints.
Pixel Invisibility: Detecting Objects Invisible in Color Images
Jun 16, 2020
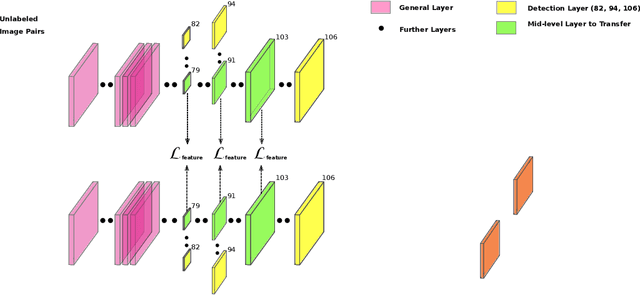

Despite recent success of object detectors using deep neural networks, their deployment on safety-critical applications such as self-driving cars remains questionable. This is partly due to the absence of reliable estimation for detectors' failure under operational conditions such as night, fog, dusk, dawn and glare. Such unquantifiable failures could lead to safety violations. In order to solve this problem, we created an algorithm that predicts a pixel-level invisibility map for color images that does not require manual labeling - that computes the probability that a pixel/region contains objects that are invisible in color domain, during various lighting conditions such as day, night and fog. We propose a novel use of cross modal knowledge distillation from color to infra-red domain using weakly-aligned image pairs from the day and construct indicators for the pixel-level invisibility based on the distances of their intermediate-level features. Quantitative experiments show the great performance of our pixel-level invisibility mask and also the effectiveness of distilled mid-level features on object detection in infra-red imagery.