 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Range Conditioned Dilated Convolutions for Scale Invariant 3D Object Detection
May 20, 2020
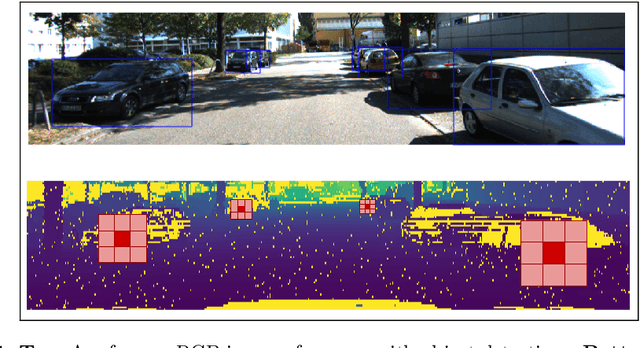

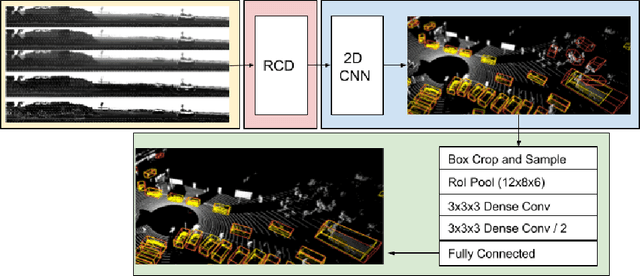
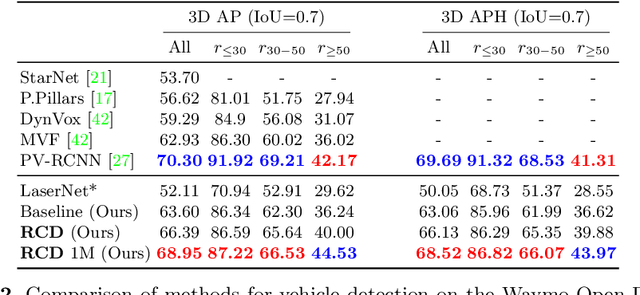
This paper presents a novel 3D object detection framework that processes LiDAR data directly on a representation of the sensor's native range images. When operating in the range image view, one faces learning challenges, including occlusion and considerable scale variation, limiting the obtainable accuracy. To address these challenges, a range-conditioned dilated block (RCD) is proposed to dynamically adjust a continuous dilation rate as a function of the measured range, achieving scale invariance. Furthermore, soft range gating helps mitigate the effect of occlusion. An end-to-end trained box-refinement network brings additional performance improvements in occluded areas, and produces more accurate bounding box predictions. On the challenging Waymo Open Dataset, our improved range-based detector outperforms state of the art at long range detection. Our framework is superior to prior multiview, voxel-based methods over all ranges, setting a new baseline for range-based 3D detection on this large scale public dataset.
DS6: Deformation-aware learning for small vessel segmentation with small, imperfectly labeled dataset
Jun 18, 2020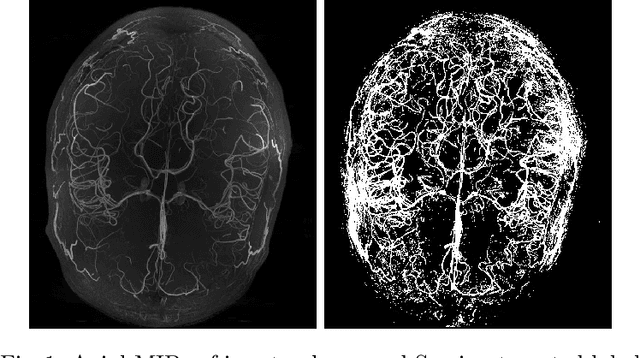
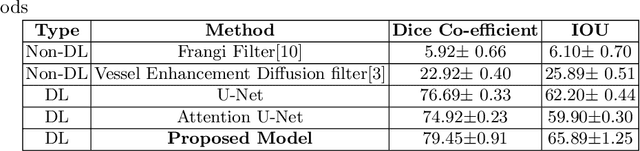


Originating from the initial segment of the middle cerebral artery of the human brain, Lenticulostriate Arteries (LSA) are a collection of perforating vessels that supply blood to the basal ganglia region. With the advancement of 7 Tesla scanner, we are able to detect these LSA which are linked to Small Vessel Diseases(SVD) and potentially a cause for neurodegenerative diseases. Segmentation of LSA with traditional approaches like Frangi or semi-automated/manual techniques can depict medium to large vessels but fail to depict the small vessels. Also, semi-automated/manual approaches are time-consuming. In this paper, we put forth a study that incorporates deep learning techniques to automatically segment these LSA using 3D 7 Tesla Time-of-fight Magnetic Resonance Angiogram images. The algorithm is trained and evaluated on a small dataset of 11 volumes. Deep learning models based on Multi-Scale Supervision U-Net accompanied by elastic deformations to give equivariance to the model, were utilized for the vessel segmentation using semi-automated labeled images. We make a qualitative analysis of the output with the original image and also on imperfect semi-manual labels to confirm the presence and continuity of small vessels.
Predicting Goal-directed Attention Control Using Inverse-Reinforcement Learning
Jan 31, 2020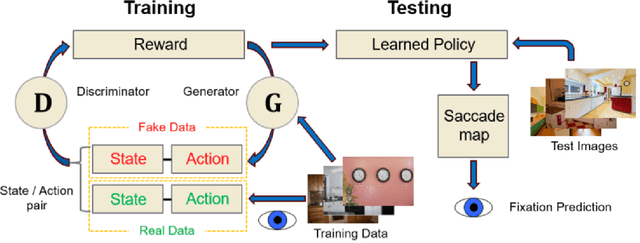



Understanding how goal states control behavior is a question ripe for interrogation by new methods from machine learning. These methods require large and labeled datasets to train models. To annotate a large-scale image dataset with observed search fixations, we collected 16,184 fixations from people searching for either microwaves or clocks in a dataset of 4,366 images (MS-COCO). We then used this behaviorally-annotated dataset and the machine learning method of Inverse-Reinforcement Learning (IRL) to learn target-specific reward functions and policies for these two target goals. Finally, we used these learned policies to predict the fixations of 60 new behavioral searchers (clock = 30, microwave = 30) in a disjoint test dataset of kitchen scenes depicting both a microwave and a clock (thus controlling for differences in low-level image contrast). We found that the IRL model predicted behavioral search efficiency and fixation-density maps using multiple metrics. Moreover, reward maps from the IRL model revealed target-specific patterns that suggest, not just attention guidance by target features, but also guidance by scene context (e.g., fixations along walls in the search of clocks). Using machine learning and the psychologically-meaningful principle of reward, it is possible to learn the visual features used in goal-directed attention control.
Set Distribution Networks: a Generative Model for Sets of Images
Jun 18, 2020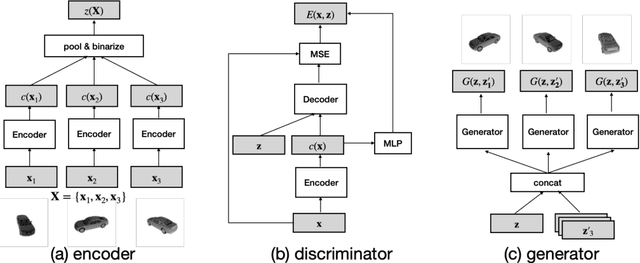


Images with shared characteristics naturally form sets. For example, in a face verification benchmark, images of the same identity form sets. For generative models, the standard way of dealing with sets is to represent each as a one hot vector, and learn a conditional generative model $p(\mathbf{x}|\mathbf{y})$. This representation assumes that the number of sets is limited and known, such that the distribution over sets reduces to a simple multinomial distribution. In contrast, we study a more generic problem where the number of sets is large and unknown. We introduce Set Distribution Networks (SDNs), a novel framework that learns to autoencode and freely generate sets. We achieve this by jointly learning a set encoder, set discriminator, set generator, and set prior. We show that SDNs are able to reconstruct image sets that preserve salient attributes of the inputs in our benchmark datasets, and are also able to generate novel objects/identities. We examine the sets generated by SDN with a pre-trained 3D reconstruction network and a face verification network, respectively, as a novel way to evaluate the quality of generated sets of images.
Adaptive Weighting Depth-variant Deconvolution of Fluorescence Microscopy Images with Convolutional Neural Network
Jul 07, 2019

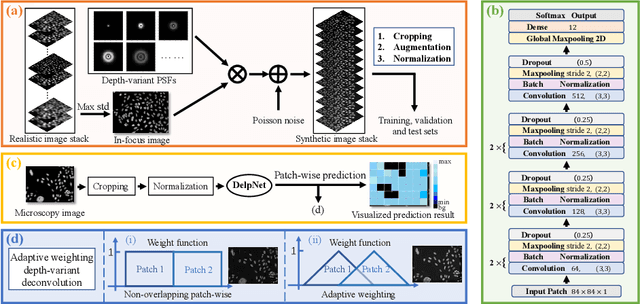
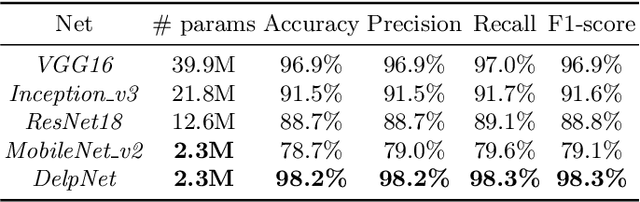
Fluorescence microscopy plays an important role in biomedical research. The depth-variant point spread function (PSF) of a fluorescence microscope produces low-quality images especially in the out-of-focus regions of thick specimens. Traditional deconvolution to restore the out-of-focus images is usually insufficient since a depth-invariant PSF is assumed. This article aims at handling fluorescence microscopy images by learning-based depth-variant PSF and reducing artifacts. We propose adaptive weighting depth-variant deconvolution (AWDVD) with defocus level prediction convolutional neural network (DelpNet) to restore the out-of-focus images. Depth-variant PSFs of image patches can be obtained by DelpNet and applied in the afterward deconvolution. AWDVD is adopted for a whole image which is patch-wise deconvolved and appropriately cropped before deconvolution. DelpNet achieves the accuracy of 98.2%, which outperforms the best-ever one using the same microscopy dataset. Image patches of 11 defocus levels after deconvolution are validated with maximum improvement in the peak signal-to-noise ratio and structural similarity index of 6.6 dB and 11%, respectively. The adaptive weighting of the patch-wise deconvolved image can eliminate patch boundary artifacts and improve deconvolved image quality. The proposed method can accurately estimate depth-variant PSF and effectively recover out-of-focus microscopy images. To our acknowledge, this is the first study of handling out-of-focus microscopy images using learning-based depth-variant PSF. Facing one of the most common blurs in fluorescence microscopy, the novel method provides a practical technology to improve the image quality.
Content Based Image Retrieval from AWiFS Images Repository of IRS Resourcesat-2 Satellite Based on Water Bodies and Burnt Areas
Sep 26, 2018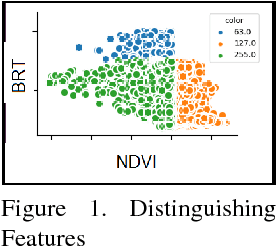
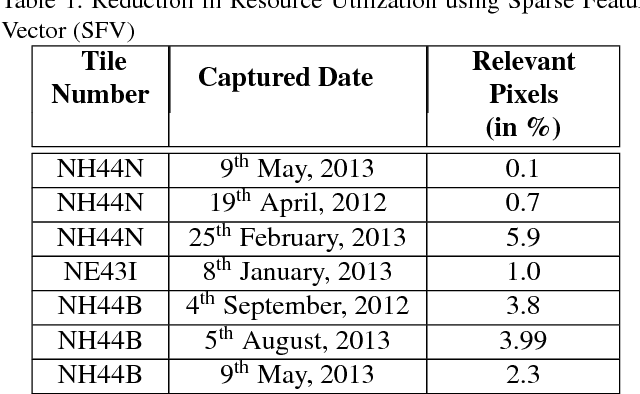
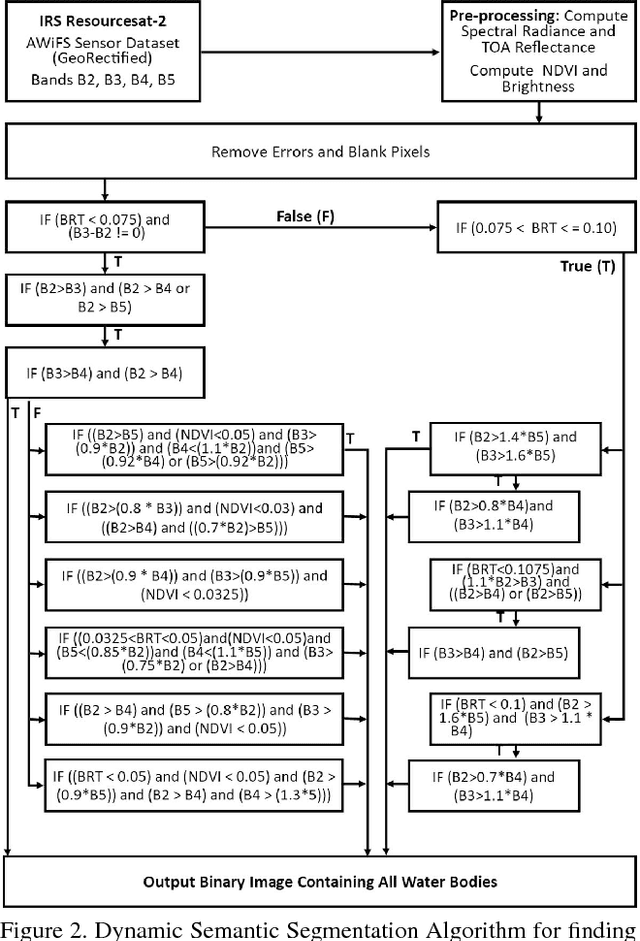
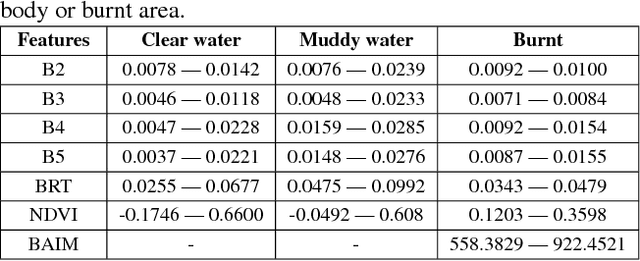
Satellite Remote Sensing Technology is becoming a major milestone in the prediction of weather anomalies, natural disasters as well as finding alternative resources in proximity using multiple multi-spectral sensors emitting electromagnetic waves at distinct wavelengths. Hence, it is imperative to extract water bodies and burnt areas from orthorectified tiles and correspondingly rank them using similarity measures. Different objects in all the spheres of the earth have the inherent capability of absorbing electromagnetic waves of distant wavelengths. This creates various unique masks in terms of reflectance on the receptor. We propose Dynamic Semantic Segmentation (DSS) algorithms that utilized the mentioned capability to extract and rank Advanced Wide Field Sensor (AWiFS) images according to various features. This system stores data intelligently in the form of a sparse feature vector which drastically mitigates the computational and spatial costs incurred for further analysis. The compressed source image is divided into chunks and stored in the database for quicker retrieval. This work is intended to utilize readily available and cost effective resources like AWiFS dataset instead of depending on advanced technologies like Moderate Resolution Imaging Spectroradiometer (MODIS) for data which is scarce.
Feature Weighting and Boosting for Few-Shot Segmentation
Sep 28, 2019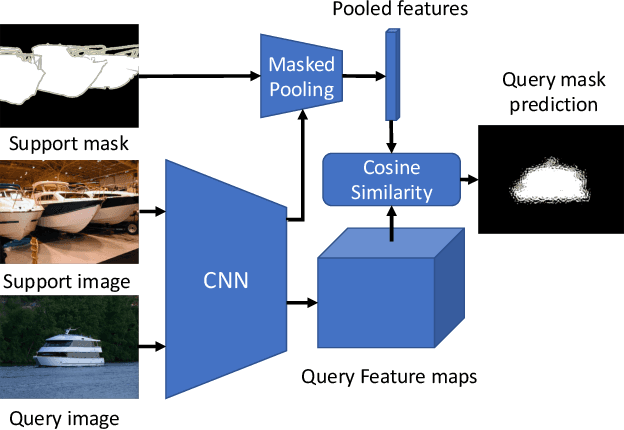
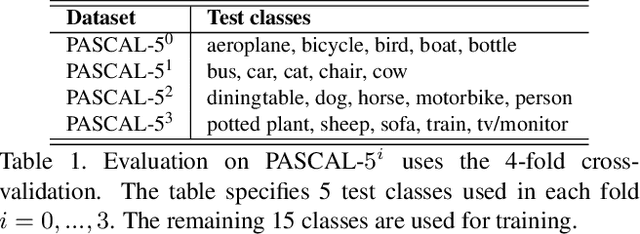
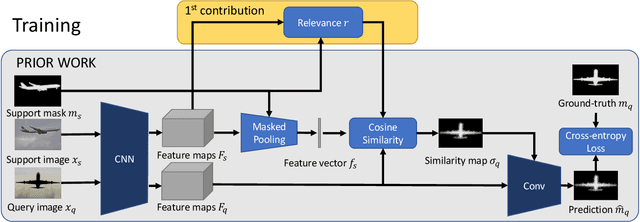
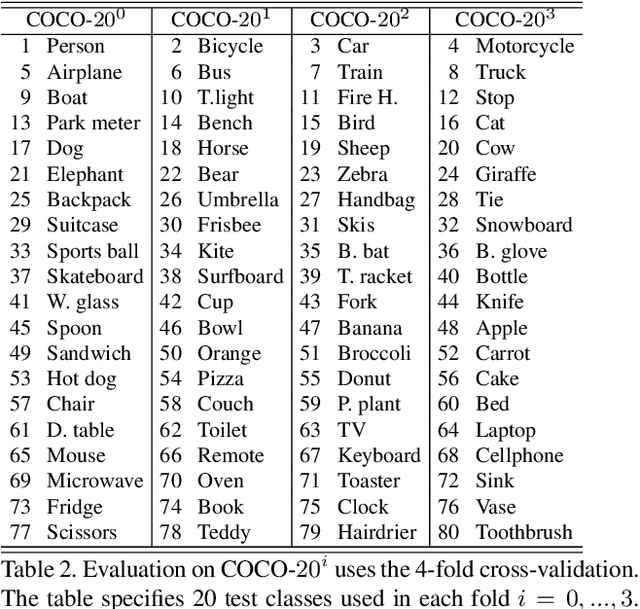
This paper is about few-shot segmentation of foreground objects in images. We train a CNN on small subsets of training images, each mimicking the few-shot setting. In each subset, one image serves as the query and the other(s) as support image(s) with ground-truth segmentation. The CNN first extracts feature maps from the query and support images. Then, a class feature vector is computed as an average of the support's feature maps over the known foreground. Finally, the target object is segmented in the query image by using a cosine similarity between the class feature vector and the query's feature map. We make two contributions by: (1) Improving discriminativeness of features so their activations are high on the foreground and low elsewhere; and (2) Boosting inference with an ensemble of experts guided with the gradient of loss incurred when segmenting the support images in testing. Our evaluations on the PASCAL-$5^i$ and COCO-$20^i$ datasets demonstrate that we significantly outperform existing approaches.
Streaming convolutional neural networks for end-to-end learning with multi-megapixel images
Nov 11, 2019



Due to memory constraints on current hardware, most convolution neural networks (CNN) are trained on sub-megapixel images. For example, most popular datasets in computer vision contain images much less than a megapixel in size (0.09MP for ImageNet and 0.001MP for CIFAR-10). In some domains such as medical imaging, multi-megapixel images are needed to identify the presence of disease accurately. We propose a novel method to directly train convolutional neural networks using any input image size end-to-end. This method exploits the locality of most operations in modern convolutional neural networks by performing the forward and backward pass on smaller tiles of the image. In this work, we show a proof of concept using images of up to 66-megapixels (8192x8192), saving approximately 50GB of memory per image. Using two public challenge datasets, we demonstrate that CNNs can learn to extract relevant information from these large images and benefit from increasing resolution. We improved the area under the receiver-operating characteristic curve from 0.580 (4MP) to 0.706 (66MP) for metastasis detection in breast cancer (CAMELYON17). We also obtained a Spearman correlation metric approaching state-of-the-art performance on the TUPAC16 dataset, from 0.485 (1MP) to 0.570 (16MP). Code to reproduce a subset of the experiments is available at https://github.com/DIAGNijmegen/StreamingCNN.
Full-reference image quality assessment by combining global and local distortion measures
Dec 17, 2014


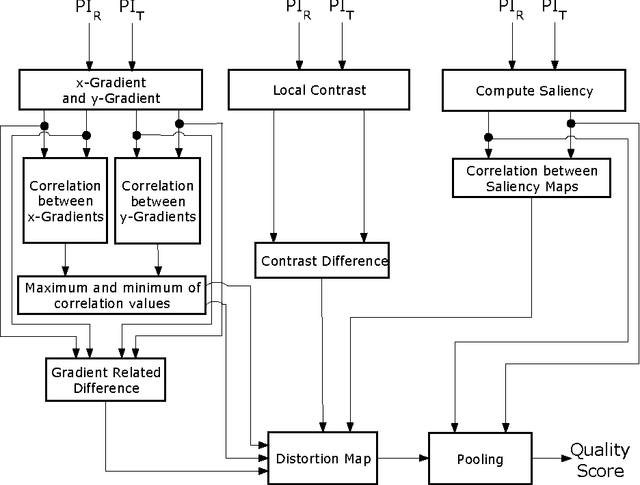
Full-reference image quality assessment (FR-IQA) techniques compare a reference and a distorted/test image and predict the perceptual quality of the test image in terms of a scalar value representing an objective score. The evaluation of FR-IQA techniques is carried out by comparing the objective scores from the techniques with the subjective scores (obtained from human observers) provided in the image databases used for the IQA. Hence, we reasonably assume that the goal of a human observer is to rate the distortion present in the test image. The goal oriented tasks are processed by the human visual system (HVS) through top-down processing which actively searches for local distortions driven by the goal. Therefore local distortion measures in an image are important for the top-down processing. At the same time, bottom-up processing also takes place signifying spontaneous visual functions in the HVS. To account for this, global perceptual features can be used. Therefore, we hypothesize that the resulting objective score for an image can be derived from the combination of local and global distortion measures calculated from the reference and test images. We calculate the local distortion by measuring the local correlation differences from the gradient and contrast information. For global distortion, dissimilarity of the saliency maps computed from a bottom-up model of saliency is used. The motivation behind the proposed approach has been thoroughly discussed, accompanied by an intuitive analysis. Finally, experiments are conducted in six benchmark databases suggesting the effectiveness of the proposed approach that achieves competitive performance with the state-of-the-art methods providing an improvement in the overall performance.
Generating Relevant Counter-Examples from a Positive Unlabeled Dataset for Image Classification
Oct 04, 2019

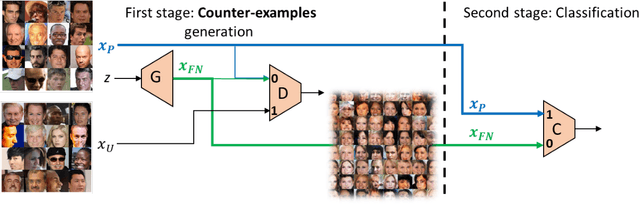

With surge of available but unlabeled data, Positive Unlabeled (PU) learning is becoming a thriving challenge. This work deals with this demanding task for which recent GAN-based PU approaches have demonstrated promising results. Generative adversarial Networks (GANs) are not hampered by deterministic bias or need for specific dimensionality. However, existing GAN-based PU approaches also present some drawbacks such as sensitive dependence to prior knowledge, a cumbersome architecture or first-stage overfitting. To settle these issues, we propose to incorporate a biased PU risk within the standard GAN discriminator loss function. In this manner, the discriminator is constrained to request the generator to converge towards the unlabeled samples distribution while diverging from the positive samples distribution. This enables the proposed model, referred to as D-GAN, to exclusively learn the counter-examples distribution without prior knowledge. Experiments demonstrate that our approach outperforms state-of-the-art PU methods without prior by overcoming their issues.