 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Holistic Approach for Modeling and Synthesis of Image Processing Applications for Heterogeneous Computing Architectures
Feb 26, 2015
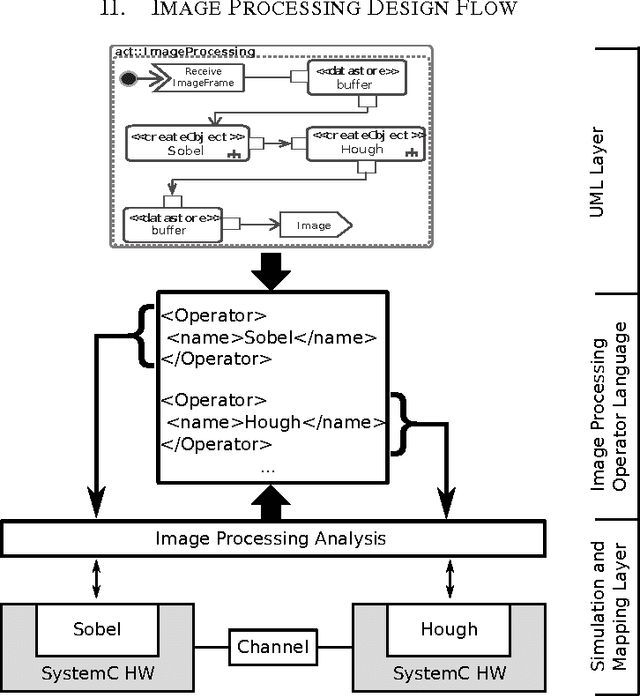
Image processing applications are common in every field of our daily life. However, most of them are very complex and contain several tasks with different complexities which result in varying requirements for computing architectures. Nevertheless, a general processing scheme in every image processing application has a similar structure, called image processing pipeline: (1) capturing an image, (2) pre-processing using local operators, (3) processing with global operators and (4) post-processing using complex operations. Therefore, application-specialized hardware solutions based on heterogeneous architectures are used for image processing. Unfortunately the development of applications for heterogeneous hardware architectures is challenging due to the distribution of computational tasks among processors and programmable logic units. Nowadays, image processing systems are started from scratch which is time-consuming, error-prone and inflexible. A new methodology for modeling and implementing is needed in order to reduce the development time of heterogenous image processing systems. This paper introduces a new holistic top down approach for image processing systems. Two challenges have to be investigated. First, designers ought to be able to model their complete image processing pipeline on an abstract layer using UML. Second, we want to close the gap between the abstract system and the system architecture.
Active Contour Models for Manifold Valued Image Segmentation
Nov 11, 2013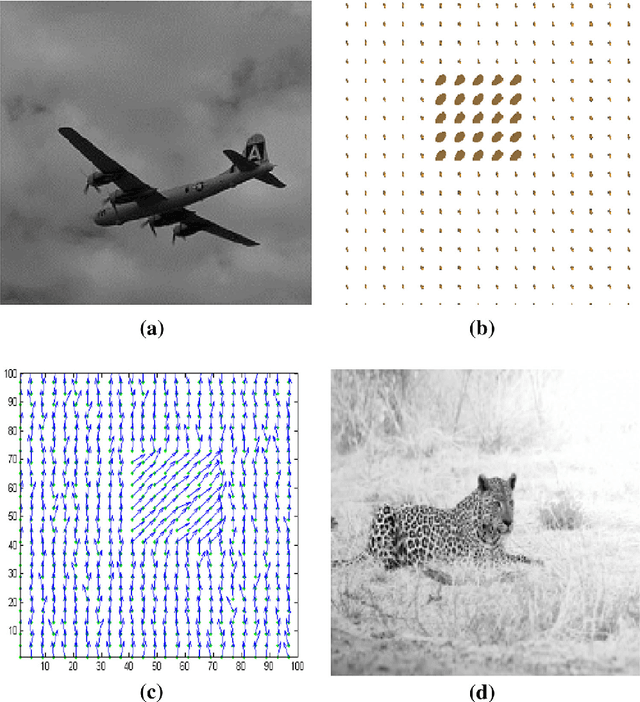
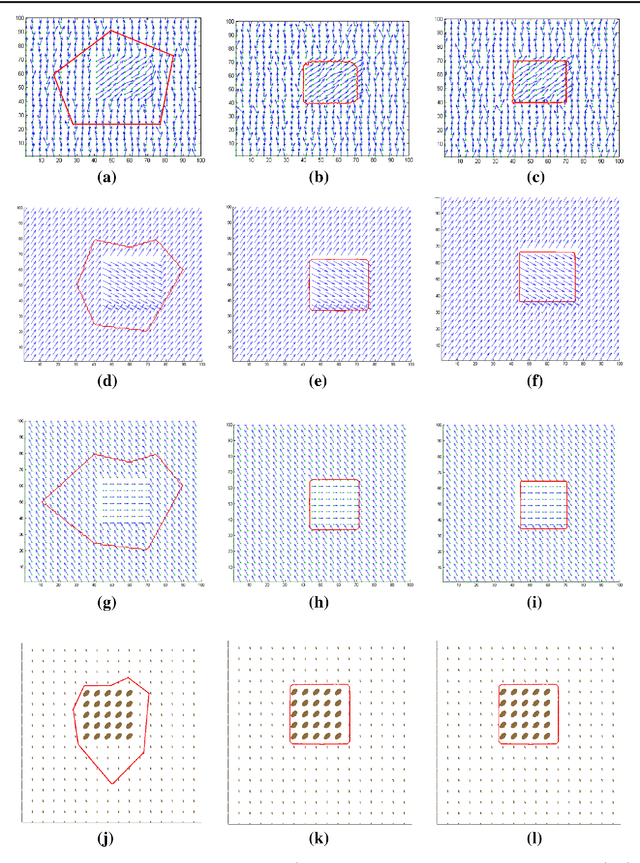
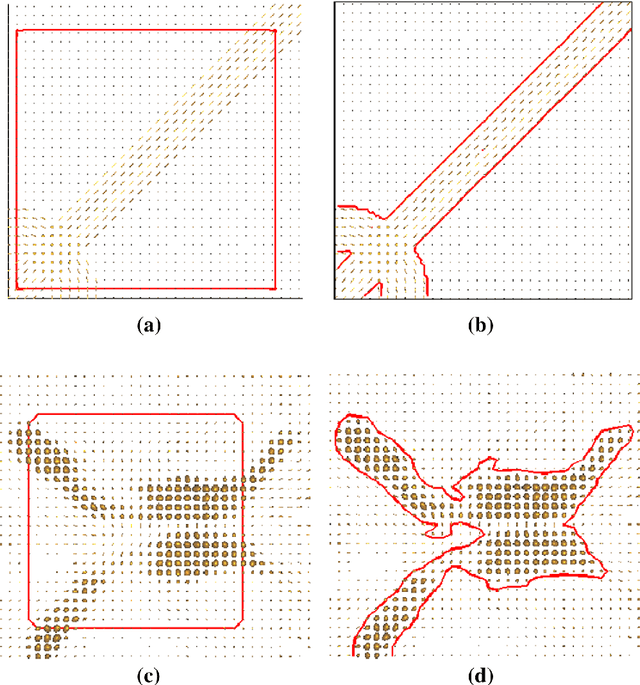
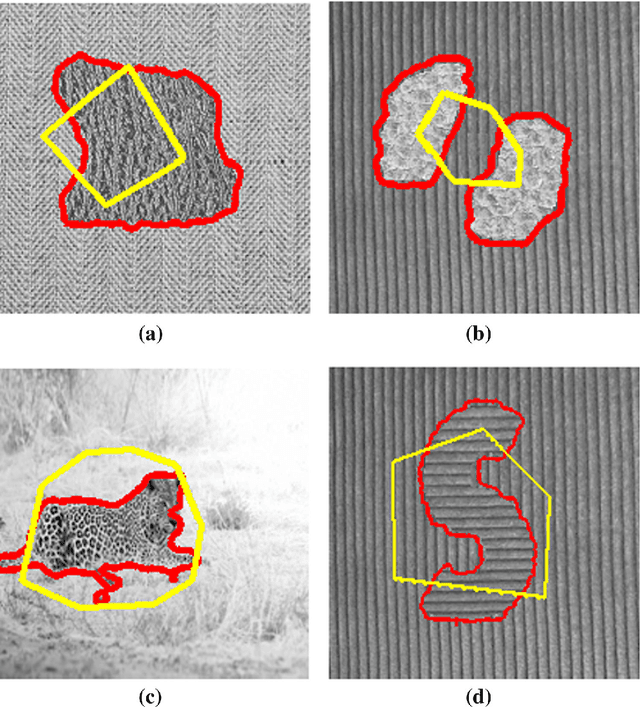
Image segmentation is the process of partitioning a image into different regions or groups based on some characteristics like color, texture, motion or shape etc. Active contours is a popular variational method for object segmentation in images, in which the user initializes a contour which evolves in order to optimize an objective function designed such that the desired object boundary is the optimal solution. Recently, imaging modalities that produce Manifold valued images have come up, for example, DT-MRI images, vector fields. The traditional active contour model does not work on such images. In this paper, we generalize the active contour model to work on Manifold valued images. As expected, our algorithm detects regions with similar Manifold values in the image. Our algorithm also produces expected results on usual gray-scale images, since these are nothing but trivial examples of Manifold valued images. As another application of our general active contour model, we perform texture segmentation on gray-scale images by first creating an appropriate Manifold valued image. We demonstrate segmentation results for manifold valued images and texture images.
Knowing Depth Quality In Advance: A Depth Quality Assessment Method For RGB-D Salient Object Detection
Aug 07, 2020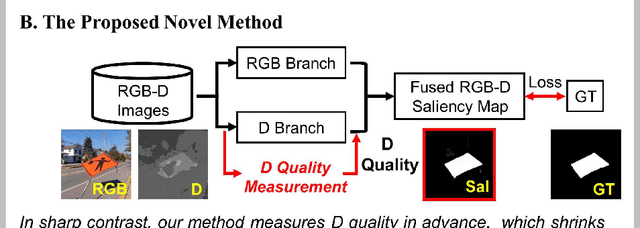
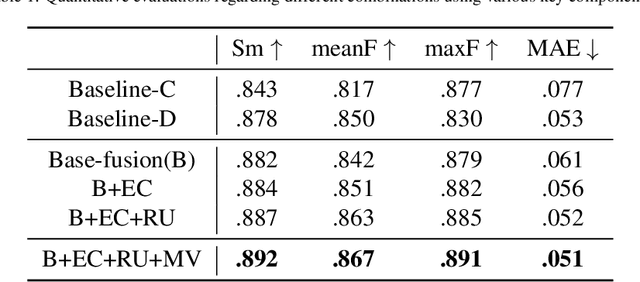
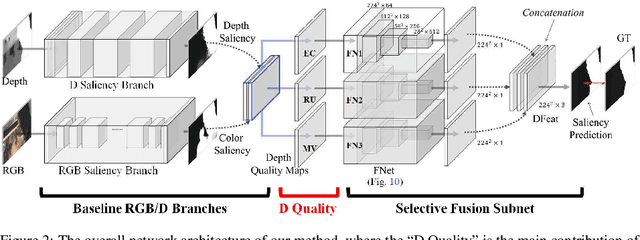
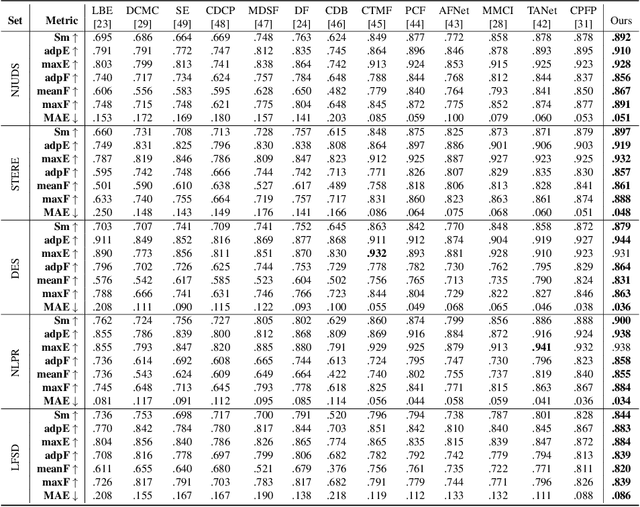
Previous RGB-D salient object detection (SOD) methods have widely adopted deep learning tools to automatically strike a trade-off between RGB and D (depth), whose key rationale is to take full advantage of their complementary nature, aiming for a much-improved SOD performance than that of using either of them solely. However, such fully automatic fusions may not always be helpful for the SOD task because the D quality itself usually varies from scene to scene. It may easily lead to a suboptimal fusion result if the D quality is not considered beforehand. Moreover, as an objective factor, the D quality has long been overlooked by previous work. As a result, it is becoming a clear performance bottleneck. Thus, we propose a simple yet effective scheme to measure D quality in advance, the key idea of which is to devise a series of features in accordance with the common attributes of high-quality D regions. To be more concrete, we conduct D quality assessments for each image region, following a multi-scale methodology that includes low-level edge consistency, mid-level regional uncertainty and high-level model variance. All these components will be computed independently and then be assembled with RGB and D features, applied as implicit indicators, to guide the selective fusion. Compared with the state-of-the-art fusion schemes, our method can achieve a more reasonable fusion status between RGB and D. Specifically, the proposed D quality measurement method achieves steady performance improvements for almost 2.0\% in general.
Adaptive Adversarial Logits Pairing
May 25, 2020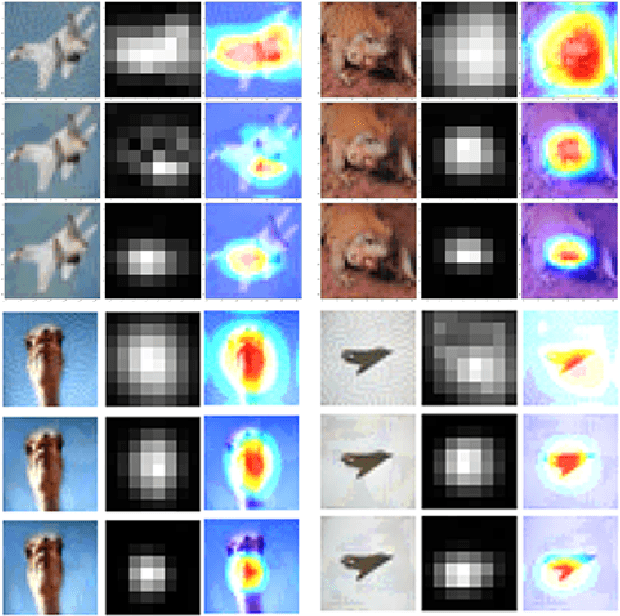
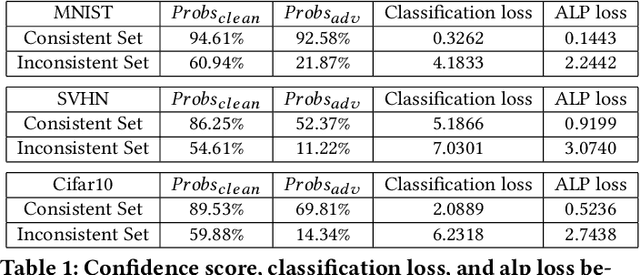
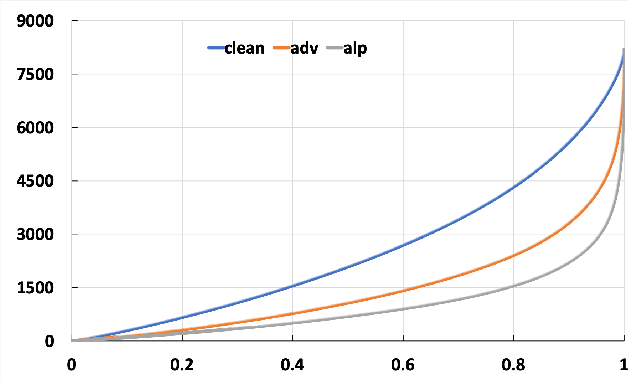
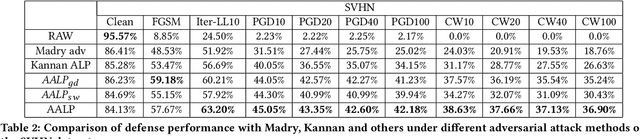
Adversarial examples provide an opportunity as well as impose a challenge for understanding image classification systems. Based on the analysis of state-of-the-art defense solution Adversarial Logits Pairing (ALP), we observed in this work that: (1) The inference of adversarially robust models tends to rely on fewer high-contribution features compared with vulnerable ones. (2) The training target of ALP doesn't fit well to a noticeable part of samples, where the logits pairing loss is overemphasized and obstructs minimizing the classification loss. Motivated by these observations, we designed an Adaptive Adversarial Logits Pairing (AALP) solution by modifying the training process and training target of ALP. Specifically, AALP consists of an adaptive feature optimization module with Guided Dropout to systematically pursue few high-contribution features, and an adaptive sample weighting module by setting sample-specific training weights to balance between logits pairing loss and classification loss. The proposed AALP solution demonstrates superior defense performance on multiple datasets with extensive experiments.
Nonnegative Low Rank Tensor Approximation and its Application to Multi-dimensional Images
Jul 28, 2020
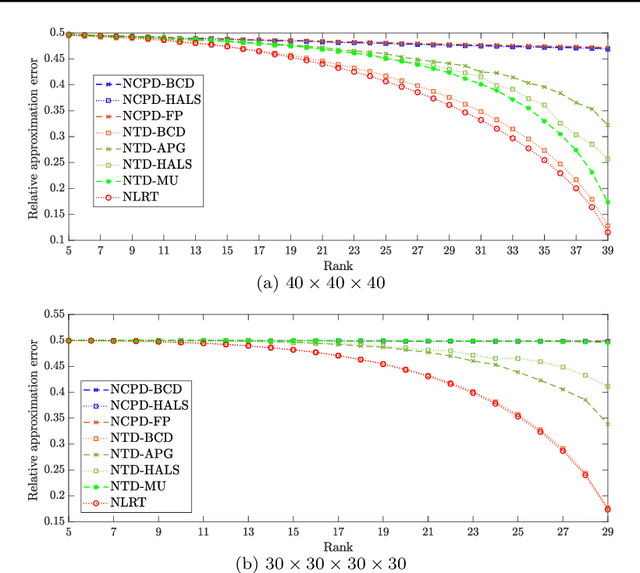
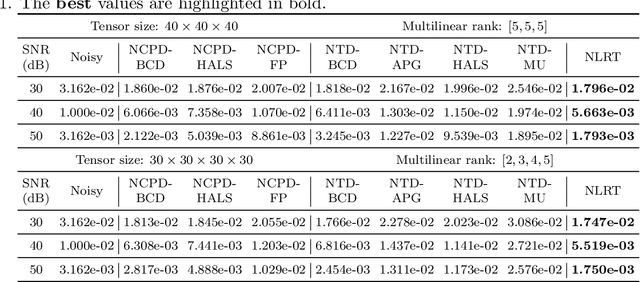
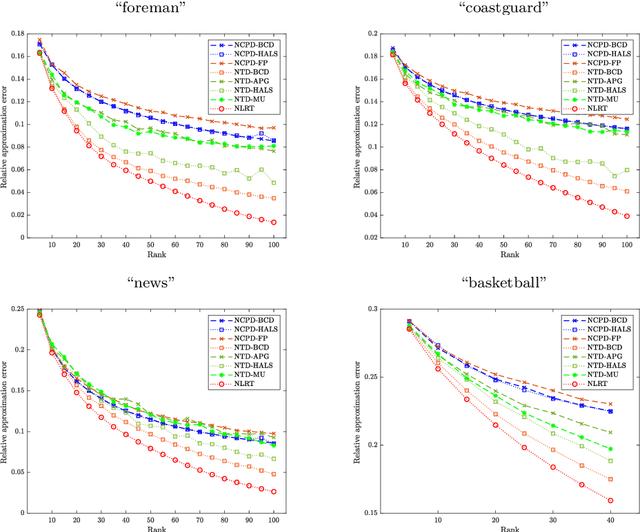
The main aim of this paper is to develop a new algorithm for computing Nonnegative Low Rank Tensor (NLRT) approximation for nonnegative tensors that arise in many multi-dimensional imaging applications. Nonnegativity is one of the important property as each pixel value refer to nonzero light intensity in image data acquisition. Our approach is different from classical nonnegative tensor factorization (NTF) which has been studied for many years. For a given nonnegative tensor, the classical NTF approach is to determine nonnegative low rank tensor by computing factor matrices or tensors (for example, CPD finds factor matrices while Tucker decomposition finds core tensor and factor matrices), such that the distance between this nonnegative low rank tensor and given tensor is as small as possible. The proposed NLRT approach is different from the classical NTF. It determines a nonnegative low rank tensor without using decompositions or factorization methods. The minimized distance by the proposed NLRT method can be smaller than that by the NTF method, and it implies that the proposed NLRT method can obtain a better low rank tensor approximation. The proposed NLRT approximation algorithm is derived by using the alternating averaged projection on the product of low rank matrix manifolds and non-negativity property. We show the convergence of the alternating projection algorithm. Experimental results for synthetic data and multi-dimensional images are presented to demonstrate the performance of the proposed NLRT method is better than that of existing NTF methods.
Explicit Gradient Learning
Jun 09, 2020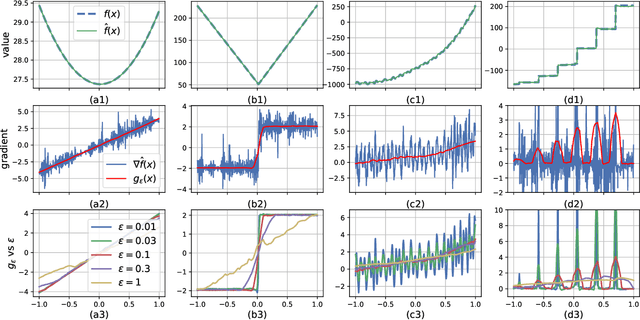
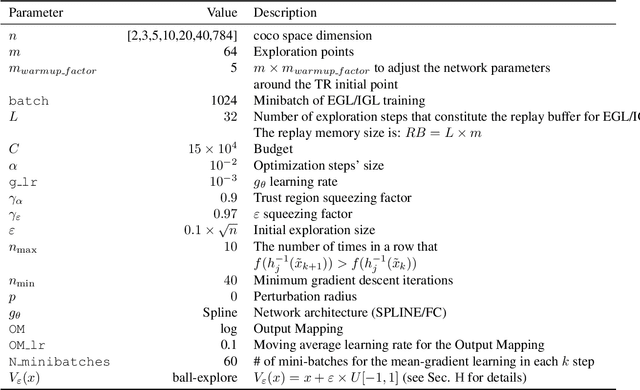
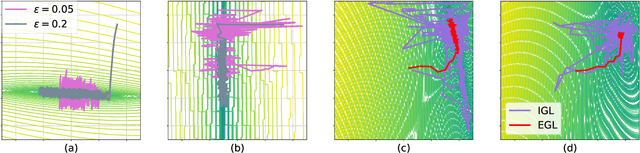

Black-Box Optimization (BBO) methods can find optimal policies for systems that interact with complex environments with no analytical representation. As such, they are of interest in many Artificial Intelligence (AI) domains. Yet classical BBO methods fall short in high-dimensional non-convex problems. They are thus often overlooked in real-world AI tasks. Here we present a BBO method, termed Explicit Gradient Learning (EGL), that is designed to optimize high-dimensional ill-behaved functions. We derive EGL by finding weak-spots in methods that fit the objective function with a parametric Neural Network (NN) model and obtain the gradient signal by calculating the parametric gradient. Instead of fitting the function, EGL trains a NN to estimate the objective gradient directly. We prove the convergence of EGL in convex optimization and its robustness in the optimization of integrable functions. We evaluate EGL and achieve state-of-the-art results in two challenging problems: (1) the COCO test suite against an assortment of standard BBO methods; and (2) in a high-dimensional non-convex image generation task.
Hysia: Serving DNN-Based Video-to-Retail Applications in Cloud
Jun 09, 2020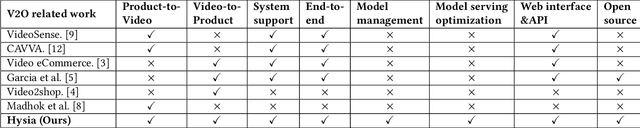
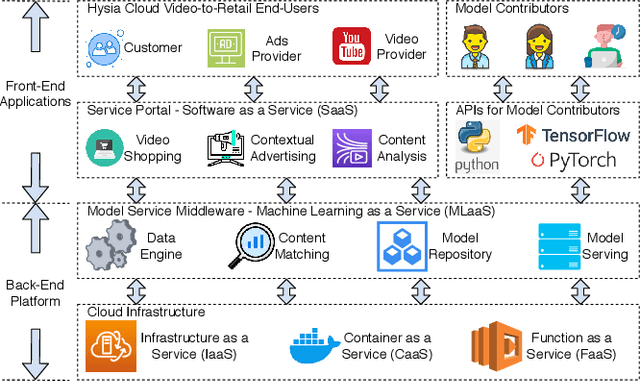
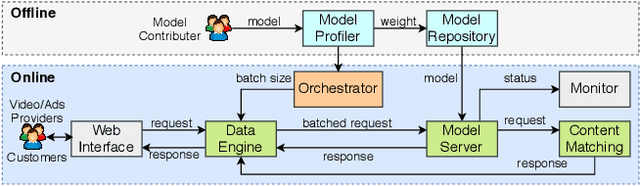
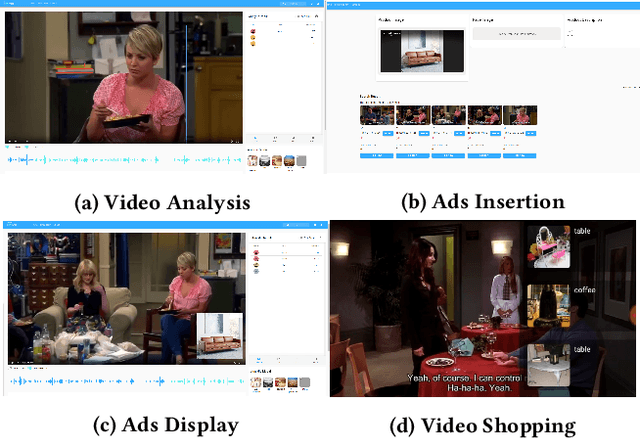
Combining \underline{v}ideo streaming and online \underline{r}etailing (V2R) has been a growing trend recently. In this paper, we provide practitioners and researchers in multimedia with a cloud-based platform named Hysia for easy development and deployment of V2R applications. The system consists of: 1) a back-end infrastructure providing optimized V2R related services including data engine, model repository, model serving and content matching; and 2) an application layer which enables rapid V2R application prototyping. Hysia addresses industry and academic needs in large-scale multimedia by: 1) seamlessly integrating state-of-the-art libraries including NVIDIA video SDK, Facebook faiss, and gRPC; 2) efficiently utilizing GPU computation; and 3) allowing developers to bind new models easily to meet the rapidly changing deep learning (DL) techniques. On top of that, we implement an orchestrator for further optimizing DL model serving performance. Hysia has been released as an open source project on GitHub, and attracted considerable attention. We have published Hysia to DockerHub as an official image for seamless integration and deployment in current cloud environments.
Hyperspectral Super-Resolution via Coupled Tensor Ring Factorization
Jan 06, 2020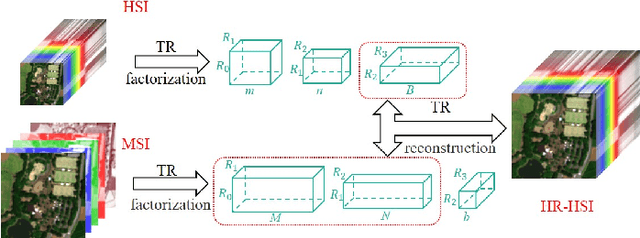
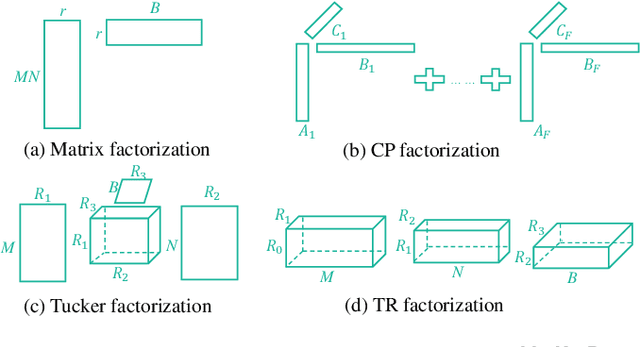
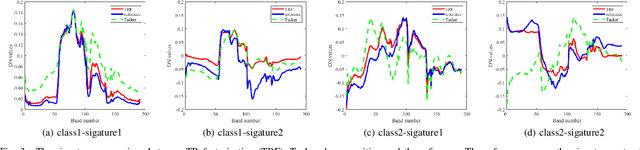
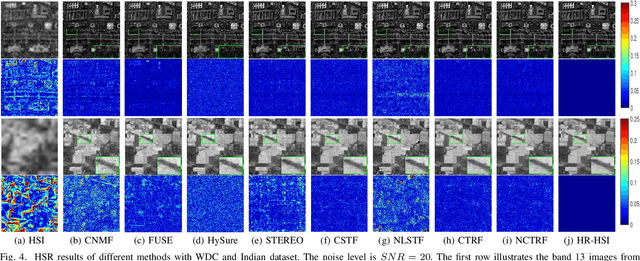
Hyperspectral super-resolution (HSR) fuses a low-resolution hyperspectral image (HSI) and a high-resolution multispectral image (MSI) to obtain a high-resolution HSI (HR-HSI). In this paper, we propose a new model, named coupled tensor ring factorization (CTRF), for HSR. The proposed CTRF approach simultaneously learns high spectral resolution core tensor from the HSI and high spatial resolution core tensors from the MSI, and reconstructs the HR-HSI via tensor ring (TR) representation (Figure~\ref{fig:framework}). The CTRF model can separately exploit the low-rank property of each class (Section \ref{sec:analysis}), which has been never explored in the previous coupled tensor model. Meanwhile, it inherits the simple representation of coupled matrix/CP factorization and flexible low-rank exploration of coupled Tucker factorization. Guided by Theorem~\ref{th:1}, we further propose a spectral nuclear norm regularization to explore the global spectral low-rank property. The experiments have demonstrated the advantage of the proposed nuclear norm regularized CTRF (NCTRF) as compared to previous matrix/tensor and deep learning methods.
Is Image Super-resolution Helpful for Other Vision Tasks?
Jan 28, 2016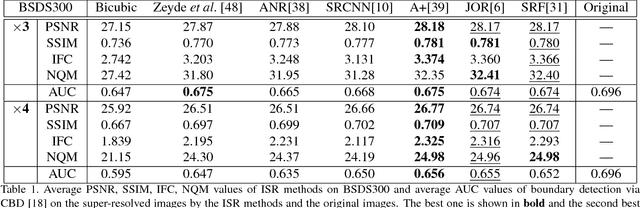
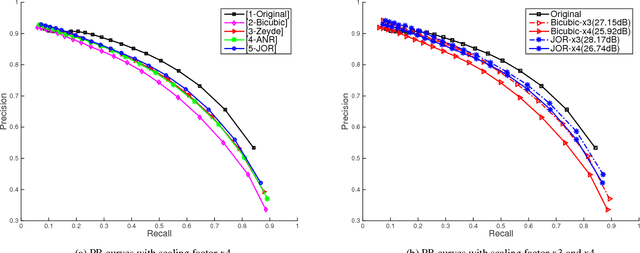

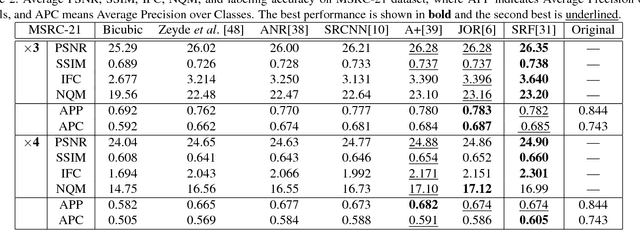
Despite the great advances made in the field of image super-resolution (ISR) during the last years, the performance has merely been evaluated perceptually. Thus, it is still unclear whether ISR is helpful for other vision tasks. In this paper, we present the first comprehensive study and analysis of the usefulness of ISR for other vision applications. In particular, six ISR methods are evaluated on four popular vision tasks, namely edge detection, semantic image segmentation, digit recognition, and scene recognition. We show that applying ISR to input images of other vision systems does improve their performance when the input images are of low-resolution. We also study the correlation between four standard perceptual evaluation criteria (namely PSNR, SSIM, IFC, and NQM) and the usefulness of ISR to the vision tasks. Experiments show that they correlate well with each other in general, but perceptual criteria are still not accurate enough to be used as full proxies for the usefulness. We hope this work will inspire the community to evaluate ISR methods also in real vision applications, and to adopt ISR as a pre-processing step of other vision tasks if the resolution of their input images is low.
Wasserstein-2 Generative Networks
Sep 28, 2019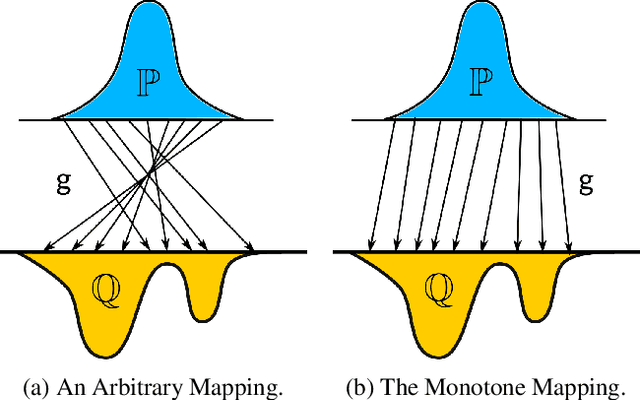
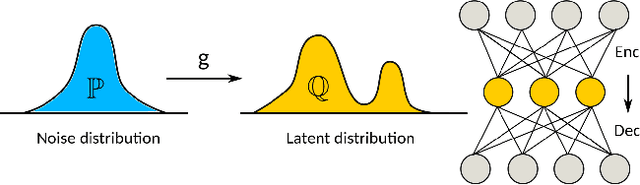
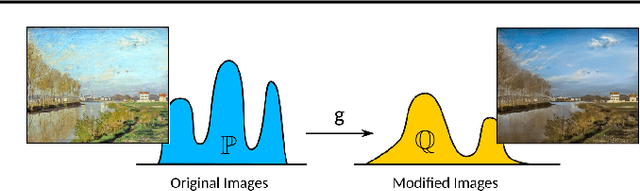
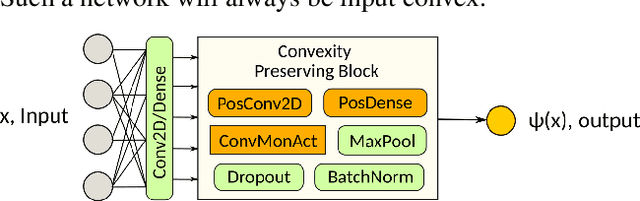
Modern generative learning is mainly associated with Generative Adversarial Networks (GANs). Training such networks is always hard due to the minimax nature of the optimization objective. In this paper we propose a novel algorithm for training generative models, which gets rid of mini-max GAN objective, thus significantly simplified model training. The proposed algorithm uses the variational approximation of Wasserstein-2 distances by Input Convex Neural Networks. We also provide the results of computational experiments, which confirms the efficiency of our algorithm in application to latent spaces optimal transport and image-to-image style transfer.