 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
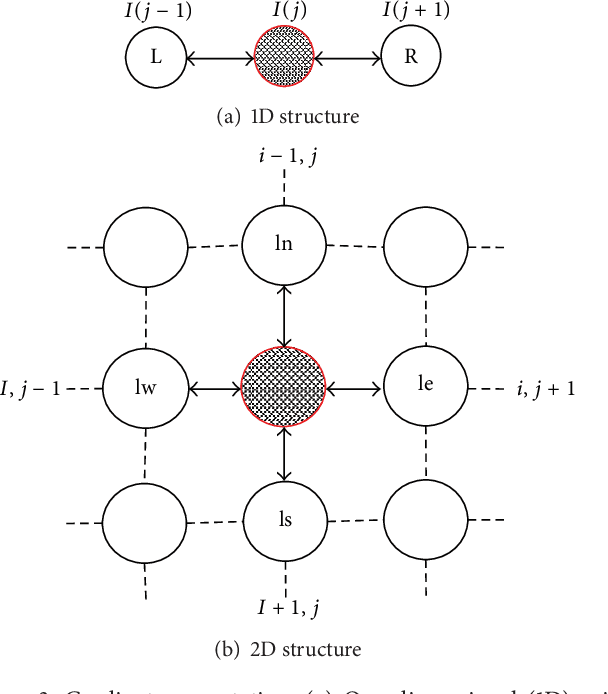
An Application of CNNs to Time Sequenced One Dimensional Data in Radiation Detection
Aug 28, 2019
A Convolutional Neural Network architecture was used to classify various isotopes of time-sequenced gamma-ray spectra, a typical output of a radiation detection system of a type commonly fielded for security or environmental measurement purposes. A two-dimensional surface (waterfall plot) in time-energy space is interpreted as a monochromatic image and standard image-based CNN techniques are applied. This allows for the time-sequenced aspects of features in the data to be discovered by the network, as opposed to standard algorithms which arbitrarily time bin the data to satisfy the intuition of a human spectroscopist. The CNN architecture and results are presented along with a comparison to conventional techniques. The results of this novel application of image processing techniques to radiation data will be presented along with a comparison to more conventional adaptive methods.
* 11 pages, 9 figures, presented: SPIE Defense + Commercial Sensing, 16-18 Apr 2019, Baltimore, MD, United States
Transfer learning in hybrid classical-quantum neural networks
Dec 17, 2019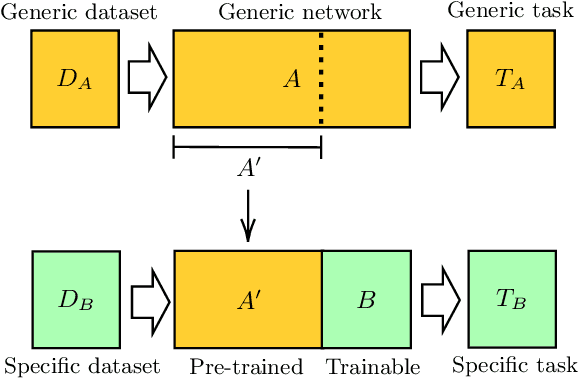
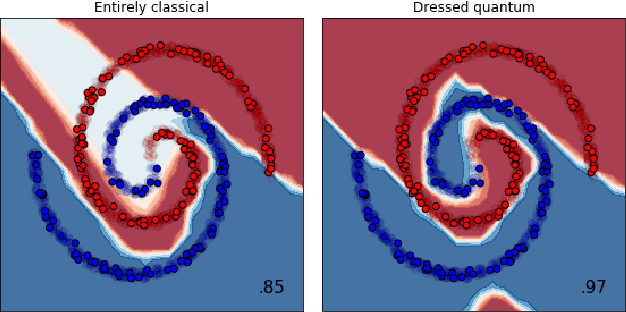

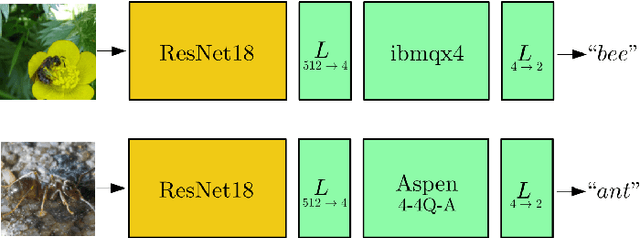
We extend the concept of transfer learning, widely applied in modern machine learning algorithms, to the emerging context of hybrid neural networks composed of classical and quantum elements. We propose different implementations of hybrid transfer learning, but we focus mainly on the paradigm in which a pre-trained classical network is modified and augmented by a final variational quantum circuit. This approach is particularly attractive in the current era of intermediate-scale quantum technology since it allows to optimally pre-process high dimensional data (e.g., images) with any state-of-the-art classical network and to embed a select set of highly informative features into a quantum processor. We present several proof-of-concept examples of the convenient application of quantum transfer learning for image recognition and quantum state classification. We use the cross-platform software library PennyLane to experimentally test a high-resolution image classifier with two different quantum computers, respectively provided by IBM and Rigetti.
One Size Fits All: Can We Train One Denoiser for All Noise Levels?
Jun 23, 2020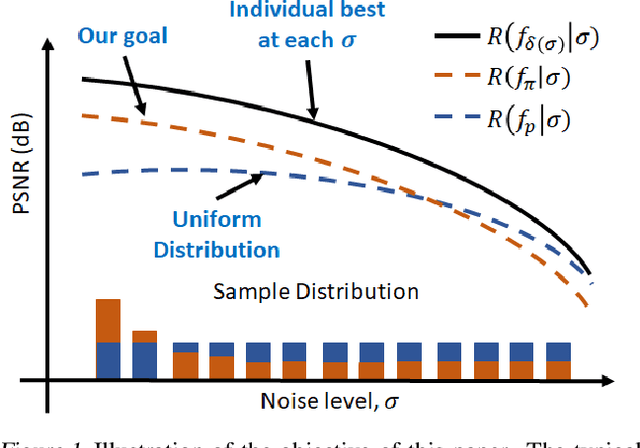
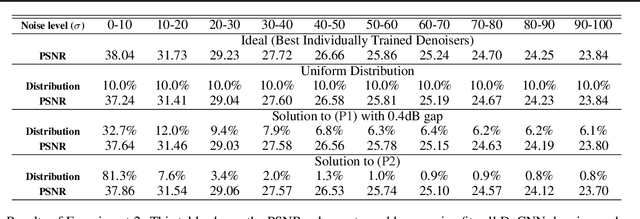
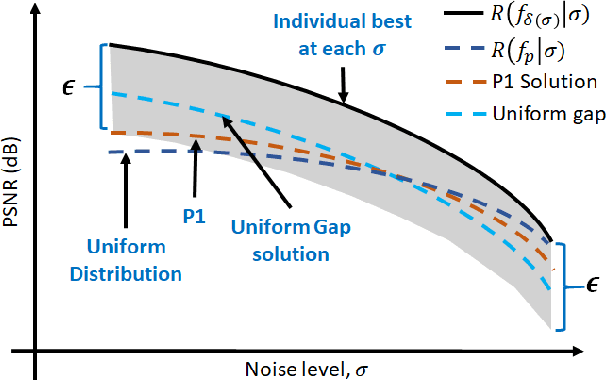
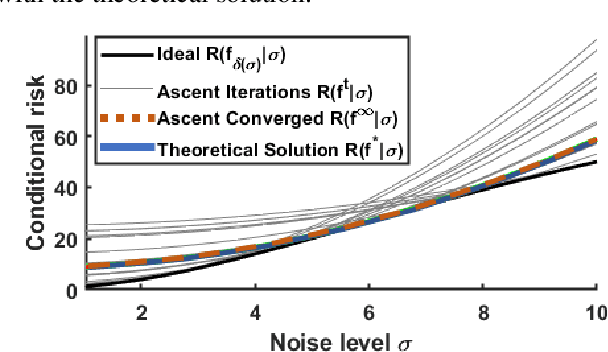
When training an estimator such as a neural network for tasks like image denoising, it is often preferred to train \emph{one} estimator and apply it to \emph{all} noise levels. The de facto training protocol to achieve this goal is to train the estimator with noisy samples whose noise levels are uniformly distributed across the range of interest. However, why should we allocate the samples uniformly? Can we have more training samples that are less noisy, and fewer samples that are more noisy? What is the optimal distribution? How do we obtain such a distribution? The goal of this paper is to address this training sample distribution problem from a minimax risk optimization perspective. We derive a dual ascent algorithm to determine the optimal sampling distribution of which the convergence is guaranteed as long as the set of admissible estimators is closed and convex. For estimators with non-convex admissible sets such as deep neural networks, our dual formulation converges to a solution of the convex relaxation. We discuss how the algorithm can be implemented in practice. We evaluate the algorithm on linear estimators and deep networks.
Anisotropic Diffusion for Details Enhancement in Multi-Exposure Image Fusion
Jul 10, 2013
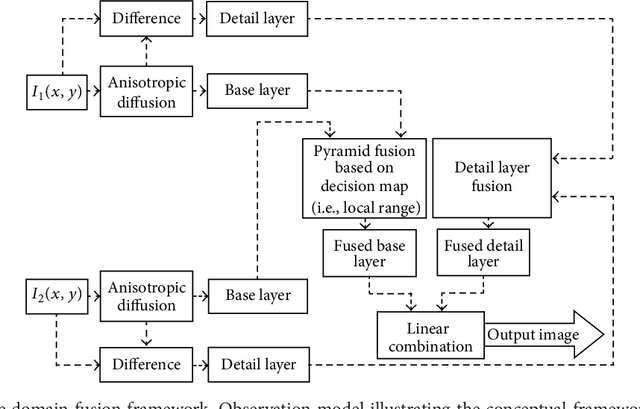
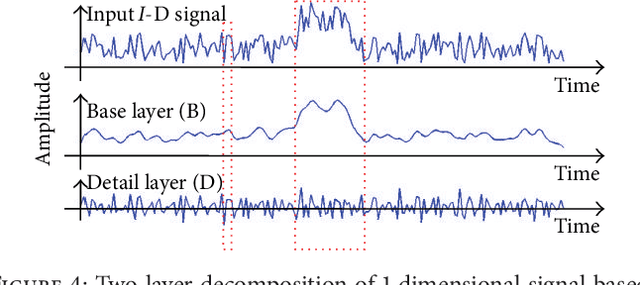
We develop a multiexposure image fusion method based on texture features, which exploits the edge preserving and intraregion smoothing property of nonlinear diffusion filters based on partial differential equations (PDE). With the captured multiexposure image series, we first decompose images into base layers and detail layers to extract sharp details and fine details, respectively. The magnitude of the gradient of the image intensity is utilized to encourage smoothness at homogeneous regions in preference to inhomogeneous regions. Then, we have considered texture features of the base layer to generate a mask (i.e., decision mask) that guides the fusion of base layers in multiresolution fashion. Finally, well-exposed fused image is obtained that combines fused base layer and the detail layers at each scale across all the input exposures. Proposed algorithm skipping complex High Dynamic Range Image (HDRI) generation and tone mapping steps to produce detail preserving image for display on standard dynamic range display devices. Moreover, our technique is effective for blending flash/no-flash image pair and multifocus images, that is, images focused on different targets.
* 30 pages
Detection of False Positive and False Negative Samples in Semantic Segmentation
Dec 08, 2019
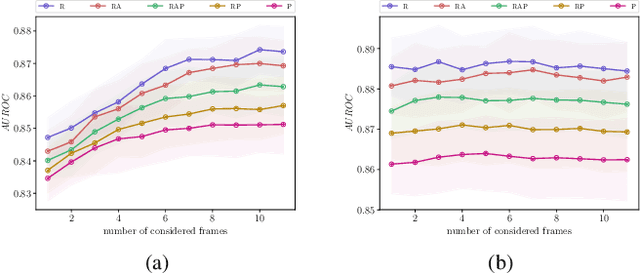

In recent years, deep learning methods have outperformed other methods in image recognition. This has fostered imagination of potential application of deep learning technology including safety relevant applications like the interpretation of medical images or autonomous driving. The passage from assistance of a human decision maker to ever more automated systems however increases the need to properly handle the failure modes of deep learning modules. In this contribution, we review a set of techniques for the self-monitoring of machine-learning algorithms based on uncertainty quantification. In particular, we apply this to the task of semantic segmentation, where the machine learning algorithm decomposes an image according to semantic categories. We discuss false positive and false negative error modes at instance-level and review techniques for the detection of such errors that have been recently proposed by the authors. We also give an outlook on future research directions.
Adversarial optimization for joint registration and segmentation in prostate CT radiotherapy
Jun 28, 2019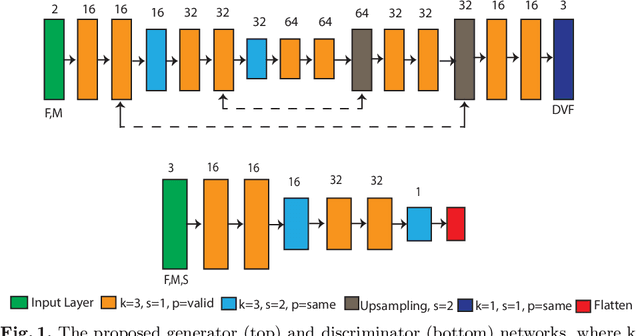


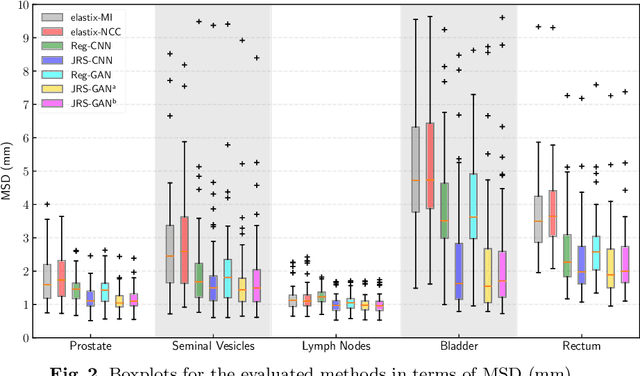
Joint image registration and segmentation has long been an active area of research in medical imaging. Here, we reformulate this problem in a deep learning setting using adversarial learning. We consider the case in which fixed and moving images as well as their segmentations are available for training, while segmentations are not available during testing; a common scenario in radiotherapy. The proposed framework consists of a 3D end-to-end generator network that estimates the deformation vector field (DVF) between fixed and moving images in an unsupervised fashion and applies this DVF to the moving image and its segmentation. A discriminator network is trained to evaluate how well the moving image and segmentation align with the fixed image and segmentation. The proposed network was trained and evaluated on follow-up prostate CT scans for image-guided radiotherapy, where the planning CT contours are propagated to the daily CT images using the estimated DVF. A quantitative comparison with conventional registration using \texttt{elastix} showed that the proposed method improved performance and substantially reduced computation time, thus enabling real-time contour propagation necessary for online-adaptive radiotherapy.
Calibrated neighborhood aware confidence measure for deep metric learning
Jun 08, 2020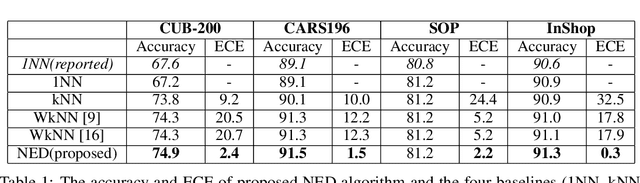
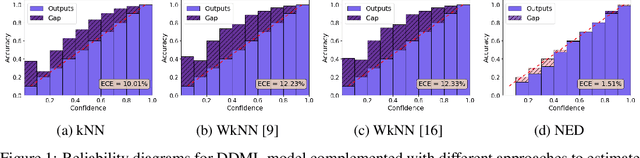
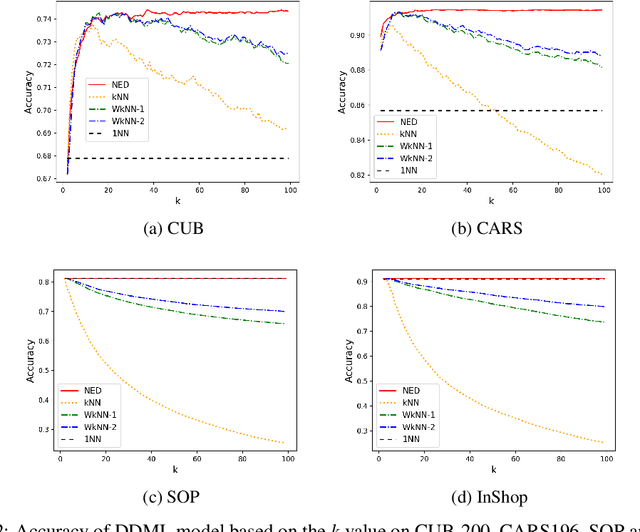
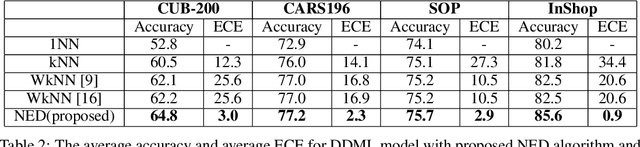
Deep metric learning has gained promising improvement in recent years following the success of deep learning. It has been successfully applied to problems in few-shot learning, image retrieval, and open-set classifications. However, measuring the confidence of a deep metric learning model and identifying unreliable predictions is still an open challenge. This paper focuses on defining a calibrated and interpretable confidence metric that closely reflects its classification accuracy. While performing similarity comparison directly in the latent space using the learned distance metric, our approach approximates the distribution of data points for each class using a Gaussian kernel smoothing function. The post-processing calibration algorithm with proposed confidence metric on the held-out validation dataset improves generalization and robustness of state-of-the-art deep metric learning models while provides an interpretable estimation of the confidence. Extensive tests on four popular benchmark datasets (Caltech-UCSD Birds, Stanford Online Product, Stanford Car-196, and In-shop Clothes Retrieval) show consistent improvements even at the presence of distribution shifts in test data related to additional noise or adversarial examples.
Benefits of temporal information for appearance-based gaze estimation
May 24, 2020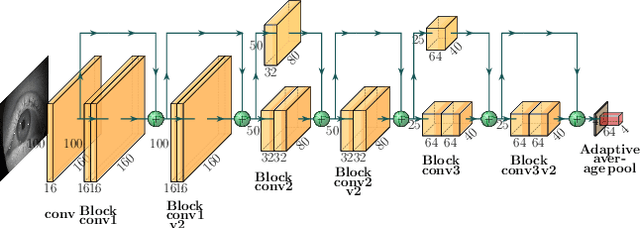
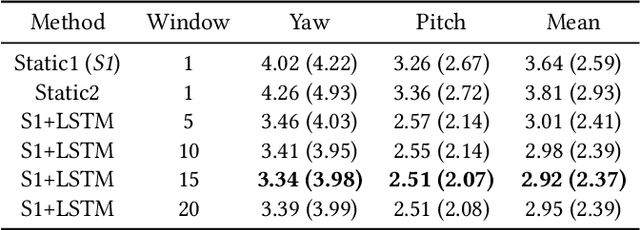
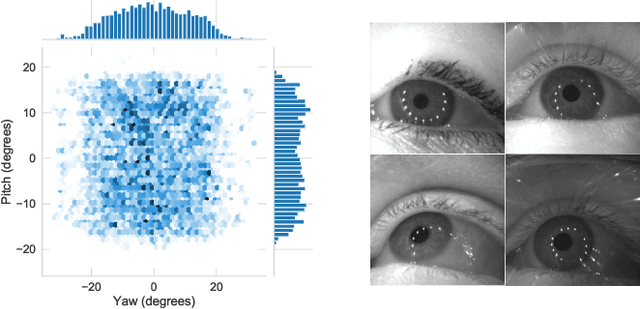
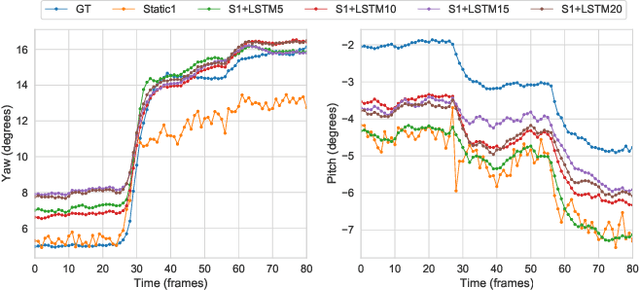
State-of-the-art appearance-based gaze estimation methods, usually based on deep learning techniques, mainly rely on static features. However, temporal trace of eye gaze contains useful information for estimating a given gaze point. For example, approaches leveraging sequential eye gaze information when applied to remote or low-resolution image scenarios with off-the-shelf cameras are showing promising results. The magnitude of contribution from temporal gaze trace is yet unclear for higher resolution/frame rate imaging systems, in which more detailed information about an eye is captured. In this paper, we investigate whether temporal sequences of eye images, captured using a high-resolution, high-frame rate head-mounted virtual reality system, can be leveraged to enhance the accuracy of an end-to-end appearance-based deep-learning model for gaze estimation. Performance is compared against a static-only version of the model. Results demonstrate statistically-significant benefits of temporal information, particularly for the vertical component of gaze.
DR-KFD: A Differentiable Visual Metric for 3D Shape Reconstruction
Nov 28, 2019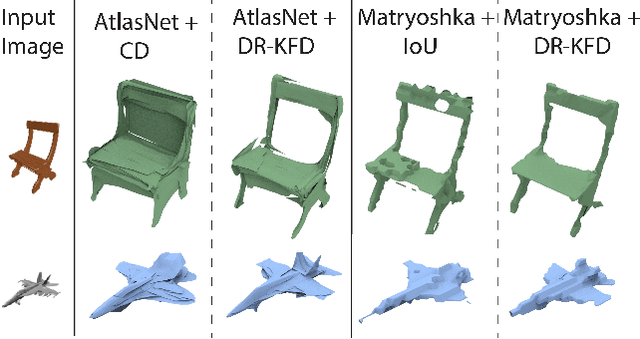
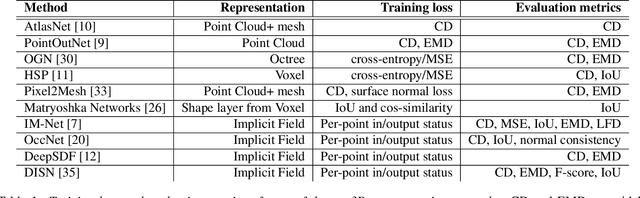
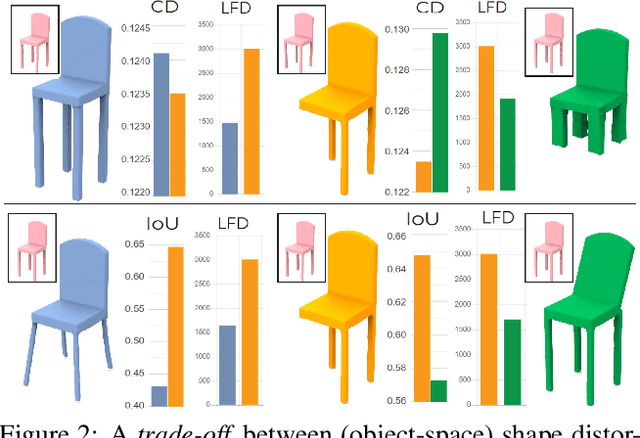
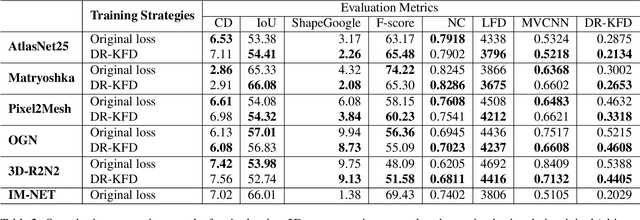
We advocate the use of differential visual shape metrics to train deep neural networks for 3D reconstruction. We introduce such a metric which compares two 3D shapes by measuring visual, image-space differences between multiview images differentiably rendered from the shapes. Furthermore, we develop a differentiable image-space distance based on mean-squared errors defined over Hard- Net features computed from probabilistic keypoint maps of the compared images. Our differential visual shape metric can be easily plugged into various reconstruction networks, replacing the object-space distortion measures, such as Chamfer or Earth Mover distances, so as to optimize the network weights to produce reconstruction results with better structural fidelity and visual quality. We demonstrate this both objectively, using well-known visual shape metrics for retrieval and classification tasks that are independent from our new metric, and subjectively through a perceptual study.
Probabilistic Semantic Mapping for Urban Autonomous Driving Applications
Jun 08, 2020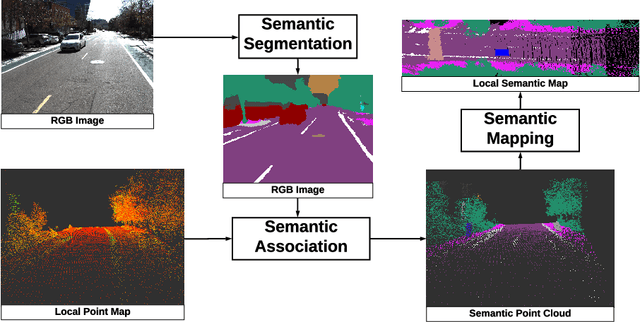
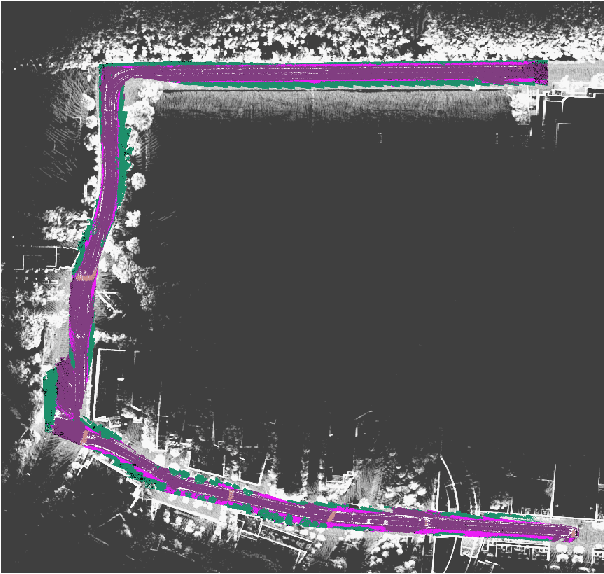

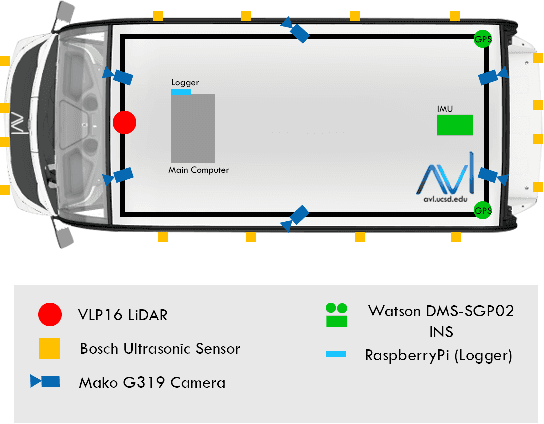
Recent advancement in statistical learning and computational ability has enabled autonomous vehicle technology to develop at a much faster rate and become widely adopted. While many of the architectures previously introduced are capable of operating under highly dynamic environments, many of these are constrained to smaller-scale deployments and require constant maintenance due to the associated scalability cost with high-definition (HD) maps. HD maps provide critical information for self-driving cars to drive safely. However, traditional approaches for creating HD maps involves tedious manual labeling. As an attempt to tackle this problem, we fuse 2D image semantic segmentation with pre-built point cloud maps collected from a relatively inexpensive 16 channel LiDAR sensor to construct a local probabilistic semantic map in bird's eye view that encodes static landmarks such as roads, sidewalks, crosswalks, and lanes in the driving environment. Experiments from data collected in an urban environment show that this model can be extended for automatically incorporating road features into HD maps with potential future work directions.