 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TIBET: Identifying and Evaluating Biases in Text-to-Image Generative Models
Dec 03, 2023
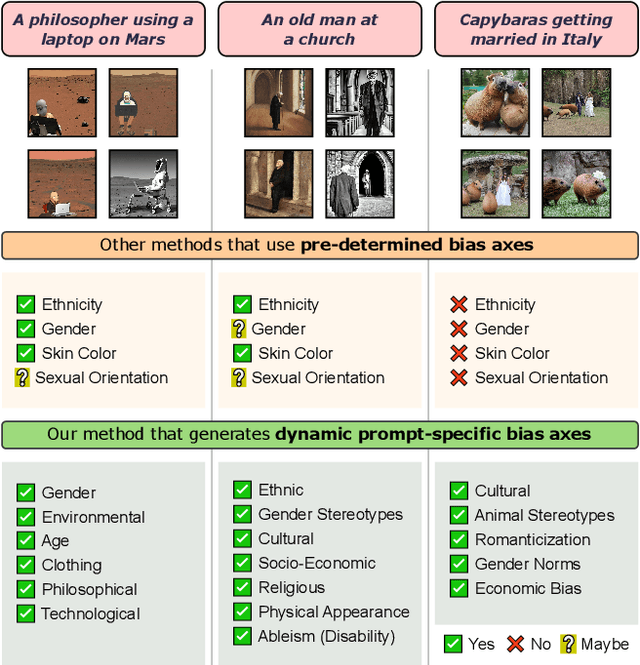
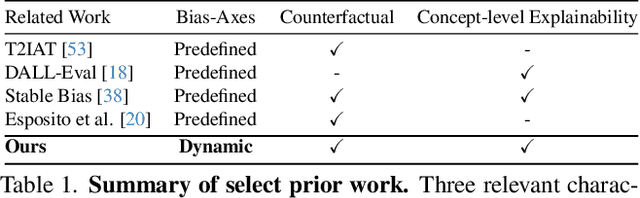
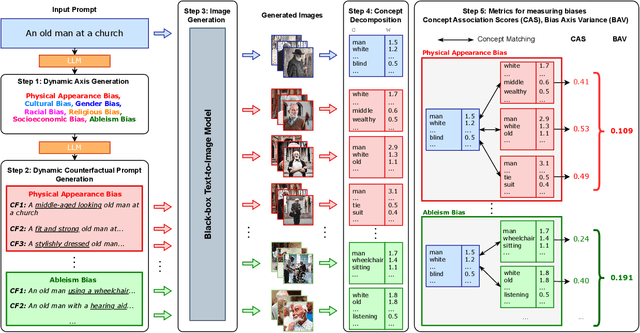
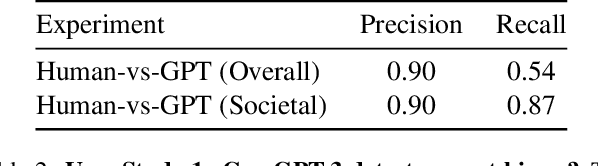
Text-to-Image (TTI) generative models have shown great progress in the past few years in terms of their ability to generate complex and high-quality imagery. At the same time, these models have been shown to suffer from harmful biases, including exaggerated societal biases (e.g., gender, ethnicity), as well as incidental correlations that limit such model's ability to generate more diverse imagery. In this paper, we propose a general approach to study and quantify a broad spectrum of biases, for any TTI model and for any prompt, using counterfactual reasoning. Unlike other works that evaluate generated images on a predefined set of bias axes, our approach automatically identifies potential biases that might be relevant to the given prompt, and measures those biases. In addition, our paper extends quantitative scores with post-hoc explanations in terms of semantic concepts in the images generated. We show that our method is uniquely capable of explaining complex multi-dimensional biases through semantic concepts, as well as the intersectionality between different biases for any given prompt. We perform extensive user studies to illustrate that the results of our method and analysis are consistent with human judgements.
NeuroPrompts: An Adaptive Framework to Optimize Prompts for Text-to-Image Generation
Nov 20, 2023Despite impressive recent advances in text-to-image diffusion models, obtaining high-quality images often requires prompt engineering by humans who have developed expertise in using them. In this work, we present NeuroPrompts, an adaptive framework that automatically enhances a user's prompt to improve the quality of generations produced by text-to-image models. Our framework utilizes constrained text decoding with a pre-trained language model that has been adapted to generate prompts similar to those produced by human prompt engineers. This approach enables higher-quality text-to-image generations and provides user control over stylistic features via constraint set specification. We demonstrate the utility of our framework by creating an interactive application for prompt enhancement and image generation using Stable Diffusion. Additionally, we conduct experiments utilizing a large dataset of human-engineered prompts for text-to-image generation and show that our approach automatically produces enhanced prompts that result in superior image quality. We make our code, a screencast video demo and a live demo instance of NeuroPrompts publicly available.
Promise:Prompt-driven 3D Medical Image Segmentation Using Pretrained Image Foundation Models
Nov 13, 2023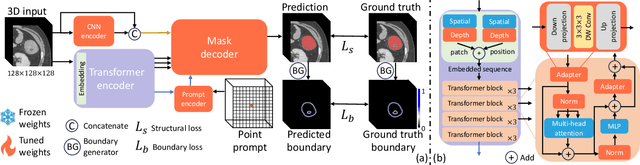

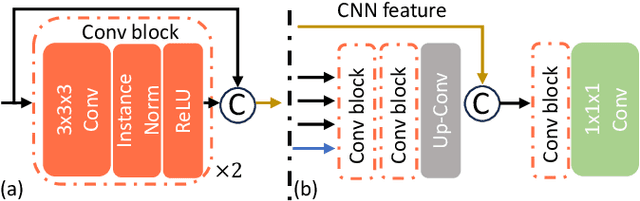
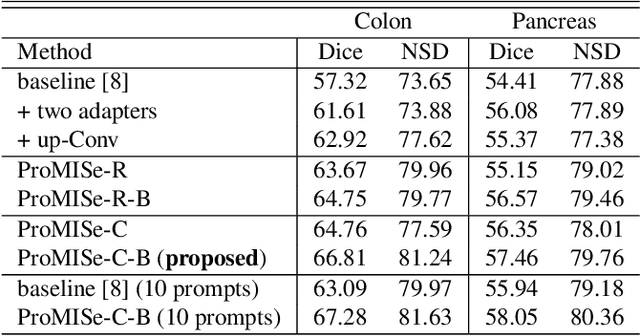
To address prevalent issues in medical imaging, such as data acquisition challenges and label availability, transfer learning from natural to medical image domains serves as a viable strategy to produce reliable segmentation results. However, several existing barriers between domains need to be broken down, including addressing contrast discrepancies, managing anatomical variability, and adapting 2D pretrained models for 3D segmentation tasks. In this paper, we propose ProMISe,a prompt-driven 3D medical image segmentation model using only a single point prompt to leverage knowledge from a pretrained 2D image foundation model. In particular, we use the pretrained vision transformer from the Segment Anything Model (SAM) and integrate lightweight adapters to extract depth-related (3D) spatial context without updating the pretrained weights. For robust results, a hybrid network with complementary encoders is designed, and a boundary-aware loss is proposed to achieve precise boundaries. We evaluate our model on two public datasets for colon and pancreas tumor segmentations, respectively. Compared to the state-of-the-art segmentation methods with and without prompt engineering, our proposed method achieves superior performance. The code is publicly available at https://github.com/MedICL-VU/ProMISe.
A graph-based multimodal framework to predict gentrification
Dec 25, 2023Gentrification--the transformation of a low-income urban area caused by the influx of affluent residents--has many revitalizing benefits. However, it also poses extremely concerning challenges to low-income residents. To help policymakers take targeted and early action in protecting low-income residents, researchers have recently proposed several machine learning models to predict gentrification using socioeconomic and image features. Building upon previous studies, we propose a novel graph-based multimodal deep learning framework to predict gentrification based on urban networks of tracts and essential facilities (e.g., schools, hospitals, and subway stations). We train and test the proposed framework using data from Chicago, New York City, and Los Angeles. The model successfully predicts census-tract level gentrification with 0.9 precision on average. Moreover, the framework discovers a previously unexamined strong relationship between schools and gentrification, which provides a basis for further exploration of social factors affecting gentrification.
Deep Structure and Attention Aware Subspace Clustering
Dec 25, 2023Clustering is a fundamental unsupervised representation learning task with wide application in computer vision and pattern recognition. Deep clustering utilizes deep neural networks to learn latent representation, which is suitable for clustering. However, previous deep clustering methods, especially image clustering, focus on the features of the data itself and ignore the relationship between the data, which is crucial for clustering. In this paper, we propose a novel Deep Structure and Attention aware Subspace Clustering (DSASC), which simultaneously considers data content and structure information. We use a vision transformer to extract features, and the extracted features are divided into two parts, structure features, and content features. The two features are used to learn a more efficient subspace structure for spectral clustering. Extensive experimental results demonstrate that our method significantly outperforms state-of-the-art methods. Our code will be available at https://github.com/cs-whh/DSASC
Combinatorial music generation model with song structure graph analysis
Dec 24, 2023In this work, we propose a symbolic music generation model with the song structure graph analysis network. We construct a graph that uses information such as note sequence and instrument as node features, while the correlation between note sequences acts as the edge feature. We trained a Graph Neural Network to obtain node representation in the graph, then we use node representation as input of Unet to generate CONLON pianoroll image latent. The outcomes of our experimental results show that the proposed model can generate a comprehensive form of music. Our approach represents a promising and innovative method for symbolic music generation and holds potential applications in various fields in Music Information Retreival, including music composition, music classification, and music inpainting systems.
Diagonal Hierarchical Consistency Learning for Semi-supervised Medical Image Segmentation
Nov 24, 2023Medical image segmentation, which is essential for many clinical applications, has achieved almost human-level performance via data-driven deep learning technologies. Nevertheless, its performance is predicated upon the costly process of manually annotating a vast amount of medical images. To this end, we propose a novel framework for robust semi-supervised medical image segmentation using diagonal hierarchical consistency learning (DiHC-Net). First, it is composed of multiple sub-models with identical multi-scale architecture but with distinct sub-layers, such as up-sampling and normalisation layers. Second, with mutual consistency, a novel consistency regularisation is enforced between one model's intermediate and final prediction and soft pseudo labels from other models in a diagonal hierarchical fashion. A series of experiments verifies the efficacy of our simple framework, outperforming all previous approaches on public Left Atrium (LA) dataset.
XAI for time-series classification leveraging image highlight methods
Nov 28, 2023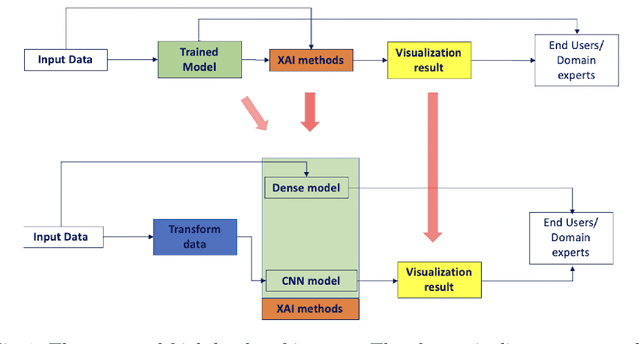
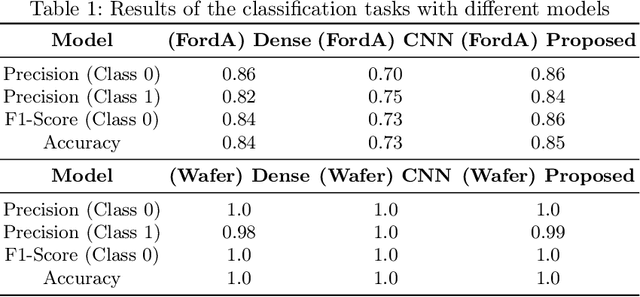
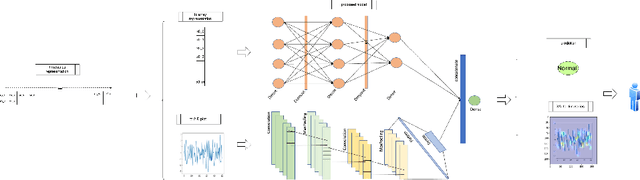
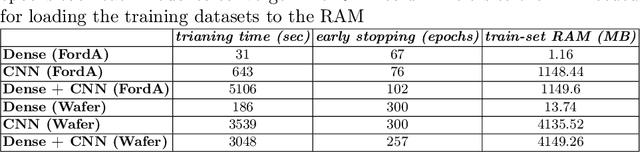
Although much work has been done on explainability in the computer vision and natural language processing (NLP) fields, there is still much work to be done to explain methods applied to time series as time series by nature can not be understood at first sight. In this paper, we present a Deep Neural Network (DNN) in a teacher-student architecture (distillation model) that offers interpretability in time-series classification tasks. The explainability of our approach is based on transforming the time series to 2D plots and applying image highlight methods (such as LIME and GradCam), making the predictions interpretable. At the same time, the proposed approach offers increased accuracy competing with the baseline model with the trade-off of increasing the training time.
Uncertainty Estimation in Contrast-Enhanced MR Image Translation with Multi-Axis Fusion
Nov 20, 2023In recent years, deep learning has been applied to a wide range of medical imaging and image processing tasks. In this work, we focus on the estimation of epistemic uncertainty for 3D medical image-to-image translation. We propose a novel model uncertainty quantification method, Multi-Axis Fusion (MAF), which relies on the integration of complementary information derived from multiple views on volumetric image data. The proposed approach is applied to the task of synthesizing contrast enhanced T1-weighted images based on native T1, T2 and T2-FLAIR scans. The quantitative findings indicate a strong correlation ($\rho_{\text healthy} = 0.89$) between the mean absolute image synthetization error and the mean uncertainty score for our MAF method. Hence, we consider MAF as a promising approach to solve the highly relevant task of detecting synthetization failures at inference time.
CLiSA: A Hierarchical Hybrid Transformer Model using Orthogonal Cross Attention for Satellite Image Cloud Segmentation
Nov 29, 2023Clouds in optical satellite images are a major concern since their presence hinders the ability to carry accurate analysis as well as processing. Presence of clouds also affects the image tasking schedule and results in wastage of valuable storage space on ground as well as space-based systems. Due to these reasons, deriving accurate cloud masks from optical remote-sensing images is an important task. Traditional methods such as threshold-based, spatial filtering for cloud detection in satellite images suffer from lack of accuracy. In recent years, deep learning algorithms have emerged as a promising approach to solve image segmentation problems as it allows pixel-level classification and semantic-level segmentation. In this paper, we introduce a deep-learning model based on hybrid transformer architecture for effective cloud mask generation named CLiSA - Cloud segmentation via Lipschitz Stable Attention network. In this context, we propose an concept of orthogonal self-attention combined with hierarchical cross attention model, and we validate its Lipschitz stability theoretically and empirically. We design the whole setup under adversarial setting in presence of Lov\'asz-Softmax loss. We demonstrate both qualitative and quantitative outcomes for multiple satellite image datasets including Landsat-8, Sentinel-2, and Cartosat-2s. Performing comparative study we show that our model performs preferably against other state-of-the-art methods and also provides better generalization in precise cloud extraction from satellite multi-spectral (MX) images. We also showcase different ablation studies to endorse our choices corresponding to different architectural elements and objective functions.