 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Y-Net: A Hybrid Deep Learning Reconstruction Framework for Photoacoustic Imaging in vivo
Aug 02, 2019
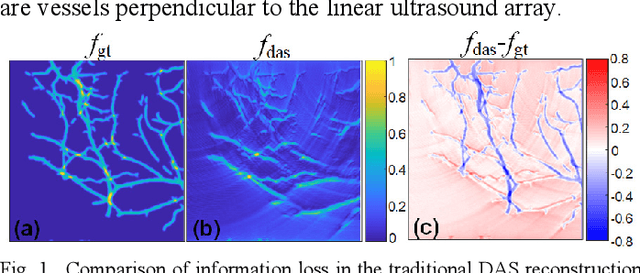
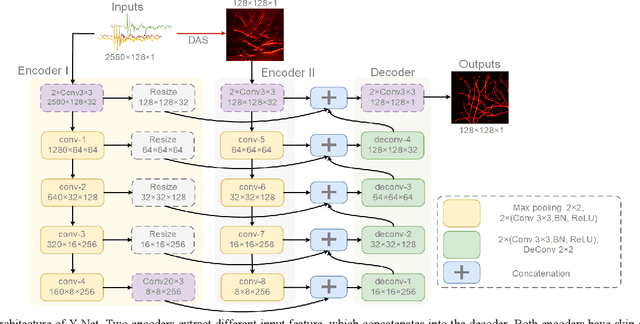
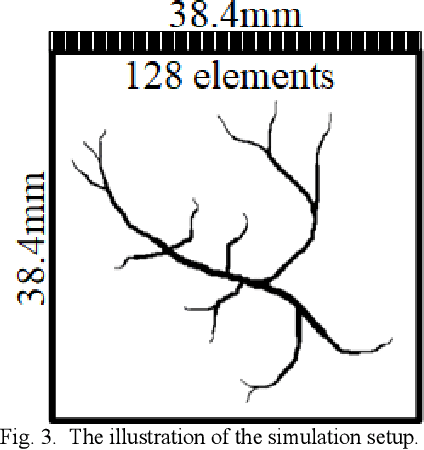

Photoacoustic imaging (PAI) is an emerging non-invasive imaging modality combining the advantages of deep ultrasound penetration and high optical contrast. Image reconstruction is an essential topic in PAI, which is unfortunately an ill-posed problem due to the complex and unknown optical/acoustic parameters in tissue. Conventional algorithms used in PAI (e.g., delay-and-sum) provide a fast solution while many artifacts remain, especially for linear array probe with limited-view issue. Convolutional neural network (CNN) has shown state-of-the-art results in computer vision, and more and more work based on CNN has been studied in medical image processing recently. In this paper, we present a non-iterative scheme filling the gap between existing direct-processing and post-processing methods, and propose a new framework Y-Net: a CNN architecture to reconstruct the PA image by optimizing both raw data and beamformed images once. The network connected two encoders with one decoder path, which optimally utilizes more information from raw data and beamformed image. The results of the test set showed good performance compared with conventional reconstruction algorithms and other deep learning methods. Our method is also validated with experiments both in-vitro and in vivo, which still performs better than other existing methods. The proposed Y-Net architecture also has high potential in medical image reconstruction for other imaging modalities beyond PAI.
On Space-spectrum Uncertainty Analysis for Coded Aperture Systems
Nov 16, 2019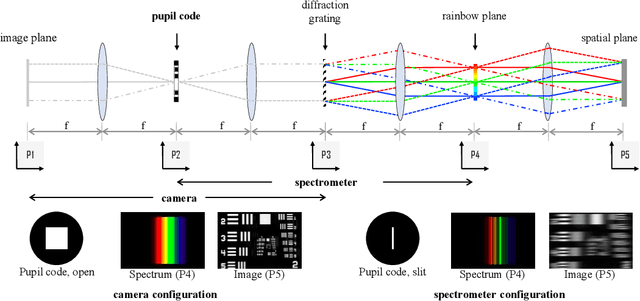
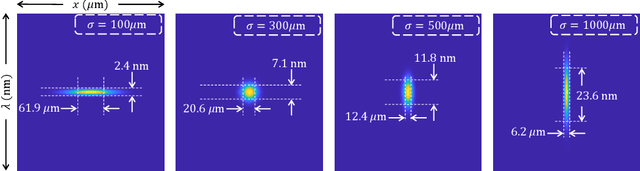
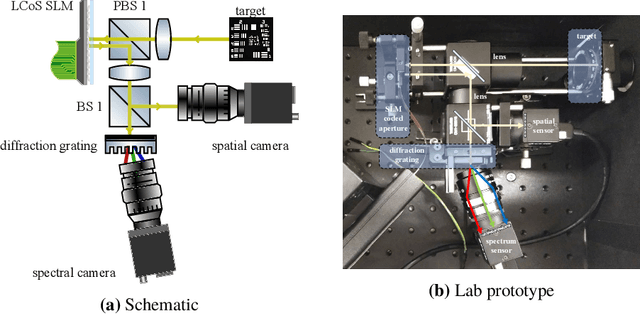

We introduce and analyze the concept of space-spectrum uncertainty for certain commonly-used designs for spectrally programmable cameras. Our key finding states that, it is impossible to simultaneously capture high-resolution spatial images while programming the spectrum at high resolution. This phenomenon arises due to a Fourier relationship between the aperture used for obtaining spectrum and its corresponding diffraction blur in the (spatial) image. We show that the product of spatial and spectral standard deviations is lower bounded by {\lambda}/4{\pi}{\nu_0} femto square-meters, where {\nu_0} is the density of groves in the diffraction grating and {\lambda} is the wavelength of light. Experiments with a lab prototype for simultaneously measuring spectrum and image validate our findings and its implication for spectral filtering.
Explaining Local, Global, And Higher-Order Interactions In Deep Learning
Jun 12, 2020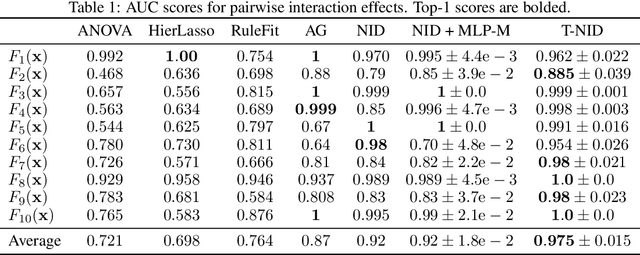
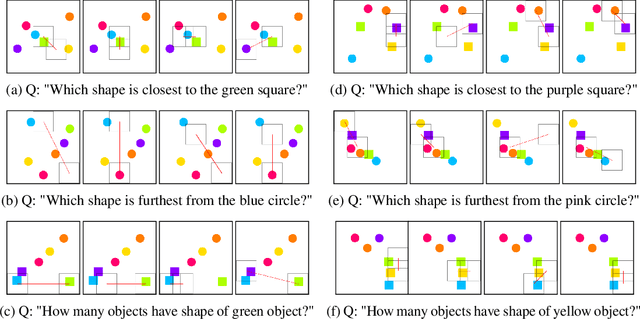
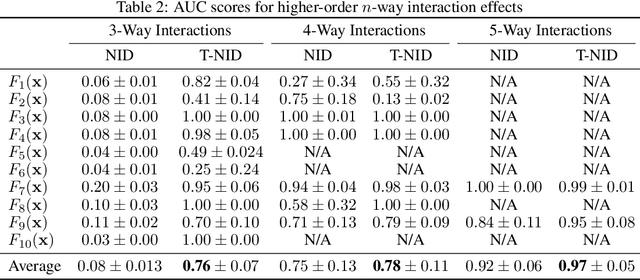
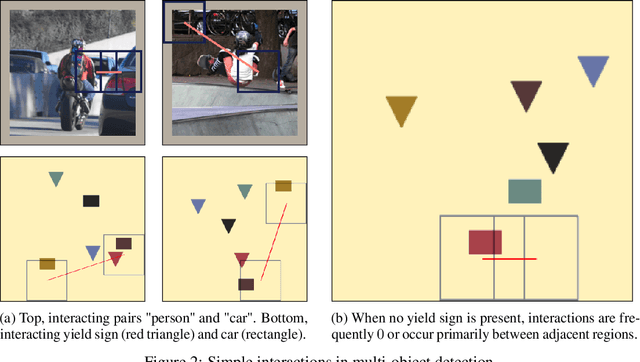
We present a simple yet highly generalizable method for explaining interacting parts within a neural network's reasoning process. In this work, we consider local, global, and higher-order statistical interactions. Generally speaking, local interactions occur between features within individual datapoints, while global interactions come in the form of universal features across the whole dataset. With deep learning, combined with some heuristics for tractability, we achieve state of the art measurement of global statistical interaction effects, including at higher orders (3-way interactions or more). We generalize this to the multidimensional setting to explain local interactions in multi-object detection and relational reasoning using the COCO annotated-image and Sort-Of-CLEVR toy datasets respectively. Here, we submit a new task for testing feature vector interactions, conduct a human study, propose a novel metric for relational reasoning, and use our interaction interpretations to innovate a more effective Relation Network. Finally, we apply these techniques on a real-world biomedical dataset to discover the higher-order interactions underlying Parkinson's disease clinical progression. Code for all experiments, fully reproducible, is available at: https://github.com/slerman12/ExplainingInteractions.
IALE: Imitating Active Learner Ensembles
Jul 09, 2020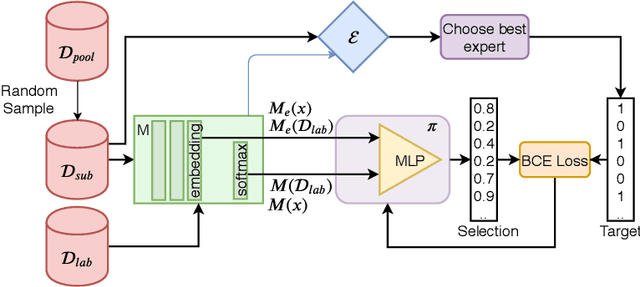

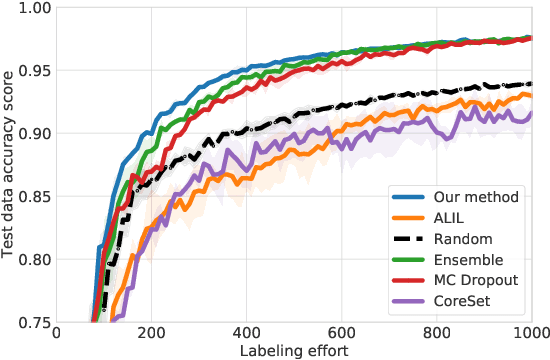
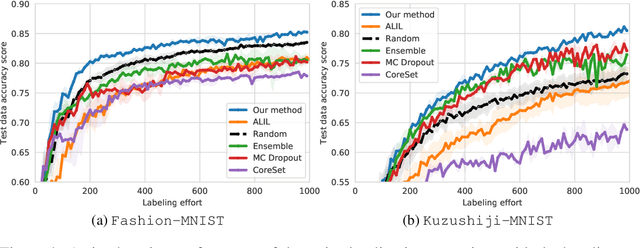
Active learning (AL) prioritizes the labeling of the most informative data samples. As the performance of well-known AL heuristics highly depends on the underlying model and data, recent heuristic-independent approaches that are based on reinforcement learning directly learn a policy that makes use of the labeling history to select the next sample. However, those methods typically need a huge number of samples to sufficiently explore the relevant state space. Imitation learning approaches aim to help out but again rely on a given heuristic. This paper proposes an improved imitation learning scheme that learns a policy for batch-mode pool-based AL. This is similar to previously presented multi-armed bandit approaches but in contrast to them we train a policy that imitates the selection of the best expert heuristic at each stage of the AL cycle directly. We use DAGGER to train the policy on a dataset and later apply it to similar datasets. With multiple AL heuristics as experts, the policy is able to reflect the choices of the best AL heuristics given the current state of the active learning process. We evaluate our method on well-known image datasets and show that we outperform state of the art imitation learners and heuristics.
Placepedia: Comprehensive Place Understanding with Multi-Faceted Annotations
Jul 09, 2020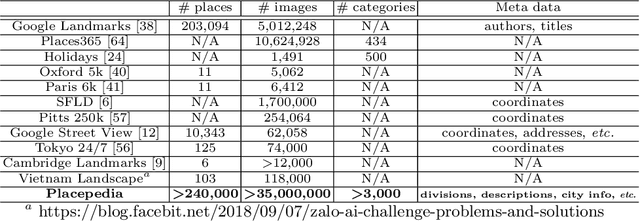
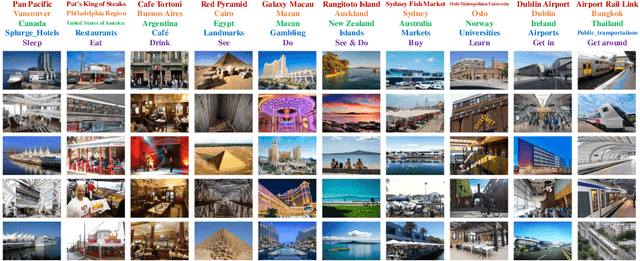
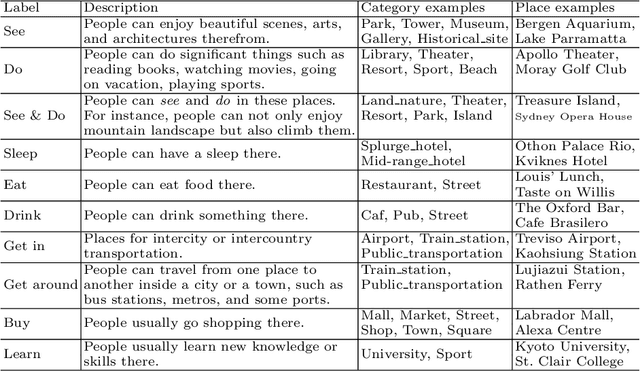

Place is an important element in visual understanding. Given a photo of a building, people can often tell its functionality, e.g. a restaurant or a shop, its cultural style, e.g. Asian or European, as well as its economic type, e.g. industry oriented or tourism oriented. While place recognition has been widely studied in previous work, there remains a long way towards comprehensive place understanding, which is far beyond categorizing a place with an image and requires information of multiple aspects. In this work, we contribute Placepedia, a large-scale place dataset with more than 35M photos from 240K unique places. Besides the photos, each place also comes with massive multi-faceted information, e.g. GDP, population, etc., and labels at multiple levels, including function, city, country, etc.. This dataset, with its large amount of data and rich annotations, allows various studies to be conducted. Particularly, in our studies, we develop 1) PlaceNet, a unified framework for multi-level place recognition, and 2) a method for city embedding, which can produce a vector representation for a city that captures both visual and multi-faceted side information. Such studies not only reveal key challenges in place understanding, but also establish connections between visual observations and underlying socioeconomic/cultural implications.
Articulated Pose Estimation by a Graphical Model with Image Dependent Pairwise Relations
Nov 04, 2014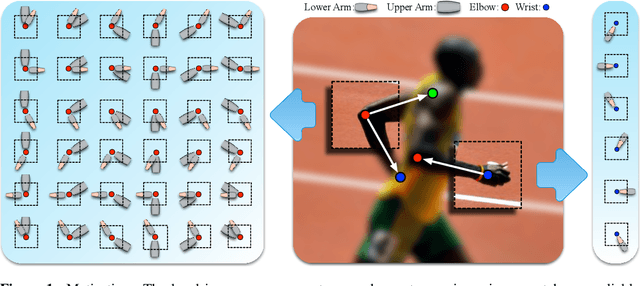
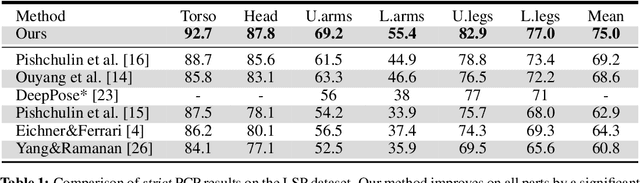
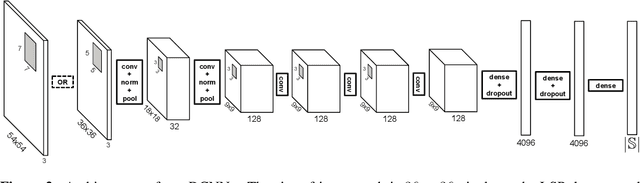

We present a method for estimating articulated human pose from a single static image based on a graphical model with novel pairwise relations that make adaptive use of local image measurements. More precisely, we specify a graphical model for human pose which exploits the fact the local image measurements can be used both to detect parts (or joints) and also to predict the spatial relationships between them (Image Dependent Pairwise Relations). These spatial relationships are represented by a mixture model. We use Deep Convolutional Neural Networks (DCNNs) to learn conditional probabilities for the presence of parts and their spatial relationships within image patches. Hence our model combines the representational flexibility of graphical models with the efficiency and statistical power of DCNNs. Our method significantly outperforms the state of the art methods on the LSP and FLIC datasets and also performs very well on the Buffy dataset without any training.
Traditional Method Inspired Deep Neural Network for Edge Detection
May 28, 2020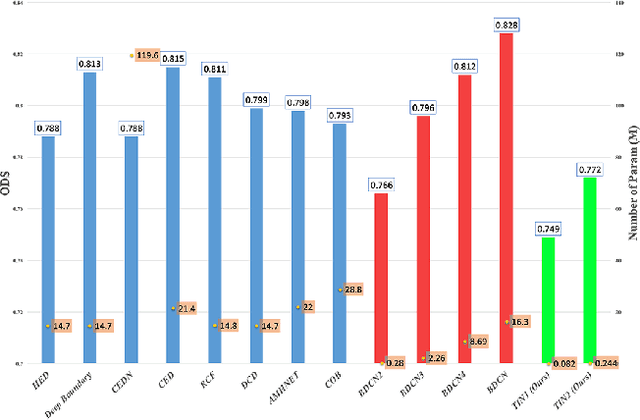
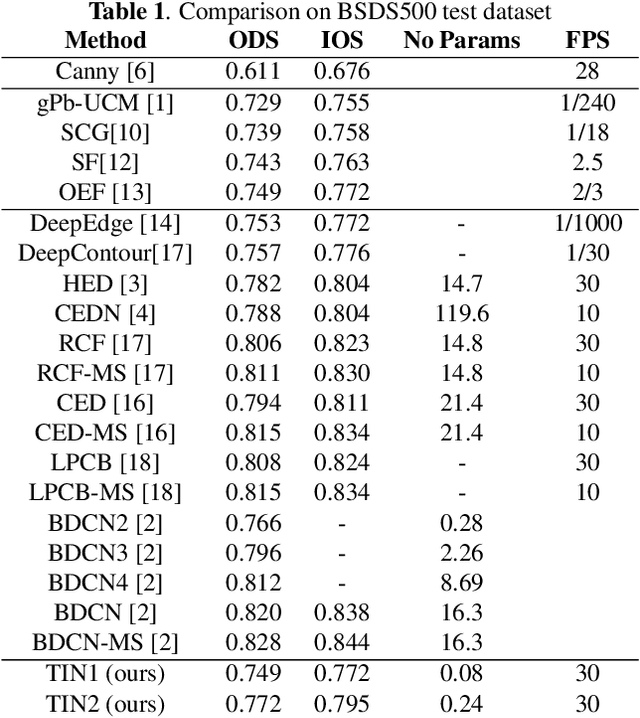

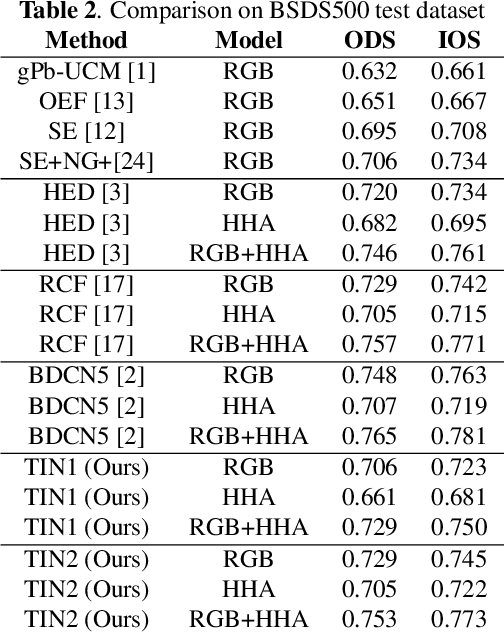
Recently, Deep-Neural-Network (DNN) based edge prediction is progressing fast. Although the DNN based schemes outperform the traditional edge detectors, they have much higher computational complexity. It could be that the DNN based edge detectors often adopt the neural net structures designed for high-level computer vision tasks, such as image segmentation and object recognition. Edge detection is a rather local and simple job, the over-complicated architecture and massive parameters may be unnecessary. Therefore, we propose a traditional method inspired framework to produce good edges with minimal complexity. We simplify the network architecture to include Feature Extractor, Enrichment, and Summarizer, which roughly correspond to gradient, low pass filter, and pixel connection in the traditional edge detection schemes. The proposed structure can effectively reduce the complexity and retain the edge prediction quality. Our TIN2 (Traditional Inspired Network) model has an accuracy higher than the recent BDCN2 (Bi-Directional Cascade Network) but with a smaller model.
Bi-Level Image Thresholding obtained by means of Kaniadakis Entropy
Feb 22, 2015In this paper we are proposing the use of Kaniadakis entropy in the bi-level thresholding of images, in the framework of a maximum entropy principle. We discuss the role of its entropic index in determining the threshold and in driving an "image transition", that is, an abrupt transition in the appearance of the corresponding bi-level image. Some examples are proposed to illustrate the method and for comparing it to the approach which is using the Tsallis entropy.
Color Image Enhancement In the Framework of Logarithmic Models
Dec 17, 2014In this paper, we propose a mathematical model for color image processing. It is a logarithmical one. We consider the cube (-1,1)x(-1,1)x(-1,1) as the set of values for the color space. We define two operations: addition <+> and real scalar multiplication <x>. With these operations the space of colors becomes a real vector space. Then, defining the scalar product (.|.) and the norm || . ||, we obtain a (logarithmic) Euclidean space. We show how we can use this model for color image enhancement and we present some experimental results.
Road Segmentation for Remote Sensing Images using Adversarial Spatial Pyramid Networks
Aug 10, 2020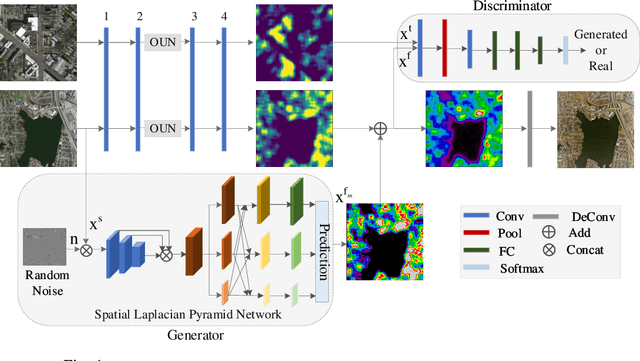
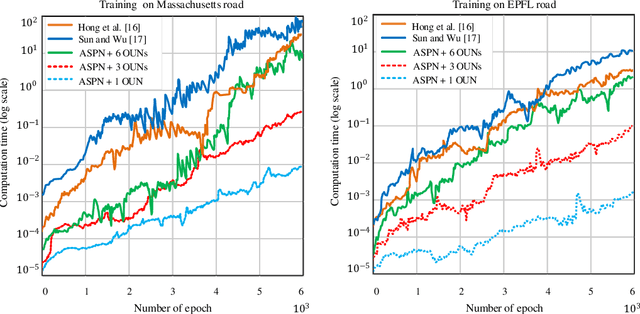
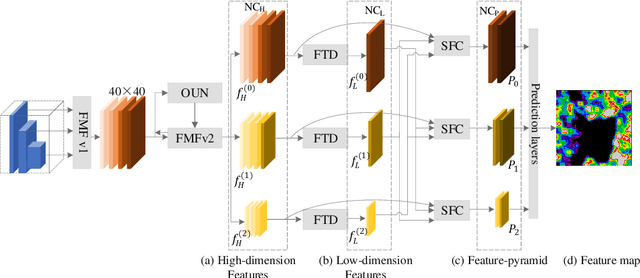
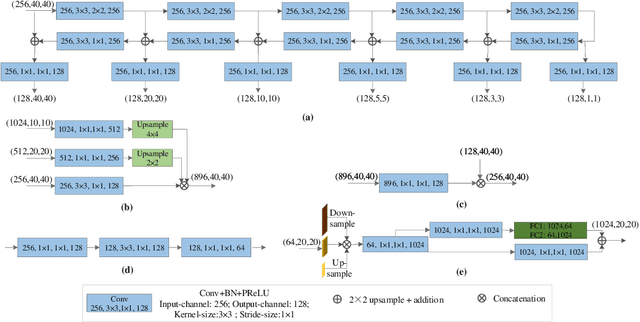
Road extraction in remote sensing images is of great importance for a wide range of applications. Because of the complex background, and high density, most of the existing methods fail to accurately extract a road network that appears correct and complete. Moreover, they suffer from either insufficient training data or high costs of manual annotation. To address these problems, we introduce a new model to apply structured domain adaption for synthetic image generation and road segmentation. We incorporate a feature pyramid network into generative adversarial networks to minimize the difference between the source and target domains. A generator is learned to produce quality synthetic images, and the discriminator attempts to distinguish them. We also propose a feature pyramid network that improves the performance of the proposed model by extracting effective features from all the layers of the network for describing different scales objects. Indeed, a novel scale-wise architecture is introduced to learn from the multi-level feature maps and improve the semantics of the features. For optimization, the model is trained by a joint reconstruction loss function, which minimizes the difference between the fake images and the real ones. A wide range of experiments on three datasets prove the superior performance of the proposed approach in terms of accuracy and efficiency. In particular, our model achieves state-of-the-art 78.86 IOU on the Massachusetts dataset with 14.89M parameters and 86.78B FLOPs, with 4x fewer FLOPs but higher accuracy (+3.47% IOU) than the top performer among state-of-the-art approaches used in the evaluation.