 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning a Domain Classifier Bank for Unsupervised Adaptive Object Detection
Jul 06, 2020
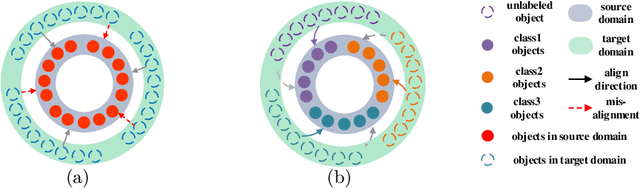
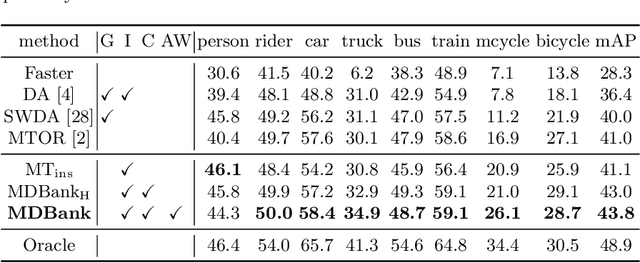
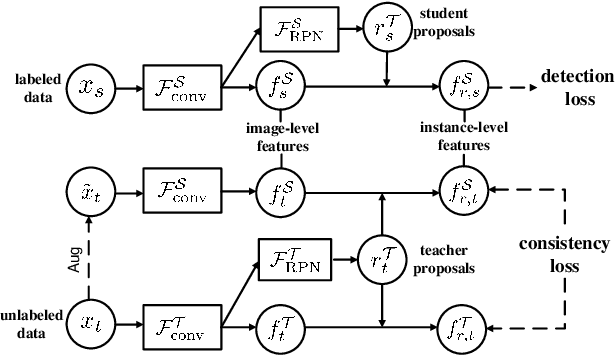
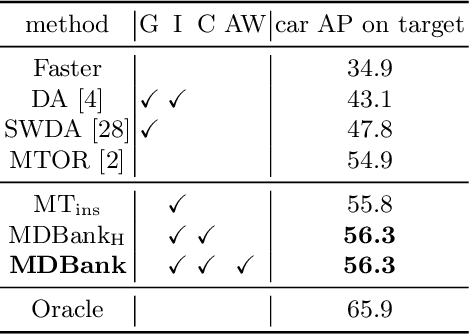
In real applications, object detectors based on deep networks still face challenges of the large domain gap between the labeled training data and unlabeled testing data. To reduce the gap, recent techniques are proposed by aligning the image/instance-level features between source and unlabeled target domains. However, these methods suffer from the suboptimal problem mainly because of ignoring the category information of object instances. To tackle this issue, we develop a fine-grained domain alignment approach with a well-designed domain classifier bank that achieves the instance-level alignment respecting to their categories. Specifically, we first employ the mean teacher paradigm to generate pseudo labels for unlabeled samples. Then we implement the class-level domain classifiers and group them together, called domain classifier bank, in which each domain classifier is responsible for aligning features of a specific class. We assemble the bare object detector with the proposed fine-grained domain alignment mechanism as the adaptive detector, and optimize it with a developed crossed adaptive weighting mechanism. Extensive experiments on three popular transferring benchmarks demonstrate the effectiveness of our method and achieve the new remarkable state-of-the-arts.
Overview of Scanner Invariant Representations
May 29, 2020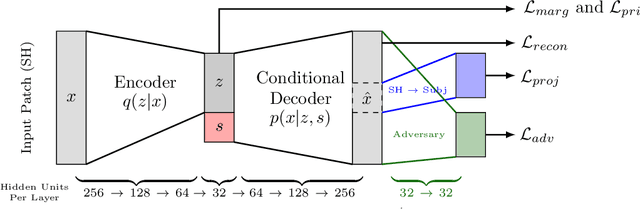
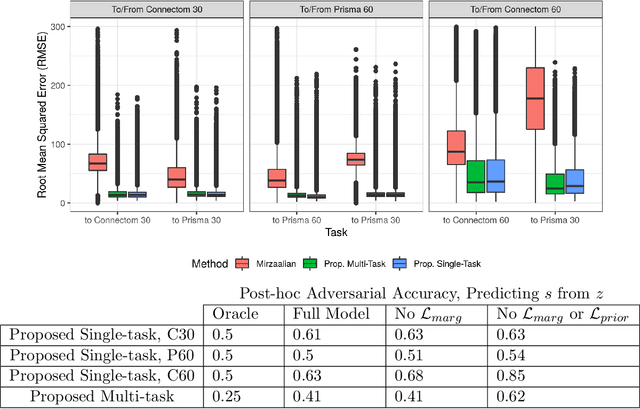
Pooled imaging data from multiple sources is subject to bias from each source. Studies that do not correct for these scanner/site biases at best lose statistical power, and at worst leave spurious correlations in their data. Estimation of the bias effects is non-trivial due to the paucity of data with correspondence across sites, so called "traveling phantom" data, which is expensive to collect. Nevertheless, numerous solutions leveraging direct correspondence have been proposed. In contrast to this, Moyer et al. (2019) proposes an unsupervised solution using invariant representations, one which does not require correspondence and thus does not require paired images. By leveraging the data processing inequality, an invariant representation can then be used to create an image reconstruction that is uninformative of its original source, yet still faithful to the underlying structure. In the present abstract we provide an overview of this method.
From Kinematics To Dynamics: Estimating Center of Pressure and Base of Support from Video Frames of Human Motion
Jan 02, 2020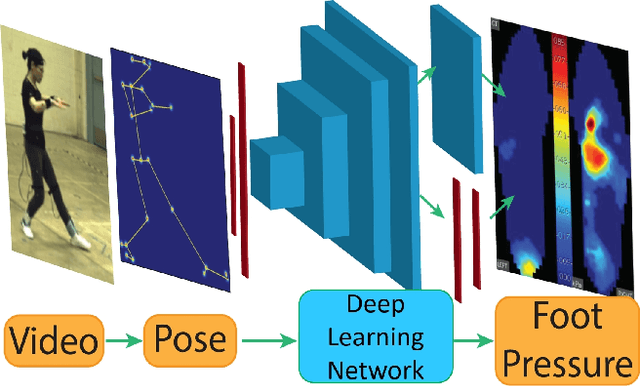
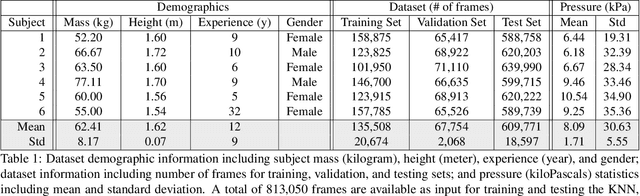
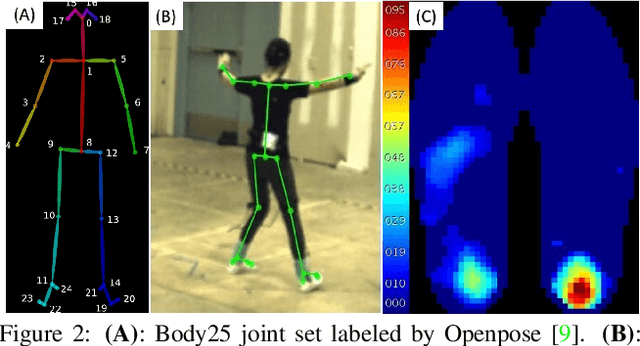
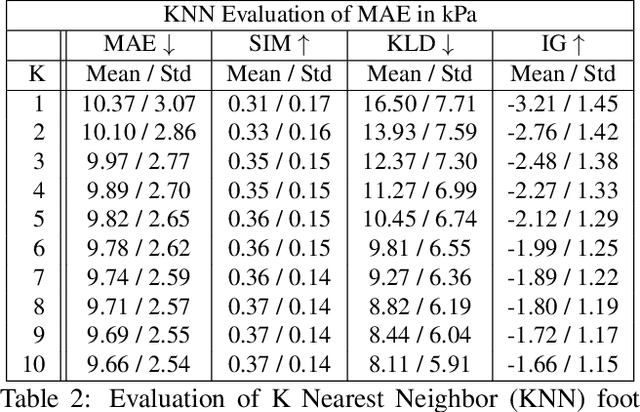
To gain an understanding of the relation between a given human pose image and the corresponding physical foot pressure of the human subject, we propose and validate two end-to-end deep learning architectures, PressNet and PressNet-Simple, to regress foot pressure heatmaps (dynamics) from 2D human pose (kinematics) derived from a video frame. A unique video and foot pressure data set of 813,050 synchronized pairs, composed of 5-minute long choreographed Taiji movement sequences of 6 subjects, is collected and used for leaving-one-subject-out cross validation. Our initial experimental results demonstrate reliable and repeatable foot pressure prediction from a single image, setting the first baseline for such a complex cross modality mapping problem in computer vision. Furthermore, we compute and quantitatively validate the Center of Pressure (CoP) and Base of Support (BoS) from predicted foot pressure distribution, obtaining key components in pose stability analysis from images with potential applications in kinesiology, medicine, sports and robotics.
Object Tracking through Residual and Dense LSTMs
Jun 22, 2020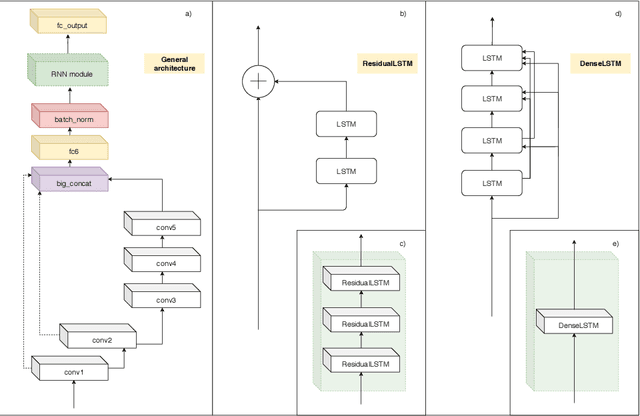

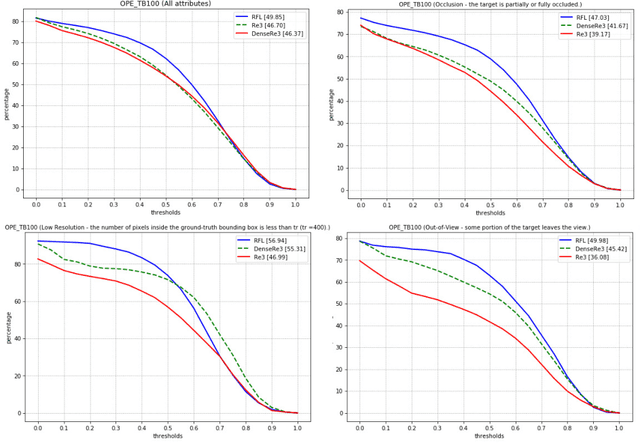
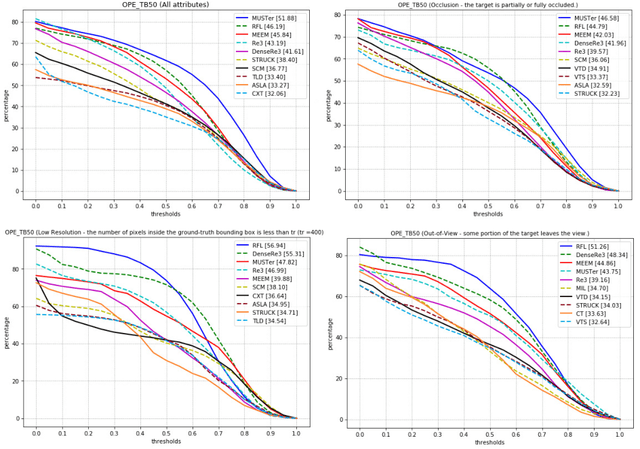
Visual object tracking task is constantly gaining importance in several fields of application as traffic monitoring, robotics, and surveillance, to name a few. Dealing with changes in the appearance of the tracked object is paramount to achieve high tracking accuracy, and is usually achieved by continually learning features. Recently, deep learning-based trackers based on LSTMs (Long Short-Term Memory) recurrent neural networks have emerged as a powerful alternative, bypassing the need to retrain the feature extraction in an online fashion. Inspired by the success of residual and dense networks in image recognition, we propose here to enhance the capabilities of hybrid trackers using residual and/or dense LSTMs. By introducing skip connections, it is possible to increase the depth of the architecture while ensuring a fast convergence. Experimental results on the Re3 tracker show that DenseLSTMs outperform Residual and regular LSTM, and offer a higher resilience to nuisances such as occlusions and out-of-view objects. Our case study supports the adoption of residual-based RNNs for enhancing the robustness of other trackers.
Improving Sample Efficiency in Model-Free Reinforcement Learning from Images
Oct 02, 2019
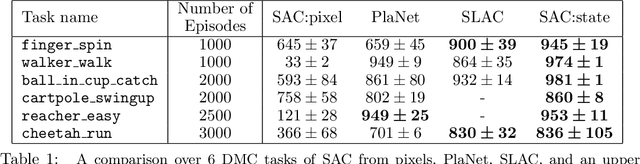
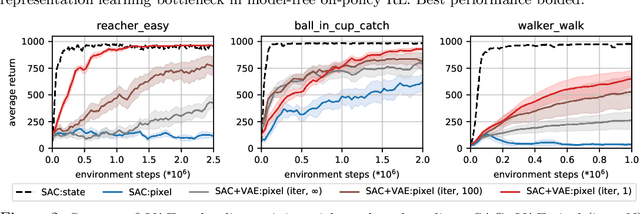
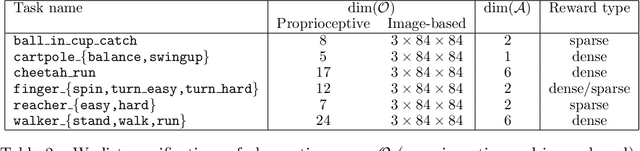
Training an agent to solve control tasks directly from high-dimensional images with model-free reinforcement learning (RL) has proven difficult. The agent needs to learn a latent representation together with a control policy to perform the task. Fitting a high-capacity encoder using a scarce reward signal is not only sample inefficient, but also prone to suboptimal convergence. Two ways to improve sample efficiency are to extract relevant features for the task and use off-policy algorithms. We dissect various approaches of learning good latent features, and conclude that the image reconstruction loss is the essential ingredient that enables efficient and stable representation learning in image-based RL. Following these findings, we devise an off-policy actor-critic algorithm with an auxiliary decoder that trains end-to-end and matches state-of-the-art performance across both model-free and model-based algorithms on many challenging control tasks. We release our code to encourage future research on image-based RL.
Image Classification at Supercomputer Scale
Dec 02, 2018
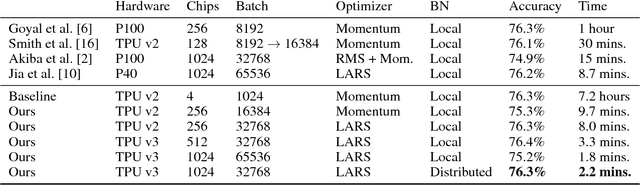

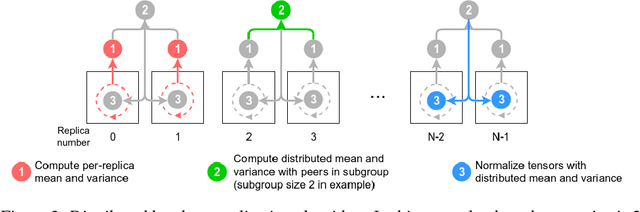
Deep learning is extremely computationally intensive, and hardware vendors have responded by building faster accelerators in large clusters. Training deep learning models at petaFLOPS scale requires overcoming both algorithmic and systems software challenges. In this paper, we discuss three systems-related optimizations: (1) distributed batch normalization to control per-replica batch sizes, (2) input pipeline optimizations to sustain model throughput, and (3) 2-D torus all-reduce to speed up gradient summation. We combine these optimizations to train ResNet-50 on ImageNet to 76.3% accuracy in 2.2 minutes on a 1024-chip TPU v3 Pod with a training throughput of over 1.05 million images/second and no accuracy drop.
Self-Knowledge Distillation: A Simple Way for Better Generalization
Jun 22, 2020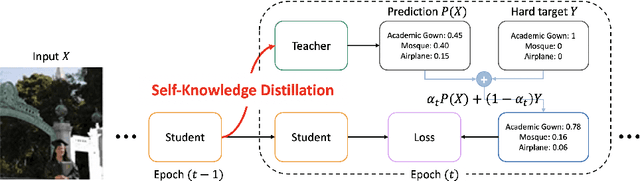
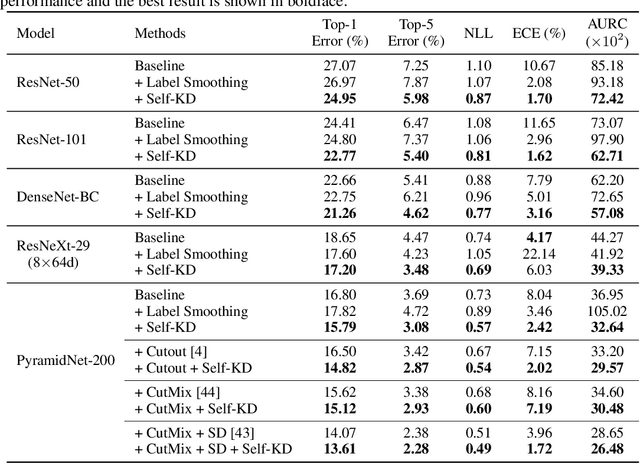
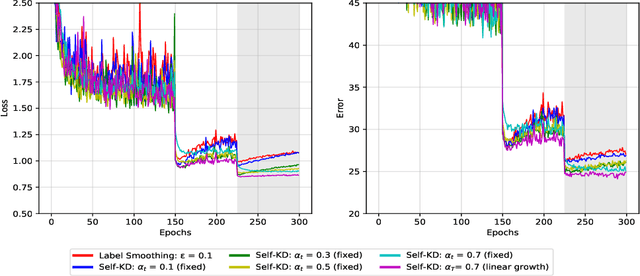
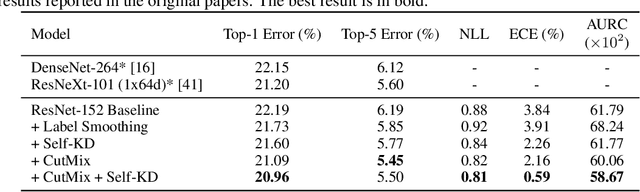
The generalization capability of deep neural networks has been substantially improved by applying a wide spectrum of regularization methods, e.g., restricting function space, injecting randomness during training, augmenting data, etc. In this work, we propose a simple yet effective regularization method named self-knowledge distillation (Self-KD), which progressively distills a model's own knowledge to soften hard targets (i.e., one-hot vectors) during training. Hence, it can be interpreted within a framework of knowledge distillation as a student becomes a teacher itself. The proposed method is applicable to any supervised learning tasks with hard targets and can be easily combined with existing regularization methods to further enhance the generalization performance. Furthermore, we show that Self-KD achieves not only better accuracy, but also provides high quality of confidence estimates. Extensive experimental results on three different tasks, image classification, object detection, and machine translation, demonstrate that our method consistently improves the performance of the state-of-the-art baselines, and especially, it achieves state-of-the-art BLEU score of 30.0 and 36.2 on IWSLT15 English-to-German and German-to-English tasks, respectively.
Turbulence Enrichment using Generative Adversarial Networks
Mar 04, 2020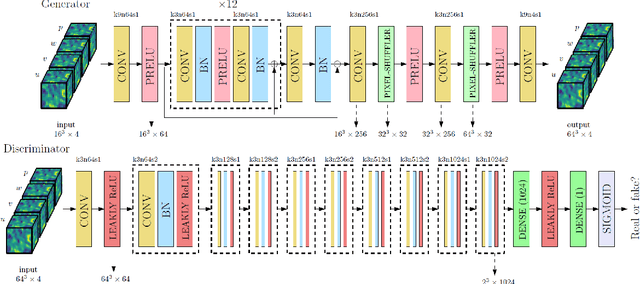
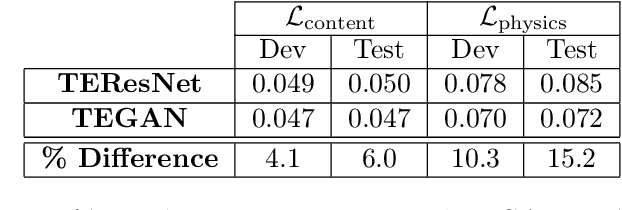
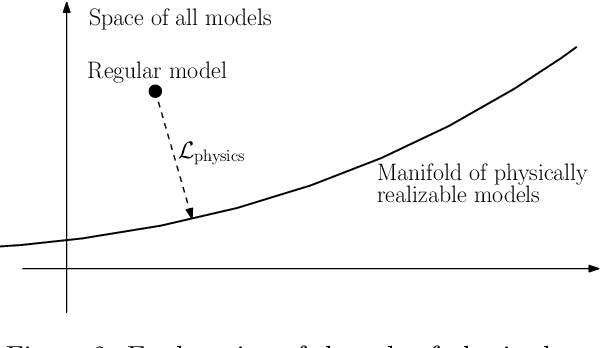
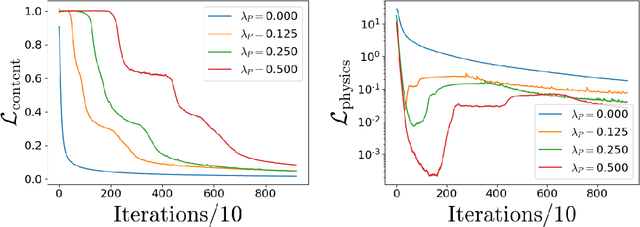
Generative Adversarial Networks (GANs) have been widely used for generating photo-realistic images. A variant of GANs called super-resolution GAN (SRGAN) has already been used successfully for image super-resolution where low resolution images can be upsampled to a $4\times$ larger image that is perceptually more realistic. However, when such generative models are used for data describing physical processes, there are additional known constraints that models must satisfy including governing equations and boundary conditions. In general, these constraints may not be obeyed by the generated data. In this work, we develop physics-based methods for generative enrichment of turbulence. We incorporate a physics-informed learning approach by a modification to the loss function to minimize the residuals of the governing equations for the generated data. We have analyzed two trained physics-informed models: a supervised model based on convolutional neural networks (CNN) and a generative model based on SRGAN: Turbulence Enrichment GAN (TEGAN), and show that they both outperform simple bicubic interpolation in turbulence enrichment. We have also shown that using the physics-informed learning can also significantly improve the model's ability in generating data that satisfies the physical governing equations. Finally, we compare the enriched data from TEGAN to show that it is able to recover statistical metrics of the flow field including energy metrics and well as inter-scale energy dynamics and flow morphology.
On segmentation of pectoralis muscle in digital mammograms by means of deep learning
Aug 29, 2020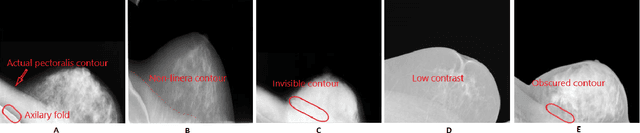
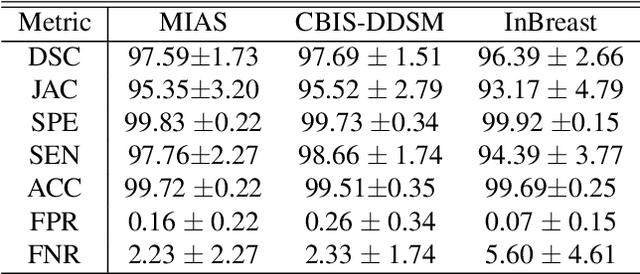
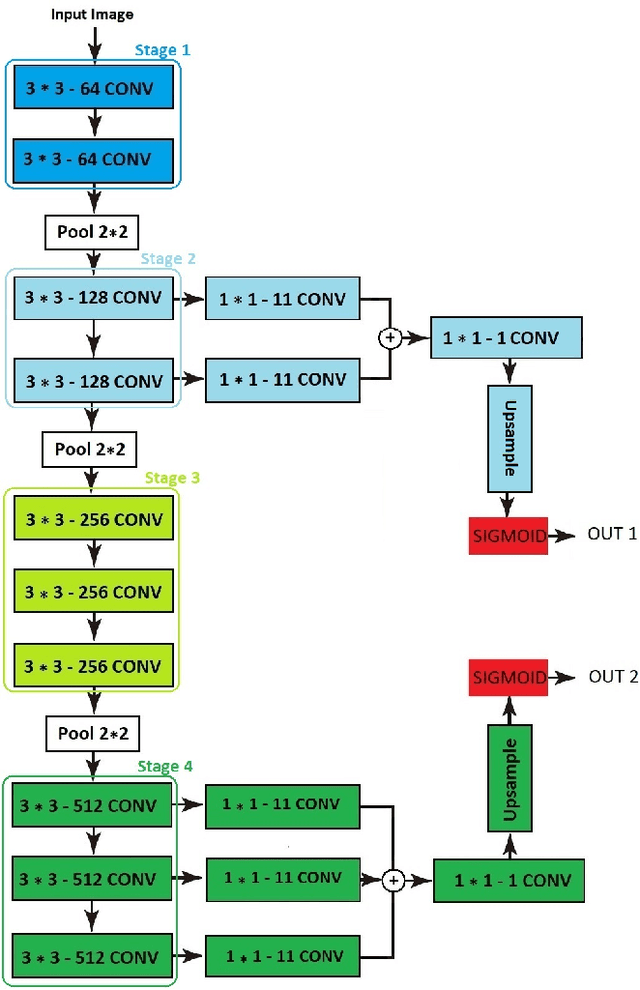
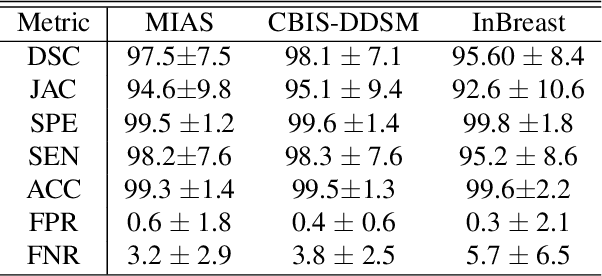
Computer-aided diagnosis (CAD) has long become an integral part of radiological management of breast disease, facilitating a number of important clinical applications, including quantitative assessment of breast density and early detection of malignancies based on X-ray mammography. Common to such applications is the need to automatically discriminate between breast tissue and adjacent anatomy, with the latter being predominantly represented by pectoralis major (or pectoral muscle). Especially in the case of mammograms acquired in the mediolateral oblique (MLO) view, the muscle is easily confusable with some elements of breast anatomy due to their morphological and photometric similarity. As a result, the problem of automatic detection and segmentation of pectoral muscle in MLO mammograms remains a challenging task, innovative approaches to which are still required and constantly searched for. To address this problem, the present paper introduces a two-step segmentation strategy based on a combined use of data-driven prediction (deep learning) and graph-based image processing. In particular, the proposed method employs a convolutional neural network (CNN) which is designed to predict the location of breast-pectoral boundary at different levels of spatial resolution. Subsequently, the predictions are used by the second stage of the algorithm, in which the desired boundary is recovered as a solution to the shortest path problem on a specially designed graph. The proposed algorithm has been tested on three different datasets (i.e., MIAS, CBIS-DDSm and InBreast) using a range of quantitative metrics. The results of comparative analysis show considerable improvement over state-of-the-art, while offering the possibility of model-free and fully automatic processing.
WHENet: Real-time Fine-Grained Estimation for Wide Range Head Pose
May 20, 2020
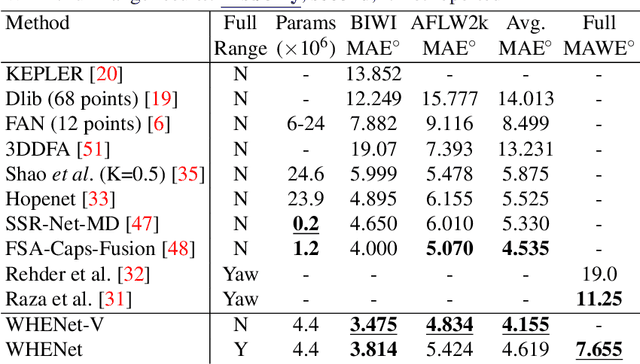
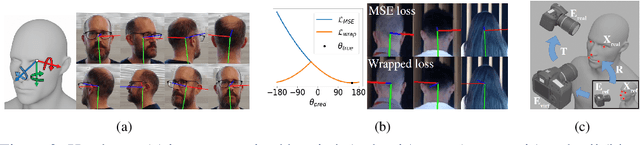
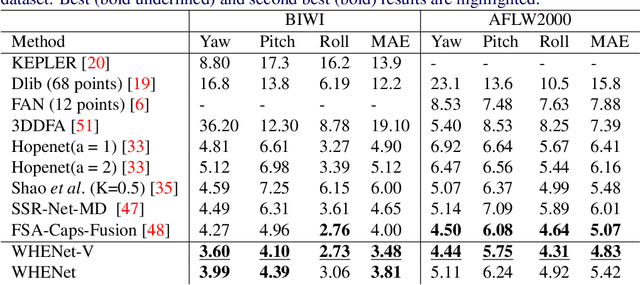
We present an end-to-end head-pose estimation network designed to predict Euler angles through the full range head yaws from a single RGB image. Existing methods perform well for frontal views but few target head pose from all viewpoints. This has applications in autonomous driving and retail. Our network builds on multi-loss approaches with changes to loss functions and training strategies adapted to wide range estimation. Additionally, we extract ground truth labelings of anterior views from a current panoptic dataset for the first time. The resulting Wide Headpose Estimation Network (WHENet) is the first fine-grained modern method applicable to the full-range of head yaws (hence wide) yet also meets or beats state-of-the-art methods for frontal head pose estimation. Our network is compact and efficient for mobile devices and applications.