 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Context-Aware Novelty Detection
Jun 01, 2020
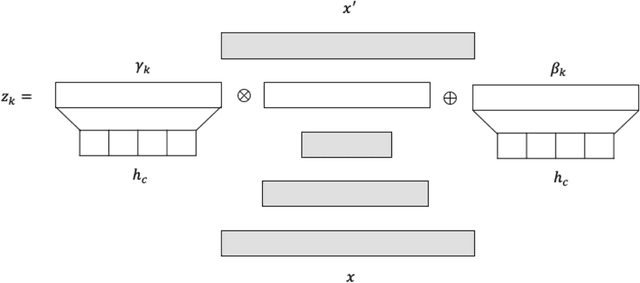
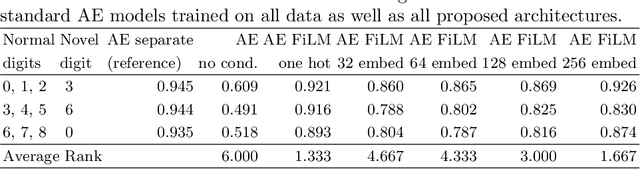
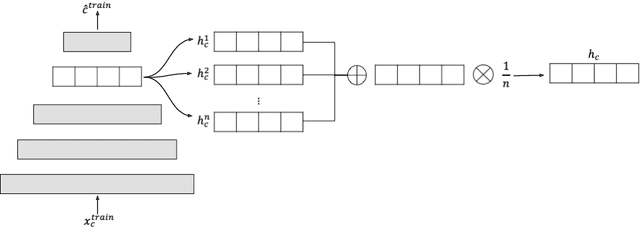
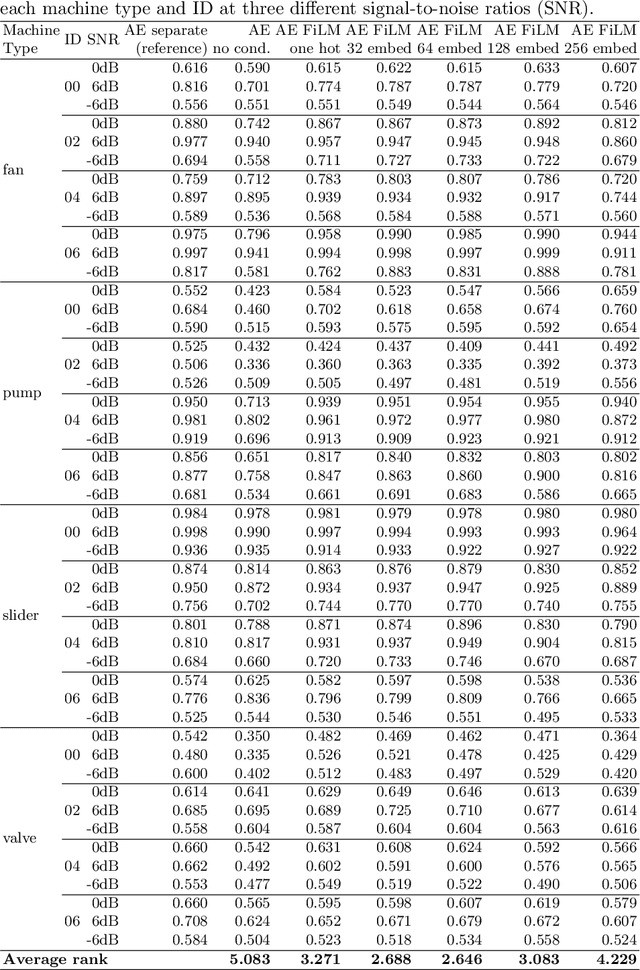
A common assumption of novelty detection is that the distribution of both "normal" and "novel" data are static. However, this is often not the case in scenarios where data evolves over time, or when the definition of normal and novel depends on contextual information, leading to changes in these distributions. This can lead to significant difficulties when attempting to train a model on datasets where the distribution of normal data in one scenario is similar to that of novel data in another scenario. In this paper we propose a context-aware approach to novelty detection for deep autoencoders. We create a semi-supervised network architecture which utilises auxiliary labels in order to reveal contextual information and allows the model to adapt to a variety of normal and novel scenarios. We evaluate our approach on both synthetic image data and real world audio data displaying these characteristics.
Sparse Coding on Cascaded Residuals
Nov 07, 2019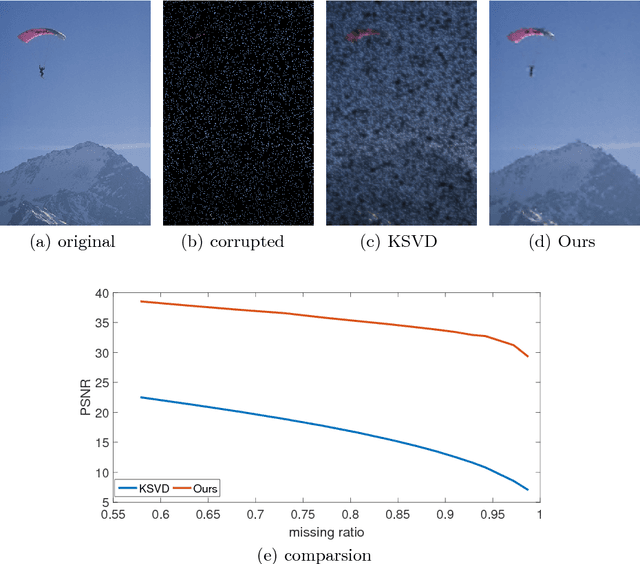
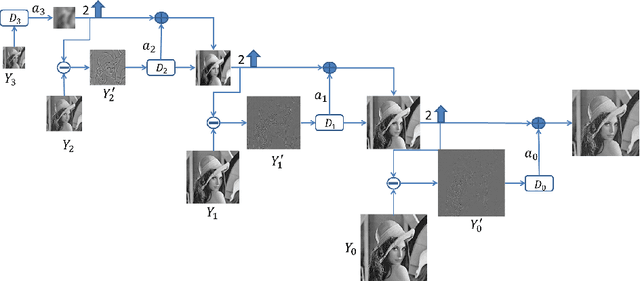
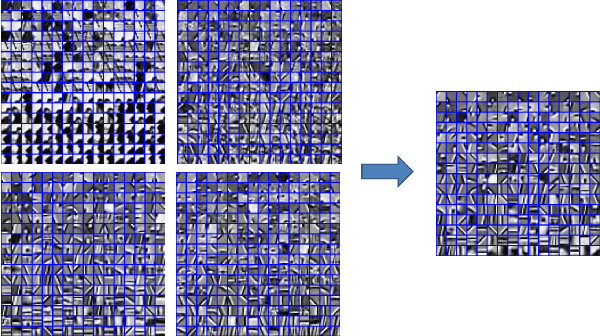
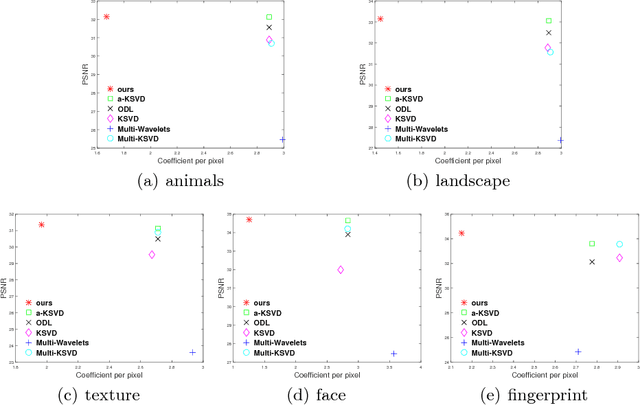
This paper seeks to combine dictionary learning and hierarchical image representation in a principled way. To make dictionary atoms capturing additional information from extended receptive fields and attain improved descriptive capacity, we present a two-pass multi-resolution cascade framework for dictionary learning and sparse coding. The cascade allows collaborative reconstructions at different resolutions using the same dimensional dictionary atoms. Our jointly learned dictionary comprises atoms that adapt to the information available at the coarsest layer where the support of atoms reaches their maximum range and the residual images where the supplementary details progressively refine the reconstruction objective. The residual at a layer is computed by the difference between the aggregated reconstructions of the previous layers and the downsampled original image at that layer. Our method generates more flexible and accurate representations using much less number of coefficients. Its computational efficiency stems from encoding at the coarsest resolution, which is minuscule, and encoding the residuals, which are relatively much sparse. Our extensive experiments on multiple datasets demonstrate that this new method is powerful in image coding, denoising, inpainting and artifact removal tasks outperforming the state-of-the-art techniques.
Symbolic Semantic Segmentation and Interpretation of COVID-19 Lung Infections in Chest CT volumes based on Emergent Languages
Aug 22, 2020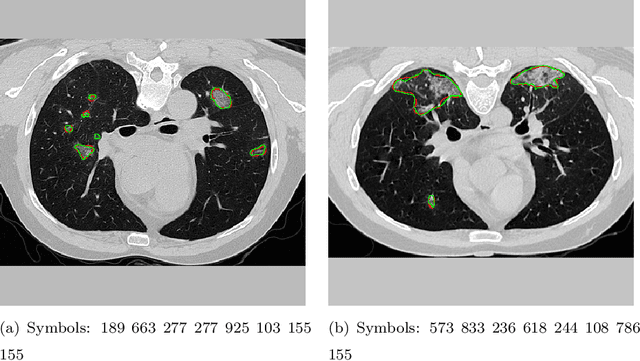
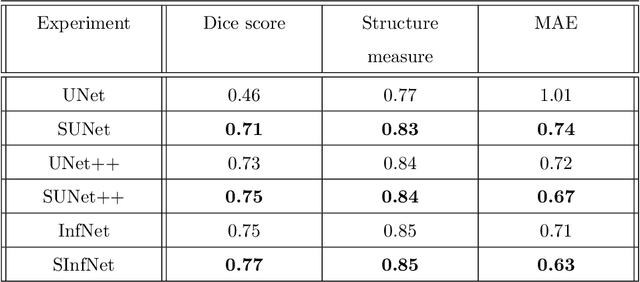
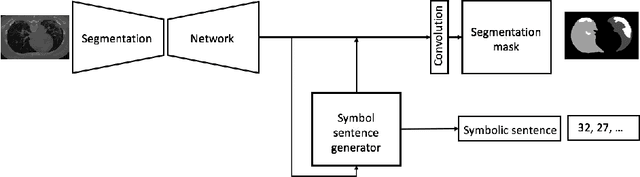
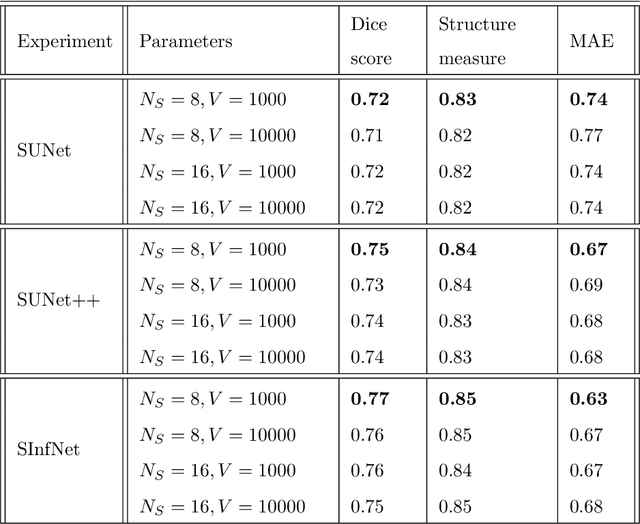
The coronavirus disease (COVID-19) has resulted in a pandemic crippling the a breadth of services critical to daily life. Segmentation of lung infections in computerized tomography (CT) slices could be be used to improve diagnosis and understanding of COVID-19 in patients. Deep learning systems lack interpretability because of their black box nature. Inspired by human communication of complex ideas through language, we propose a symbolic framework based on emergent languages for the segmentation of COVID-19 infections in CT scans of lungs. We model the cooperation between two artificial agents - a Sender and a Receiver. These agents synergistically cooperate using emergent symbolic language to solve the task of semantic segmentation. Our game theoretic approach is to model the cooperation between agents unlike Generative Adversarial Networks (GANs). The Sender retrieves information from one of the higher layers of the deep network and generates a symbolic sentence sampled from a categorical distribution of vocabularies. The Receiver ingests the stream of symbols and cogenerates the segmentation mask. A private emergent language is developed that forms the communication channel used to describe the task of segmentation of COVID infections. We augment existing state of the art semantic segmentation architectures with our symbolic generator to form symbolic segmentation models. Our symbolic segmentation framework achieves state of the art performance for segmentation of lung infections caused by COVID-19. Our results show direct interpretation of symbolic sentences to discriminate between normal and infected regions, infection morphology and image characteristics. We show state of the art results for segmentation of COVID-19 lung infections in CT.
More Diverse Means Better: Multimodal Deep Learning Meets Remote Sensing Imagery Classification
Aug 12, 2020
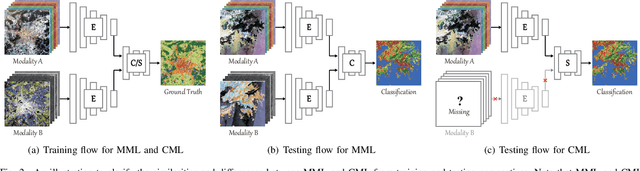
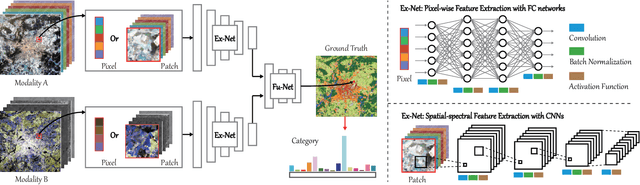
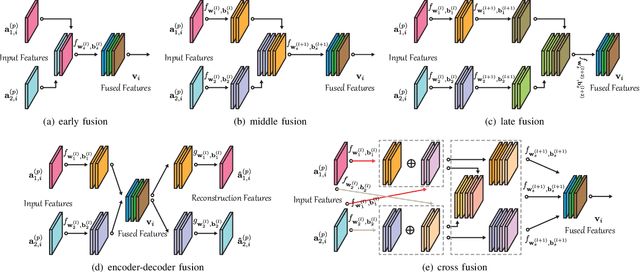
Classification and identification of the materials lying over or beneath the Earth's surface have long been a fundamental but challenging research topic in geoscience and remote sensing (RS) and have garnered a growing concern owing to the recent advancements of deep learning techniques. Although deep networks have been successfully applied in single-modality-dominated classification tasks, yet their performance inevitably meets the bottleneck in complex scenes that need to be finely classified, due to the limitation of information diversity. In this work, we provide a baseline solution to the aforementioned difficulty by developing a general multimodal deep learning (MDL) framework. In particular, we also investigate a special case of multi-modality learning (MML) -- cross-modality learning (CML) that exists widely in RS image classification applications. By focusing on "what", "where", and "how" to fuse, we show different fusion strategies as well as how to train deep networks and build the network architecture. Specifically, five fusion architectures are introduced and developed, further being unified in our MDL framework. More significantly, our framework is not only limited to pixel-wise classification tasks but also applicable to spatial information modeling with convolutional neural networks (CNNs). To validate the effectiveness and superiority of the MDL framework, extensive experiments related to the settings of MML and CML are conducted on two different multimodal RS datasets. Furthermore, the codes and datasets will be available at https://github.com/danfenghong/IEEE_TGRS_MDL-RS, contributing to the RS community.
Computing Topology Preservation of RBF Transformations for Landmark-Based Image Registration
Oct 13, 2014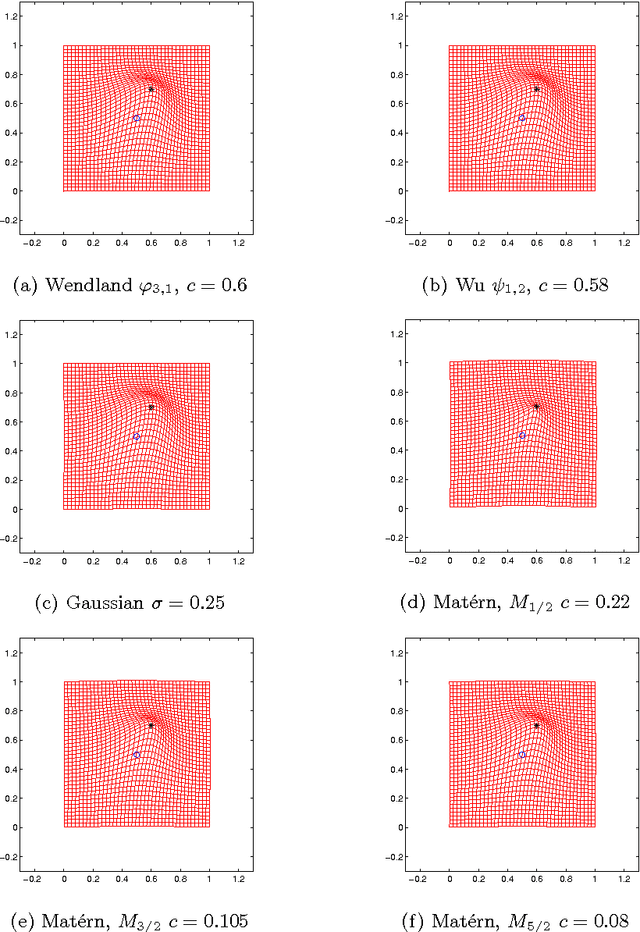
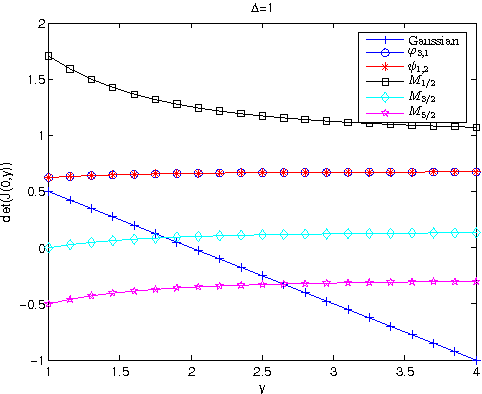
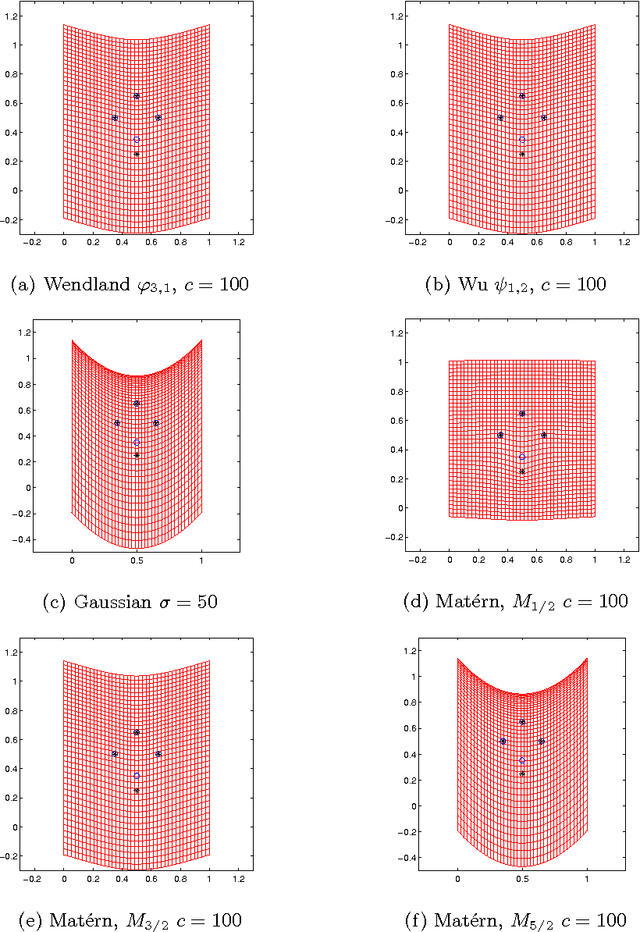
In image registration, a proper transformation should be topology preserving. Especially for landmark-based image registration, if the displacement of one landmark is larger enough than those of neighbourhood landmarks, topology violation will be occurred. This paper aim to analyse the topology preservation of some Radial Basis Functions (RBFs) which are used to model deformations in image registration. Mat\'{e}rn functions are quite common in the statistic literature (see, e.g. \cite{Matern86,Stein99}). In this paper, we use them to solve the landmark-based image registration problem. We present the topology preservation properties of RBFs in one landmark and four landmarks model respectively. Numerical results of three kinds of Mat\'{e}rn transformations are compared with results of Gaussian, Wendland's, and Wu's functions.
End-to-End Learning for Image Burst Deblurring
Sep 06, 2016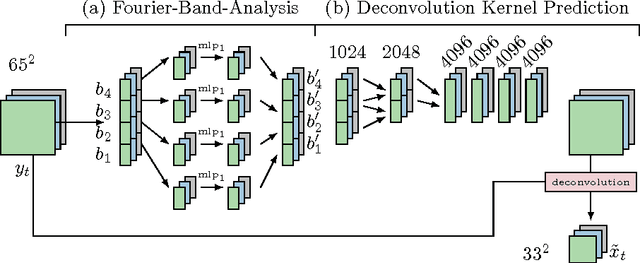
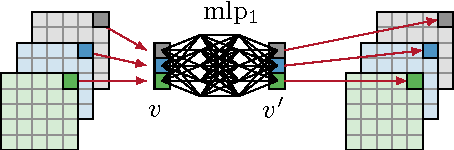
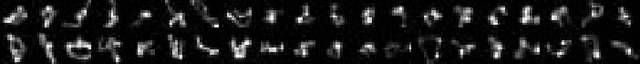

We present a neural network model approach for multi-frame blind deconvolution. The discriminative approach adopts and combines two recent techniques for image deblurring into a single neural network architecture. Our proposed hybrid-architecture combines the explicit prediction of a deconvolution filter and non-trivial averaging of Fourier coefficients in the frequency domain. In order to make full use of the information contained in all images in one burst, the proposed network embeds smaller networks, which explicitly allow the model to transfer information between images in early layers. Our system is trained end-to-end using standard backpropagation on a set of artificially generated training examples, enabling competitive performance in multi-frame blind deconvolution, both with respect to quality and runtime.
Efficient training-image based geostatistical simulation and inversion using a spatial generative adversarial neural network
Aug 16, 2017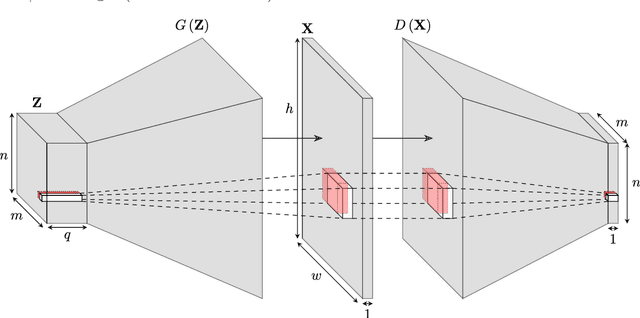
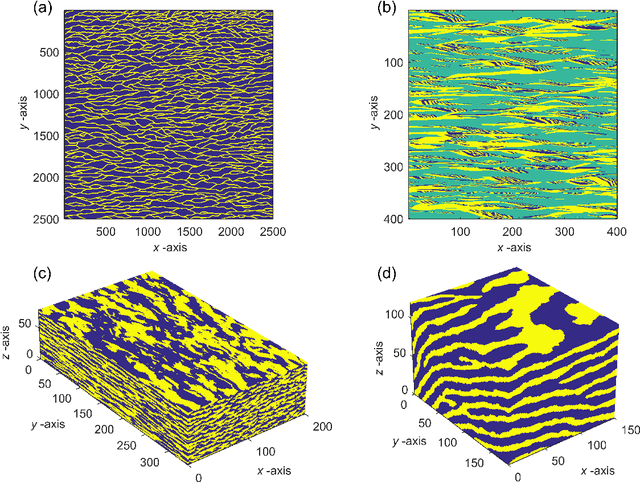
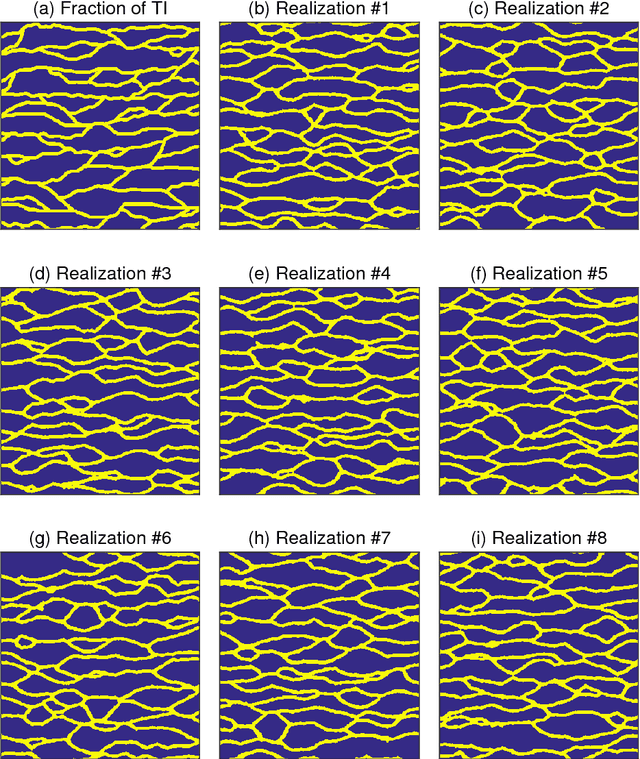
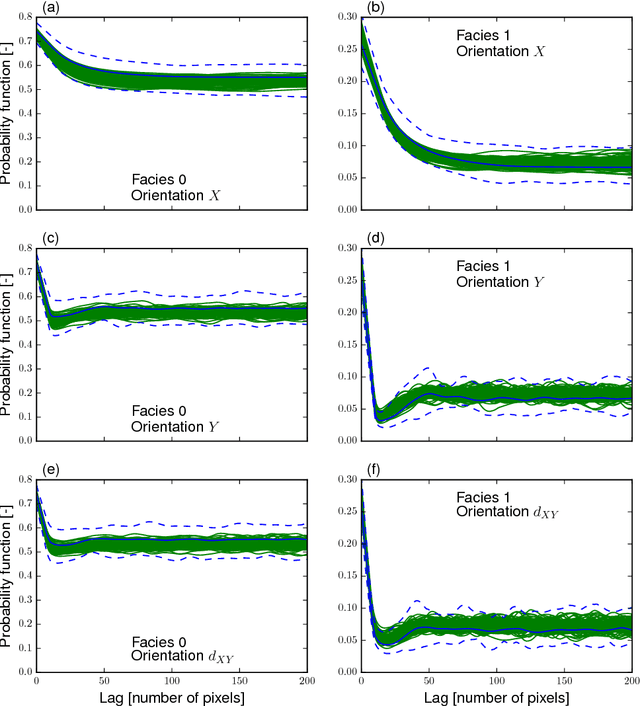
Probabilistic inversion within a multiple-point statistics framework is still computationally prohibitive for large-scale problems. To partly address this, we introduce and evaluate a new training-image based simulation and inversion approach for complex geologic media. Our approach relies on a deep neural network of the spatial generative adversarial network (SGAN) type. After training using a training image (TI), our proposed SGAN can quickly generate 2D and 3D unconditional realizations. A key feature of our SGAN is that it defines a (very) low-dimensional parameterization, thereby allowing for efficient probabilistic (or deterministic) inversion using state-of-the-art Markov chain Monte Carlo (MCMC) methods. A series of 2D and 3D categorical TIs is first used to analyze the performance of our SGAN for unconditional simulation. The speed at which realizations are generated makes it especially useful for simulating over large grids and/or from a complex multi-categorical TI. Subsequently, synthetic inversion case studies involving 2D steady-state flow and 3D transient hydraulic tomography are used to illustrate the effectiveness of our proposed SGAN-based probabilistic inversion. For the 2D case, the inversion rapidly explores the posterior model distribution. For the 3D case, the inversion recovers model realizations that fit the data close to the target level and visually resemble the true model well. Future work will focus on the inclusion of direct conditioning data and application to continuous TIs.
Compositional Explanations of Neurons
Jun 24, 2020
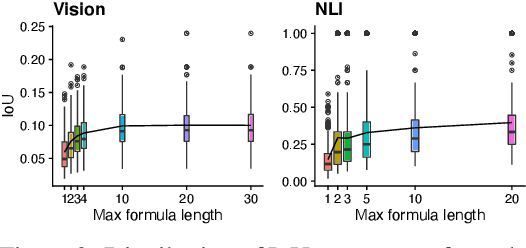


We describe a procedure for explaining neurons in deep representations by identifying compositional logical concepts that closely approximate neuron behavior. Compared to prior work that uses atomic labels as explanations, analyzing neurons compositionally allows us to more precisely and expressively characterize their behavior. We use this procedure to answer several questions on interpretability in models for vision and natural language processing. First, we examine the kinds of abstractions learned by neurons. In image classification, we find that many neurons learn highly abstract but semantically coherent visual concepts, while other polysemantic neurons detect multiple unrelated features; in natural language inference (NLI), neurons learn shallow lexical heuristics from dataset biases. Second, we see whether compositional explanations give us insight into model performance: vision neurons that detect human-interpretable concepts are positively correlated with task performance, while NLI neurons that fire for shallow heuristics are negatively correlated with task performance. Finally, we show how compositional explanations provide an accessible way for end users to produce simple "copy-paste" adversarial examples that change model behavior in predictable ways.
Event-based Asynchronous Sparse Convolutional Networks
Mar 20, 2020

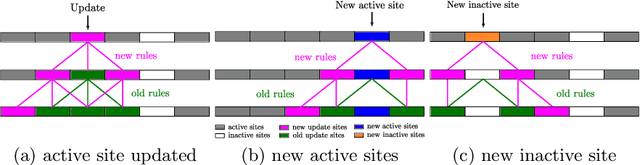
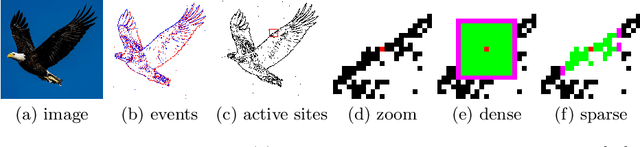
Event cameras are bio-inspired sensors that respond to per-pixel brightness changes in the form of asynchronous and sparse "events". Recently, pattern recognition algorithms, such as learning-based methods, have made significant progress with event cameras by converting events into synchronous dense, image-like representations and applying traditional machine learning methods developed for standard cameras. However, these approaches discard the spatial and temporal sparsity inherent in event data at the cost of higher computational complexity and latency. In this work, we present a general framework for converting models trained on synchronous image-like event representations into asynchronous models with identical output, thus directly leveraging the intrinsic asynchronous and sparse nature of the event data. We show both theoretically and experimentally that this drastically reduces the computational complexity and latency of high-capacity, synchronous neural networks without sacrificing accuracy. In addition, our framework has several desirable characteristics: (i) it exploits spatio-temporal sparsity of events explicitly, (ii) it is agnostic to the event representation, network architecture, and task, and (iii) it does not require any train-time change, since it is compatible with the standard neural networks' training process. We thoroughly validate the proposed framework on two computer vision tasks: object detection and object recognition. In these tasks, we reduce the computational complexity up to 20 times with respect to high-latency neural networks. At the same time, we outperform state-of-the-art asynchronous approaches up to 24% in prediction accuracy.
Labelling imaging datasets on the basis of neuroradiology reports: a validation study
Jul 08, 2020


Natural language processing (NLP) shows promise as a means to automate the labelling of hospital-scale neuroradiology magnetic resonance imaging (MRI) datasets for computer vision applications. To date, however, there has been no thorough investigation into the validity of this approach, including determining the accuracy of report labels compared to image labels as well as examining the performance of non-specialist labellers. In this work, we draw on the experience of a team of neuroradiologists who labelled over 5000 MRI neuroradiology reports as part of a project to build a dedicated deep learning-based neuroradiology report classifier. We show that, in our experience, assigning binary labels (i.e. normal vs abnormal) to images from reports alone is highly accurate. In contrast to the binary labels, however, the accuracy of more granular labelling is dependent on the category, and we highlight reasons for this discrepancy. We also show that downstream model performance is reduced when labelling of training reports is performed by a non-specialist. To allow other researchers to accelerate their research, we make our refined abnormality definitions and labelling rules available, as well as our easy-to-use radiology report labelling app which helps streamline this process.