 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep convolutional tensor network
May 29, 2020
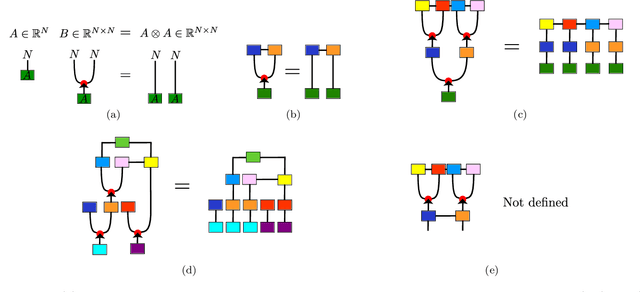

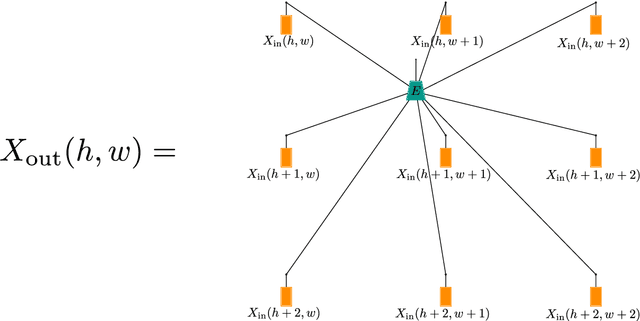
Tensor networks are linear algebraic representations of quantum many-body states based on their entanglement structure. People are exploring their applications to machine learning. Deep convolutional neural networks achieve state of the art results in computer vision and other areas. Supposedly this happens because of parameter sharing, locality, and deepness. We devise a novel tensor network based model called Deep convolutional tensor network (DCTN) for image classification, which has parameter sharing, locality, and deepness. It is based on the Entangled plaquette states (EPS) tensor network. We show how Entangled plaquette states can be implemented as a backpropagatable layer which can be used in neural networks. We test our model on FashionMNIST dataset and find that deepness increases overfitting and decreases test accuracy. Also, we find that the shallow version performs well considering its low parameter count. We discuss how hyperparameters of DCTN affect its training and overfitting.
DeepHAZMAT: Hazardous Materials Sign Detection and Segmentation with Restricted Computational Resources
Jul 18, 2020



One of the most challenging and non-trivial tasks in robot-based rescue operations is the Hazardous Materials or HAZMATs sign detection in the operation field, to prevent further unexpected disasters. Each Hazmat sign has a specific meaning that the rescue robot should detect and interpret it to take a safe action, accordingly. Accurate Hazmat detection and real-time processing are the two most important factors in such robotics applications. Furthermore, we also have to cope with some secondary challenges such as image distortion and restricted CPU and computational resources which are embedded in a rescue robot. In this paper, we propose a CNN-Based pipeline called DeepHAZMAT for detecting and segmenting Hazmats in four steps; 1) optimising the number of input images that are fed into the CNN network, 2) using the YOLOv3-tiny structure to collect the required visual information from the hazardous areas, 3) Hazmat sign segmentation and separation from the background using GrabCut technique, and 4) post-processing the result with morphological operators and convex hull algorithm. In spite of the utilisation of a very limited memory and CPU resources, the experimental results show the proposed method has successfully maintained a better performance in terms of detection-speed and detection-accuracy, compared with the state-of-the-art methods.
Weakly Supervised Lesion Localization With Probabilistic-CAM Pooling
May 29, 2020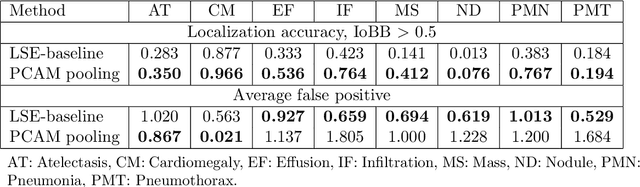
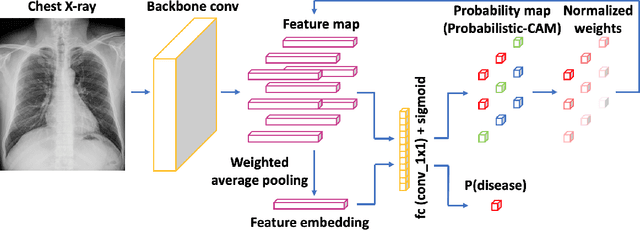
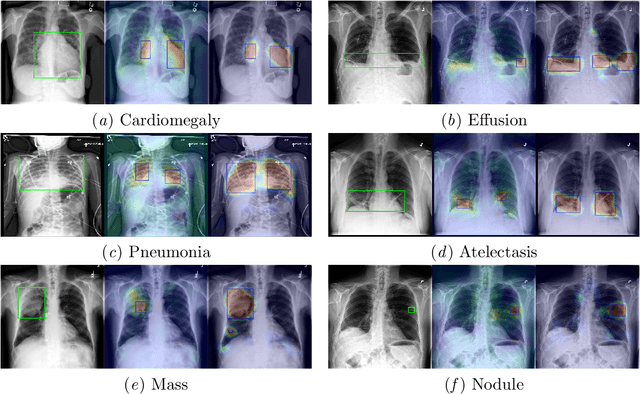
Localizing thoracic diseases on chest X-ray plays a critical role in clinical practices such as diagnosis and treatment planning. However, current deep learning based approaches often require strong supervision, e.g. annotated bounding boxes, for training such systems, which is infeasible to harvest in large-scale. We present Probabilistic Class Activation Map (PCAM) pooling, a novel global pooling operation for lesion localization with only image-level supervision. PCAM pooling explicitly leverages the excellent localization ability of CAM during training in a probabilistic fashion. Experiments on the ChestX-ray14 dataset show a ResNet-34 model trained with PCAM pooling outperforms state-of-the-art baselines on both the classification task and the localization task. Visual examination on the probability maps generated by PCAM pooling shows clear and sharp boundaries around lesion regions compared to the localization heatmaps generated by CAM. PCAM pooling is open sourced at https://github.com/jfhealthcare/Chexpert.
Adaptive Learning Rates with Maximum Variation Averaging
Jun 21, 2020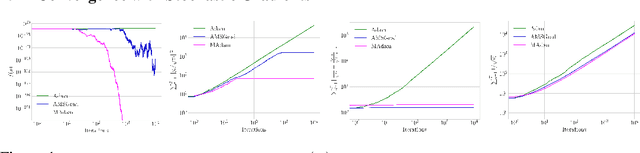

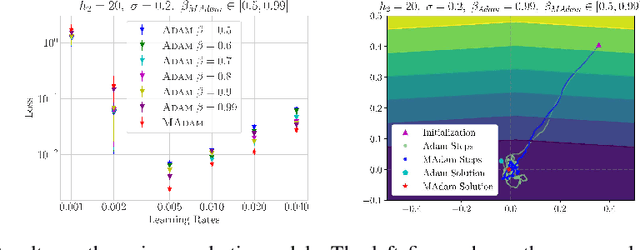

Adaptive gradient methods such as RMSProp and Adam use exponential moving estimate of the squared gradient to compute element-wise adaptive step sizes and handle noisy gradients. However, Adam can have undesirable convergence behavior in some problems due to unstable or extreme adaptive learning rates. Methods such as AMSGrad and AdaBound have been proposed to stabilize the adaptive learning rates of Adam in the later stage of training, but they do not outperform Adam in some practical tasks such as training Transformers. In this paper, we propose an adaptive learning rate rule in which the running mean squared gradient is replaced by a weighted mean, with weights chosen to maximize the estimated variance of each coordinate. This gives a worst-case estimate for the local gradient variance, taking smaller steps when large curvatures or noisy gradients are present, resulting in more desirable convergence behavior than Adam. We analyze and demonstrate the improved efficacy of our adaptive averaging approach on image classification, neural machine translation and natural language understanding tasks.
Contextual-Relation Consistent Domain Adaptation for Semantic Segmentation
Jul 05, 2020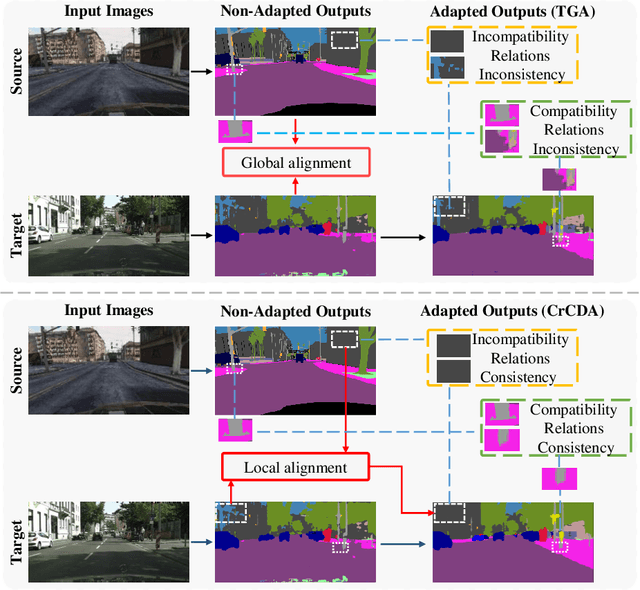
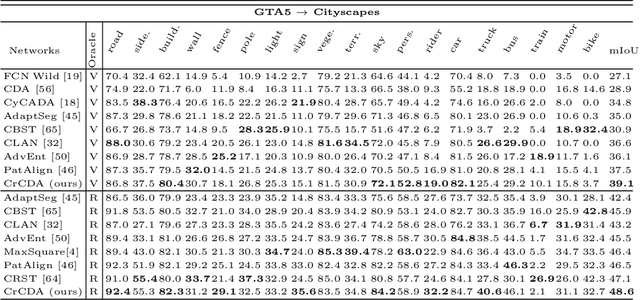
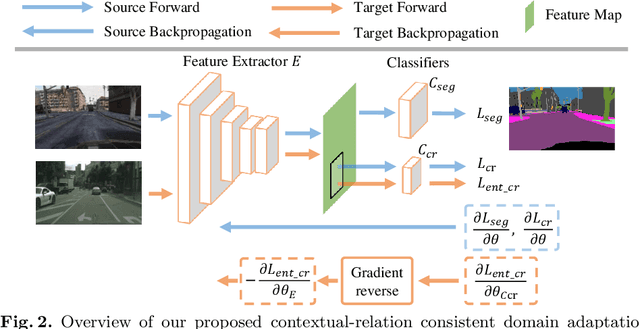
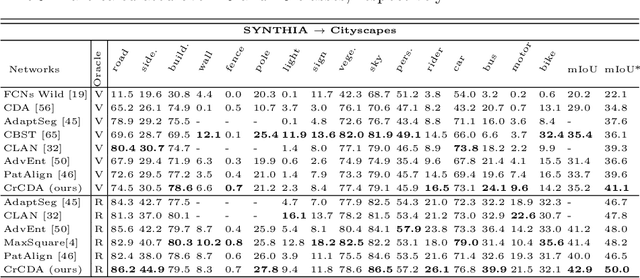
Recent advances in unsupervised domain adaptation for semantic segmentation have shown great potentials to relieve the demand of expensive per-pixel annotations. However, most existing works address the domain discrepancy by aligning the data distributions of two domains at a global image level whereas the local consistencies are largely neglected. This paper presents an innovative local contextual-relation consistent domain adaptation (CrCDA) technique that aims to achieve local-level consistencies during the global-level alignment. The idea is to take a closer look at region-wise feature representations and align them for local-level consistencies. Specifically, CrCDA learns and enforces the prototypical local contextual-relations explicitly in the feature space of a labelled source domain while transferring them to an unlabelled target domain via backpropagation-based adversarial learning. An adaptive entropy max-min adversarial learning scheme is designed to optimally align these hundreds of local contextual-relations across domain without requiring discriminator or extra computation overhead. The proposed CrCDA has been evaluated extensively over two challenging domain adaptive segmentation tasks (e.g., GTA5 to Cityscapes and SYNTHIA to Cityscapes), and experiments demonstrate its superior segmentation performance as compared with state-of-the-art methods.
Image Classification at Supercomputer Scale
Dec 02, 2018
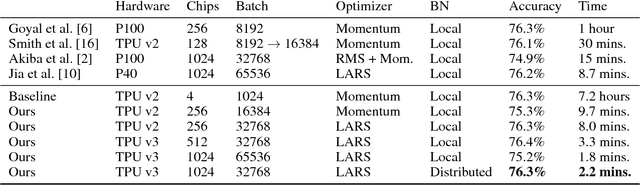

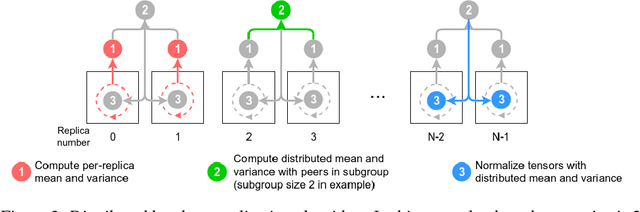
Deep learning is extremely computationally intensive, and hardware vendors have responded by building faster accelerators in large clusters. Training deep learning models at petaFLOPS scale requires overcoming both algorithmic and systems software challenges. In this paper, we discuss three systems-related optimizations: (1) distributed batch normalization to control per-replica batch sizes, (2) input pipeline optimizations to sustain model throughput, and (3) 2-D torus all-reduce to speed up gradient summation. We combine these optimizations to train ResNet-50 on ImageNet to 76.3% accuracy in 2.2 minutes on a 1024-chip TPU v3 Pod with a training throughput of over 1.05 million images/second and no accuracy drop.
PermuteAttack: Counterfactual Explanation of Machine Learning Credit Scorecards
Aug 28, 2020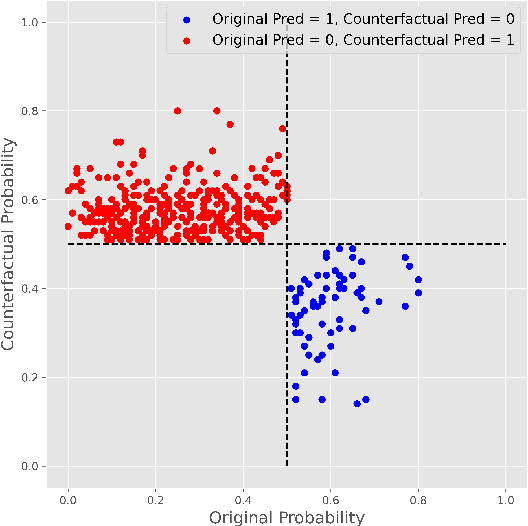
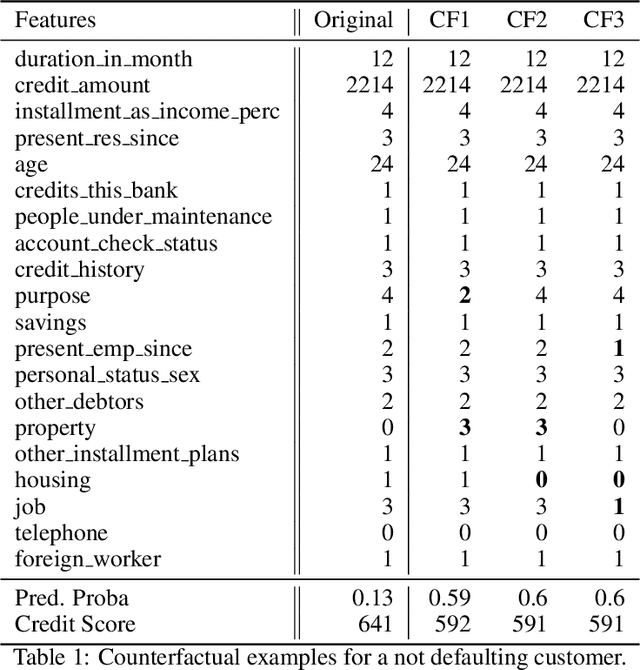
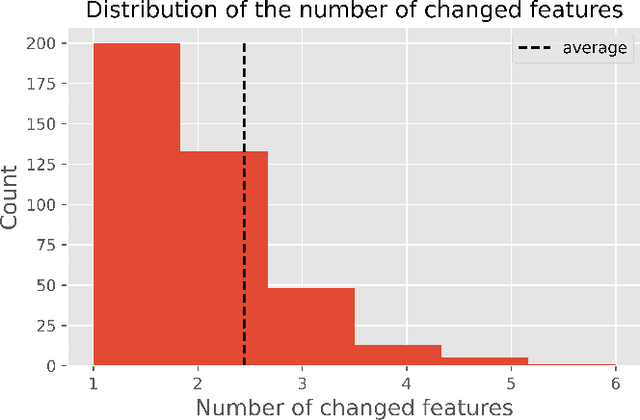
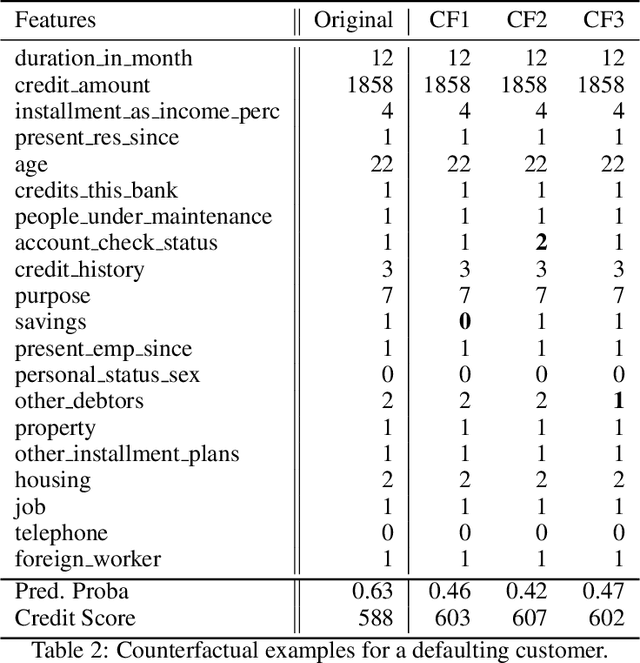
This paper is a note on new directions and methodologies for validation and explanation of Machine Learning (ML) models employed for retail credit scoring in finance. Our proposed framework draws motivation from the field of Artificial Intelligence (AI) security and adversarial ML where the need for certifying the performance of the ML algorithms in the face of their overwhelming complexity poses a need for rethinking the traditional notions of model architecture selection, sensitivity analysis and stress testing. Our point of view is that the phenomenon of adversarial perturbations when detached from the AI security domain, has purely algorithmic roots and fall within the scope of model risk assessment. We propose a model criticism and explanation framework based on adversarially generated counterfactual examples for tabular data. A counterfactual example to a given instance in this context is defined as a synthetically generated data point sampled from the estimated data distribution which is treated differently by a model. The counterfactual examples can be used to provide a black-box instance-level explanation of the model behaviour as well as studying the regions in the input space where the model performance deteriorates. Adversarial example generating algorithms are extensively studied in the image and natural language processing (NLP) domains. However, most financial data come in tabular format and naive application of the existing techniques on this class of datasets generates unrealistic samples. In this paper, we propose a counterfactual example generation method capable of handling tabular data including discrete and categorical variables. Our proposed algorithm uses a gradient-free optimization based on genetic algorithms and therefore is applicable to any classification model.
Detecting Anomalous Inputs to DNN Classifiers By Joint Statistical Testing at the Layers
Jul 29, 2020
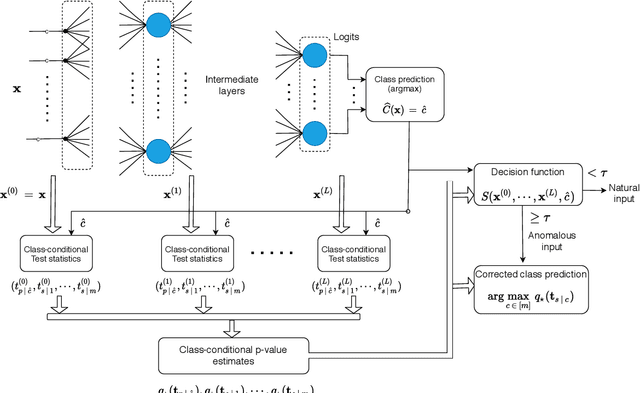
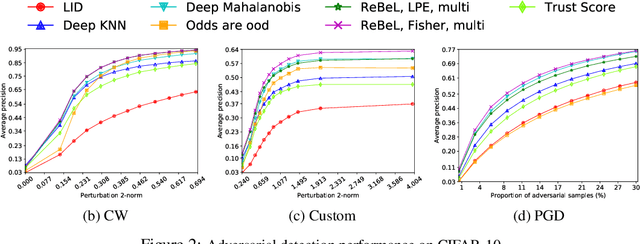
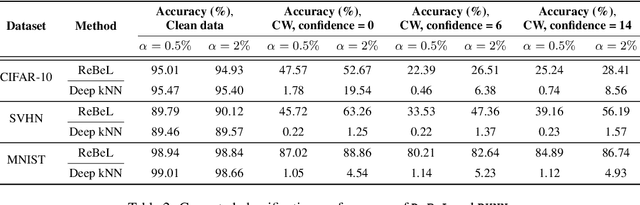
Detecting anomalous inputs, such as adversarial and out-of-distribution (OOD) inputs, is critical for classifiers deployed in real-world applications, especially deep neural network (DNN) classifiers that are known to be brittle on such inputs. We propose an unsupervised statistical testing framework for detecting such anomalous inputs to a trained DNN classifier based on its internal layer representations. By calculating test statistics at the input and intermediate-layer representations of the DNN, conditioned individually on the predicted class and on the true class of labeled training data, the method characterizes their class-conditional distributions on natural inputs. Given a test input, its extent of non-conformity with respect to the training distribution is captured using p-values of the class-conditional test statistics across the layers, which are then combined using a scoring function designed to score high on anomalous inputs. We focus on adversarial inputs, which are an important class of anomalous inputs, and also demonstrate the effectiveness of our method on general OOD inputs. The proposed framework also provides an alternative class prediction that can be used to correct the DNNs prediction on (detected) adversarial inputs. Experiments on well-known image classification datasets with strong adversarial attacks, including a custom attack method that uses the internal layer representations of the DNN, demonstrate that our method outperforms or performs comparably with five state-of-the-art detection methods.
Synthetic patches, real images: screening for centrosome aberrations in EM images of human cancer cells
Aug 27, 2019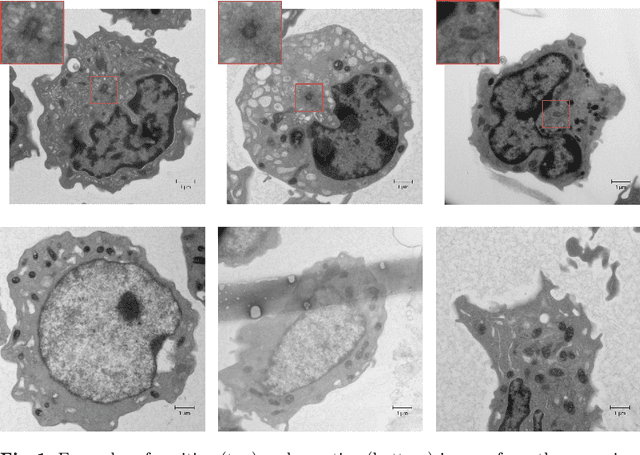


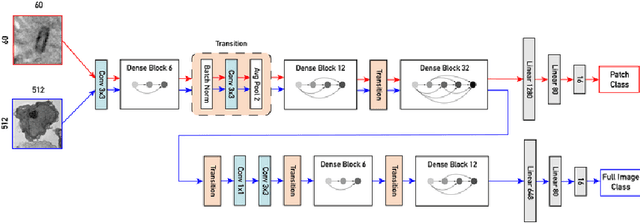
Recent advances in high-throughput electron microscopy imaging enable detailed study of centrosome aberrations in cancer cells. While the image acquisition in such pipelines is automated, manual detection of centrioles is still necessary to select cells for re-imaging at higher magnification. In this contribution we propose an algorithm which performs this step automatically and with high accuracy. From the image labels produced by human experts and a 3D model of a centriole we construct an additional training set with patch-level labels. A two-level DenseNet is trained on the hybrid training data with synthetic patches and real images, achieving much better results on real patient data than training only at the image-level. The code can be found at https://github.com/kreshuklab/centriole_detection.
RSVQA: Visual Question Answering for Remote Sensing Data
Mar 16, 2020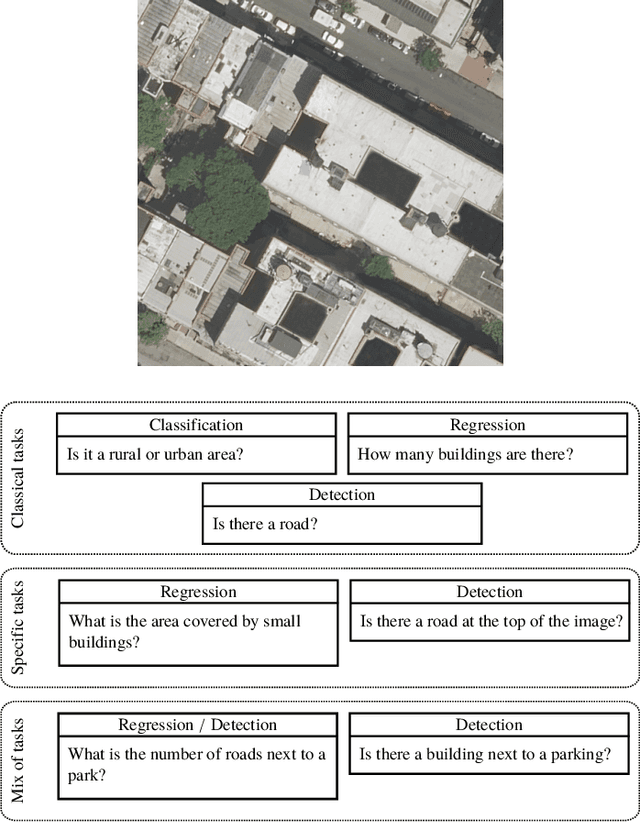
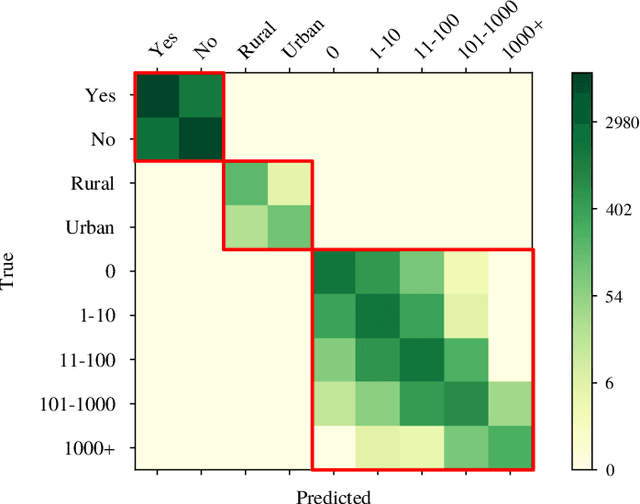
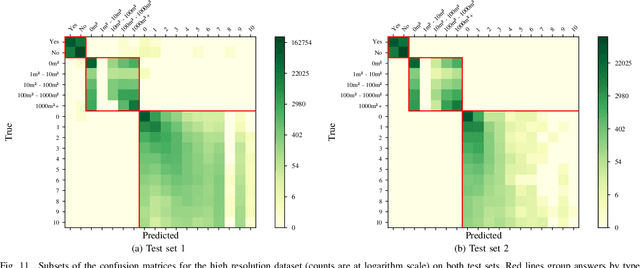
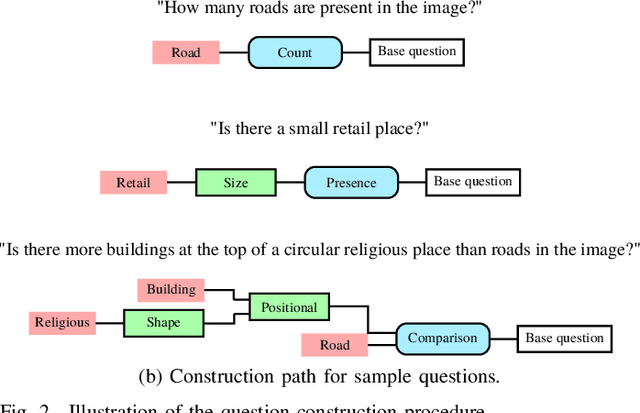
This paper introduces the task of visual question answering for remote sensing data (RSVQA). Remote sensing images contain a wealth of information which can be useful for a wide range of tasks including land cover classification, object counting or detection. However, most of the available methodologies are task-specific, thus inhibiting generic and easy access to the information contained in remote sensing data. As a consequence, accurate remote sensing product generation still requires expert knowledge. With RSVQA, we propose a system to extract information from remote sensing data that is accessible to every user: we use questions formulated in natural language and use them to interact with the images. With the system, images can be queried to obtain high level information specific to the image content or relational dependencies between objects visible in the images. Using an automatic method introduced in this article, we built two datasets (using low and high resolution data) of image/question/answer triplets. The information required to build the questions and answers is queried from OpenStreetMap (OSM). The datasets can be used to train (when using supervised methods) and evaluate models to solve the RSVQA task. We report the results obtained by applying a model based on Convolutional Neural Networks (CNNs) for the visual part and on a Recurrent Neural Network (RNN) for the natural language part to this task. The model is trained on the two datasets, yielding promising results in both cases.