 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On the Suitable Domain for SVM Training in Image Coding
Oct 18, 2013
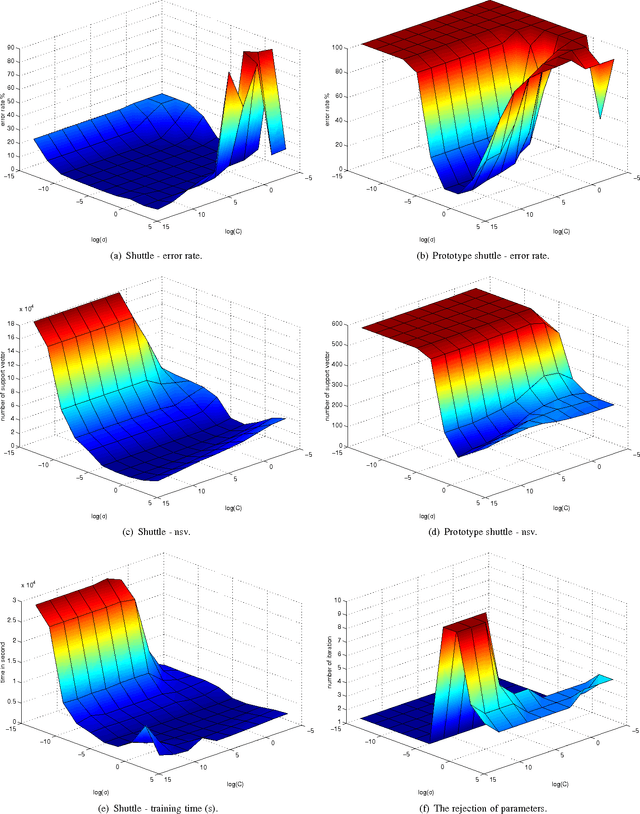
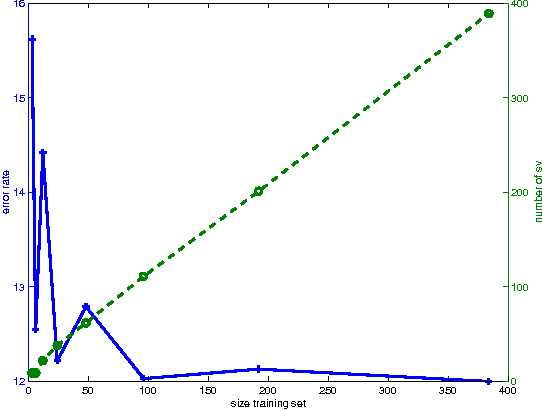

Conventional SVM-based image coding methods are founded on independently restricting the distortion in every image coefficient at some particular image representation. Geometrically, this implies allowing arbitrary signal distortions in an $n$-dimensional rectangle defined by the $\varepsilon$-insensitivity zone in each dimension of the selected image representation domain. Unfortunately, not every image representation domain is well-suited for such a simple, scalar-wise, approach because statistical and/or perceptual interactions between the coefficients may exist. These interactions imply that scalar approaches may induce distortions that do not follow the image statistics and/or are perceptually annoying. Taking into account these relations would imply using non-rectangular $\varepsilon$-insensitivity regions (allowing coupled distortions in different coefficients), which is beyond the conventional SVM formulation. In this paper, we report a condition on the suitable domain for developing efficient SVM image coding schemes. We analytically demonstrate that no linear domain fulfills this condition because of the statistical and perceptual inter-coefficient relations that exist in these domains. This theoretical result is experimentally confirmed by comparing SVM learning in previously reported linear domains and in a recently proposed non-linear perceptual domain that simultaneously reduces the statistical and perceptual relations (so it is closer to fulfilling the proposed condition). These results highlight the relevance of an appropriate choice of the image representation before SVM learning.
Deep Learning-based Denoising of Mammographic Images using Physics-driven Data Augmentation
Dec 11, 2019


Mammography is using low-energy X-rays to screen the human breast and is utilized by radiologists to detect breast cancer. Typically radiologists require a mammogram with impeccable image quality for an accurate diagnosis. In this study, we propose a deep learning method based on Convolutional Neural Networks (CNNs) for mammogram denoising to improve the image quality. We first enhance the noise level and employ Anscombe Transformation (AT) to transform Poisson noise to white Gaussian noise. With this data augmentation, a deep residual network is trained to learn the noise map of the noisy images. We show, that the proposed method can remove not only simulated but also real noise. Furthermore, we also compare our results with state-of-the-art denoising methods, such as BM3D and DNCNN. In an early investigation, we achieved qualitatively better mammogram denoising results.
Image enhancement using the mean dynamic range maximization with logarithmic operations
Dec 18, 2014

In this paper we use a logarithmic model for gray level image enhancement. We begin with a short presentation of the model and then, we propose a new formula for the mean dynamic range. After that we present two image transforms: one performs an optimal enhancement of the mean dynamic range using the logarithmic addition, and the other does the same for positive and negative values using the logarithmic scalar multiplication. We present the comparison of the results obtained by dynamic ranges optimization with the results obtained using classical image enhancement methods like gamma correction and histogram equalization.
The Semantic Mutex Watershed for Efficient Bottom-Up Semantic Instance Segmentation
Dec 29, 2019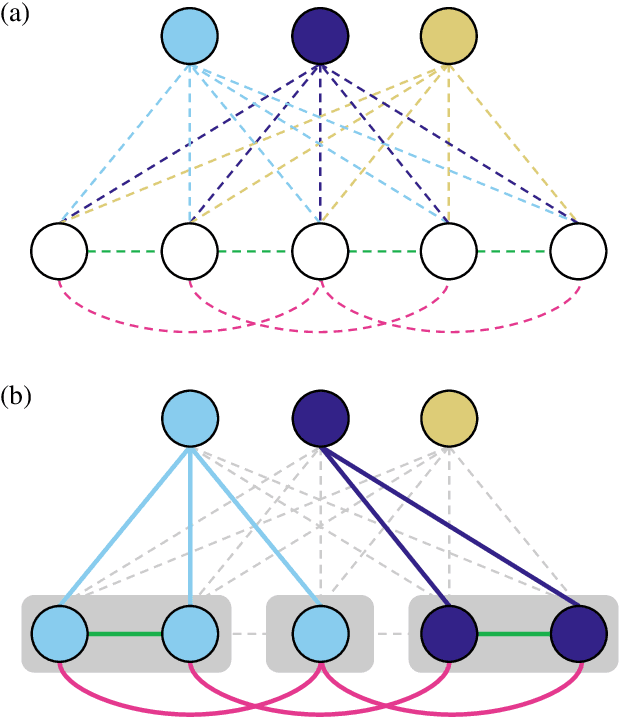


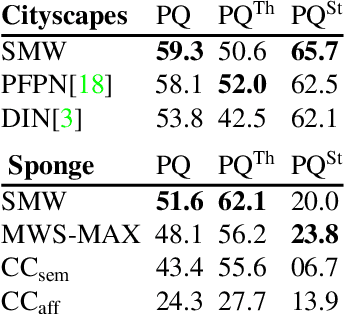
Semantic instance segmentation is the task of simultaneously partitioning an image into distinct segments while associating each pixel with a class label. In commonly used pipelines, segmentation and label assignment are solved separately since joint optimization is computationally expensive. We propose a greedy algorithm for joint graph partitioning and labeling derived from the efficient Mutex Watershed partitioning algorithm. It optimizes an objective function closely related to the Symmetric Multiway Cut objective and empirically shows efficient scaling behavior. Due to the algorithm's efficiency it can operate directly on pixels without prior over-segmentation of the image into superpixels. We evaluate the performance on the Cityscapes dataset (2D urban scenes) and on a 3D microscopy volume. In urban scenes, the proposed algorithm combined with current deep neural networks outperforms the strong baseline of `Panoptic Feature Pyramid Networks' by Kirillov et al. (2019). In the 3D electron microscopy images, we show explicitly that our joint formulation outperforms a separate optimization of the partitioning and labeling problems.
Variational Quantum Singular Value Decomposition
Jun 03, 2020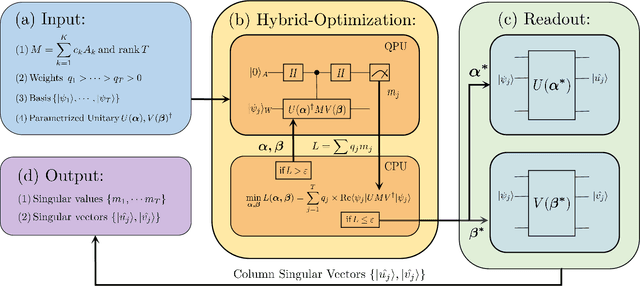
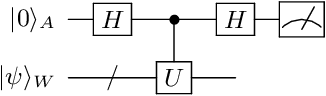
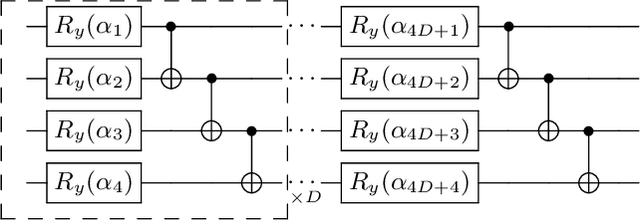
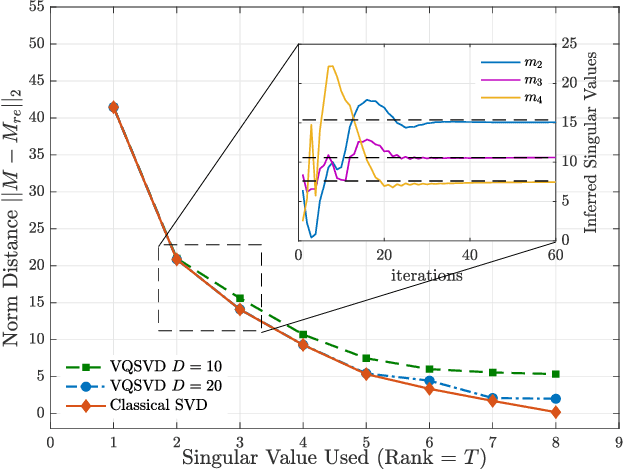
Singular value decomposition is central to many problems in both engineering and scientific fields. Several quantum algorithms have been proposed to determine the singular values and their associated singular vectors of a given matrix. Although these quantum algorithms are promising, the required quantum subroutines and resources are too costly on near-term quantum devices. In this work, we propose a variational quantum algorithm for singular value decomposition (VQSVD). By exploiting the variational principles for singular values and the Ky Fan Theorem, we design a novel loss function such that two quantum neural networks or parameterized quantum circuits could be trained to learn the singular vectors and output the corresponding singular values. We further conduct numerical simulations of the algorithm for singular-value decomposition of random matrices as well as its applications in image compression of handwritten digits. Finally, we discuss the applications of our algorithm in systems of linear equations, least squares estimation, and recommendation systems.
Fast Low-rank Shared Dictionary Learning for Image Classification
Jul 16, 2017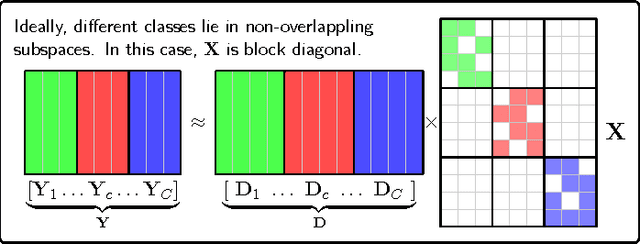

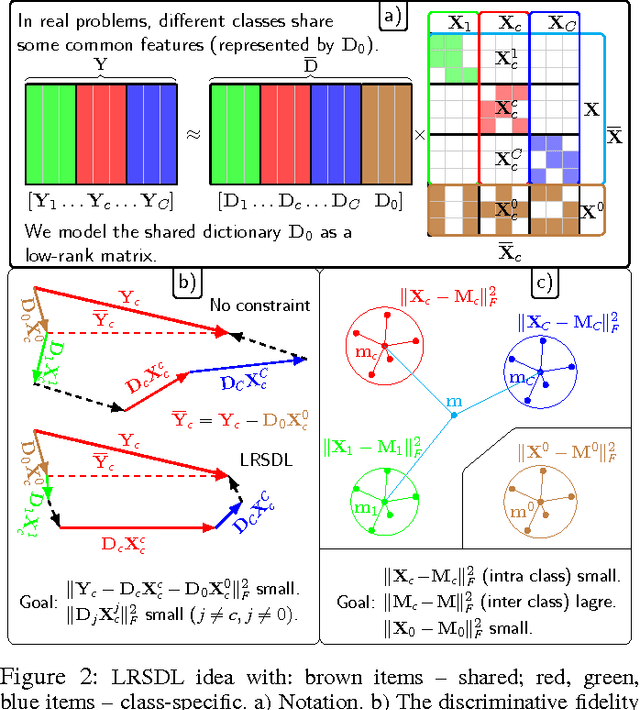
Despite the fact that different objects possess distinct class-specific features, they also usually share common patterns. This observation has been exploited partially in a recently proposed dictionary learning framework by separating the particularity and the commonality (COPAR). Inspired by this, we propose a novel method to explicitly and simultaneously learn a set of common patterns as well as class-specific features for classification with more intuitive constraints. Our dictionary learning framework is hence characterized by both a shared dictionary and particular (class-specific) dictionaries. For the shared dictionary, we enforce a low-rank constraint, i.e. claim that its spanning subspace should have low dimension and the coefficients corresponding to this dictionary should be similar. For the particular dictionaries, we impose on them the well-known constraints stated in the Fisher discrimination dictionary learning (FDDL). Further, we develop new fast and accurate algorithms to solve the subproblems in the learning step, accelerating its convergence. The said algorithms could also be applied to FDDL and its extensions. The efficiencies of these algorithms are theoretically and experimentally verified by comparing their complexities and running time with those of other well-known dictionary learning methods. Experimental results on widely used image datasets establish the advantages of our method over state-of-the-art dictionary learning methods.
Deep Learning Models for Visual Inspection on Automotive Assembling Line
Jul 02, 2020

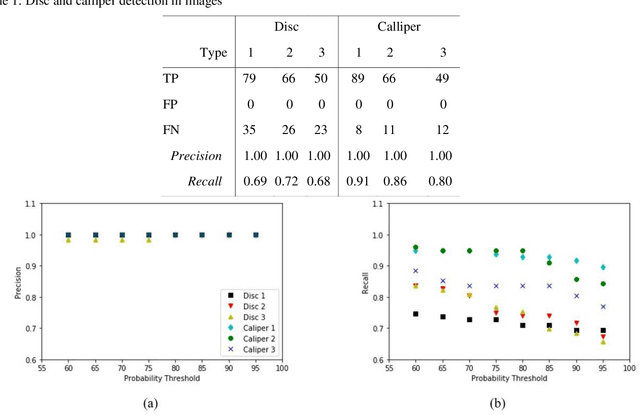

Automotive manufacturing assembly tasks are built upon visual inspections such as scratch identification on machined surfaces, part identification and selection, etc, which guarantee product and process quality. These tasks can be related to more than one type of vehicle that is produced within the same manufacturing line. Visual inspection was essentially human-led but has recently been supplemented by the artificial perception provided by computer vision systems (CVSs). Despite their relevance, the accuracy of CVSs varies accordingly to environmental settings such as lighting, enclosure and quality of image acquisition. These issues entail costly solutions and override part of the benefits introduced by computer vision systems, mainly when it interferes with the operating cycle time of the factory. In this sense, this paper proposes the use of deep learning-based methodologies to assist in visual inspection tasks while leaving very little footprints in the manufacturing environment and exploring it as an end-to-end tool to ease CVSs setup. The proposed approach is illustrated by four proofs of concept in a real automotive assembly line based on models for object detection, semantic segmentation, and anomaly detection.
* arXiv admin note: text overlap with arXiv:1802.08717, arXiv:1703.05921 by other authors
A Method for Estimating Reflectance map and Material using Deep Learning with Synthetic Dataset
Jan 15, 2020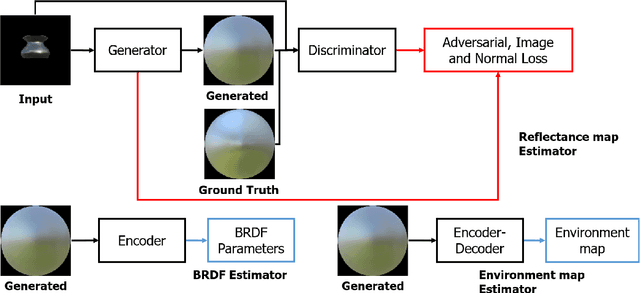
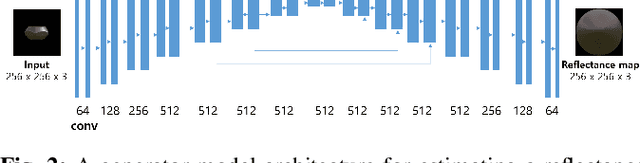
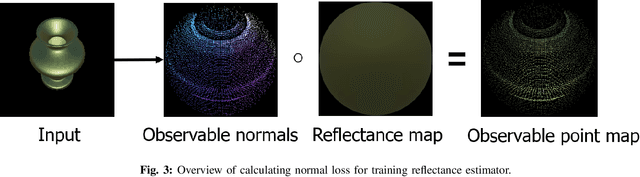
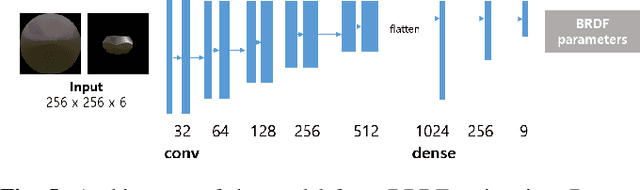
The process of decomposing target images into their internal properties is a difficult task due to the inherent ill-posed nature of the problem. The lack of data required to train a network is a one of the reasons why the decomposing appearance task is difficult. In this paper, we propose a deep learning-based reflectance map prediction system for material estimation of target objects in the image, so as to alleviate the ill-posed problem that occurs in this image decomposition operation. We also propose a network architecture for Bidirectional Reflectance Distribution Function (BRDF) parameter estimation, environment map estimation. We also use synthetic data to solve the lack of data problems. We get out of the previously proposed Deep Learning-based network architecture for reflectance map, and we newly propose to use conditional Generative Adversarial Network (cGAN) structures for estimating the reflectance map, which enables better results in many applications. To improve the efficiency of learning in this structure, we newly utilized the loss function using the normal map of the target object.
Jointly Adversarial Network to Wavelength Compensation and Dehazing of Underwater Images
Jul 12, 2019


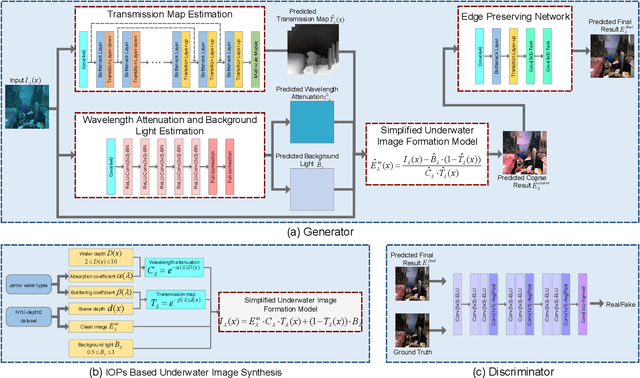
Severe color casts, low contrast and blurriness of underwater images caused by light absorption and scattering result in a difficult task for exploring underwater environments. Different from most of previous underwater image enhancement methods that compute light attenuation along object-camera path through hazy image formation model, we propose a novel jointly wavelength compensation and dehazing network (JWCDN) that takes into account the wavelength attenuation along surface-object path and the scattering along object-camera path simultaneously. By embedding a simplified underwater formation model into generative adversarial network, we can jointly estimates the transmission map, wavelength attenuation and background light via different network modules, and uses the simplified underwater image formation model to recover degraded underwater images. Especially, a multi-scale densely connected encoder-decoder network is proposed to leverage features from multiple layers for estimating the transmission map. To further improve the recovered image, we use an edge preserving network module to enhance the detail of the recovered image. Moreover, to train the proposed network, we propose a novel underwater image synthesis method that generates underwater images with inherent optical properties of different water types. The synthesis method can simulate the color, contrast and blurriness appearance of real-world underwater environments simultaneously. Extensive experiments on synthetic and real-world underwater images demonstrate that the proposed method yields comparable or better results on both subjective and objective assessments, compared with several state-of-the-art methods.
Localization and Mapping of Sparse Geologic Features with Unpiloted Aircraft Systems
Jul 02, 2020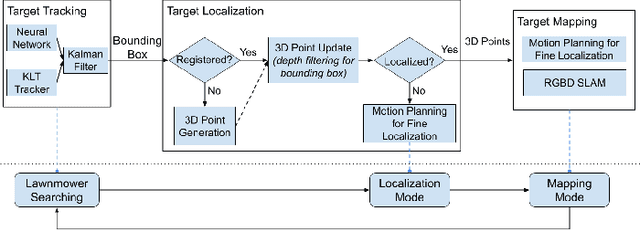

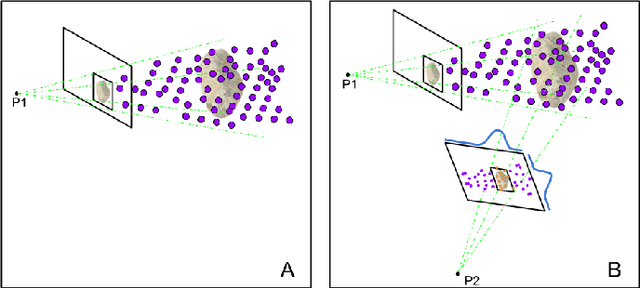
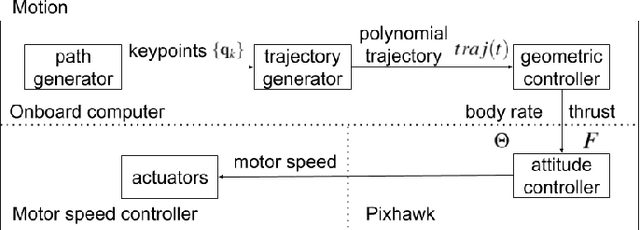
Robotic mapping is attractive in many science applications that involve environmental surveys. This paper presents a system for localization and mapping of sparsely distributed surface features such as precariously balanced rocks (PBRs), whose geometric fragility (stability) parameters provide valuable information on earthquake processes. With geomorphology as the test domain, we carry out a lawnmower search pattern using an Unpiloted Aerial Vehicle (UAV) equipped with a GPS module, stereo camera, and onboard computers. Once a target is detected by a deep neural network, we track its bounding box in the image coordinates by applying a Kalman filter that fuses the deep learning detection with KLT tracking. The target is localized in world coordinates using depth filtering where a set of 3D points are filtered by object bounding boxes from different camera perspectives. The 3D points also provide a strong prior on target shape, which is used for UAV path planning to accurately map the target using RGBD SLAM. After target mapping, the UAS resumes the lawnmower search pattern to locate the next target. Our end goal is a real-time mapping methodology for sparsely distributed surface features on earth or on extraterrestrial surfaces.