 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Gradient Distribution Priors for Biomedical Image Processing
Sep 03, 2014
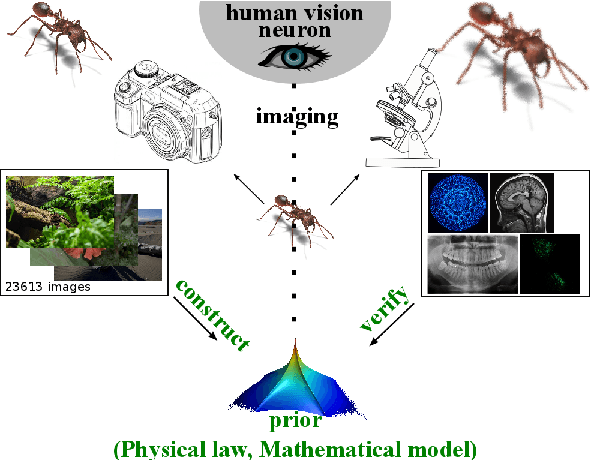
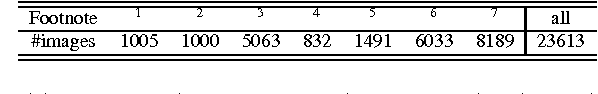
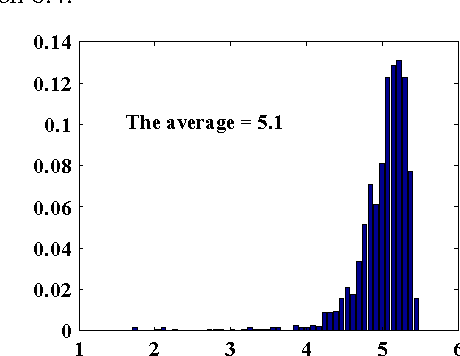
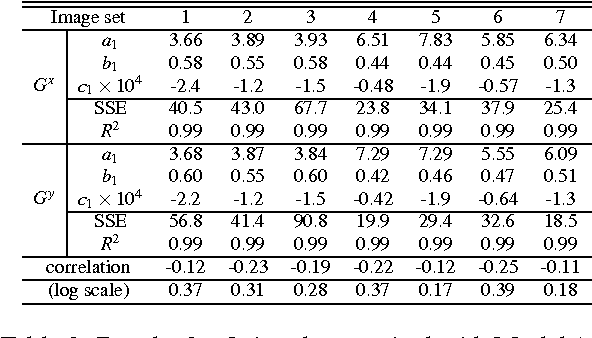
Ill-posed inverse problems are commonplace in biomedical image processing. Their solution typically requires imposing prior knowledge about the latent ground truth. While this regularizes the problem to an extent where it can be solved, it also biases the result toward the expected. With inappropriate priors harming more than they use, it remains unclear what prior to use for a given practical problem. Priors are hence mostly chosen in an {\em ad hoc} or empirical fashion. We argue here that the gradient distribution of natural-scene images may provide a versatile and well-founded prior for biomedical images. We provide motivation for this choice from different points of view, and we fully validate the resulting prior for use on biomedical images by showing its stability and correlation with image quality. We then provide a set of simple parametric models for the resulting prior, leading to straightforward (quasi-)convex optimization problems for which we provide efficient solver algorithms. We illustrate the use of the present models and solvers in a variety of common image-processing tasks, including contrast enhancement, noise level estimation, denoising, blind deconvolution, zooming/up-sampling, and dehazing. In all cases we show that the present method leads to results that are comparable to or better than the state of the art; always using the same, simple prior. We conclude by discussing the limitations and possible interpretations of the prior.
Look into Facial Expression Domain Adaptation: Adversarial Graph Learning and A Fair Evaluation Benchmark
Aug 27, 2020

To address the problem of data inconsistencies among different facial expression recognition (FER) datasets, many cross-domain FER methods (CD-FERs) have been extensively devised in recent years. Although each declares to achieve superior performance, fair comparisons are lacking due to the inconsistent choices of the source/target datasets and feature extractors. In this work, we first analyze the performance effect caused by these inconsistent choices, and then re-implement some well-performing CD-FER and recently published domain adaptation algorithms. We ensure that all these algorithms adopt the same source datasets and feature extractors for fair CD-FER evaluations. We find that most of the current leading algorithms use adversarial learning to learn holistic domain-invariant features to mitigate domain shifts. However, these algorithms ignore local features, which are more transferable across different datasets and carry more detailed content for fine-grained adaptation. To address these issues, we integrate graph representation propagation with adversarial learning for cross-domain holistic-local feature co-adaptation by developing a novel adversarial graph representation adaptation (AGRA) framework. Specifically, it first builds two graphs to correlate holistic and local regions within each domain and across different domains, respectively. Then, it extracts holistic-local features from the input image and uses learnable per-class statistical distributions to initialize the corresponding graph nodes. Finally, two stacked graph convolution networks (GCNs) are adopted to propagate holistic-local features within each domain to explore their interaction and across different domains for holistic-local feature co-adaptation. We conduct extensive and fair evaluations on several popular benchmarks and show that the proposed AGRA framework outperforms previous state-of-the-art methods.
Convolutional Networks with MuxOut Layers as Multi-rate Systems for Image Upscaling
May 22, 2017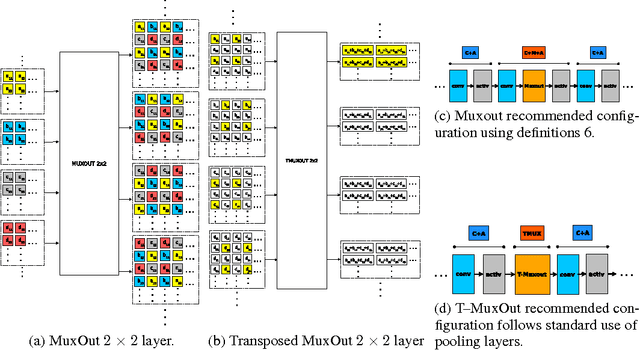

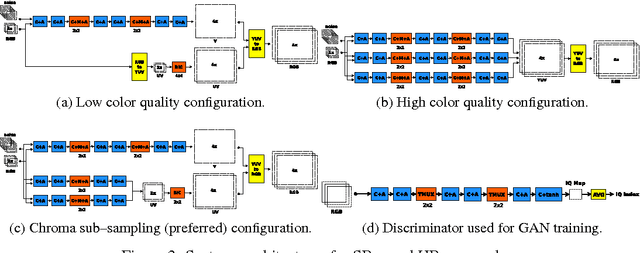
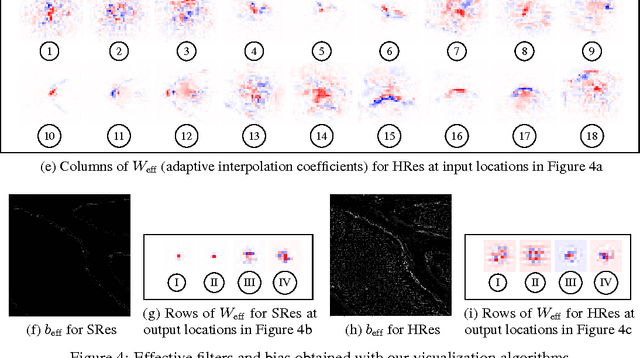
We interpret convolutional networks as adaptive filters and combine them with so-called MuxOut layers to efficiently upscale low resolution images. We formalize this interpretation by deriving a linear and space-variant structure of a convolutional network when its activations are fixed. We introduce general purpose algorithms to analyze a network and show its overall filter effect for each given location. We use this analysis to evaluate two types of image upscalers: deterministic upscalers that target the recovery of details from original content; and second, a new generation of upscalers that can sample the distribution of upscale aliases (images that share the same downscale version) that look like real content.
Single Image Super-Resolution Using Multi-Scale Convolutional Neural Network
May 15, 2017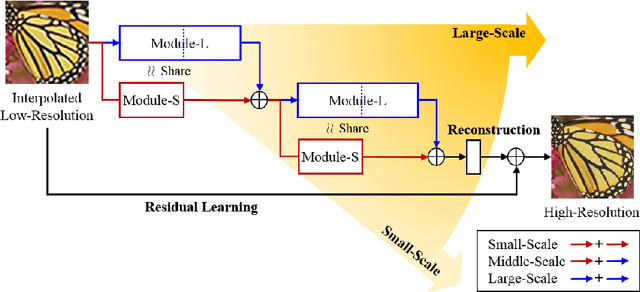


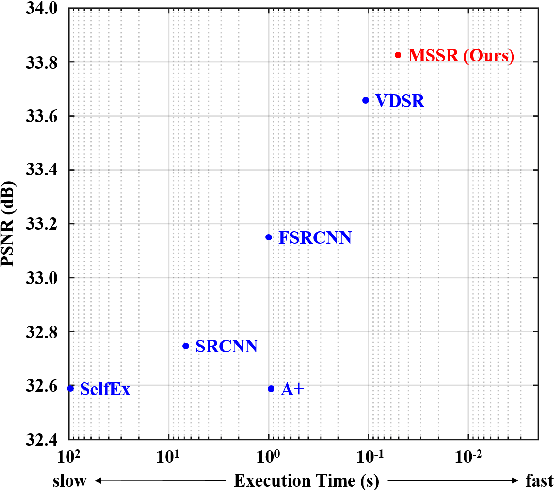
Methods based on convolutional neural network (CNN) have demonstrated tremendous improvements on single image super-resolution. However, the previous methods mainly restore images from one single area in the low resolution (LR) input, which limits the flexibility of models to infer various scales of details for high resolution (HR) output. Moreover, most of them train a specific model for each up-scale factor. In this paper, we propose a multi-scale super resolution (MSSR) network. Our network consists of multi-scale paths to make the HR inference, which can learn to synthesize features from different scales. This property helps reconstruct various kinds of regions in HR images. In addition, only one single model is needed for multiple up-scale factors, which is more efficient without loss of restoration quality. Experiments on four public datasets demonstrate that the proposed method achieved state-of-the-art performance with fast speed.
Coupled Convolutional Neural Network with Adaptive Response Function Learning for Unsupervised Hyperspectral Super-Resolution
Jul 28, 2020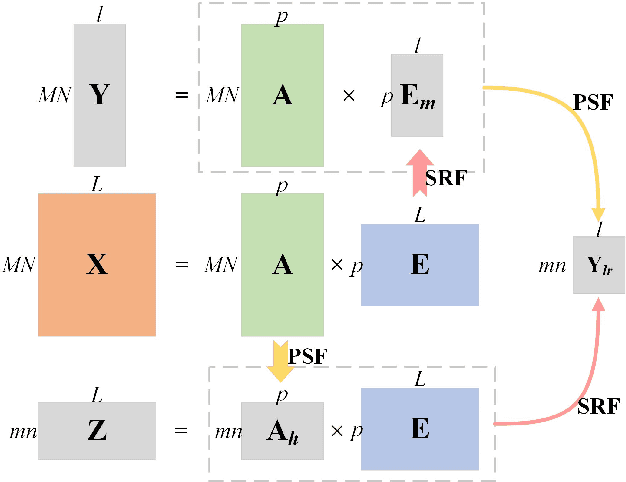
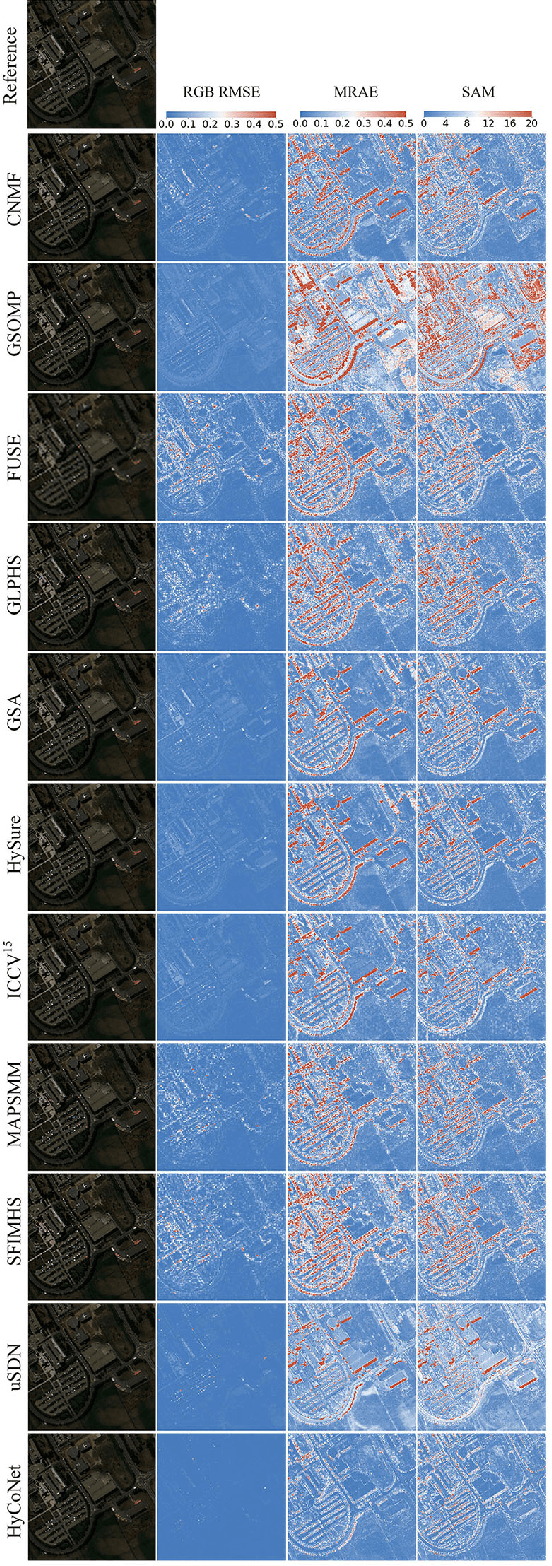
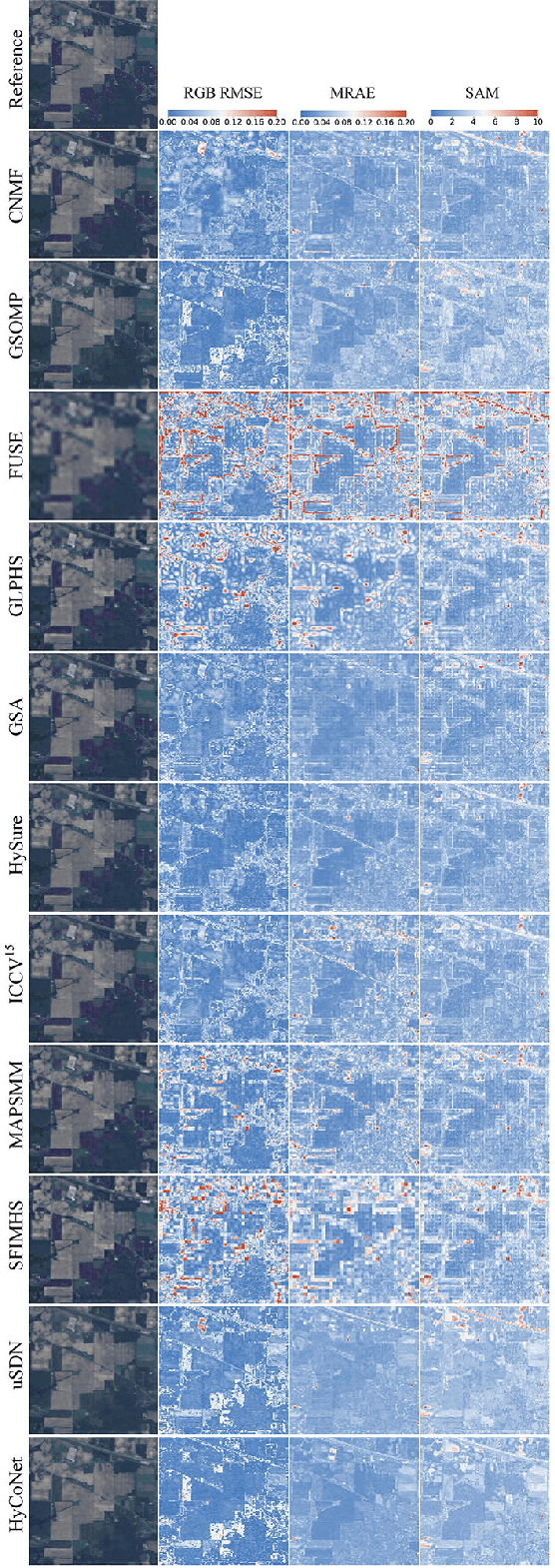
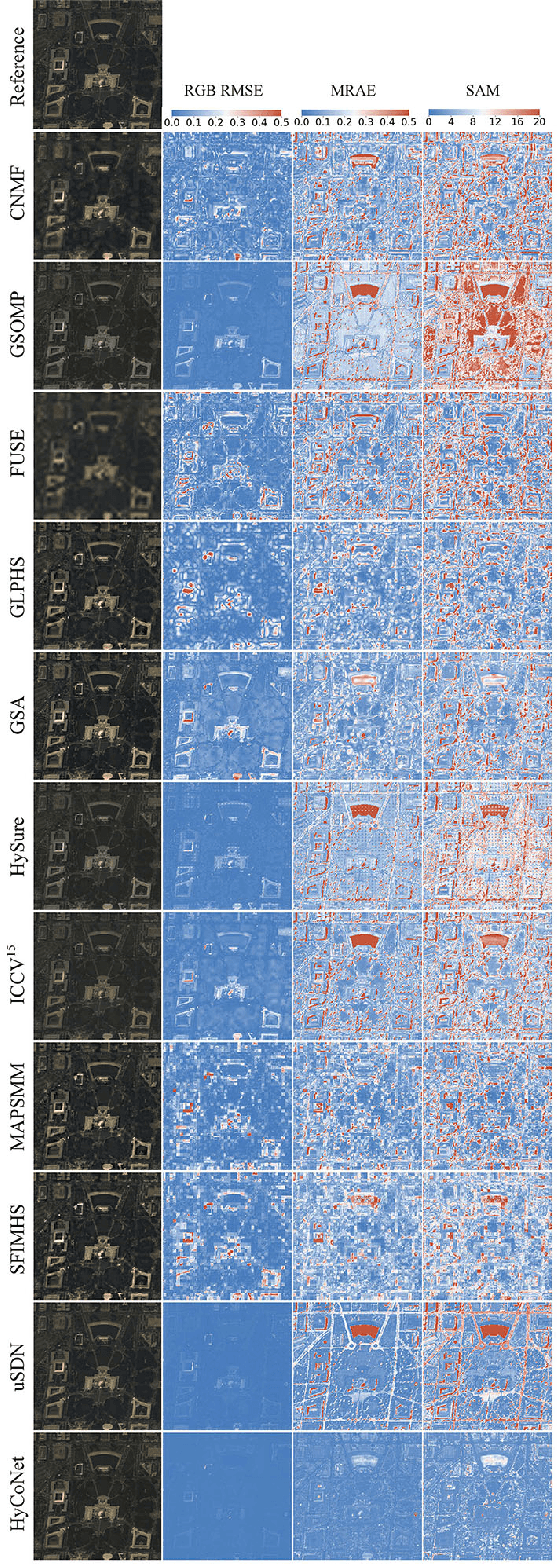
Due to the limitations of hyperspectral imaging systems, hyperspectral imagery (HSI) often suffers from poor spatial resolution, thus hampering many applications of the imagery. Hyperspectral super-resolution refers to fusing HSI and MSI to generate an image with both high spatial and high spectral resolutions. Recently, several new methods have been proposed to solve this fusion problem, and most of these methods assume that the prior information of the Point Spread Function (PSF) and Spectral Response Function (SRF) are known. However, in practice, this information is often limited or unavailable. In this work, an unsupervised deep learning-based fusion method - HyCoNet - that can solve the problems in HSI-MSI fusion without the prior PSF and SRF information is proposed. HyCoNet consists of three coupled autoencoder nets in which the HSI and MSI are unmixed into endmembers and abundances based on the linear unmixing model. Two special convolutional layers are designed to act as a bridge that coordinates with the three autoencoder nets, and the PSF and SRF parameters are learned adaptively in the two convolution layers during the training process. Furthermore, driven by the joint loss function, the proposed method is straightforward and easily implemented in an end-to-end training manner. The experiments performed in the study demonstrate that the proposed method performs well and produces robust results for different datasets and arbitrary PSFs and SRFs.
Cross-Domain Imitation Learning with a Dual Structure
Jun 04, 2020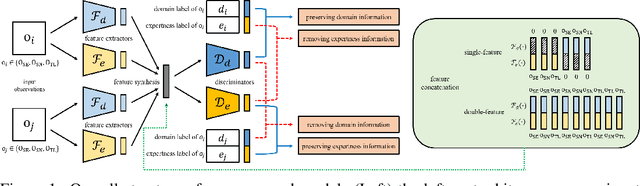
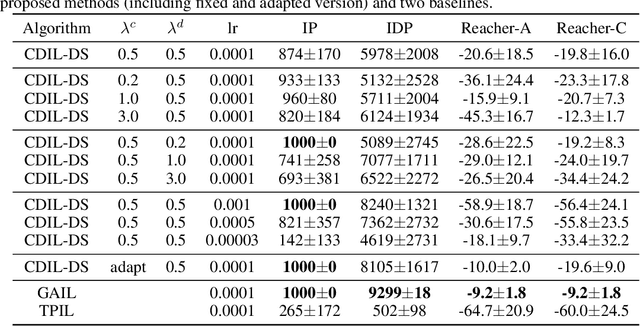
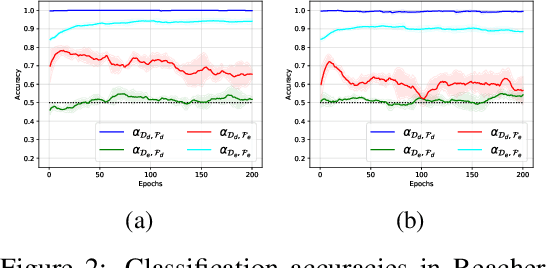
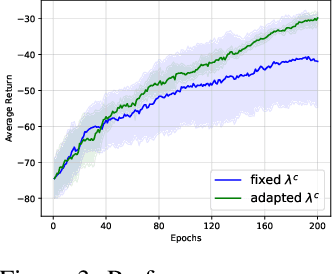
In this paper, we consider cross-domain imitation learning (CDIL) in which an agent in a target domain learns a policy to perform well in the target domain by observing expert demonstrations in a source domain without accessing any reward function. In order to overcome the domain difference for imitation learning, we propose a dual-structured learning method. The proposed learning method extracts two feature vectors from each input observation such that one vector contains domain information and the other vector contains policy expertness information, and then enhances feature vectors by synthesizing new feature vectors containing both target-domain and policy expertness information. The proposed CDIL method is tested on several MuJoCo tasks where the domain difference is determined by image angles or colors. Numerical results show that the proposed method shows superior performance in CDIL to other existing algorithms and achieves almost the same performance as imitation learning without domain difference.
Generator From Edges: Reconstruction of Facial Images
Feb 16, 2020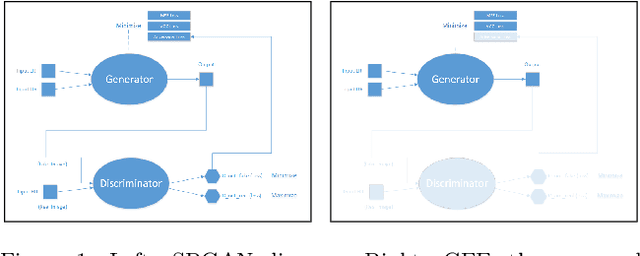


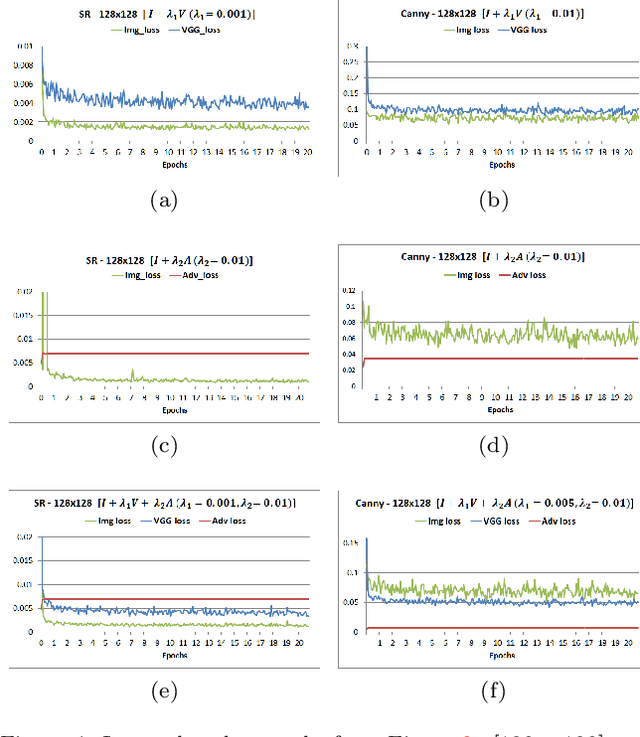
Applications that involve supervised training require paired images. Researchers of single image super-resolution (SISR) create such images by artificially generating blurry input images from the corresponding ground truth. Similarly we can create paired images with the canny edge. We propose Generator From Edges (GFE) [Figure 2]. Our aim is to determine the best architecture for GFE, along with reviews of perceptual loss [1, 2]. To this end, we conducted three experiments. First, we explored the effects of the adversarial loss often used in SISR. In particular, we uncovered that it is not an essential component to form a perceptual loss. Eliminating adversarial loss will lead to a more effective architecture from the perspective of hardware resource. It also means that considerations for the problems pertaining to generative adversarial network (GAN) [3], such as mode collapse, are not necessary. Second, we reexamined VGG loss and found that the mid-layers yield the best results. By extracting the full potential of VGG loss, the overall performance of perceptual loss improves significantly. Third, based on the findings of the first two experiments, we reevaluated the dense network to construct GFE. Using GFE as an intermediate process, reconstructing a facial image from a pencil sketch can become an easy task.
Action Recognition with Spatio-Temporal Visual Attention on Skeleton Image Sequences
Apr 11, 2018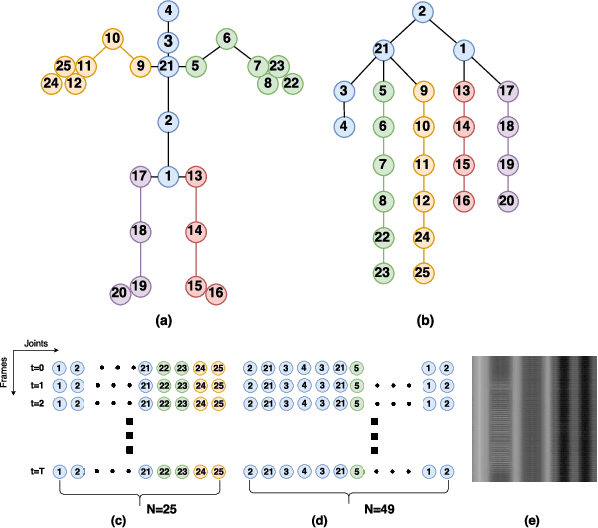

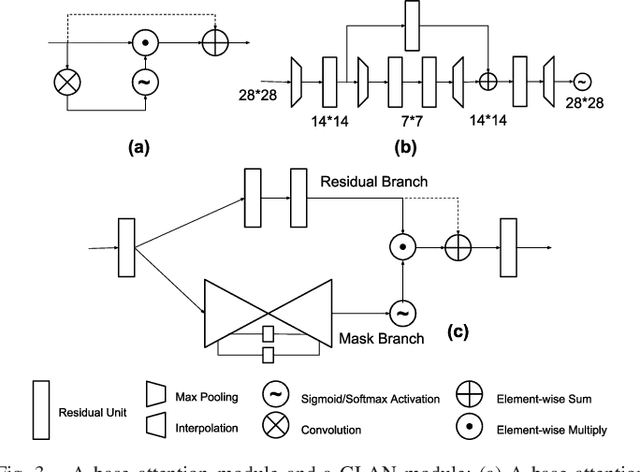
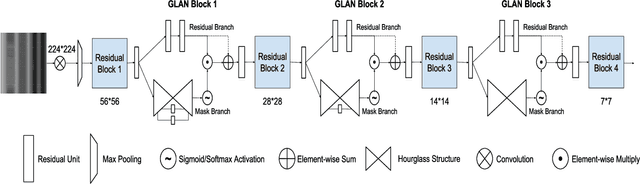
Action recognition with 3D skeleton sequences is becoming popular due to its speed and robustness. The recently proposed Convolutional Neural Networks (CNN) based methods have shown good performance in learning spatio-temporal representations for skeleton sequences. Despite the good recognition accuracy achieved by previous CNN based methods, there exist two problems that potentially limit the performance. First, previous skeleton representations are generated by chaining joints with a fixed order. The corresponding semantic meaning is unclear and the structural information among the joints is lost. Second, previous models do not have an ability to focus on informative joints. The attention mechanism is important for skeleton based action recognition because there exist spatio-temporal key stages while the joint predictions can be inaccurate. To solve these two problems, we propose a novel CNN based method for skeleton based action recognition. We first redesign the skeleton representations with a depth-first tree traversal order, which enhances the semantic meaning of skeleton images and better preserves the associated structural information. We then propose the idea of a two-branch attention architecture that focuses on spatio-temporal key stages and filters out unreliable joint predictions. A base attention model with the simplest structure is first introduced. By improving the structures in both branches, we further propose a Global Long-sequence Attention Network (GLAN). Furthermore, in order to adjust the kernel's spatio-temporal aspect ratios and better capture long term dependencies, we propose a Sub-Sequence Attention Network (SSAN) that takes sub-image sequences as inputs. Our experiment results on NTU RGB+D and SBU Kinetic Interaction outperforms the state-of-the-art. The model is further validated on noisy estimated poses from UCF101 and Kinetics.
ktrain: A Low-Code Library for Augmented Machine Learning
Apr 19, 2020We present ktrain, a low-code Python library that makes machine learning more accessible and easier to apply. As a wrapper to TensorFlow and many other libraries (e.g., transformers, scikit-learn, stellargraph), it is designed to make sophisticated, state-of-the-art machine learning models simple to build, train, inspect, and deploy by both beginners and experienced practitioners. Featuring modules that support text data (e.g., text classification, sequence-tagging, open-domain question-answering), vision data (e.g., image classification), and graph data (e.g., node classification, link prediction), ktrain presents a simple unified interface enabling one to quickly solve a wide range of tasks in as little as three or four "commands" or lines of code.
An Alternate Approach for Designing a Domain Specific Image Search Prototype Using Histogram
Nov 28, 2013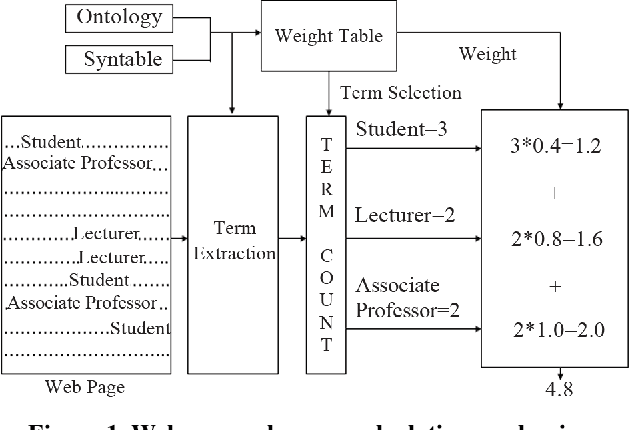
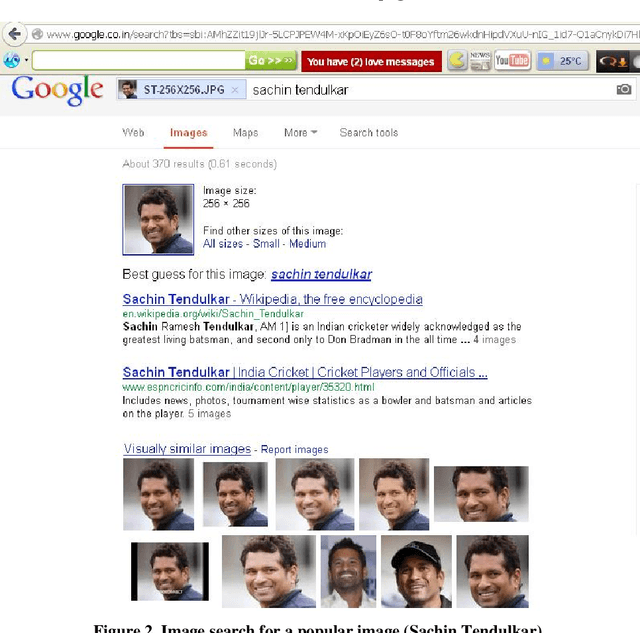
Everyone knows that thousand of words are represented by a single image. As a result image search has become a very popular mechanism for the Web searchers. Image search means, the search results are produced by the search engine should be a set of images along with their Web page Unified Resource Locator. Now Web searcher can perform two types of image search, they are Text to Image and Image to Image search. In Text to Image search, search query should be a text. Based on the input text data system will generate a set of images along with their Web page URL as an output. On the other hand, in Image to Image search, search query should be an image and based on this image system will generate a set of images along with their Web page URL as an output. According to the current scenarios, Text to Image search mechanism always not returns perfect result. It matches the text data and then displays the corresponding images as an output, which is not always perfect. To resolve this problem, Web researchers have introduced the Image to Image search mechanism. In this paper, we have also proposed an alternate approach of Image to Image search mechanism using Histogram.