 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Food Image Recognition by Using Convolutional Neural Networks (CNNs)
Dec 03, 2016
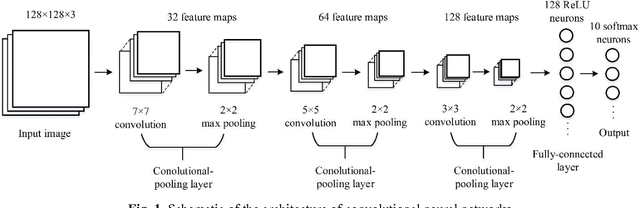


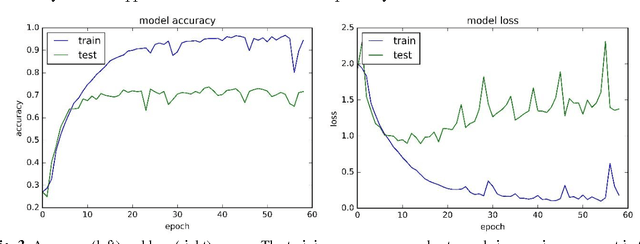
Food image recognition is one of the promising applications of visual object recognition in computer vision. In this study, a small-scale dataset consisting of 5822 images of ten categories and a five-layer CNN was constructed to recognize these images. The bag-of-features (BoF) model coupled with support vector machine was first tested as comparison, resulting in an overall accuracy of 56%, while the CNN performed much better with an overall accuracy of 74%. Data expansion techniques were applied to increase the size of training images, which achieved a significantly improved accuracy of more than 90% and prevent the overfitting issue that occurred to the CNN without using data expansion. Further improvement is within reach by collecting more images and optimizing the network architecture and relevant hyper-parameters.
Global visual localization in LiDAR-maps through shared 2D-3D embedding space
Oct 02, 2019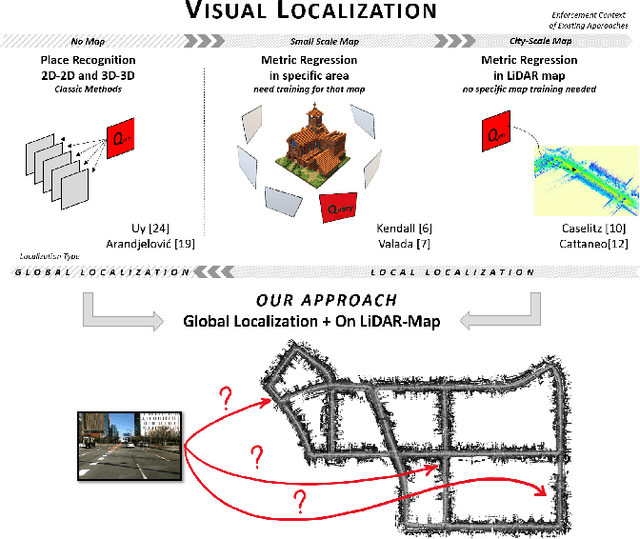
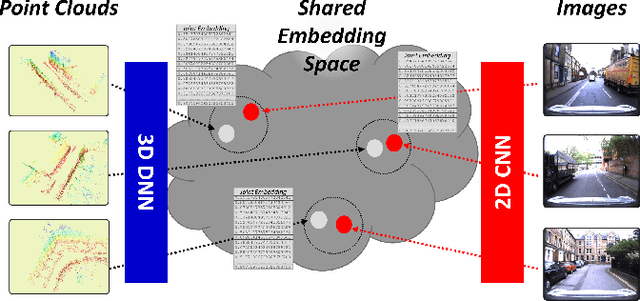
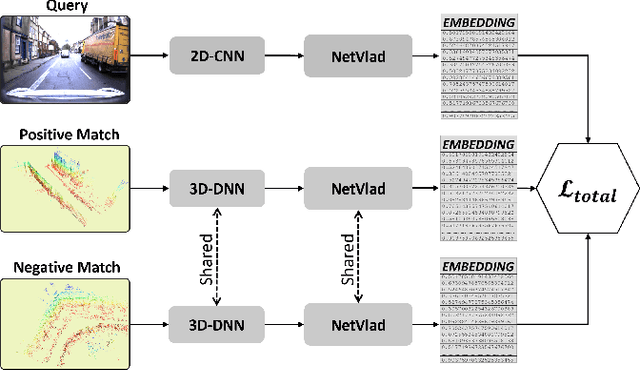
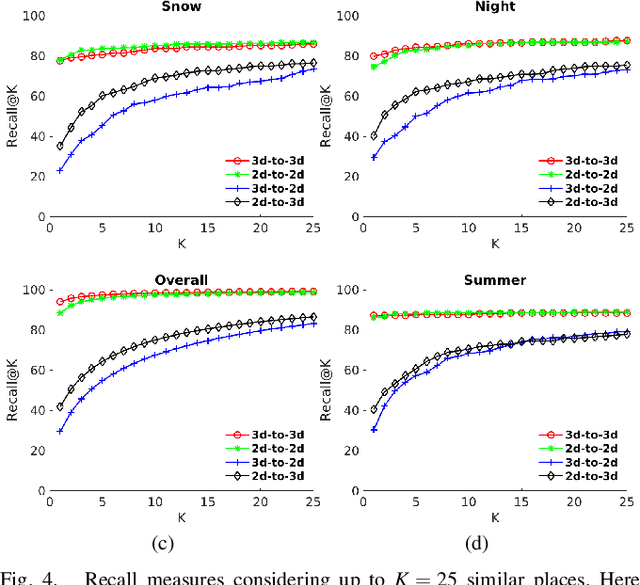
Global localization is an important and widely studied problem for many robotic applications. Place recognition approaches can be exploited to solve this task, e.g., in the autonomous driving field. While most vision-based approaches match an image w.r.t an image database, global visual localization within LiDAR-maps remains fairly unexplored, even though the path toward high definition 3D maps, produced mainly from LiDARs, is clear. In this work we leverage DNN approaches to create a shared embedding space between images and LiDAR-maps, allowing for image to 3D-LiDAR place recognition. We trained a 2D and a 3D Deep Neural Networks (DNNs) that create embeddings, respectively from images and from point clouds, that are close to each other whether they refer to the same place. An extensive experimental activity is presented to assess the effectiveness of the approach w.r.t. different learning methods, network architectures, and loss functions. All the evaluations have been performed using the Oxford Robotcar Dataset, which encompasses a wide range of weather and light conditions.
Image Analysis Using a Dual-Tree $M$-Band Wavelet Transform
Feb 27, 2017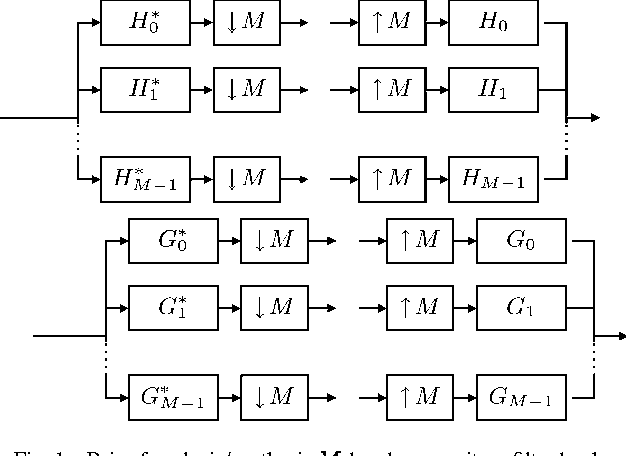
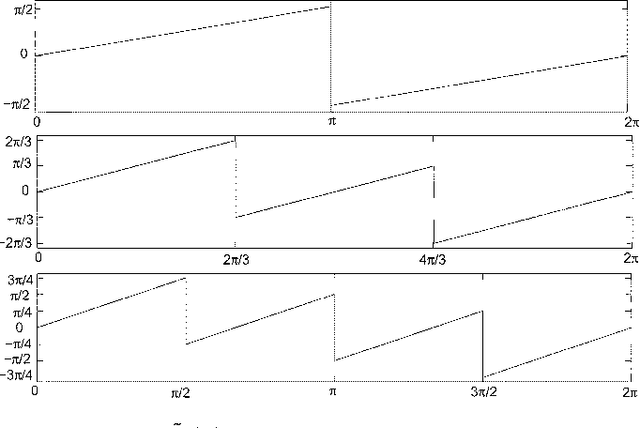
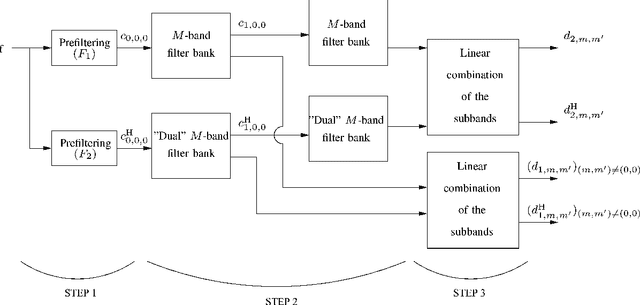
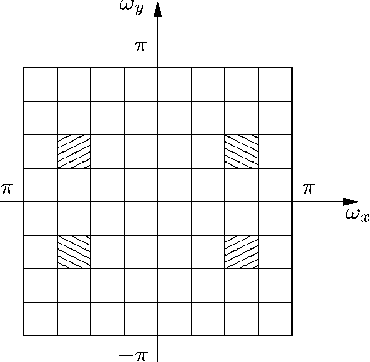
We propose a 2D generalization to the $M$-band case of the dual-tree decomposition structure (initially proposed by N. Kingsbury and further investigated by I. Selesnick) based on a Hilbert pair of wavelets. We particularly address (\textit{i}) the construction of the dual basis and (\textit{ii}) the resulting directional analysis. We also revisit the necessary pre-processing stage in the $M$-band case. While several reconstructions are possible because of the redundancy of the representation, we propose a new optimal signal reconstruction technique, which minimizes potential estimation errors. The effectiveness of the proposed $M$-band decomposition is demonstrated via denoising comparisons on several image types (natural, texture, seismics), with various $M$-band wavelets and thresholding strategies. Significant improvements in terms of both overall noise reduction and direction preservation are observed.
BreastScreening: On the Use of Multi-Modality in Medical Imaging Diagnosis
Apr 07, 2020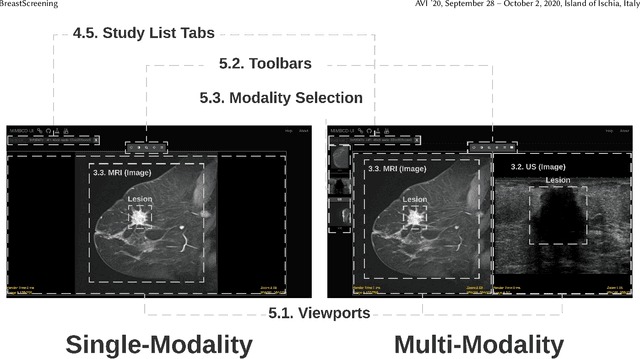
This paper describes the field research, design and comparative deployment of a multimodal medical imaging user interface for breast screening. The main contributions described here are threefold: 1) The design of an advanced visual interface for multimodal diagnosis of breast cancer (BreastScreening); 2) Insights from the field comparison of single vs multimodality screening of breast cancer diagnosis with 31 clinicians and 566 images, and 3) The visualization of the two main types of breast lesions in the following image modalities: (i) MammoGraphy (MG) in both Craniocaudal (CC) and Mediolateral oblique (MLO) views; (ii) UltraSound (US); and (iii) Magnetic Resonance Imaging (MRI). We summarize our work with recommendations from the radiologists for guiding the future design of medical imaging interfaces.
Real-Time Document Image Classification using Deep CNN and Extreme Learning Machines
Nov 03, 2017


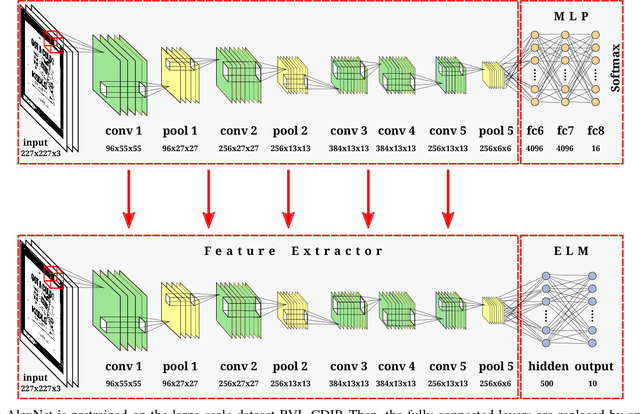
This paper presents an approach for real-time training and testing for document image classification. In production environments, it is crucial to perform accurate and (time-)efficient training. Existing deep learning approaches for classifying documents do not meet these requirements, as they require much time for training and fine-tuning the deep architectures. Motivated from Computer Vision, we propose a two-stage approach. The first stage trains a deep network that works as feature extractor and in the second stage, Extreme Learning Machines (ELMs) are used for classification. The proposed approach outperforms all previously reported structural and deep learning based methods with a final accuracy of 83.24% on Tobacco-3482 dataset, leading to a relative error reduction of 25% when compared to a previous Convolutional Neural Network (CNN) based approach (DeepDocClassifier). More importantly, the training time of the ELM is only 1.176 seconds and the overall prediction time for 2,482 images is 3.066 seconds. As such, this novel approach makes deep learning-based document classification suitable for large-scale real-time applications.
Point Cloud Based Reinforcement Learning for Sim-to-Real and Partial Observability in Visual Navigation
Jul 27, 2020
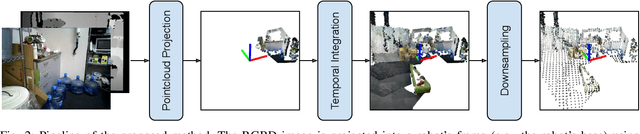
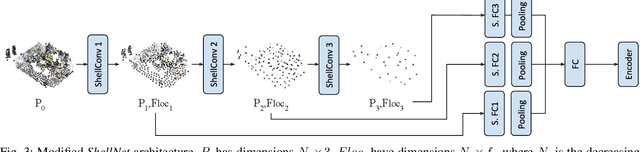
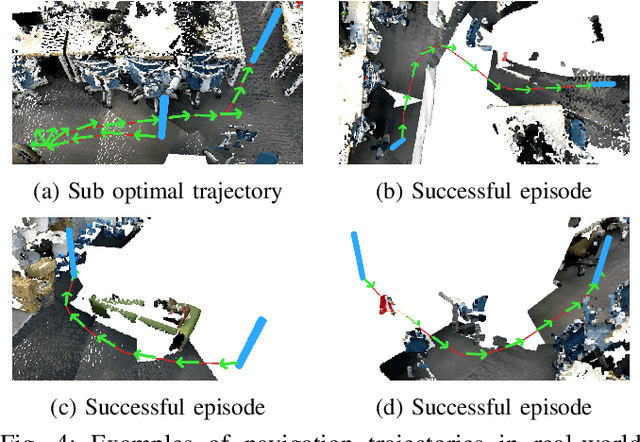
Reinforcement Learning (RL), among other learning-based methods, represents powerful tools to solve complex robotic tasks (e.g., actuation, manipulation, navigation, etc.), with the need for real-world data to train these systems as one of its most important limitations. The use of simulators is one way to address this issue, yet knowledge acquired in simulations does not work directly in the real-world, which is known as the sim-to-real transfer problem. While previous works focus on the nature of the images used as observations (e.g., textures and lighting), which has proven useful for a sim-to-sim transfer, they neglect other concerns regarding said observations, such as precise geometrical meanings, failing at robot-to-robot, and thus in sim-to-real transfers. We propose a method that learns on an observation space constructed by point clouds and environment randomization, generalizing among robots and simulators to achieve sim-to-real, while also addressing partial observability. We demonstrate the benefits of our methodology on the point goal navigation task, in which our method proves to be highly unaffected to unseen scenarios produced by robot-to-robot transfer, outperforms image-based baselines in robot-randomized experiments, and presents high performances in sim-to-sim conditions. Finally, we perform several experiments to validate the sim-to-real transfer to a physical domestic robot platform, confirming the out-of-the-box performance of our system.
Transfer learning in hybrid classical-quantum neural networks
Dec 17, 2019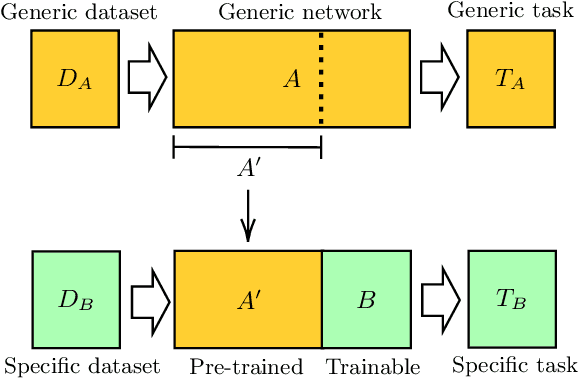
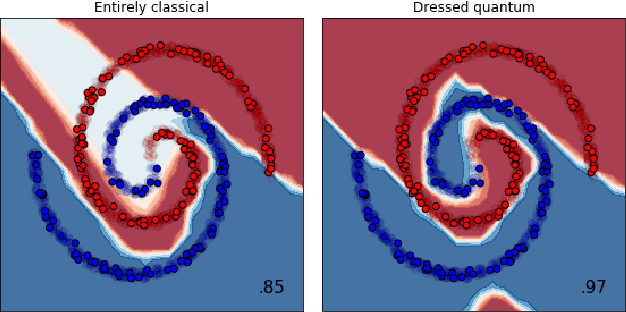

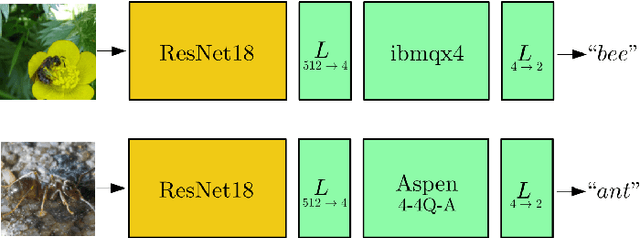
We extend the concept of transfer learning, widely applied in modern machine learning algorithms, to the emerging context of hybrid neural networks composed of classical and quantum elements. We propose different implementations of hybrid transfer learning, but we focus mainly on the paradigm in which a pre-trained classical network is modified and augmented by a final variational quantum circuit. This approach is particularly attractive in the current era of intermediate-scale quantum technology since it allows to optimally pre-process high dimensional data (e.g., images) with any state-of-the-art classical network and to embed a select set of highly informative features into a quantum processor. We present several proof-of-concept examples of the convenient application of quantum transfer learning for image recognition and quantum state classification. We use the cross-platform software library PennyLane to experimentally test a high-resolution image classifier with two different quantum computers, respectively provided by IBM and Rigetti.
IV-SLAM: Introspective Vision for Simultaneous Localization and Mapping
Aug 06, 2020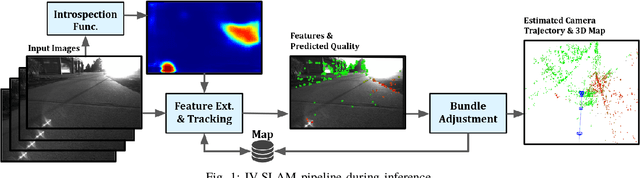

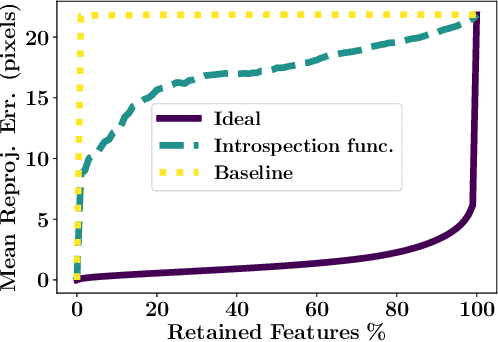
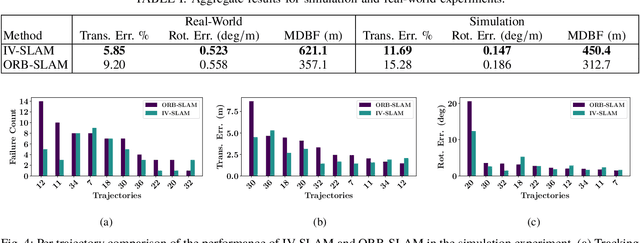
Existing solutions to visual simultaneous localization and mapping (V-SLAM) assume that errors in feature extraction and matching are independent and identically distributed (i.i.d), but this assumption is known to not be true -- features extracted from low-contrast regions of images exhibit wider error distributions than features from sharp corners. Furthermore, V-SLAM algorithms are prone to catastrophic tracking failures when sensed images include challenging conditions such as specular reflections, lens flare, or shadows of dynamic objects. To address such failures, previous work has focused on building more robust visual frontends, to filter out challenging features. In this paper, we present introspective vision for SLAM (IV-SLAM), a fundamentally different approach for addressing these challenges. IV-SLAM explicitly models the noise process of reprojection errors from visual features to be context-dependent, and hence non-i.i.d. We introduce an autonomously supervised approach for IV-SLAM to collect training data to learn such a context-aware noise model. Using this learned noise model, IV-SLAM guides feature extraction to select more features from parts of the image that are likely to result in lower noise, and further incorporate the learned noise model into the joint maximum likelihood estimation, thus making it robust to the aforementioned types of errors. We present empirical results to demonstrate that IV-SLAM 1) is able to accurately predict sources of error in input images, 2) reduces tracking error compared to V-SLAM, and 3) increases the mean distance between tracking failures by more than 70% on challenging real robot data compared to V-SLAM.
DO-Conv: Depthwise Over-parameterized Convolutional Layer
Jun 22, 2020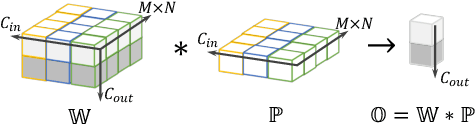
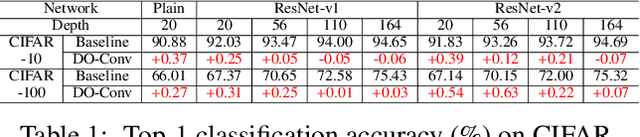

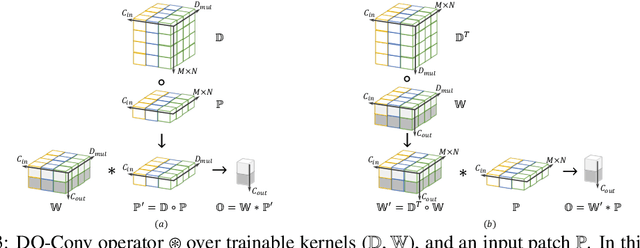
Convolutional layers are the core building blocks of Convolutional Neural Networks (CNNs). In this paper, we propose to augment a convolutional layer with an additional depthwise convolution, where each input channel is convolved with a different 2D kernel. The composition of the two convolutions constitutes an over-parameterization, since it adds learnable parameters, while the resulting linear operation can be expressed by a single convolution layer. We refer to this depthwise over-parameterized convolutional layer as DO-Conv. We show with extensive experiments that the mere replacement of conventional convolutional layers with DO-Conv layers boosts the performance of CNNs on many classical vision tasks, such as image classification, detection, and segmentation. Moreover, in the inference phase, the depthwise convolution is folded into the conventional convolution, reducing the computation to be exactly equivalent to that of a convolutional layer without over-parameterization. As DO-Conv introduces performance gains without incurring any computational complexity increase for inference, we advocate it as an alternative to the conventional convolutional layer. We open-source a reference implementation of DO-Conv in Tensorflow, PyTorch and GluonCV at https://github.com/yangyanli/DO-Conv.
Generating Memorable Images Based on Human Visual Memory Schemas
May 06, 2020
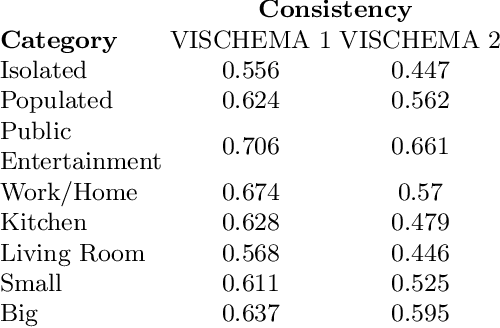
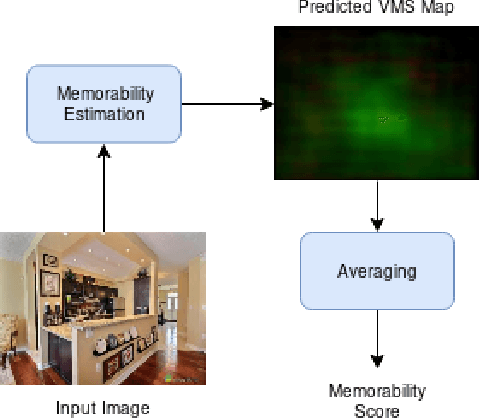
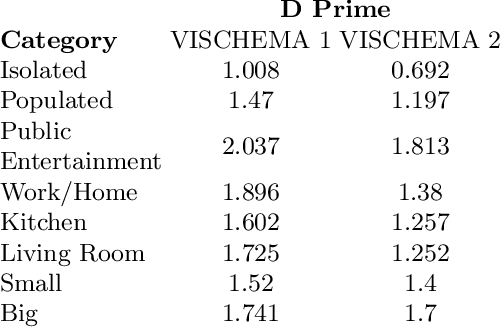
This research study proposes using Generative Adversarial Networks (GAN) that incorporate a two-dimensional measure of human memorability to generate memorable or non-memorable images of scenes. The memorability of the generated images is evaluated by modelling Visual Memory Schemas (VMS), which correspond to mental representations that human observers use to encode an image into memory. The VMS model is based upon the results of memory experiments conducted on human observers, and provides a 2D map of memorability. We impose a memorability constraint upon the latent space of a GAN by employing a VMS map prediction model as an auxiliary loss. We assess the difference in memorability between images generated to be memorable or non-memorable through an independent computational measure of memorability, and additionally assess the effect of memorability on the realness of the generated images.