 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RSVQA: Visual Question Answering for Remote Sensing Data
Mar 16, 2020
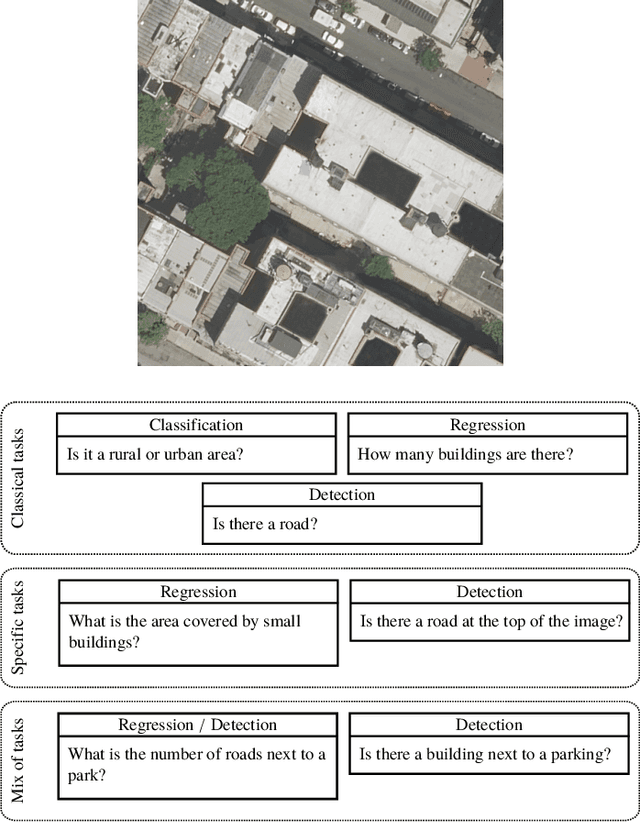
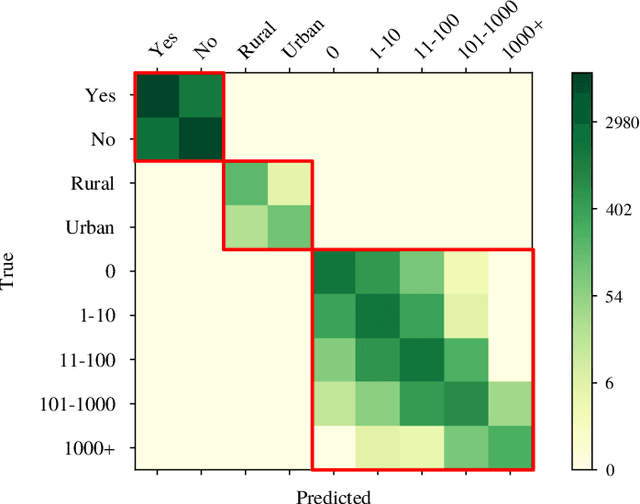
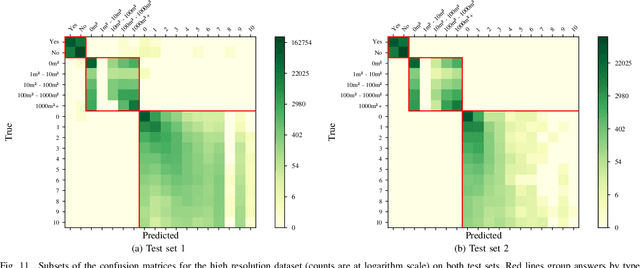
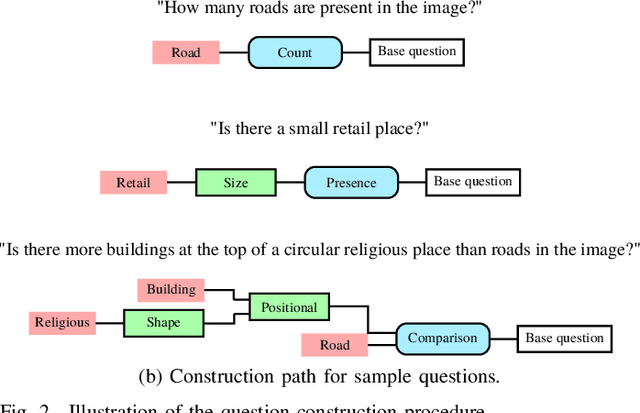
This paper introduces the task of visual question answering for remote sensing data (RSVQA). Remote sensing images contain a wealth of information which can be useful for a wide range of tasks including land cover classification, object counting or detection. However, most of the available methodologies are task-specific, thus inhibiting generic and easy access to the information contained in remote sensing data. As a consequence, accurate remote sensing product generation still requires expert knowledge. With RSVQA, we propose a system to extract information from remote sensing data that is accessible to every user: we use questions formulated in natural language and use them to interact with the images. With the system, images can be queried to obtain high level information specific to the image content or relational dependencies between objects visible in the images. Using an automatic method introduced in this article, we built two datasets (using low and high resolution data) of image/question/answer triplets. The information required to build the questions and answers is queried from OpenStreetMap (OSM). The datasets can be used to train (when using supervised methods) and evaluate models to solve the RSVQA task. We report the results obtained by applying a model based on Convolutional Neural Networks (CNNs) for the visual part and on a Recurrent Neural Network (RNN) for the natural language part to this task. The model is trained on the two datasets, yielding promising results in both cases.
Detecting Anomalous Inputs to DNN Classifiers By Joint Statistical Testing at the Layers
Jul 29, 2020
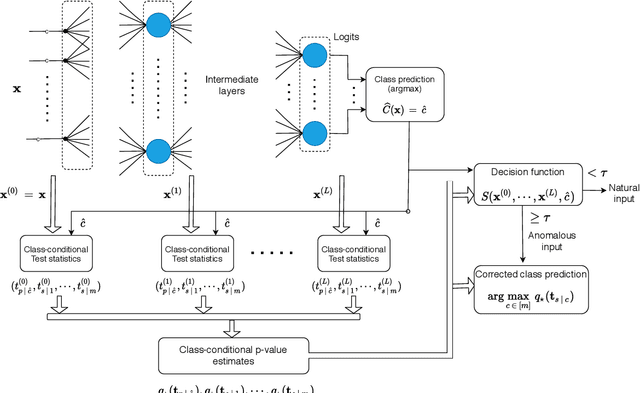
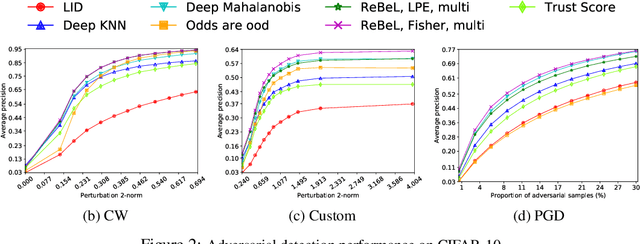
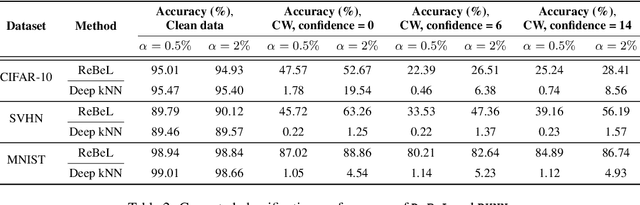
Detecting anomalous inputs, such as adversarial and out-of-distribution (OOD) inputs, is critical for classifiers deployed in real-world applications, especially deep neural network (DNN) classifiers that are known to be brittle on such inputs. We propose an unsupervised statistical testing framework for detecting such anomalous inputs to a trained DNN classifier based on its internal layer representations. By calculating test statistics at the input and intermediate-layer representations of the DNN, conditioned individually on the predicted class and on the true class of labeled training data, the method characterizes their class-conditional distributions on natural inputs. Given a test input, its extent of non-conformity with respect to the training distribution is captured using p-values of the class-conditional test statistics across the layers, which are then combined using a scoring function designed to score high on anomalous inputs. We focus on adversarial inputs, which are an important class of anomalous inputs, and also demonstrate the effectiveness of our method on general OOD inputs. The proposed framework also provides an alternative class prediction that can be used to correct the DNNs prediction on (detected) adversarial inputs. Experiments on well-known image classification datasets with strong adversarial attacks, including a custom attack method that uses the internal layer representations of the DNN, demonstrate that our method outperforms or performs comparably with five state-of-the-art detection methods.
PermuteAttack: Counterfactual Explanation of Machine Learning Credit Scorecards
Aug 28, 2020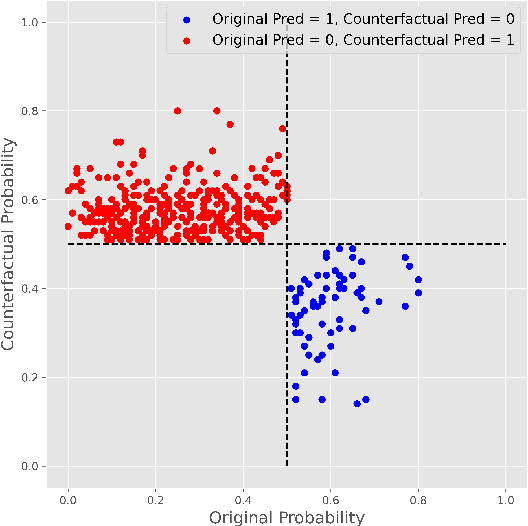
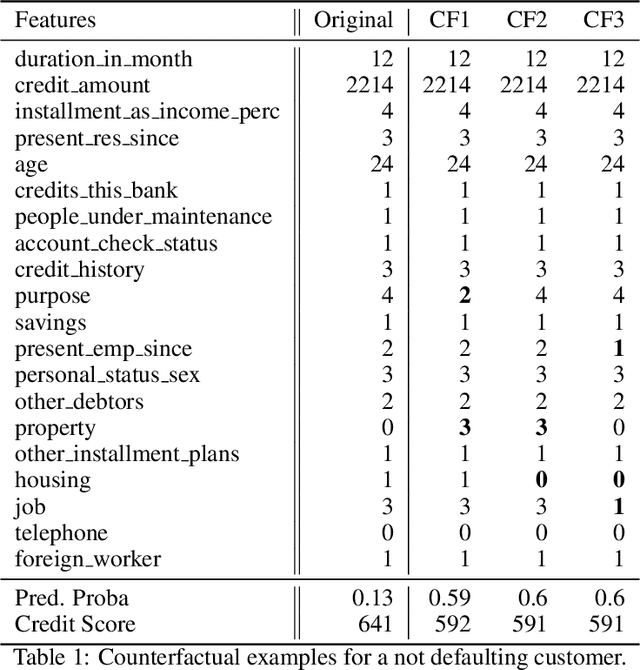
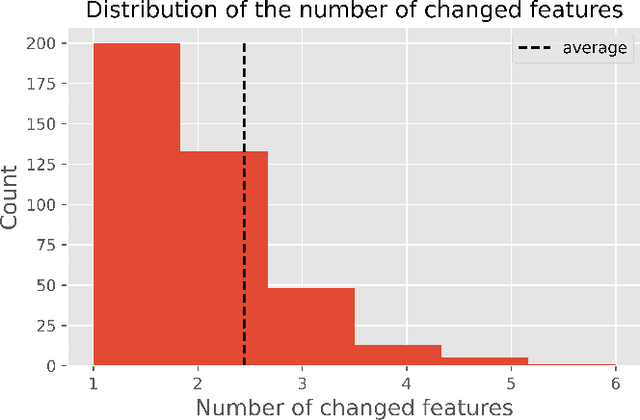
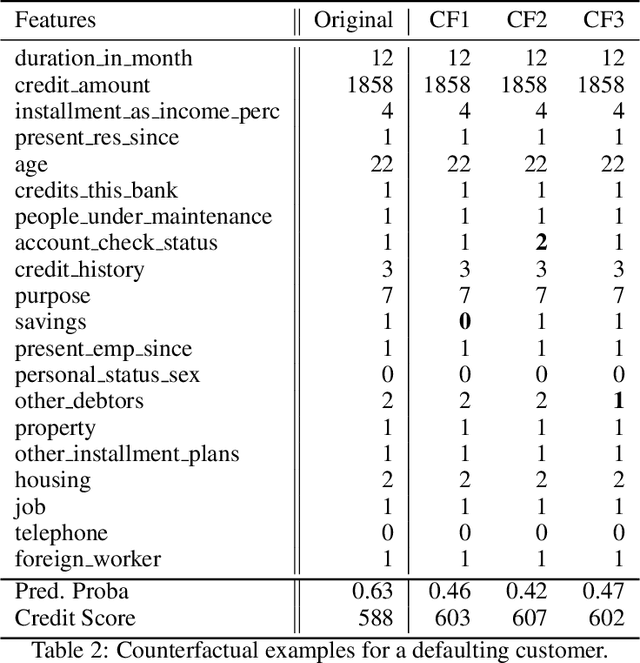
This paper is a note on new directions and methodologies for validation and explanation of Machine Learning (ML) models employed for retail credit scoring in finance. Our proposed framework draws motivation from the field of Artificial Intelligence (AI) security and adversarial ML where the need for certifying the performance of the ML algorithms in the face of their overwhelming complexity poses a need for rethinking the traditional notions of model architecture selection, sensitivity analysis and stress testing. Our point of view is that the phenomenon of adversarial perturbations when detached from the AI security domain, has purely algorithmic roots and fall within the scope of model risk assessment. We propose a model criticism and explanation framework based on adversarially generated counterfactual examples for tabular data. A counterfactual example to a given instance in this context is defined as a synthetically generated data point sampled from the estimated data distribution which is treated differently by a model. The counterfactual examples can be used to provide a black-box instance-level explanation of the model behaviour as well as studying the regions in the input space where the model performance deteriorates. Adversarial example generating algorithms are extensively studied in the image and natural language processing (NLP) domains. However, most financial data come in tabular format and naive application of the existing techniques on this class of datasets generates unrealistic samples. In this paper, we propose a counterfactual example generation method capable of handling tabular data including discrete and categorical variables. Our proposed algorithm uses a gradient-free optimization based on genetic algorithms and therefore is applicable to any classification model.
Regional Active Contours based on Variational level sets and Machine Learning for Image Segmentation
Oct 31, 2015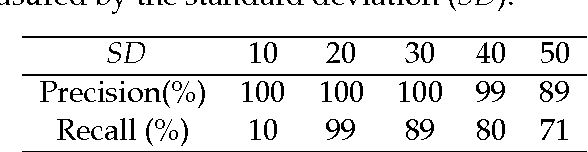
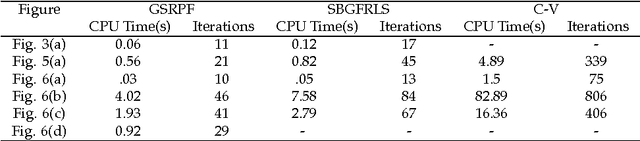
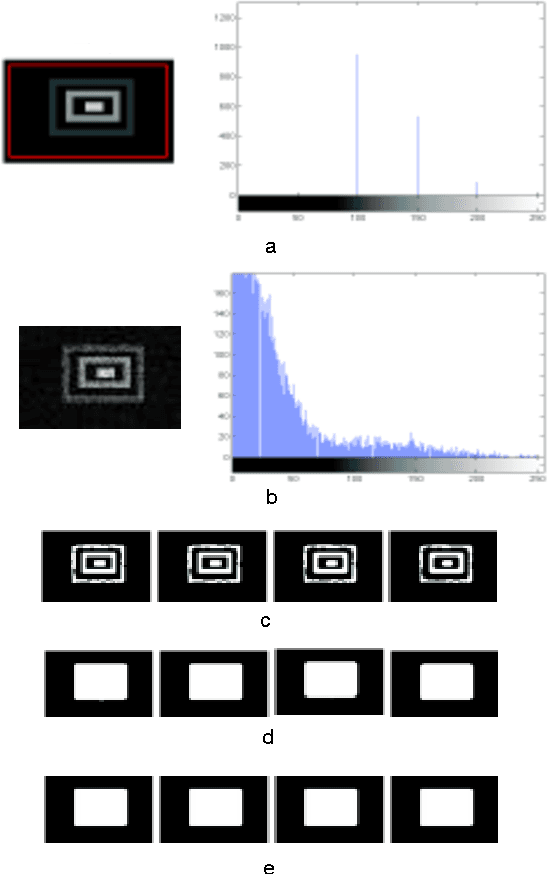

Image segmentation is the problem of partitioning an image into different subsets, where each subset may have a different characterization in terms of color, intensity, texture, and/or other features. Segmentation is a fundamental component of image processing, and plays a significant role in computer vision, object recognition, and object tracking. Active Contour Models (ACMs) constitute a powerful energy-based minimization framework for image segmentation, which relies on the concept of contour evolution. Starting from an initial guess, the contour is evolved with the aim of approximating better and better the actual object boundary. Handling complex images in an efficient, effective, and robust way is a real challenge, especially in the presence of intensity inhomogeneity, overlap between the foreground/background intensity distributions, objects characterized by many different intensities, and/or additive noise. In this thesis, to deal with these challenges, we propose a number of image segmentation models relying on variational level set methods and specific kinds of neural networks, to handle complex images in both supervised and unsupervised ways. Experimental results demonstrate the high accuracy of the segmentation results, obtained by the proposed models on various benchmark synthetic and real images compared with state-of-the-art active contour models.
Data consistency networks for (calibration-less) accelerated parallel MR image reconstruction
Sep 25, 2019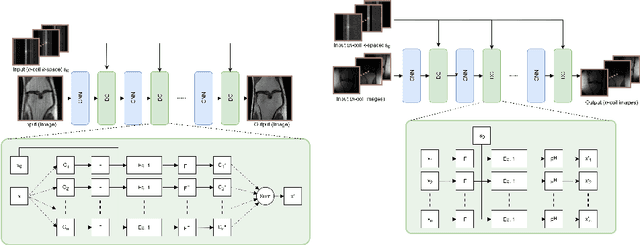
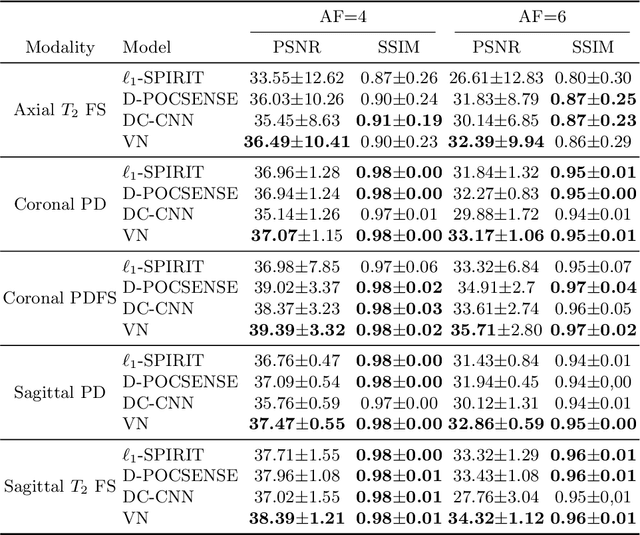
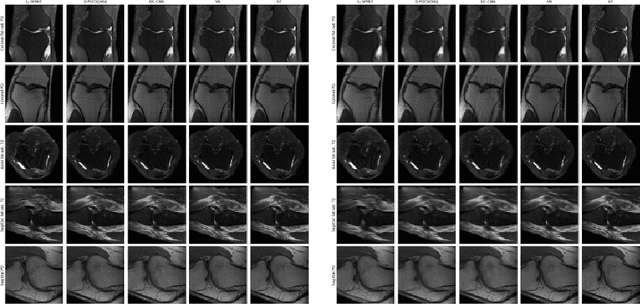
We present simple reconstruction networks for multi-coil data by extending deep cascade of CNN's and exploiting the data consistency layer. In particular, we propose two variants, where one is inspired by POCSENSE and the other is calibration-less. We show that the proposed approaches are competitive relative to the state of the art both quantitatively and qualitatively.
Methodology for Building Synthetic Datasets with Virtual Humans
Jun 21, 2020


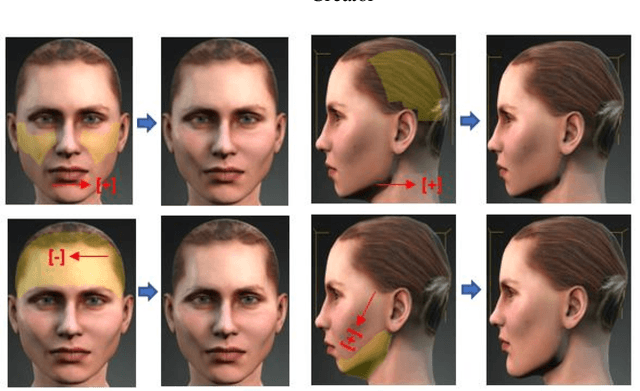
Recent advances in deep learning methods have increased the performance of face detection and recognition systems. The accuracy of these models relies on the range of variation provided in the training data. Creating a dataset that represents all variations of real-world faces is not feasible as the control over the quality of the data decreases with the size of the dataset. Repeatability of data is another challenge as it is not possible to exactly recreate 'real-world' acquisition conditions outside of the laboratory. In this work, we explore a framework to synthetically generate facial data to be used as part of a toolchain to generate very large facial datasets with a high degree of control over facial and environmental variations. Such large datasets can be used for improved, targeted training of deep neural networks. In particular, we make use of a 3D morphable face model for the rendering of multiple 2D images across a dataset of 100 synthetic identities, providing full control over image variations such as pose, illumination, and background.
What Neural Networks Memorize and Why: Discovering the Long Tail via Influence Estimation
Aug 09, 2020
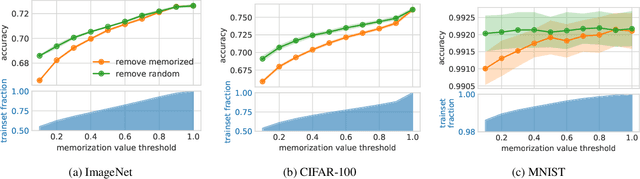
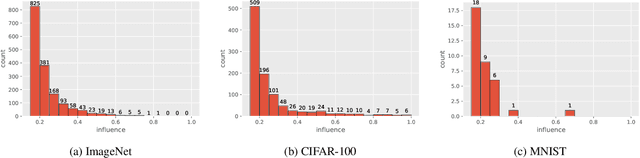

Deep learning algorithms are well-known to have a propensity for fitting the training data very well and often fit even outliers and mislabeled data points. Such fitting requires memorization of training data labels, a phenomenon that has attracted significant research interest but has not been given a compelling explanation so far. A recent work of Feldman (2019) proposes a theoretical explanation for this phenomenon based on a combination of two insights. First, natural image and data distributions are (informally) known to be long-tailed, that is have a significant fraction of rare and atypical examples. Second, in a simple theoretical model such memorization is necessary for achieving close-to-optimal generalization error when the data distribution is long-tailed. However, no direct empirical evidence for this explanation or even an approach for obtaining such evidence were given. In this work we design experiments to test the key ideas in this theory. The experiments require estimation of the influence of each training example on the accuracy at each test example as well as memorization values of training examples. Estimating these quantities directly is computationally prohibitive but we show that closely-related subsampled influence and memorization values can be estimated much more efficiently. Our experiments demonstrate the significant benefits of memorization for generalization on several standard benchmarks. They also provide quantitative and visually compelling evidence for the theory put forth in (Feldman, 2019).
Personalized Face Modeling for Improved Face Reconstruction and Motion Retargeting
Jul 17, 2020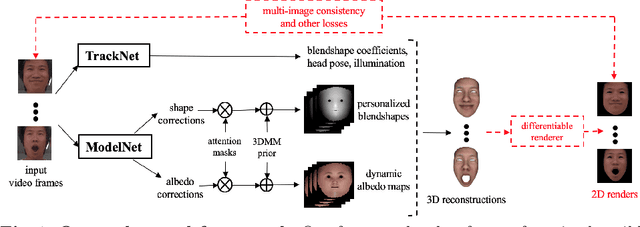
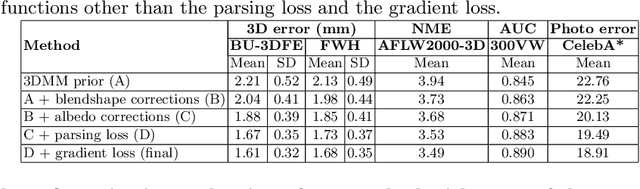


Traditional methods for image-based 3D face reconstruction and facial motion retargeting fit a 3D morphable model (3DMM) to the face, which has limited modeling capacity and fail to generalize well to in-the-wild data. Use of deformation transfer or multilinear tensor as a personalized 3DMM for blendshape interpolation does not address the fact that facial expressions result in different local and global skin deformations in different persons. Moreover, existing methods learn a single albedo per user which is not enough to capture the expression-specific skin reflectance variations. We propose an end-to-end framework that jointly learns a personalized face model per user and per-frame facial motion parameters from a large corpus of in-the-wild videos of user expressions. Specifically, we learn user-specific expression blendshapes and dynamic (expression-specific) albedo maps by predicting personalized corrections on top of a 3DMM prior. We introduce novel constraints to ensure that the corrected blendshapes retain their semantic meanings and the reconstructed geometry is disentangled from the albedo. Experimental results show that our personalization accurately captures fine-grained facial dynamics in a wide range of conditions and efficiently decouples the learned face model from facial motion, resulting in more accurate face reconstruction and facial motion retargeting compared to state-of-the-art methods.
Underwhelming Generalization Improvements From Controlling Feature Attribution
Oct 01, 2019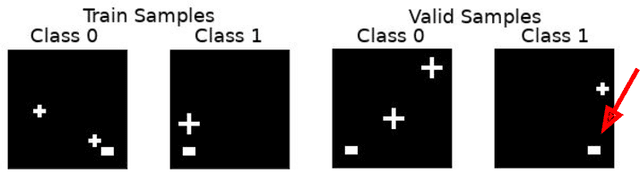
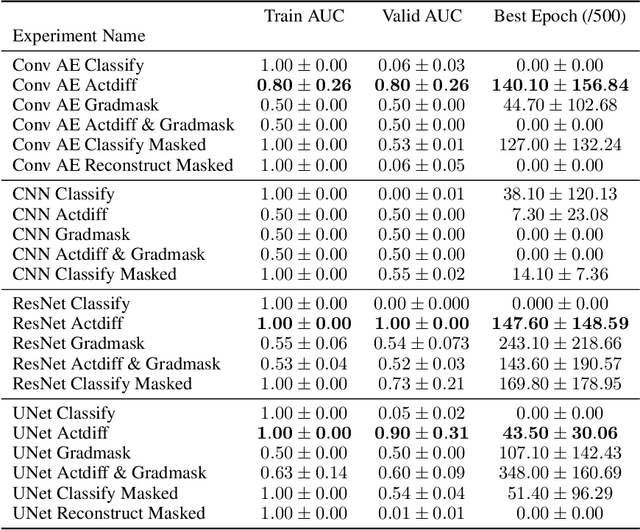
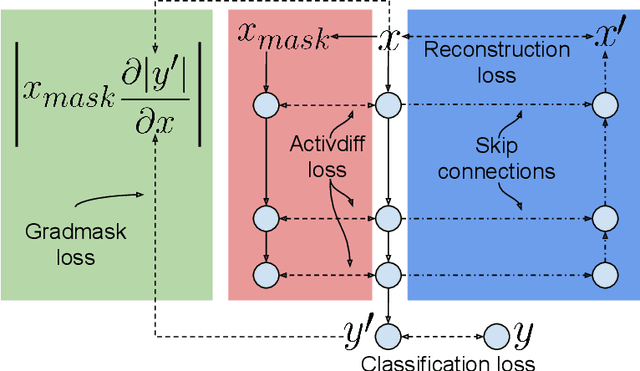
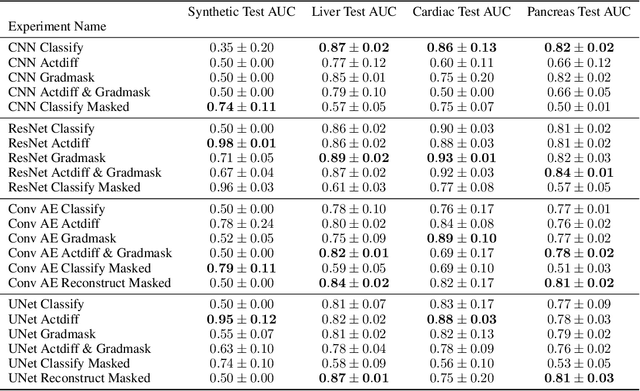
Overfitting is a common issue in machine learning, which can arise when the model learns to predict class membership using convenient but spuriously-correlated image features instead of the true image features that denote a class. These are typically visualized using saliency maps. In some object classification tasks such as for medical images, one may have some images with masks, indicating a region of interest, i.e., which part of the image contains the most relevant information for the classification. We describe a simple method for taking advantage of such auxiliary labels, by training networks to ignore the distracting features which may be extracted outside of the region of interest, on the training images for which such masks are available. This mask information is only used during training and has an impact on generalization accuracy in a dataset-dependent way. We observe an underwhelming relationship between controlling saliency maps and improving generalization performance.
Adversarial Attacks and Defense on Textual Data: A Review
May 28, 2020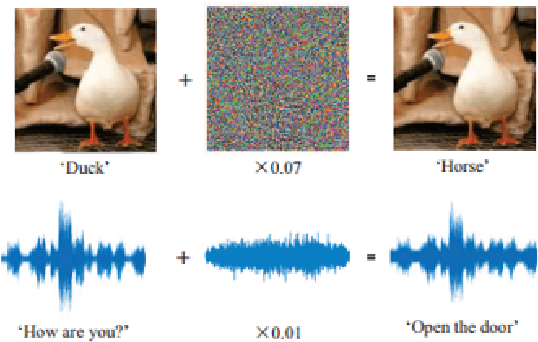
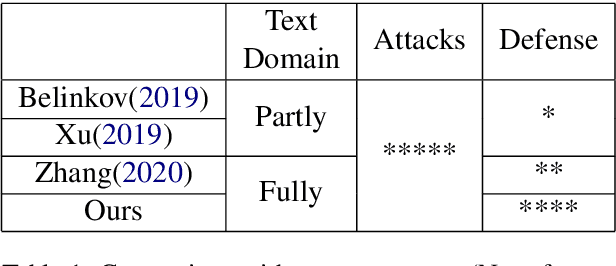
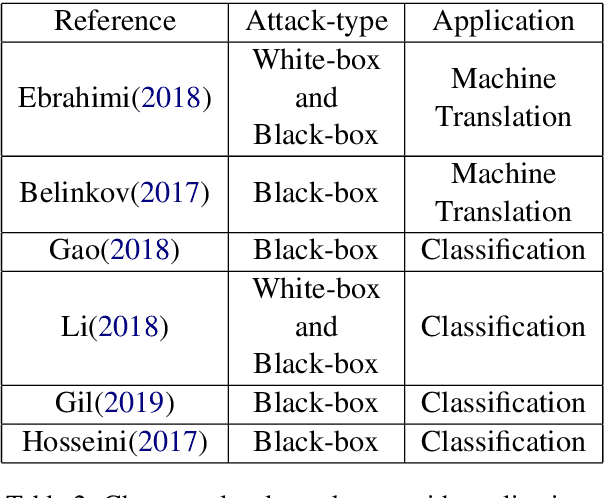
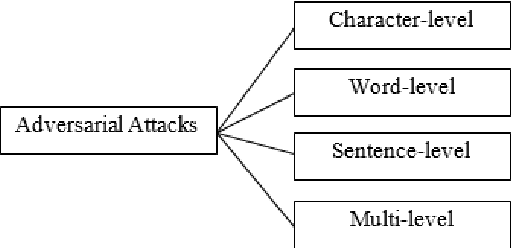
Deep leaning models have been used widely for various purposes in recent years in object recognition, self-driving cars, face recognition, speech recognition, sentiment analysis and many others. However, in recent years it has been shown that these models possess weakness to noises which forces the model to misclassify. This issue has been studied profoundly in image and audio domain. Very little has been studied on this issue with respect to textual data. Even less survey on this topic has been performed to understand different types of attacks and defense techniques. In this manuscript we accumulated and analyzed different attacking techniques, various defense models on how to overcome this issue in order to provide a more comprehensive idea. Later we point out some of the interesting findings of all papers and challenges that need to be overcome in order to move forward in this field.