 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Recognition and 3D Localization of Pedestrian Actions from Monocular Video
Aug 03, 2020
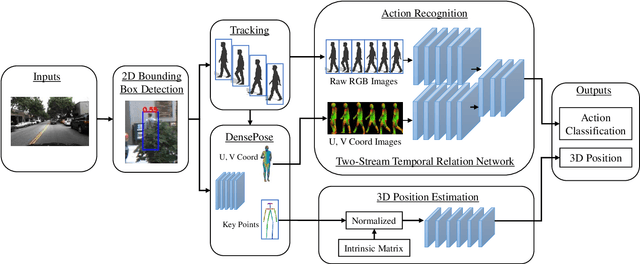
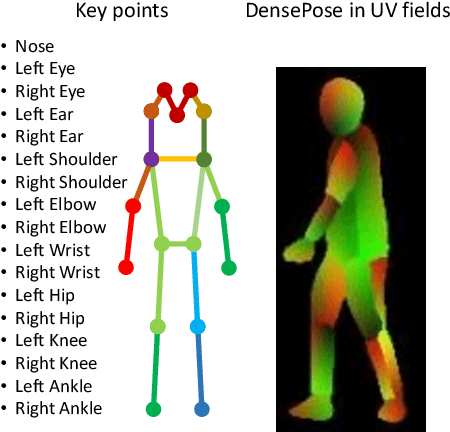
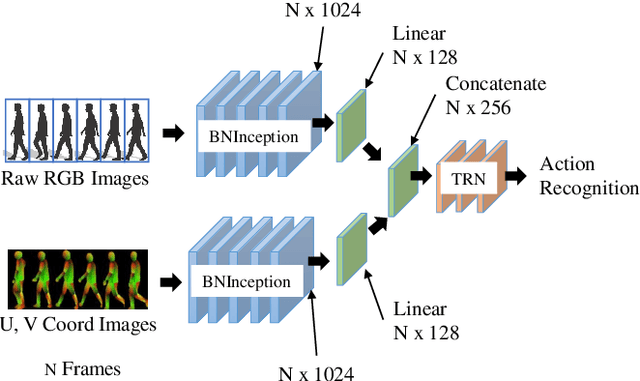
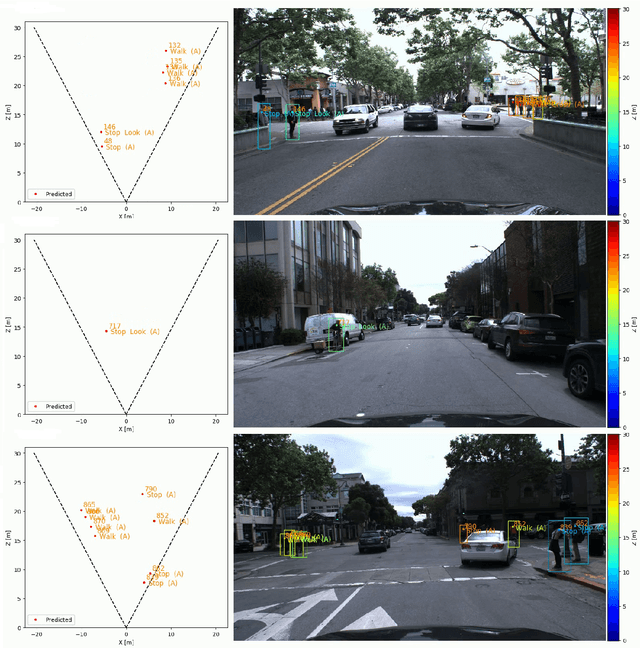
Understanding and predicting pedestrian behavior is an important and challenging area of research for realizing safe and effective navigation strategies in automated and advanced driver assistance technologies in urban scenes. This paper focuses on monocular pedestrian action recognition and 3D localization from an egocentric view for the purpose of predicting intention and forecasting future trajectory. A challenge in addressing this problem in urban traffic scenes is attributed to the unpredictable behavior of pedestrians, whereby actions and intentions are constantly in flux and depend on the pedestrians pose, their 3D spatial relations, and their interaction with other agents as well as with the environment. To partially address these challenges, we consider the importance of pose toward recognition and 3D localization of pedestrian actions. In particular, we propose an action recognition framework using a two-stream temporal relation network with inputs corresponding to the raw RGB image sequence of the tracked pedestrian as well as the pedestrian pose. The proposed method outperforms methods using a single-stream temporal relation network based on evaluations using the JAAD public dataset. The estimated pose and associated body key-points are also used as input to a network that estimates the 3D location of the pedestrian using a unique loss function. The evaluation of our 3D localization method on the KITTI dataset indicates the improvement of the average localization error as compared to existing state-of-the-art methods. Finally, we conduct qualitative tests of action recognition and 3D localization on HRI's H3D driving dataset.
Synthetic Image Augmentation for Improved Classification using Generative Adversarial Networks
Jul 31, 2019
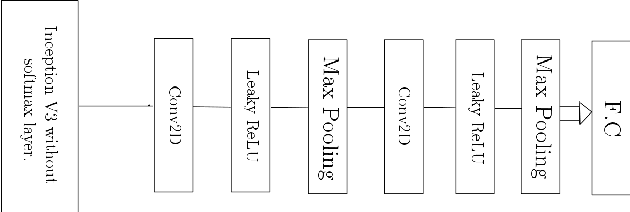
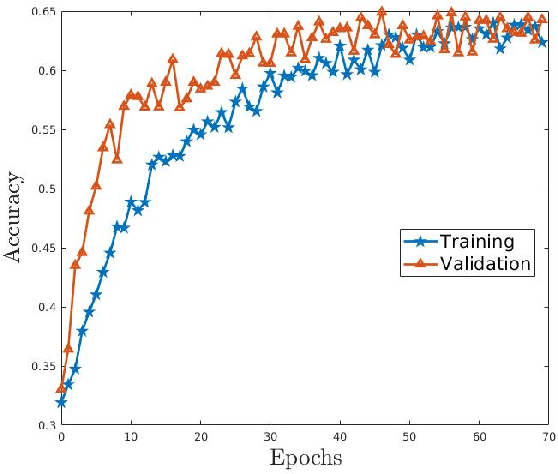
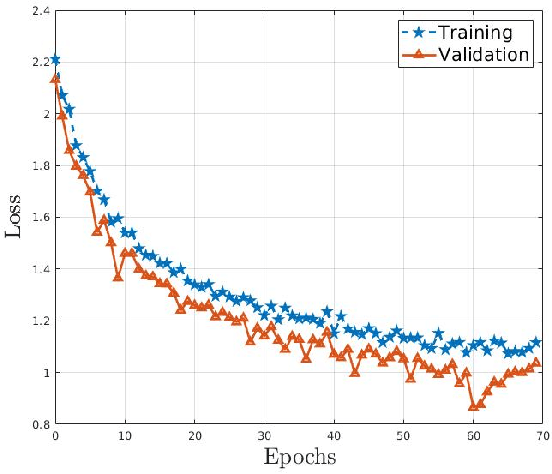
Object detection and recognition has been an ongoing research topic for a long time in the field of computer vision. Even in robotics, detecting the state of an object by a robot still remains a challenging task. Also, collecting data for each possible state is also not feasible. In this literature, we use a deep convolutional neural network with SVM as a classifier to help with recognizing the state of a cooking object. We also study how a generative adversarial network can be used for synthetic data augmentation and improving the classification accuracy. The main motivation behind this work is to estimate how well a robot could recognize the current state of an object
Learning to Learn Image Classifiers with Informative Visual Analogy
Oct 17, 2017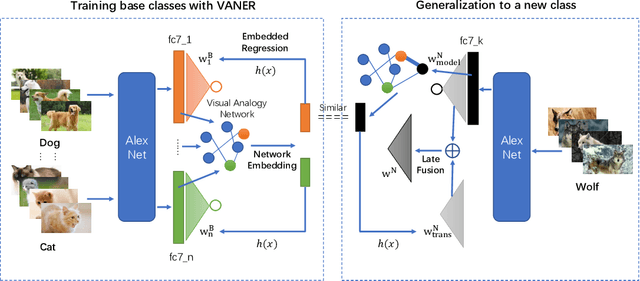
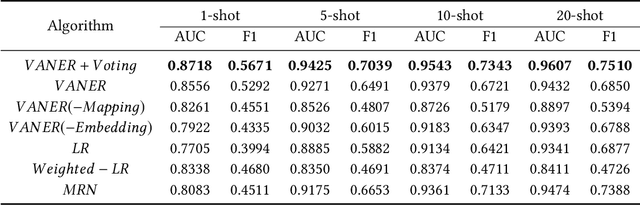
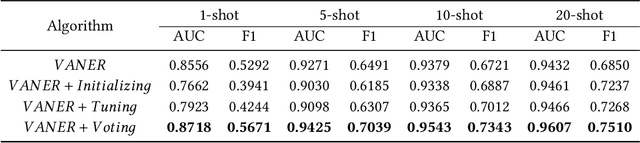
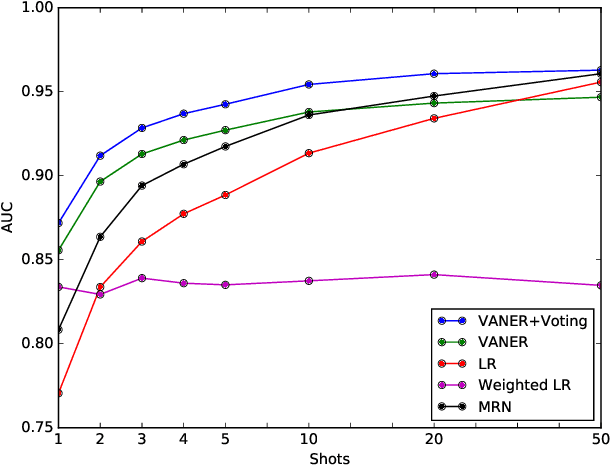
In recent years, we witnessed a huge success of Convolutional Neural Networks on the task of the image classification. However, these models are notoriously data hungry and require tons of training images to learn the parameters. In contrast, people are far better learner who can learn a new concept very fast with only a few samples. The plausible mysteries making the difference are two fundamental learning mechanisms: learning to learn and learning by analogy. In this paper, we attempt to investigate a new human-like learning method by organically combining these two mechanisms. In particular, we study how to generalize the classification parameters of previously learned concepts to a new concept. we first propose a novel Visual Analogy Network Embedded Regression (VANER) model to jointly learn a low-dimensional embedding space and a linear mapping function from the embedding space to classification parameters for base classes. We then propose an out-of-sample embedding method to learn the embedding of a new class represented by a few samples through its visual analogy with base classes. By inputting the learned embedding into VANER, we can derive the classification parameters for the new class.These classification parameters are purely generalized from base classes (i.e. transferred classification parameters), while the samples in the new class, although only a few, can also be exploited to generate a set of classification parameters (i.e. model classification parameters). Therefore, we further investigate the fusion strategy of the two kinds of parameters so that the prior knowledge and data knowledge can be fully leveraged. We also conduct extensive experiments on ImageNet and the results show that our method can consistently and significantly outperform state-of-the-art baselines.
Deep learning on edge: extracting field boundaries from satellite images with a convolutional neural network
Oct 26, 2019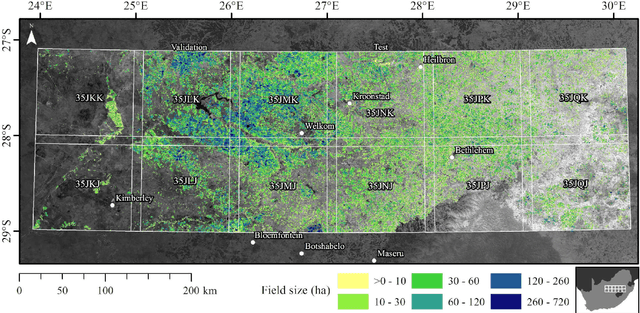
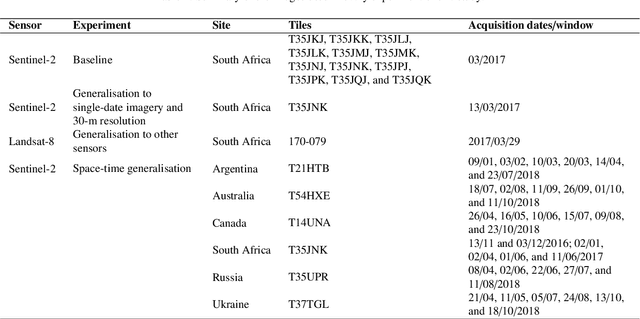
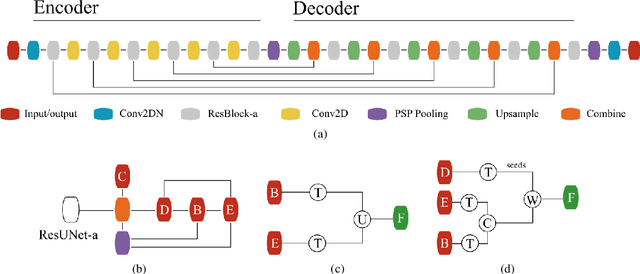
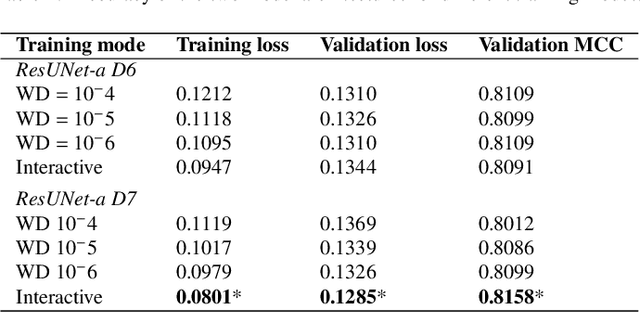
Applications of digital agricultural services often require either farmers or their advisers to provide digital records of their field boundaries. Automatic extraction of field boundaries from satellite imagery would reduce the reliance on manual input of these records which is time consuming and error-prone, and would underpin the provision of remote products and services. The lack of current field boundary data sets seems to indicate low uptake of existing methods,presumably because of expensive image preprocessing requirements and local, often arbitrary, tuning. In this paper, we address the problem of field boundary extraction from satellite images as a multitask semantic segmentation problem. We used ResUNet-a, a deep convolutional neural network with a fully connected UNet backbone that features dilated convolutions and conditioned inference, to assign three labels to each pixel: 1) the probability of belonging to a field; 2) the probability of being part of a boundary; and 3) the distance to the closest boundary. These labels can then be combined to obtain closed field boundaries. Using a single composite image from Sentinel-2, the model was highly accurate in mapping field extent, field boundaries, and, consequently, individual fields. Replacing the monthly composite with a single-date image close to the compositing period only marginally decreased accuracy. We then showed in a series of experiments that our model generalised well across resolutions, sensors, space and time without recalibration. Building consensus by averaging model predictions from at least four images acquired across the season is the key to coping with the temporal variations of accuracy. By minimising image preprocessing requirements and replacing local arbitrary decisions by data-driven ones, our approach is expected to facilitate the extraction of individual crop fields at scale.
Adversarial optimization for joint registration and segmentation in prostate CT radiotherapy
Jun 28, 2019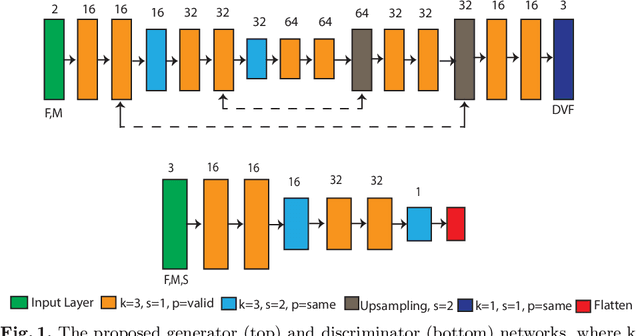


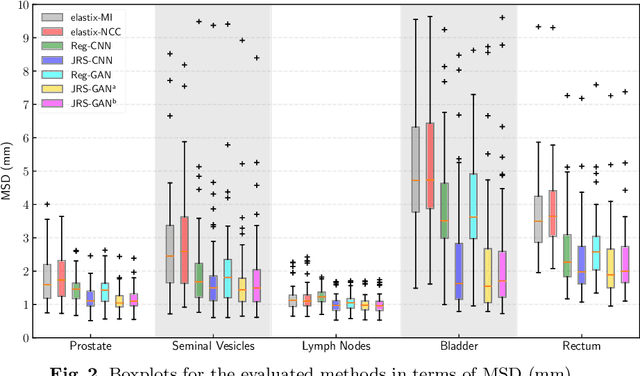
Joint image registration and segmentation has long been an active area of research in medical imaging. Here, we reformulate this problem in a deep learning setting using adversarial learning. We consider the case in which fixed and moving images as well as their segmentations are available for training, while segmentations are not available during testing; a common scenario in radiotherapy. The proposed framework consists of a 3D end-to-end generator network that estimates the deformation vector field (DVF) between fixed and moving images in an unsupervised fashion and applies this DVF to the moving image and its segmentation. A discriminator network is trained to evaluate how well the moving image and segmentation align with the fixed image and segmentation. The proposed network was trained and evaluated on follow-up prostate CT scans for image-guided radiotherapy, where the planning CT contours are propagated to the daily CT images using the estimated DVF. A quantitative comparison with conventional registration using \texttt{elastix} showed that the proposed method improved performance and substantially reduced computation time, thus enabling real-time contour propagation necessary for online-adaptive radiotherapy.
Spectral Data Augmentation Techniques to quantify Lung Pathology from CT-images
Apr 24, 2020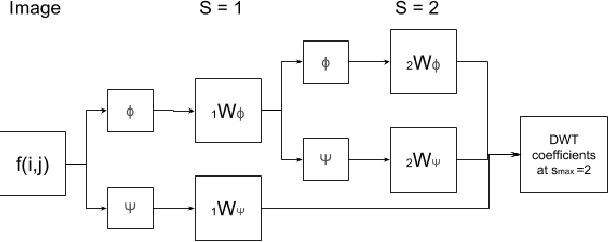
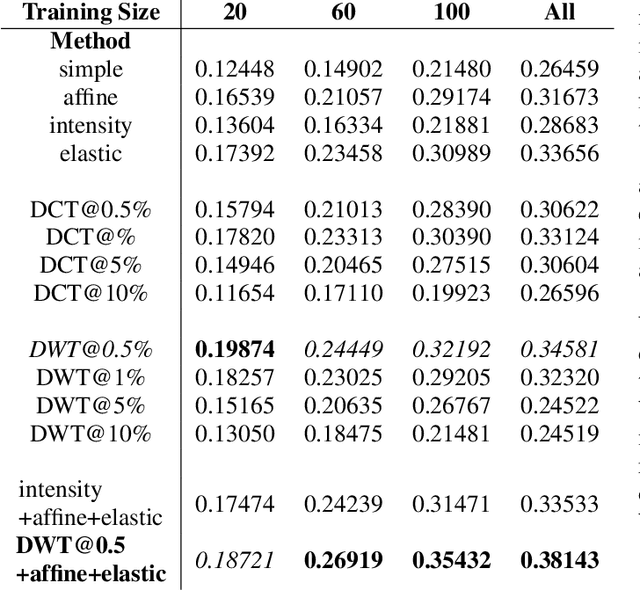

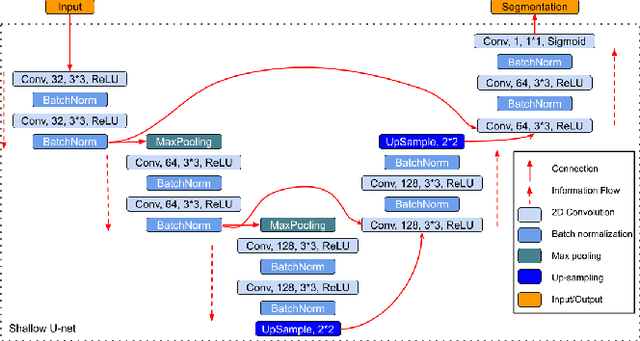
Data augmentation is of paramount importance in biomedical image processing tasks, characterized by inadequate amounts of labelled data, to best use all of the data that is present. In-use techniques range from intensity transformations and elastic deformations, to linearly combining existing data points to make new ones. In this work, we propose the use of spectral techniques for data augmentation, using the discrete cosine and wavelet transforms. We empirically evaluate our approaches on a CT texture analysis task to detect abnormal lung-tissue in patients with cystic fibrosis. Empirical experiments show that the proposed spectral methods perform favourably as compared to the existing methods. When used in combination with existing methods, our proposed approach can increase the relative minor class segmentation performance by 44.1% over a simple replication baseline.
Frame-to-Frame Aggregation of Active Regions in Web Videos for Weakly Supervised Semantic Segmentation
Aug 13, 2019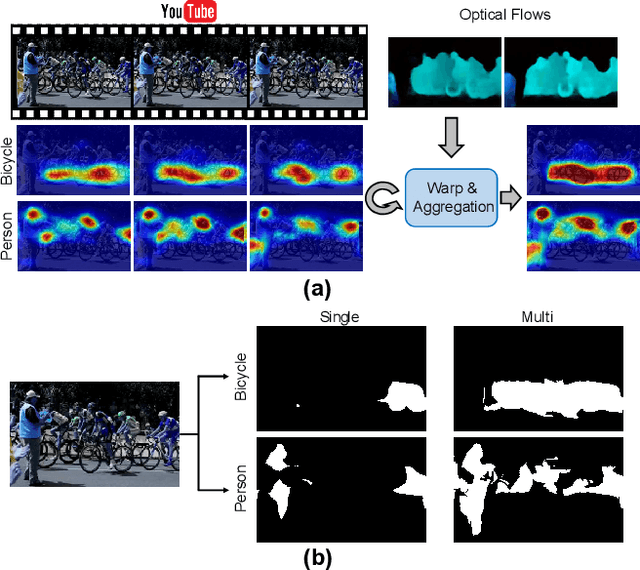
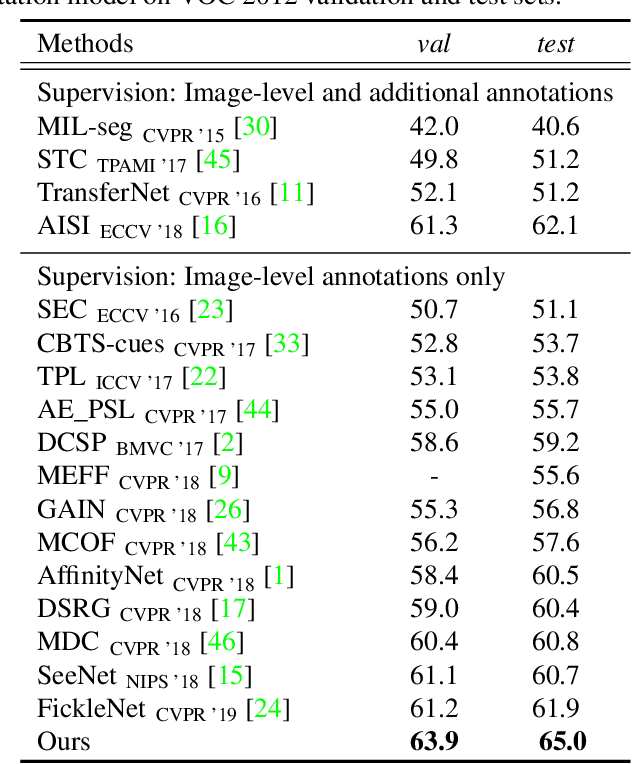
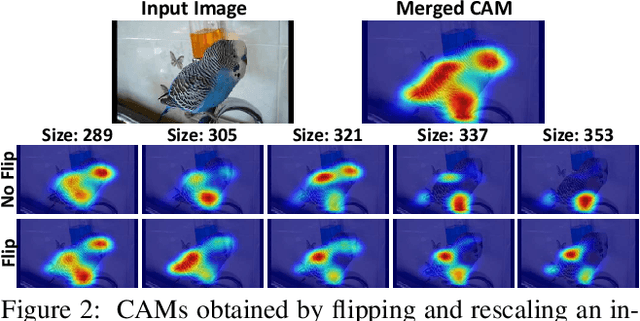
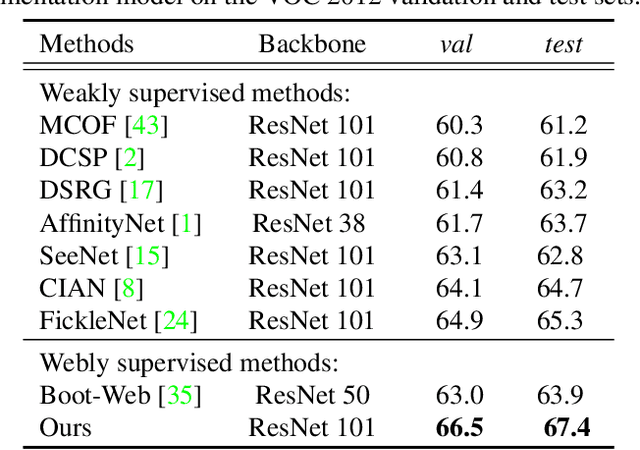
When a deep neural network is trained on data with only image-level labeling, the regions activated in each image tend to identify only a small region of the target object. We propose a method of using videos automatically harvested from the web to identify a larger region of the target object by using temporal information, which is not present in the static image. The temporal variations in a video allow different regions of the target object to be activated. We obtain an activated region in each frame of a video, and then aggregate the regions from successive frames into a single image, using a warping technique based on optical flow. The resulting localization maps cover more of the target object, and can then be used as proxy ground-truth to train a segmentation network. This simple approach outperforms existing methods under the same level of supervision, and even approaches relying on extra annotations. Based on VGG-16 and ResNet 101 backbones, our method achieves the mIoU of 65.0 and 67.4, respectively, on PASCAL VOC 2012 test images, which represents a new state-of-the-art.
AUTSL: A Large Scale Multi-modal Turkish Sign Language Dataset and Baseline Methods
Aug 03, 2020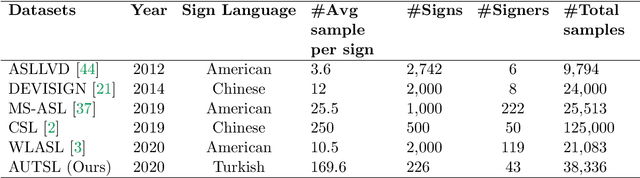

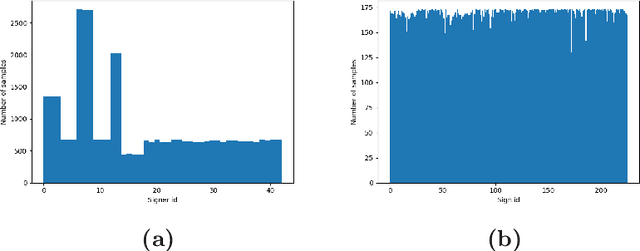

Sign language recognition is a challenging problem where signs are identified by simultaneous local and global articulations of multiple sources, i.e. hand shape and orientation, hand movements, body posture and facial expressions. Solving this problem computationally for a large vocabulary of signs in real life settings is still a challenge, even with the state-of-the-art models. In this study, we present a new large-scale multi-modal Turkish Sign Language dataset (AUTSL) with a benchmark and provide baseline models for performance evaluations. Our dataset consists of 226 signs performed by 43 different signers and 38,336 isolated sign video samples in total. Samples contain a wide variety of backgrounds recorded in indoor and outdoor environments. Moreover, spatial positions and the postures of signers also vary in the recordings. Each sample is recorded with Microsoft Kinect v2 and contains color image (RGB), depth and skeleton data modalities. We prepared benchmark training and test sets for user independent assessments of the models. We trained several deep learning based models and provide empirical evaluations using the benchmark; we used Convolutional Neural Networks (CNNs) to extract features, unidirectional and bidirectional Long Short-Term Memory (LSTM) models to characterize temporal information. We also incorporated feature pooling modules and temporal attention to our models to improve the performances. Using the benchmark test set, we obtained 62.02% accuracy with RGB+Depth data and 47.62% accuracy with RGB only data with the CNN+FPM+BLSTM+Attention model. Our dataset will be made publicly available at https://cvml.ankara.edu.tr.
MADGAN: unsupervised Medical Anomaly Detection GAN using multiple adjacent brain MRI slice reconstruction
Jul 24, 2020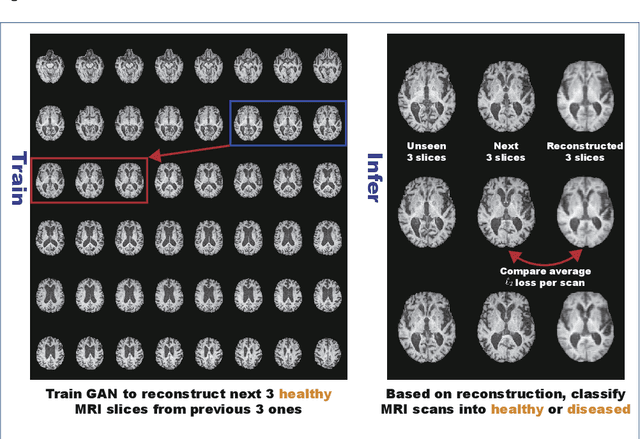
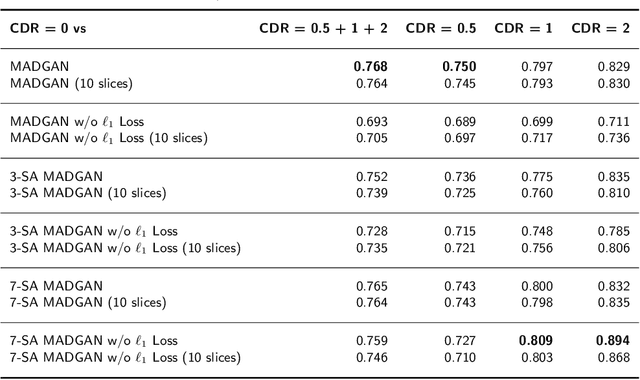
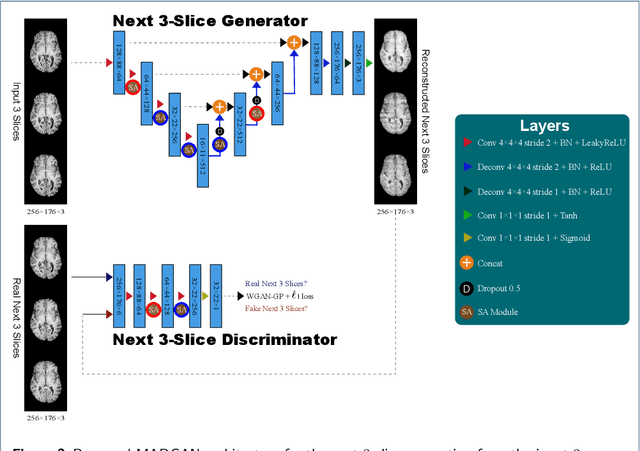
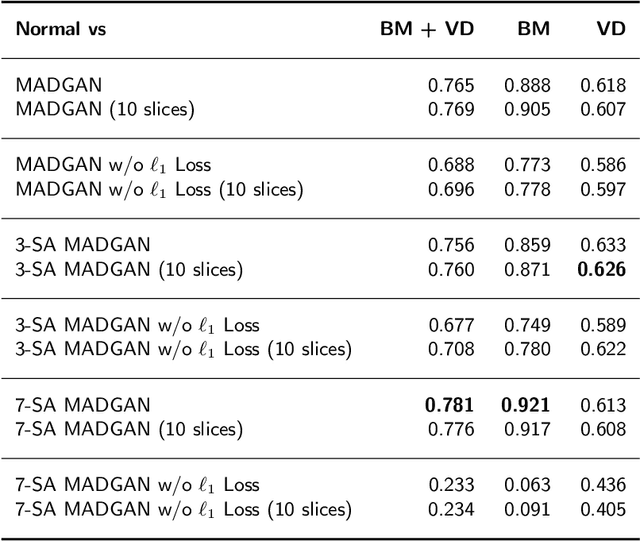
Unsupervised learning can discover various unseen diseases, relying on large-scale unannotated medical images of healthy subjects. Towards this, unsupervised methods reconstruct a 2D/3D single medical image to detect outliers either in the learned feature space or from high reconstruction loss. However, without considering continuity between multiple adjacent slices, they cannot directly discriminate diseases composed of the accumulation of subtle anatomical anomalies, such as Alzheimer's Disease (AD). Moreover, no study has shown how unsupervised anomaly detection is associated with either disease stages, various (i.e., more than two types of) diseases, or multi-sequence Magnetic Resonance Imaging (MRI) scans. Therefore, we propose unsupervised Medical Anomaly Detection Generative Adversarial Network (MADGAN), a novel two-step method using GAN-based multiple adjacent brain MRI slice reconstruction to detect various diseases at different stages on multi-sequence structural MRI: (Reconstruction) Wasserstein loss with Gradient Penalty + 100 L1 loss-trained on 3 healthy brain axial MRI slices to reconstruct the next 3 ones-reconstructs unseen healthy/abnormal scans; (Diagnosis) Average L2 loss per scan discriminates them, comparing the ground truth/reconstructed slices. For training, we use 1,133 healthy T1-weighted (T1) and 135 healthy contrast-enhanced T1 (T1c) brain MRI scans. Our Self-Attention MADGAN can detect AD on T1 scans at a very early stage, Mild Cognitive Impairment (MCI), with Area Under the Curve (AUC) 0.727, and AD at a late stage with AUC 0.894, while detecting brain metastases on T1c scans with AUC 0.921.
Indiscapes: Instance Segmentation Networks for Layout Parsing of Historical Indic Manuscripts
Dec 15, 2019
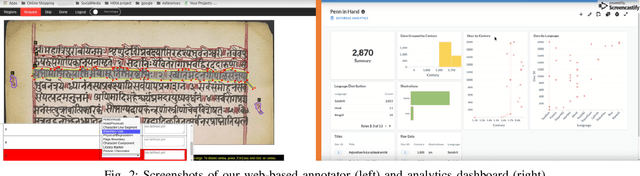
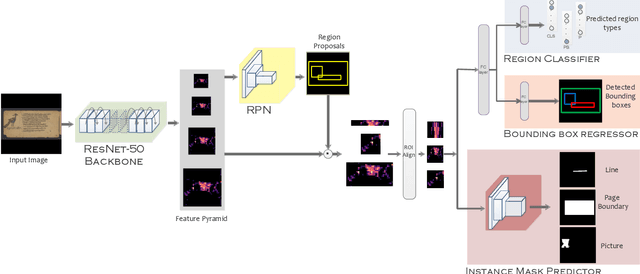

Historical palm-leaf manuscript and early paper documents from Indian subcontinent form an important part of the world's literary and cultural heritage. Despite their importance, large-scale annotated Indic manuscript image datasets do not exist. To address this deficiency, we introduce Indiscapes, the first ever dataset with multi-regional layout annotations for historical Indic manuscripts. To address the challenge of large diversity in scripts and presence of dense, irregular layout elements (e.g. text lines, pictures, multiple documents per image), we adapt a Fully Convolutional Deep Neural Network architecture for fully automatic, instance-level spatial layout parsing of manuscript images. We demonstrate the effectiveness of proposed architecture on images from the Indiscapes dataset. For annotation flexibility and keeping the non-technical nature of domain experts in mind, we also contribute a custom, web-based GUI annotation tool and a dashboard-style analytics portal. Overall, our contributions set the stage for enabling downstream applications such as OCR and word-spotting in historical Indic manuscripts at scale.